CNN成长路:从AlexNet到EfficientNet(01)
一、说明
在 10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。
如果我们在 Imagenet 上绘制所有报告作品的准确性,我们会得到这样的结果:
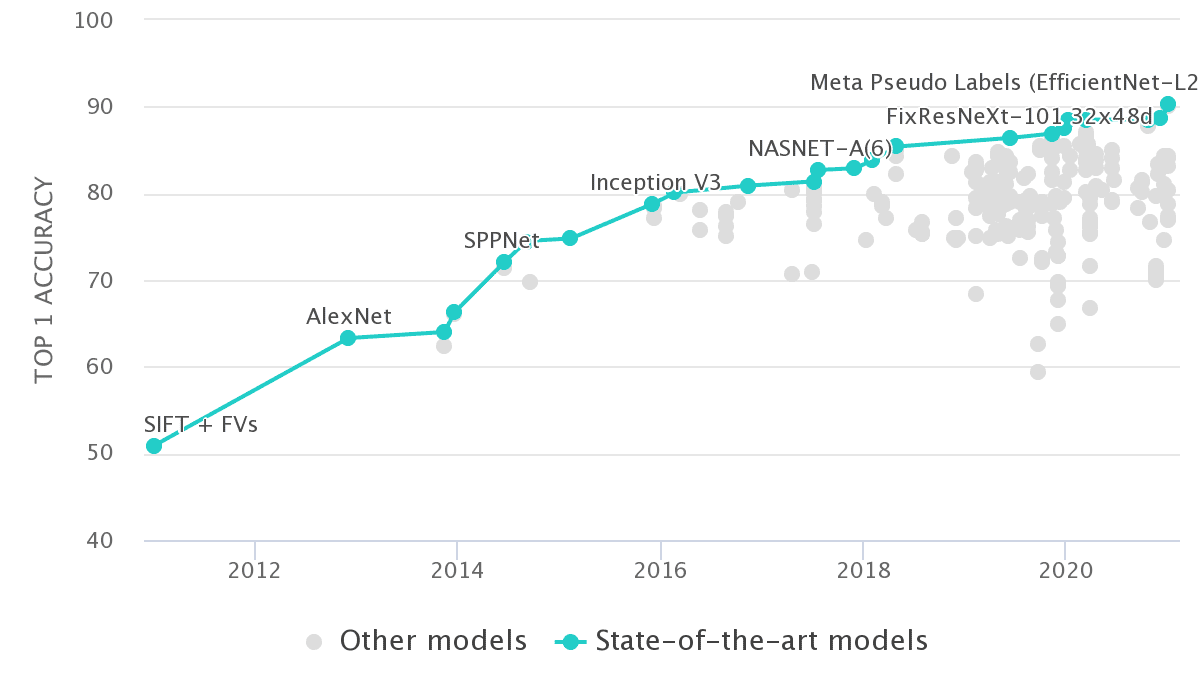
来源:Papers with Code - Imagenet Benchmark
在本文中,我们将重点介绍卷积神经网络(CNN)架构的演变。我们将专注于基本原则,而不是报告简单的数字。为了提供另一种视觉概览,可以在单个图像中捕获2018年之前表现最佳的CNN:
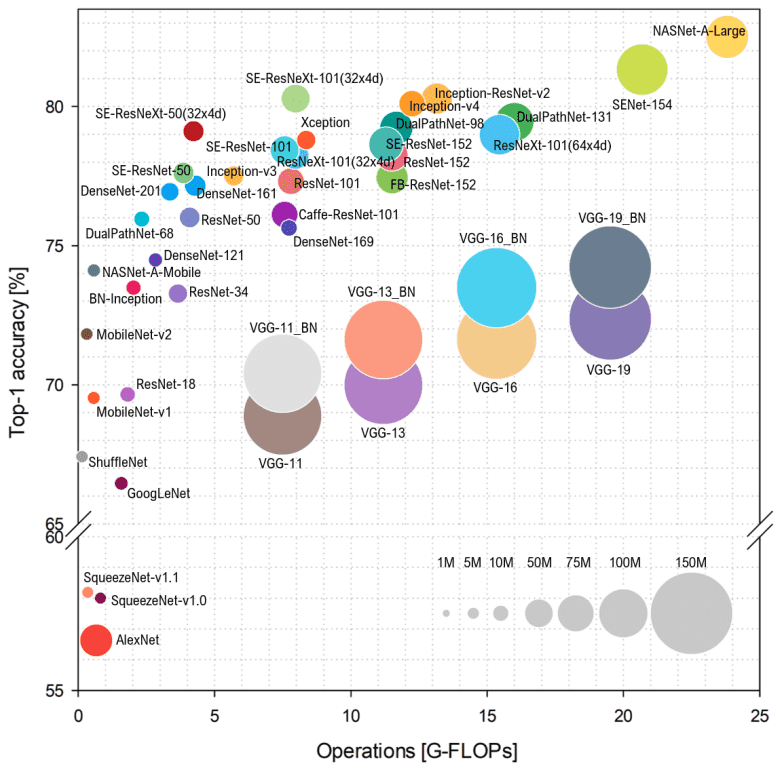
截至 2018 年的架构概述。资料来源:Simone Bianco et al. 2018
不要惊慌失措。所有描述的体系结构都基于我们将要描述的概念。
请注意,每秒浮点运算数 (FLOP) 表示模型的复杂性,而在垂直轴上,我们有 Imagenet 精度。圆的半径表示参数的数量。
从上图中可以看出,更多的参数并不总是能带来更好的准确性。我们将尝试对CNN进行更广泛的思考,看看为什么这是正确的。
如果您想从头开始了解卷积的工作原理,请推荐 Andrew 的 Ng 课程。
二、第一阶段:CNN架构的递进
2.1 术语解释
但首先,我们必须定义一些术语:
-
更宽的网络意味着卷积层中更多的特征图(过滤器)
-
更深的网络意味着更多的卷积层
-
具有更高分辨率的网络意味着它处理具有更大宽度和深度(空间分辨率)的输入图像。这样,生成的特征图将具有更高的空间维度。
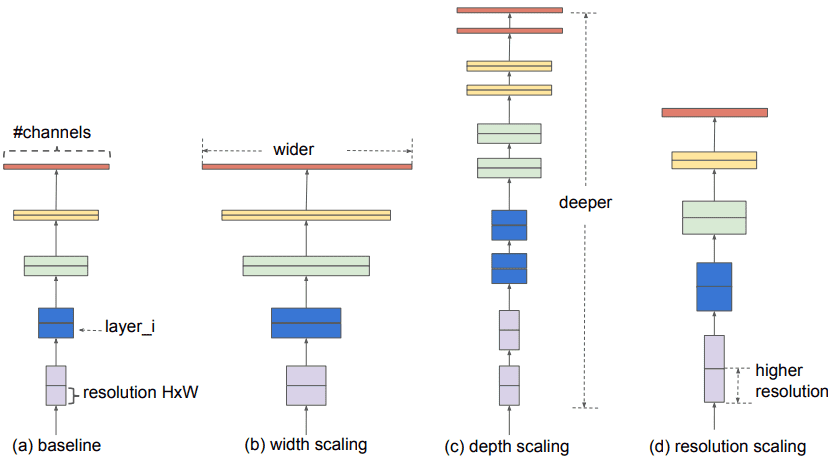
架构扩展。来源:谭明兴,Quoc V. Le 2019
架构工程就是关于扩展的。我们将彻底使用这些术语,因此在继续之前请务必理解它们。
2.2 AlexNet: ImageNet Classification with Deep Convolutional Neural Networks (2012)
Alexnet [1] 由 5 个从 11x11 内核开始的卷积层组成。它是第一个采用最大池化层、ReLu 激活函数和 3 个巨大线性层的 dropout 的架构。该网络用于具有 1000 个可能类的图像分类,这在当时是疯狂的。现在,您可以在 35 行 PyTorch 代码中实现它:
class AlexNet(nn.Module):def __init__(self, num_classes: int = 1000) -> None:super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((6, 6))self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x这是第一个在 Imagenet 上成功训练的卷积模型,当时在 CUDA 中实现这样的模型要困难得多。Dropout 在巨大的线性变换中大量使用,以避免过度拟合。在 2015-2016 年自动微分出现之前,在 GPU 上实现反向传播需要几个月的时间。
2.3 VGG (2014)
著名的论文“用于大规模图像识别的非常深度卷积网络”[2]使深度一词病毒式传播。这是第一项提供不可否认证据的研究,证明简单地添加更多层可以提高性能。尽管如此,这一假设在一定程度上是正确的。为此,他们只使用3x3内核,而不是AlexNet。该架构使用 224 × 224 个 RGB 图像进行训练。
主要原理是一叠三3×3 转换层类似于单个7×7 层。甚至可能更好!因为它们在两者之间使用三个非线性激活(而不是一个),这使得函数更具鉴别性。
其次,这种设计减少了参数的数量。具体来说,您需要 权重,与7×7 需要的转换层
参数(增加 81%)。
直观地,它可以被视为对7×7 转换过滤器,限制它们具有 3x3 非线性分解。最后,这是规范化开始成为一个相当成问题的架构。
尽管如此,预训练的VGG仍然用于生成对抗网络中的特征匹配损失,以及神经风格转移和特征可视化。
以我的拙见,检查凸网相对于输入的特征非常有趣,如以下视频所示:
最后,在Alexnet旁边进行视觉比较:
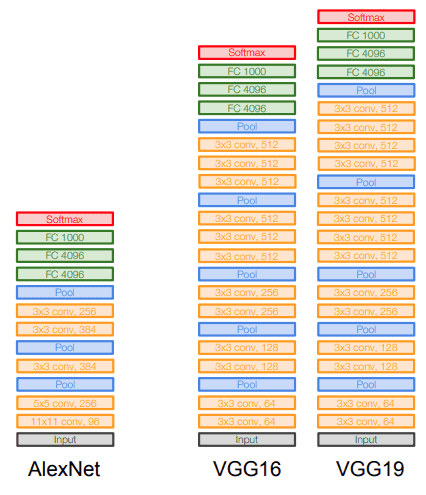
来源:斯坦福大学2017年深度学习讲座:CNN架构
2.4 InceptionNet/GoogleNet (2014)
在VGG之后,Christian Szegedy等人的论文“Go Deep with Convolutions”[3]是一个巨大的突破。
动机:增加深度(层数)并不是使模型变大的唯一方法。如何增加网络的深度和宽度,同时将计算保持在恒定的水平?
这一次的灵感来自人类视觉系统,其中信息在多个尺度上进行处理,然后在本地聚合[3]。如何在不发生记忆爆炸的情况下实现这一目标?
答案是1×1 卷 积!主要目的是通过减少每个卷积块的输出通道来减小尺寸。然后我们可以处理具有不同内核大小的输入。只要填充输出,它就与输入相同。
要找到具有单步幅且无扩张的合适填充,请填充p和内核k被定义为(输入和输出空间调光):
,这意味着
.在 Keras 中,您只需指定 padding='same'。这样,我们可以连接与不同内核卷积的特征。
然后我们需要1×1 卷积层将特征“投影”到更少的通道,以赢得计算能力。有了这些额外的资源,我们可以添加更多的层。实际上,1×1 convs 的工作方式类似于低维嵌入。
有关 1x1 转换的快速概述,请推荐来自著名 Coursera 课程的以下视频:
这反过来又允许通过使用Inception模块不仅增加深度,而且增加著名的GoogleNet的宽度。核心构建块称为 inception 模块,如下所示:
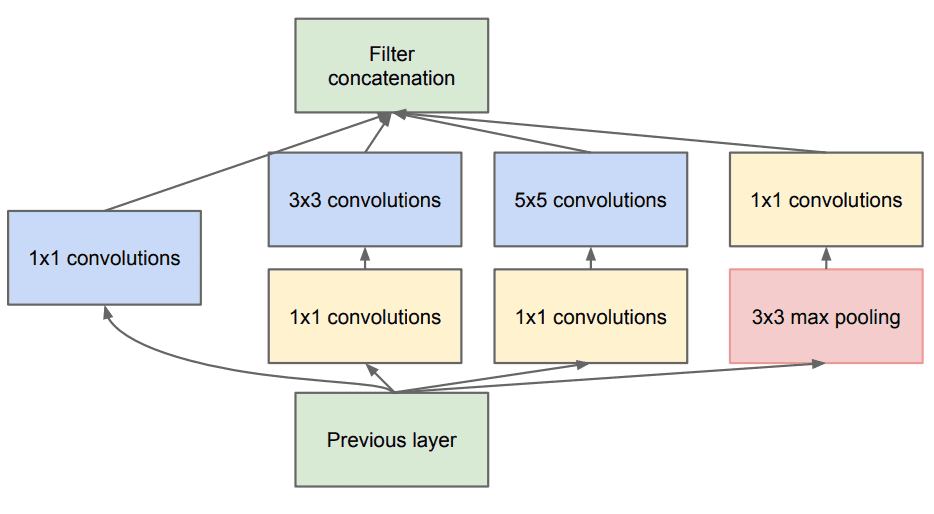
整个架构被称为GoogLeNet或InceptionNet。从本质上讲,作者声称他们试图用正常的密集层近似稀疏的凸网(如图所示)。
为什么?因为他们相信只有少数神经元是有效的。这符合Hebbian原则:“一起放电的神经元,连接在一起”。
此外它使用不同内核大小的卷积(5×55×5,3×33×3,1×11×1) 以捕获多个比例下的细节.
通常,对于驻留在全局的信息,首选较大的内核,对于本地分发的信息,首选较小的内核。
此外1×1 卷积用于在计算成本高昂的卷积(3×3 和 5×5)之前计算约简。
InceptionNet/GoogLeNet架构由9个堆叠在一起的初始模块组成,其间有最大池化层(将空间维度减半)。它由 22 层组成(27 层带有池化层)。它在上次启动模块之后使用全局平均池化。
我写了一个非常简单的 Inception 块实现,可能会澄清一些事情:
import torch
import torch.nn as nnclass InceptionModule(nn.Module):def __init__(self, in_channels, out_channels):super(InceptionModule, self).__init__()relu = nn.ReLU()self.branch1 = nn.Sequential(nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0),relu)conv3_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)conv3_3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)self.branch2 = nn.Sequential(conv3_1, conv3_3,relu)conv5_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)conv5_5 = nn.Conv2d(out_channels, out_channels, kernel_size=5, stride=1, padding=2)self.branch3 = nn.Sequential(conv5_1,conv5_5,relu)max_pool_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)conv_max_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)self.branch4 = nn.Sequential(max_pool_1, conv_max_1,relu)def forward(self, input):output1 = self.branch1(input)output2 = self.branch2(input)output3 = self.branch3(input)output4 = self.branch4(input)return torch.cat([output1, output2, output3, output4], dim=1)model = InceptionModule(in_channels=3,out_channels=32)
inp = torch.rand(1,3,128,128)
print(model(inp).shape)
torch.Size([1, 128, 128, 128])当然,您可以在激活函数之前添加规范化层。但由于归一化技术不是很成熟,作者引入了两个辅助分类器。原因是:梯度消失问题)。
2.5 Inception V2, V3 (2015)
后来,在论文“重新思考计算机视觉的初始体系结构”中,作者基于以下原则改进了Inception模型:
-
将 5x5 和 7x7(在 InceptionV3 中)卷积分别分解为两个和三个 3x3 顺序卷积。这提高了计算速度。这与 VGG 的原理相同。
-
他们使用了空间上可分的卷积。简单地说,一个 3x3 内核被分解为两个较小的内核:一个 1x3 和一个 3x1 内核,它们按顺序应用。
-
初始模块变得更宽(更多特征图)。
-
他们试图在网络的深度和宽度之间以平衡的方式分配计算预算。
-
他们添加了批量规范化。
inception 模型的更高版本是 InceptionV4 和 Inception-Resnet。
2.6 ResNet:用于图像识别的深度残差学习(2015)
所有预先描述的问题(例如梯度消失)都通过两个技巧得到解决:
-
批量归一化和
-
短跳跃连接
而不是 ,我们要求他们模型学习差异(残差)
,这意味着
将是剩余部分 [4]。

来源:斯坦福大学2017年深度学习讲座:CNN架构
通过这个简单但有效的模块,作者设计了从18层(Resnet-18)到150层(Resnet-150)的更深层次的架构。
对于最深的模型,他们采用了 1x1 卷积,如右图所示:

图片来源:何开明等人,2015年。来源:用于图像识别的深度残差学习
瓶颈层(1×1)层首先减小然后恢复通道尺寸,使3×3层具有较少的输入和输出通道。
总的来说,这里是整个架构的草图:
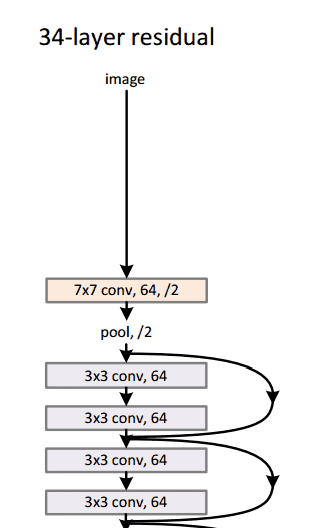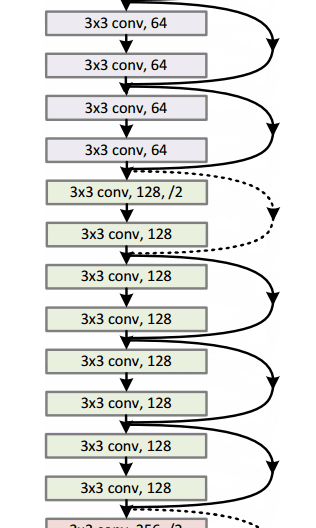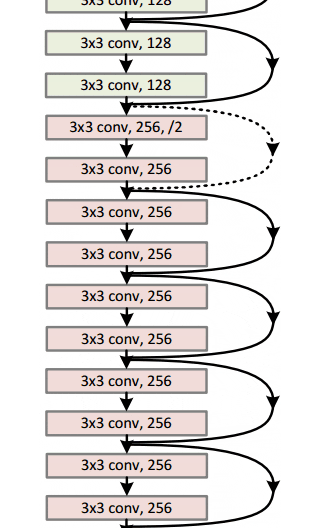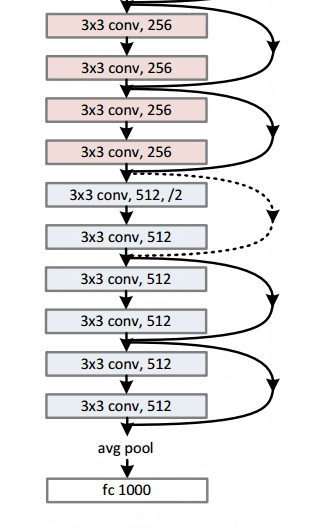
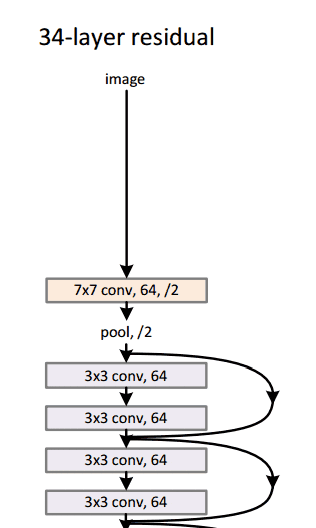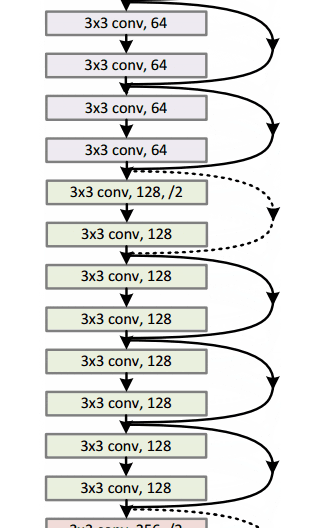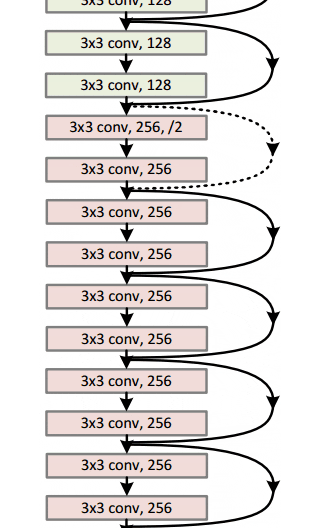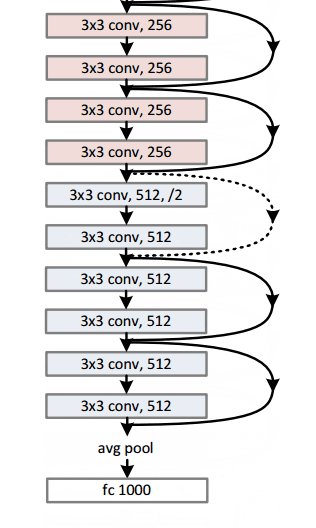
有关更多详细信息,您可以在ResNets上观看Henry AI Labs的精彩视频:
你可以通过直接从Torchvision导入一堆ResNet来玩它们:
import torchvision
pretrained = True# A lot of choices :P
model = torchvision.models.resnet18(pretrained)
model = torchvision.models.resnet34(pretrained)
model = torchvision.models.resnet50(pretrained)
model = torchvision.models.resnet101(pretrained)
model = torchvision.models.resnet152(pretrained)
model = torchvision.models.wide_resnet50_2(pretrained)
model = torchvision.models.wide_resnet101_2(pretrained)n.models.wide_resnet101_2(pretrained)
试试吧!
相关文章:
CNN成长路:从AlexNet到EfficientNet(01)
一、说明 在 10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。 如果我们在 Ima…...
使用IDEA操作Mysql数据库
idea中自带了关于数据库的连接 首先要确保你的MySQL正在运行中 打开idea找到database( view —> Tool Windows —> database),大家也可以定个快捷键,方便以后日常操作 就是这个样子,然后点加号 然后就可以编写执…...

ChatGPT下架官方检测工具,承认无法鉴别AI内容
去年底,OpenAI 推出的 ChatGPT ,带来了生成式人工智能涌现的热潮。它不仅能够协助完成撰写邮件、视频脚本、文案、翻译、代码等任务,还能通过学习和理解人类的语言来进行对话,并根据聊天的上下文进行互动。 但随之而来的争议也让人…...
方法、类名.class操作、通过运行时类获取其它信息)
Java通过实例调用getClass()方法、类名.class操作、通过运行时类获取其它信息
说明 Java Object类的getClass()函数,是通过对象调用的,是一个实例方法,该方法返回当前对象的运行时类。 通过类名.class可以获得和通过实例调用getClass()函数一样的信息。 获得运行时类以后,可以进一步获取其它信息。 代码示例…...
UE5+Paperzd问题
TopDown的2D游戏,遇到两个问题,第一问题是游戏一开始就会从tilemap上掉下去。第二个问题是没法和图层2上的物体做碰撞。 一、碰撞问题 1、创建的TileSet后,左侧选中一个tile后,一定要点击上边的Add Box,否则创建出来的…...
K8S系列文章之 自动化运维利器 Ansible
Ansible-安装 第一步:安装我们的epel扩展源 yum -y install epel-release 我这里会报/var/run/yum.pid 已被锁定,如果没有直接进行下一步 [rootmaster home]# yum -y install epel-release 已加载插件:fastestmirror, langpacks /var/run/…...
Julia 字典和集合
数组是一种集合,此外 Julia 也有其他类型的集合,比如字典和 set(无序集合列表)。 字典 字典是一种可变容器模型,且可存储任意类型对象。 字典的每个键值 key>value 对用 > 分割,每个键值对之间用逗…...
devops-发布vue前端项目
回到目录 将使用jenkinsk8s发布前端项目 1 环境准备 node环境 在部署jenkins的服务器上搭建node环境 node版本 # 1.拉取 https://nodejs.org/download/release/v20.4.0/node-v20.4.0-linux-x64.tar.gz# 2.解压到/usr/local目录下 sudo tar xf v20.4.0.tar.gz -C /usr/loc…...

使用正则表达式设置强密码
文章目录 例子和解析测试工具Java中的应用 例子和解析 强密码需要同时含有大写字母、小写字母、数字、特殊符号。 这边先展示我自己写的。 ^(?.*[a-z])(?.*[A-Z])(?.*[0-9])(?.*[!#$%?])[a-zA-Z0-9!#$%?_]{8,}$以上代8位以上的强密码。 下面是具体解析: ^代…...
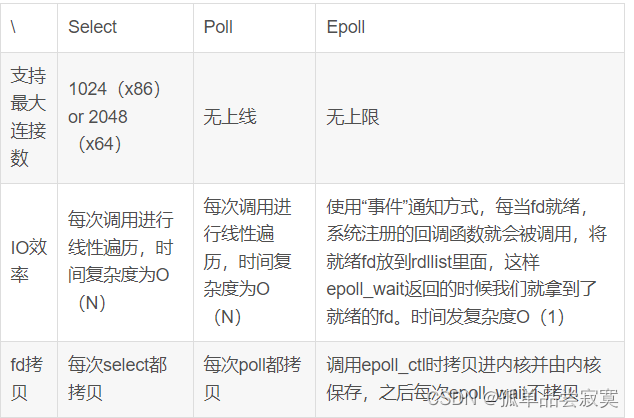
epoll、poll、select的原理和区别
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select&a…...
【学习笔记】Java安全之反序列化
文章目录 反序列化方法的对比PHP的反序列化Java的反序列化Python反序列化 URLDNS链利用链分析触发DNS请求 CommonCollections1利用链利用TransformedMap构造POC利用LazyMap构造POCCommonsCollections6 利用链 最近在学习Phith0n师傅的知识星球的Java安全漫谈系列,随…...
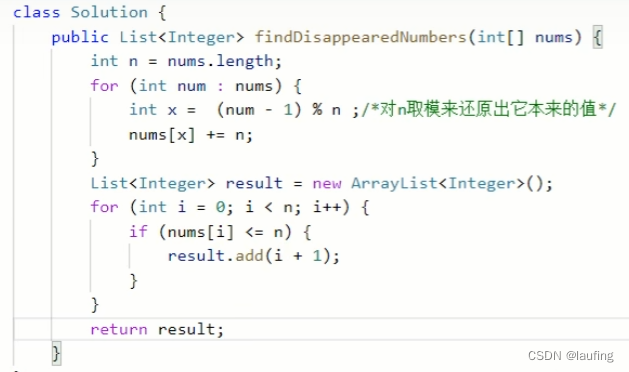
算法练习--leetcode 数组
文章目录 爬楼梯问题裴波那契数列两数之和 [数组]合并两个有序数组移动零找到所有数组中消失的数字三数之和 爬楼梯问题 输入n阶楼梯,每次爬1或者2个台阶,有多少种方法可以爬到楼顶? 示例1:输入2, 输出2 一次爬2阶&a…...

本地 shell无法连接centos 7 ?
1、首先检查是否安装ssh服务; yum list installed | grep openssh-server# 没有安装尝试安装下 yum install openssh-server 2、检查ssh服务是否开启 systemctl status sshd.service# 未开启,开启下 systemctl start sshd.service # 将sshd 服务添…...

C 语言的基本算术运算符 = + - * /
C 语言的基本算术运算符有: - * / 赋值运算符 赋值运算符左侧必须引用一个内存中的位置, 最简单的方法就是使用变量名, 也可以使用指针指向内存中的某个位置. 赋值表达式的目的是把值储存到目标内存位置上. 下面语句中的 表示初始化而不是赋值: const int …...

SQL注入实操三(SQLilabs Less41-50)
文章目录 一、sqli-labs靶场1.轮子模式总结2.Less-41 stacked Query Intiger type blinda.注入点判断b.轮子测试c.获取数据库名称d.堆叠注入e.堆叠注入外带注入获取表名f.堆叠注入外带注入获取列名g.堆叠注入外带注入获取表内数据 3.Less-42 Stacked Query error baseda.注入点…...

HOT77-买卖股票的最佳时机
leetcode原题链接:买卖股票的最佳时机 题目描述 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所…...
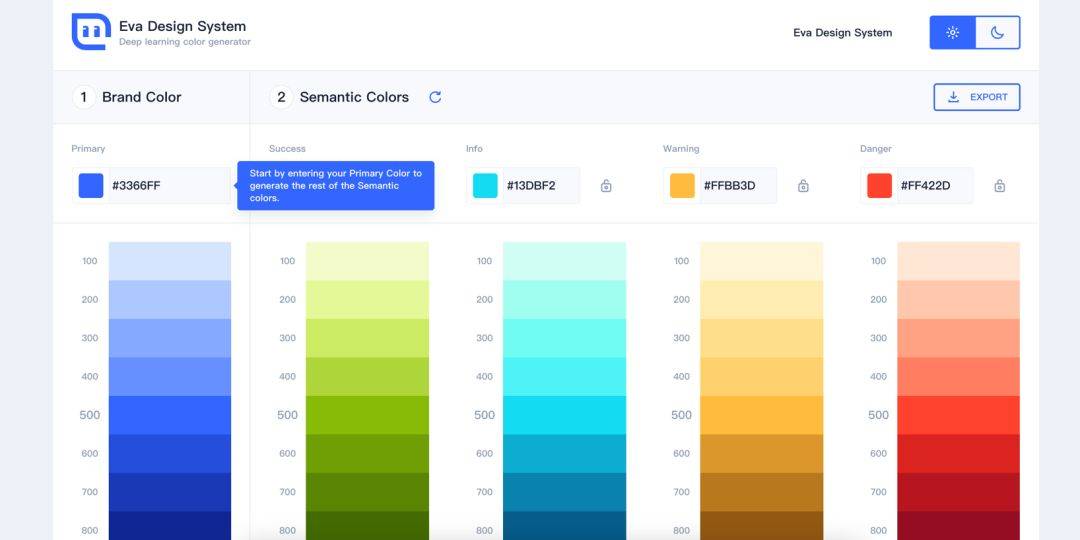
CSS调色网有哪些
本文章转载于湖南五车教育,仅用于学习和讨论,如有侵权请联系 1、https://webgradients.com/ Wbgradients 是一个在线调整渐变色的网站 ,可以根据你想要的调整效果,同时支持复制 CSS 代码,可以更好的与开发对接。 Wbg…...

Day10-NodeJS和NPM配置
Day10-NodeJS和NPM 一 Nodejs 1 简介 Nodejs学习中文网:https://www.nodeapp.cn/synopsis.html Nodejs的官网:https://nodejs.org/ 概念:Nodejs是JavaScript的服务端运行环境.Nodejs不是框架,也不是编程语言,就是一个运行环境. Nodejs是基于chrome V8引擎开发的一套js代码…...
线性代数 | 机器学习数学基础
前言 线性代数(linear algebra)是关于向量空间和线性映射的一个数学分支。它包括对线、面和子空间的研究,同时也涉及到所有的向量空间的一般性质。 本文主要介绍机器学习中所用到的线性代数核心基础概念,供读者学习阶段查漏补缺…...
Nios初体验之——Hello world!
文章目录 前言一、系统设计1、系统模块框图2、系统涉及到的模块1、时钟2、nios2_qsys3、片内存储(onchip_rom、onchip_ram)4、串行通信(jtag_uart)5、System ID(sysid_qsys) 二、硬件设计1、创建Qsys2、重命…...

PlotSquared完整指南:5分钟掌握Minecraft领地管理神器 [特殊字符]
PlotSquared完整指南:5分钟掌握Minecraft领地管理神器 🎮 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared PlotSquared是一个革命性的Minecraft领地管理插件&am…...
)
Perplexity Pro高阶用法深度解密:结合Obsidian/Notion实现知识自动蒸馏的完整链路(含可复用JSON Schema)
更多请点击: https://intelliparadigm.com 第一章:Perplexity Pro高阶用法深度解密:结合Obsidian/Notion实现知识自动蒸馏的完整链路(含可复用JSON Schema) Perplexity Pro 的 API 提供了结构化响应能力,配…...

4步让旧款Mac焕发新生:OpenCore Legacy Patcher完全指南
4步让旧款Mac焕发新生:OpenCore Legacy Patcher完全指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果官方放弃支持的旧款Ma…...

新手入门指南使用 Python 快速调用 TaoToken 多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门指南:使用 Python 快速调用 TaoToken 多模型服务 对于刚接触大模型 API 的开发者而言,面对众多模型…...

前端地图开发避坑指南:解决天地图、高德、百度坐标偏移的完整JS方案
前端地图开发避坑指南:解决天地图、高德、百度坐标偏移的完整JS方案 当你在物流轨迹系统中发现GPS设备采集的坐标在高德地图上偏离实际位置500米,或在门店选址工具里百度地图的围栏总是无法匹配真实建筑轮廓时,这背后隐藏着中国地图服务特有…...

DriverStore Explorer:Windows驱动存储管理的终极解决方案与实战指南
DriverStore Explorer:Windows驱动存储管理的终极解决方案与实战指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer DriverStore Explorer(简称RAPR)…...

Rdkit实战:从2D到3D,解锁分子构象生成与优化的全流程
1. 从2D到3D:分子构象生成的基础概念 第一次接触分子构象生成时,我完全被各种术语搞晕了——距离几何、ETKDG、MMFF这些名词听起来就像天书。直到用RDKit实际操作了几次,才发现这个过程其实就像搭积木:先有个平面设计图ÿ…...

3步高效下载抖音无水印视频:douyin_downloader专业解决方案完整指南
3步高效下载抖音无水印视频:douyin_downloader专业解决方案完整指南 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader …...

抖音批量下载神器:一键保存多个创作者的所有视频作品
抖音批量下载神器:一键保存多个创作者的所有视频作品 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 在当前短视频内容爆炸的时代,抖音汇聚了无数创意视频和优质内容。无论是学习舞蹈…...

零基础极速上手教程:用AI建站工具10分钟生成你的第一个网站
你是不是也想过拥有一个属于自己的网站,但总觉得那是程序员才干得了的事?或者你曾经试过一些建站工具,结果被复杂的后台、密密麻麻的选项和所谓的「可视化拖拽」搞得晕头转向?别担心,今天这篇教程,就是专门…...