python与深度学习(十三):CNN和IKUN模型
目录
- 1. 说明
- 2. IKUN模型
- 2.1 导入相关库
- 2.2 建立模型
- 2.3 模型编译
- 2.4 数据生成器
- 2.5 模型训练
- 2.6 模型保存
- 2.7 模型训练结果的可视化
- 3. IKUN的CNN模型可视化结果图
- 4. 完整代码
1. 说明
本篇文章是CNN的另外一个例子,IKUN模型,是自制数据集的例子。之前的例子都是python中库自带的,但是这次的例子是自己搜集数据集,如下图所示整理。

在这里简单介绍如何自制数据集,本人采用爬虫下载图片,如下,只需要输入需要下载图片的名字,然后代码执行之后就会自动爬取图片。当然在使用爬虫的时候需要下载好相关的库。
"""
objective:爬取任意偶像/单词的百度图片
coding: UTF-8
"""
# 导入相关库
import re
import requests
import osdef download(html, search_word, j):pic_url = re.findall('"objURL":"(.*?)",.*?"fromURL"', html, re.S) # 利用正则表达式找每一个图片的网址# print(pic_url)n = j * 60for k in pic_url:print('正在下载第' + str(n + 1) + '张图片,图片地址:' + str(k))try:pic = requests.get(k, timeout=20)except requests.exceptions.ConnectionError:print('当前图片无法下载')continuedir_path = r'D:\偶像图片\偶像' + search_word + '_' + str(n + 1) + '.jpg'if not os.path.exists('D:\偶像图片'):os.makedirs('D:\偶像图片')fp = open(dir_path, 'wb')fp.write(pic.content)fp.close()n += 1if __name__ == '__main__':name = input("输入你想要获取偶像的名称: ")headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}page = 2 # 可以自定义,想获取几页就是几页,一页有60张图片,但是有的可能就很少,自己注意下for i in range(page):url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + name + '&pn=' + str(i * 20) # 网址result = requests.get(url, headers=headers) # 请求网址# print(result.content) # 如果运行失败,一步一步找到原因,可以先看下网页输出的内容download(result.content.decode('utf-8'), name, i) # 保存图片
print("偶像图片下载完成")
2. IKUN模型
2.1 导入相关库
以下第三方库是python专门用于深度学习的库。需要提前下载并安装
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
2.2 建立模型
这是采用另外一种书写方式建立模型。
构建了三层卷积层,三层池化层,然后是展平层(将二维特征图拉直输入给全连接层),然后是三层全连接层,并且加入了dropout层。
"1.模型建立"
# 1.卷积层,输入图片大小(150, 150, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu'
conv_layer1 = Conv2D(input_shape=(150, 150, 3), filters=16, kernel_size=(5, 5), activation='relu')
# 2.最大池化层,池化层大小(2, 2), 步长为2
max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu'
conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu')
# 4.最大池化层,池化层大小(2, 2), 步长为2
max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu'
conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu')
# 6.最大池化层,池化层大小(2, 2), 步长为2
max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2)
# 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu'
conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu')
# 8.最大池化层,池化层大小(2, 2), 步长为2
max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2)
# 9.展平层
flatten_layer = Flatten()
# 10.Dropout层, Dropout(0.2)
third_dropout = Dropout(0.2)
# 11.全连接层/隐藏层1,240个节点, 激活函数'relu'
hidden_layer1 = Dense(240, activation='relu')
# 12.全连接层/隐藏层2,84个节点, 激活函数'relu'
hidden_layer3 = Dense(84, activation='relu')
# 13.Dropout层, Dropout(0.2)
fif_dropout = Dropout(0.5)
# 14.输出层,输出节点个数1, 激活函数'sigmoid'
output_layer = Dense(1, activation='sigmoid')
model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2,conv_layer3, max_pool3, conv_layer4, max_pool4,flatten_layer, third_dropout, hidden_layer1,hidden_layer3, fif_dropout, output_layer])
2.3 模型编译
模型的优化器是Adam,学习率是0.01,
损失函数是binary_crossentropy,二分类交叉熵,
性能指标是正确率accuracy,
另外还加入了回调机制。
回调机制简单理解为训练集的准确率持续上升,而验证集准确率基本不变,此时已经出现过拟合,应该调制学习率,让验证集的准确率也上升。
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=Adam(lr=0.0001), # 优化器选择Adam,初始学习率设置为0.0001loss='binary_crossentropy', # 代价函数选择 binary_crossentropymetrics=['accuracy']) # 设置指标为准确率
model.summary() # 模型统计# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracypatience=2, # 设置耐心容忍次数为2verbose=1, #factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少min_lr=0.000001 # 学习率最小值0.000001) # 监控val_accuracy增加趋势
2.4 数据生成器
加载自制数据集
利用数据生成器对数据进行数据加强,即每次训练时输入的图片会是原图片的翻转,平移,旋转,缩放,这样是为了降低过拟合的影响。
然后通过迭代器进行数据加载,目标图像大小统一尺寸1501503,设置每次加载到训练网络的图像数目,设置而分类模型(默认one-hot编码),并且数据打乱。
# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(rescale=1 / 255.0,rotation_range=5, # 图片随机旋转的角度5度width_shift_range=0.1,height_shift_range=0.1, # 水平和竖直方向随机移动0.1shear_range=0.1, # 剪切变换的程度0.1zoom_range=0.1, # 随机放大的程度0.1fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'imgs', 'train')
val_path = os.path.join(sys.path[0], 'imgs', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
2.5 模型训练
模型训练的次数是20,每1次循环进行测试
"3.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器epochs=20, # 循环次数12次validation_data=val_iter, # 验证数据的迭代器callbacks=[reduce], # 回调机制设置为reduceverbose=1)
2.6 模型保存
以.h5文件格式保存模型
"4.模型保存"
# 保存训练好的模型
model.save('my_ikun.h5')
2.7 模型训练结果的可视化
对模型的训练结果进行可视化,可视化的结果用曲线图的形式展现
"5.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('my_ikun_acc.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('my_ikun_loss.png', dpi=600)
plt.show() # 将结果显示出来
3. IKUN的CNN模型可视化结果图
Epoch 1/20
125/125 [==============================] - 30s 229ms/step - loss: 0.6012 - accuracy: 0.6450 - val_loss: 0.3728 - val_accuracy: 0.8200 - lr: 1.0000e-04
Epoch 2/20
125/125 [==============================] - 28s 223ms/step - loss: 0.3209 - accuracy: 0.8710 - val_loss: 0.3090 - val_accuracy: 0.8900 - lr: 1.0000e-04
Epoch 3/20
125/125 [==============================] - 34s 270ms/step - loss: 0.2564 - accuracy: 0.8990 - val_loss: 0.4873 - val_accuracy: 0.8075 - lr: 1.0000e-04
Epoch 4/20
125/125 [==============================] - ETA: 0s - loss: 0.2546 - accuracy: 0.9050
Epoch 4: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.
125/125 [==============================] - 34s 275ms/step - loss: 0.2546 - accuracy: 0.9050 - val_loss: 0.3298 - val_accuracy: 0.8875 - lr: 1.0000e-04
Epoch 5/20
125/125 [==============================] - 31s 246ms/step - loss: 0.1867 - accuracy: 0.9310 - val_loss: 0.3577 - val_accuracy: 0.8500 - lr: 5.0000e-05
Epoch 6/20
125/125 [==============================] - 31s 245ms/step - loss: 0.1805 - accuracy: 0.9260 - val_loss: 0.2816 - val_accuracy: 0.8975 - lr: 5.0000e-05
Epoch 7/20
125/125 [==============================] - 30s 238ms/step - loss: 0.1689 - accuracy: 0.9340 - val_loss: 0.2679 - val_accuracy: 0.9100 - lr: 5.0000e-05
Epoch 8/20
125/125 [==============================] - 30s 237ms/step - loss: 0.2230 - accuracy: 0.9200 - val_loss: 0.2561 - val_accuracy: 0.9075 - lr: 5.0000e-05
Epoch 9/20
125/125 [==============================] - ETA: 0s - loss: 0.1542 - accuracy: 0.9480
Epoch 9: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-05.
125/125 [==============================] - 30s 238ms/step - loss: 0.1542 - accuracy: 0.9480 - val_loss: 0.2527 - val_accuracy: 0.9100 - lr: 5.0000e-05
Epoch 10/20
125/125 [==============================] - 30s 239ms/step - loss: 0.1537 - accuracy: 0.9450 - val_loss: 0.2685 - val_accuracy: 0.9125 - lr: 2.5000e-05
Epoch 11/20
125/125 [==============================] - 33s 263ms/step - loss: 0.1395 - accuracy: 0.9540 - val_loss: 0.2703 - val_accuracy: 0.9100 - lr: 2.5000e-05
Epoch 12/20
125/125 [==============================] - ETA: 0s - loss: 0.1331 - accuracy: 0.9560
Epoch 12: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-05.
125/125 [==============================] - 31s 250ms/step - loss: 0.1331 - accuracy: 0.9560 - val_loss: 0.2739 - val_accuracy: 0.9025 - lr: 2.5000e-05
Epoch 13/20
125/125 [==============================] - 31s 245ms/step - loss: 0.1374 - accuracy: 0.9500 - val_loss: 0.2551 - val_accuracy: 0.9250 - lr: 1.2500e-05
Epoch 14/20
125/125 [==============================] - 32s 254ms/step - loss: 0.1261 - accuracy: 0.9590 - val_loss: 0.2705 - val_accuracy: 0.9050 - lr: 1.2500e-05
Epoch 15/20
125/125 [==============================] - ETA: 0s - loss: 0.1256 - accuracy: 0.9620
Epoch 15: ReduceLROnPlateau reducing learning rate to 6.24999984211172e-06.
125/125 [==============================] - 31s 248ms/step - loss: 0.1256 - accuracy: 0.9620 - val_loss: 0.2449 - val_accuracy: 0.9125 - lr: 1.2500e-05
Epoch 16/20
125/125 [==============================] - 31s 245ms/step - loss: 0.1182 - accuracy: 0.9610 - val_loss: 0.2460 - val_accuracy: 0.9225 - lr: 6.2500e-06
Epoch 17/20
125/125 [==============================] - ETA: 0s - loss: 0.1261 - accuracy: 0.9610
Epoch 17: ReduceLROnPlateau reducing learning rate to 3.12499992105586e-06.
125/125 [==============================] - 30s 243ms/step - loss: 0.1261 - accuracy: 0.9610 - val_loss: 0.2466 - val_accuracy: 0.9250 - lr: 6.2500e-06
Epoch 18/20
125/125 [==============================] - 30s 240ms/step - loss: 0.1098 - accuracy: 0.9630 - val_loss: 0.2544 - val_accuracy: 0.9125 - lr: 3.1250e-06
Epoch 19/20
125/125 [==============================] - ETA: 0s - loss: 0.1165 - accuracy: 0.9630
Epoch 19: ReduceLROnPlateau reducing learning rate to 1.56249996052793e-06.
125/125 [==============================] - 31s 246ms/step - loss: 0.1165 - accuracy: 0.9630 - val_loss: 0.2476 - val_accuracy: 0.9225 - lr: 3.1250e-06
Epoch 20/20
125/125 [==============================] - 35s 281ms/step - loss: 0.1214 - accuracy: 0.9570 - val_loss: 0.2503 - val_accuracy: 0.9225 - lr: 1.5625e-06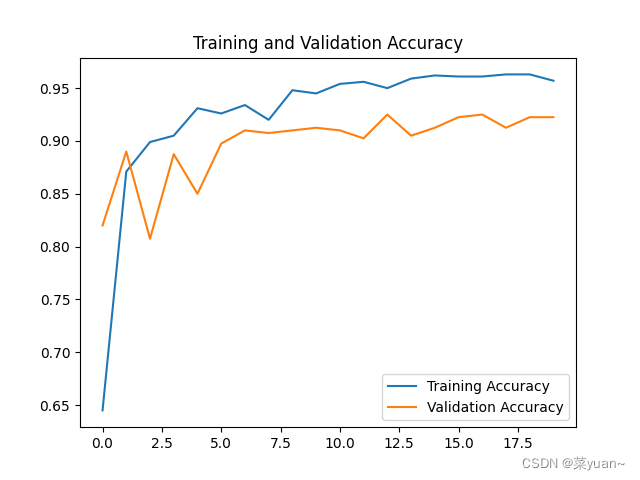
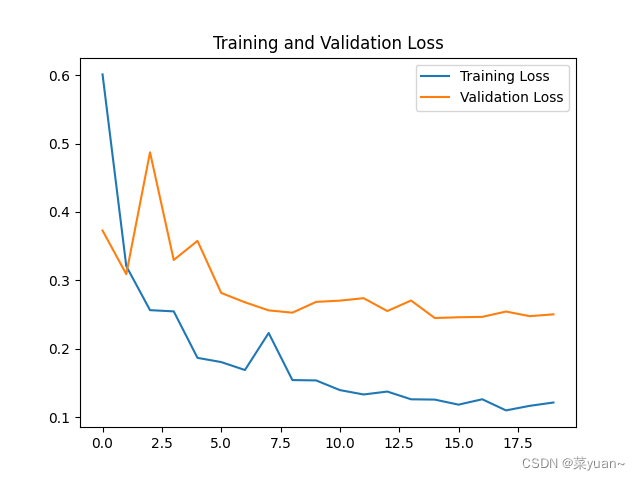
从以上结果可知,模型的准确率达到了92%,准确率还是很高的。
4. 完整代码
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
import sys, os # 目录结构
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping, ReduceLROnPlateau"1.模型建立"
# 1.卷积层,输入图片大小(150, 150, 3), 卷积核个数16,卷积核大小(5, 5), 激活函数'relu'
conv_layer1 = Conv2D(input_shape=(150, 150, 3), filters=16, kernel_size=(5, 5), activation='relu')
# 2.最大池化层,池化层大小(2, 2), 步长为2
max_pool1 = MaxPool2D(pool_size=(2, 2), strides=2)
# 3.卷积层,卷积核个数32,卷积核大小(5, 5), 激活函数'relu'
conv_layer2 = Conv2D(filters=32, kernel_size=(5, 5), activation='relu')
# 4.最大池化层,池化层大小(2, 2), 步长为2
max_pool2 = MaxPool2D(pool_size=(2, 2), strides=2)
# 5.卷积层,卷积核个数64,卷积核大小(5, 5), 激活函数'relu'
conv_layer3 = Conv2D(filters=64, kernel_size=(5, 5), activation='relu')
# 6.最大池化层,池化层大小(2, 2), 步长为2
max_pool3 = MaxPool2D(pool_size=(2, 2), strides=2)
# 7.卷积层,卷积核个数128,卷积核大小(5, 5), 激活函数'relu'
conv_layer4 = Conv2D(filters=128, kernel_size=(5, 5), activation='relu')
# 8.最大池化层,池化层大小(2, 2), 步长为2
max_pool4 = MaxPool2D(pool_size=(2, 2), strides=2)
# 9.展平层
flatten_layer = Flatten()
# 10.Dropout层, Dropout(0.2)
third_dropout = Dropout(0.2)
# 11.全连接层/隐藏层1,240个节点, 激活函数'relu'
hidden_layer1 = Dense(240, activation='relu')
# 12.全连接层/隐藏层2,84个节点, 激活函数'relu'
hidden_layer3 = Dense(84, activation='relu')
# 13.Dropout层, Dropout(0.2)
fif_dropout = Dropout(0.5)
# 14.输出层,输出节点个数1, 激活函数'sigmoid'
output_layer = Dense(1, activation='sigmoid')
model = Sequential([conv_layer1, max_pool1, conv_layer2, max_pool2,conv_layer3, max_pool3, conv_layer4, max_pool4,flatten_layer, third_dropout, hidden_layer1,hidden_layer3, fif_dropout, output_layer])
"2.模型编译"
# 模型编译,2分类:binary_crossentropy
model.compile(optimizer=Adam(lr=0.0001), # 优化器选择Adam,初始学习率设置为0.0001loss='binary_crossentropy', # 代价函数选择 binary_crossentropymetrics=['accuracy']) # 设置指标为准确率
model.summary() # 模型统计# 回调机制 动态调整学习率
reduce = ReduceLROnPlateau(monitor='val_accuracy', # 设置监测的值为val_accuracypatience=2, # 设置耐心容忍次数为2verbose=1, #factor=0.5, # 缩放学习率的值为0.5,学习率将以lr = lr*factor的形式被减少min_lr=0.000001 # 学习率最小值0.000001) # 监控val_accuracy增加趋势# 生成器对象1: 归一化
gen = ImageDataGenerator(rescale=1 / 255.0)
# 生成器对象2: 归一化 + 数据加强
gen1 = ImageDataGenerator(rescale=1 / 255.0,rotation_range=5, # 图片随机旋转的角度5度width_shift_range=0.1,height_shift_range=0.1, # 水平和竖直方向随机移动0.1shear_range=0.1, # 剪切变换的程度0.1zoom_range=0.1, # 随机放大的程度0.1fill_mode='nearest') # 当需要进行像素填充时选择最近的像素进行填充
# 拼接训练和验证的两个路径
train_path = os.path.join(sys.path[0], 'imgs', 'train')
val_path = os.path.join(sys.path[0], 'imgs', 'val')
print('训练数据路径: ', train_path)
print('验证数据路径: ', val_path)
# 训练和验证的两个迭代器
train_iter = gen1.flow_from_directory(train_path, # 训练train目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
val_iter = gen.flow_from_directory(val_path, # 测试val目录路径target_size=(150, 150), # 目标图像大小统一尺寸150batch_size=8, # 设置每次加载到内存的图像大小class_mode='binary', # 设置分类模型(默认one-hot编码)shuffle=True) # 是否打乱
"3.模型训练"
# 模型的训练, model.fit
result = model.fit(train_iter, # 设置训练数据的迭代器epochs=20, # 循环次数12次validation_data=val_iter, # 验证数据的迭代器callbacks=[reduce], # 回调机制设置为reduceverbose=1)
"4.模型保存"
# 保存训练好的模型
model.save('my_ikun.h5')"5.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = result.history['accuracy'] # 获取模型训练中的accuracy
val_acc = result.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = result.history['loss'] # 获取模型训练中的loss
val_loss = result.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.savefig('my_ikun_acc.png', dpi=600)
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('my_ikun_loss.png', dpi=600)
plt.show() # 将结果显示出来相关文章:
python与深度学习(十三):CNN和IKUN模型
目录 1. 说明2. IKUN模型2.1 导入相关库2.2 建立模型2.3 模型编译2.4 数据生成器2.5 模型训练2.6 模型保存2.7 模型训练结果的可视化 3. IKUN的CNN模型可视化结果图4. 完整代码 1. 说明 本篇文章是CNN的另外一个例子,IKUN模型,是自制数据集的例子。之前…...

题目:2283.判断一个数的数字计数是否等于数位的值
题目来源: leetcode题目,网址:2283. 判断一个数的数字计数是否等于数位的值 - 力扣(LeetCode) 解题思路: 两次遍历。第一次对字符串中每个出现的数字计数。第二次比较数字计数与数位的值是否相等。 解…...

任务14、无缝衔接,MidJourney瓷砖(Tile)参数制作精良贴图
14.1 任务概述 在这个实验任务中,我们将深入探索《Midjourney Ai绘画》中的Tile技术和其在艺术创作中的具有挑战性的应用。此任务将通过理论学习与实践操作相结合的方式,让参与者更好地理解Tile的核心概念,熟练掌握如何在Midjourney平台上使用Tile参数,并实际运用到AI绘画…...

【uniapp APP如何优化】
以下是一些可以进行优化的建议: 1. 减少网络请求次数:尽量避免在首页加载时请求大量数据,可以考虑使用分页加载,或者使用下拉刷新和上拉加载更多的方式。 2. 减小图片大小:使用压缩图片的工具,可以尽可能…...
uni-app——下拉框多选
一、组件components/my-selectCheckbox.vue <template><view class"uni-stat__select"><span v-if"label" class"uni-label-text">{{label :}}</span><view class"uni-stat-box" :class"…...
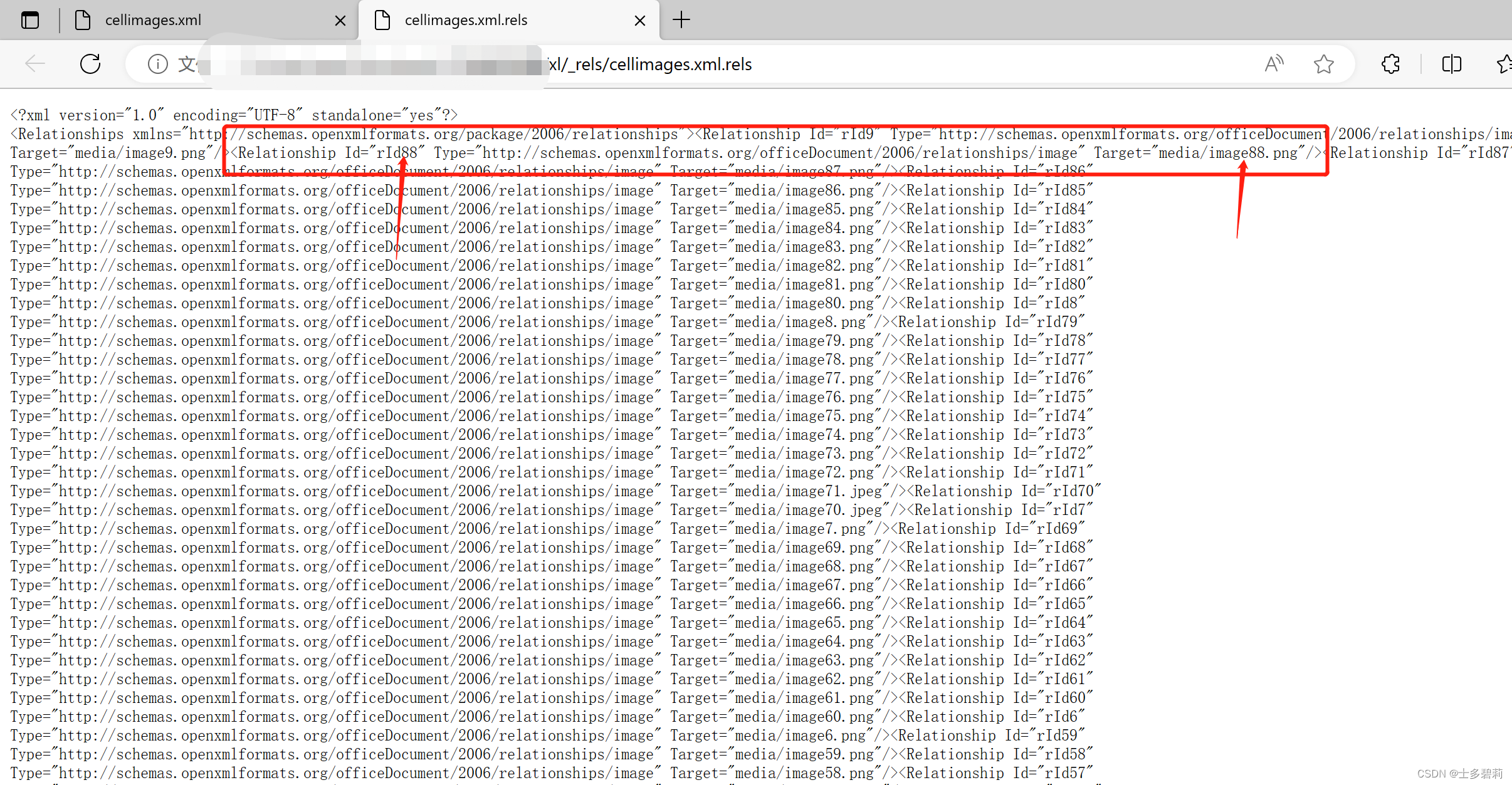
从excel中提取嵌入式图片的解决方法
1 发现问题 我的excel中有浮动图片和嵌入式图片,但是openpyxl的_image对象只提取到了浮动图片,通过阅读其源码发现,这是因为openpyxl只解析了drawing文件导致的,所以确定需要自己解析 2 解决思路 1、解析出media资源 2、解析…...

python socket 网络编程的基本功
python socket逻辑思维整理 UDP发送步骤: 1 、先建立udp套接字 udp_socket socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 2、利用sendto把数据并指定对端IP和端口,本端端口可以不用指定用自动随机的 udp_socket.sendto(“发送的内容”.encode(“…...

【element-ui】form表单初始化页面如何取消自动校验rules
问题描述:elementUI表单提交页面,初始化页面是获取接口数据,给form赋值,但是有时候这些会是空值情况,如果是空值,再给form表单赋值的话,页面初始化时候进行rules校验会不通过,此时前…...
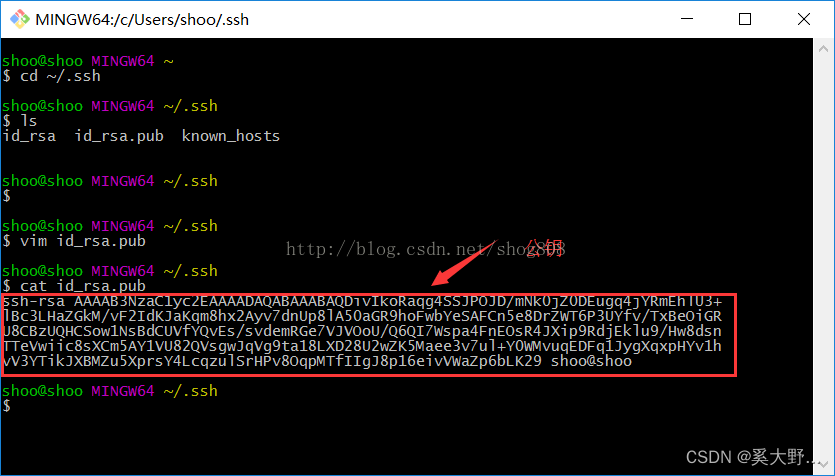
git 公钥密钥 生成与查看
1.什么是公钥 很多服务器都是需要认证的,ssh认证是其中的一种。在客户端生成公钥,把生成的公钥添加到服务器,你以后连接服务器就不用每次都输入用户名和密码了。 很多git服务器都是用ssh认证方式,你需要把你生成的公钥发送给代码仓…...
数据标注对新零售的意义及人工智能在新零售领域的应用?
数据标签对于新零售至关重要,因为它构成了训练和部署人工智能(AI)和机器学习(ML)模型的基础。在新零售的背景下,数据标签涉及对数据进行分类、标记或注释以使其能够被机器理解的过程。然后,这些…...
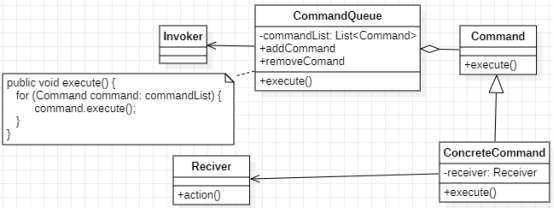
命令模式-请求发送者与接收者解耦
去小餐馆吃饭的时候,顾客直接跟厨师说想要吃什么菜,然后厨师再开始炒菜。去大点的餐馆吃饭时,我们是跟服务员说想吃什么菜,然后服务员把这信息传到厨房,厨师根据这些订单信息炒菜。为什么大餐馆不省去这个步骤…...
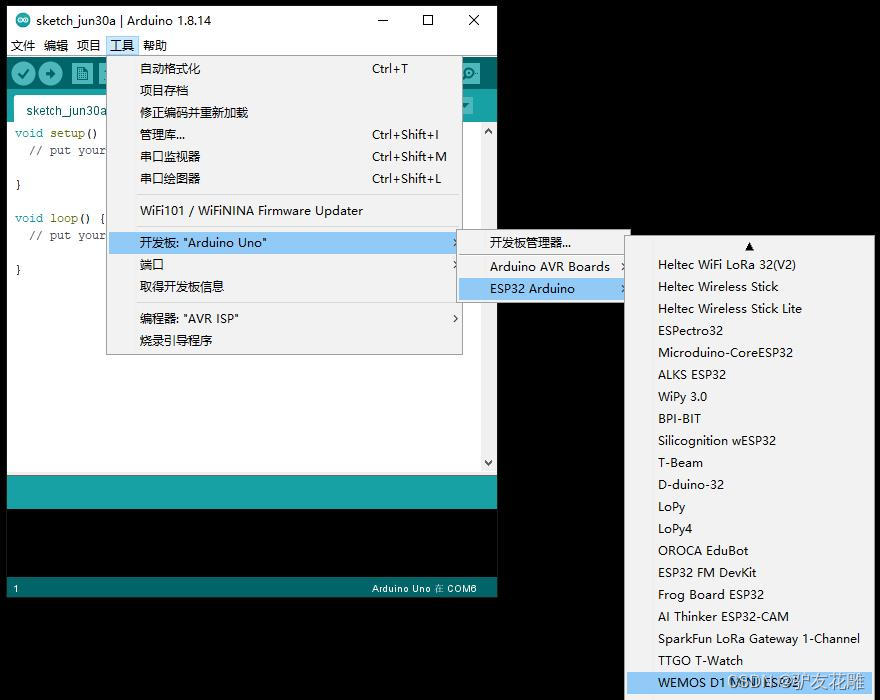
【雕爷学编程】Arduino动手做(186)---WeMos ESP32开发板
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的&#x…...

3、JSON数据的处理
3.1 介绍 JSON数据 Spark SQL can automatically infer the schema of a JSON dataset and load it as a DataFrame Spark SQL能够自动将JSON数据集以结构化的形式加载为一个DataFrame This conversion can be done using SparkSession.read.json on a JSON file 读取一个JSO…...

8月5日上课内容 nginx的优化和防盗链
全部都是面试题 nginx的优化和防盗链 重点就是优化: 每一个点都是面试题,非常重要,都是面试题 1、隐藏版本号(重点,一定要会) 备份 cp nginx.conf nginx.conf.bak.2023.0805 方法一:修改配…...

网络爬虫请求头中的Referer和User-Agent与代理IP的配合使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8EJgMcgK-1691050515642)(https://cdn.nlark.com/yuque/0/2023/png/1313150/1691048724422-2a76d7b8-3ec3-48b7-9aec-d609d09b16d4.png#averageHue%2385b0a7&clientIdu3856fd20-7701-4&fromui&…...

RabbitMQ 生产者-消息丢失 之 场景分析
生产者-消息丢失 之 场景分析 生产者消息丢失的场景消息无法到达RabbitMQ连接断开信道关闭 RabbitMQ无法将消息入队交换机不存在无匹配队列 消息过期丢失消息丢失场景对比 生产者消息丢失的场景 生产者发送消息的流程如下:首先生产者和RabbitMQ服务器建立连接&…...
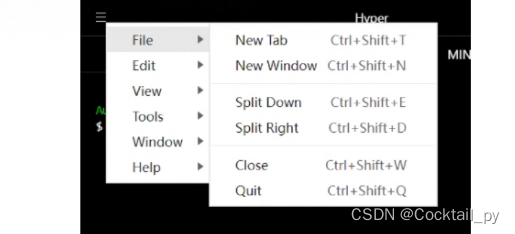
Hyper实现git bash在windows环境下多tab窗口显示
1.电脑上安装有git bash 下载链接:https://gitforwindows.org/ 安装Hyper 下载链接:官网 https://hyper.is/ 或者在百度云盘下载: https://pan.baidu.com/s/1BVjzlK0s4SgAbQgsiK1Eow 提取码:0r1f 设置 打开Hyper,依次点左上角-&g…...

Matlab的信号频谱分析——FFT变换
Matlab的信号频谱分析——FFT变换 Matlab的信号频谱分析 FFT是离散傅立叶变换的快速算法,可以将一个时域信号变换到频域。 有些信号在时域上是很难看出什么特征的。但是如果变换到频域之后,就很容易看出特征了。 这就是很多信号分析采用FFT变换的原因…...
如何从 Android 设备恢复已删除的文件?
从 Android 设备恢复已删除的文件很简单,但您需要了解内部恢复和SD 卡恢复之间的区别。 目前销售的大多数 Android 设备都配备了 SD 卡插槽(通常为 microSD),可以轻松添加额外的存储空间。该存储空间可用于存储照片、视频、文档&a…...
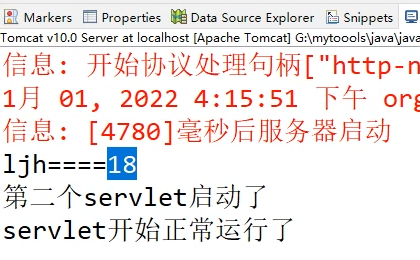
servlet生命周期和初始化参数传递
servlet生命周期和初始化参数传递 1、servlet生命周期 只有第一次访问才会初始化,之后访问都只执行service中的。 除非tomcat关闭重新启动: 2、初始化参数传递...
)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南) 1. 理解W25Q16存储芯片的核心特性 W25Q16作为一款16Mbit容量的SPI Flash存储器,在嵌入式系统中扮演着重要角色。这款芯片采用标准的SPI接口,支持单…...

EasyWatermark代码架构详解:MVVM模式与依赖注入实践
EasyWatermark代码架构详解:MVVM模式与依赖注入实践 【免费下载链接】EasyWatermark 🔒 🖼 Securely, easily add a watermark to your sensitive photos. 安全、简单地为你的敏感照片添加水印,防止被人泄露、利用 项目地址: ht…...

AI Agent Harness Engineering 后端架构选型:微服务 vs 单体架构的取舍
AI Agent Harness Engineering 后端架构选型深度指南:微服务 vs 单体架构的取舍、落地与最佳实践 摘要/引言 你有没有过这样的经历:团队好不容易赶完了AI Agent的POC验证,正准备规模化落地,却卡在了后端架构选型上? 有人说“微服务是未来”,上来就拆了8个服务,结果3个后…...

3步掌握Navicat无限试用重置:Mac用户的完整专业指南
3步掌握Navicat无限试用重置:Mac用户的完整专业指南 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 还在为Navica…...
的演进与实战选择)
从U盘到高端SSD:一文搞懂FTL映射表(块/页/混合)的演进与实战选择
从U盘到高端SSD:一文搞懂FTL映射表(块/页/混合)的演进与实战选择 存储设备的性能差异往往隐藏在底层算法的设计哲学中。当你在电商平台对比两款SSD时,是否思考过为什么同样标称1TB容量的产品,价格能相差数倍ÿ…...

[Android] 文案设计助手_24.06.25
[Android] 文案设计助手_24.06.25 链接:https://pan.xunlei.com/s/VOszMVvm4BmG5za6Ib11nfGrA1?pwdsg9f# 文案设计助手,助您文案生成、自动写作,模拟手写生成器。免登陆,下载即用,无需会员。...

STM32 HAL库实战:用CD74HC4067扩展模拟输入通道,附完整工程代码
STM32 HAL库实战:用CD74HC4067扩展模拟输入通道,附完整工程代码 在嵌入式开发中,模拟信号采集是常见需求,但MCU内置ADC通道数量往往有限。当面对多路传感器信号采集时,如何经济高效地扩展输入通道成为开发者必须解决的…...

家长选择赶考小状元AI自习室还是其他品牌对孩子学习更有帮助?深度解析三大维度
随着教育智能化浪潮席卷而来,家长们在为孩子选择学习辅助工具时,面临着前所未有的多元选择。传统网课、新兴自习室品牌层出不穷,而深耕智能教育领域二十年的赶考小状元AI智能自习室,以其独特的“教育内核科技工具运营支持”三维融…...

跨平台流媒体下载神器:N_m3u8DL-RE的完整使用指南
跨平台流媒体下载神器:N_m3u8DL-RE的完整使用指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 你…...

AI 高性能笔记本电脑高效紧凑型功率 MOSFET 完整选型方案
随着 AI 算力在笔记本电脑中的爆发式增长(如本地大模型、智能温控、性能调度),电源架构对功率 MOSFET 提出严苛要求:超高电流密度、极低损耗、超小封装、逻辑电平驱动。微碧半导体(VBsemi)基于先进的 Trenc…...