Pytorch Tutorial【Chapter 3. Simple Neural Network】
Pytorch Tutorial【Chapter 3. Simple Neural Network】
文章目录
- Pytorch Tutorial【Chapter 3. Simple Neural Network】
- Chapter 3. Simple Neural Network
- 3.1 Train Neural Network Procedure训练神经网络流程
- 3.2 Build Neural Network Procedure 搭建神经网络
- 3.3 Use Loss Function to Backward 利用损失函数进行反向传播
- 3.4 Update Parameter of NN 更新神经网络参数
- 3.4.1 Update Manually手动更新参数
- 3.4.2 Update Automatically自动更新参数
- Reference
Chapter 3. Simple Neural Network
3.1 Train Neural Network Procedure训练神经网络流程
一个典型的神经网络训练过程包括以下几点:
-
定义一个包含可训练参数的神经网络
-
迭代整个输入
-
通过神经网络处理输入
-
计算损失(loss)
-
反向传播梯度到神经网络的参数
-
更新网络的参数,典型的用一个简单的更新方法:weight = weight - learning_rate *gradient
3.2 Build Neural Network Procedure 搭建神经网络
- 定义一个类并继承
torch.nn.Moulde - 使用类
torch.nn中的组件和torch.nn.functional中的组件来搭建网络结构 - 改写该类的
forward方法,在此方法中,进一步完善网络结构(如激活函数,池化层等),并且获得返回值的输出
先简要介绍一下需要使用到的torch.nn组件
torch.nn.Conv2d(in_channels, out_channels, kernel_size)进行卷积操作,输入是 ( N , C i n , H , W ) (N, C_{in},H,W) (N,Cin,H,W),输出是 ( N , C o u t , H , W ) (N,C_{out},H,W) (N,Cout,H,W)(详见Conv2d),卷积对图片尺寸的影响如下

torch.nn.Linear(in_features, out_features)进行放射变换操作(affine mapping),即 y = x A T + b y=xA^T+b y=xAT+b,(详见Linear)torch.nn.Flatten(start_dim=1, end_dim=- 1),将连续的范围展平为张量(详见Flatten)
再介绍一下需要使用到的torch.nn.functional组件
-
torch.nn.functional.relu(),对输入使用Relu激活函数,具体操作是对每个元素都进行 ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x)=\max(0,x) ReLU(x)=max(0,x)的计算,(详见ReLu) -
torch.nn.functional.softmax(),对输入使用Softmax激活函数,具体操作是对每个元素都进行 Softmax ( x i ) = exp ( x i ) ∑ j exp ( x j ) \text{Softmax}(x_i)=\frac{\exp(x_i)}{\sum_{j}\exp(x_j)} Softmax(xi)=∑jexp(xj)exp(xi)(详见Softmax) -
torch.nn.functional.max_pool2d(input, kernel_size, stride), 进行最大池化操作,输入是KaTeX parse error: Expected 'EOF', got '_' at position 28: …atch}, \text{in_̲channels}, iH,i…,详见Max_Pool2D)
例如下述代码,我们要搭建一个下图的神经网络结构
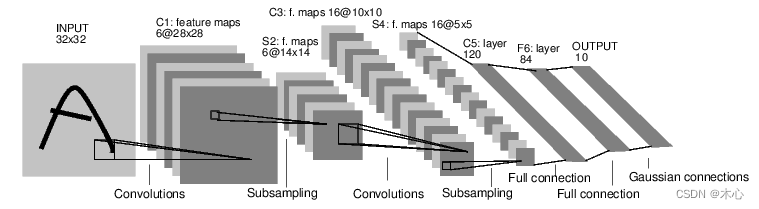
输入是 [ batch , channels , height , weight ] [\text{batch},\text{channels},\text{height},\text{weight}] [batch,channels,height,weight]的图片,分别代表批量大小、通道数、图像的高度、图像的宽度。在我们取批量大小为 1 1 1,然后这个例子变成 [ 1 , 1 , 32 , 32 ] [1,1,32,32] [1,1,32,32],张量的变化过程如下所示
KaTeX parse error: Expected 'EOF', got '_' at position 74: …arrow{\text{max_̲pool}}[1,6,14,1…
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net,self).__init__()# 1 is input_channel 6 is output_channelself.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# affine function y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self,x):# Max pooling over a (2,2) windowx = F.max_pool2d(F.relu(self.conv1(x)), (2,2))# If the size is a square you can only specify a single numberx = F.max_pool2d(F.relu(self.conv2(x)), (2,2))# flat the feature as a vectorx = x.view(-1, self.num_flat_features(x))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = F.softmax(self.fc3(x), dim=1)return xdef num_flat_features(self,x):size = x.size()[1:] # all dimensions except the batch dimensionnum_feature = 1for s in size:num_feature *= sreturn num_featurenet = Net()
print(net)
或
class Net(nn.Module):def __init__(self):super(Net,self).__init__()# 1 is input_channel 6 is output_channelself.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# affine function y = Wx + bself.flat = nn.Flatten(1,-1) # flat the featureself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self,x):# Max pooling over a (2,2) windowx = F.max_pool2d(F.relu(self.conv1(x)), (2,2))# If the size is a square you can only specify a single numberx = F.max_pool2d(F.relu(self.conv2(x)), (2,2))# flat the feature as a vectorx = self.flat(x)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = F.softmax(self.fc3(x), dim=1)return xnet = Net()
print(net)
结果如下,可以查看网络结构
Net((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)
一个模型可训练的参数可以通过调用 net.parameters() 返回,
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
结果如下
10
torch.Size([6, 1, 5, 5])
然后我们可以自定义一些输入,来获得网络的输出
input = torch.randn(3, 1, 32, 32)
out = net(input)
print(out.data)
sum = 0
for i in out.data[0]:sum += i.item()
print(sum)
输出如下
tensor([[0.0996, 0.1000, 0.0907, 0.0946, 0.0930, 0.1067, 0.1044, 0.1119, 0.1073,0.0918],[0.0975, 0.1005, 0.0913, 0.0935, 0.0939, 0.1070, 0.1045, 0.1121, 0.1065,0.0933],[0.0968, 0.1009, 0.0896, 0.0978, 0.0903, 0.1107, 0.1055, 0.1130, 0.1043,0.0913]])
0.9999999925494194
torch.nn.Module.zero_grad()把所有参数梯度缓存器置零,
net.zero_grad() #把所有参数梯度缓存器置零,用随机的梯度来反向传播
out.backward(torch.randn_like(out))
net.conv1.bias.grad #查看Conv卷积层的偏置和权重一些参数的梯度
net.conv1.weight.grad
结果如下
tensor([-0.0064, 0.0136, -0.0046, 0.0008, -0.0044, 0.0021])
...
3.3 Use Loss Function to Backward 利用损失函数进行反向传播
现在我们已经完成了
-
定义一个神经网络
-
处理输入以及调用反向传播
还剩下:
-
计算损失值
-
更新网络中的权重
损失函数
一个损失函数需要一对输入:模型输出和目标,然后计算一个值来评估输出距离目标有多远。
有一些不同的损失函数在 nn 包(详细请查看loss-functions)。一个简单的损失函数就是 nn.MSELoss ,这计算了均方误差
input = torch.randn(3, 1, 32, 32)
target = torch.randn(3, 10)
predict = net(input)
criterion = nn.MSELoss()
loss = criterion(predict, target)print(loss)
print(loss.grad_fn.next_functions[0][0])
我们计算了MSE损失函数,并且能够跟踪其计算图
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d-> view -> linear -> relu -> linear -> relu -> linear -> sfotmax-> MSELoss-> loss
当我们使用loss.backward()时,整个计算图都会进行微分,为了实现反向传播损失,我们所有需要做的事情仅仅是使用 loss.backward()。你需要清空现存的梯度,要不然现在计算的梯度都将会和历史保存的梯度累计到一起。
net.zero_grad() # zeroes the gradient buffers of all parametersprint('conv1.bias.grad before backward')
print(net.conv1.bias.grad)loss.backward()print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
结果如下
conv1.bias.grad before backward
None
conv1.bias.grad after backward
tensor([-3.4418e-04, -1.0766e-04, 1.0913e-04, -5.5018e-05, 1.7342e-04,-5.3316e-04])
3.4 Update Parameter of NN 更新神经网络参数
3.4.1 Update Manually手动更新参数
我们可以手动实现随机梯度下降(stochastic gradient descent)来更新参数(详细请参考Chapter 6. Stochastic Approximation)
w k + 1 = w k − a k ∇ w k f ( w k , x k ) \textcolor{red}{w_{k+1} = w_k - a_k \nabla_{w_k} f(w_k,x_k)} wk+1=wk−ak∇wkf(wk,xk)
learning_rate = 0.01
for f in net.parameters():f.data.sub_(f.grad.data * learning_rate) #sub_() is in-place minus
3.4.2 Update Automatically自动更新参数
尽管如此,如果你是用神经网络,你想使用不同的更新规则,类似于 SGD, Nesterov-SGD, Adam, RMSProp, 等。为了让这可行,我们建立了一个小包:torch.optim 实现了所有的方法。我们可以使用optim.step()来替代上述手动实现的代码,使用它非常的简单。
import torch.optim as optim# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward() # 计算梯度
optimizer.step() # Does the update
Reference
参考教程1
参考教程2
相关文章:
Pytorch Tutorial【Chapter 3. Simple Neural Network】
Pytorch Tutorial【Chapter 3. Simple Neural Network】 文章目录 Pytorch Tutorial【Chapter 3. Simple Neural Network】Chapter 3. Simple Neural Network3.1 Train Neural Network Procedure训练神经网络流程3.2 Build Neural Network Procedure 搭建神经网络3.3 Use Loss …...

2.虚拟机开启kali_linux
首先你应该搞一个虚拟机,搞虚拟机可以看一下这个 附录三 虚拟机的使用_Suyuoa的博客-CSDN博客 然后你需要搞一个 kali linux的镜像 Get Kali | Kali Linux 镜像下载好之后解压,你会得到一个文件夹包含下面这些文件 之后打开VMware,点击打开虚…...

【StyleGAN2论文精读CVPR_2020】Analyzing and Improving the Image Quality of StyleGAN
【StyleGAN2论文精读CVPR_2020】Analyzing and Improving the Image Quality of StyleGAN 一、前言Abstract1. Introduction2. Removing normalization artifacts2.1. Generator architecture revisited2.2. Instance normalization revisited 3. Image quality and generator …...

医学图像处理
医学图像处理 opencv批量分片高像素图像病理图像色彩特征提取病理图像细微特征提取自动数据标注分类场景下的医学图像分析分割场景下的医学图像分析检测场景下的医学图像分析 , i ] k 8 < * I opencv批量分片高像素图像 医学图像通常是大像素(1920x1080&…...
PyCharm安装使用2023年教程,PyCharm与现流行所有编辑器对比。
与PyCharm类似的功能和特性的集成开发环境(IDE)和代码编辑器有以下几种: Visual Studio Code(VS Code):由Microsoft开发,VS Code是一个高度可定制和可扩展的代码编辑器。它支持多种编程语言&am…...
vue3中CompositionApi理解与使用
CompositionApi,组合式API,相当于react中hooks,函数式。 优势:1,增加了代码的复用性(类似mixin,slot,高阶组件功能) 2,代码可读性更好。可以将处理逻辑和视图…...
【前瞻】视频技术的发展趋势讨论以及应用场景
视频技术的发展可以追溯到19世纪初期的早期实验。到20世纪初期,电视技术的发明和普及促进了视频技术的进一步发展。 1)数字化:数字化技术的发明和发展使得视频技术更加先进。数字电视信号具有更高的清晰度和更大的带宽,可以更快地…...

Visual Studio在Debug模式下,MFC工程中包含Eigen库时的定义冲突的问题
Visual Studio在Debug模式下,MFC工程中包含Eigen库时的定义冲突的问题 报错信息 Eigen\src\Core\PlainObjectBase.h(143,5): error C2061: 语法错误: 标识符“THIS_FILE” Eigen\src\Core\PlainObjectBase.h(143,1): error C2333: “Eigen::PlainObjectBase::opera…...
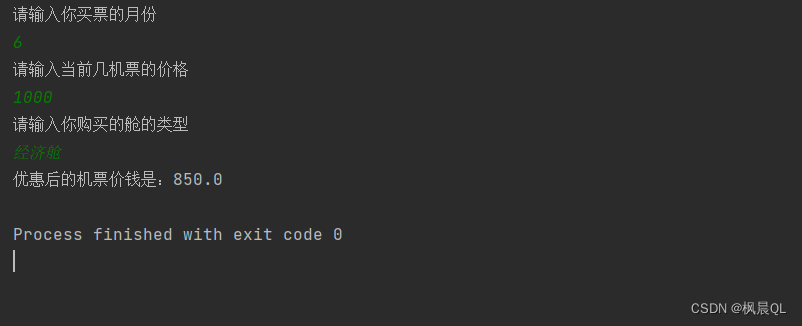
Java实现购买机票案例
Java实现购买机票案例 需求分析代码实现小结Time 需求分析 1.首先,考虑方法是否需要接收数据处理? 阅读需求我们会发现,不同月份、不同原价、不同舱位类型优惠方案都不一样; 所以,可以将原价、月份、舱位类型写成参数 …...

通用FIR滤波器的verilog实现(内有Lowpass、Hilbert参数生成示例)
众所周知,Matlab 中的 Filter Designer 可以直接生成 FIR 滤波器的 verilog 代码,可以方便地生成指定阶数、指定滤波器参数的高通、低通、带通滤波器,生成的 verilog 代码也可以指定输入输出信号的类型和位宽。然而其生成的代码实在算不上美观…...
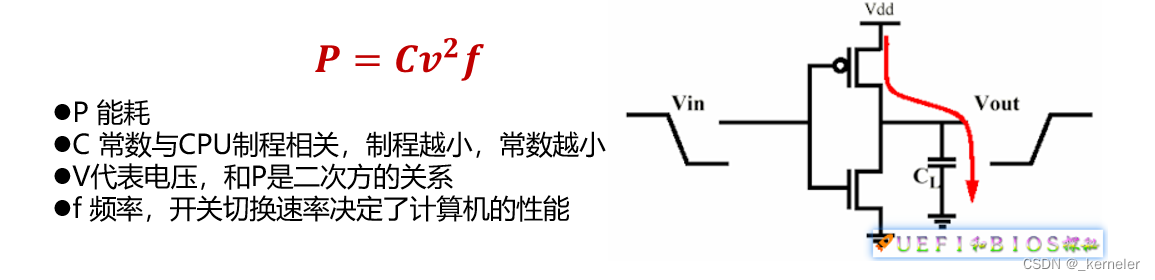
有利于提高xenomai /PREEMPT-RT 实时性的一些配置建议
版权声明:转自: https://www.cnblogs.com/wsg1100 一、前言 1. 什么是实时 “实时”一词在许多应用领域中使用,人们它有不同的解释,并不总是正确的。人们常说,如果控制系统能够对外部事件做出快速反应,那么它就是实时运行的。根据这种解释,如果系统速度快,则系统被认…...
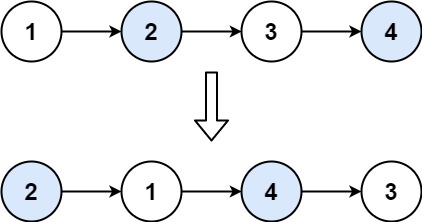
【LeetCode】24.两两交换链表中的节点
题目 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出:…...
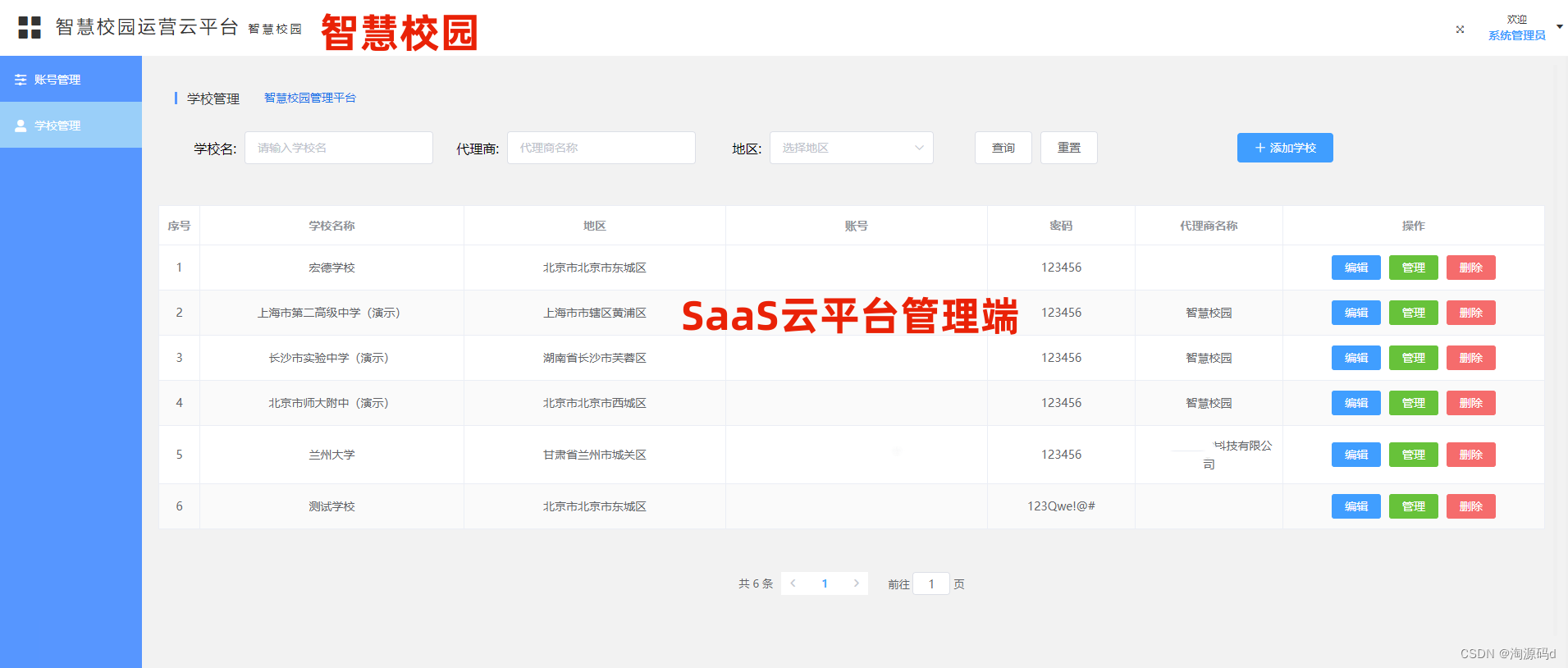
融合大数据、物联网和人工智能的智慧校园云平台源码 智慧学校源码
电子班牌系统用以展示各个班级的考勤信息、授课信息、精品课程、德育宣传、班级荣誉、校园电视台、考场信息、校园通知、班级风采,是智慧校园和智慧教室的对外呈现窗口,也是学校校园文化宣传和各种信息展示的重要载体。将大数据、物联网和人工智能等新兴…...

Spring Boot通过切面实现方法耗时情况
Spring Boot通过切面实现方法耗时情况 依赖 <dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId><version>1.9.9.1</version></dependency>自定义注解 package com.geekmice.springbootself…...
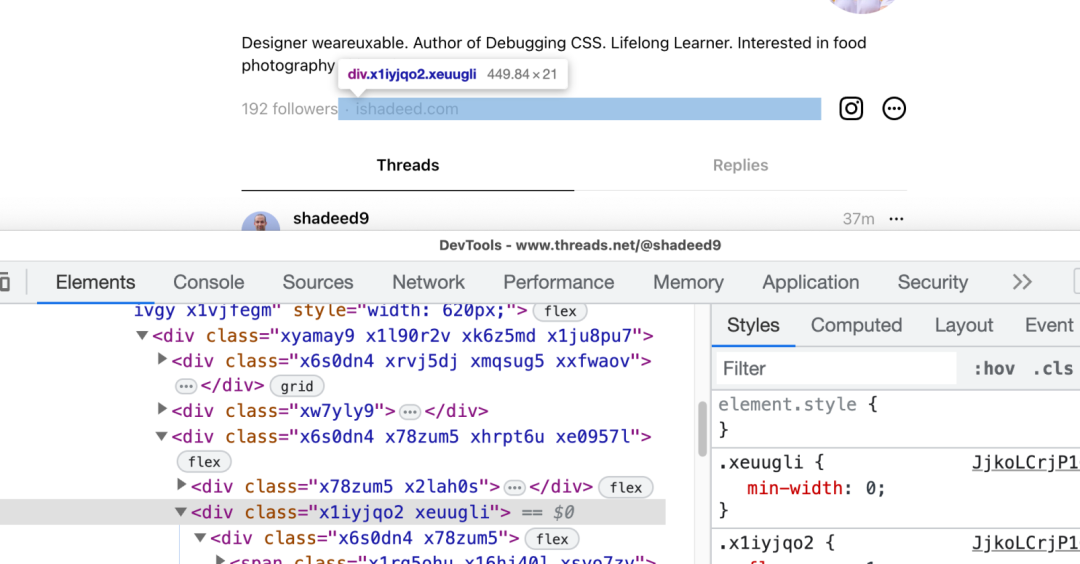
深挖 Threads App 帖子布局,我进一步加深了对CSS网格布局的理解
当我遇到一个新产品时,我首先想到的是他们如何实现CSS。当我遇到Meta的Threads时也不例外。我很快就探索了移动应用程序,并注意到我可以在网页上预览公共帖子。 这为我提供了一个深入挖掘的机会。我发现了一些有趣的发现,我将在本文中讨论。 …...

leetcode做题笔记54
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 思路一:模拟题意 int* spiralOrder(int** matrix, int matrixSize, int* matrixColSize, int* returnSize){int m matrixSize; int n matrixColSi…...
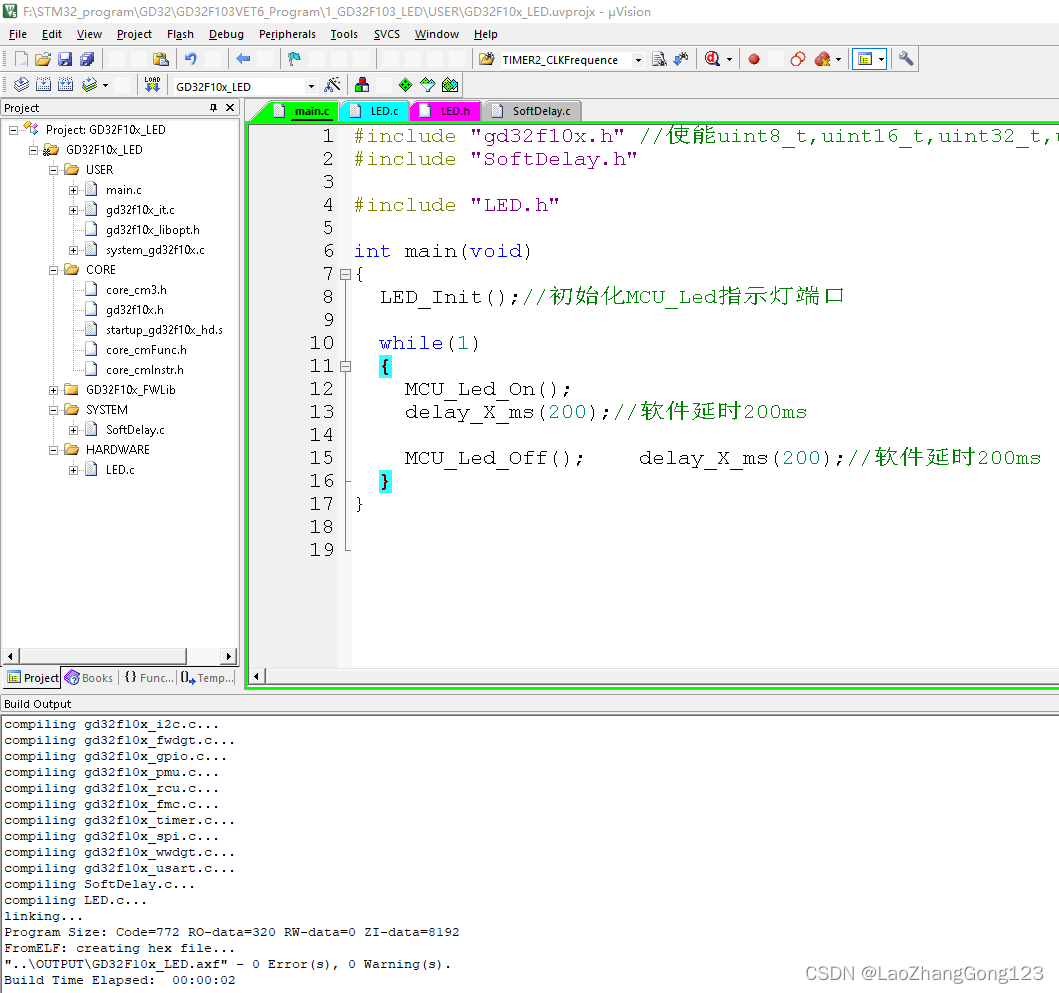
GD32F103VE点灯
GD32F103VE点灯主要用来学习端口引脚的输出配置。它由LED.c,LED.h,SoftDelay.c和main.c组成。 #include "gd32f10x.h" //使能uint8_t,uint16_t,uint32_t,uint64_t,int8_t,int16_t,int32_t,int64_t #include "SoftDelay.h"#include …...

matlab使用教程(8)—绘制三维曲面图
1网格图和曲面图 MATLAB 在 x-y 平面中的网格上方使用点的 z 坐标来定义曲面图,并使用直线连接相邻的点。mesh 和surf 函数以三维形式显示曲面图。 • mesh 生成仅使用颜色来标记连接定义点的线条的线框曲面图。 • surf 使用颜色显示曲面图的连接线和面。 MATL…...
其它配置)
【Nginx14】Nginx学习:HTTP核心模块(十一)其它配置
Nginx学习:HTTP核心模块(十一)其它配置 剩下的一些配置指令没有大的归属,不过也有一些是比较常见的,这部分内容学习完成之后,整个 http 模块相关的核心基础配置指令就全部学习完成了。今晚可以举杯庆祝一下…...
243. 一个简单的整数问题2(树状数组)
输入样例: 10 5 1 2 3 4 5 6 7 8 9 10 Q 4 4 Q 1 10 Q 2 4 C 3 6 3 Q 2 4输出样例: 4 55 9 15 解析: 一般树状数组都是单点修改、区间查询或者单点查询、区间修改。这道题都是区间操作。 1. 区间修改用数组数组维护差分数组 2. 区间查询&am…...

长期使用Taotoken聚合服务对开发效率的实际提升感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对开发效率的实际提升感受 作为一名在多个项目中集成大模型能力的开发者,我过去需要为不同的…...

Magisk:重新定义Android系统定制边界的技术框架
Magisk:重新定义Android系统定制边界的技术框架 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统定制领域的革命性框架,以其独特的"无系统"&#…...

OctoBase源码解析:深入理解Rust实现的本地优先数据库引擎 [特殊字符]
OctoBase源码解析:深入理解Rust实现的本地优先数据库引擎 🐙 【免费下载链接】OctoBase 🐙 OctoBase is the open-source database behind AFFiNE, local-first, yet collaborative. A light-weight, scalable, data engine written in Rust.…...

别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器
别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器 信号处理工程师的日常工作中,滤波器设计是个绕不开的话题。无论是音频处理、通信系统还是生物医学信号分析,我们总需要根据不同的应用场景调整滤波器参数。传统方法中…...

从零开始理解阵列信号处理:用Python模拟阵列流形与波数响应
从零开始理解阵列信号处理:用Python模拟阵列流形与波数响应 阵列信号处理是雷达、声纳和无线通信等领域的核心技术之一。对于初学者来说,面对复杂的数学公式和抽象概念常常感到无从下手。本文将采用实践优先的方法,通过Python代码实现阵列流形…...

Godot引擎集成Box2D物理插件:提升2D游戏物理模拟精度与稳定性
1. 项目概述:当Godot遇上Box2D如果你是一个用过Godot引擎,特别是做过2D物理游戏的开发者,大概率对它的默认物理引擎有过又爱又恨的复杂感情。Godot内置的物理引擎在处理一些简单碰撞、刚体运动时非常方便,但一旦项目需求变得复杂—…...

微信读书笔记助手:3分钟快速上手的终极笔记管理指南
微信读书笔记助手:3分钟快速上手的终极笔记管理指南 【免费下载链接】wereader 一个浏览器扩展:主要用于微信读书做笔记,对常使用 Markdown 做笔记的读者比较有帮助。 项目地址: https://gitcode.com/gh_mirrors/wer/wereader 微信读书…...


使用Taotoken后API调用延迟与稳定性体感观察报告
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后API调用延迟与稳定性体感观察报告 1. 引言:从直接对接模型到使用聚合平台 在开发基于大语言模型的应用…...

ROS新手也能玩转AUBO i5:用MoveIt和Rviz在Ubuntu 20.04上实现机械臂可视化仿真与控制
ROS新手也能玩转AUBO i5:用MoveIt和Rviz在Ubuntu 20.04上实现机械臂可视化仿真与控制 机械臂控制一直是机器人开发中的核心课题,而ROS(Robot Operating System)为这一领域提供了强大的工具链。本文将带你从零开始,在Ub…...