数据结构-链表
🗡CSDN主页:d1ff1cult.🗡
🗡代码云仓库:d1ff1cult.🗡
🗡文章栏目:数据结构专栏🗡
目录
目录
代码总览:
接口slist.h:
slist.c:
1.什么是链表
1.1链表的概念
1.2链表的分类
2.链表与顺序表
顺序表的优点与缺陷
3链表
3.1链表实现
总结
代码总览:
slist.h:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
typedef int SLTDataType;typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;void SLTPrint(SLTNode* phead);SLTNode* BuySListNode(SLTDataType x);
//开辟新的节点void SLTPushBack(SLTNode** pphead, SLTDataType x);
//尾插
void SLTPushFront(SLTNode* phead, SLTDataType x);
//头插
void SLTPopBack(SLTNode** pphead);
//尾删
void SLTPopFront(SLTNode** pphead);
//头删
void SLTInsert(SLTNode**phead,SLTNode* pos, SLTDataType x);
//在pos之前插入x
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//在pos之后插入x
void SLTErase(SLTNode** pphead, SLTNode*pos);
//删除pos位置
void SLTEraseAfter(SLTNode* pos);
//删除pos后一个位置
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//查找 slist.c:
#define _CRT_SECURE_NO_WARNINGS
#include"slist.h"
void SLTPrint(SLTNode* phead)
{SLTNode* cur = phead;while (cur != NULL){printf("%d->", cur->data);cur = cur->next;}printf("NULL\n");
}SLTNode* BuySListNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->data = x;newnode->next = NULL;
}
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{SLTNode* newnode = BuySListNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLTNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newnode;}
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{SLTNode* newnode = BuySListNode(x);newnode->next = *pphead;*pphead = newnode;
}//头插
void SLTPopBack(SLTNode** pphead, SLTDataType x)
{//1.空assert(*pphead);//2.一个节点//3.一个以上节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{/*SLTNode* tailPrev = NULL;SLTNode* tail = *pphead;while (tail->next != NULL){tailPrev = tail;tail = tail->next;}free(tail);tailPrev->next = NULL;*/SLTNode* tail = *pphead;while(tail->next->next){tail = tail->next;}free(tail->next);tail->next = NULL;}
}
void SLTPopFront(SLTNode** pphead)
{assert(*pphead);//空//非空SLTNode* newhead = (*pphead)->next;free(*pphead);*pphead = newhead;
}
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{SLTNode* cur = phead;while (cur){if (cur->data== x){return cur;}cur = cur->next;}return NULL;
}
void SLTInsert(SLTNode** pphead,SLTNode* pos, SLTDataType x)
{assert(pos);if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLTNode* newnode = BuySListNode(x);prev->next = newnode;newnode->next = pos;}
}
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = BuySListNode(x);newnode->next = pos->next;pos->next = newnode;
}
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead);assert(pos);if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);}
}
void SLTEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* posNext = pos->next;pos->next = posNext->next;free(posNext);posNext = NULL;
}1.什么是链表
1.1链表的概念
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。


从上图可看出,链式结构在逻辑上是连续的,但是在物理上不一定连续现实中的结点一般都是从堆上申请出来的从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续

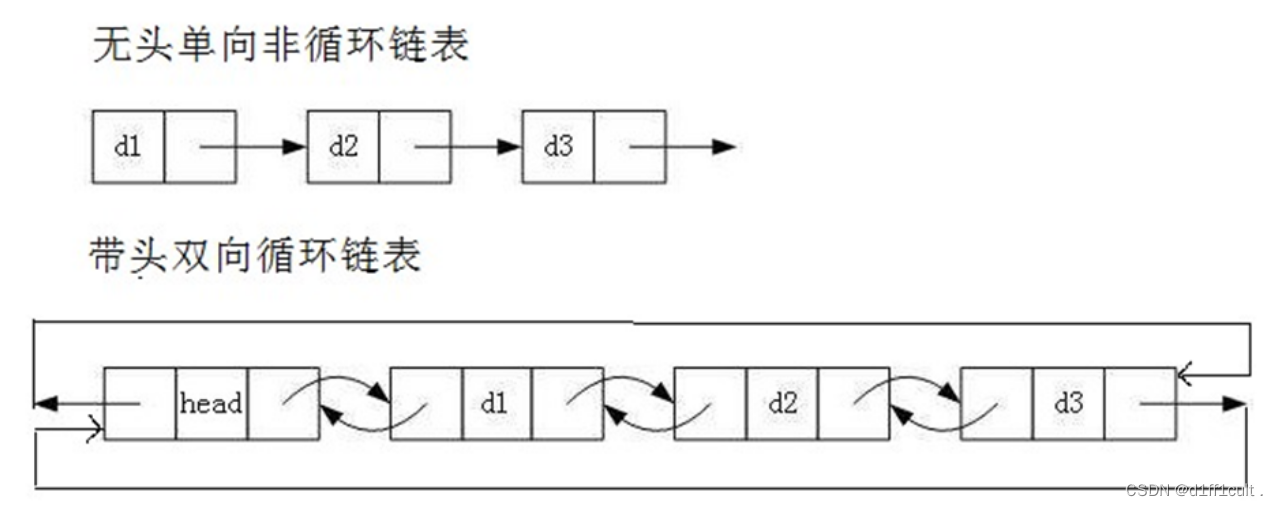
1.2链表的分类
1.带头或不带头
2.循环或不循环
3.双向或单向
2.链表与顺序表
顺序表的优点与缺陷
顺序表的数据在物理空间上是连续存放的,使得我们用数组下标访问变的十分简单,尾插尾删的效率比较高,但同时想要在中间删除数据时,需要将数据一个个挪动,效率比较低,但同时他的数据在物理空间上连续存放也有了以下的问题
1中间/头部的插入删除,时间复杂度为O(N)
2.增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
3.增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
详细了解请移步:
3链表
链表是一块一块独立的空间,通过结构体指针来连接,删除/插入数据比较方便,空间使用malloc函数开辟,浪费的空间比较少,而且在物理上不是连续存放的,不会出现异地扩容之类的行为,对空间懂得利用较高,空间都是按需申请的
3.1链表实现
1.定义一个结构体
typedef int SLTDataType;
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;同时为了方便改变数据的类型,我们定义typedef int SLTDataType;结构体中的内容有存储的数据还有指向下一块内容的结构体指针 next
2.链表的遍历
void PrintSlist(SLTNode* phead)
{SLTNode* cur = phead;while (cur != NULL){printf("%d->", cur->data);cur = cur->next;}printf("\n");
}这其中有一句非常关键的代码:cur=cur->next;这个时候又得拿出这张图了:

将头指针phead赋值给cur,让cur不断向后遍历,直到遇到NULL指针停下来
那么cur=cur->next;首先cur=phead,此时cur指向了第一个结构体,打印data
然后再将结构体中next指向的地址赋值给cur,此时cur就指向了下一个结构体,
如此遍历直到cur遇到了NULL;
3.创建新节点
定义一个结构体指针newnode用来创建新的节点,使用malloc手动开辟所需的空间,需要注意的是newnode是结构体指针,类型是SLTNode而不是SLTDataType,如果定义成了SLTDataType类型,后续的free操作就会报错
SLTNode* BuySListNode(SLTDataType x)
{SLTNode* newnode =(SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->data = x;newnode->next = NULL;
}4.尾插
引入了新的结构体指针tail,不断遍历链表,直到tail->next==NULL的时候说明已经找到了链表的尾部,此时再将创建好的newnode赋值给tail->next将新节点和链表链接起来实现了链表的尾插。 注意,while中tail->next==NULL,不能写成tail==NULL,tail=newnode。
因为phead newnode tail都是形参出了作用域后就会销毁,这样写不仅实现不了尾插,还会导致内存的泄露。
下面这个图就是错误原因
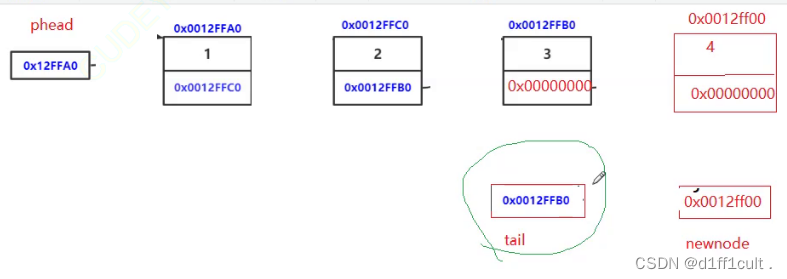
这一段尾插没有考虑链表为空的情况。
void SLTPushBack(SLTNode* phead, SLTDataType x)
{SLTNode* newnode = BuySListNode(x);SLTNode* tail = phead;while (tail->next != NULL){tail = tail->next;}tail->next = newnode;
}//尾插下面为正确的尾插,参数需要传二级指针
1.改变结构体需要用结构体指针(参数)
2.改变结构体指针需要用结构体指针的指针(tail->next = newnode)
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{SLTNode* newnode = BuySListNode(x);if (*pphead == NULL){*pphead = newnode;}else{SLTNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = newnode;}
}5.头插
分为三种情况
1.空
2.一个节点
3.一个以上的节点(两种写法)
当找到尾部tail后不能直接将tail free释放掉然后置空,因为上一个结构体还指向tail,然而tail又是局部变量,出了作用域就会被销毁,所以上一个结构体的next指向了野指针,所以我们就想到了使用tail的前一个 tailPrev,避免了野指针的出现;
链表的头插,,简单而且效率高
void SLTPopBack(SLTNode** pphead, SLTDataType x)
{//1.空assert(*pphead);//2.一个节点//3.一个以上节点if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{/*SLTNode* tailPrev = NULL;SLTNode* tail = *pphead;while (tail->next != NULL){tailPrev = tail;tail = tail->next;}free(tail);tailPrev->next = NULL;*/SLTNode* tail = *pphead;while(tail->next->next){tail = tail->next;}free(tail->next);tail->next = NULL;}
}6.头删
同样考虑是否为空,较为简单,头删简单效率高。
void SLTPopFront(SLTNode** pphead)
{assert(*pphead);//空//非空SLTNode* newhead = (*pphead)->next;free(*pphead);*pphead = newhead;
}7.查
这里的查也同时可以起到修改的作用,查找到数据后,将其内容修改。
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{SLTNode* cur = phead;while (cur){if (cur->data== x){return cur;}cur = cur->next;}return NULL;
}//修改:
//SLTNode* pos = SLTFind(plist, 1);//if (pos)//{// pos->data *= 10;//}8.在pos位置前插入
(其实相当于在pos位置插入)在pos位置前插入,需要链表遍历到pos,但是此时不知道pos前一个位置的地址,无法做到在pos位置前插入,所以我们又引进了一个结构体指针prev,指向了pos的前一个位置.
单链表的前插还是具有一定的局限性,前插用双向链表来实现更为便捷。
void SLTInsert(SLTNode** pphead,SLTNode* pos, SLTDataType x)
{assert(pos);if (pos == *pphead){SLTPushFront(pphead, x);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}SLTNode* newnode = BuySListNode(x);prev->next = newnode;newnode->next = pos;}}9.在pos位置后插入
注意
newnode->next = pos->next;
pos->next = newnode;这两句代码的顺序不能改变,不然就会出现环链表,,从而导致死循环
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = BuySListNode(x);newnode->next = pos->next;pos->next = newnode;
}10.删除pos位置
首先判断一下pos是不是头指针,如果是就复用之前写的头删,如果不是,就选择引入prev指针指向pos的前一个位置,方便与pos后面的指针链接
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead);assert(pos);if (pos == *pphead){SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);}
}11.删除pos位置后一个
较为简单不再赘述
void SLTEraseAfter(SLTNode* pos)
{assert(pos);assert(pos->next);SLTNode* posNext = pos->next;pos->next = posNext->next;free(posNext);posNext = NULL;
}12.销毁
void SLTDestory(SLTNode** pphead)
{assert(pphead);SLTNode* cur = *pphead;while (cur){SLTNode* next = cur->next;free(cur);cur = next;}*pphead = NULL;
}总结
以上便是不带哨兵 单链表的实现。
相关文章:
数据结构-链表
🗡CSDN主页:d1ff1cult.🗡 🗡代码云仓库:d1ff1cult.🗡 🗡文章栏目:数据结构专栏🗡 目录 目录 代码总览: 接口slist.h: slist.c: 1.什么是链表 1.1链…...

大数据Flink(五十五):Flink架构体系
文章目录 Flink架构体系 一、 Flink中的重要角色 二、Flink数据流编程模型 三、Libraries支持...

使用矢量数据库打造全新的搜索引擎
在技术层面上,矢量数据库采用了一种名为“矢量索引”的技术,这是一种组织和搜索矢量数据的方法,可以快速找到相似矢量。其中关键的一环是“距离函数”的概念,它可以衡量两个矢量的相似程度。 1.矢量数据库简介 矢量数据库是专门…...

算法提高-树状数组
算法提高-树状数组 241. 楼兰图腾(区间求和 单点修改)242. 一个简单的整数问题(差分推公式 实现 维护区间修改单点求和)243. 一个简单的整数问题2(区间修改和区间求和)AcWing 244. 谜一样的牛(…...

Django ORM详解:最全面的数据库处理指南
概要 深度探讨Django ORM的概念、基础使用、进阶操作以及详细解析在实际使用中如何处理数据库操作。这篇文章旨在帮助大家全面掌握Django ORM,理解其如何简化数据库操作,并透过表象理解其内部工作原理。 Django ORM简介 在深入讨论Django的ORMÿ…...

Istio 安全 授权管理AuthorizationPolicy
这个和cka考试里面的网络策略是类似的。它是可以实现更加细颗粒度限制的。 本质其实就是设置谁可以访问,谁不可以访问。默认命名空间是没有AuthorizationPolicy---允许所有的客户端访问。 这里是没有指定应用到谁上面去,有没有指定使用哪些客户端&#…...
04 Ubuntu中的中文输入法的安装
在Ubuntu22.04这种版本相对较高的系统中安装中文输入法,一般推荐使用fctix5,相比于其他的输入法,这款输入法的推荐词要好得多,而且不会像ibus一样莫名其妙地失灵。 首先感谢文章《滑动验证页面》,我是根据这篇文章的教…...
faac内存开销较大,为方便嵌入式设备使用进行优化(valgrind使用)
faac内存开销较大,为方便嵌入式设备使用进行优化,在github上提了issues但是没人理我,所以就搞一份代码自己玩吧。 基于faac_1_30版本,原工程https://github.com/knik0/faac faac内存优化: faac内存开销较大,为方便嵌入…...
)
分数线划定(c++题解)
题目描述 世博会志愿者的选拔工作正在 A 市如火如荼的进行。为了选拔最合适的人才,A 市对所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入面试。面试分数线根据计划录取人数的 150% 划定,即如果计划录取 m 名志愿者…...
React 在 html 中 CDN 引入(包含 antd、axios ....)
一、简介 cdn 获取推荐 https://unpkg.com,unpkg 是一个快速的全球内容交付网络,适用于 npm 上所有内容。 【必备】react 相关 cdn。附:github 官方文档获取、现阶段官方文档 CDN 网址。 <script crossorigin src"https://unpkg.com…...

数据结构----异或
数据结构----异或 一.何处用到了异或 1. 运算符 //判断是否相同 用到了异或,看异或结果如果是0就是相同,不是0就是不同//注意: 不能给小数用,小数没有相等的概念,所以小数判断是否相同都是进行相减判断2.找一堆数中…...

PHP Smarty模板的语法规则是怎样的?
首先,你要知道Smarty模板是以模板格式来编写的。模板格式类似于HTML,但它的语法更加简洁明了。 以下是PHP Smarty模板的语法规则和代码例子: 变量:在Smarty模板中,你可以使用变量来显示动态内容。变量通常以“{$”符…...

Socks IP轮换:为什么是数据挖掘和Web爬取的最佳选择?
在数据挖掘和Web爬取的过程中,IP轮换是一个非常重要的概念。数据挖掘和Web爬取需要从多个网站或来源获取数据,而这些网站通常会对来自同一IP地址的请求进行限制或封锁。为了避免这些问题,数据挖掘和Web爬取过程中需要使用Socks IP轮换技术。在…...

优化|当机器学习上运筹学:PyEPO与端对端预测后优化
分享者:唐博 编者按: 这篇文章我想要写已经很久了,毕竟“端对端预测后优化”(End-to-End Predict-then-Optimize)正是我读博期间的主要研究方向,但我又一直迟迟没能下笔。想说自己杂事缠身(实…...
Cocos Creator的 Cannot read property ‘applyForce‘ of undefined报错
序: 1、博主是看了这个教程操作的时候出的bug>游戏开发 | 17节课学会如何用Cocos Creator制作3D跑酷游戏 | P9 代码控制对象移动_哔哩哔哩_bilibili 2、其实问题不是出在代码上,但是发现物体就是不平移 3、node全栈的资料》node全栈框架 正文…...

纯css实现九宫格图片
本篇文章所分享的内容主要涉及到结构伪类选择器,不熟悉的小伙伴可以了解一下,在常用的css选择器中我也有分享相关内容。 话不多说,接下来我们直接上代码: <!DOCTYPE html> <html lang"en"><head>&l…...

【MySQL】数据库的增删查改+备份与恢复
文章目录 一、创建数据库create二、数据库所使用的编码2.1 查询字符集和校验集2.2 指定编码创建数据库2.3 不同的校验集对比 三、删除数据库drop四、查看数据库show五、修改数据库alter六、数据库的备份与恢复6.1 备份 mysqldump6.2 恢复source6.3 仅备份几张表或备份多个数据库…...

Docker 部署 redis 举例
1、搜索镜像,也可以访问 https://hub.docker.com/ 搜索镜像,查看所有版本。 $ docker search redis2、拉取镜像 $ docker pull redis:5.03、启动镜像,并配置相关映射与绑定(附:Docker 常用命令与指令参数)…...

通过HandlerMethodArgumentResolver实现统一添加接口入参参数
背景:项目中有些接口的入参需要用户id信息,最简单的做法在每个Controller方法调用的时候获取登录信息然后给入参设置用户id,但是这样就会有很多重复性的工作。另一个可行的也更好的方案可以使用HandlerMethodArgumentResolver来实现。 部分示…...

JAVA-spring boot 2.4.X报错Unable to find GatewayFilterFactory with name Hystrix
网关升级spring boot项目后,启动网关报错,具体报错信息如下: 2021-12-06 09:06:25.335 ERROR 45102 --- [oundedElastic-3] reactor.core.publisher.Operators : Operator called default onErrorDropped reactor.core.Exceptions$ErrorCallback…...

cannot import name ‘__version__‘ from ‘tensorflow.keras‘ 的解决方案
进到你的keras默认目录,维度在这里“C:\Users\HP\miniconda3\envs\brain\Lib\site-packages\rl”进入文件夹 ,要修改callbacks.py找到并用记事本(或代码编辑器)打开 callbacks.py 文件。找到 第 8 行 左右的代码:pytho…...

ViGEmBus游戏控制器模拟驱动技术解析与应用指南
ViGEmBus游戏控制器模拟驱动技术解析与应用指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 游戏控制器模拟驱动是连接玩家与游戏世界的重要桥梁…...

AI建站工具分人群解决方案:中小企业主、运营、外贸人分别怎么选
同样是想要一个网站,中小企业主、市场运营、外贸负责人、个人创作者的内心诉求,其实天差地别。老板看重的是成本和品牌形象;运营人员关心的是好不好改、能不能帮我获取线索;外贸人则把多语言和海外访问速度放在第一位。今天这篇文…...

oh-my-posh2 配置备份与恢复终极指南:确保你的个性化设置永不丢失
oh-my-posh2 配置备份与恢复终极指南:确保你的个性化设置永不丢失 【免费下载链接】oh-my-posh2 A prompt theming engine for Powershell 项目地址: https://gitcode.com/gh_mirrors/oh/oh-my-posh2 oh-my-posh2 是一款强大的 PowerShell 提示主题引擎&…...

LabView实战:高效实现float到十六进制的精准转换VI设计
1. 为什么需要float到十六进制的精准转换? 在工业自动化和测试测量领域,我们经常需要处理各种传感器采集的浮点数据。比如温度传感器返回的25.6℃、压力传感器检测的101.325kPa,这些数据在LabView中通常以float类型存储。但在某些特殊场景下&…...

新手福音:在快马平台上零配置运行第一个yolov11检测程序
今天想和大家分享一个特别适合深度学习新手的体验——在InsCode(快马)平台上零配置运行第一个yolov11目标检测程序。作为计算机视觉的入门项目,目标检测既能带来直观的视觉反馈,又能快速建立成就感,但传统方式的环境配置往往让初学者望而却步…...

突破性音源聚合!洛雪音乐实现全网高品质音乐自由
突破性音源聚合!洛雪音乐实现全网高品质音乐自由 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否曾因音乐平台版权限制而无法听到心仪歌曲?是否厌倦了在不同应用间切…...

macOS菜单栏终极管理方案:Ice如何重塑你的数字工作空间
macOS菜单栏终极管理方案:Ice如何重塑你的数字工作空间 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice 核心关键词:macOS菜单栏管理,Ice菜单栏工具 长尾关键词&am…...

在RK3588上搞定XDMA AXI-Stream回环测试:从Verilog到Rust的完整流程与避坑指南
RK3588平台XDMA AXI-Stream全链路开发实战:从FPGA设计到Rust测试的工程化实现 当我们需要在嵌入式系统中实现高速数据交换时,PCIeAXI-Stream的组合无疑是黄金搭档。RK3588作为一款高性能处理器,配合FPGA的灵活可编程特性,能够构建…...

突破压缩技术边界:7-Zip ZS多算法融合解决方案全解析
突破压缩技术边界:7-Zip ZS多算法融合解决方案全解析 【免费下载链接】7-Zip-zstd 7-Zip with support for Brotli, Fast-LZMA2, Lizard, LZ4, LZ5 and Zstandard 项目地址: https://gitcode.com/gh_mirrors/7z/7-Zip-zstd 在数据爆炸的时代,文件…...