【python】绘图代码模板
【python】绘图代码模板
- pandas.DataFrame.plot( )画图函数
- Seaborn绘图 -数据可视化必备
- 主题样式
- 导入数据集
- 可视化统计关系
- 散点图
- 抖动图
- 箱线图
- 小提琴图
- Pointplot
- 群图
- 可视化数据集的分布
- 绘制单变量分布
- 柱状图
- 直方图
- 绘制双变量分布
- Hex图
- KDE 图
- 可视化数据集中的成对关系
- 好看的图模板
- 来自宽格式数据集的线图
- 带观察值的水平箱线图
- 多个面上的线图
- 具有多种语义的散点图
- 问题解决方案
- 解决seaborn绘图无法显示中文等问题
pandas.DataFrame.plot( )画图函数
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None,xerr=None,secondary_y=False, sort_columns=False, **kwds)以下是DataFrame.plot()方法的参数以及它们的作用和可选值:
-
x:横轴的列名或位置索引,用于指定绘图时使用的横轴数据。 -
y:纵轴的列名或位置索引,用于指定绘图时使用的纵轴数据。 -
kind:绘图类型,可以是以下选项:'line':折线图'bar':垂直条形图'barh':水平条形图'hist':直方图'box':箱线图'kde':核密度估计图'density':与'kde'相同'area':面积图'pie':饼图'scatter':散点图'hexbin':六边形散点图
-
ax:Matplotlib Axes对象,用于在已有的图形上添加新的图层。 -
subplots:布尔值,如果为True,则为每个列绘制单独的子图。 -
sharex:布尔值,如果subplots为True,则共享x轴。 -
sharey:布尔值,如果subplots为True,则共享y轴。 -
layout:元组,用于指定子图的行列布局。 -
figsize:元组,图形的尺寸,以英寸为单位。 -
use_index:布尔值,默认为True,使用行索引作为x轴。 -
title:字符串,图形的标题。 -
grid:布尔值,控制是否显示网格线。 -
legend:布尔值或者字符串’reverse’,控制是否显示图例。 -
style:列表或字典,用于指定每列折线图的线条样式。 -
logx:布尔值,是否使用对数坐标轴(x轴)。 -
logy:布尔值,是否使用对数坐标轴(y轴)。 -
loglog:布尔值,是否同时使用对数坐标轴(x轴和y轴)。 -
xticks:序列,用于自定义x轴刻度值。 -
yticks:序列,用于自定义y轴刻度值。 -
xlim:列表或元组,自定义x轴显示范围。 -
ylim:列表或元组,自定义y轴显示范围。 -
rot:整数,设置刻度标签的旋转角度。 -
fontsize:整数,设置刻度标签的字体大小。 -
colormap:字符串或Matplotlib colormap对象,默认为None,用于选择图的区域颜色。 -
colorbar:布尔值,如果为True,则在柱状图和散点图上添加颜色条。 -
position:浮点数,用于指定条形图布局的相对对齐位置(0表示左端/底端,1表示右端/顶端)。 -
table:布尔值、Series或DataFrame,默认为False,如果为True,则根据DataFrame的数据绘制表格。 -
yerr和xerr:DataFrame、Series、数组或字典,用于绘制带有误差条的图表(详情请参考绘图带有误差条的方法)。 -
stacked:布尔值,在折线图和柱状图中默认为False,在面积图中默认为True,用于创建堆叠图。 -
sort_columns:布尔值,默认为False,以字母表顺序绘制各列,默认使用前列顺序。 -
secondary_y:布尔值或序列,默认为False,是否在右侧添加第二个y轴。如果是序列,指定要在右侧绘制的列。 -
mark_right:布尔值,默认为True,当使用第二个y轴时,是否自动在图例中标记列标签为"(right)"。 -
**kwds:其他传递给Matplotlib绘图方法的关键字参数。
返回值:
axes:Matplotlib AxesSubplot对象或其数组。
示例:
import pandas as pd
import matplotlib.pyplot as plt# 创建示例数据
data = {'Year': [2015, 2016, 2017, 2018, 2019, 2020, 2021],'Sales': [100, 120, 150, 180, 200, 230, 250],'Expenses': [80, 90, 100, 110, 120, 130, 140]
}df = pd.DataFrame(data)# 绘制折线图
df.plot(x='Year', y=['Sales', 'Expenses'], kind='line', marker='o', linewidth=2)
plt.title('Sales and Expenses Over Years')
plt.xlabel('Year')
plt.ylabel('Amount (in thousands)')
plt.grid(True)
plt.legend(['Sales', 'Expenses'])
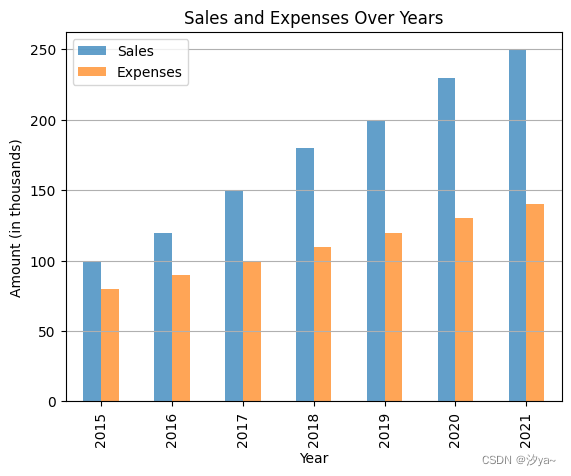
plt.show()# 绘制条形图
df.plot(x='Year', y=['Sales', 'Expenses'], kind='bar', alpha=0.7)
plt.title('Sales and Expenses Over Years')
plt.xlabel('Year')
plt.ylabel('Amount (in thousands)')
plt.grid(axis='y')
plt.legend(['Sales', 'Expenses'])
plt.show()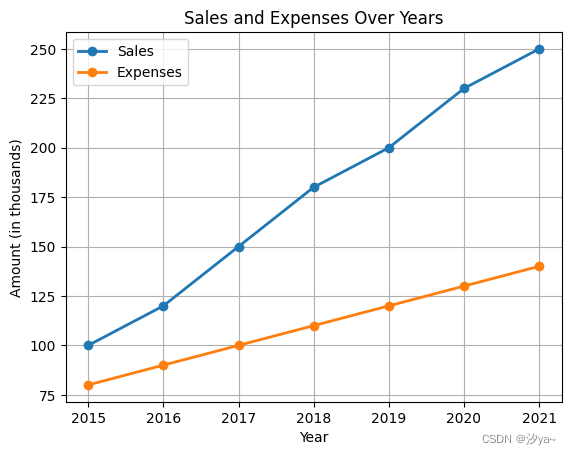
Seaborn绘图 -数据可视化必备
官方示例:https://seaborn.pydata.org/tutorial.html
Seaborn是一个构建在matplotlib之上的一个非常完美的Python可视化库。
与Matplotlib的低级接口相比,Seaborn具有高级接口。适合处理数据流
主题样式
Seaborn 有五个预设的主题样式:darkgrid、whitegrid、dark、white 和 ticks。这些主题样式可通过 sns.set(style='样式名') 或 sns.set_style('样式名') 命令切换
darkgrid 主题,显示灰色背景带网格线,无坐标轴刻度线。# 默认主题,可简写为 sns.set()
whitegrid 主题,显示白色背景带网格线,无坐标轴刻度线。
dark 主题,显示灰色背景无网格线,无坐标轴刻度线。
white 主题,显示白色背景无网格线,无坐标轴刻度线。
ticks 主题,显示白色背景无网格线,有坐标轴刻度线
需要导入的包
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from scipy import stats
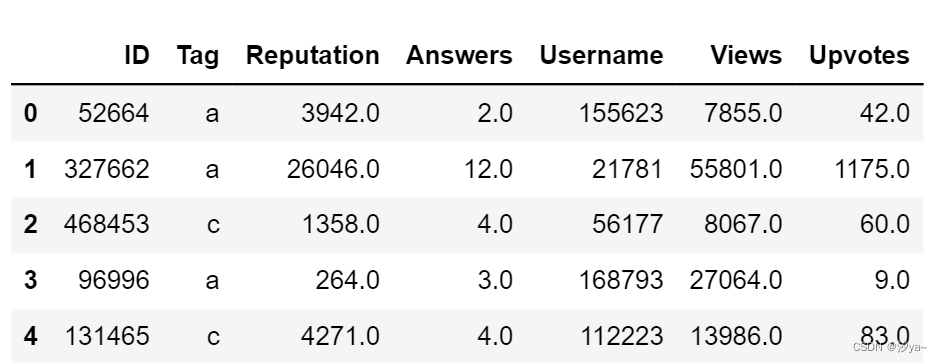
导入数据集
数据来源:https://datahack.analyticsvidhya.com/contest/enigmacodefestmachinelearning1/
df = pd.read_csv(r"train_NIR5Yl1.csv")
df.head()
可视化统计关系
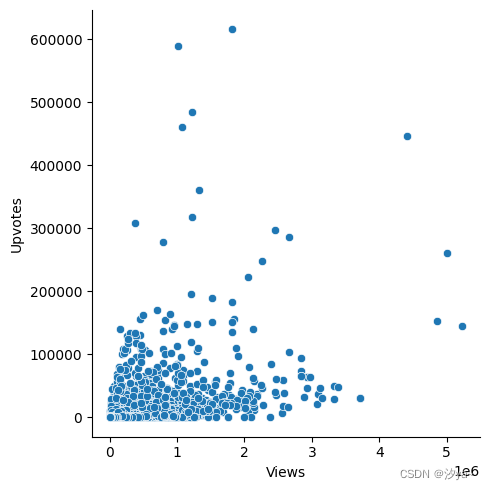
散点图
散点图可以可视化两个变量之间的关系。每个点在数据集中显示一个观察值,这些观察值用点状结构表示。图中显示了两个变量的联合分布。
# 创建图形和轴
sns.relplot(x="Views", y="Upvotes", data = df)
显示与数据相关的标签
sns.relplot(x="Views", y="Upvotes", hue = "Tag", data = df)
# 另外还可以通过参数size = "Tag"或者数size=(15,200)。,改变点大小
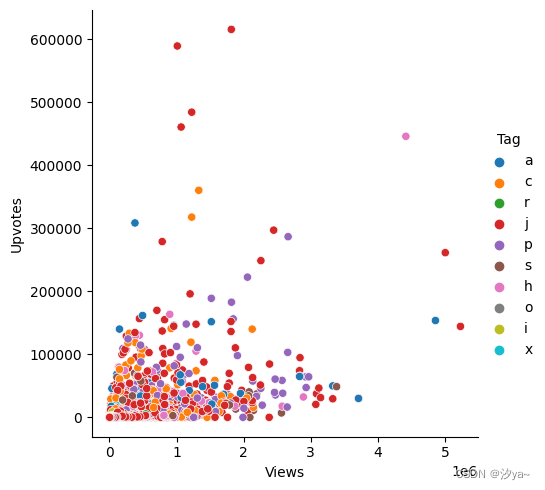
另外可以在色调(Hue)的帮助下在我们的图片中添加另一个维度,通过为点赋予颜色来实现,每种颜色都有一些附加的意义。
sns.relplot(x="Views", y="Upvotes", hue = "Answers", data = df);
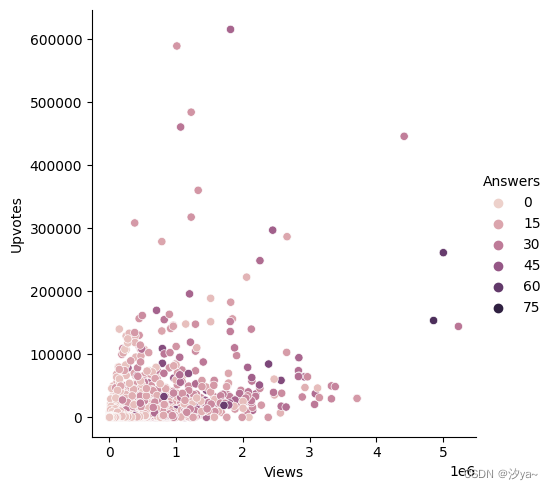
抖动图
使用的数据来源:https://datahack.analyticsvidhya.com/contest/wnsanalyticshackathon20181/
使用catplot()函数查看education列和avg_training_score列之间的关系
sns.catplot(x="education", y="avg_training_score", jitter = False, data=df2)
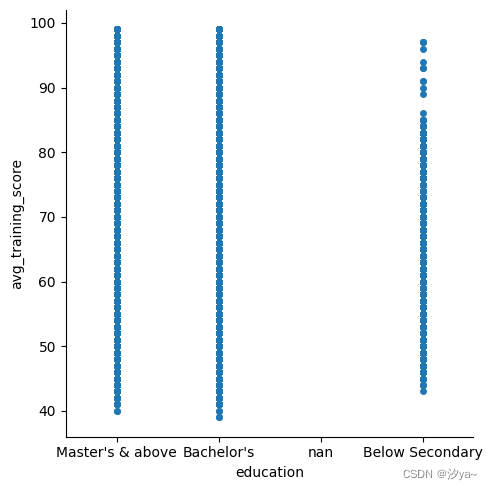
在Seaborn的catplot函数中,jitter参数控制是否对数据点进行抖动(jittering)。抖动是在分类变量上添加一些随机的小偏移量,使得数据点在x轴上稍微分散,从而防止多个数据点重叠在同一个位置,增加可视化的可读性。
-
jitter=True:表示在x轴上对数据进行抖动。这样做可以有效避免数据点的重叠,特别是当数据较密集时,使得图表更易于观察和解读。 -
jitter=False:表示不对数据进行抖动。如果你的数据不太密集,或者你更关心各个数据点的精确位置,可以选择这个选项。
选择是否使用抖动取决于数据的特点和你想要达到的可视化效果。对于大多数情况下,启用抖动是一个好的选择,因为它可以帮助更好地展示数据的分布情况。然而,如果你的数据较少或者有特定需求,可以将jitter设置为False。
Hue图
接下来,如果我们想在我们的图中引入另一个变量或另一个维度,我们可以使用hue参数。假设我们希望看到教育和avg_training_score图中的性别分布
sns.catplot(x="education", y="avg_training_score", hue = "gender", data=df2)
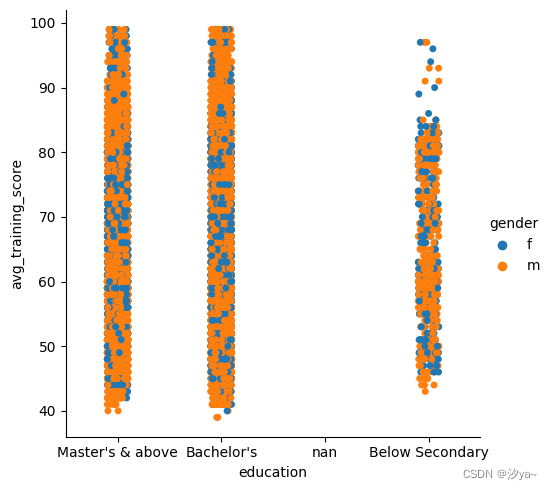
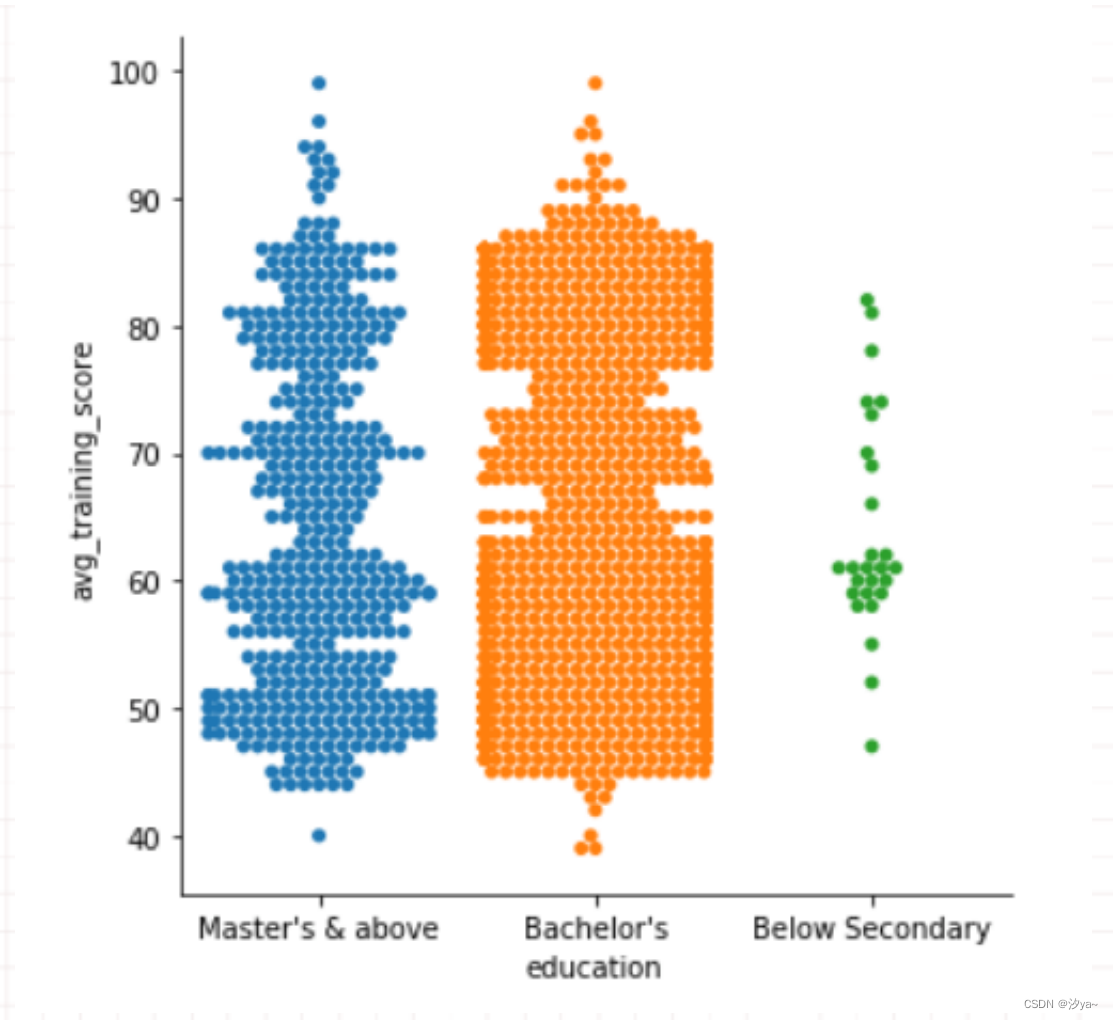
在上面的图中,一些点是相互重叠的,为了消除这种情况,可以设置kind =
“swarm”, swarm使用一种算法来防止这些点重叠,并且沿着分类轴调整这些点。
sns.catplot(x="education", y="avg_training_score", kind = "swarm", data=df2)
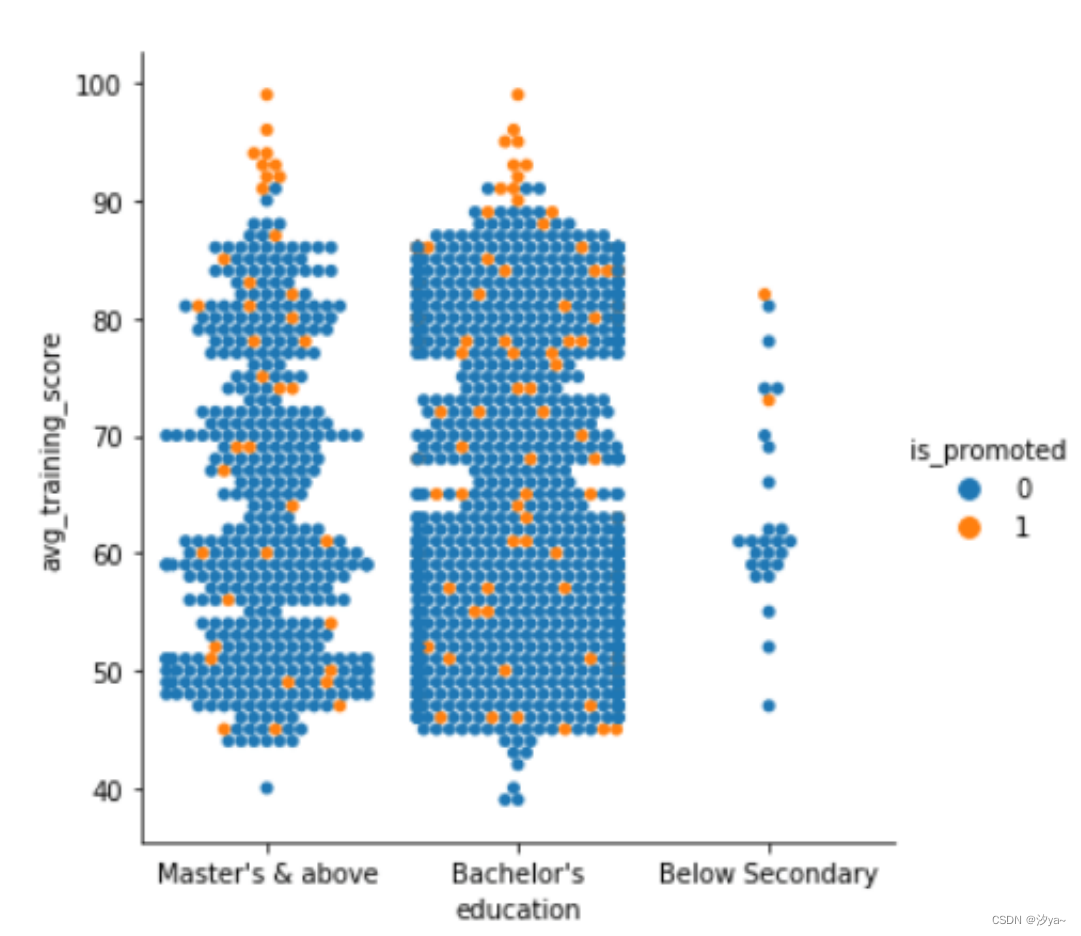
将is_promoted作为一个新变量引入
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "swarm", data=df2)
箱线图
箱线图 ,它显示了分布的三个四分位值以及最终值。箱图中的每个值都对应于数据中的实际观察值
sns.catplot(x="education", y="avg_training_score", kind = "box", data=df2)

小提琴图
小提琴图结合了箱线图和核密度估计程序,以提供更丰富的值分布描述。四分位数值显示在小提琴内部。
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "violin", data=df2)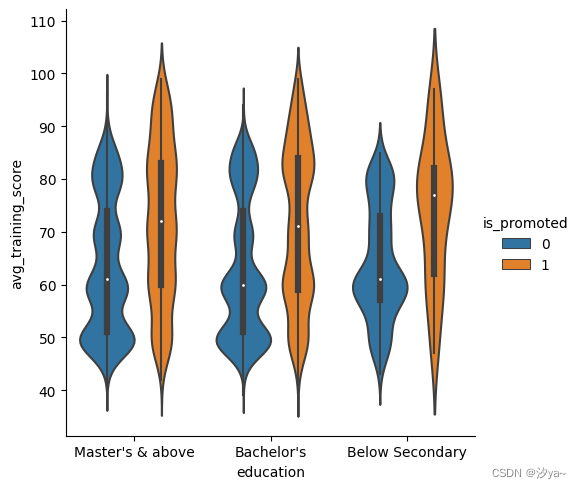
当色调语义参数是二值时,我们还可以拆分小提琴,这也可能有助于节省绘图空间。
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "violin",split=True, data=df2)
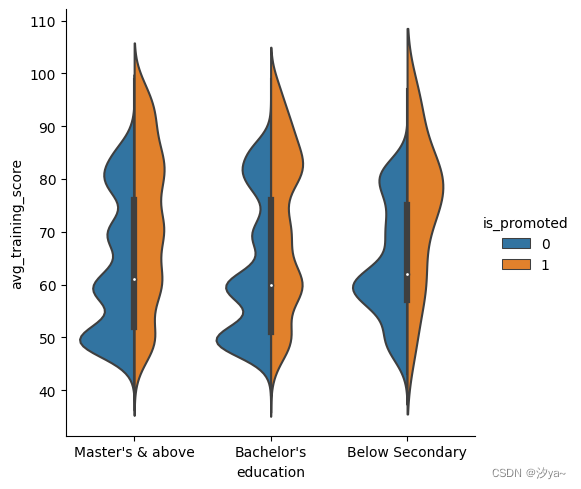
Pointplot
pointplot,这个图指出估计值和置信区间。Pointplot连接来自相同色调类别的数据。这有助于识别特定色调类别中的关系如何变化
sns.catplot(x="education", y="avg_training_score", hue = "is_promoted", kind = "point", data=df2)
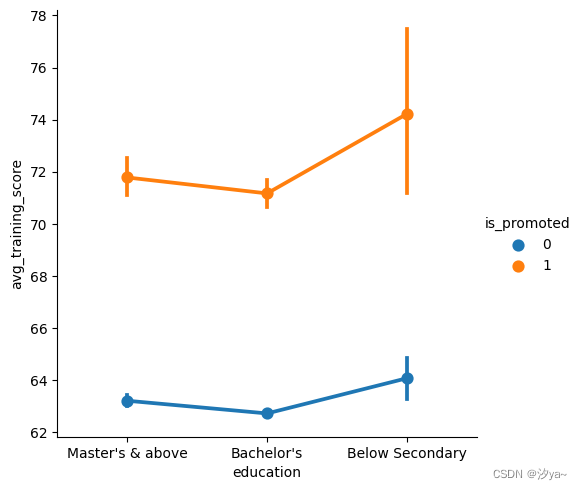
群图
sns.catplot(x="education", # x轴上的分类变量,这里是教育程度y="avg_training_score", # y轴上的数值变量,这里是平均培训分数hue="is_promoted", # 按照是否晋升(is_promoted)来给数据点着色col="gender", # 按照性别(gender)分列绘制图表aspect=.9, # 控制每个绘图块(facet)的纵横比例kind="swarm", # 指定绘图类型为分类散点图(swarm plot)data=df2) # 数据来源,这里是一个DataFrame df2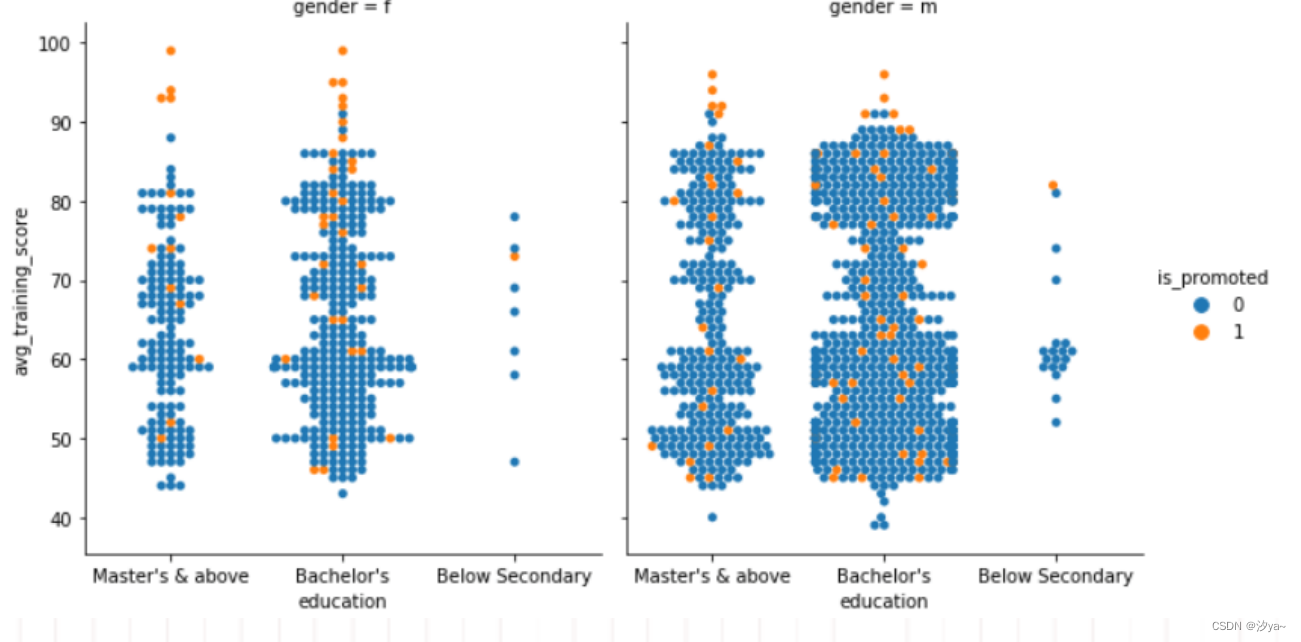
可视化数据集的分布
绘制单变量分布
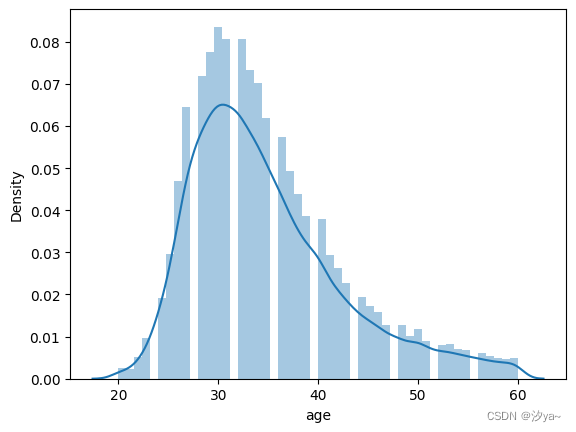
柱状图
在研究变量分布时,最常见的是柱状图。默认情况下,distplot()函数绘制柱状图并适合内核密度估计
sns.distplot(df2.age)
直方图
直方图以箱子的形式表示数据的分布,并使用条形图来显示每个箱子下的观察次数。我们还可以在其中添加一个加固图,而不是使用KDE(核密度估计),这意味着在每次观察时,它都会画一个小的垂直标尺。
sns.distplot(df2.age, kde=False, rug = True)
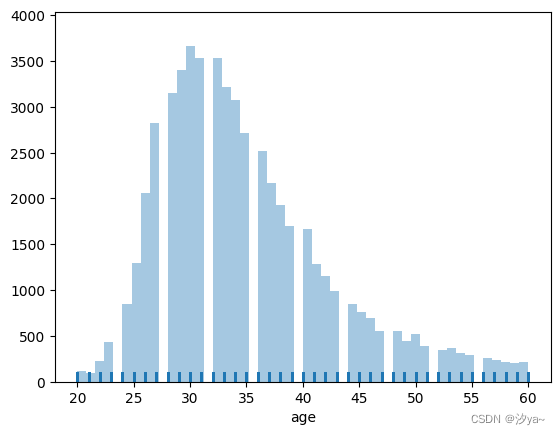
绘制双变量分布
使用了seaborn库的jointplot()函数。默认情况下,jointplot绘制散点图。
sns.jointplot(x="avg_training_score", y="age", data=df2);
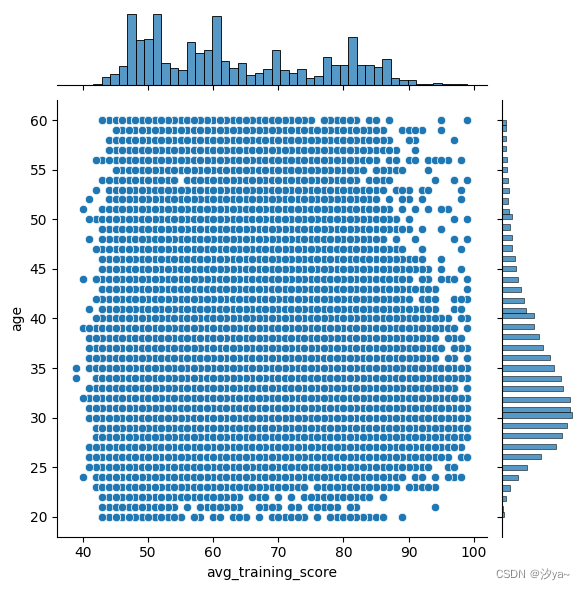
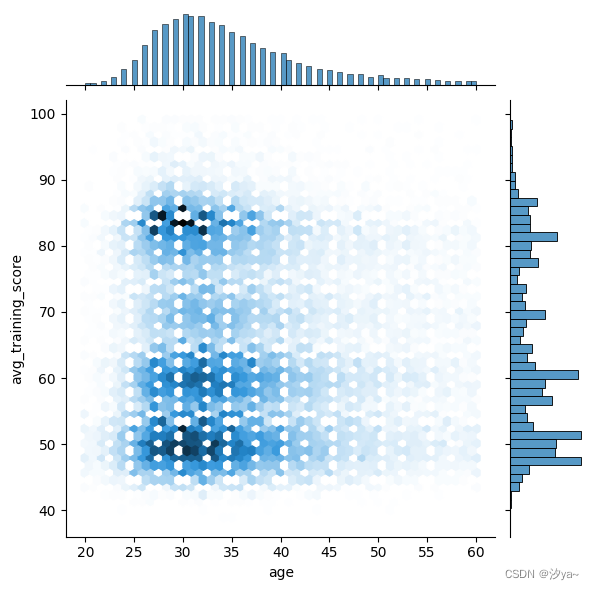
Hex图
Hexplot是一个双变量的直方图,因为它显示了在六边形区域内的观察次数。这是一个非常容易处理大数据集的图。为了绘制Hexplot,我们将把kind属性设置为hex
sns.jointplot(x=df2.age, y=df2.avg_training_score, kind="hex", data = df2)
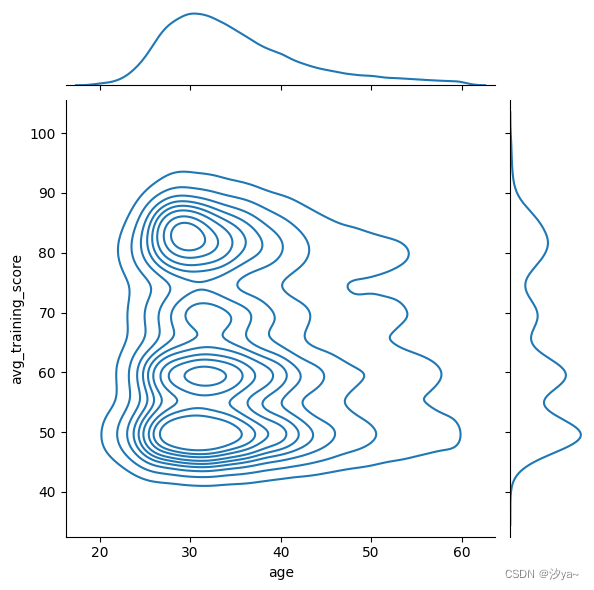
KDE 图
sns.jointplot(x="age", y="avg_training_score", data=df2, kind="kde");
可视化数据集中的成对关系
sns.pairplot(df2)

好看的图模板
来自宽格式数据集的线图
# 导入必要的库
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid") # 设置Seaborn绘图的主题和样式# 创建一个随机种子,以便结果可以复现
rs = np.random.RandomState(365)# 生成一个包含随机数据的数组,形状为(365, 4),并计算每一列的累积和
values = rs.randn(365, 4).cumsum(axis=0)# 创建日期范围为2016年1月1日起的365个日期,间隔为1天
dates = pd.date_range("1 1 2016", periods=365, freq="D")# 使用Pandas将数据和日期合并为DataFrame,并给每列指定名称"A", "B", "C", "D"
data = pd.DataFrame(values, dates, columns=["A", "B", "C", "D"])# 使用滚动窗口计算每列的7天滚动均值,并更新数据
data = data.rolling(7).mean()# 使用Seaborn绘制折线图,展示数据中每列的变化趋势
sns.lineplot(data=data, palette="tab10", linewidth=2.5)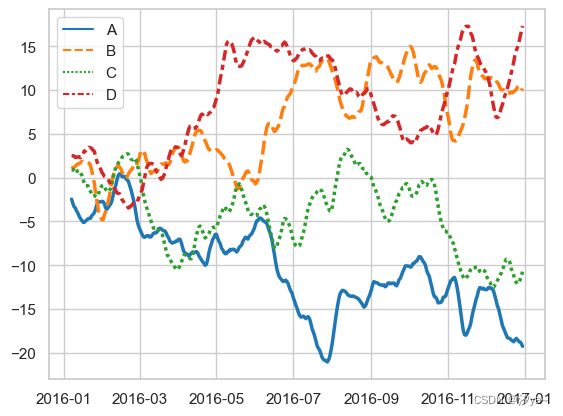
带观察值的水平箱线图
数据来源:https://github.com/mwaskom/seaborn-data/blob/master/planets.csv
# 导入所需的库
import seaborn as sns
import matplotlib.pyplot as plt# 设置seaborn的主题样式为'ticks'
sns.set_theme(style="ticks") # 初始化图表,大小为(7,6),并设置x轴为对数刻度
f, ax = plt.subplots(figsize=(7, 6))
ax.set_xscale("log")# 载入seaborn内置的'planets'数据集
planets = pd.read_csv(r"planets.csv")# 使用箱形图绘制'distance'为x轴,'method'为y轴
# 设置whis可显示异常值的范围,width调整箱形的宽度
# 使用'vlag'色阶
sns.boxplot(x="distance", y="method", data=planets, whis=[0, 100], width=.6, palette="vlag")# 使用散点图绘制'distance'为x轴,'method'为y轴
# 设置点的大小,颜色和线宽
sns.stripplot(x="distance", y="method", data=planets,size=4, color=".3", linewidth=0)# 数据可视化美化
# 显示x轴网格线,移除y轴标签,裁剪左边边框
ax.xaxis.grid(True)
ax.set(ylabel="")
sns.despine(trim=True, left=True)# 显示图表
plt.show()
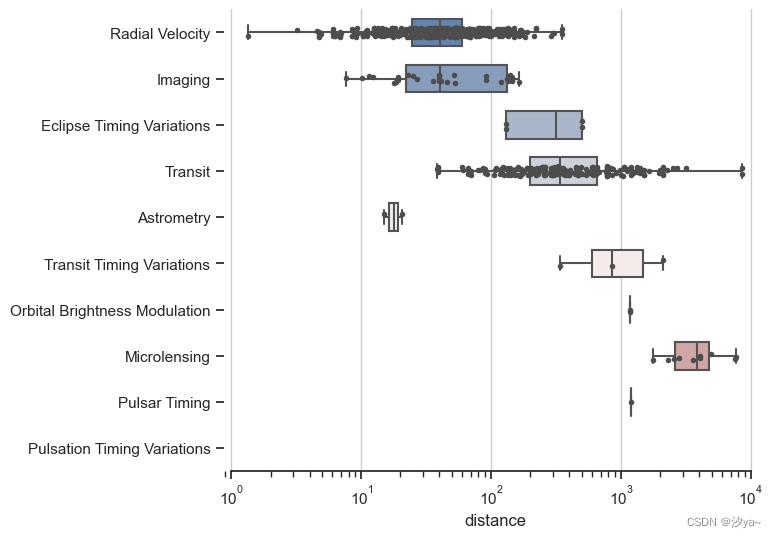
多个面上的线图
import seaborn as sns # 设置seaborn主题样式为'ticks'
sns.set_theme(style="ticks") # 加载'sdots'示例数据集
dots = sns.load_dataset("dots")# 定义调色板的具体颜色值
palette = sns.color_palette("rocket_r") # 绘制两面多个线图
# x轴为'time',y轴为'firing_rate'
# hue表示颜色区分的变量'coherence'
# size表示点的大小代表的变量'choice'
# col表示按'slign'分面
# kind指定折线图类型
# size_order设置点的大小顺序
# palette定义上面指定的调色板
# height/aspect设置图形大小,facet_kws定义分面参数
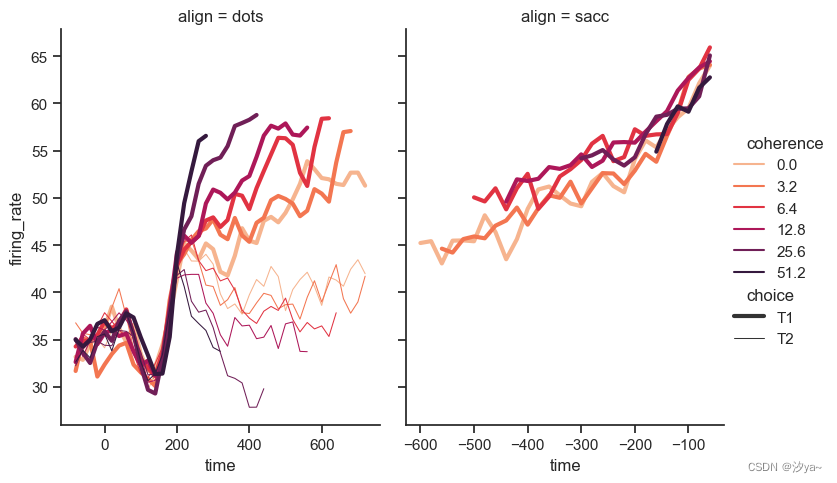
sns.relplot(data=dots, x="time", y="firing_rate",hue="coherence", size="choice", col="align",kind="line", size_order=["T1", "T2"], palette=palette,height=5, aspect=.75, facet_kws=dict(sharex=False))# 该图的作用是:
# 使用线图展示'dots'数据集中
# 'time','firing_rate'两个变量的关系
# 并利用颜色、点大小、分面等视觉编码显示不同的第三维和第四维信息
# 直观呈现多维数据集的关系
具有多种语义的散点图
import seaborn as sns
import matplotlib.pyplot as plt# 设置seaborn主题样式为白色网格
sns.set_theme(style="whitegrid") # 加载内置的钻石数据集
diamonds = sns.load_dataset("diamonds")# 初始化图像和子图,并移除子图边框
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)# 定义钻石clarity的排序
clarity_ranking = ["I1", "SI2", "SI1", "VS2", "VS1", "VVS2", "VVS1", "IF"] # 绘制散点图
# x轴为carat,y轴为price
# hue为clarity,即颜色区分clarity
# size为depth,即点的大小代表depth
# palette定义颜色渐变
# hue_order指定上面定义的clarity顺序
# sizes设置点的大小范围
# data和ax指定所用的数据及子图
sns.scatterplot(x="carat", y="price", hue="clarity", size="depth",palette="ch:r=-.2,d=.3_r",hue_order=clarity_ranking,sizes=(1, 8), linewidth=0,data=diamonds, ax=ax)# 这是一个组合了多个变量的散点图
# 既展示了carat与price的关系
# 又通过颜色和大小编码呈现了clarity和depth维度的信息
# 可以更清晰地呈现钻石数据集的多维分布情况
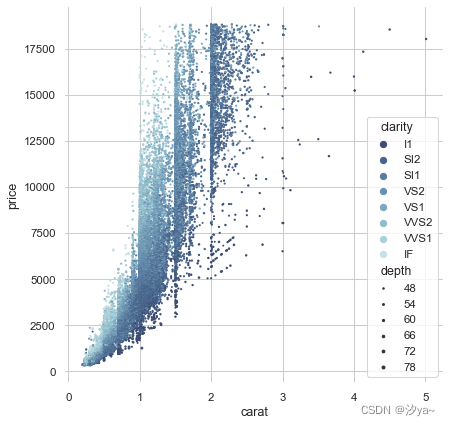
问题解决方案
解决seaborn绘图无法显示中文等问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决无法显示符号的问题
sns.set(font='SimHei', font_scale=0.8) # 解决Seaborn中文显示问题相关文章:
【python】绘图代码模板
【python】绘图代码模板 pandas.DataFrame.plot( )画图函数Seaborn绘图 -数据可视化必备主题样式导入数据集可视化统计关系散点图抖动图箱线图小提琴图Pointplot群图 可视化数据集的分布绘制单变量分布柱状图直方图 绘制双变量分布Hex图KDE 图可视化数据集中的成对关系 好看的图…...
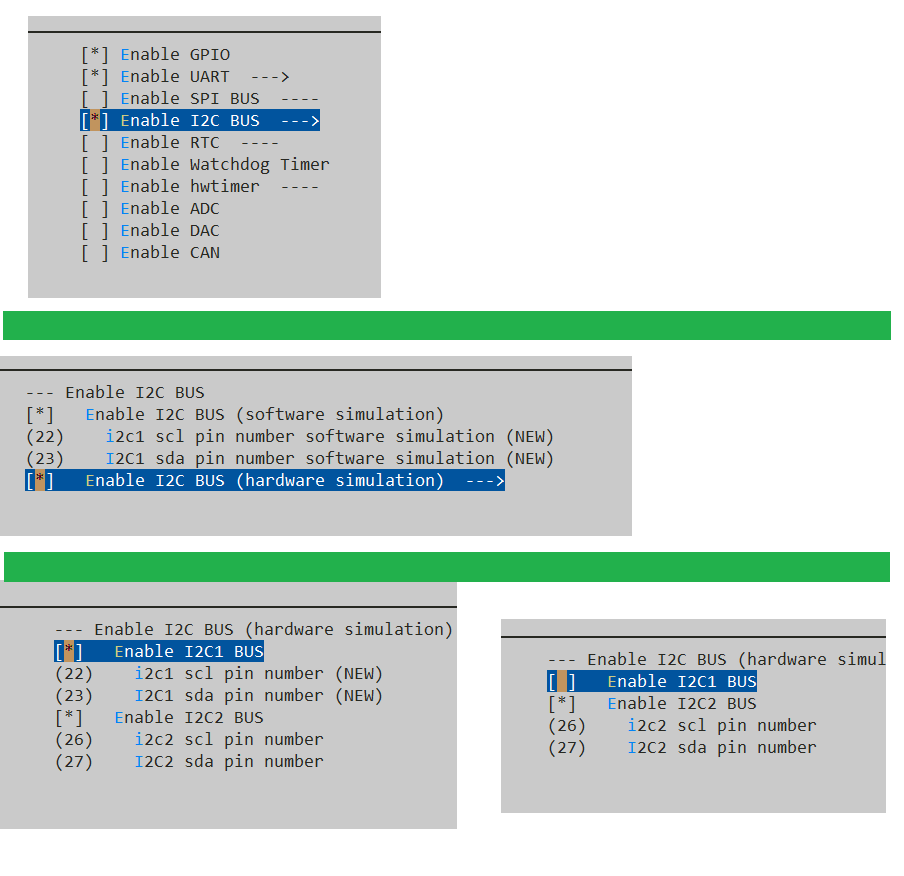
RTT学习笔记12-KConfig 语法学习
KConfig 语法学习 RTT 官方教程 https://www.rt-thread.org/document/site/#/development-tools/build-config-system/Kconfig 我自己写的IIC配置 menuconfig BSP_USING_I2C # I2C 菜单bool "Enable I2C BUS" # 提示I2C 菜单default n # 默认不使能I2C 菜单…...
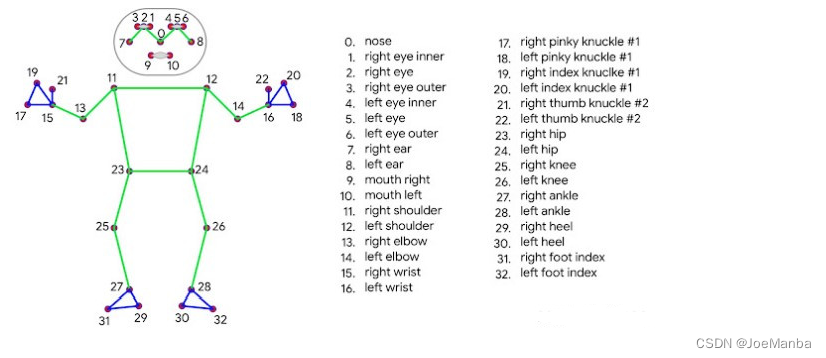
基于Mediapipe的姿势识别并同步到Unity人体模型中
如题,由于是商业项目,无法公开源码,这里主要说一下实现此功能的思路。 人体关节点识别 基于Mediapipe Unity插件进行开发,性能比较低的CPU主机,无法流畅地运行Mediapipe,这个要注意一下。 Mediapipe33个人体…...
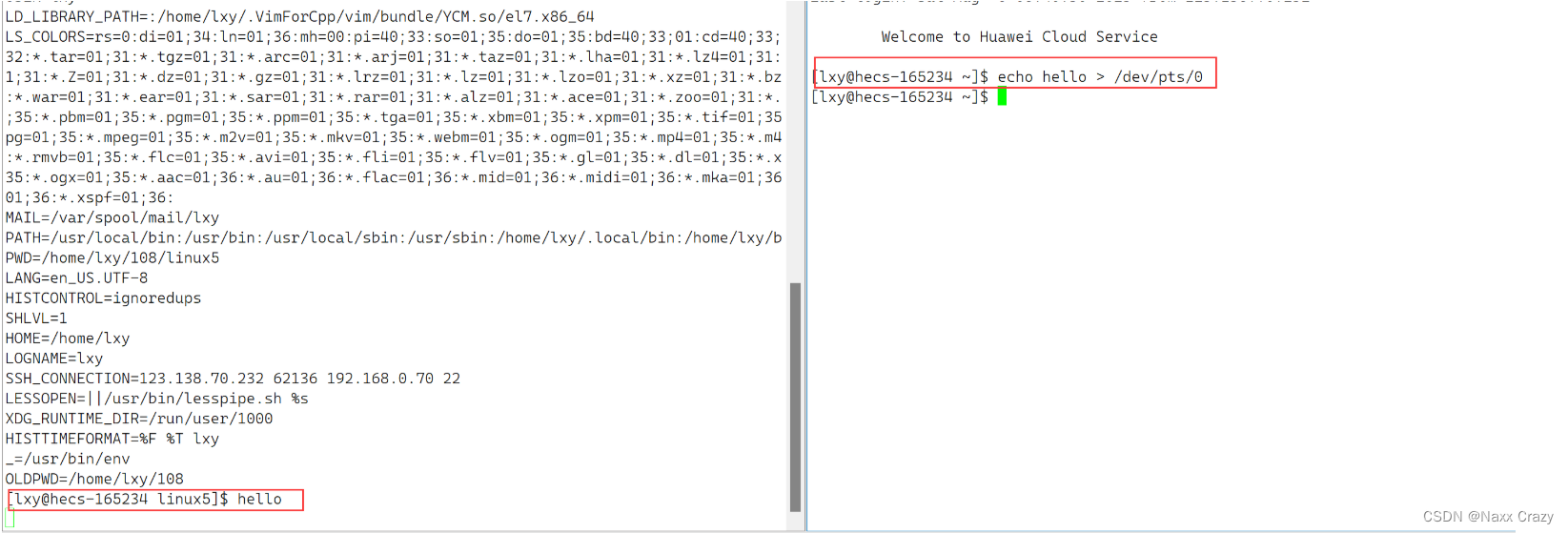
Linux下进程的特点与环境变量
目录 进程的特点 进程特点的介绍 进程时如何实现并发性的 进程间如何切换 概念铺设 PC指针 上下文 环境变量 PATH 修改PATH HOME SHELL env 命令行参数 什么是命令行参数? 打印命令行参数 通过函数获得环境变量 getenv 命令行参数 env 修改环境变…...

以Llama-2为例,在生成模型中使用自定义LogitsProcessor
以Llama-2为例,在生成模型中使用自定义LogitsProcessor 1. 前言2. 场景介绍3. 解决方法4. 结语 1. 前言 在上一篇文章 以Llama-2为例,在生成模型中使用自定义StoppingCriteria中,介绍了怎样在生成的过程中,使用stopping criteria…...

python 计算图片hash 缓存图片为key
python,有时希望缓存图片作为key,怎么办?缓存整张突破占用内存太多,不妨缓存hash值: Fast way to Hash Numpy objects for Caching import hashlib import numpy a numpy.random.rand(10, 100) b a.view(numpy.uin…...

制造型企业如何实现车间设备生产数据的实时采集?需要5G网络吗?
引言 在制造业数字化转型的浪潮下,实时采集车间设备生产数据变得尤为重要。工业边缘网关HiWoo Box作为一款专为工业应用而设计的智能设备,具备工业级设计和多种联网方式,为制造型企业提供了高性能的车间设备数据实时采集解决方案。本文将重点…...

第2章 HTML中的JavaScript
引言 将JavaScript引入网页,首先要解决它与网页的主导语言HTML的关系问题 script元素 将JavaScript插入HTML的主要方法是使用script元素,script有8个可选属性 async:表示异步加载js文件内容,他们之间的顺序不一定按照html顺序ch…...
景联文科技高质量成品数据集上新啦!
景联文科技近期上新多个成品数据集,包含图像、视频等多种类型的数据,涵盖丰富的场景,可满足不同模型的多元化需求。 高质量成品数据集可用于训练和优化模型,使得模型能够更加全面和精准地理解和处理任务,更好地应对复…...

flask------请求拓展
flask中也有类似与django中的中间件,只不过是另一种写法,但是他们的作用是一样的,下面我们就一一介绍: 1.before_request 作用 : before_request 相当于 django 中的 process_request,每一个请求在被处理前都会经…...

大数据-玩转数据-FLINK-从kafka消费数据
一、基于前面kafka部署 大数据-玩转数据-Kafka安装 二、FLINK中编写代码 package com.lyh.flink04;import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apa…...
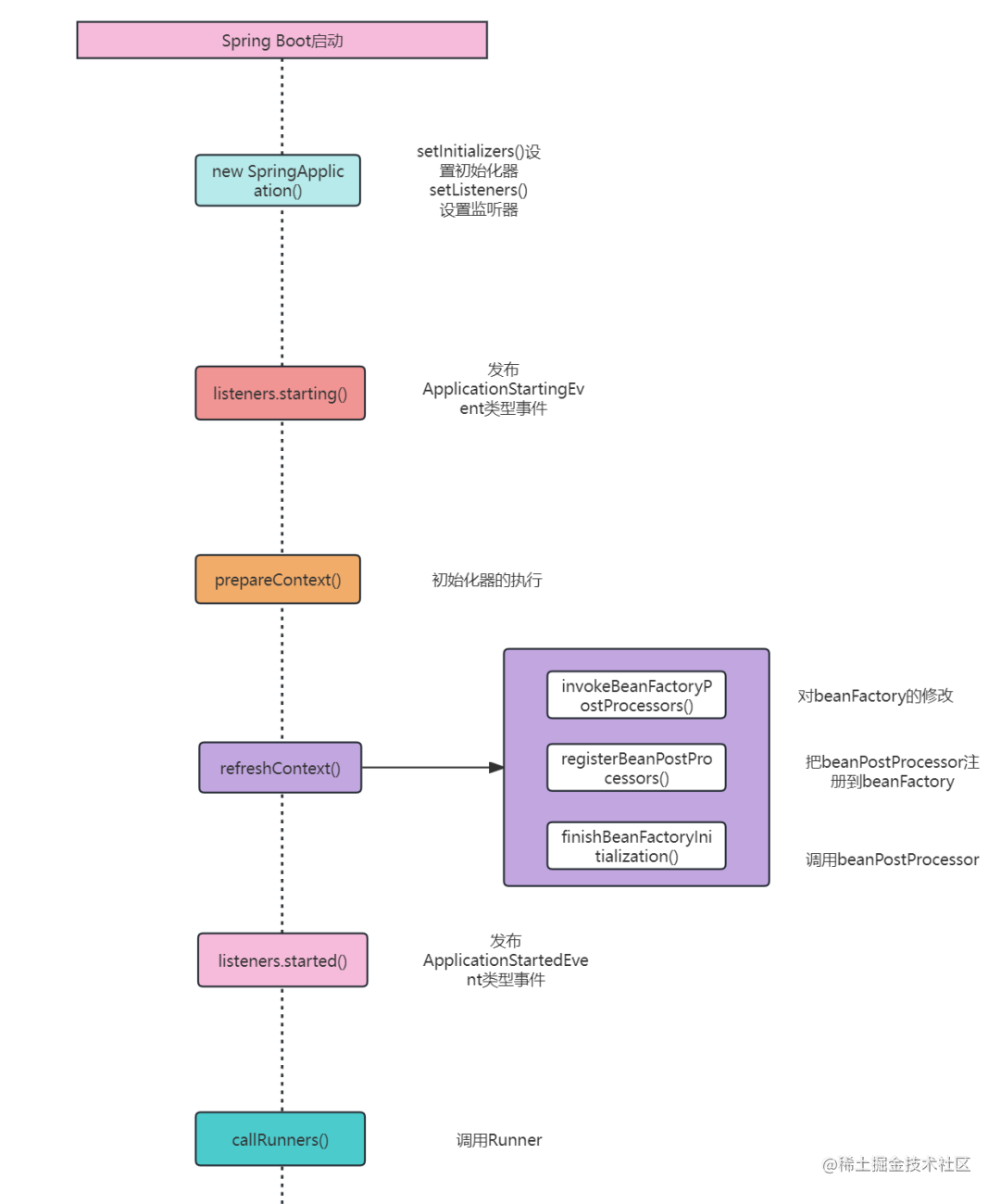
介绍Sping Boot的5个扩展点
1、初始化器ApplicationContextInitializer 我们在启动Spring Boot项目的时候,是执行这样一个方法来启动的 我们一层一层往下点,最终发现执行的是这个方法 所以我们在启动项目的时候也可以这样启动 new SpringApplication(SpringbootExtensionPointAp…...

Linux2.6内核配置说明
maturity level options代码成熟度选项 Prompt for development and/or incomplete code/drivers 显示尚在开发中或尚未完成的代码与驱动.除非你是测试人员或者开发者,否则请勿选择 setup常规设置 Local version - append to kernel release 在内核版本后面加上自定义的…...

Pytest简介及jenkins集成
一、pytest介绍 pytest介绍 - unittest\nose pytest:基于unittest之上的单元测试框架 自动发现测试模块和测试方法 断言使用assert表达式即可 可以设置测试会话级、模块级、类级、函数级的fixtures 数据准备 清理工作 unittest:setUp、teardown、…...

【LeetCode】105. 从前序与中序遍历序列构造二叉树 106. 从中序与后序遍历序列构造二叉树
105. 从前序与中序遍历序列构造二叉树 这道题也是经典的数据结构题了,有时候面试题也会遇到,已知前序与中序的遍历序列,由前序遍历我们可以知道第一个元素就是根节点,而中序遍历的特点就是根节点的左边全部为左子树,右…...
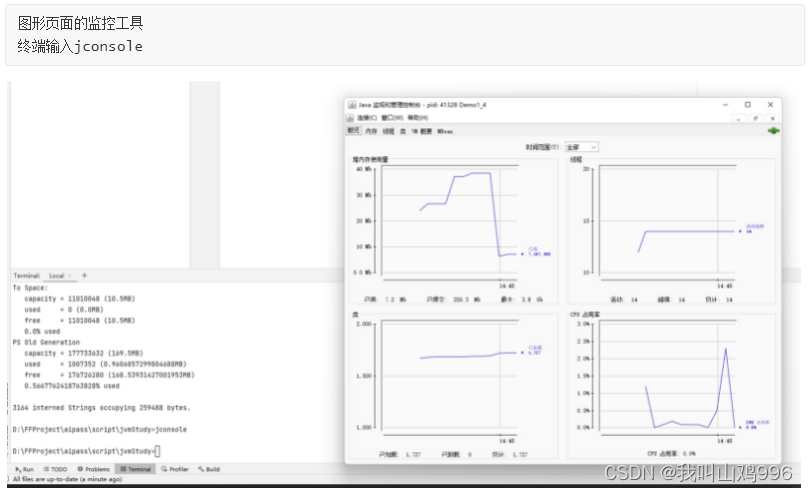
堆内存和一些检测工具
17 堆定义 通过new关键字创建,创建对象都会使用堆内存。 是线程共享的,需要考虑线程安全问题。 有垃圾回收机制。18 堆-内存溢出 当默认情况下,发现执行到26,出现内存溢出。 当我们将堆内存调为8m,继续执行ÿ…...

【JavaScript】元素获取指南
简介 在 JavaScript 中,我们经常需要通过获取元素来进行 DOM 操作和交互。本教程将介绍多种获取元素的方式,包括根据 ID、标签名、类名、选择器、属性和名称等。 通过ID获取元素 使用getElementById方法根据元素的ID属性获取单个元素。 var element = document.getElementB…...
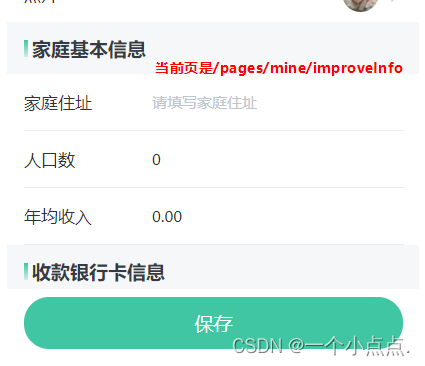
uniapp 返回上一页并刷新
如要刷新的是mine页面 在/pages/mine/improveInfo页面修改信息,点击保存后跳转到个人中心(/pages/mine/index)页面并刷新更新数据 点击保存按钮时执行以下代码: wx.switchTab({url: /pages/mine/index }) // 页面重载 let pages …...
Java阶段五Day21
Java阶段五Day21 文章目录 Java阶段五Day21问题解析rocketmq清空数据 linux学习背景什么是linux系统虚拟机介绍启动 虚拟机linux虚拟机网络的问题 linux系统的基础命令命令提示符命令格式pwd指令ls指令cd指令mkdirtouch指令cp指令rm指令mv指令cat指令tail指令 文本编辑器vim操作…...
2023,谁在引领实时互动进入高清时代?
实践是检验真理的唯一标准,技术是行业进步的核心动能。在实时互动的新时代里,不断进化的声网已然完成自证。 作者|斗斗 出品|产业家 “一个医疗行业的客户,曾向我们提出一个需求,希望在120急救场景下,可以远程看清…...

Pine Script交易策略开发实战指南:从零基础到自动化交易的完整路径
Pine Script交易策略开发实战指南:从零基础到自动化交易的完整路径 【免费下载链接】awesome-pinescript A Comprehensive Collection of Everything Related to Tradingview Pine Script. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-pinescript …...
)
电路分析不求人:手把手教你用戴维南定理搞定复杂电路(附Multisim仿真验证)
电路分析实战:用戴维南定理拆解复杂电路的全流程指南 当你面对一个布满电阻、电源和交叉连线的复杂电路图时,是否感到无从下手?戴维南定理就像一把瑞士军刀,能将这些看似棘手的电路简化为一个电压源和一个电阻的串联组合。但理论归…...

RN 0.63 双端冷启动线程流转
RN 0.63 旧架构下,Android 和 iOS 的冷启动都经历了相同的思路:主线程入口 → 后台线程做重活(创建引擎、加载 Bundle)→ JS Thread 接管 → Shadow 计算布局 → 主线程渲染首帧。两端实现细节不同,但线程模型一致。一…...
)
基于信息流的移动智能终端隐私保护关键技术研究(中期检查报告)
一、基本情况论文题目 基于信息流的移动智能终端隐私保护关键技术研究 √ 课题进展情况 本课题按开题报告所预定的内容及进度顺利进行,课题进展情况正常。目前已经在开题文献阅读的基础上,对Android隐私保护与信息流分析技术进行了深入研究,挖掘出了信息流分析技术应用于…...

终极Cubism.js部署指南:从开发到生产环境的完整实践方案
终极Cubism.js部署指南:从开发到生产环境的完整实践方案 【免费下载链接】cubism Cubism.js: A JavaScript library for time series visualization. 项目地址: https://gitcode.com/gh_mirrors/cu/cubism Cubism.js是一款强大的JavaScript时间序列可视化库&…...

373. Java IO API - 文件存储属性
文章目录373. Java IO API - 文件存储属性📏 示例:检查文件存储的空间使用情况⚙️ 解释🔍 确定 MIME 类型📂 示例:获取文件 MIME 类型⚠️ 重要注意事项🛠️ 示例:自定义文件类型探测器&#x…...
)
保姆级教程:用AntV L7快速搭建可交互的3D地图(附四川地图JSON数据下载)
从零构建3D地图可视化:AntV L7实战指南与四川地貌呈现 第一次看到3D地图在城市规划、气象监测或商业分析中的应用时,那种立体数据跃然屏上的震撼感,让我立刻想动手尝试。作为蚂蚁集团推出的地理空间数据可视化引擎,AntV L7确实能让…...

macOS菜单栏终极管理方案:Ice如何重塑你的数字工作空间
macOS菜单栏终极管理方案:Ice如何重塑你的数字工作空间 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice 核心关键词:macOS菜单栏管理,Ice菜单栏工具 长尾关键词&am…...

Nunchaku-flux-1-dev在网络安全中的应用:生成攻击路径与防御示意图
Nunchaku-flux-1-dev在网络安全中的应用:生成攻击路径与防御示意图 最近和几个做安全的朋友聊天,他们都在抱怨同一件事:写安全报告太痛苦了。不是分析过程有多难,而是要把那些复杂的攻击链、零散的安全事件,画成一张能…...
本来我多日前都说,我只想做个杨振宁先生就行了,基础架构有了,无数的珍珠,留给别人去捡,岂不美哉!奈何,世人质疑,那就把之前的拿出来,校对下,发出。)
第八篇:OFIRM 之 统一场论(V1.1)本来我多日前都说,我只想做个杨振宁先生就行了,基础架构有了,无数的珍珠,留给别人去捡,岂不美哉!奈何,世人质疑,那就把之前的拿出来,校对下,发出。
第八篇:OFIRM 之 统一场论(V1.1) Authors: Haiting Allen Chen Affiliations: Chen Xiao’er Creative Workshop, Independent Researcher, Guangzhou, China. Corresponding Author: Name: Haiting Allen Chen Emails: mailto: OFIRMCS…...