优化|当机器学习上运筹学:PyEPO与端对端预测后优化

分享者:唐博
编者按:
这篇文章我想要写已经很久了,毕竟“端对端预测后优化”(End-to-End Predict-then-Optimize)正是我读博期间的主要研究方向,但我又一直迟迟没能下笔。想说自己杂事缠身(实际是重度拖延症晚期的缘故),更主要的原因恐怕是我对这一领域理解依然尚浅,尤其我希望以综述的形式,为读者提供详尽的介绍。然而,这篇文章并不能称为一篇综述,原因有二:一方面,我虽然进行相关的研究,但还无法自称为专家;另一方面,"端对端预测后优化"还处于起步阶段,有很大的探索空间,尚有无穷可能。因此,此时编写综述可能为时尚早。因此,我选择用这篇文章抛砖引玉,旨在引发关于这个领域的进一步探讨和思考。
1. 引言
运筹学和统计学/数据科学/机器学习的紧密关系由来已久。机器学习通过挖掘数据,预测未知或不确定的信息,一旦得到预测结果,常常需要进一步的决策行动来获取收益。而运筹学作为建模求解最优化问题的工具,尽管可以(相对)高效地找到最优解,但一大限制是通常需要参数(无论是本身还是其分布)的确定性,无法充分利用数据。
本文就是要讨论数据驱动下,带有不确定参数的优化问题。这种问题通常通过“预测后优化”的范式来解决。这一问题在现实生产生活中有着深远的意义。举例来说,车辆路径规划中,由于交通状况的不断变化,在每段道路的行驶时间是不确定的;电网调度中,不同地区的电力负荷也会随时间发生变化;投资组合中,金融资产的收益率会受到市场波动的影响。以上这些情况都涉及到优化模型参数的不确定性,但是,我们可以利用时间、天气、金融因素等特征,预测这些不确定的参数,从而进行最优决策。
此外,本文也会介绍一个端对端预测后优化的开源框架PyEPO (https://github.com/khalil-research/PyEPO)。PyEPO基于PyTorch, 主要针对(但不限于)线性规划(LP)和整数线性规划(ILP),集成了文中提到的多种算法,并提供了Gurobi、Pyomo等优化建模工具的API。PyEPO可以作为PyTorch的autograd模块进行深度学习的训练和测试,使用起来简洁明了。这个框架的设计目标是为广大学界和业界用户提供便捷的工具,帮助大家更好地理解和应用端对端预测后优化方法。
2. 问题描述和符号
首先,请各位读者放心,本文并不打算深入挖掘端对端预测后优化背后的数学推导,而是致力于提供一些直观的理解。
我们以一个简单的线性优化问题为例:
max w 1 , w 2 c 1 w 1 + c 2 w 2 s . t . w 1 + w 2 ≤ 1 w 1 , w 2 ≥ 0 \begin{aligned} \underset{w_1,w_2}{\max} \quad & c_1 w_1+c_2 w_2 \\ s.t. \quad & w_1 + w_2 \leq 1 \\ & w_1, w_2 \geq 0 \end{aligned} w1,w2maxs.t.c1w1+c2w2w1+w2≤1w1,w2≥0
在这里, w = ( w 1 , w 2 ) \mathbf{w} = (w_1,w_2) w=(w1,w2)代表的是决策变量, W = { w 1 + w 2 ≤ 1 , w 1 , w 2 ≥ 0 } \mathbf{W} = \lbrace w_1 + w_2 ≤ 1,w_1, w_2 ≥ 0 \rbrace W={w1+w2≤1,w1,w2≥0}定义了可行域,而 c = ( c 1 , c 2 ) \mathbf{c}=(c_1,c_2) c=(c1,c2)就是我们不确定的成本向量。
给定成本向量 c \mathbf{c} c,由于退化问题的存在,优化问题可能得到多个最优解,但可以假定使用某种特定的求解器(如Gurobi)时,只返回唯一一个最优解 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)。
有一组数据 D = { ( x 1 , c 1 ) , ( x 2 , c 2 ) , ⋯ , ( x n , c n ) } \mathbf{D} = \lbrace(\mathbf{x}^1,\mathbf{c}^1), (\mathbf{x}^2,\mathbf{c}^2), ⋯, (\mathbf{x}^n,\mathbf{c}^n)\rbrace D={(x1,c1),(x2,c2),⋯,(xn,cn)},其中 x \mathbf{x} x为数据特征,我们可以利用机器学习模型 g ( x , θ ) \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) g(x,θ)来最小化某个损失函数 l ( g ( x , θ ) , c ) l(\mathbf{g}(\mathbf{x},\boldsymbol{\theta}),\mathbf{c}) l(g(x,θ),c)。其中, θ \boldsymbol{\theta} θ是模型 g ( x , θ ) \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) g(x,θ)的参数,会在训练过程中不断更新,而 c ^ = g ( x , θ ) \hat{\mathbf{c}} = \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) c^=g(x,θ)则是成本向量 c \mathbf{c} c的预测值。由此我们可以利用数据驱动的方式来预测不确定的参数,帮助实现优化决策。
3. 什么是端对端预测后优化?
在回答这个问题之前,我们首先需要理解端对端学习(End-to-End Learning)的理念。端对端的这个“端”,指的是输入端和输出端。相比于传统的分步骤方式,它并不依赖于中间过程的手动特征工程或者人为设计的步骤,而直接构建从输入到输出的映射,以一种更直接和自动的方式解决问题。这种简化不仅减轻了手动特征工程的负担,而且通过学习直接的映射,减少了对中间结果的依赖,有可能发现传统方法难以发现的模式,从而提高整体的性能。端对端学习作为一个整体,使得整个系统变得更简洁,有利于处理复杂和高维度的问题。
[图片]
对于端对端预测后优化,我们在训练机器学习模型 g ( x , θ ) \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) g(x,θ)的过程中,模型预测了成本向量 c ^ = g ( x , θ ) \hat{\mathbf{c}} = \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) c^=g(x,θ),然后通过求解器得到最优解 w ∗ ( c ^ ) = min w ∈ W c ^ ⊤ w \mathbf{w}^* (\hat{\mathbf{c}}) = \underset{\mathbf{w} \in \mathbf{W}}{\min} \hat{\mathbf{c}}^{\top} \mathbf{w} w∗(c^)=w∈Wminc^⊤w,并计算损失函数 l ( c ^ , c ) l(\hat{\mathbf{c}}, \mathbf{c}) l(c^,c)来直接衡量决策损失。
借助链式法则,我们能够计算出模型参数 θ \boldsymbol{\theta} θ相对于损失函数 l ( c ^ , c ) l(\hat{\mathbf{c}}, \mathbf{c}) l(c^,c)的梯度,用于更新模型参数:
∂ l ( c ^ , c ) ∂ θ = ∂ l ( c ^ , c ) ∂ c ^ ∂ c ^ ∂ θ = ∂ l ( c ^ , c ) ∂ w ∗ ( c ^ ) ∂ w ∗ ( c ^ ) ∂ c ^ ∂ c ^ ∂ θ \begin{aligned} \frac{\partial l(\hat{\mathbf{c}}, \mathbf{c})}{\partial \boldsymbol{\theta}} & = \frac{\partial l(\hat{\mathbf{c}}, \mathbf{c})}{\partial \hat{\mathbf{c}}} \frac{\partial \hat{\mathbf{c}}}{\partial \boldsymbol{\theta}} \\ & = \frac{\partial l(\hat{\mathbf{c}}, \mathbf{c})}{\partial \mathbf{w}^* (\hat{\mathbf{c}})} \frac{\partial \mathbf{w}^* (\hat{\mathbf{c}})}{\partial \hat{\mathbf{c}}} \frac{\partial \hat{\mathbf{c}}}{\partial \boldsymbol{\theta}} \end{aligned} ∂θ∂l(c^,c)=∂c^∂l(c^,c)∂θ∂c^=∂w∗(c^)∂l(c^,c)∂c^∂w∗(c^)∂θ∂c^
显然,对于依赖于链式法则进行反向传播的模型(如神经网络),关键部分是计算求解过程的梯度 ∂ w ∗ ( c ^ ) ∂ c ^ \frac{\partial \mathbf{w}^* (\hat{\mathbf{c}})}{\partial \hat{\mathbf{c}}} ∂c^∂w∗(c^)。端对端预测后优化的各类算法几乎都是在此基础上展开的。然而,在此,我们先不深入讨论这些算法,因为我们我们必须先回答一个更为重要,也是更致命的问题:
4. 为什么要使用端对端预测后优化?
4.1 关于两阶段的预测后优化
毫无疑问,采用两阶段的预测后优化,即将机器学习预测模型 g ( x , θ ) \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) g(x,θ)和优化求解器 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)独立使用,看似是一个更为自然、直接的做法。此方法的预测任务中,我们最小化成本向量预测值 c ^ = g ( x , θ ) \hat{\mathbf{c}} = \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) c^=g(x,θ)和真实值 c \mathbf{c} c之间的预测误差,如均方误差 l MSE ( c ^ , c ) = ∥ c ^ − c ∥ 2 l_{\text{MSE}} (\hat{\mathbf{c}},\mathbf{c}) = {\lVert \hat{\mathbf{c}}-\mathbf{c} \rVert}^2 lMSE(c^,c)=∥c^−c∥2。熟悉机器学习的读者可能会发现,这实际上是一项非常经典的回归任务,对应的模型和算法已经相当成熟。而在决策任务中,一旦给定预测参数 c ^ \hat{\mathbf{c}} c^,现代求解器可以将问题视作确定性优化直接求解。既然预测任务和决策任务都有成熟的方案,那么为什么我们还要尝试将它们结合在一起?
文献中的解释——“与直接考虑决策误差相比,基于预测误差训练预测模型会导致更糟糕的决策。”用人话来说就是:像 l MSE ( c ^ , c ) l_{\text{MSE}} (\hat{\mathbf{c}},\mathbf{c}) lMSE(c^,c)这样的预测误差,不能准确地衡量决策的质量。
在日常生活中,人们只关心决策的好坏,而不是各项指标预测的准确度。正如我们驱车赶往目的地时,只关心自己是否选中捷径,而无须精确预测每段可能经过的路段所耗费的时间。
让我们回到前文提到的线性优化问题:假设实际成本向量为 c = ( 0 , 1 ) \mathbf{c}=(0,1) c=(0,1),最优解为 w ∗ ( c ) = ( 0 , 1 ) \mathbf{w}^* (\mathbf{c}) = (0,1) w∗(c)=(0,1)。当我们将成本向量预测为 c ^ = ( 1 , 0 ) \hat{\mathbf{c}} = (1,0) c^=(1,0),其最优解为 w ∗ ( c ^ ) = ( 1 , 0 ) \mathbf{w}^* (\hat{\mathbf{c}}) = (1,0) w∗(c^)=(1,0),预测的均方误差 l MSE ( c ^ , c ) = 2 l_{\text{MSE}} (\hat{\mathbf{c}},\mathbf{c}) = 2 lMSE(c^,c)=2;当我们将成本向量预测为 c ^ = ( 0 , 3 ) \hat{\mathbf{c}} = (0,3) c^=(0,3),其最优解为 w ∗ ( c ^ ) = ( 0 , 1 ) \mathbf{w}^* (\hat{\mathbf{c}}) = (0,1) w∗(c^)=(0,1),预测的均方误差 l MSE ( c ^ , c ) = 4 l_{\text{MSE}} (\hat{\mathbf{c}},\mathbf{c}) = 4 lMSE(c^,c)=4。
这个例子揭示了一个有趣的现象:后者虽然在预测误差上比前者大,但在决策上却是最优的。
因此,即使预测模型表现出了较大的误差,但只要预测的成本向量能引导我们做出正确的决策,这个预测模型就是有效的。这就是为什么我们需要考虑端对端预测后优化,我们希望训练出的模型能够引导我们做出最优的决策,而不必预测出精确的成本向量。
那么,如果预测模型的预测结果足够精确,那是不是可以摒弃使用端对端方法了呢?答案是肯定的。然而,不要忘记统计学家George E.P. Box有句名言: “All models are wrong, but some are useful.”
4.2 关于模仿学习
既然端对端方法展现了足够的优势,那我们为什么不妨更激进一点,采用模仿学习(Imitation Learning),把(最优)决策行为 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)作为标签,省去了中间的求解过程,直接训练模型 w ^ ∗ = g ( x , θ ) \hat{\mathbf{w}}^* = \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) w^∗=g(x,θ)预测最优解呢?
毫无疑问,模仿学习在计算效率上具有显著优势,因为它规避了计算效率的主要瓶颈:优化求解。
然而,其局限性也很明显。尽管研究人员已经做出了许多尝试,比如Kervadec等人的“Constrained deep networks: Lagrangian optimization via log-barrier extensions” [8],但目前的预测模型,无论是线性回归、决策树、还是神经网络,在处理带有硬约束(Hard Constraints)的问题上仍存在难度。因此,模仿学习的预测结果常常面临可行性问题,特别是对于高维度、有复杂约束的优化问题。
5. 如何进行端对端预测后优化?
开篇名义,这个章节将会讨论端对端预测后优化的若干方法,这些方法适用的优化问题有所差异,但主要集中在成本向量 c \mathbf{c} c未知、有线性目标函数的问题上。需要明确的是,这里强调的是目标函数的线性,并不意味着约束条件也必须是线性的。例如,在SPO+的相关论文中 [1],作者们探讨了具有二次约束的投资组合均值-方差模型。此外,对比、排序方法和损失函数近似法甚至对优化问题的形式几乎没有特定要求。
尽管也存在基于决策树的模型SPO Tree [9],大部分方法还是依赖梯度下降更新参数。之前提到,端对端学习的关键是计算求解过程的梯度 ∂ w ∗ ( c ^ ) ∂ c ^ \frac{\partial \mathbf{w}^* (\hat{\mathbf{c}})}{\partial \hat{\mathbf{c}}} ∂c^∂w∗(c^)。然而,传统的优化求解器和算法往往并未提供梯度信息。
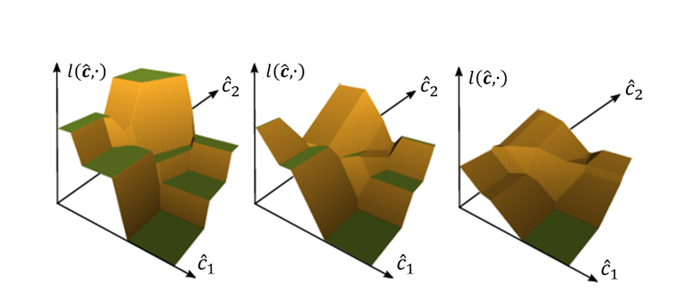
更坏的消息是:线性规划、整数线性规划等具有线性目标函数的问题,其最优解 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)作为成本向量 c \mathbf{c} c的函数,是一个分片常数函数(Piecewise Constant Function),它的一阶导数要么为0,要么不存在。熟悉线性规划敏感性分析的话,就会知道成本向量系数 c \mathbf{c} c的元素发生变化时,最优解 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)要么不发生改变,要么会从可行域的一个极点跳到另一个极点。我们依然以线性规划 max w 1 , w 2 { c 1 w 1 + c 2 w 2 : w 1 + w 2 ≤ 1 , w 1 , w 2 ≥ 0 } \underset{w_1,w_2}{\max} \lbrace c_1 w_1 + c_2 w_2: w_1 + w_2 ≤ 1,w_1, w_2 ≥ 0 \rbrace w1,w2max{c1w1+c2w2:w1+w2≤1,w1,w2≥0}为例,如图:

既然梯度几乎处处为0,梯度下降法似乎无法实施。然而,科研的魅力正是将不可能变为可能。面对这一挑战,研究者们提出了多种解决策略:一类是寻找替代的梯度信息,用以更新模型参数;另一类索性重新设计一个(有非0梯度的)替代损失函数。这两类思路基本囊括了基于梯度的端对端预测后优化算法:
5.1 基于KKT条件的隐函数求导
Amos和Kolter提出“OptNet” [10],通过求解KKT条件的偏微分矩阵线性方程组来计算求解器反向传播的梯度。为了克服线性规划中无法得到非0梯度的问题,Wilder等人 [11] 在线性目标函数中加入了一个微小的二次项。基于这类方法,后续的研究者展开了多方面的探索。例如,引入割平面法(Cutting-Plane Method)以处理整数问题 [12],或使用障碍函数来替代拉格朗日罚函数 [13]。
值得一提的是,这类方法不仅能计算出目标函数成本向量的梯度,而且能够得到约束条件中参数的梯度信息。
5.2 SPO+
不同于KKT方法,Elmachtoub和Grigas [1] 为目标函数是线性( c ⊤ w \mathbf{c}^{\top} \mathbf{w} c⊤w)的决策误差找到了一个凸且可导的替代损失函数SPO+ Loss。
在这里,对于一个最小化问题 min w ∈ W c ⊤ w \underset{\mathbf{w} \in \mathbf{W}}{\min} \mathbf{c}^{\top} \mathbf{w} w∈Wminc⊤w,我们先定义一个决策损失“遗憾”: l Regret ( c ^ , c ) = c ⊤ w ∗ ( c ^ ) − c ⊤ w ∗ ( c ) l_{\text{Regret}} (\hat{\mathbf{c}}, \mathbf{c}) = \mathbf{c}^{{\top}} \mathbf{w}^* (\hat{\mathbf{c}}) - \mathbf{c}^{{\top}} \mathbf{w}^* (\mathbf{c}) lRegret(c^,c)=c⊤w∗(c^)−c⊤w∗(c),衡量实际成本向量 c \mathbf{c} c下,实际目标值 c ⊤ w ∗ ( c ^ ) \mathbf{c}^{{\top}} \mathbf{w}^* (\hat{\mathbf{c}}) c⊤w∗(c^)与最优目标值 c ⊤ w ∗ ( c ) \mathbf{c}^{{\top}} \mathbf{w}^* (\mathbf{c}) c⊤w∗(c)之间的差距,也可以理解为优化间隙(optimality gap)。
由于 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)没有非0导数,这个损失函数同样也没有非0导数。Elmachtoub和Grigas [1] 找到了这个函数的一个凸上界作为替代::
l SPO+ ( c ^ , c ) = − min w ∈ W { ( 2 c ^ − c ) ⊤ w } + 2 c ^ ⊤ w ∗ ( c ) − c ⊤ w ∗ ( c ) l_{\text{SPO+}} (\hat{\mathbf{c}}, \mathbf{c}) = - \underset{\mathbf{w} \in \mathbf{W}}{\min} \{(2 \hat{\mathbf{c}} - \mathbf{c})^{\top} \mathbf{w}\} + 2 \hat{\mathbf{c}}^{\top} \mathbf{w}^* (\mathbf{c}) - \mathbf{c}^{{\top}} \mathbf{w}^* (\mathbf{c}) lSPO+(c^,c)=−w∈Wmin{(2c^−c)⊤w}+2c^⊤w∗(c)−c⊤w∗(c)
对于损失函数 l SPO+ ( c ^ , c ) l_{\text{SPO+}} (\hat{\mathbf{c}}, \mathbf{c}) lSPO+(c^,c),有次梯度:
2 w ∗ ( c ) − 2 w ∗ ( 2 c ^ − c ) ∈ ∂ l SPO+ ( c ^ , c ) ∂ c ^ 2 \mathbf{w}^* (\mathbf{c}) - 2 \mathbf{w}^* (2 \hat{\mathbf{c}} - \mathbf{c}) \in \frac{\partial l_{\text{SPO+}}(\hat{\mathbf{c}}, \mathbf{c})}{\partial \hat{\mathbf{c}}} 2w∗(c)−2w∗(2c^−c)∈∂c^∂lSPO+(c^,c)
5.3 扰动方法
同样是线性目标函数,扰动方法则是另辟蹊径,引入随机扰动来处理成本向量的预测值 c ^ \hat{\mathbf{c}} c^。
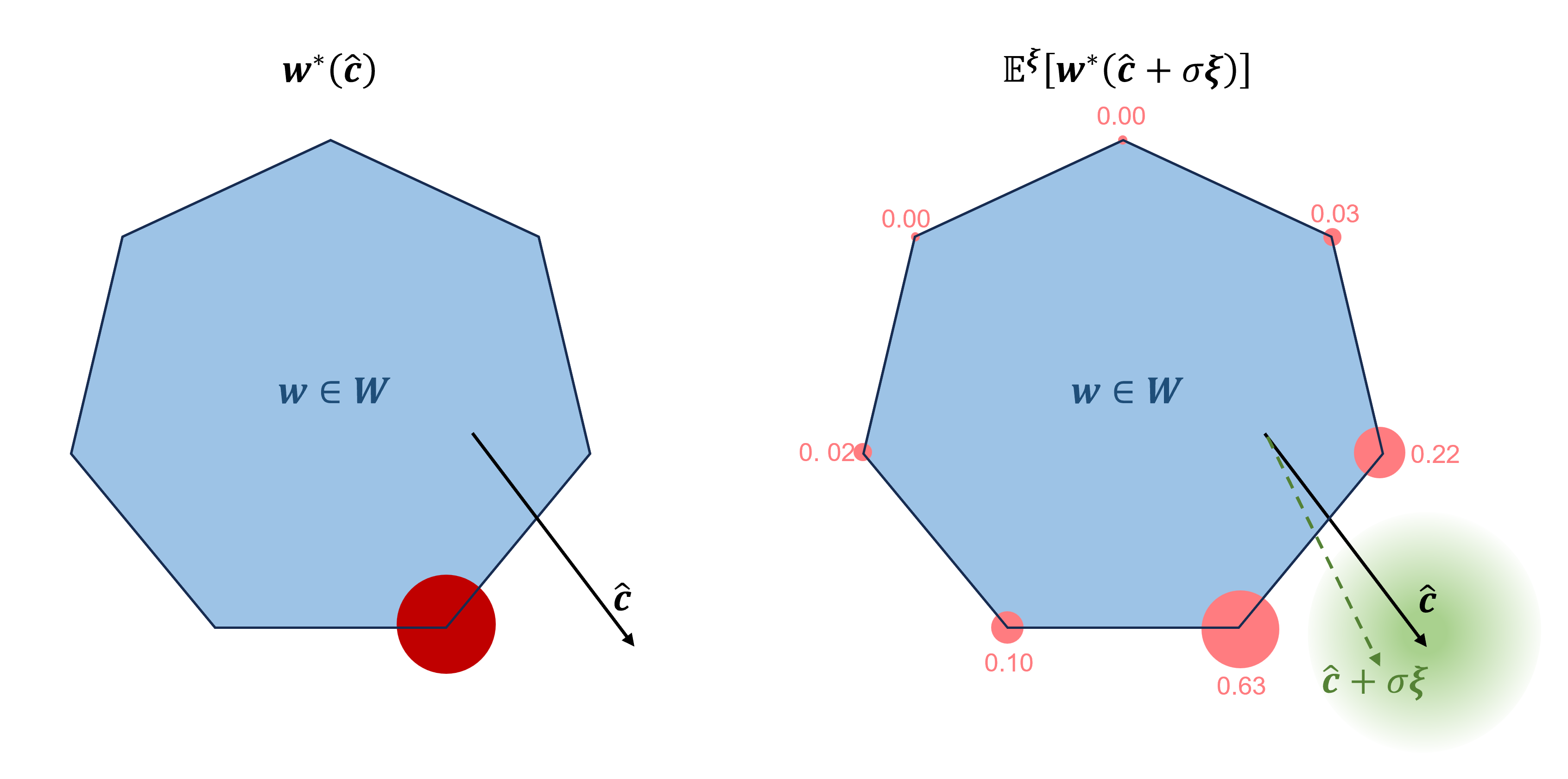
Berthet等人 [4] 用在高斯随机扰动 ξ \boldsymbol{\xi} ξ下最优决策的期望值 E ξ [ w ∗ ( c ^ + σ ξ ) ] \mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})] Eξ[w∗(c^+σξ)]代替 w ∗ ( c ^ ) \mathbf{w}^* (\hat{\mathbf{c}}) w∗(c^)。如图所示, w ∗ ( c ^ + σ ξ ) \mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi}) w∗(c^+σξ)是可行域极点(基本可行解)的离散型随机向量,决策的期望值 E ξ [ w ∗ ( c ^ + σ ξ ) ] \mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})] Eξ[w∗(c^+σξ)]实际上可视为可行域极点的概率加权平均(凸组合)。与 w ∗ ( c ^ ) \mathbf{w}^* (\hat{\mathbf{c}}) w∗(c^)不同,只要 c ^ \hat{\mathbf{c}} c^在 E ξ [ w ∗ ( c ^ + σ ξ ) ] \mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})] Eξ[w∗(c^+σξ)]中发生一些微小的变化,可行域极点权重(其发生的概率)就会相应变化。本质上,扰动方法通过为离散的解向量引入概率分布实现平滑,这种方法与机器学习中SoftMax的思想有着异曲同工之处。
接下来,我们“只”需要通过概率密度函数 f ( ξ ) f(\boldsymbol{\xi}) f(ξ)的积分求期望 E ξ [ w ∗ ( c ^ + σ ξ ) ] = ∫ w ∗ ( c ^ + σ ξ ) f ( ξ ) d ξ \mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})] = \int \mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi}) f(\boldsymbol{\xi}) d \boldsymbol{\xi} Eξ[w∗(c^+σξ)]=∫w∗(c^+σξ)f(ξ)dξ,然后发现好像做不到。在实际操作中,我们用样本量为 K K K的蒙特卡洛采样来近似期望:
E ξ [ w ∗ ( c ^ + σ ξ ) ] ≈ 1 K ∑ κ K w ∗ ( c ^ + σ ξ κ ) \mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})] \approx \frac{1}{K} \sum_{\kappa}^K {\mathbf{w}^*(\hat{\mathbf{c}} + \sigma \boldsymbol{\xi}_{\kappa})} Eξ[w∗(c^+σξ)]≈K1κ∑Kw∗(c^+σξκ)
由于 ∂ E ξ [ w ∗ ( c ^ + σ ξ ) ] ∂ c ^ \frac{\partial\mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})]}{\partial \hat{\mathbf{c}}} ∂c^∂Eξ[w∗(c^+σξ)]存在且非0,梯度问题由此引刃而解。
除了加法扰动,Dalle等人 [14] 进一步提出了乘法扰动,同样引入高斯随机扰动 ξ \boldsymbol{\xi} ξ,但让预测成本向量 c ^ \hat{\mathbf{c}} c^与 e σ ξ − 1 / 2 σ 2 e^{\sigma \boldsymbol{\xi} - 1/2 {\sigma}^2} eσξ−1/2σ2对应位元素相乘。乘法扰动消除了加法扰动可能引起的正负号变化问题。在一些特定的应用中,例如Dijkstra算法等,对成本向量有非负性的要求,乘法扰动就非常有用。
基于扰动方法,Berthet等人 [4] 利用了Fenchel-Young对偶的性质,进一步构造了一个新的损失函数,用来降低 F ξ ( c ^ ) = E ξ [ min w ∈ W { ( c ^ + σ ξ ) ⊤ w } ] F^{\boldsymbol{\xi}}(\hat{\mathbf{c}}) = \mathbb{E}^{\boldsymbol{\xi}}[\underset{\mathbf{w} \in \mathbf{W}}{\min} {\{(\hat{\mathbf{c}}+\sigma \boldsymbol{\xi})^{\top} \mathbf{w}\}}] Fξ(c^)=Eξ[w∈Wmin{(c^+σξ)⊤w}]的对偶间隙。令 Ω ( w ∗ ( c ) ) \Omega (\mathbf{w}^* ({\mathbf{c}})) Ω(w∗(c))为 F ξ ( c ) F^{\boldsymbol{\xi}}(\mathbf{c}) Fξ(c)的对偶,则有:
l PFY ( c ^ , w ∗ ( c ) ) = c ^ ⊤ w ∗ ( c ) − F ξ ( c ^ ) − Ω ( w ∗ ( c ) ) l_{\text{PFY}}(\hat{\mathbf{c}}, \mathbf{w}^* ({\mathbf{c}})) = \hat{\mathbf{c}}^{\top} \mathbf{w}^* ({\mathbf{c}}) - F^{\boldsymbol{\xi}}(\hat{\mathbf{c}}) - \Omega (\mathbf{w}^* ({\mathbf{c}})) lPFY(c^,w∗(c))=c^⊤w∗(c)−Fξ(c^)−Ω(w∗(c))
这个损失函数可能看起来有些复杂,它甚至包含一个神秘的对偶函数 Ω ( w ∗ ( c ) ) \Omega (\mathbf{w}^* ({\mathbf{c}})) Ω(w∗(c))。但是,当我们对其进行求导操作时,会发现 Ω ( w ∗ ( c ) ) \Omega (\mathbf{w}^* ({\mathbf{c}})) Ω(w∗(c))实际上是常数,因此,梯度表达式非常简单:
∂ l PFY ( c ^ , w ∗ ( c ) ) ∂ c ^ = w ∗ ( c ) − E ξ [ w ∗ ( c ^ + σ ξ ) ] \frac{\partial l_{\text{PFY}}(\hat{\mathbf{c}}, \mathbf{w}^* ({\mathbf{c}}))}{\partial \hat{\mathbf{c}}} = \mathbf{w}^* ({\mathbf{c}}) - \mathbb{E}^{\boldsymbol{\xi}} [\mathbf{w}^* (\hat{\mathbf{c}} + \sigma \boldsymbol{\xi})] ∂c^∂lPFY(c^,w∗(c))=w∗(c)−Eξ[w∗(c^+σξ)]
5.4 黑箱方法
面对 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)的不可导问题,有一个更加简单粗暴的方法,即将求解器函数视为一个“黑箱”,并利用解空间的几何形状等性质找到替代梯度。
如图所示,Pogancic等人 [3] 提出了“Differentiable Black-box”方法引入一个插值超参数 λ \lambda λ。对于一个成本向量预测值 c ^ \hat{\mathbf{c}} c^,在 c ^ \hat{\mathbf{c}} c^与 c ^ + λ ∂ l ( c ^ , c ) ∂ w ∗ ( c ^ ) \hat{\mathbf{c}} + \lambda \frac{\partial l (\hat{\mathbf{c}}, \mathbf{c})}{\partial \mathbf{w}^* (\hat{{\mathbf{c}}})} c^+λ∂w∗(c^)∂l(c^,c)之间对分片常数损失函数 l ( c ^ , c ) l (\hat{\mathbf{c}}, \mathbf{c}) l(c^,c)进行线性插值,从而将其转化为分片线性函数(Piecewise Affine Function),以此可得非0梯度。
此外,Sahoo等人 [7] 提出了一种相当简洁的方案,即用负单位矩阵 − I - \mathbf{I} −I替代求解器梯度 ∂ w ∗ ( c ^ ) ∂ c ^ \frac{\partial \mathbf{w}^* (\hat{\mathbf{c}})}{\partial \hat{\mathbf{c}}} ∂c^∂w∗(c^)。我们可以将其称为“Negative Identity”方法。从直观角度理解,对于一个最小化问题 min w ∈ W c ⊤ w \underset{\mathbf{w} \in \mathbf{W}}{\min} \mathbf{c}^{\top} \mathbf{w} w∈Wminc⊤w,我们希望通过如下方式更新成本向量的预测值 c ^ \hat{\mathbf{c}} c^:沿着 w ∗ ( c ^ ) \mathbf{w}^* (\hat{\mathbf{c}}) w∗(c^)需要上升的方向减少,沿着 w ∗ ( c ^ ) \mathbf{w}^* (\hat{\mathbf{c}}) w∗(c^)需要下降的方向增加,这会使 w ∗ ( c ^ ) \mathbf{w}^* (\hat{\mathbf{c}}) w∗(c^)接近最优决策 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)。另外,该研究也证明了,这个方法可以看作是“Differentiable Black-box”方法在特定超参数λ下的特例。
5.5 对比、排序方法:
Mulamba [5] 则是曲线救国,采用了 “噪声对比估计(Noise Contrastive Estimation)” 的技巧,巧妙地计算出替代损失函数。
首先,由于我们的可行域 w ∈ W \mathbf{w} \in \mathbf{W} w∈W是固定不变的,因此在训练集以及训练、求解过程中,我们可以自然地收集到大量的可行解,形成一个解集合 Γ \Gamma Γ。
该方法的关键思路是,将非最优可行解的子集 Γ ∖ w ∗ ( c ) \Gamma \setminus \mathbf{w}^* (c) Γ∖w∗(c)作为负样本,让最优解和“负样本”之间的的差值尽可能大。对于一个最小化问题 min w ∈ W c ⊤ w \underset{\mathbf{w} \in \mathbf{W}}{\min} \mathbf{c}^{\top} \mathbf{w} w∈Wminc⊤w,有:
l NCE ( c ^ , c ) = 1 ∣ Γ ∣ − 1 ∑ w ∈ Γ ∖ w ∗ ( c ) ( c ^ ⊤ w ∗ ( c ) − c ^ ⊤ w ) l_{\text{NCE}} (\hat{\mathbf{c}},\mathbf{c}) = \frac{1}{|\Gamma|-1} \sum_{\mathbf{w} \in {\Gamma \setminus {\mathbf{w}^* (\mathbf{c})}}}(\hat{\mathbf{c}}^{\top} \mathbf{w}^* (\mathbf{c})-\hat{\mathbf{c}}^{\top} \mathbf{w}) lNCE(c^,c)=∣Γ∣−11w∈Γ∖w∗(c)∑(c^⊤w∗(c)−c^⊤w)
受到这项工作构造损失函数区分最优解的启发,Mandi等人 [6] 提出了一种新思路,将端对端预测后优化任务转化为一个排序学习(Learning to rank) [15],学习一个目标函数(如 c ^ ⊤ w \hat{\mathbf{c}}^{\top} \mathbf{w} c^⊤w)作为排序得分,以便对可行解的子集 Γ \Gamma Γ进行正确排序(和使用真实成本向量 c \mathbf{c} c时一致)。和之前的方法相比,这种方法的优势在于,它对使用的优化方法和目标函数的形式不加以限制。
例如,对于一个线性规划问题, c ⊤ w \mathbf{c}^{\top} \mathbf{w} c⊤w可以被视为排序得分。对于预测的成本向量 c ^ \hat{\mathbf{c}} c^,为了排序得分 c ^ ⊤ w \hat{\mathbf{c}}^{\top} \mathbf{w} c^⊤w能在解集 w ∈ Γ \mathbf{w} \in \Gamma w∈Γ中有正确的排序,我们可以采用以下三种经典的排序学习方法:单文档方法(Pointwise Approach)、文档对方法(Pairwise Approach)、以及文档列表方法(Listwise Approach)。
在单文档方法中,我们希望成本向量的预测值 c ^ \hat{\mathbf{c}} c^在可行解的子集 Γ \Gamma Γ中的得分 c ^ ⊤ w \hat{\mathbf{c}}^{\top} \mathbf{w} c^⊤w尽可能接近 c ⊤ w \mathbf{c}^{\top} \mathbf{w} c⊤w;在文档对方法中,我们可以在最优解和其他解之间创造排序得分的差值;而在文档列表方法中,我们根据排序得分使用SoftMax函数计算每个可能解 w ∈ Γ \mathbf{w} \in \Gamma w∈Γ被排在最前面的概率 P ( w ∣ c ) P(\mathbf{w} | \mathbf{c}) P(w∣c),然后定义损失为概率的交叉熵 l LTR ( c ^ , c ) = 1 ∣ Γ ∣ ∑ w ∈ Γ P ( w ∣ c ) log P ( w ∣ c ^ ) l_{\text{LTR}} (\hat{\mathbf{c}},\mathbf{c}) = \frac{1}{|\Gamma|} \sum_{\mathbf{w} \in \Gamma} P(\mathbf{w} | \mathbf{c}) \log P(\mathbf{w} | \hat{\mathbf{c}}) lLTR(c^,c)=∣Γ∣1∑w∈ΓP(w∣c)logP(w∣c^)。
5.6 损失函数近似法:
最后,我们来聊一个堪称邪道的方法——损失函数近似法。当我们的预测模型 g ( x , θ ) \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) g(x,θ)预测出成本向量 c ^ \hat{\mathbf{c}} c^后,我们需要寻找最优解 w ∗ ( c ^ ) \mathbf{w}^* (\hat{\mathbf{c}}) w∗(c^),然后计算相应的决策损失 l ( c ^ , c ) l(\hat{\mathbf{c}}, \mathbf{c}) l(c^,c)。然而,这个过程面临着两个主要的问题:一是优化求解过程计算效率低下,二是损失函数 l ( c ^ , c ) l(\hat{\mathbf{c}}, \mathbf{c}) l(c^,c)可能不存在有效的梯度。
针对这些问题,Shah等人 [17] 提出了一个颇为惊人的方案:局部优化决策损失(Locally Optimized Decision Loss)。他们提出对于任意决策误差的损失函数 l ( c ^ , c ) l(\hat{\mathbf{c}}, \mathbf{c}) l(c^,c),我们都可以使用一个额外的神经网络模型 h LODL ( c ^ , c ) h_{\text{LODL}} (\hat{\mathbf{c}}, \mathbf{c}) hLODL(c^,c)进行拟合。具体来说,他们通过采样预测成本向量和其对应的真实值 ( c ^ , c ) (\hat{\mathbf{c}}, \mathbf{c}) (c^,c),训练近似函数模型 h LODL ( c ^ , c ) h_{\text{LODL}} (\hat{\mathbf{c}}, \mathbf{c}) hLODL(c^,c),其损失定义为真实损失函数 l ( c ^ , c ) l(\hat{\mathbf{c}}, \mathbf{c}) l(c^,c)和近似损失函数 h LODL ( c ^ , c ) h_{\text{LODL}} (\hat{\mathbf{c}}, \mathbf{c}) hLODL(c^,c)的均方误差(MSE):
∥ l ( c ^ , c ) − h LODL ( c ^ , c ) ∥ 2 { \lVert l(\hat{\mathbf{c}}, \mathbf{c}) - h_{\text{LODL}} (\hat{\mathbf{c}}, \mathbf{c}) \rVert}^2 ∥l(c^,c)−hLODL(c^,c)∥2
接下来,我们固定好模型 h LODL ( c ^ , c ) h_{\text{LODL}} (\hat{\mathbf{c}}, \mathbf{c}) hLODL(c^,c)的参数,作为决策损失的近似。在这个近似的指导下,我们通过对 h LODL ( g ( x , θ ) , c ) h_{\text{LODL}} (\mathbf{g}(\mathbf{x},\boldsymbol{\theta}), \mathbf{c}) hLODL(g(x,θ),c)执行梯度下降操作来更新预测模型 g ( x , θ ) \mathbf{g}(\mathbf{x},\boldsymbol{\theta}) g(x,θ)的参数 θ \boldsymbol{\theta} θ。这个流程既避免了求解优化问题的计算成本,又确保了损失函数能够有效地计算梯度。

虽然这种方法看似天方夜谭,实则根植于深度学习的一项核心理论——“万能近似定理(Universal Approximation Theorem)”,即神经网络理论上具备拟合任何函数的能力。事实上,值函数的近似是强化学习中的一种常见策略。因此,用类似的方法拟合端到端预测后优化的决策误差中也是行得通的。
这种策略优雅地规避了求解优化问题的计算效率瓶颈(尽管在训练近似函数 h LODL ( c ^ , c ) h_{\text{LODL}} (\hat{\mathbf{c}}, \mathbf{c}) hLODL(c^,c)的时候,优化求解仍然难以避免),同时充分利用了神经网络在拟合复杂损失函数方面的强大能力。然而,这也带来了额外的模型训练步骤,并且近似损失函数的准确性将直接影响到最终模型的表现。尽管理论上神经网络具备表示任何函数的能力,但在实践中,要训练神经网络有效地学习并近似特定函数可能并非易事。这涉及到一个复杂损失函数的优化问题,可能存在大量的局部最优解,而且可能受到过拟合、梯度消失、梯度爆炸等问题的影响。此外,这种方法在基准数据集上的性能尚缺乏详尽的比较,其实际效用仍待进一步探索和证明。
6. 使用PyEPO进行端对端预测后优化
PyEPO(PyTorch-based End-to-End Predict-then-Optimize Tool) [16] 是我读博期间的开发的工具,该工具的源代码已经发布在GitHub上,可以通过以下链接查找:https://github.com/khalil-research/PyEPO。它是一款基于Python的开源软件,支持预测后优化问题的建模和求解。PyEPO的核心功能是使用GurobiPy、Pyomo或其他求解器和算法建立优化模型,然后将优化模型嵌入到人工神经网络中进行端到端训练。具体来说,PyEPO借助PyTorch autograd模块,实现了如SPO+、黑箱方法、扰动方法以及对比排序方法等多种策略的框架。具体使用方法可以查看文档。

作为一款开源工具,PyEPO也欢迎社区的贡献和反馈,我们也将持续更新和优化其中的算法。
6.1 下载和安装
要下载PyEPO,你可以从GitHub仓库克隆:
git clone -b main --depth 1 https://github.com/khalil-research/PyEPO.git
之后进行安装:
pip install PyEPO/pkg/.
6.2 建立优化模型
使用PyEPO的第一步是创建一个继承于optModel类的优化模型。由于PyEPO处理未知成本系数的预测后优化,因此首先需要实例化一个具有固定约束和可变成本的优化模型optModel。这样一个优化模型可以接受不同的成本向量,并能够在固定的约束条件下找到相应的最优解。
在PyEPO中,optModel类的作用类似于一个黑箱对求解器进行封装,这意味着PyEPO并不一定要使用某种特定的算法或求解器。
对如下问题:
max x ∑ i = 0 4 c i x i s . t . 3 x 0 + 4 x 1 + 3 x 2 + 6 x 3 + 4 x 4 ≤ 12 4 x 0 + 5 x 1 + 2 x 2 + 3 x 3 + 5 x 4 ≤ 10 5 x 0 + 4 x 1 + 6 x 2 + 2 x 3 + 3 x 4 ≤ 15 ∀ x i ∈ { 0 , 1 } \begin{aligned} \underset{\mathbf{x}}{\max} & \sum_{i=0}^4 c_i x_i \\ s.t. \quad & 3 x_0 + 4 x_1 + 3 x_2 + 6 x_3 + 4 x_4 \leq 12 \\ & 4 x_0 + 5 x_1 + 2 x_2 + 3 x_3 + 5 x_4 \leq 10 \\ & 5 x_0 + 4 x_1 + 6 x_2 + 2 x_3 + 3 x_4 \leq 15 \\ & \forall x_i \in \{0, 1\} \end{aligned} xmaxs.t.i=0∑4cixi3x0+4x1+3x2+6x3+4x4≤124x0+5x1+2x2+3x3+5x4≤105x0+4x1+6x2+2x3+3x4≤15∀xi∈{0,1}
PyEPO也提供了Gurobi的API,用户能轻松地对各种优化问题进行建模,无需手动编写复杂的求解过程:
import gurobipy as gp
from gurobipy import GRB
from pyepo.model.grb import optGrbModelclass myOptModel(optGrbModel):def _getModel(self):# ceate a modelm = gp.Model()# variblesx = m.addVars(5, name="x", vtype=GRB.BINARY)# sensem.modelSense = GRB.MAXIMIZE# constraintsm.addConstr(3*x[0]+4*x[1]+3*x[2]+6*x[3]+4*x[4]<=12)m.addConstr(4*x[0]+5*x[1]+2*x[2]+3*x[3]+5*x[4]<=10)m.addConstr(5*x[0]+4*x[1]+6*x[2]+2*x[3]+3*x[4]<=15)return m, xoptmodel = myOptModel()
6.3 生成数据集
我们用随机特征生成有高斯噪音的成本向量:
import torch
torch.manual_seed(42)num_data = 1000 # number of data
num_feat = 5 # feature dimension
num_cost = 5 # cost dimension# randomly generate data
x_true = torch.rand(num_data, num_feat) # feature
weight_true = torch.rand(num_feat, num_cost) # weight
bias_true = torch.randn(num_cost) # bias
noise = 0.5 * torch.randn(num_data, num_cost) # random noise
c_true = x_true @ weight_true + bias_true + noise # cost coef
对于端到端预测后优化,只有成本向量 c \mathbf{c} c作为标签是不够的,我们还需要最优解 w ∗ ( c ) \mathbf{w}^* (\mathbf{c}) w∗(c)和相应的目标函数值。因此,我们可以使用optDataset。optDataset是在PyTorch的Dataset类的基础上进行扩展的一个类,它允许我们利用optModel方便地获取求解数据,并且可以被PyTorch的DataLoader直接使用。
# split train test data
from sklearn.model_selection import train_test_split
x_train, x_test, c_train, c_test = train_test_split(x_true, c_true, test_size=200, random_state=42)# build optDataset
from pyepo.data.dataset import optDataset
dataset_train = optDataset(optmodel, x_train, c_train)
dataset_test = optDataset(optmodel, x_test, c_test)# build DataLoader
from torch.utils.data import DataLoader
batch_size = 32
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True)
loader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=False)
6.4 建立预测模型
由于PyEPO是基于PyTorch构建的,所以我们可以像平常一样使用PyTorch进行模型的搭建,函数的使用,以及模型的训练等操作。这为使用各种深度学习技术的用户提供了极大的便利。下面,我们将建立一个简单的线性回归模型作为预测模型:
import torch
from torch import nn# build linear model
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(num_feat, num_cost)def forward(self, x):out = self.linear(x)return out# init model
reg = LinearRegression()
# cuda
if torch.cuda.is_available():reg = reg.cuda()
6.5 模型的训练和测试
PyEPO的核心组件就是它的autograd优化模块,可以方便地调用前文中提到的各种方法,比如:
SPO+
import pyepo
# init SPO+ loss
spop = pyepo.func.SPOPlus(optmodel, processes=2)
扰动方法
import pyepo
# init perturbed optimizer layer
ptb = pyepo.func.perturbedOpt(optmodel, n_samples=3, sigma=1.0, processes=2)
# init perturbed Fenchel-Younge loss
pfy = pyepo.func.perturbedFenchelYoung(optmodel, n_samples=3, sigma=1.0, processes=2)
黑箱方法
import pyepo
# init dbb optimizer layer
dbb = pyepo.func.blackboxOpt(optmodel, lambd=20, processes=2)
# init optimizer layer with identity grad
nid = pyepo.func.negativeIdentity(optmodel, processes=2)
对比、排序方法
import pyepo
# init NCE loss
nce = pyepo.func.NCE(optmodel, processes=2, solve_ratio=0.05, dataset=dataset_train)
# init constrastive MAP loss
cmap = pyepo.func.contrastiveMAP(optmodel, processes=2, solve_ratio=0.05, dataset=dataset_train)
import pyepo
# init pointwise LTR loss
ltr = pyepo.func.pointwiseLTR(optmodel, processes=2, solve_ratio=0.05, dataset=dataset_train)
# init pairwise LTR loss
ltr = pyepo.func.pairwiseLTR(optmodel, processes=2, solve_ratio=0.05, dataset=dataset_train)
# init listwise LTR loss
ltr = pyepo.func.listwiseLTR(optmodel, processes=2, solve_ratio=0.05, dataset=dataset_train)
训练
接下来,以SPO+为例,我们可以正常使用PyTorch进行模型训练:
# set adam optimizeroptimizer = torch.optim.Adam(reg.parameters(), lr=5e-3)# train modereg.train()for epoch in range(5):# load datafor i, data in enumerate(loader_train):x, c, w, z = data # feat, cost, sol, obj# cudaif torch.cuda.is_available():x, c, w, z = x.cuda(), c.cuda(), w.cuda(), z.cuda()# forward passcp = reg(x)# spo+ lossloss = spop(cp, c, w, z)# backward passoptimizer.zero_grad()loss.backward()optimizer.step()# logregret = pyepo.metric.regret(reg, optmodel, loader_test)print("Loss: {:9.4f}, Regret: {:7.4f}%".format(loss.item(), regret*100))
由于不同的模块可能有不同的输入输出,在使用这些模块时,我们需要特别关注各模块的接口文档,确保我们的输入输出数据与其兼容,避免出现不一致的情况。
以扰动优化(perturbedOpt)为例,其训练过程和SPO+有所不同:
# set adam optimizeroptimizer = torch.optim.Adam(reg.parameters(), lr=5e-3)# set some lossl1 = nn.L1Loss()# train modereg.train()for epoch in range(5):# load datafor i, data in enumerate(loader_train):x, c, w, z = data # feat, cost, sol, obj# cudaif torch.cuda.is_available():x, c, w, z = x.cuda(), c.cuda(), w.cuda(), z.cuda()# forward passcp = reg(x)# perturbed optimizerwe = ptb(cp)# lossloss = l1(we, w)# backward passoptimizer.zero_grad()loss.backward()optimizer.step()# logregret = pyepo.metric.regret(reg, optmodel, loader_test)print("Loss: {:9.4f}, Regret: {:7.4f}%".format(loss.item(), regret*100))
7. 结语
端到端预测后优化是一项有趣的工作,也正是这项工作激发了我对优化和机器学习的深入探索。我无比敬佩在这个领域中工作的研究者们,他们提出的各种方法都有着独特的理论支撑和应用价值。我们明白这只是一个开始,端对端预测后优化这个领域还有有许多新的问题和理论等待我们去探索。我期待在未来的研究中,我们可以继续深化对这个领域的理解,发现更多的可能性。
参考文献
[1] Elmachtoub, A. N., & Grigas, P. (2021). Smart “predict, then optimize”. Management Science.
[2] Mandi, J., Stuckey, P. J., & Guns, T. (2020). Smart predict-and-optimize for hard combinatorial optimization problems. In Proceedings of the AAAI Conference on Artificial Intelligence.
[3] Pogančić, M. V., Paulus, A., Musil, V., Martius, G., & Rolinek, M. (2019, September). Differentiation of blackbox combinatorial solvers. In International Conference on Learning Representations.
[4] Berthet, Q., Blondel, M., Teboul, O., Cuturi, M., Vert, J. P., & Bach, F. (2020). Learning with differentiable pertubed optimizers. Advances in neural information processing systems, 33, 9508-9519.
[5] Mulamba, M., Mandi, J., Diligenti, M., Lombardi, M., Bucarey, V., & Guns, T. (2021). Contrastive losses and solution caching for predict-and-optimize. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence.
[6] Mandi, J., Bucarey, V., Mulamba, M., & Guns, T. (2022). Decision-focused learning: through the lens of learning to rank. Proceedings of the 39th International Conference on Machine Learning.
[7] Sahoo, S. S., Paulus, A., Vlastelica, M., Musil, V., Kuleshov, V., & Martius, G. (2022). Backpropagation through combinatorial algorithms: Identity with projection works. arXiv preprint arXiv:2205.15213.
[8] Kervadec, H., Dolz, J., Yuan, J., Desrosiers, C., Granger, E., & Ayed, I. B. (2022, August). Constrained deep networks: Lagrangian optimization via log-barrier extensions. In 2022 30th European Signal Processing Conference (EUSIPCO) (pp. 962-966). IEEE.
[9] Elmachtoub, A. N., Liang, J. C. N., & McNellis, R. (2020, November). Decision trees for decision-making under the predict-then-optimize framework. In International Conference on Machine Learning (pp. 2858-2867). PMLR.
[10] Amos, B., & Kolter, J. Z. (2017, July). Optnet: Differentiable optimization as a layer in neural networks. In International Conference on Machine Learning (pp. 136-145). PMLR.
[11] Wilder, B., Dilkina, B., & Tambe, M. (2019, July). Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, No. 01, pp. 1658-1665).
[12] Mandi, J., & Guns, T. (2020). Interior point solving for lp-based prediction+ optimisation. Advances in Neural Information Processing Systems, 33, 7272-7282.
[13] Ferber, A., Wilder, B., Dilkina, B., & Tambe, M. (2020, April). Mipaal: Mixed integer program as a layer. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 02, pp. 1504-1511).
[14] Dalle, G., Baty, L., Bouvier, L., & Parmentier, A. (2022). Learning with combinatorial optimization layers: a probabilistic approach. arXiv preprint arXiv:2207.13513.
[15] Liu, T. Y. (2009). Learning to rank for information retrieval. Foundations and Trends® in Information Retrieval, 3(3), 225-331.
[16] Tang, B., & Khalil, E. B. (2022). PyEPO: A PyTorch-based end-to-end predict-then-optimize library for linear and integer programming. arXiv preprint arXiv:2206.14234.
[17] Shah, S., Wilder, B., Perrault, A., & Tambe, M. (2022). Learning (local) surrogate loss functions for predict-then-optimize problems. arXiv e-prints, arXiv-2203.
相关文章:
优化|当机器学习上运筹学:PyEPO与端对端预测后优化
分享者:唐博 编者按: 这篇文章我想要写已经很久了,毕竟“端对端预测后优化”(End-to-End Predict-then-Optimize)正是我读博期间的主要研究方向,但我又一直迟迟没能下笔。想说自己杂事缠身(实…...
Cocos Creator的 Cannot read property ‘applyForce‘ of undefined报错
序: 1、博主是看了这个教程操作的时候出的bug>游戏开发 | 17节课学会如何用Cocos Creator制作3D跑酷游戏 | P9 代码控制对象移动_哔哩哔哩_bilibili 2、其实问题不是出在代码上,但是发现物体就是不平移 3、node全栈的资料》node全栈框架 正文…...

纯css实现九宫格图片
本篇文章所分享的内容主要涉及到结构伪类选择器,不熟悉的小伙伴可以了解一下,在常用的css选择器中我也有分享相关内容。 话不多说,接下来我们直接上代码: <!DOCTYPE html> <html lang"en"><head>&l…...

【MySQL】数据库的增删查改+备份与恢复
文章目录 一、创建数据库create二、数据库所使用的编码2.1 查询字符集和校验集2.2 指定编码创建数据库2.3 不同的校验集对比 三、删除数据库drop四、查看数据库show五、修改数据库alter六、数据库的备份与恢复6.1 备份 mysqldump6.2 恢复source6.3 仅备份几张表或备份多个数据库…...

Docker 部署 redis 举例
1、搜索镜像,也可以访问 https://hub.docker.com/ 搜索镜像,查看所有版本。 $ docker search redis2、拉取镜像 $ docker pull redis:5.03、启动镜像,并配置相关映射与绑定(附:Docker 常用命令与指令参数)…...

通过HandlerMethodArgumentResolver实现统一添加接口入参参数
背景:项目中有些接口的入参需要用户id信息,最简单的做法在每个Controller方法调用的时候获取登录信息然后给入参设置用户id,但是这样就会有很多重复性的工作。另一个可行的也更好的方案可以使用HandlerMethodArgumentResolver来实现。 部分示…...

JAVA-spring boot 2.4.X报错Unable to find GatewayFilterFactory with name Hystrix
网关升级spring boot项目后,启动网关报错,具体报错信息如下: 2021-12-06 09:06:25.335 ERROR 45102 --- [oundedElastic-3] reactor.core.publisher.Operators : Operator called default onErrorDropped reactor.core.Exceptions$ErrorCallback…...

运输层---UDP协议
目录 一. 无连接运输:UDP1.1 定义1.2 特点1.3 应用 二. UDP报文段结构三. UDP检验和3.1 定义3.2 检验和计算实例3.2 UDP检验和的局限 一. 无连接运输:UDP 1.1 定义 UDP(User Datagram Protocol)用户数据报协议:由 [RF…...
【LeetCode】剑指 Offer Ⅱ 第3章:字符串(7道题) -- Java Version
题库链接:https://leetcode.cn/problem-list/e8X3pBZi/ 题目解决方案剑指 Offer II 014. 字符串中的变位词双指针 数组模拟哈希表 ⭐剑指 Offer II 015. 找到字符串中所有字母异位词双指针 数组模拟哈希表 ⭐剑指 Offer II 016. 不含重复字符的最长子字符串双指针…...
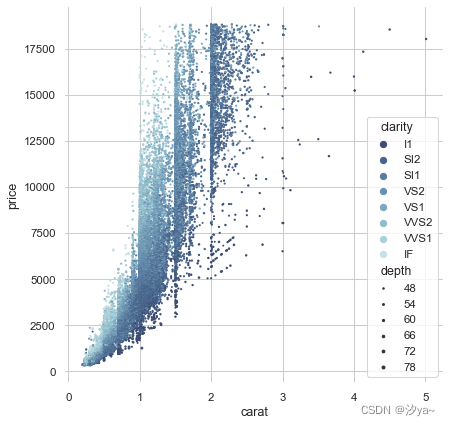
【python】绘图代码模板
【python】绘图代码模板 pandas.DataFrame.plot( )画图函数Seaborn绘图 -数据可视化必备主题样式导入数据集可视化统计关系散点图抖动图箱线图小提琴图Pointplot群图 可视化数据集的分布绘制单变量分布柱状图直方图 绘制双变量分布Hex图KDE 图可视化数据集中的成对关系 好看的图…...
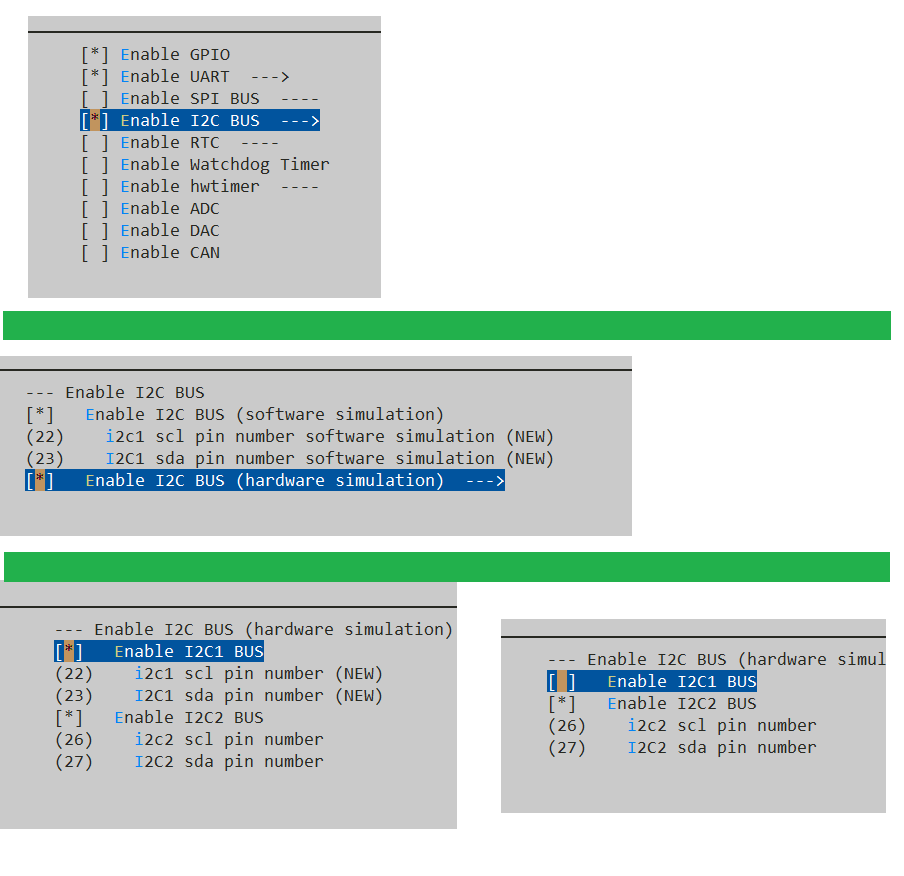
RTT学习笔记12-KConfig 语法学习
KConfig 语法学习 RTT 官方教程 https://www.rt-thread.org/document/site/#/development-tools/build-config-system/Kconfig 我自己写的IIC配置 menuconfig BSP_USING_I2C # I2C 菜单bool "Enable I2C BUS" # 提示I2C 菜单default n # 默认不使能I2C 菜单…...
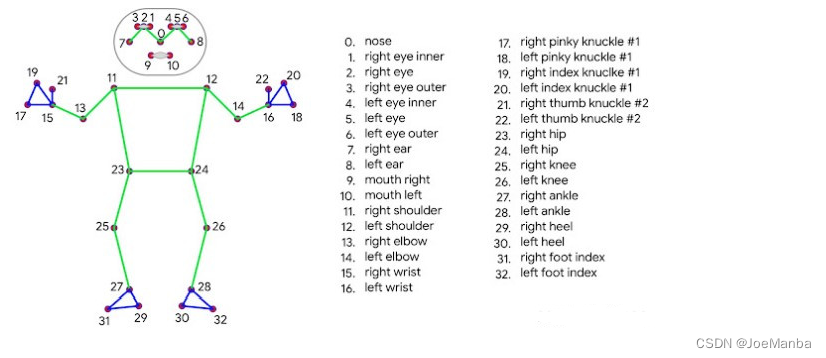
基于Mediapipe的姿势识别并同步到Unity人体模型中
如题,由于是商业项目,无法公开源码,这里主要说一下实现此功能的思路。 人体关节点识别 基于Mediapipe Unity插件进行开发,性能比较低的CPU主机,无法流畅地运行Mediapipe,这个要注意一下。 Mediapipe33个人体…...
Linux下进程的特点与环境变量
目录 进程的特点 进程特点的介绍 进程时如何实现并发性的 进程间如何切换 概念铺设 PC指针 上下文 环境变量 PATH 修改PATH HOME SHELL env 命令行参数 什么是命令行参数? 打印命令行参数 通过函数获得环境变量 getenv 命令行参数 env 修改环境变…...

以Llama-2为例,在生成模型中使用自定义LogitsProcessor
以Llama-2为例,在生成模型中使用自定义LogitsProcessor 1. 前言2. 场景介绍3. 解决方法4. 结语 1. 前言 在上一篇文章 以Llama-2为例,在生成模型中使用自定义StoppingCriteria中,介绍了怎样在生成的过程中,使用stopping criteria…...

python 计算图片hash 缓存图片为key
python,有时希望缓存图片作为key,怎么办?缓存整张突破占用内存太多,不妨缓存hash值: Fast way to Hash Numpy objects for Caching import hashlib import numpy a numpy.random.rand(10, 100) b a.view(numpy.uin…...

制造型企业如何实现车间设备生产数据的实时采集?需要5G网络吗?
引言 在制造业数字化转型的浪潮下,实时采集车间设备生产数据变得尤为重要。工业边缘网关HiWoo Box作为一款专为工业应用而设计的智能设备,具备工业级设计和多种联网方式,为制造型企业提供了高性能的车间设备数据实时采集解决方案。本文将重点…...

第2章 HTML中的JavaScript
引言 将JavaScript引入网页,首先要解决它与网页的主导语言HTML的关系问题 script元素 将JavaScript插入HTML的主要方法是使用script元素,script有8个可选属性 async:表示异步加载js文件内容,他们之间的顺序不一定按照html顺序ch…...
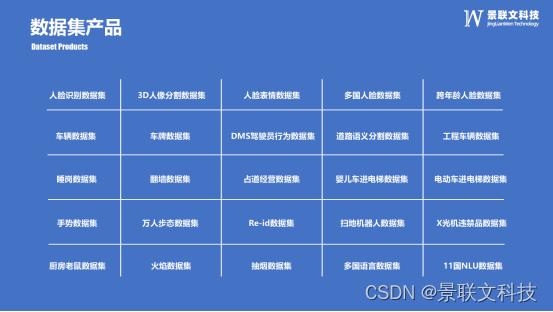
景联文科技高质量成品数据集上新啦!
景联文科技近期上新多个成品数据集,包含图像、视频等多种类型的数据,涵盖丰富的场景,可满足不同模型的多元化需求。 高质量成品数据集可用于训练和优化模型,使得模型能够更加全面和精准地理解和处理任务,更好地应对复…...

flask------请求拓展
flask中也有类似与django中的中间件,只不过是另一种写法,但是他们的作用是一样的,下面我们就一一介绍: 1.before_request 作用 : before_request 相当于 django 中的 process_request,每一个请求在被处理前都会经…...

大数据-玩转数据-FLINK-从kafka消费数据
一、基于前面kafka部署 大数据-玩转数据-Kafka安装 二、FLINK中编写代码 package com.lyh.flink04;import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apa…...

SMS-Activate接码避坑指南:为什么你总收不到验证码?网络、号码选择与退款机制详解
SMS-Activate接码实战优化:从网络配置到号码选择的深度避坑手册 每次点击"获取验证码"按钮后的漫长等待,就像一场数字时代的赌博——你永远不知道这次是顺利通关还是再次掉进验证码黑洞。作为全球开发者、跨境电商从业者和隐私需求者的"数…...

OpenClaw安全防护指南:千问3.5-27B本地化部署的权限管控策略
OpenClaw安全防护指南:千问3.5-27B本地化部署的权限管控策略 1. 为什么需要特别关注OpenClaw的安全防护? 去年冬天,我在自己的MacBook上部署OpenClaw时,曾因为一个简单的配置疏忽差点酿成大祸。当时我只是想让AI助手帮我整理桌面…...

Micropython实战指南:ESP32C3开发板固件烧录全解析
1. 认识你的开发板:ESP32C3与MicroPython的完美组合 第一次拿到合宙ESP32C3开发板时,我盯着那个小小的Type-C接口看了半天——这玩意儿真的能跑Python?事实证明它不仅支持MicroPython,还能通过USB直接交互,比传统串口调…...

终极指南:5步快速上手SillyTavern打造个性化AI对话体验
终极指南:5步快速上手SillyTavern打造个性化AI对话体验 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern SillyTavern是一款专为高级用户设计的LLM前端界面,让你能够轻…...

ofa_image-caption镜像免配置:内置CUDA 11.8+cuDNN 8.6预编译环境
ofa_image-caption镜像免配置:内置CUDA 11.8cuDNN 8.6预编译环境 你是不是也遇到过这种情况?看到一张有趣的图片,想为它配上一段精准的描述,却一时词穷。或者,手头有一大堆产品图片,需要批量生成英文介绍&…...

3小时掌握拼多多数据采集:Scrapy框架实战指南
3小时掌握拼多多数据采集:Scrapy框架实战指南 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 对于电商数据分析和市场研究从业者而言,获…...
Pixel Language Portal效果展示:实时翻译+st.balloons()庆祝动画+HP状态变化的沉浸式交互录屏
Pixel Language Portal效果展示:实时翻译st.balloons()庆祝动画HP状态变化的沉浸式交互录屏 1. 像素冒险工坊的诞生 在传统翻译工具千篇一律的界面中,Pixel Language Portal(像素语言跨维传送门)带来了全新的视觉冲击。这款基于…...

惊艳音效生成效果:HunyuanVideo-Foley实际作品展示与测评
惊艳音效生成效果:HunyuanVideo-Foley实际作品展示与测评 你肯定有过这样的经历:精心拍摄了一段视频,画面构图、光影、运镜都堪称完美,但导出后总觉得少了点什么。对,就是声音。画面里的人物在奔跑,却听不…...

运算放大器电流流向的5个常见误区:硬件工程师都踩过哪些坑?
运算放大器电流流向的5个常见误区:硬件工程师都踩过哪些坑? 在硬件设计领域,运算放大器就像一位沉默的舞者——看似动作简单,实则每个细节都暗藏玄机。记得我第一次调试仪表放大电路时,盯着示波器上诡异的电流波形百思…...

【从0开始学设计模式-6| 原型模式】
一个月没更新了,在找实习。。 其实还是懒了,其实每天花个半小时左右就能写一篇博客的。。。概念 原型模式(Prototype Pattern) 设计出来的目标就是:通过本体复制出与本体一样的分身(分身具有本体一样特性)定义…...