Python 文件操作详解
概要
Python进行文件操作,在日常编程中是很常用的。为了方便大家,这里对各种文件操作的知识进行汇总。一文在手,无须它求!来一起学习吧。
一、文件的打开和关闭
open()函数
f1 = open(r'd:\测试文件.txt', mode='r', encoding='utf-8')
content = f1.read()
print(content)
f1.close()
with open(r'd:\测试文件.txt', mode='r', encoding='utf-8') as f1:content = f1.read()print(content)
1.open()内置函数,open底层调用的是操作系统的接口。
2.f1变量,又叫文件句柄,通常文件句柄命名有f1,fh,file_handler,f_h,对文件进行的任何操作,都得通过文件句柄.方法的形式。
3.encoding:可以不写。不写参数,默认的编码本是操作系统默认的编码本。windows默认gbk,linux默认utf-8,mac默认utf-8。
4.mode:可以不写。默认mode='r'。
5.f1.close()关闭文件句柄。
6.使用with open()的好处。
优点1:不用手动关闭文件句柄。
with open('文件操作的读', encoding='utf-8') as f1:print(f1.read())优点2:一个语句可以操作多个文件句柄。
with open('文件操作的读', encoding='utf-8') as f1, \open('文件操作的写', encoding='utf-8', mode='w') as f2:print(f1.read())f2.write('hahaha')
绝对路径和相对路径
1.绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。比如:C:/Users/chris/AppData/Local/Programs/Python/Python37/python.exe
2.相对路径:是从当前文件所在的文件夹开始的路径。
-
test.txt:是在当前文件夹查找 test.txt 文件。
-
./test.txt:也是在当前文件夹里查找test.txt文件, ./ 表示的是当前文件夹,可以省略。
-
../test.txt:从当前文件夹的上一级文件夹里查找 test.txt 文件。../ 表示的是上一级文件夹。
-
demo/test.txt,在当前文件夹里查找demo这个文件夹,并在这个文件夹里查找 test.txt文件。
3.路径书写的三种方式
-
\file = open('C:\Users\chris\Desktop\Python基础\xxx.txt')
-
r''file = open(r'C:\Users\chris\Desktop\Python基础\xxx.txt')
-
'/'(推荐)file = open('C:/Users/chris/Desktop/Python基础/xxx.txt')
常用文件的访问模式
1.打开文件的模式有(默认为文本模式):
r 只读模式【默认模式,文件必须存在,不存在则抛出异常】
w 只写模式【不可读;不存在则创建;存在则清空内容在写入】
a 只追加写模式【不可读;不存在则创建;存在则只追加内容】
2.对于非文本文件,我们只能使用b模式。
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码。
rb 以二进制读取
wb 以二进制写入
ab 以二进制追加
3.‘+’模式(就是增加了一个功能)
r+ 读写【可读,可写】
w+ 写读【可写,可读】
a+ 写读【可写,可读】
4.以bytes类型操作的读写,写读,写读模式
r+b 读写【可读,可写】
w+b 写读【可写,可读】
a+b 写读【可写,可读】
5.关于r+模式:打开一个文件用于读写,文件指针默认将会放在文件的开头。
注意:如果在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会将原内容覆盖掉,直到覆盖到你写完的内容,然后在从后面开始读取。
# 文件'其他模式'中的内容是:王副班最帅# 1. 先读后写
f1 = open('其他模式', encoding='utf-8', mode='r+')
content = f1.read()
print(content)
f1.write('王强强')
f1.close()3 2. 先写后读(错误实例)
f1 = open('其他模式', encoding='utf-8', mode='r+')
f1.write('王强强')
content = f1.read()
print(content) # 最帅
f1.close()
二、文件的读取和写入
读取
代码中用到的文件文件操作的读.txt 文件内容如下:
lucy最帅
lucy很励志
abcdef
哈哈哈
read() 全部读取出来。用rb模式打开,不用写encoding
f1 = open('文件操作的读', encoding='utf-8')
content = f1.read()
print(content, type(content))
f1.close()f1 = open(r'C:\Users\lenovo\Desktop\编码进阶.png', mode='rb')
content = f1.read()
print(content)
f1.close()
read(n) 按照字符读取(r模式),按照字节读取(rb模式)。
f1 = open('文件操作的读', encoding='utf-8')
content = f1.read(6)
print(content) # lucy最帅
f1.close()
readline() 读取一行。
f1 = open('文件操作的读', encoding='utf-8')
print(f1.readline().strip()) # lucy最帅
print(f1.readline()) # lucy很励志\n
f1.close()
readlines() 返回一个列表,列表中的每个元素是原文件的每一行。如果文件很大,占内存,容易崩盘。
f1 = open('文件操作的读', encoding='utf-8')
li = f1.readlines()
print(li) # ['lucy最帅\n', 'lucy很励志\n', 'abcdef\n', '哈哈哈']
f1.close()
for 循环读取。文件句柄是一个迭代器。特点是每次循环只在内存中占一行的数据,非常节省内存。
f1 = open('文件操作的读', encoding='utf-8')
for line in f1:print(line.strip())
f1.close()
写入
模式
没有文件,则创建文件,写入内容;如果文件存在,先清空原文件内容,在写入新内容。
f1 = open('文件操作的写', encoding='utf-8', mode='w')
f1.write('lucy真帅')
f1.close()
wb模式
f1 = open(r'C:\Users\lenovo\Desktop\编码进阶.png', mode='rb')
content = f1.read()
f1.close()f2 = open('图片.jpg', mode='wb')
f2.write(content)
f2.close()
关于清空
关闭文件句柄,再次以w模式打开此文件时,才会清空。
指针定位
tell() 方法用来显示当前指针的位置。
f = open('test.txt')
print(f.read(10)) # read 指定读取的字节数
print(f.tell()) # tell()方法显示当前文件指针所在的文字
f.close()
seek(offset,whence)方法用来重新设定指针的位置。
-
offset:表示偏移量
-
whence:只能传入012中的一个数字。
-
0表示从文件头开始
-
1表示从当前位置开始
-
2 表示从文件的末尾开始
-
f = open('test.txt','rb') # 需要指定打开模式为rb,只读二进制模式print(f.read(3))
print(f.tell())f.seek(2,0) # 从文件的开头开始,跳过两个字节
print(f.read())f.seek(1,1) # 从当前位置开始,跳过一个字节
print(f.read())f.seek(-4,2) # 从文件末尾开始,往前跳过四个字节
print(f.read())f.close()
三、实现文件拷贝功能
import osfile_name = input('请输入一个文件路径:')
if os.path.isfile(file_name):old_file = open(file_name, 'rb') # 以二进制的形式读取文件names = os.path.splitext(file_name)new_file_name = names[0] + '.bak' + names[1]new_file = open(new_file_name, 'wb') # 以二进制的形式写入文件while True:content = old_file.read(1024) # 读取出来的内容是二进制new_file.write(content)if not content:breaknew_file.close()old_file.close()
else:print('您输入的文件不存在')
四、CSV文件的读写
CSV文件
CSV文件:Comma-Separated Values,中文叫逗号分隔值或者字符分割值,其文件以纯文本的形式存储表格数据。可以把它理解为一个表格,只不过这个表格是以纯文本的形式显示的,单元格与单元格之间,默认使用逗号进行分隔;每行数据之间,使用换行进行分隔。
name,age,score
zhangsan,18,98
lisi,20,99
wangwu,17,90
jerry,19,95
Python中的csv模块,提供了相应的函数,可以让我们很方便的读写csv文件。
CSV文件的写入
import csv# 以写入方式打开一个csv文件
file = open('test.csv','w')# 调用writer方法,传入csv文件对象,得到的结果是一个CSVWriter对象
writer = csv.writer(file)# 调用CSVWriter对象的writerow方法,一行行的写入数据
writer.writerow(['name', 'age', 'score'])# 还可以调用writerows方法,一次性写入多行数据
writer.writerows([['zhangsan', '18', '98'],['lisi', '20', '99'], ['wangwu', '17', '90'], ['jerry', '19', '95']])
file.close()
CSV文件的读取
import csv# 以读取方式打开一个csv文件
file = open('test.csv', 'r')# 调用csv模块的reader方法,得到的结果是一个可迭代对象
reader = csv.reader(file)# 对结果进行遍历,获取到结果里的每一行数据
for row in reader:print(row)file.close()
五、将数据写入内存
除了将数据写入到一个文件以外,我们还可以使用代码,将数据暂时写入到内存里,可以理解为数据缓冲区。Python中提供了StringIO和BytesIO这两个类将字符串数据和二进制数据写入到内存里。
StringIO
StringIO可以将字符串写入到内存中,像操作文件一下操作字符串。
from io import StringIO# 创建一个StringIO对象
f = StringIO()
# 可以像操作文件一下,将字符串写入到内存中
f.write('hello\r\n')
f.write('good')# 使用文件的 readline和readlines方法,无法读取到数据
# print(f.readline())
# print(f.readlines())# 需要调用getvalue()方法才能获取到写入到内存中的数据
print(f.getvalue())f.close()
Copy
BytesIO
如果想要以二进制的形式写入数据,可以使用BytesIO类,它的用法和StringIO相似,只不过在调用write方法写入时,需要传入二进制数据。
from io import BytesIOf = BytesIO()
f.write('你好\r\n'.encode('utf-8'))
f.write('中国'.encode('utf-8'))print(f.getvalue())
f.close()
六、sys模块的使用
sys.stdin 接收用户的输入,就是读取键盘里输入的数据,默认是控制台。input方法就是读取 sys.stdin 里的数据。
import sys
s_in = sys.stdin
while True:content = s_in.readline().rstrip('\n')if content == '':breakprint(content)
sys.stdout 标准输出,默认是控制台
import sys
m = open('stdout.txt', 'w', encoding='utf8')
sys.stdout = m
print('hello')
print('yes')
print('good')
m.close()
运行结果:生成一个stdout.txt文件,文件内容如下:
hello
yes
good
sys.stderr 错误输出,默认是控制台
import sys
x = open('stderr.txt', 'w', encoding='utf8')
sys.stderr = x
print(1 / 0)
x.close()
运行结果:生成一个stderr.txt文件,文件内容如下:
Traceback (most recent call last):File "E:/python基础/demo.py", line 4, in <module>print(1 / 0)
ZeroDivisionError: division by zero
七、序列化和反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
-
序列化:将数据从内存持久化保存到硬盘的过程
-
反序列化:将数据从硬盘加载到内存的过程
python 里存入数据只支持存入字符串和二进制
-
json:将Python里的数据(str/list/tuple/dict/int/float/bool/None)等转换成为对应的json
-
pickle:将Python里任意的对象转换成为二进制
Python中提供了JSON和pickle两个模块用来实现数据的序列化和反序列化。
JSON模块
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换格式,它基于 ECMAScript 的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。JSON的本质是字符串,区别在于json里要是用双引号表示字符串。
使用JSON实现序列化
1、dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# file.write(names) 出错,不能直接将列表写入到文件里# 可以调用 json的dumps方法,传入一个对象参数
result = json.dumps(names)# dumps 方法得到的结果是一个字符串
print(type(result)) # <class 'str'># 可以将字符串写入到文件里
file.write(result)file.close()
2、dump方法可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里。
import jsonfile = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']# dump方法可以接收一个文件参数,在将对象转换成为字符串的同时写入到文件里
json.dump(names, file)
file.close()使用JSON实现反序列化
1、loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。
使用JSON实现反序列化
1、loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。
import json
# 调用loads方法,传入一个字符串,可以将这个字符串加载成为Python对象
result = json.loads('["zhangsan", "lisi", "wangwu", "jerry", "henry", "merry", "chris"]')
print(type(result)) # <class 'list'>
2、load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象。
import json# 以可读方式打开一个文件
file = open('names.txt', 'r')# 调用load方法,将文件里的内容加载成为一个Python对象
result = json.load(file)print(result)
file.close()
pickle模块
和json模块类似,pickle模块也有dump和dumps方法可以对数据进行序列化,同时也有load和loads方法进行反序列化。区别在于,json模块是将对象转换成为字符串,而pickle模块是将对象转换成为二进制。
pickle模块里方法的使用和json里方法的使用大致相同,需要注意的是,pickle是将对象转换成为二进制,所以,如果想要把内容写入到文件里,这个文件必须要以二进制的形式打开。
使用pickle模块实现序列号
1、dumps方法将Python数据转换成为二进制
import pickle
names = ['张三', '李四', '杰克', '亨利']
b_names = pickle.dumps(names)
# print(b_names)
file = open('names.txt', 'wb')
file.write(b_names) # 写入的是二进制,不是存文本
file.close()
2、dump方法将Python数据转换成为二进制,同时保存到指定文件
import pickle
names = ['张三', '李四', '杰克', '亨利']
file2 = open('names.txt', 'wb')
pickle.dump(names, file2)
file2.close()
使用pickle模块实现反序列号
1、loads方法,将二进制加载成为Python数据
import pickle
file1 = open('names.txt', 'rb')
x = file1.read()
y = pickle.loads(x)
print(y)
file1.close()
2、load方法,读取文件,并将文件的二进制内容加载成为Python数据
import pickle
file3 = open('names.txt', 'rb')
z = pickle.load(file3)
print(z)
JSON与pickle区别
json模块:
-
将对象转换成为字符串,不管是在哪种操作系统,哪种编程语言里,字符串都是可识别的。
-
json就是用来在不同平台间传递数据的。
-
并不是所有的对象都可以直接转换成为一个字符串,下标列出了Python对象与json字符串的对应关系。
Python JSON dict object list,tuple array str string int,float number True true False false None null -
如果是一个自定义对象,默认无法装换成为json字符串,需要手动指定JSONEncoder.
-
如果是将一个json串重新转换成为对象,这个对象里的方法就无法使用了。
import json
class MyEncode(json.JSONEncoder):def default(self, o):# return {"name":o.name,"age":o.age}return o.__dict__class Person(object):def __init__(self, name, age):self.name = nameself.age = agedef eat(self):print(self.name+'正在吃东西')p1 = Person('zhangsan', 18)# 自定义对象想要转换成为json字符串,需要给这个自定义对象指定JSONEncoder
result = json.dumps(p1, cls=MyEncode)
print(result) # {"name": "zhangsan", "age": 18}# 调用loads方法将对象加载成为一个对象以后,得到的结果是一个字典
p = json.loads(result)
print(type(p))
pickle模块:
-
pickle序列化是将对象按照一定的规则转换成为二进制保存,它不能跨平台传递数据。
-
pickle的序列化会将对象的所有数据都保存。
今天的分享到这里,如5果的文章对你有所帮助欢迎点赞收藏转发,感谢🙏!
相关文章:

Python 文件操作详解
概要 Python进行文件操作,在日常编程中是很常用的。为了方便大家,这里对各种文件操作的知识进行汇总。一文在手,无须它求!来一起学习吧。 一、文件的打开和关闭 open()函数 f1 open(rd:\测试文件.txt, moder, encodingutf-8) c…...

【Rust 基础篇】Rust Never类型:表示不会返回的类型
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。在Rust中,Never类型是一种特殊的类型,它表示一个函数永远不会返回。Never类型在Rust中有着重要的应用场…...

error “Component name “*****“ should always be multi-word”解决方案
问题 在 vue-cli 创建的项目中,创建文件并命名后,会报 “Component name "*****" should always be multi-word” 报错; Component name "index" should always be multi-word.eslintvue/multi-word-component-names原…...

前后端开发的区别是什么?
VUE的开发方式为什么和后端的MVC开发方式不一样呢? 实际上,Vue 和后端开发的 MVC(Model-View-Controller)方式是不同的,因为它们面对的问题和场景也不同。 前端与后端的职责不同: 前端和后端的职责和任务不…...
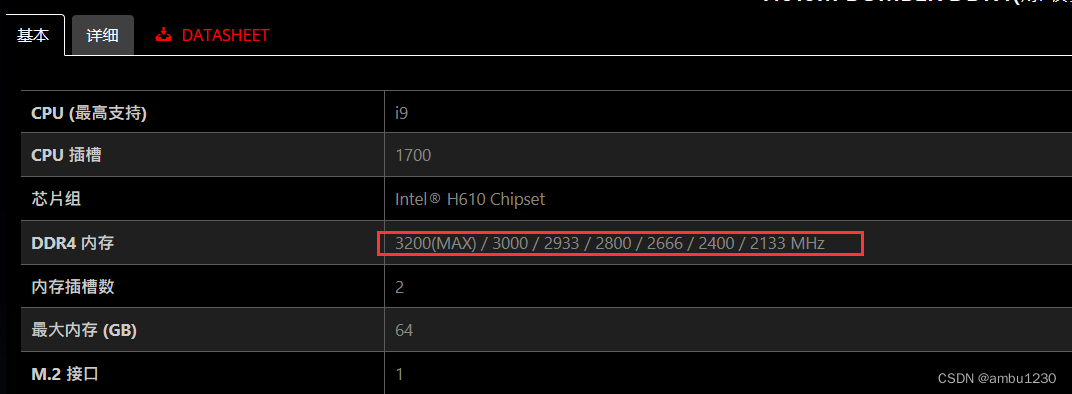
小白电脑装机(自用)
几个月前买了配件想自己装电脑,结果最后无法成功点亮,出现的问题是主板上的DebugLED黄灯常亮,即DRAM灯亮。对于微星主板的Debug灯,其含义这篇博文中有说明。 根据另一篇博文,有两种可能。 我这边曾将内存条和主板一块…...

Quic协议 0-RTT
目录 1、Quic协议 2、Quic直接通过TLS握手进行建立链接,TLS是1.3版本 3.1、通过缓存服务器公钥实现0-RTT,服务器 通过kdf密钥派生机制,来产生会话加密key,保证数据向前安全性 3.2、通过PKN来实现数据重传保证数据完整性&…...

在排序数组中查找元素的第一个和最后一个位置——力扣34
文章目录 题目描述法一 二分查找题目描述 法一 二分查找 int bsearch_1(int l, int r) {while (l < r)<...

python列表处理方法
原始文件: id start end a1 10 19 a1 25 34 a2 89 124 a2 149 167 a2 188 221目的文件: a1 1 10 a1 16 25 a2 1 36 a2 61 79 a2 100 133解释说明: 原始文件是gff3文件的一部分,第一列id是基因的名字,第二列和第三列分…...

【Java】快速入门JVM
文章目录 1. JVM简介2. 类加载简介3. 类加载的过程4. 双亲委派5. GC垃圾回收6. JVM的回收方式7. 分代回收 1. JVM简介 JVM(Java虚拟机)是一个名字为Java的进程,是用于执行Java程序的虚拟机。 JVM会从操作系统中申请一大块内存空间,又把这个内存空间划分…...

C#之Winfrom自定义输入框对话框。
如果你需要一个带有输入框的对话框,并在输入完成后接收输入的值,你可以使用自定义窗体来实现。以下是一个示例代码:创建一个继承自 Form 的自定义窗体类,命名为 InputDialogForm,并将窗体上放置一个文本框(…...

docker制作镜像
docker制作镜像 docker制作镜像有两种: 1.docker build dockerfile 2.基于容器制作镜像 基于容器制作镜像 语法:docker commit options 容器名称 参数: -a:作者 -c:修改dockfile创建的镜像 -m:提交…...

广西茶叶元宇宙 武隆以茶为媒 推动茶文旅产业融合发展
8月4日,重庆市武隆区启动为期3天的“武隆首届玩茶荟”。本次活动以“中国最美玩茶地——武隆”为主题,吸引众多国内知名专家、茶企和茶馆相关负责人,共同探索武隆茶文旅融合发展新路径和新业态。 广西茶叶元宇宙:广西茶叶元宇宙 …...

alibaba.excel库使用
目录 依赖 实体类 Controller Service 所用到的接口及工具类 ExcelUtil ExcelListener DefaultExcelListener DefaultExcelResult ExcelResult JsonUtils SpringUtils StreamUtils ValidatorUtils SpringUtils 使用alibab中的excel库来实现excel的导入、导出 依赖 <de…...

机器学习模型选择评估和超参数调优
如何选择模型?如何评估模型?如何调整模型的超参数?模型评估要在测试集上进行,不能在训练集上进行,否则评估的准确率总是100%。所以,一般我们准备好数据集后,要将其分为训练集和测试集࿰…...

深入浅出 Typescript
TypeScript 是 JavaScript 的一个超集,支持 ECMAScript 6 标准(ES6 教程)。 TypeScript 由微软开发的自由和开源的编程语言。 TypeScript 设计目标是开发大型应用,它可以编译成纯 JavaScript,编译出来的 JavaScript …...
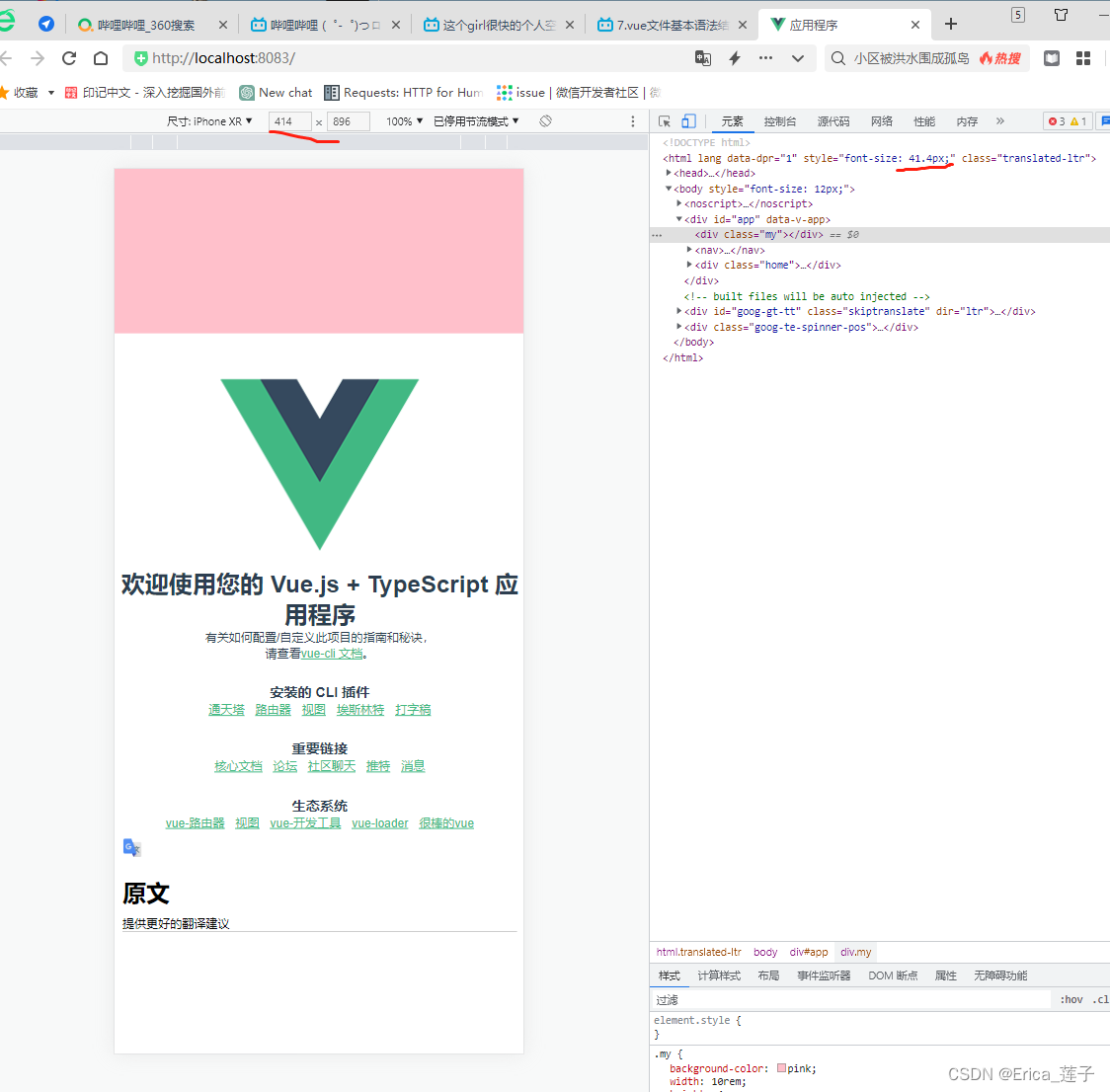
Vue3和TypeScript项目-移动端兼容
1 全局安装typescript 2 检测安装成功 3 写的是ts代码,但是最后一定要变成js代码,才能在浏览器使用 这样就会多一个js文件 3 ts语法 数组语法 对象语法 安装vue3项目 成功后进入app。安装依赖。因为我们用的是脚手架,要引入东西的时候不需要…...
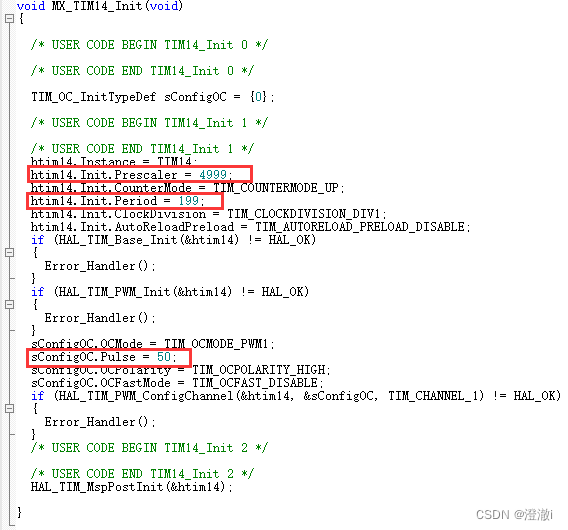
基于STM32CubeMX和keil采用通用定时器中断实现固定PWM可调PWM波输出分别实现LED闪烁与呼吸灯
文章目录 前言1. PWM波阐述2. 通用定时器2.1 为什么用TIM142.2 TIM14功能介绍2.3 一些配置参数解释2.4 PWM实现流程&中断2.4.1 非中断PWM输出(LED闪烁)2.4.2 中断PWM输出(LED呼吸灯) 3. STM32CubeMX配置3.1 GPIO配置3.2 时钟配置3.3 定时器相关参数配置3.4 Debug配置3.5 中…...
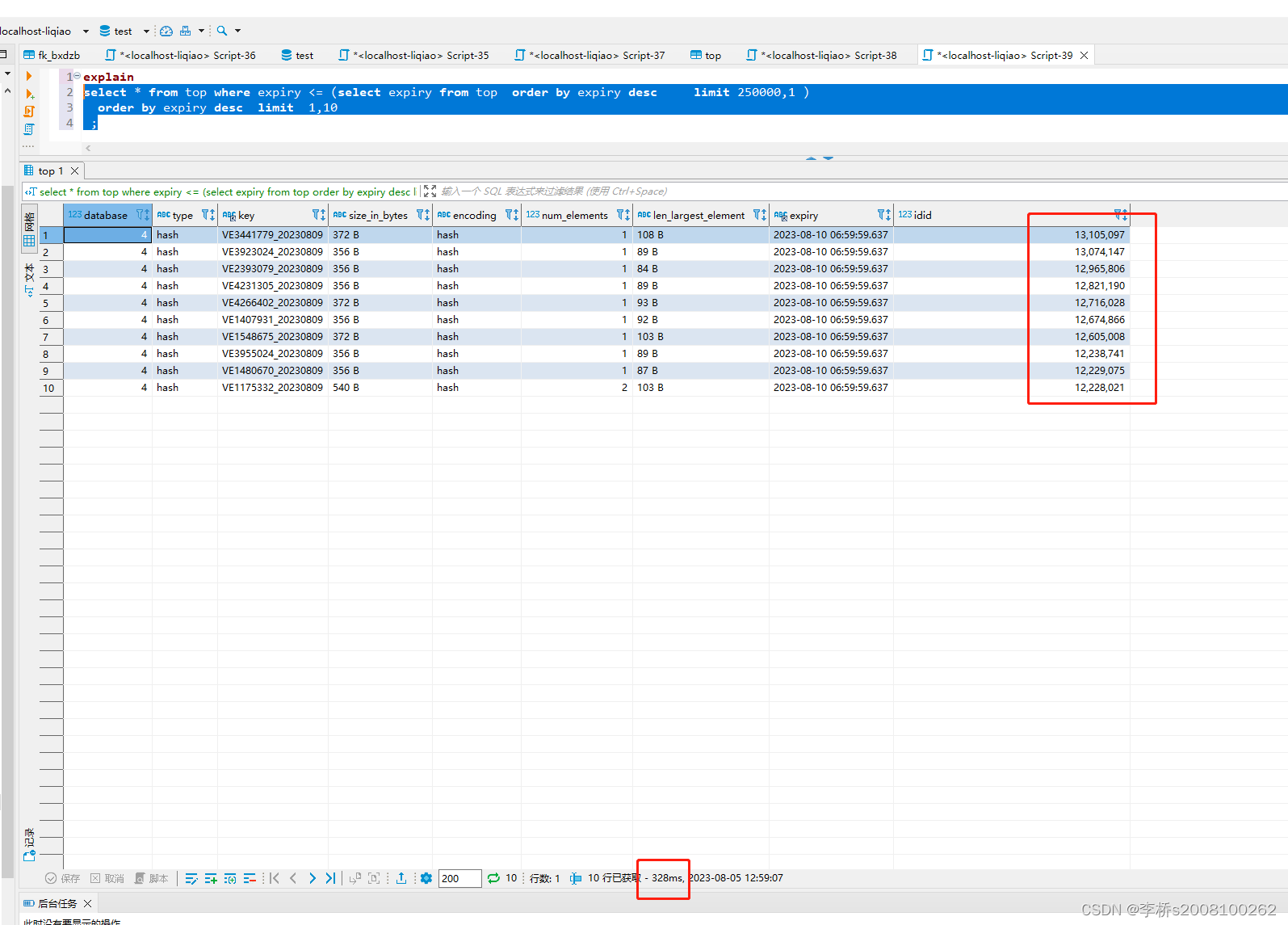
mysql大表的深度分页慢sql案例(跳页分页)
1 背景 有一张表,内容是 redis缓存中的key信息,数据量约1000万级, expiry列上有一个普通B树索引。 -- test.top definitionCREATE TABLE top (database int(11) DEFAULT NULL,type varchar(50) DEFAULT NULL,key varchar(500) DEFAULT NUL…...
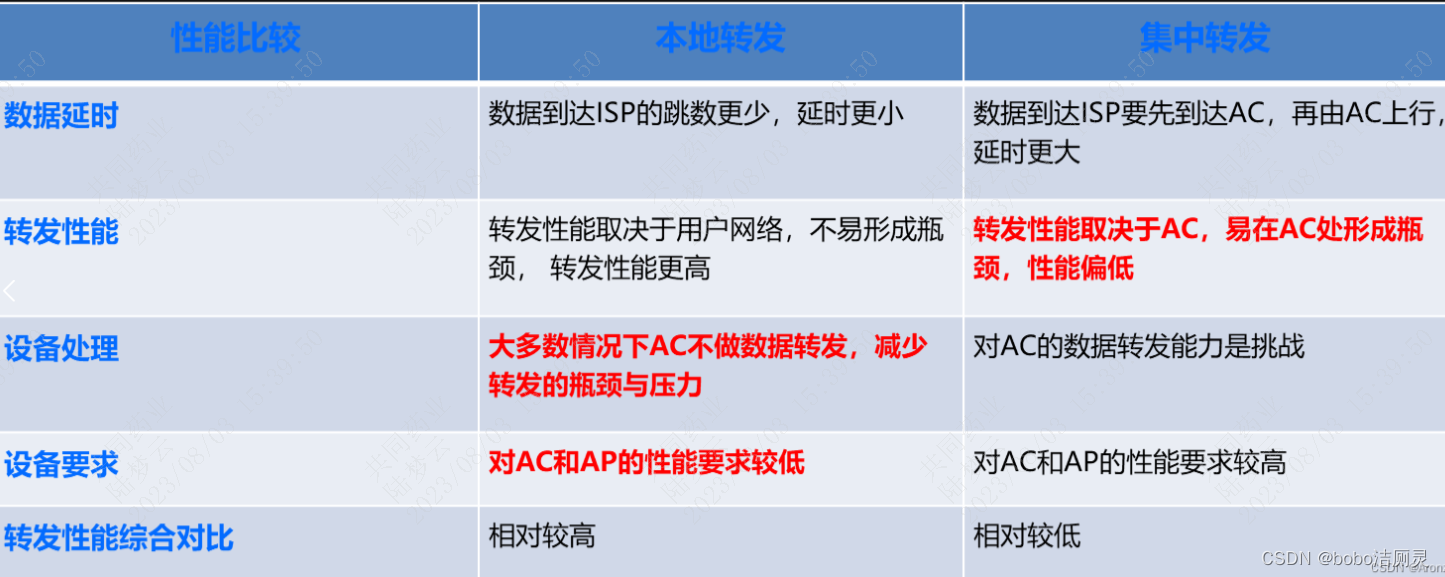
集中/本地转发、AC、AP
1.ADSL ADSL MODEM(ADSL 强制解调器)俗称ADSL猫 ADSL是一种异步传输模式(ATM)。ADSL是指使用电话线上网,需要专用的猫(Modem),在上网的时候高频和低频分离,所以上网电话两不耽误,速…...

Spring集成Seata
Seata的集成方式有: 1. Seata-All 2. Seata-Spring-Boot-Starter 3. Spring-Cloud-Starter-Seata 本案例使用Seata-All演示: 第一步:下载Seata 第二步:为了更好看到效果,我们将Seata的数据存储改为db 将seata\sc…...

终极指南:如何解锁光猫全部性能?RTL960x开源方案深度解析
终极指南:如何解锁光猫全部性能?RTL960x开源方案深度解析 【免费下载链接】RTL960x Hacking & Reverse Engineering RTL960x-based xPON ONTs to suit your OLT 项目地址: https://gitcode.com/gh_mirrors/rt/RTL960x RTL960x开源光猫固件是基…...

零成本获取全球股票数据:AKShare开源金融数据接口完整指南
零成本获取全球股票数据:AKShare开源金融数据接口完整指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/ak…...

从信号处理到AI:卷积的含参积分本质,如何帮你理解PyTorch中的Conv1d层?
从信号处理到AI:卷积的含参积分本质,如何帮你理解PyTorch中的Conv1d层? 在信号处理领域,卷积操作早已是工程师们耳熟能详的工具。但当我们踏入深度学习的殿堂,面对PyTorch中的nn.Conv1d层时,是否曾疑惑过&a…...

钉钉知识库日志迁移至Cursor的实践方法和具体操作步骤
一、钉钉知识库导出方法 方法1:手动导出(适合文档数量较少) 操作步骤: 电脑端钉钉 → 左下角【更多】→【文档】→【知识库】 进入目标知识库,打开需要迁移的文档 点击页面左上角 【文档】→【下载为】 选择导出格式:Word (.docx)、PDF 或 长图 文件默认以当前文档…...

为ubuntu20.04上的开源agent框架配置taotoken供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Ubuntu 20.04 上的开源 Agent 框架配置 Taotoken 供应商 在本地或服务器环境中部署开源 Agent 框架时,开发者常常希…...

Kindle Comic Converter终极指南:解锁电子墨水屏漫画阅读体验
Kindle Comic Converter终极指南:解锁电子墨水屏漫画阅读体验 【免费下载链接】kcc KCC (a.k.a. Kindle Comic Converter) is a comic and manga converter for ebook readers. 项目地址: https://gitcode.com/gh_mirrors/kc/kcc 你是否曾尝试在Kindle或Kobo…...

CANN/asc-devkit SIMD向量长度获取函数
GetVecLen 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

3步快速部署海风小店微信小程序商城 - 开源免费商用实战指南
3步快速部署海风小店微信小程序商城 - 开源免费商用实战指南 【免费下载链接】hioshop-miniprogram 微信小程序商城,开源免费商用,海风小店 项目地址: https://gitcode.com/gh_mirrors/hi/hioshop-miniprogram 海风小店是一款基于Node.jsThinkJSM…...

极限竞速涂装转换神器:Forza Painter终极免费指南
极限竞速涂装转换神器:Forza Painter终极免费指南 【免费下载链接】forza-painter Import images into Forza 项目地址: https://gitcode.com/gh_mirrors/fo/forza-painter 还在为《极限竞速:地平线》中的车辆涂装设计而苦恼吗?想要将…...
;RGRRQPIPKA)
HCV Core Protein (59-68);RGRRQPIPKA
一、基础信息多肽名称:丙型肝炎病毒 核心蛋白片段 (59-68) 英文名称:HCV Core Protein (59-68) 三字母序列:Arg-Gly-Arg-Arg-Gln-Pro-Ile-Pro-Lys-Ala 单字母序列:RGRRQPIPKA 氨基酸数量:10 aa 结构特征:线…...