机器学习模型选择评估和超参数调优
如何选择模型?如何评估模型?如何调整模型的超参数?模型评估要在测试集上进行,不能在训练集上进行,否则评估的准确率总是100%。所以,一般我们准备好数据集后,要将其分为训练集和测试集,分配比例一般在5:5到8:2之间,即最多训练集80%,测试集20%。sklearn中有sklearn.model_selection.train_test_split方法来实现数据集的拆分。
一、如何选择一个合适的模型呢?
模型的选择需要考虑很多因素,比如模型的灵活度或复杂度(即模型支持的超参数),并不是越大越好,主要考虑的核心点在于模型的偏差和方差之间得到一个平衡点,偏差相当于模型预测的准确度,方差相当于模型在整个测试数据预测的稳定性或鲁棒性,一般来说,欠拟合就是训练集过少,导致预测准确度大(即偏差大,波动或方差小),过拟合就是训练集数据过多,过度学习了训练集的所有波动数据,导致预测准确度小(即偏差小,波动或方差大),两种情况都不好,两者的平衡点是最好的。
二、最常用的四种模型评估方法
1.一般的评估验证:将数据集拆分为训练集和测试集,在训练集上完成训练,形成模型,在测试集上进行预测, 进而评估模型的准确率,这样会带来两个问题,1个问题由于拆分比例的没有一个标准方法,导致模型有可能欠拟合或过拟合,1个问题是由于测试集数据的随机选择,有可能正好选择了一组适合该模型的预测数据,导致准确率偏高,或者出现相反情况。示例如下:
#加载花萼数据
from sklearn.datasets import load_iris
iris = load_iris()
import numpy as np
X = iris.data.astype(np.float32)
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=37,train_size=0.8) #8:2拆分,随机
knn = cv2.ml.KNearest_create()
knn.setDefaultK(1) #设置K近邻的数量为1
knn.train(X_train, cv2.ml.ROW_SAMPLE, y_train)
_, y_test_hat = knn.predict(X_test)
accuracy_score(y_test, y_test_hat) #96.7%2.K折交叉验证:相当于将N个数据集分为K折,每组相当于N/K个数据,后续将K-1个数据集用于训练了,另一个用于测试,优点是更高效的使用数据,通过多次迭代循环,得到更高的准确率。示例如下:
#加载花萼数据
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
X = iris.data.astype(np.float32)
y = iris.target
from sklearn.model_selection import train_test_split
#将数据分为两等分,各50%,相当于二折
X_fold1, X_fold2, y_fold1, y_fold2 = train_test_split(X, y, random_state=37, train_size=0.5)
#opencv方式
import cv2
knn = cv2.ml.KNearest_create()
knn.setDefaultK(1) #K=1
knn.train(X_fold1, cv2.ml.ROW_SAMPLE, y_fold1) #第一折训练
_, y_hat_fold2 = knn.predict(X_fold2) #第一折预测
knn.train(X_fold2, cv2.ml.ROW_SAMPLE, y_fold2) #第二折训练
_, y_hat_fold1 = knn.predict(X_fold1) #第二折预测
from sklearn.metrics import accuracy_score
accuracy_score(y_fold1, y_hat_fold1) #第一折评估
accuracy_score(y_fold2, y_hat_fold2) #第二折评估
#sklearn方式
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=1)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5) #cv指定折数,这里是5折,无需手动分割数据集,cross_val_score会根据折数自动分割。
scores.mean(), scores.std() #评估的平均值和标准差
#留一法交叉验证,这是交叉验证的一种特殊方法,相当于将K=N,在K或N次迭代中,留一个数据点进行测试验证评估,具体实现如下
from sklearn.model_selection import LeaveOneOut
scores = cross_val_score(model, X, y, cv=LeaveOneOut())
scores.mean(), scores.std()3.自举验证:用于评估模型的鲁棒性,示例如下:
#加载花萼数据
from sklearn.datasets import load_iris
iris = load_iris()
import numpy as np
X = iris.data.astype(np.float32)
y = iris.target
idx_boot = np.random.choice(len(X), size=len(X), replace=True) #随机以替换的方式选择N个样本
X_boot = X[idx_boot, :]
y_boot = y[idx_boot]
idx_oob = np.array([x not in idx_boot for x in np.arange(len(X))], dtype=np.bool)
X_oob = X[idx_oob, :]
y_oob = y[idx_oob]
knn = cv2.ml.KNearest_create()
knn.setDefaultK(1)
knn.train(X_boot, cv2.ml.ROW_SAMPLE, y_boot)
_, y_hat = knn.predict(X_oob)
accuracy_score(y_oob, y_hat)
acc=list(yield_bootstrap(knn, X, y, n_iter=10))
print(acc)
acc = list(yield_bootstrap(knn, X, y, n_iter=1000))#迭代1000次
np.mean(acc), np.std(acc)#迭代调用n_iter次的函数,实现模型训练预测和准确率评估
def yield_bootstrap(model, X, y, n_iter=10000):for _ in range(n_iter):# train the classifier on bootstrapidx_boot = np.random.choice(len(X), size=len(X),replace=True)X_boot = X[idx_boot, :]y_boot = y[idx_boot]model.train(X_boot, cv2.ml.ROW_SAMPLE, y_boot) # test classifier on out-of-bag examplesidx_oob = np.array([x not in idx_boot for x in np.arange(len(X))],dtype=np.bool)X_oob = X[idx_oob, :]y_oob = y[idx_oob]_, y_hat = model.predict(X_oob) # return accuracyyield accuracy_score(y_oob, y_hat)4.T检验
T检验测试确定两个数据样本是否来自于相同的平均值或期望值的潜在分布。示例如下:
#加载花萼数据
from sklearn.datasets import load_iris
iris = load_iris()
import numpy as np
X = iris.data.astype(np.float32)
y = iris.target
k1 = KNeighborsClassifier(n_neighbors=1)
scores_k1 = cross_val_score(k1, X, y, cv=10)
np.mean(scores_k1), np.std(scores_k1)
k3 = KNeighborsClassifier(n_neighbors=3)
scores_k3 = cross_val_score(k3, X, y, cv=10)
np.mean(scores_k3), np.std(scores_k3)
from scipy.stats import ttest_ind
ttest_ind(scores_k1, scores_k3)三、模型的超参数选择及调优
模型的参数调优一般采用网格搜索,网格搜索其实就是多个for循环嵌套调整,一般一个参数采用一个for循环,示例如下:
#加载花萼数据
from sklearn.datasets import load_iris
import numpy as np
iris = load_iris()
X = iris.data.astype(np.float32)
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=37)
best_acc = 0
best_k = 0
import cv2
from sklearn.metrics import accuracy_score
for k in range(1, 20):knn = cv2.ml.KNearest_create()knn.setDefaultK(k)knn.train(X_train, cv2.ml.ROW_SAMPLE, y_train)_, y_test_hat = knn.predict(X_test)acc = accuracy_score(y_test, y_test_hat)if acc > best_acc:best_acc = accbest_k = k
print(best_acc, best_k)
#训练集、验证集和测试集的拆分:在网格搜索过程中,如果将数据集还分为训练集和测试集,利用测试集来评估模型并更新超参数,就会出现将测试集信息暴漏给模型,导致评估不准确,因此需要将数据集拆分为训练集、验证集和测试集,训练集用于训练数据,验证集用于选择模型的最佳参数,测试集用于评估模型。
X_trainval, X_test, y_trainval, y_test = train_test_split(X, y, random_state=37) #数据集分为训练验证集和测试集
X_train, X_valid, y_train, y_valid = train_test_split(X_trainval, y_trainval, random_state=37)#训练验证集进一步分为训练集和验证集
best_acc = 0.0
best_k = 0
for k in range(1, 20):knn = cv2.ml.KNearest_create()knn.setDefaultK(k)knn.train(X_train, cv2.ml.ROW_SAMPLE, y_train) #在训练集训练模型_, y_valid_hat = knn.predict(X_valid) #在验证集上预测数据acc = accuracy_score(y_valid, y_valid_hat) #根据验证集预测数据情况评估准确率,不断更新最佳超参数if acc >= best_acc:best_acc = accbest_k = k
print(best_acc, best_k) #1.0,7knn = cv2.ml.KNearest_create()
knn.setDefaultK(best_k) #best_k=7,是前面迭代得到的最近k值
knn.train(X_trainval, cv2.ml.ROW_SAMPLE, y_trainval) #在训练验证集上重新训练模型
_, y_test_hat = knn.predict(X_test)
print(accuracy_score(y_test, y_test_hat))
print(best_k)
#网格搜索结合交叉验证实现超参数调优,利用sklearn提供的GridSearchCV类,实现在网格搜索中加入交叉验证机制
param_grid = {'n_neighbors': range(1, 20)} #搜索n_neighbors的最佳参数,范围1~19,多个其他参数也用类似方式设置
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_trainval, y_trainval) #在训练集训练模型
print(grid_search.best_score_, grid_search.best_params_) #获得最佳的验证得分和最佳超参数k值
print(grid_search.score(X_test, y_test)) #测试集上的评估四、利用管道Pipeline实现机器学习各步骤的连接
机器学习算法需要很多步骤,比如数据预处理、训练、预测、评估等步骤,而sklearn的Pipeline类本身就有fit、predict和score方法,因此他可以将分类器不同模型和处理步骤连接起来,相当于一个管道。示例如下:
#加载花萼数据
from sklearn.datasets import load_breast_cancer
import numpy as np
cancer = load_breast_cancer()
X = cancer.data.astype(np.float32)
y = cancer.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=37)
#采用SVM
from sklearn.svm import SVC
svm = SVC()
#svm.fit(X_train, y_train)
#svm.score(X_test, y_test)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
pipe = Pipeline([("scaler", MinMaxScaler()), ("svm", SVC())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)#结合sklearn的网格搜索
param_grid = {'svm__C': [0.001, 0.01, 0.1, 1, 10, 100],'svm__gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(pipe, param_grid=param_grid, cv=10)
grid.fit(X_train, y_train)
print(grid.best_score_)
print(grid.best_params_)
print(grid.score(X_test, y_test))五、模型的评估指标主要有那些
1.分类模型
1)准确率:就是前面各种示例关注的评估指标,测试集中预测正确的数据占比。
2)精确率:表示模型未将正样本预测为负的能力。
3)召回率:表示模型预测所有正样本的能力,还有一个F值=2*(精确率*召回率)/(精确率+召回率),相当于两者的调和均值。
2.回归模型
1)均方误差:预测值与真实值之间的平方误差,也是回归算法中经常用到的指标。
2)可解释方差:预测的方差或离散度。
3)R2值:无偏方差估计,详见sklearn.metrics.r2_score类,也是回归算法中经常用到的指标。
相关文章:

机器学习模型选择评估和超参数调优
如何选择模型?如何评估模型?如何调整模型的超参数?模型评估要在测试集上进行,不能在训练集上进行,否则评估的准确率总是100%。所以,一般我们准备好数据集后,要将其分为训练集和测试集࿰…...

深入浅出 Typescript
TypeScript 是 JavaScript 的一个超集,支持 ECMAScript 6 标准(ES6 教程)。 TypeScript 由微软开发的自由和开源的编程语言。 TypeScript 设计目标是开发大型应用,它可以编译成纯 JavaScript,编译出来的 JavaScript …...
Vue3和TypeScript项目-移动端兼容
1 全局安装typescript 2 检测安装成功 3 写的是ts代码,但是最后一定要变成js代码,才能在浏览器使用 这样就会多一个js文件 3 ts语法 数组语法 对象语法 安装vue3项目 成功后进入app。安装依赖。因为我们用的是脚手架,要引入东西的时候不需要…...
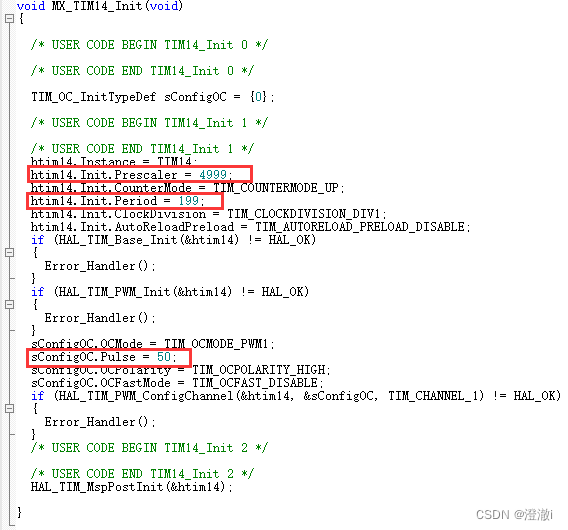
基于STM32CubeMX和keil采用通用定时器中断实现固定PWM可调PWM波输出分别实现LED闪烁与呼吸灯
文章目录 前言1. PWM波阐述2. 通用定时器2.1 为什么用TIM142.2 TIM14功能介绍2.3 一些配置参数解释2.4 PWM实现流程&中断2.4.1 非中断PWM输出(LED闪烁)2.4.2 中断PWM输出(LED呼吸灯) 3. STM32CubeMX配置3.1 GPIO配置3.2 时钟配置3.3 定时器相关参数配置3.4 Debug配置3.5 中…...
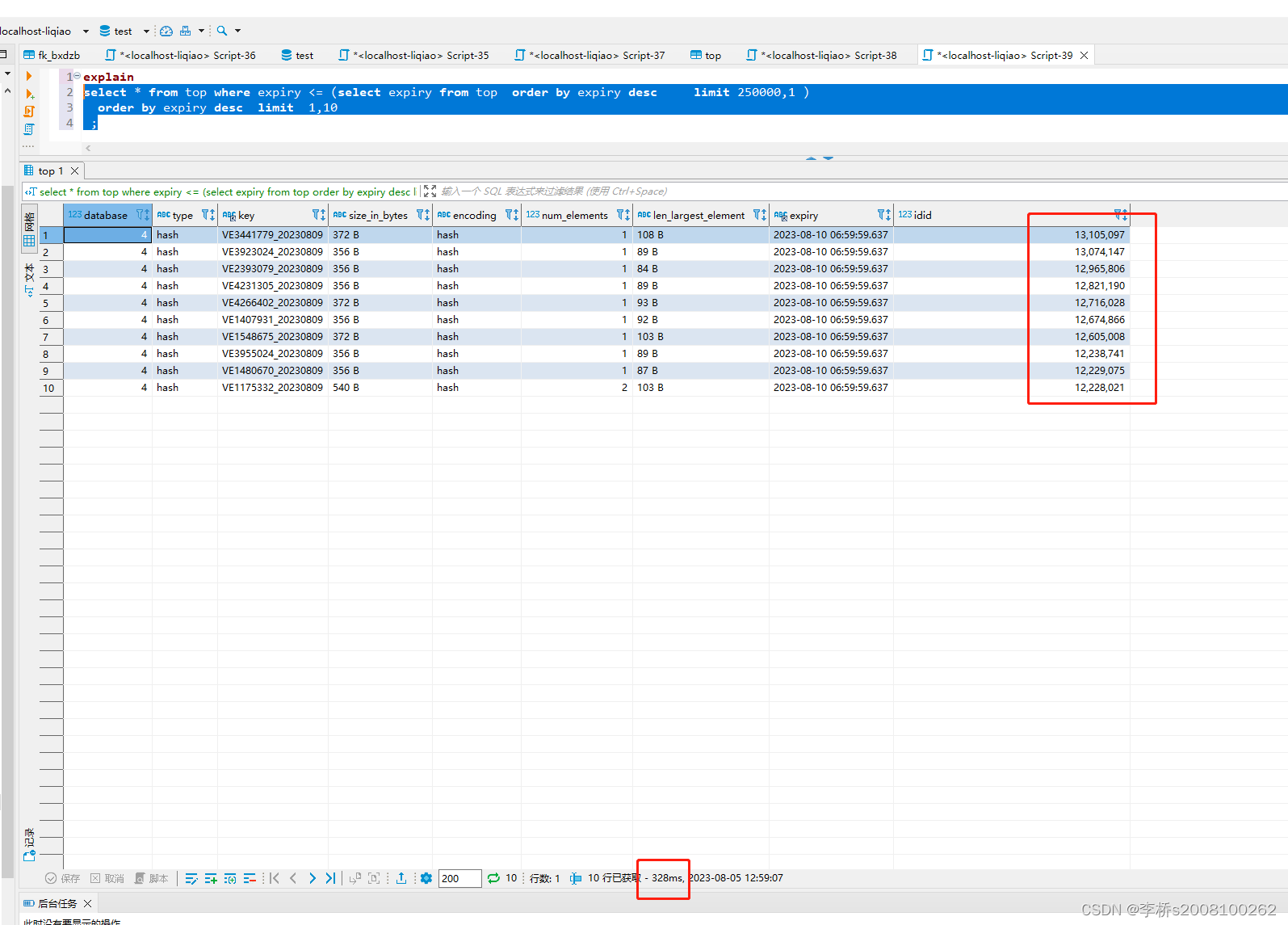
mysql大表的深度分页慢sql案例(跳页分页)
1 背景 有一张表,内容是 redis缓存中的key信息,数据量约1000万级, expiry列上有一个普通B树索引。 -- test.top definitionCREATE TABLE top (database int(11) DEFAULT NULL,type varchar(50) DEFAULT NULL,key varchar(500) DEFAULT NUL…...
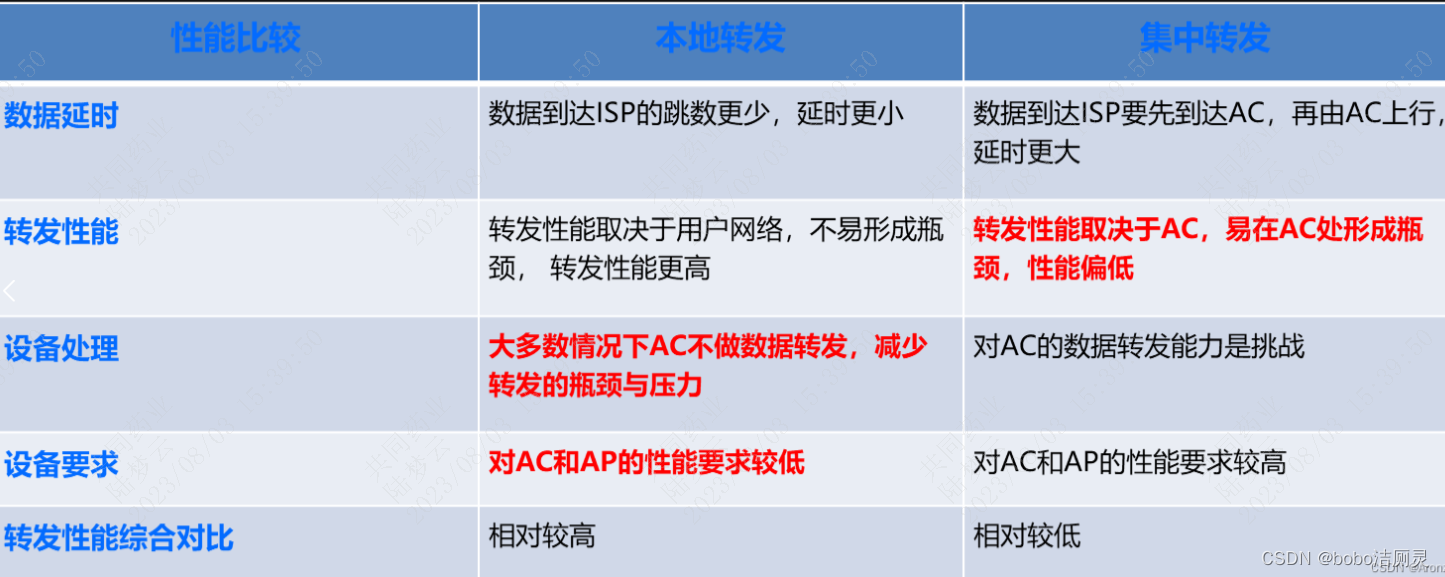
集中/本地转发、AC、AP
1.ADSL ADSL MODEM(ADSL 强制解调器)俗称ADSL猫 ADSL是一种异步传输模式(ATM)。ADSL是指使用电话线上网,需要专用的猫(Modem),在上网的时候高频和低频分离,所以上网电话两不耽误,速…...

Spring集成Seata
Seata的集成方式有: 1. Seata-All 2. Seata-Spring-Boot-Starter 3. Spring-Cloud-Starter-Seata 本案例使用Seata-All演示: 第一步:下载Seata 第二步:为了更好看到效果,我们将Seata的数据存储改为db 将seata\sc…...
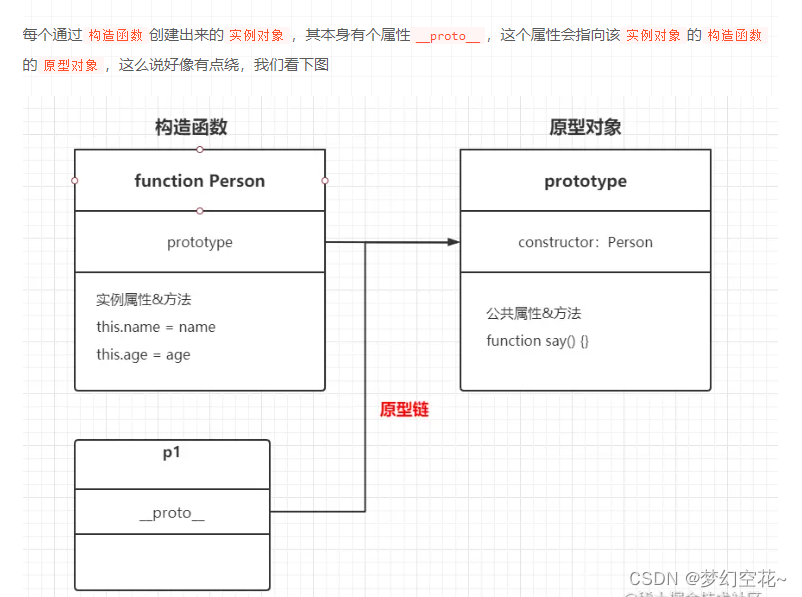
三种方式创建对象的几种方式及new实例化时做了什么?
创建对象的几种方式 利用对象字面量创建对象 const obj {}2.利用 new Object创建对象 const obj new Object()3.使用 构造函数实例化对象 function Fn(name) {this.name name} const obj new Fn(张三) console.log(obj.name); //张三为什么要用构造函数的形式࿱…...
vue2-vue实例挂载的过程
1、思考 new Vue()这个过程中究竟做了什么?过程中是如何完成数据的绑定,又是如何将数据渲染到视图的等等。 2、分析 首先找到vue的构造函数。 源码位置:/src/core/instance/index.js options是用户传递过来的配置项,如data、meth…...

C++ 右值引用案例
C 右值引用案例 右值引用(Rvalue reference)是 C11 引入的新特性,它的主要意义是实现移动语义(Move semantics)和完美转发(Perfect forwarding)。这两者都可以提高代码的性能和灵活性。 一、移…...

2.文件的逻辑结构
第四章 文件管理 2.文件的逻辑结构 顺序文件采用顺序存储则意味着各个逻辑上相邻的记录在物理上也是相邻的存储的。所以如果第0号记录的逻辑地址为0的话,则i号记录的逻辑为i *L。 特别的如果这个定长记录的顺序文件采用串结构,也就是这些记录的顺序和他…...
20天学rust(一)和rust say hi
关注我,学习Rust不迷路 工欲善其事,必先利其器。第一节我们先来配置rust需要的环境和安装趁手的工具,然后写一个简单的小程序。 安装 Rust环境 Rust 官方有提供一个叫做 rustup 的工具,专门用于 rust 版本的管理,网…...
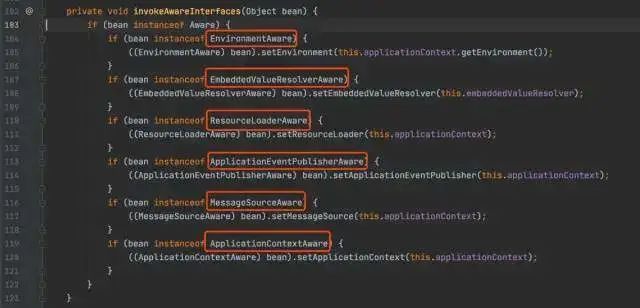
牢记这16个SpringBoot 扩展接口,写出更加漂亮的代码
1、背景 Spring的核心思想就是容器,当容器refresh的时候,外部看上去风平浪静,其实内部则是一片惊涛骇浪,汪洋一片。Springboot更是封装了Spring,遵循约定大于配置,加上自动装配的机制。很多时候我们只要引…...

c++两种设计模式 单例和工厂模式
c两种设计模式 单例和工厂模式 一.单例 1.单例的概念 1.当前的类最多只能创建一个实例 2.当前这个唯一的实例,必须由当前类创建(自主创建),而不是调用者创建 3.必须向整个系统提供全局的访问点,来获取唯一的实例 …...
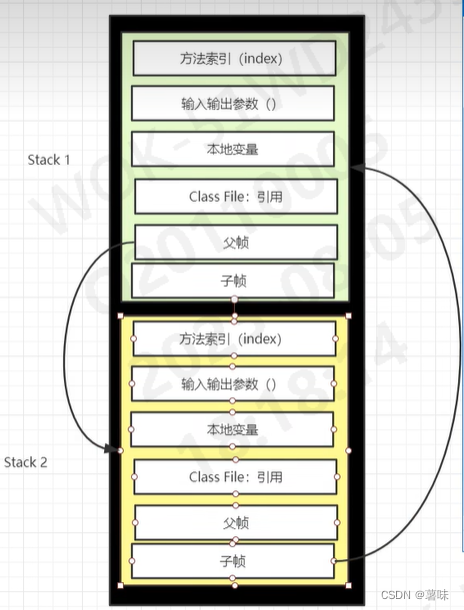
2023-08-05——JVM 栈
栈 stack 栈:数据结构 程序数据结构算法 栈:先进后出,后进先出 好比一个:桶 队列:先进先出(FIFO :First Input First Out) 好比一个:管道 栈:喝多了吐。队列…...

Camera之PhysicalCameraSettingsList/SurfaceMap/CameraMetadata/RequestList的关系(三十二)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生从来没有捷径,只有行动才是治疗恐惧和懒惰的唯一良药. 更多原创,欢迎关注:Android…...
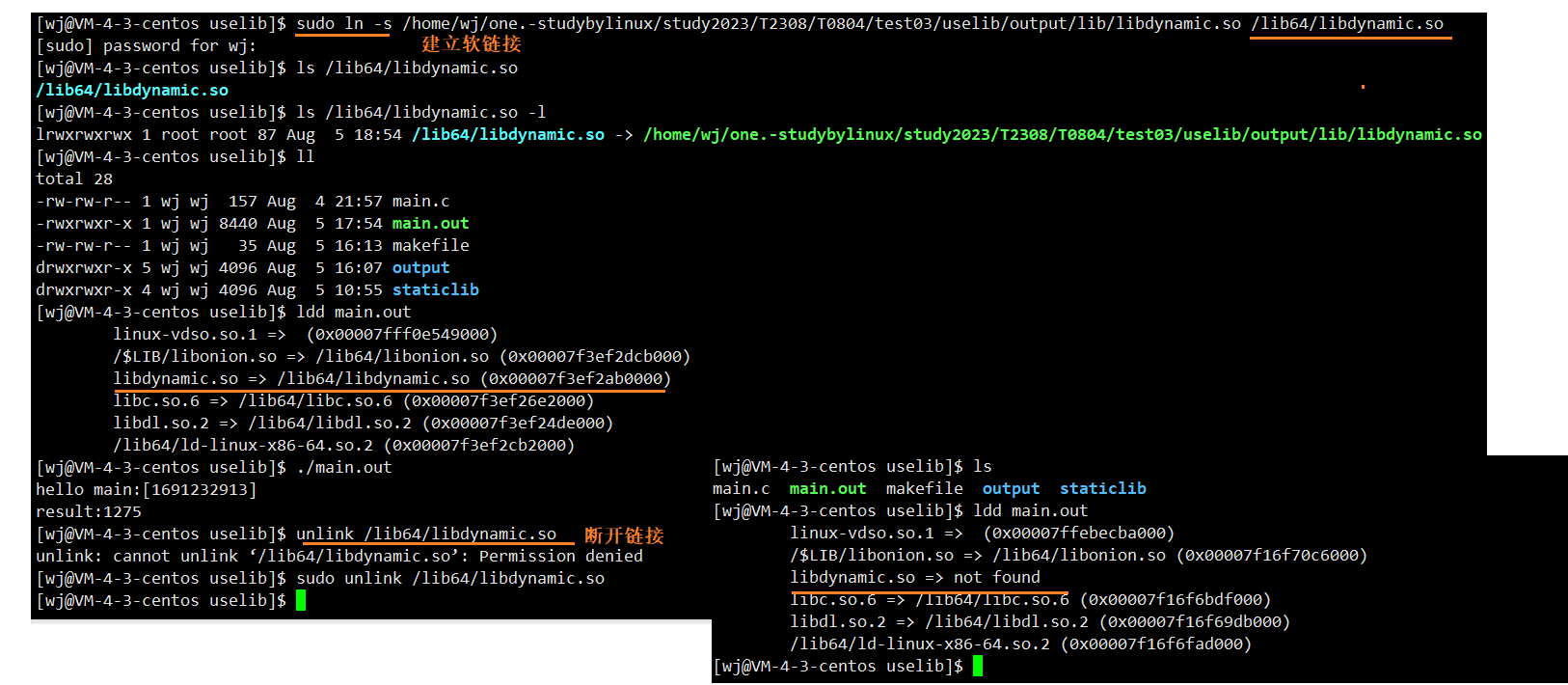
【ONE·Linux || 基础IO(二)】
总言 文件系统与动静态库相关介绍。 文章目录 总言2、文件系统2.1、背景知识2.2、磁盘管理2.2.1、磁盘文件系统图2.2.2、inode与文件名 2.3、软硬链接 3、动静态库3.1、站在编写库的人的角度:如何写一个库?3.1.1、静态库制作3.1.3、动态库制作 3.2、站在…...

【LeetCode 算法】Power of Heroes 英雄的力量
文章目录 Power of Heroes 英雄的力量问题描述:分析代码Math Tag Power of Heroes 英雄的力量 问题描述: 给你一个下标从 0 开始的整数数组 nums ,它表示英雄的能力值。如果我们选出一部分英雄,这组英雄的 力量 定义为ÿ…...

合宙Air724UG LuatOS-Air script lib API--ntp
ntp Table of Contents ntp ntp.timeSync(period, fnc, fun) ntp 模块功能:网络授时. 重要提醒!!!!!! 本功能模块采用多个免费公共的NTP服务器来同步时间 并不能保证任何时间任何地点都能百分…...
LangChain+ChatGLM大模型应用落地实践(一)
LLMs的落地框架(LangChain),给LLMs套上一层盔甲,快速构建自己的新一代人工智能产品。 一、简介二、LangChain源码三、租用云服务器实例四、部署实例 一、简介 LangChain是一个近期非常活跃的开源代码库,目前也还在快速…...

Android Studio中文插件终极指南:3分钟实现完整汉化体验
Android Studio中文插件终极指南:3分钟实现完整汉化体验 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Androi…...

3分钟让通达信自动画缠论中枢:告别复杂手动画线
3分钟让通达信自动画缠论中枢:告别复杂手动画线 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 还在为缠论分析中的手动画线、笔段划分、中枢识别而烦恼吗?ChanlunX缠论插件为你带…...

为什么英语是编程最重要的前置技能?Newbie-Guideline揭示成功秘诀
为什么英语是编程最重要的前置技能?Newbie-Guideline揭示成功秘诀 【免费下载链接】Newbie-Guideline 컴퓨터과학/공학 신입생 및 비전공자 신입을 위한 지침서 项目地址: https://gitcode.com/gh_mirrors/ne/Newbie-Guideline 在编程学习的道路上࿰…...

ESP32任务阻塞导致看门狗报错?手把手教你用menuconfig调整超时时间
ESP32任务看门狗超时问题全解析:从原理到menuconfig实战配置 在ESP32开发过程中,许多开发者都遇到过那个令人头疼的报错:"Task watchdog got triggered"。这个看似简单的错误背后,其实隐藏着实时操作系统任务调度的核心…...

人工智能术语库:2442个专业AI词汇一站式查询指南
人工智能术语库:2442个专业AI词汇一站式查询指南 【免费下载链接】Artificial-Intelligence-Terminology-Database A comprehensive mapping database of English to Chinese technical vocabulary in the artificial intelligence domain 项目地址: https://gitc…...

极限竞速涂装转换神器:Forza Painter终极免费指南
极限竞速涂装转换神器:Forza Painter终极免费指南 【免费下载链接】forza-painter Import images into Forza 项目地址: https://gitcode.com/gh_mirrors/fo/forza-painter 还在为《极限竞速:地平线》中的车辆涂装设计而苦恼吗?想要将…...

创业团队如何利用Taotoken以可控成本快速上线AI功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken以可控成本快速上线AI功能 对于资源有限的创业团队而言,为产品快速集成AI能力是提升竞争力的…...

Linux内核hrtimer高精度定时器深度解析与驱动开发实战
1. 项目概述与核心价值在Linux内核驱动开发中,定时器是一个再基础不过的组件。从早期的timer_list到如今的高精度定时器hrtimer,内核为我们提供了越来越精细的时间控制能力。今天,我们不谈那些老生常谈的基础用法,而是深入内核源码…...
)
保姆级教程:用阿莫K202C-1烧录器搞定国产MCU(GD32/N32/APM32等)
国产MCU高效烧录实战:K202C-1脱机烧录器深度应用指南 1. 国产MCU崛起背景与烧录需求 近年来,国产MCU厂商如GD32、N32、APM32等品牌迅速崛起,凭借性价比优势在工业控制、消费电子等领域逐步替代进口芯片。根据行业调研数据,2023年国…...

蓝桥杯JavaB组赛后复盘:从‘类斐波那契’到‘星际旅行’,我的解题思路与踩坑实录
蓝桥杯JavaB组赛后复盘:从‘类斐波那契’到‘星际旅行’,我的解题思路与踩坑实录 1. 考场策略与时间分配 比赛开始前15分钟,我快速浏览了所有题目,用铅笔在草稿纸上标注了每道题的预估难度和解题方向。这种策略让我避免了"死…...