使用矢量数据库打造全新的搜索引擎
在技术层面上,矢量数据库采用了一种名为“矢量索引”的技术,这是一种组织和搜索矢量数据的方法,可以快速找到相似矢量。其中关键的一环是“距离函数”的概念,它可以衡量两个矢量的相似程度。
1.矢量数据库简介
矢量数据库是专门设计用来高效处理矢量数据的数据库。什么是矢量数据呢?矢量数据代表多维空间中的数据点,是一种用数学方法来定义现实世界信息的方式。
比如说,您有一组图片,每张图片都可以在高维空间中表示为一个矢量,其中每个维度都与图片的某些特征(如颜色、形状或纹理)相关。通过比较这些矢量,我们可以找到相似的图片。
这种能力非常关键,因为它可用来进行相似性搜索——一种寻找相似物品而不是完全相同复制品的搜索方式。对于推荐系统和机器学习等许多领域来说,这都是一个重大的变革。
2.解析矢量数据库
在技术层面上,矢量数据库采用了一种名为“矢量索引”的技术,这是一种组织和搜索矢量数据的方法,可以快速找到相似矢量。其中关键的一环是“距离函数”的概念,它可以衡量两个矢量的相似程度。
当您寻找与给定矢量相似的矢量时,数据库并不会将给定矢量与数据库中的每个矢量进行比较。相反,它使用矢量索引快速定位到可能相似的一小部分矢量。这个特性使搜索变得更快、更高效。
3.矢量数据库的实际应用
矢量数据库在实际应用中的优势:
- 推荐系统:许多受欢迎的网站和应用都使用矢量数据库向您推荐喜欢的节目和产品。他们将项目(如电影或产品)和用户表示为矢量,然后利用项目矢量和用户矢量之间的相似性来预测用户可能喜欢的项目。
- 图像和视频搜索:矢量数据库非常适合图像类比这种应用,它们使图像或视频搜索系统能够根据视觉相似性而不仅仅是文本标签来查找相似的图像或视频。
- 语义搜索:语义搜索是一种高级的方式,可以理解查询的含义,不仅仅是特定的单词。例如,如果您搜索“可爱猫咪的图片”,语义搜索系统可能还会向您展示可爱的小猫的图片,即使“小猫”这个词不在您的查询中。矢量数据库可以将文档、查询和概念表示为矢量,然后利用矢量相似性来查找相关结果。
4.将文本转换为矢量
当我们谈论将查询和文章转换为矢量时,实际上我们想要的是将人类可读的文本转换为机器可以理解和执行的格式,即矢量。在这种情况下,矢量实质上是个数字列表,捕捉了文本的本质或含义。这个过程通常被称为“文本嵌入”或“词嵌入”。
4.1 应用于我们的情况:
对于我们的应用程序,我们需要将文章和用户查询都转换为矢量。我们来看看如何完成此过程:
- 选择嵌入算法:假设我们使用Word2Vec,这是一种可以接收文本并输出矢量的算法。Word2Vec通过分析单词在文本中出现的上下文,并以这样一种方式分配矢量,使共享相似上下文的单词被分配相似的矢量。
- 预处理文本:在我们将文本输入Word2Vec之前,我们需要对其进行一些清理。这通常涉及将所有文本转换为小写,删除标点符号和特殊字符,有时甚至删除意义不大的的常用词(如 "和"、"的"、"是 "等)(称为“stop words”)。
- 将清理后的文本输入到算法中:文本整理好后,就将其输入到Word2Vec中。输出将是矢量,我们可以将其用于我们的矢量数据库。
4.2 案例:
假设我们有一篇标题为“The Best Chocolate Chip Cookie Recipe”的博客文章。清理后,它可能看起来像“best chocolate chip cookie recipe”。然后,使用Word2Vec,我们将每个单词转换为矢量。为简单起见,假设我们的矢量只有两个维度。 “best”的矢量可能看起来像[0.25,-0.1],“chocolate”可能是[0.75,0.8],“chip”可能是[-0.6,0.5],“cookie”可能是[0.4,-0.2],“recipe”可能是[-0.1,0.65]。
在这种情况下,我们将这些矢量的平均值表示整个文章,然后将其用于我们的矢量数据库。用户查询也会经过相同的过程,它们的矢量将用于搜索矢量数据库。
这是一个简化的解释,实际过程涉及更复杂的数学和更大的矢量,但这提供了如何将查询和文章转换为矢量的基本理解。一旦您了解了基本概念,就有很多库可以为您完成繁重的工作!
在我们的Java Spring Boot应用程序中,可以使用像DL4J(Deeplearning4j)这样的库来帮助我们进行文本到矢量的转换。虽然使用 DL4J 进行文本到矢量的转换需要一些时间和精力去掌握,但一旦掌握,DL4J 就是数据管理工具包中非常强大的一个工具。
现在,我们将这一步添加到我们的Spring Boot应用程序中,使用Deeplearning4j库将文本转换为矢量。以下是如何使用它创建一个Word2Vec模型的示例:
首先,请将DL4J库添加到您的pom.xml中:
<dependency><groupId>org.deeplearning4j</groupId><artifactId>deeplearning4j-core</artifactId><version>1.0.0-beta7</version>
</dependency>以下代码显示了如何构建Word2Vec模型:
import org.deeplearning4j.text.sentenceiterator.BasicLineIterator;
import org.deeplearning4j.text.sentenceiterator.SentenceIterator;
import org.deeplearning4j.text.tokenization.tokenizer.preprocessor.CommonPreprocessor;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.deeplearning4j.text.tokenization.tokenizerfactory.TokenizerFactory;
import org.deeplearning4j.models.word2vec.Word2Vec;public Word2Vec createWord2VecModel(String filePath) {SentenceIterator iter = new BasicLineIterator(filePath);TokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).iterations(1).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();vec.fit();return vec;
}以上是构建Word2Vec模型的示例代码,下面是如何将文本转换为矢量的示例代码:
import org.nd4j.linalg.api.ndarray.INDArray;
public INDArray textToVector(Word2Vec word2VecModel, String text) {TokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());List<String> tokens = t.create(text).getTokens();INDArray vector = word2VecModel.getWordVectorMatrixNormalized(tokens.get(0));for (int i = 1; i < tokens.size(); i++) {vector.addi(word2VecModel.getWordVectorMatrixNormalized(tokens.get(i)));}vector.divi(tokens.size());return vector;
}将INDArray对象转换为双精度列表的代码如下:
public List<Double> toDoubleVector(INDArray vector) {return Arrays.stream(vector.toDoubleVector()).boxed().collect(Collectors.toList());
}5.在Spring Boot应用程序中实现矢量数据库
让我们从理论转向实践,看看如何将矢量数据库集成到Spring Boot应用程序中。在本示例中,我们将使用Vespa,这是一个开源的矢量数据库,它在语义搜索方面表现非常出色,因此备受关注和推崇。
首先,您需要在pom.xml中的Maven依赖项中添加Vespa客户端:
<dependency><groupId>com.yahoo.vespa</groupId><artifactId>vespa-feed-client</artifactId><version>8.91.4</version>
</dependency>然后,您将创建一个与Vespa数据库交互的VespaClient类。
public class VespaClient {private FeedClient feedClient;public VespaClient(String endpoint) {this.feedClient = FeedClientFactory.create(new FeedParams.Builder().build(), endpoint);}public CompletableFuture<Result> indexDocument(String documentId, Map<String, Object> fields) {DocumentId docId = new DocumentId("namespace", "documentType", documentId);Document document = new Document(docId, fields);return feedClient.send(document);}// 其他Vespa客户端方法在此处...
}您还将拥有一个BlogPost类,该类将表示您的数据。
public class BlogPost {private String id;private String title;private String content;// Getters、setters和其他方法在此处...
}要索引文章,我们将把BlogPost转换为Vespa友好格式,该格式是一个Map<String, Object>,其中键是字段名称,值是字段值。您可能会使用一个方法来执行此转换。
public CompletableFuture<Result> indexBlogPost(BlogPost post) {Map<String, Object> fields = new HashMap<>();fields.put("id", post.getId());fields.put("title", post.getTitle());fields.put("content", post.getContent());// 根据需要包含其他字段...return indexDocument(post.getId(), fields);
}使用Vespa,您可以进行最近邻搜索,以查找与给定查询类似的文章。我们假设您有一种方法可以将查询和文章转换为矢量。
public CompletableFuture<SearchResult> searchSimilarBlogPosts(String query) {List<Double> queryVector = convertQueryToVector(query);Query request = new Query.Builder("namespace", "documentType").setYql("select * from sources * where ([{" +"\"targetNumHits\": 10," +"\"algorithm\": \"euclidean\"," +"\"pivot\": " + queryVector.toString() +"}])" +" output distance").build();return feedClient.search(request);
}现在您已经将矢量数据库集成到Spring Boot应用程序中,并准备使用矢量数据库的强大功能来改善搜索功能!
6.总结
矢量数据库已经成为一种处理搜索功能的新方式,提供了独特的优势,特别是在处理“相似性”概念至关重要的数据时。通过了解这项技术的基本原理并学习如何在实际场景中应用它,您可以发掘其潜力,从而彻底改变处理数据的方式。
善用工具
成功的前端工程师很会善用工具,这些年低代码概念开始流行,像国外的 Mendix,国内的 JNPF,这种新型的开发方式,图形化的拖拉拽配置界面,并兼容了自定义的组件、代码扩展,确实在 B 端后台管理类网站建设中很大程度上的提升了效率。
开源地址:JNPF体验中心
代码量少,系统的稳定性和易调整性都会得到一定的保障。基于代码生成器,可一站式开发多端使用 Web、Android、IOS、微信小程序。代码自动生成后可以下载本地,进行二次开发,有效提高整体开发效率。同时,支持多种云环境部署、本地部署给予最大的安全保障,可以快速搭建适合自身应用场景的产品。
相关文章:

使用矢量数据库打造全新的搜索引擎
在技术层面上,矢量数据库采用了一种名为“矢量索引”的技术,这是一种组织和搜索矢量数据的方法,可以快速找到相似矢量。其中关键的一环是“距离函数”的概念,它可以衡量两个矢量的相似程度。 1.矢量数据库简介 矢量数据库是专门…...

算法提高-树状数组
算法提高-树状数组 241. 楼兰图腾(区间求和 单点修改)242. 一个简单的整数问题(差分推公式 实现 维护区间修改单点求和)243. 一个简单的整数问题2(区间修改和区间求和)AcWing 244. 谜一样的牛(…...

Django ORM详解:最全面的数据库处理指南
概要 深度探讨Django ORM的概念、基础使用、进阶操作以及详细解析在实际使用中如何处理数据库操作。这篇文章旨在帮助大家全面掌握Django ORM,理解其如何简化数据库操作,并透过表象理解其内部工作原理。 Django ORM简介 在深入讨论Django的ORMÿ…...

Istio 安全 授权管理AuthorizationPolicy
这个和cka考试里面的网络策略是类似的。它是可以实现更加细颗粒度限制的。 本质其实就是设置谁可以访问,谁不可以访问。默认命名空间是没有AuthorizationPolicy---允许所有的客户端访问。 这里是没有指定应用到谁上面去,有没有指定使用哪些客户端&#…...
04 Ubuntu中的中文输入法的安装
在Ubuntu22.04这种版本相对较高的系统中安装中文输入法,一般推荐使用fctix5,相比于其他的输入法,这款输入法的推荐词要好得多,而且不会像ibus一样莫名其妙地失灵。 首先感谢文章《滑动验证页面》,我是根据这篇文章的教…...
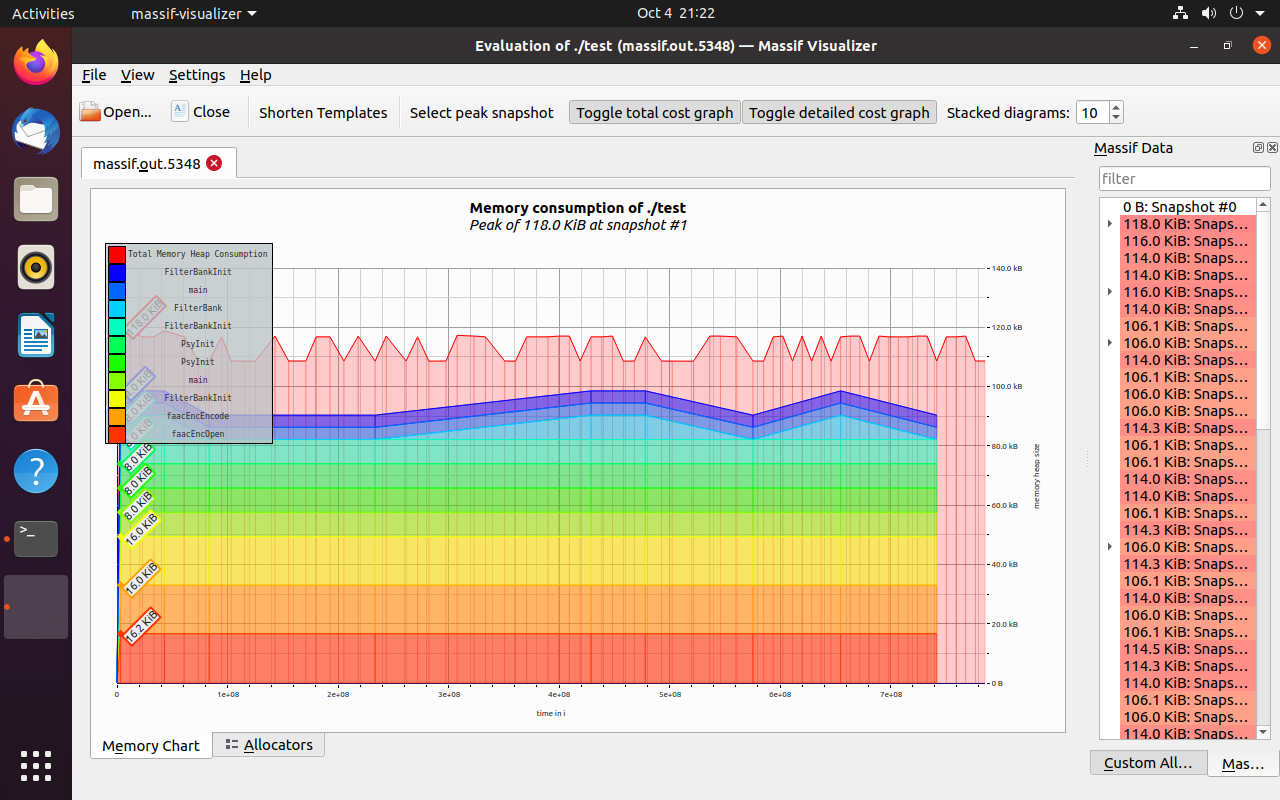
faac内存开销较大,为方便嵌入式设备使用进行优化(valgrind使用)
faac内存开销较大,为方便嵌入式设备使用进行优化,在github上提了issues但是没人理我,所以就搞一份代码自己玩吧。 基于faac_1_30版本,原工程https://github.com/knik0/faac faac内存优化: faac内存开销较大,为方便嵌入…...
)
分数线划定(c++题解)
题目描述 世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A 市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入面试。面试分数线根据计划录取人数的 150% 划定,即如果计划录取 m 名志愿者…...
React 在 html 中 CDN 引入(包含 antd、axios ....)
一、简介 cdn 获取推荐 https://unpkg.com,unpkg 是一个快速的全球内容交付网络,适用于 npm 上所有内容。 【必备】react 相关 cdn。附:github 官方文档获取、现阶段官方文档 CDN 网址。 <script crossorigin src"https://unpkg.com…...

数据结构----异或
数据结构----异或 一.何处用到了异或 1. 运算符 //判断是否相同 用到了异或,看异或结果如果是0就是相同,不是0就是不同//注意: 不能给小数用,小数没有相等的概念,所以小数判断是否相同都是进行相减判断2.找一堆数中…...

PHP Smarty模板的语法规则是怎样的?
首先,你要知道Smarty模板是以模板格式来编写的。模板格式类似于HTML,但它的语法更加简洁明了。 以下是PHP Smarty模板的语法规则和代码例子: 变量:在Smarty模板中,你可以使用变量来显示动态内容。变量通常以“{$”符…...

Socks IP轮换:为什么是数据挖掘和Web爬取的最佳选择?
在数据挖掘和Web爬取的过程中,IP轮换是一个非常重要的概念。数据挖掘和Web爬取需要从多个网站或来源获取数据,而这些网站通常会对来自同一IP地址的请求进行限制或封锁。为了避免这些问题,数据挖掘和Web爬取过程中需要使用Socks IP轮换技术。在…...

优化|当机器学习上运筹学:PyEPO与端对端预测后优化
分享者:唐博 编者按: 这篇文章我想要写已经很久了,毕竟“端对端预测后优化”(End-to-End Predict-then-Optimize)正是我读博期间的主要研究方向,但我又一直迟迟没能下笔。想说自己杂事缠身(实…...
Cocos Creator的 Cannot read property ‘applyForce‘ of undefined报错
序: 1、博主是看了这个教程操作的时候出的bug>游戏开发 | 17节课学会如何用Cocos Creator制作3D跑酷游戏 | P9 代码控制对象移动_哔哩哔哩_bilibili 2、其实问题不是出在代码上,但是发现物体就是不平移 3、node全栈的资料》node全栈框架 正文…...

纯css实现九宫格图片
本篇文章所分享的内容主要涉及到结构伪类选择器,不熟悉的小伙伴可以了解一下,在常用的css选择器中我也有分享相关内容。 话不多说,接下来我们直接上代码: <!DOCTYPE html> <html lang"en"><head>&l…...

【MySQL】数据库的增删查改+备份与恢复
文章目录 一、创建数据库create二、数据库所使用的编码2.1 查询字符集和校验集2.2 指定编码创建数据库2.3 不同的校验集对比 三、删除数据库drop四、查看数据库show五、修改数据库alter六、数据库的备份与恢复6.1 备份 mysqldump6.2 恢复source6.3 仅备份几张表或备份多个数据库…...

Docker 部署 redis 举例
1、搜索镜像,也可以访问 https://hub.docker.com/ 搜索镜像,查看所有版本。 $ docker search redis2、拉取镜像 $ docker pull redis:5.03、启动镜像,并配置相关映射与绑定(附:Docker 常用命令与指令参数)…...

通过HandlerMethodArgumentResolver实现统一添加接口入参参数
背景:项目中有些接口的入参需要用户id信息,最简单的做法在每个Controller方法调用的时候获取登录信息然后给入参设置用户id,但是这样就会有很多重复性的工作。另一个可行的也更好的方案可以使用HandlerMethodArgumentResolver来实现。 部分示…...

JAVA-spring boot 2.4.X报错Unable to find GatewayFilterFactory with name Hystrix
网关升级spring boot项目后,启动网关报错,具体报错信息如下: 2021-12-06 09:06:25.335 ERROR 45102 --- [oundedElastic-3] reactor.core.publisher.Operators : Operator called default onErrorDropped reactor.core.Exceptions$ErrorCallback…...

运输层---UDP协议
目录 一. 无连接运输:UDP1.1 定义1.2 特点1.3 应用 二. UDP报文段结构三. UDP检验和3.1 定义3.2 检验和计算实例3.2 UDP检验和的局限 一. 无连接运输:UDP 1.1 定义 UDP(User Datagram Protocol)用户数据报协议:由 [RF…...
【LeetCode】剑指 Offer Ⅱ 第3章:字符串(7道题) -- Java Version
题库链接:https://leetcode.cn/problem-list/e8X3pBZi/ 题目解决方案剑指 Offer II 014. 字符串中的变位词双指针 数组模拟哈希表 ⭐剑指 Offer II 015. 找到字符串中所有字母异位词双指针 数组模拟哈希表 ⭐剑指 Offer II 016. 不含重复字符的最长子字符串双指针…...
)
PostgreSQL 17安装后必做的5件事:从安全加固到性能调优(附pg_hba.conf配置详解)
PostgreSQL 17安装后必做的5件事:从安全加固到性能调优 刚完成PostgreSQL 17的安装只是数据库旅程的第一步。要让这个强大的关系型数据库真正发挥生产级效能,还需要一系列精细化的配置。本文将带你完成五个关键步骤,从安全策略到性能参数&…...

IndexTTS2 V23实战:用情感语音为你的视频配音,效果超真实
IndexTTS2 V23实战:用情感语音为你的视频配音,效果超真实 1. 引言:让视频配音拥有真实情感 想象一下,当你制作了一个精彩的视频,却苦于找不到合适的配音演员。或者你需要为大量视频内容快速生成配音,但又…...

res-downloader:多源媒体捕获与智能管理的跨平台资源获取工具
res-downloader:多源媒体捕获与智能管理的跨平台资源获取工具 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数…...

构建包容性界面:Vant Weapp无障碍设计全流程解析
构建包容性界面:Vant Weapp无障碍设计全流程解析 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp 一、设计理念:无障碍设计的核心价值 无障碍设计不是可选功能,而…...

利用SoftEther实现跨平台虚拟私有网络部署指南
1. SoftEther简介与核心优势 如果你正在寻找一款能同时在Windows、Linux、Mac、Android和iOS上运行的虚拟私有网络解决方案,SoftEther绝对值得深入了解。这个源自日本筑波大学的开源项目,经过多年发展已经成为支持协议最全面的跨平台工具之一。我第一次…...

用pnpm安装一个软件显示包找不到的问题解决
问题总览 您遇到的是**pnpm环境缺失与目标包mmem0ai无法从npm registry获取**的双重问题,具体表现为两条错误链: sudo pnpm add mmem0ai → sudo: pnpm: command not found(sudo环境下未识别pnpm命令);直接运行pnpm ad…...

5个强力步骤实现旧Mac升级:开源工具OpenCore Legacy Patcher全攻略
5个强力步骤实现旧Mac升级:开源工具OpenCore Legacy Patcher全攻略 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当你的Mac提示"此Mac不支…...

用OpenMV和麦克纳姆轮给智能车做个‘漂移外挂’:从循迹到横滑的代码改造实录
OpenMV与麦克纳姆轮智能车的可控漂移改造实战 当一台普通的循迹小车突然在弯道甩出漂亮的横滑轨迹,围观者的惊叹声往往比技术本身更早到达终点。本文将彻底拆解如何通过运动解算逻辑重构和视觉处理优化,将基础麦轮智能车升级为"赛道艺术家"的…...
)
汽车BCM控制器实战:从零搭建HIL测试环境(附Python自动化脚本)
汽车BCM控制器HIL测试环境搭建实战指南 车身控制模块(BCM)作为现代汽车电子架构中的核心枢纽,其稳定性直接影响着整车的舒适性与安全性。本文将带您从零开始构建一套完整的硬件在环(HIL)测试环境,覆盖从台架…...

python pygame实现贪食蛇
文章目录步骤2、创建snake.py,然后运行即可操作方式解读很简单的一个例子,开启小游戏制作大门。步骤 1、安装依赖 pip install pygame2、创建snake.py,然后运行即可 代码: import pygame import time import random# --- 1. 初…...