【PyTorch】PyTorch、Cuda 的安装和使用
原文作者:我辈李想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
文章目录
- 前言
- 一、Anaconda 中安装 PyTorch 和 CUDA
- 二、检查PyTorch和CUDA版本
- 三、PyTorch的基本使用
- 四、PyTorch调用cuda
- 五、Matplotlib绘制Pytorch损失函数和准确率
- 六、tesorbrand显示图像
- 七、用Pytorch写一个卷积神经网络
- 八、用Pytorch写一个目标检测模型
前言
PyTorch是一个开源的Python深度学习框架,可以用于构建各种类型的神经网络模型。
一、Anaconda 中安装 PyTorch 和 CUDA
-
首先下载并安装适用于您系统的 Anaconda 版本。
-
打开 Anaconda Prompt 或命令行工具,并创建一个名为“pytorch”或任何其他您喜欢的环境,此处假设您使用的是 Anaconda 4.5 或更高版本:
conda create -n pytorch python=3.7 anaconda
- 激活新环境:
conda activate pytorch
- 安装 PyTorch:
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia
此命令将安装适用于 CUDA 11.1 的 PyTorch 和 TorchVision,以及适用于 CUDA 11.1 的 CUDA 工具包。
- 验证 PyTorch 安装是否成功:
python -c "import torch; print(torch.__version__)"
如果成功安装,这将打印 PyTorch 的版本号。
二、检查PyTorch和CUDA版本
可以使用以下命令:
import torchprint(torch.__version__)
print(torch.version.cuda)
这将打印出您正在使用的PyTorch和CUDA版本。
三、PyTorch的基本使用
示例
PyTorch是一个开源的Python深度学习框架,可以用于构建各种类型的神经网络模型。要使用PyTorch,您需要首先安装它。可以使用以下命令在终端中安装PyTorch:
pip install torch
然后,您可以在Python脚本中导入PyTorch并开始使用它。例如,要构建一个简单的全连接神经网络,可以使用以下代码:
import torch
import torch.nn as nn# Define the neural network model
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784, 256)self.fc2 = nn.Linear(256, 10)def forward(self, x):x = x.view(-1, 784)x = torch.relu(self.fc1(x))x = self.fc2(x)return x# Instantiate the model and define the loss function and optimizer
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)# Load the data and train the model
for epoch in range(10):for i, (inputs, labels) in enumerate(train_loader, 0):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# Evaluate the trained model on the test set
correct = 0
total = 0
with torch.no_grad():for inputs, labels in test_loader:outputs = net(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print('Accuracy: %d %%' % (100 * correct / total))
在这个例子中,我们定义了一个简单的全连接神经网络,使用MNIST数据集进行训练和测试。我们使用PyTorch内置的nn.Module类来定义神经网络模型,并在forward方法中定义正向传播的操作。我们使用交叉熵损失函数和随机梯度下降(SGD)优化器来训练模型。我们使用训练数据集中的数据来更新模型参数,并使用测试数据集来评估模型的准确性。
四、PyTorch调用cuda
在PyTorch中使用CUDA可以大大加速训练和推理过程。以下是使用CUDA的几个步骤:
- 检查CUDA是否可用:
import torchif torch.cuda.is_available():device = torch.device("cuda") # 如果GPU可用,则使用CUDA
else:device = torch.device("cpu") # 如果GPU不可用,则使用CPU
- 将模型和数据加载到CUDA设备:
model.to(device)
inputs, labels = inputs.to(device), labels.to(device)
- 将数据转换为CUDA张量:
inputs = inputs.cuda()
labels = labels.cuda()
- 在训练过程中,使用CUDA加速计算:
for inputs, labels in dataloader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()
请注意,在使用CUDA时,您需要确保您的计算机具有兼容的GPU和正确的CUDA和cuDNN版本。您可以在PyTorch的官方文档中找到更多详细信息。
五、Matplotlib绘制Pytorch损失函数和准确率
在Pytorch中,我们可以使用Matplotlib来绘制训练过程中的损失函数曲线、准确率曲线等。下面是一个简单的示例:
import matplotlib.pyplot as plt# 定义损失函数和准确率列表
train_losses = [0.1, 0.08, 0.05, 0.03, 0.02]
train_accs = [90, 92, 95, 97, 98]# 绘制损失函数曲线
plt.plot(train_losses, label='Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()# 绘制准确率曲线
plt.plot(train_accs, label='Train Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
运行后会分别显示训练过程中的损失函数曲线和准确率曲线。我们可以根据自己的需要调整图表的样式和参数,例如修改线条颜色、线条宽度、坐标轴范围等。
六、tesorbrand显示图像
PyTorch下的Tensorboard 使用
七、用Pytorch写一个卷积神经网络
下面是一个简单的卷积神经网络(CNN)的实现,用PyTorch框架来训练MNIST手写数字识别数据集。
首先,您需要导入所需的库和模块,如下所示:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
接下来,您需要定义网络的架构。这个CNN有两个卷积层,一个最大池化层和两个全连接层。代码如下:
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 输入为28*28*1self.conv1 = nn.Conv2d(1, 10, kernel_size=5)# 输入为24*24*10self.conv2 = nn.Conv2d(10, 20, kernel_size=5)# 输入为20*20*20self.mp = nn.MaxPool2d(2)# 输入为10*10*20self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = F.relu(self.mp(self.conv1(x)))x = F.relu(self.mp(self.conv2(x)))x = x.view(-1, 320)x = F.relu(self.fc1(x))x = self.fc2(x)return F.log_softmax(x, dim=1)
现在,您需要定义训练函数和测试函数。训练函数将会用来训练模型,而测试函数将会用来测试模型。代码如下:
def train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))def test(model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += F.nll_loss(output, target, reduction='sum').item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
接下来,您需要加载数据集和定义训练和测试参数。代码如下:
batch_size = 64train_transforms = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])test_transforms = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])train_dataset = datasets.MNIST('./data', train=True, download=True, transform=train_transforms)
test_dataset = datasets.MNIST('./data', train=False, transform=test_transforms)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
最后,您需要在循环中训练和测试模型。代码如下:
epochs = 10for epoch in range(1, epochs + 1):train(model, device, train_loader, optimizer, epoch)test(model, device, test_loader)
这是一个简单的CNN的实现,用PyTorch训练MNIST数据集。您可以调整模型的超参数,例如学习率、动量等,来提高模型的准确性和性能。
八、用Pytorch写一个目标检测模型
下面是一个基于PyTorch的目标检测模型的实现,使用Faster R-CNN网络,并使用COCO数据集进行训练和测试。
首先,您需要导入所需的库和模块,如下所示:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.utils.data
import numpy as np
import matplotlib.pyplot as plt
import time
import os
import json
import torch.utils.data as data
from torchvision.datasets import CocoDetection
import torchvision.transforms.functional as F
import torch.nn as nn
import torch.optim as optim
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torchvision.models.detection.backbone_utils import resnet_fpn_backbone
from torchvision.ops import MultiScaleRoIAlign
接下来,您需要定义数据转换和数据集类,以加载和预处理COCO数据集。代码如下:
class Compose(object):def __init__(self, transforms):self.transforms = transformsdef __call__(self, img, target):for t in self.transforms:img, target = t(img, target)return img, targetclass RandomHorizontalFlip(object):def __init__(self, probability=0.5):self.probability = probabilitydef __call__(self, img, target):if np.random.rand() < self.probability:img = F.hflip(img)target["boxes"][:, [0, 2]] = img.width - target["boxes"][:, [2, 0]]return img, targetclass Resize(object):def __init__(self, max_size=900, min_size=600):self.max_size = max_sizeself.min_size = min_sizedef __call__(self, img, target):w, h = img.sizesize = self.min_sizeif w < h and max(h, w * size / w) <= self.max_size:size = int(w * size / w)elif max(h, w * size / h) <= self.max_size:size = int(h * size / h)img = F.resize(img, (size, size))target["boxes"][:, :4] *= size / self.min_sizereturn img, targetclass ToTensor(object):def __call__(self, img, target):img = F.to_tensor(img)return img, targetclass COCODataset(data.Dataset):def __init__(self, data_dir, set_name='train', transform=None):super().__init__()self.data_dir = data_dirself.images_dir = os.path.join(data_dir, set_name)self.set_name = set_nameself.transform = transformself.coco = CocoDetection(self.images_dir, os.path.join(data_dir, f'{set_name}.json'))def __getitem__(self, index):image, target = self.coco[index]image_id = self.coco.ids[index]if self.transform is not None:image, target = self.transform(image, target)return image, target, image_iddef __len__(self):return len(self.coco)
接下来,您需要定义模型的架构。这个Faster R-CNN网络使用ResNet-50 FPN作为骨干网络。代码如下:
class FasterRCNNResNetFPN(nn.Module):def __init__(self, num_classes):super(FasterRCNNResNetFPN, self).__init__()self.num_classes = num_classesbackbone = resnet_fpn_backbone('resnet50', pretrained=True)anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),aspect_ratios=((0.5, 1.0, 2.0),))roi_pooler = MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'],output_size=7,sampling_ratio=2)self.model = FasterRCNN(backbone,num_classes=num_classes + 1,rpn_anchor_generator=anchor_generator,box_roi_pool=roi_pooler)def forward(self, x, targets=None):if self.training and targets is None:raise ValueError("In training mode, targets should be passed")elif not self.training and targets is not None:raise ValueError("In inference mode, targets should not be passed")else:return self.model(x, targets)
现在,您需要设置训练和测试的超参数并进行模型训练。代码如下:
batch_size = 2
num_workers = 2
num_epochs = 10data_dir = '/path/to/coco'train_transforms = Compose([Resize(min_size=600, max_size=900),RandomHorizontalFlip(),ToTensor()])
test_transforms = Compose([Resize(min_size=800, max_size=1333),ToTensor()])train_dataset = COCODataset(data_dir, set_name='train', transform=train_transforms)
test_dataset = COCODataset(data_dir, set_name='val', transform=test_transforms)train_loader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, collate_fn=lambda x: tuple(zip(*x)))
test_loader = data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, collate_fn=lambda x: tuple(zip(*x)))num_classes = 80device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = FasterRCNNResNetFPN(num_classes=num_classes).to(device)optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)def train_one_epoch(model, optimizer, data_loader, device, epoch):model.train()train_loss = 0.0start_time = time.time()for step, (images, targets, image_ids) in enumerate(data_loader):images = [img.to(device) for img in images]targets = [{k: v.to(device) for k, v in t.items()} for t in targets]loss_dict = model(images, targets)losses = sum(loss_dict.values())train_loss += losses.item()optimizer.zero_grad()losses.backward()optimizer.step()if step % 10 == 0:print(f'Epoch: [{epoch}/{num_epochs}] Step: [{step}/{len(data_loader)}] Loss: {losses.item()}')train_loss /= len(data_loader)end_time = time.time()print(f'Training Loss: {train_loss} Time: {end_time - start_time}')def evaluate(model, data_loader, device):model.eval()results = []for images, targets, image_ids in data_loader:images = [img.to(device) for img in images]targets = [{k: v.to(device) for k, v in t.items()} for t in targets]with torch.no_grad():outputs = model(images)for i, (output, target) in enumerate(zip(outputs, targets)):result = {'image_id': image_ids[i],'boxes': output['boxes'].detach().cpu().numpy(),'scores': output['scores'].detach().cpu().numpy(),'labels': output['labels'].detach().cpu().numpy(),}target = {'image_id': image_ids[i],'boxes': target['boxes'].cpu().numpy(),'labels': target['labels'].cpu().numpy(),}results.append((result, target))return resultsfor epoch in range(num_epochs):train_one_epoch(model, optimizer, train_loader, device, epoch)results = evaluate(model, test_loader, device)
这是一个使用PyTorch实现的目标检测模型的示例,使用Faster R-CNN网络和COCO数据集进行训练和测试。您可以根据需要调整模型的超参数,以提高模型的准确性和性能。
相关文章:

【PyTorch】PyTorch、Cuda 的安装和使用
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、Anaconda 中安装 PyTorch 和 CUDA二、检查PyTorch和CUDA版本三、PyTorch的基本使用四、PyTorch调用cuda五、Matplotlib绘制Pytorch损…...
1.初识typescript
在很多地方的示例代码中使用的都是ts而不是js,为了使用那些示例,学习ts还是有必要的 JS有的TS都有,JS与TS的关系很像css与less ts在运行前需要先编译为js,浏览器不能直接运行ts 目录 1 编译TS的工具包 1.1 安装 1.2 基本…...

iPhone 6透明屏是什么?原理、特点、优势
iPhone 6透明屏是一种特殊的屏幕技术,它能够使手机屏幕变得透明,让用户能够透过屏幕看到手机背后的物体。 这种技术在科幻电影中经常出现,给人一种未来科技的感觉。下面将介绍iPhone 6透明屏的原理、特点以及可能的应用。 iPhone 6透明屏的原…...
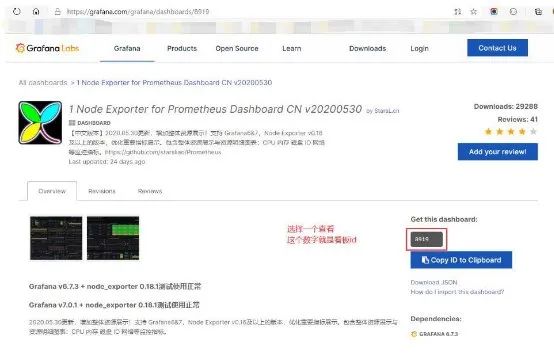
prometheus+grafana进行服务器资源监控
在性能测试中,服务器资源是值得关注一项内容,目前,市面上已经有很多的服务器资 源监控方法和各种不同的监控工具,方便在各个项目中使用。 但是,在性能测试中,究竟哪些指标值得被关注呢? 监控有…...
EventBus 开源库学习(三)
源码细节阅读 上一节根据EventBus的使用流程把实现源码大体梳理了一遍,因为精力有限,所以看源码都是根据实现过程把基本流程看下,中间实现细节先忽略,否则越看越深不容易把握大体思路,这节把一些细节的部分再看看。 …...
.map(Pb_zjzcy::getZjid).collect(Collectors.toList()); 解释一下)
zjzcyList.stream().map(Pb_zjzcy::getZjid).collect(Collectors.toList()); 解释一下
zjzcyList.stream().map(Pb_zjzcy::getZjid).collect(Collectors.toList()); 解释一下 这段代码是使用Java 8的流式处理(Stream)对一个存储了对象的列表(zjzcyList)进行操作,并最终返回一个包含了列表中每个对象的Zji…...

车载总线系列——J1939 二
车载总线系列——J1939 二 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 没有人关注你。也无需有人关注你。你必须承认自己的价值,你不能站…...

【C#学习笔记】引用类型(2)
文章目录 ObjectEqualsGetTypeToStringGetHashCode string逐字文本复合格式字符串字符串内插 StringBuilderStringBuilder 的工作原理StringBuilder提供的方法访问字符迭代字符查询字符 dynamic Object 支持 .NET 类层次结构中的所有类,并为派生类提供低级别服务。…...

【Rust 基础篇】Rust类函数宏:代码生成的魔法
导言 Rust是一门现代的、安全的系统级编程语言,它提供了丰富的元编程特性,其中类函数宏(Function-Like Macros)是其中之一。类函数宏允许开发者创建类似函数调用的宏,并在编译期间对代码进行生成和转换。在本篇博客中…...

Spring-1-透彻理解Spring XML的Bean创建--IOC
学习目标 上一篇文章我们介绍了什么是Spring,以及Spring的一些核心概念,并且快速快发一个Spring项目,实现IOC和DI,今天具体来讲解IOC 能够说出IOC的基础配置和Bean作用域 了解Bean的生命周期 能够说出Bean的实例化方式 一、Bean的基础配置 …...
【JAVA】类和对象
作者主页:paper jie的博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JAVASE语法系列》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精…...
jenkins准备
回到目录 jenkins是一个开源的、提供友好操作界面的持续集成(CI)工具,主要用于持续、自动的构建/测试软件项目、监控外部任务的运行。Jenkins用Java语言编写,可在Tomcat等流行的servlet容器中运行,也可独立运行。通常与版本管理工具(SCM)、构…...

【Rust】Rust学习
文档:Rust 程序设计语言 - Rust 程序设计语言 简体中文版 (bootcss.com) 墙裂推荐这个文档 第一章入门 入门指南 - Rust 程序设计语言 简体中文版 第二章猜猜看游戏 猜猜看游戏教程 - Rust 程序设计语言 简体中文版 (bootcss.com) // 导入库 use std::io; use s…...

Linux 常用命令之配置环境变量 PATH
PATH是系统环境变量中的一种,同时将一些二进制文件的绝对路径追加进去,则在系统终端中可以发现这些路径下的文件。 一. 环境变量设置 export PATH<二进制文件的绝对路径>:$PATH 以下为结合实际例子的操作 1、临时设置 打开一个终端执行如下命令 e…...
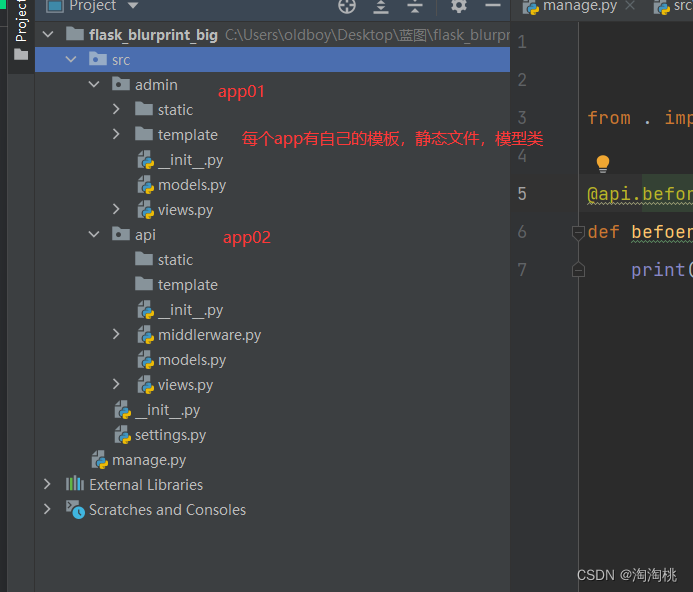
flask-----蓝图
1.引入蓝图 flask都写在一个文件中,项目这样肯定不行,会导致循环导入的问题,分目录,分包,使用蓝图划分目录。 2.使用蓝图 步骤如下: -1 实例化得到一个蓝图对象-order_blueBlueprint(order,__name__,tem…...

学习左耳听风栏目90天——第一天 1-90(学习左耳朵耗子的工匠精神,对技术的热爱)【洞悉技术的本质,享受科技的乐趣】
洞悉技术的本质,享受科技的乐趣 第一篇,我的感受就是 耗叔是一个热爱技术,可以通过代码找到快乐的技术人。 作为it从业者,我们如何可以通过代码找到快乐呢?这是一个问题? 至少目前,我还没有这种…...

后端登录安全的一种思路
PS:作者是小白能接触到的就只会这样写。勿喷。 前提 思路: 结合io流将登录token存储到配置文件中,不将token存储到浏览器端,从而避免盗取。 下面jwt的学习可以参考下这个: JWT --- 入门学习_本郡主是喵的博客-CSDN博客 JWT工具类 Component public class JWTtU…...

【深度学习_TensorFlow】激活函数
写在前面 上篇文章我们了解到感知机使用的阶跃函数和符号函数,它们都是非连续,导数为0的函数: 建议回顾上篇文章,本篇文章将介绍神经网络中的常见激活函数,这些函数都是平滑可导的,适合于梯度下降算法。 写…...

机器学习笔记之优化算法(七)线搜索方法(步长角度;非精确搜索;Wolfe Condition)
机器学习笔记之优化算法——线搜索方法[步长角度,非精确搜索,Wolfe Condition] 引言回顾: Armijo \text{Armijo} Armijo准则及其弊端 Glodstein \text{Glodstein} Glodstein准则及其弊端 Wolfe Condition \text{Wolfe Condition} Wolfe Condi…...
十四.redis哨兵模式
redis哨兵模式 1.概述2.测试3.哨兵模式优缺点 redis哨兵模式基础是主从复制 1.概述 主从切换的技术方法:当主节点服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费时费力,还会造成一段时间内服…...

Kimera-VIO实战评估:Euroc数据集上的精度分析与性能测试
Kimera-VIO实战评估:Euroc数据集上的精度分析与性能测试 【免费下载链接】Kimera-VIO Visual Inertial Odometry with SLAM capabilities and 3D Mesh generation. 项目地址: https://gitcode.com/gh_mirrors/ki/Kimera-VIO 想要了解开源视觉惯性里程计系统在…...

AI 编码循环验证关卡:结构背压比智能代理更优,Shen-Backpressure 来助力!
结构背压优于智能代理:用 Shen-Backpressure 为 AI 编码循环设验证关卡2026 年 5 月 18 日,一些最严重的软件漏洞往往不起眼,访问控制漏洞仍是 [OWASP 十大安全风险中的头号问题](https://owasp.org/Top10/2025/A01_2025-Broken_Access_Contr…...

视频修复终极指南:3步拯救你的损坏视频文件
视频修复终极指南:3步拯救你的损坏视频文件 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 你是否曾经遇到过这…...

AD导出Gerber文件时,单位选英寸格式选2:5?一文讲透这些‘祖传’设置背后的原因
为什么PCB工程师至今仍在使用英寸和2:5格式导出Gerber文件? 在PCB设计领域,有一个看似奇怪却普遍存在的现象:即使全球绝大多数国家采用公制单位,工程师们在导出Gerber文件时却坚持使用英制单位(英寸)&#…...

GD32 RISC-V BSP框架设计:从硬件抽象到跨平台移植实战
1. 项目概述:为什么我们需要一个专属的BSP框架?如果你正在使用GD32的RISC-V内核MCU,比如GD32VF103系列,并且是从STM32或者其他ARM Cortex-M平台转过来的,那你大概率踩过这样的坑:官方提供的固件库ÿ…...

别再只盯着IoU了!深入浅出聊聊边界框回归:从IoU到Shape-IoU的演进与选择
边界框回归的进化论:从IoU到Shape-IoU的技术跃迁与实战选型 当我们在计算机视觉领域谈论目标检测时,边界框回归就像是一场永不停歇的进化竞赛。从最初的IoU开始,这场竞赛已经经历了GIoU、DIoU、CIoU、SIoU等多个技术迭代,而最新登…...

PCB设计避坑指南:用ANSYS Designer快速评估耦合长度,别再盲目布线了
PCB设计避坑指南:用ANSYS Designer快速评估耦合长度,别再盲目布线了 高速PCB设计中,平行走线的耦合效应一直是工程师们头疼的问题。那些看似整齐的并行布线,往往在信号完整性测试时暴露出意想不到的串扰问题。我曾亲眼见过一个千兆…...

Go语言实现CI/CD流水线:从GitHub Actions到Argo CD的完整指南
Go语言实现CI/CD流水线:从GitHub Actions到Argo CD的完整指南 引言 CI/CD是现代软件开发的核心实践,Go语言项目可以通过各种CI/CD工具实现自动化构建、测试和部署。本文将深入探讨Go语言项目的CI/CD流水线实现,涵盖GitHub Actions、GitLab CI…...

CANN Triton排序选择算子优化
Sort/Select 算子优化 【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills 适用于需要迭代选择元素的算子:NMS、…...

ChipDNA PUF技术:从晶体管失配到硬件安全密钥的工程实践
1. 项目概述:当芯片拥有“DNA”,嵌入式安全进入新纪元在嵌入式系统设计领域,安全从来不是一个可以事后弥补的附加功能,而是必须从硬件层面开始构建的基石。随着物联网设备的爆炸式增长,从智能门锁到工业控制器…...