爬虫获取电影数据----以沈腾参演电影为例
数据可视化&分析实战
1.1 沈腾参演电影数据获取
文章目录
- 数据可视化&分析实战
- 前言
- 1. 网页分析
- 2. 构建数据获取函数
- 2.1 网页数据获取函数
- 2.2 网页照片获取函数
- 3. 获取参演影视作品基本数据
- 4. 电影详细数据获取
- 4.1 导演、演员、描述、类型、投票人数、评分信息、电影海报获取
- 4.1.1 电影海报获取(以超能一家人为例):
- 4.1.2 导演、演员信息获取:
- 4.1.3 描述、类型、投票人数、评分信息获取:
- 4.2 IMDb号、感兴趣的人数,看过的人数信息获取
- 4.2.1 IMDb号获取:
- 4.2.2 感兴趣的人数,看过的人数信息获取:
- 4.3 详细信息获取全代码
- 总结
前言
大家好✨,这里是bio🦖。今天为大家带来的是数据获取的一种方法,网络爬虫(Web Crawler)。是一种自动化程序,用于在互联网上获取信息、抓取网页内容并进行数据收集。网络爬虫通过访问网页的链接,并从中提取信息和数据,然后将这些数据保存或用于后续处理和分析。
网络爬虫的工作流程通常包括以下几个步骤:
- 发送请求:网络爬虫首先发送HTTP请求到指定的URL,请求获取网页内容。
- 获取响应:网站服务器接收到请求后,会返回相应的网页内容作为HTTP响应。爬虫会获取并接收这个响应内容。
- 解析网页:爬虫会对网页内容进行解析,提取出需要的数据和信息。通常使用HTML解析器或XPath等技术来解析网页的结构和元素。
- 数据提取:从解析的网页中,爬虫会提取出感兴趣的数据,如文字、图片、链接等。
- 存储数据:爬虫将提取的数据保存到数据库、文件或其他存储介质中,以备后续分析和应用。
通过本文获取电影数据信息,为后续的数据可视化提供数据支撑~
1. 网页分析
数据来源于豆瓣电影网,在豆瓣电影网搜索演员沈腾,找到他参演的所有作品(沈腾参演作品)。打开页面发现沈腾一共参演134部作品,其中第一页所有作品均未上映,所以之后获取数据时,可以不用关注第一页。其次应该关注网页链接,查看不同网页链接之间的差异,以便于批量获取数据。

下面是各个页面的链接,通过观察不难看出各个链接之间的差异在start=后的数字,第一页是0,第二页是1,第三页是2……最后一页是13。在上文中说到第一页的所有电影均未上映,未上映的电影没有后续数据可视化可用的数据,故不用获取。使用1到13的循环,便可获取沈腾参演的所有电影数据。
https://movie.douban.com/celebrity/1325700/movies?start=0&format=pic&sortby=time&
https://movie.douban.com/celebrity/1325700/movies?start=10&format=pic&sortby=time&
https://movie.douban.com/celebrity/1325700/movies?start=20&format=pic&sortby=time&
…
https://movie.douban.com/celebrity/1325700/movies?start=130&format=pic&sortby=time&
2. 构建数据获取函数
2.1 网页数据获取函数
由于网络爬虫的访问网站的速度很快,会给网站服务器增加负担,因此网站会设置反爬机制。
为了防止网站检测出来,使用header参数伪造浏览器信号。
然后使用requests包获取网页数据,对获得的文本数据使用gbk编码,同时遗忘不能被gbk编码的数据
最后使用BeautifulSoup对获取的数据转化成html格式。
# time: 2023.07.26
# author: bio大恐龙# define a function to get website infomation with html format
import requests
from bs4 import BeautifulSoupdef get_url_info(url):headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'}try:info = requests.get(url, headers=headers).text.encode('gbk', 'ignore').decode('gbk')soup = BeautifulSoup(info, 'html.parser')return soupexcept:print('Sorry! The film information is not got')
2.2 网页照片获取函数
每个电影都有自己的海报,具有观赏价值。获取的图片数据是二进制数据,所有当保存照片是使用b(二进制写入)。其他代码注释同网页数据获取函数。
# define a function to download film poster
def download_image(url, save_path):headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'}try:image = requests.get(url, headers=headers).contentwith open(save_path, 'wb') as f:f.write(image)except:print('Sorry! failure to download the image')
3. 获取参演影视作品基本数据
通过网页数据获取函数get_url_info()获取一个任意一个网页的信息,这里以最后一页为例。首先获取参演影视作品(不一定是电影)的名字,URL和年份,之后根据影视作品的URL获取具体信息。
在获取的网页信息中发现,想获得的数据在h6下,因此可以使用BeautifulSoup的find()去获取我们想要的信息。例如,获取年份信息可以使用html_content.find('span').text.strip('()'),其中.text是返回文本信息,strip('()')是去除括号。(假设你已经使用了find(h6)得到了下面html的内容),
<img alt="案发现场2" class="" src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2466501379.jpg" title="案发现场2"/>
</a>
</dt>
<dd>
<h6>
<a class="" href="https://movie.douban.com/subject/3151813/">案发现场2</a><span class="">(2007)</span><span class="">[ 演员 (饰 夏晓强) ]</span>
</h6>
同理,可以获得影视数据的名字、URL。获取第二页到第十四页所有影视作品的基本信息,代码如下,思路与寻找一致。
import pandas as pd
import time# construct a dataframe to store movies shenteng involved in information
shenteng_movies_df = pd.DataFrame(columns=['Film_Name', 'URL', 'Year'])'''
the urls of website were constructed as following url with difference in "start" and total pages are 13
'https://movie.douban.com/celebrity/1325700/movies?start=10&format=pic&sortby=time&'
'https://movie.douban.com/celebrity/1325700/movies?start=20&format=pic&sortby=time&'
'''
df_index = 0
website_list = list(range(1,14))for i in website_list:movie_info = get_url_info(f'https://movie.douban.com/celebrity/1325700/movies?start={i}0&format=pic&sortby=time&')interest_info = movie_info.find_all('h6')#print(interest_info[0].find('span'))#breakfor k in range(len(interest_info)):movie_year = interest_info[k].find('span').text.strip('()')movie_url = interest_info[k].find('a')['href']movie_name = interest_info[k].find('a').textshenteng_movies_df.loc[df_index] = [movie_name, movie_url, movie_year]df_index += 1time.sleep(10)
获取的结果如下,对应的CSV文件可以从CSDN资源库中下载——沈腾参演影视作品基础信息。

4. 电影详细数据获取
由于后续是想做数据可视化,故拟获取电影名称、URL、年份、导演、演员、类型、投票人数、评分、IMDb号、描述、感兴趣的人数,看过的人数。名称、URL、年份在上一步中已经获取了,这一步主要是为了获取剩余信息,由于部分信息不是电影、且部分电影信息不含有投票人数、感兴趣人数等,需要不断调试,故对最后的全部代码解释可能不全面,如果你没有看懂,欢迎留言or私信。
4.1 导演、演员、描述、类型、投票人数、评分信息、电影海报获取
4.1.1 电影海报获取(以超能一家人为例):
通过2.1、2.2定义的get_url_info(),download_iamge()函数,在下面的html信息中可以看到"image": "https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2890369636.jpg"在<script type="application/ld+json">一栏下,所以首先通过find()函数提取这部分信息,然后通过json.load()函数将html格式转换为字典形式,然后根据键名提取对应的值。代码如下:
json_data = json.load(movie_info.find('script', type="application/ld+json").string.strip()) # 假设movie_info你通过get_url_info()获取的电影信息数据
image_url = json_data['image'] # 提取图片url
downloaw_image(image_url, save_path) # 下载图片
获取的海报共计27张,也就是说总共27部电影~~
4.1.2 导演、演员信息获取:
通过之前转换的字典格式数据,可以轻松获取导演、演员信息。这里只获取中文名
director = json_data['director'][0]['name'].split()[0]
actors = str([i['name'].split()[0] for i in json_data['actor']]).strip('[]')
4.1.3 描述、类型、投票人数、评分信息获取:
同理,运用字典的键值对提取信息即可
genre = str(json_data['genre']).strip('[]') # 类型
rating_count = json_data['aggregateRating']['ratingCount'] # 投票人数
rating_value = json_data['aggregateRating']['ratingValue'] # 评分
description = json_data['description'] # 描述
html信息:
<script type="application/ld+json">
{"@context": "http://schema.org","name": "超能一家人","url": "/subject/35228789/","image": "https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2890369636.jpg","director": [{"@type": "Person","url": "/celebrity/1350407/","name": "宋阳 Yang Song"}]
,"author": [{"@type": "Person","url": "/celebrity/1350407/","name": "宋阳 Yang Song"},{"@type": "Person","url": "/celebrity/1375192/","name": "毕慷 Kang Bi"}]
,"actor": [{"@type": "Person","url": "/celebrity/1350408/","name": "艾伦 Allen"},{"@type": "Person","url": "/celebrity/1325700/","name": "沈腾 Teng Shen"}]
,"datePublished": "2023-07-21","genre": ["\u559c\u5267", "\u5bb6\u5ead", "\u5947\u5e7b"],"duration": "PT1H53M","description": "郑前(艾伦 饰)新开发的APP被狡猾又诚实的反派乞乞科夫(沈腾 饰)盯上了。幸好郑前一家人意外获得了超能力,姐姐会飞天,爸爸能隐身,爷爷不死术,妹妹力大无穷。郑前本指望家人们出手帮忙,一家人却常常出糗...","@type": "Movie","aggregateRating": {"@type": "AggregateRating","ratingCount": "60348","bestRating": "10","worstRating": "2","ratingValue": "4.0"}
}
4.2 IMDb号、感兴趣的人数,看过的人数信息获取
4.2.1 IMDb号获取:
IMDb在html信息中如下所示,在span class="pl"下,所以通过find()函数获取该信息所在位置,然后使用next_sibling获取兄弟节点的信息即可,代码如下
movie_info.find('span', class_='pl', text="IMDb:").next_sibling.strip()
html信息:
<span class="pl">IMDb:</span> tt12787014<br/>
4.2.2 感兴趣的人数,看过的人数信息获取:
该信息位于<div class="subject-others-interests-ft">下,所以先通过find_all()找到信息所在位置,然后提取相关信息即可,代码如下:
tem_info = movie_info.find("div", class_="subject-others-interests-ft").find_all('a')
interest_count = tem_info[0].text.split('人')[0]
watched_count = tem_info[1].text.split('人')[0]
html信息:
<div class="subject-others-interests-ft">
<a href="https://movie.douban.com/subject/35228789/comments?status=P">62456人看过</a>/ <a href="https://movie.douban.com/subject/35228789/comments?status=F">36999人想看</a>
</div>
4.3 详细信息获取全代码
其中很多过滤条件是为了筛选掉不属于电影类型的数据,同时为了防止部分电影数据信息缺失造成脚本报错,引入了Tag,是beautifulsoup中的一种类型。
其中[\x00-\x1F\x7F-\x9F]是不能被转义的符号,故进行替换,防止脚本报错。
json_data = re.sub(r'[\x00-\x1F\x7F-\x9F]', '', movie_info.find('script', type="application/ld+json").string.strip())
最后获得的表现如图所示,对应的CSV文件可以从CSDN资源库中下载——沈腾参演电影详细信息:

import json
import os
from bs4.element import Tag
import re# create a directory to store the posters of film
dir_path = '/mnt/c/Users/ouyangkang/Desktop/film_poster/'
if not os.path.exists(dir_path):os.makedirs(dir_path)# construct a dataframe to store new infomation of films
films_detail_df = pd.DataFrame(columns=['Film_name', 'URL', 'Year', 'Director', 'Actors', 'Genre', 'Rating_count', 'Rating_value', 'IMDb', 'Description', 'Interesting_count', 'Watched_count'])
# index
initial_number = 0for single_movie_url in shenteng_movies_df['URL'].tolist():time.sleep(4)movie_info = get_url_info(single_movie_url)# screen non-film infomation and not yet shownif isinstance(movie_info.find('div', class_="rating_sum"), Tag):if "暂无" not in movie_info.find('div', class_="rating_sum").text and "尚未" not in movie_info.find('div', class_="rating_sum").text: # construct directory data foramtjson_data = re.sub(r'[\x00-\x1F\x7F-\x9F]', '', movie_info.find('script', type="application/ld+json").string.strip())json_data = json.loads(json_data)if json_data['@type'] == 'Movie' and json_data['aggregateRating']['ratingValue'] != "" and json_data['description'] != "" and "真人秀" not in json_data['genre'] and "脱口秀" not in json_data['genre'] and '歌舞' not in json_data['genre']:# namename = shenteng_movies_df[shenteng_movies_df["URL"] == single_movie_url]['Film_Name'].tolist()[0]# urlurl = single_movie_url# yearyear = shenteng_movies_df[shenteng_movies_df["URL"] == single_movie_url]['Year'].tolist()[0]# directordirector = json_data['director'][0]['name'].split()[0]# actorsactors = str([i['name'].split()[0] for i in json_data['actor']]).strip('[]') # only chinese name# genregenre = str(json_data['genre']).strip('[]')# rating countrating_count = json_data['aggregateRating']['ratingCount']# rating valuerating_value = json_data['aggregateRating']['ratingValue']# IMDbif isinstance(movie_info.find('span', class_='pl', text="IMDb:"), Tag):imdb = movie_info.find('span', class_='pl', text="IMDb:").next_sibling.strip()else:imdb = None# descriptiondescription = json_data['description']# how many people are interested in the film and had watchedif isinstance(movie_info.find("div", class_="subject-others-interests-ft"), Tag):tem_info = movie_info.find("div", class_="subject-others-interests-ft").find_all('a')interest_count = tem_info[0].text.split('人')[0]watched_count = tem_info[1].text.split('人')[0]else:interest_count = Nonewatched_count = None# poster urlimage_url = json_data['image']films_detail_df.loc[initial_number] = [name, url, year, director, actors, genre, rating_count, rating_value, imdb, description, interest_count, watched_count]initial_number += 1time.sleep(8)save_path = dir_path + name + '.jpg'download_image(image_url, save_path)time.sleep(8)films_detail_df.head()
# conserve file
# films_detail_df.to_csv('/mnt/c/Users/ouyangkang/Desktop/films_info.csv', index=None, encoding='gbk')
总结
本文向大家介绍如何获取网页信息(以电影信息为例),但是相关的函数功能并没有详细介绍,如果你有疑问可以留言、私信或者自行百度,这里向大家提供的是一个思路,先定位信息的位置,然后通过将html数据转换为字典数据提取相关信息,当然你也可以使用正则表达式提取你想提取的信息。感谢大家的观看,如果期待后续的可视化文章,点点关注不迷路~
相关文章:
爬虫获取电影数据----以沈腾参演电影为例
数据可视化&分析实战 1.1 沈腾参演电影数据获取 文章目录 数据可视化&分析实战前言1. 网页分析2. 构建数据获取函数2.1 网页数据获取函数2.2 网页照片获取函数 3. 获取参演影视作品基本数据4. 电影详细数据获取4.1 导演、演员、描述、类型、投票人数、评分信息、电影海…...

网页版Java(Spring/Spring Boot/Spring MVC)五子棋项目(二)前后端实现用户的登录和注册功能【用户模块】
网页版Java五子棋项目(二)前后端实现用户的登录和注册功能【用户模块】 在用户模块我们要清楚要完成的任务一、MyBatis后端操作数据库1. 需要在数据库创建用户数据库1. 用户id2. 用户名3. 密码4. 天梯积分5. 总场数6. 获胜场数 2. 创建用户类User和数据库…...

2023年华数杯数学建模A题思路代码分析 - 隔热材料的结构优化控制研究
# 1 赛题 A 题 隔热材料的结构优化控制研究 新型隔热材料 A 具有优良的隔热特性,在航天、军工、石化、建筑、交通等 高科技领域中有着广泛的应用。 目前,由单根隔热材料 A 纤维编织成的织物,其热导率可以直接测出;但是 单根隔热…...
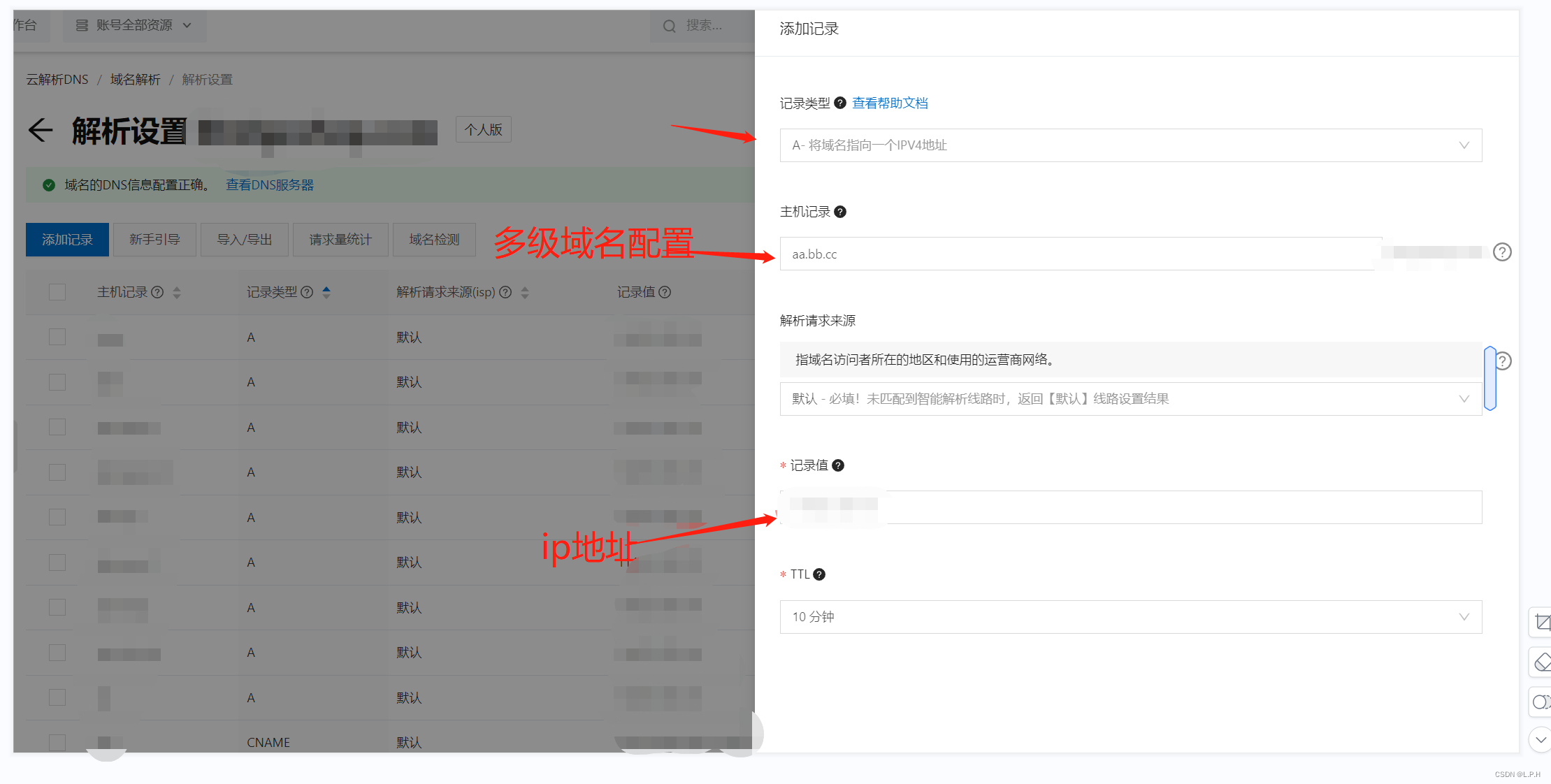
阿里云二级域名配置
阿里云二级域名配置 首先需要进入阿里云控制台的域名管理 1.选择域名点击解析 2.添加记录 3.选择A类型 4.主机记录设置【可以aa.bb或者aa.bb.cc】 到时候会变成:aa.bb.***.com 5.解析请求来源设置为默认 6.记录值 设置为要解析的服务器的ip地址 7.TTL 默认即…...

Webpack5 动态导入按需加载
文章目录 一、 什么是动态导入和按需加载?二、 具体用法示例二、 总结 一、 什么是动态导入和按需加载? 传统上,在Webpack中,我们使用import语句可以在代码中静态地导入模块。这意味着所有的模块都会在构建时被打包到bundle中。然…...

【Linux操作系统】Ubuntu和center两个Linux发行版本中指令的区别
Ubuntu和center是Linux的两个发行版本,本文将详细介绍两个发行版的使用命令区别,分析两者的优缺点。 文章目录 常见的区别:细节差异:两个发行版本各自的优点和缺点Ubuntu 的优点:Ubuntu 的缺点:CentOS 的优…...
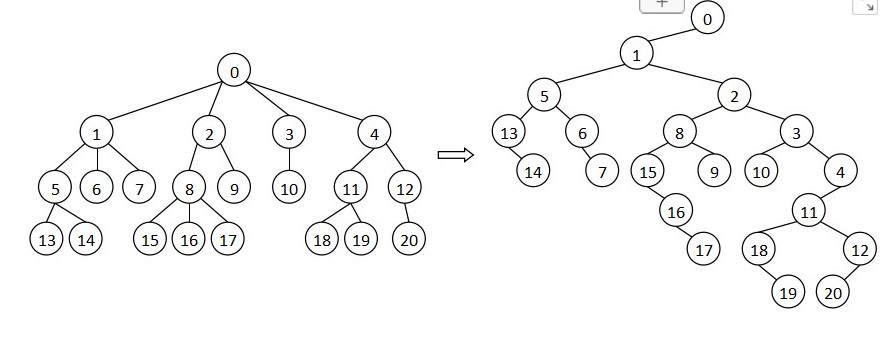
c++基本数据结构
void insert(const node *head, node *p) {node *x, *y;yhead;do{xy;yx->next;} while ((y!NULL) && (y->value < p->value);x->nextp;p->nexty; } 二.栈 (1) 栈的实现! 操作规则:先进后出,先出后进。 int stack[N], top0; /…...
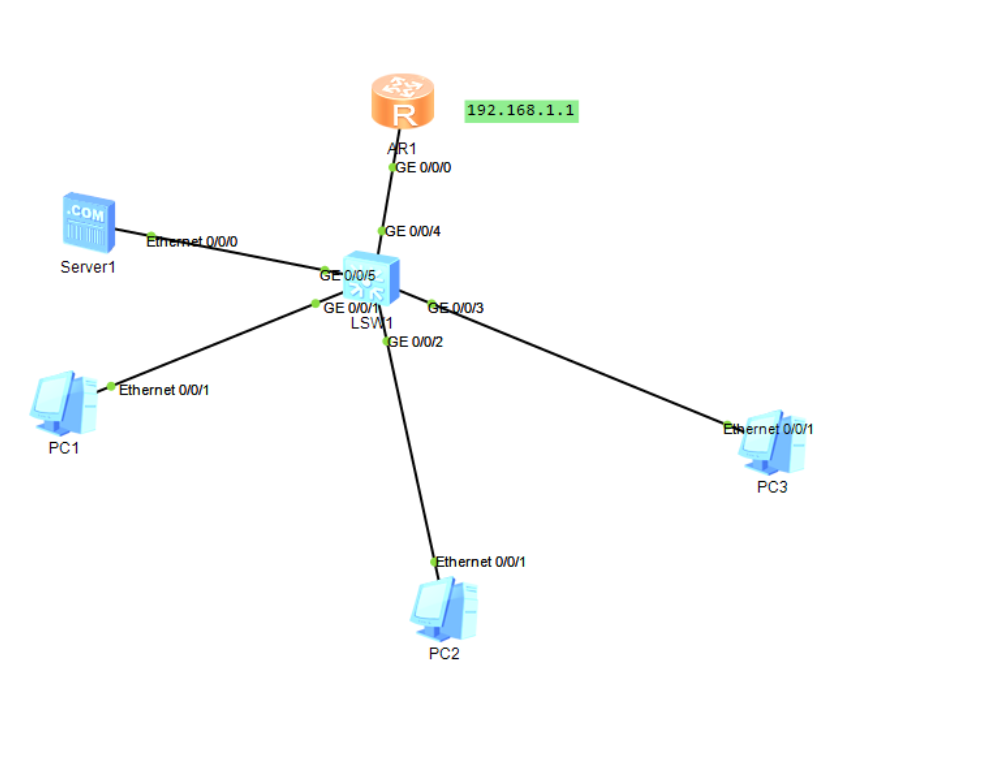
路由器DHCP实验
拓扑图 配置 # 配置ip地址并开启dhcp [Huawei]int g0/0/0 [Huawei-GigabitEthernet0/0/0]ip addr 192.168.1.1 255.255.255.0 [Huawei-GigabitEthernet0/0/0]dhcp enable## 配置dns地址 [Huawei-GigabitEthernet0/0/0]dhcp dns-list 192.168.1.5## 指定某个接口开通DHCP 功能…...

Linux 电源子系统之充电、放电、低功耗
在嵌入式产品中,有三个重要模块:充电、放电、低功耗。 1、充电 charging 1、开关电源基本原理 2、线性充电和开关电源硬件电路图分析 3、Battery_Charging_v1.2 spec 4、typec spec 5、typec-PD spec 6、Uevent 在 Android 层的实现 7、battery service 监听 uevent 事件以…...

捕捉时刻:将PDF文件中的图像提取为个性化的瑰宝(从pdf提取图像)
应用场景: 该功能的用途是从PDF文件中提取图像。这在以下情况下可能会很有用: 图片提取和转换:可能需要将PDF文件中的图像提取出来,并保存为单独的图像文件,以便在其他应用程序中使用或进行进一步处理。例如ÿ…...

【基础类】—HTTP协议类
一、HTTP协议的主要特点 简单快速:每个资源URI是固定的,访问某个资源输入URI即可灵活:在每一个HTTP协议中,请求头部分有一个数据类型,通过一个HTTP协议可以完成不同的数据类型传输无连接:连接一次就会断开…...

【Qt高级】QThread与QTimer组合使用引出的信号槽执行在哪个线程的思考【2023.08.06】
源码见 testQThread_QTimer… Qt 版本5.6.3 视频讲解:https://www.bilibili.com/video/BV15P411C79i/ 链接: 视频讲解 简介 想法很单纯,就是主线程启动一个子线程,子线程里启动一个定时器,定时执行一些任务,然鹅实际开…...
用于大型图像模型的 CNN 内核的最新内容
一、说明 由于OpenAI的ChatGPT的巨大成功引发了大语言模型的繁荣,许多人预见到大图像模型的下一个突破。在这个领域,可以提示视觉模型分析甚至生成图像和视频,其方式类似于我们目前提示 ChatGPT 的方式。 用于大型图像模型的最新深度学习方法…...

索尼电视怎么完全关机
索尼电视怎么完全关机 当用户想要关闭索尼电视时,可能会遇到一些问题。例如,他们可能会遇到如何完全关闭电视的问题。在本文中,我们将介绍如何完全关闭索尼电视。 首先,您需要找到索尼电视的电源按钮。通常,该按钮位…...
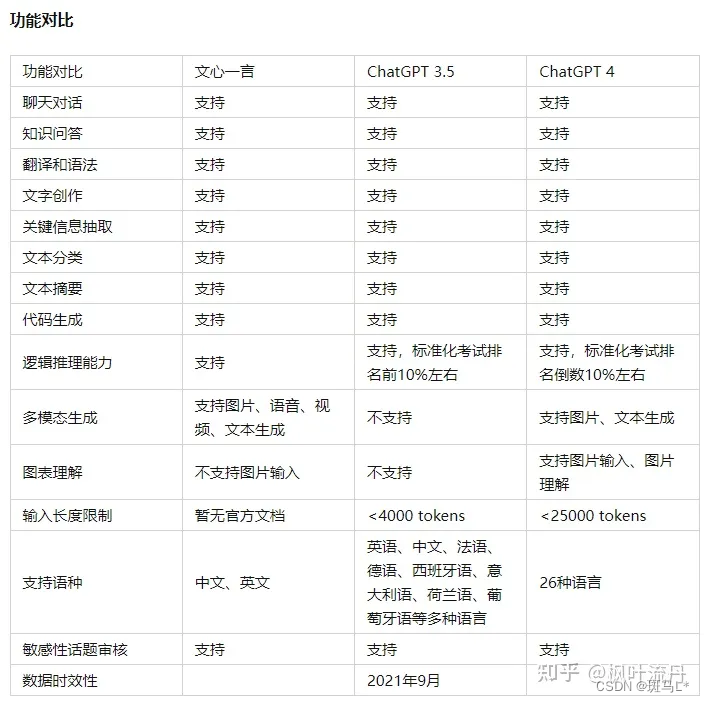
AI介绍——chat gpt/文心一言/claude/bard/星火大模型/bing AI
AI体验 1. AI 介绍(注册和使用)1.1 Chat GPT1.2 文心一言1.3 Slack 上的 Claude1.3.1 Claude 介绍1.3.2 Claude 使用 1.4 Google的Bard1.4.1 Bard 介绍1.4.2 Bard 使用 1.5 科大讯飞的星火大模型1.5.1 星火大模型 介绍1.5.2 星火大模型 使用 1.6 new bin…...
C++ 访问控制——公有继承、私有继承、保护继承
派生类继承了基类的全部数据成员和除了构造函数和析构函数之外的全部函数成员,但是这些成员的访问属性在派生的过程中是可以调整的。从基类继承的成员,其访问属性由继承方式控制。 基类的成员有public(公有)、protectedÿ…...

python性能调试
py-spy生成cpu火焰图 ft5.svg env/xxxx/bin pid26443$env/py-spy record -o /tmp/$f --pid $pid --nativememray实时查看内存 env/xxxx/bin$env/python -m memray run --live --trace-python-allocators --native run_demo.pymemray生成内存火焰图报告 frun_demo_042.bin en…...

738. 单调递增的数字
738. 单调递增的数字 当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。 给定一个整数 n ,返回 小于或等于 n 的最大数字,且数字呈 单调递增 。 示例 1: 输入: n 10 输出: 9示例 2: 输入: n 1234 输出…...

ssh安全远程管理
目录 1、什么是ssh 2、ssh登陆 3、ssh文件传输 1、什么是ssh ssh是 Secure Shell 的缩写,是一个建立在应用层上的安全远程管理协议。ssh 是目前较为可靠的传输协议,专为远程登录会话和其他网络服务提供安全性。利用ssh 协议可以有效防止远程管理过程中…...
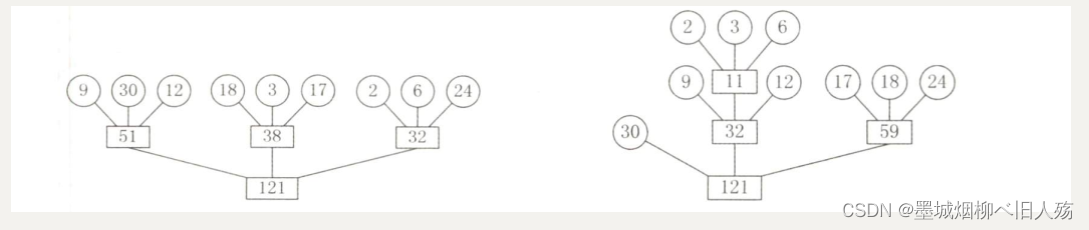
外部排序算法总结
一.内排总结 在之前博客里,博主已经介绍了各种内部排序算法的原理和C语言代码实现,不懂的朋友可以在同系列专栏里选择查看,今天介绍常见排序算法的最后一点,也就是外部排序。在此之前,我们先对外部排序的各种算法做一…...

如何快速掌握unnpk:网易游戏资源解包的完整入门指南
如何快速掌握unnpk:网易游戏资源解包的完整入门指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 你是否曾经好奇过网易游戏《阴阳师》中那些精美的角色立绘…...

终极指南:如何在Windows上免费扩展虚拟显示器,轻松打造多屏工作空间
终极指南:如何在Windows上免费扩展虚拟显示器,轻松打造多屏工作空间 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc …...

obamify跨平台兼容性解决方案:从桌面到Web的完美迁移指南
obamify跨平台兼容性解决方案:从桌面到Web的完美迁移指南 【免费下载链接】obamify revolutionary new technology that turns any image into obama 项目地址: https://gitcode.com/gh_mirrors/ob/obamify 想要在任何设备上将图片转换为奥巴马风格吗&#x…...

AdvancedLiterateMachinery的LORE-TSR:逻辑位置回归网络在表格结构识别中的突破
AdvancedLiterateMachinery的LORE-TSR:逻辑位置回归网络在表格结构识别中的突破 【免费下载链接】AdvancedLiterateMachinery A collection of original, innovative ideas and algorithms towards Advanced Literate Machinery. This project is maintained by the…...

深入解析ACP Bridge:构建高效微服务通信与数据同步的协议转换桥梁
1. 项目概述与核心价值最近在折腾一个跨平台数据同步的项目,遇到了一个挺有意思的组件——allvegetable/acp-bridge。乍一看这个名字,可能会有点摸不着头脑,acp是什么?bridge又在这里扮演什么角色?实际上,这…...

AI Coding 言出法随,未来什么还会值钱?
本文整理自播客《AI炼金术》任鑫(云九资本)与徐文浩的深度对话,探讨 AI Coding 如何重塑个人开发方式、组织形态,以及在生产力极大释放的时代,究竟什么能力还会持续增值。—本文资料通过Ai好记智能解析获取。一、AI Co…...
的完整避坑指南:从SPI配置到LVGL局部刷新修复)
ESP32S3驱动1.3寸圆形AMOLED屏(RM67162芯片)的完整避坑指南:从SPI配置到LVGL局部刷新修复
ESP32S3驱动1.3寸圆形AMOLED屏(RM67162芯片)全流程实战:从SPI配置到LVGL优化 这块1.3寸圆形AMOLED屏幕以其出色的显示效果和独特的外形设计,在智能穿戴设备和小型嵌入式项目中越来越受欢迎。然而,当它与ESP32S3开发板结…...
)
FPGA新手必看:用Verilog手搓一个SPI Master控制器(Mode 0/3实战)
FPGA实战:从零构建SPI Master控制器的Verilog实现指南 1. 初识SPI协议与FPGA开发环境搭建 对于刚接触FPGA和数字电路设计的工程师来说,SPI(Serial Peripheral Interface)协议是一个理想的起点。这种同步串行通信协议广泛应用于传感…...

Apache RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景
本文将从技术角度了解 RocketMQ 的云原生架构,了解 RocketMQ 如何基于一套统一的架构支撑多元化的场景。 文章主要包含三部分内容。首先介绍 RocketMQ 5.0 的核心概念和架构概览;然后从集群角度出发,从宏观视角学习 RocketMQ 的管控链路、数…...

RocketMQ 源码解析——Controller 高可用切换架构
延伸阅读:🔍「RocketMQ 中文社区」 持续更新源码解析/最佳实践,提供 RocketMQ 专家 AI 答疑服务 一、原理及核心概念浅述 1.1 核心架构 1.2 核心概念 controller:负责管理broker间的主备关系,可以挂在namesrv中&…...