YOLOv5基础知识入门(2)— YOLOv5核心基础知识讲解

前言:Hello大家好,我是小哥谈。YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,使检测性能得到更进一步的提升。YOLOv5算法作为目前工业界使用的最普遍的检测算法,存在着很多可以学习的地方。本文将对YOLOv5检测算法的核心基础知识进行详细的解说,希望大家可以透彻的理解。🌈
![]() 前期回顾:
前期回顾:
YOLOv5基础知识入门(1)— YOLO算法的发展历程
目录
🚀1.YOLOv5简介
🚀2.YOLOv5网络结构
🚀3.输入端
3.1 Mosaic数据增强
3.2 自适应锚框计算
3.3 自适应图像缩放
🚀4.主干网络(Backbone)
4.1 Focus结构
4.2 CSP结构
🚀5.Neck网络
🚀6.输出端
🚀7.训练策略

🚀1.YOLOv5简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放。
主干网络(Backbone):融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构。
Neck网络:目标检测网络在BackBone与最后的输出端之间往往会插入一些层,Yolov5中添加了FPN+PAN结构。
输出端:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的DIOU_nms。
总结:
输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
主干网络(Backbone):Focus结构、CSP结构
Neck网络:FPN+PAN结构
输出端:CIOU_Loss、DIOU_nms
YOLOv5目标检测算法是Ultralytics公司于2020年发布的,根据模型的大小,YOLOv5有5个版本,分别为YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这5个版本的权重、模型的宽度和深度是依次增加的。这些不同的变体使得YOLOv5能很好的在精度和速度中权衡,方便用户选择。YOLOv5五个版本的算法性能图和相应的指标如下所示:

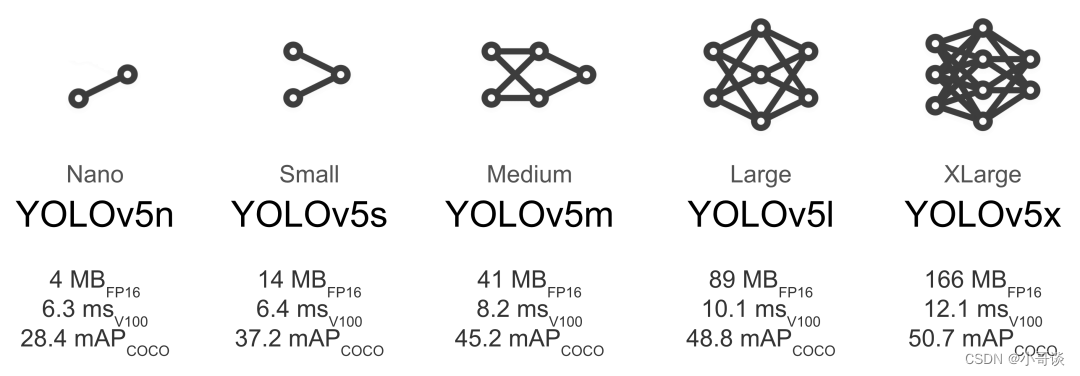

说明:
YOLOv5官方代码:🌷
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
🚀2.YOLOv5网络结构
YOLOv5的网络模型分为4个部分,包括输入端、主干网络(Backbone)、Neck网络和输出端,本文将使用常用的YOLOv5s检测模型来进行介绍,下面即是YOLOv5s的网络结构图。👇👇👇
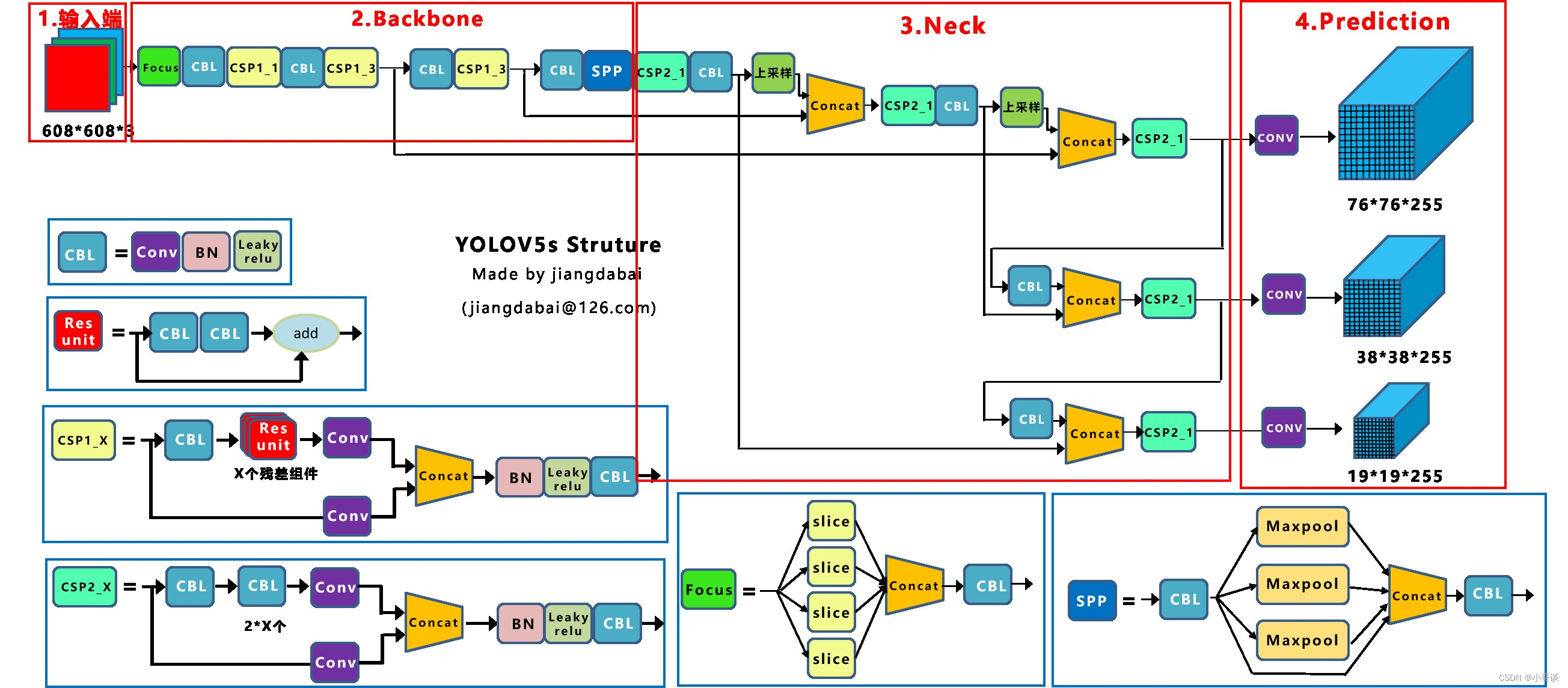
基本组件:
- CBL模块由Conv+BN+Leaky_relu激活函数组成,如上图中的模块1所示。
- Res unit借鉴ResNet网络中的残差结构,用来构建深层网络,CBM是残差模块中的子模块,如上图中的模块2所示。
- CSP1_X借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concat组成而成,如上图中的模块3所示。
- CSP2_X借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concat组成而成,如上图中的模块4所示。
- Focus如上图中的模块5所示,Focus结构首先将多个slice结果Concat起来,然后将其送入CBL模块中。
- SPP采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合,如上图中的模块6所示。
其他基础操作:
- Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。
- add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。
说明:
YOLOv5n网络最小,速度最快,AP精度也最低。若检测的以大目标为主,追求速度,是个不错的选择。其他的四种网络,在YOLOv5基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。🌱🌱🌱
福利:
Yolov3&Yolov4&Yolov5资源相关(包括模型权重、网络结构图等)💥💥💥
链接:https://pan.baidu.com/s/1NdVEtGxntCaAa_wWU0yG-g?pwd=zm4q
提取码:zm4q
🚀3.输入端
YOLOv5的输入端主要包括Mosaic数据增强、自适应锚框计算和自适应图像缩放三个部分。输入端表示需要输入图片,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。🌻🌻🌻
3.1 Mosaic数据增强
Mosaic数据增强是在模型训练阶段使用的,将四张图片按照随机缩放、随机裁剪和随机排布的方式进行拼接,可以增加数据集中小目标的数量,从而提升模型对小目标物体的检测能力。YOLOv5会根据参数启动自适应锚框计算功能,自适应的计算不同类别训练集中的最佳锚框值。Mosaic数据增强方法,使用随机增减亮度、对比度、饱和度、色调以及随机缩放、裁减、翻转、擦除等基本方法进行数据增强。Mosaic数据增强选取四张经过上述基本方法操作后的图片进行随机编排和拼接,一方面变相增大BatchSize,降低显存占用率,另一方面扩充了原始数据集,防止过拟合的发生,提高了模型的整体鲁棒性。🚵
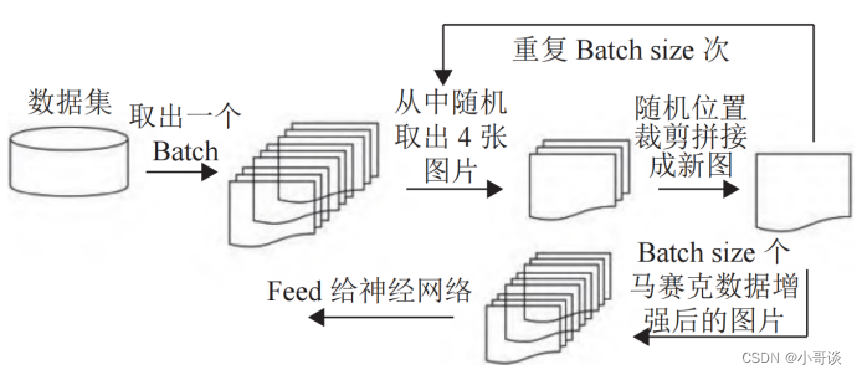

说明:
使用Mosaic数据增强方法的优点:🏆
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,丰富了检测数据集,尤其是随机缩放增加了小目标,让网络的鲁棒性更好。
减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
3.2 自适应锚框计算
在YOLO算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数,因此初始锚框是比较重要的一部分。在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但YOLOv5中将此功能嵌入到代码中,每次训练将会自适应的计算不同训练集中的最佳锚框值。如果觉得计算的锚框效果不好,可以将自动计算锚框功能关闭。🚃

3.3 自适应图像缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。YOLO算法中常用416*416、608*608等尺寸,比如对下面800*600的图像进行缩放。🐳
步骤1:根据原始图片大小以及输入到网络的图片大小来计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。🍀
步骤2:根据原始图片大小与缩放比例计算缩放后的图片大小

原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。🍀
步骤3:计算黑边填充数值
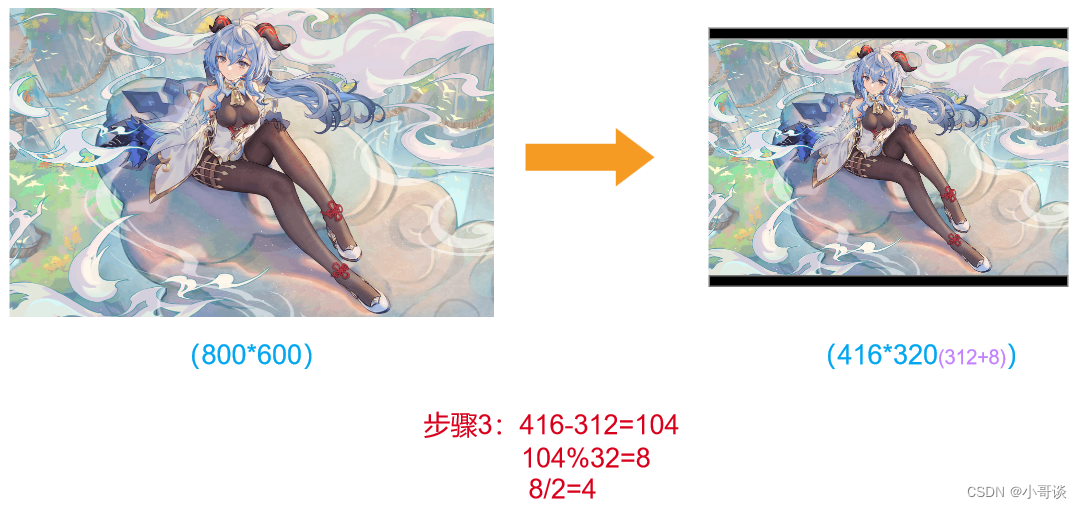
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。🌺
注意:
1.Yolov5中填充的是灰色,即(114,114,114)。
2.训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
3.为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
🚀4.主干网络(Backbone)
模型的Backbone主要由Focus、C3(改进后的BottleneckCSP)等模块组成。
4.1 Focus结构

Focus 模块,输入通道扩充了4倍,作用是可以使信息不丢失的情况下提高计算力。Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。📒
比如右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。💊
4.2 CSP结构
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck网络中。 💯
🚀5.Neck网络
该模块采用特征金字塔结构(FPN)+路径聚合网络结构(PAN)的结构,可以加强网络对不同缩放尺度对象特征融合的能力。Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。🌹
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。
结构如下图所示:
FPN层自顶向下传达强语义特征,而PAN则自底向上传达定位特征。

🚀6.输出端
输出端采用CIOU函数作为边界框的损失函数(关于损失函数,小哥谈后面会单独进行介绍,包括IOU_Loss、GIOU_Loss、DIOU_Loss和CIOU_Loss),在目标检测后处理过程中,使用NMS(非极大值抑制)来对多目标框进行筛选,增强了多目标和遮挡目标的检测能力。🌴
说明:
综合的看下各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。Yolov5中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
NMS算法实现:
为了从多个候选边界框中选择一个最佳边界框,通常会使用非极大值抑制(NMS)算法,这种算法用于“抑制”置信度低的边界框并只保留置信度最高的边界框。🍃
算法的实现过程为:🍃
输入: 候选边界框集合B(每个候选框都有一个置信度)、IoU阈值N
输出: 最终的边界框集合D(初始为空集合)
1. 对集合B根据置信度进行降序排序;
2. 从集合B中选择第一个候选框(置信度最高),把它放入集合D中并从集合B中删除;
3. 遍历集合B中的每个候选框,计算它们与D集合中这个候选框的IoU值。如果IoU值大于阈值N, 则把它从集合B中删除;
4. 重复步骤2~3直到集合B为空。

说明:
关于NMS(非极大值抑制),请参考我的另一篇文章。🌼🌼🌼
目标检测中NMS(非极大值抑制)原理解析
🚀7.训练策略
- 多尺度训练 (Multi-scale training)。如果网络的输入是416 x 416,那么训练的时候就会从0.5 x416到1.5×416中任意取值,但所取的值都是32的整数倍。
- 训练开始前使用 warmup 进行训练。在模型预训练阶段,先使用较小的学习率训练一些epochs或者steps,再修改为预先设置的学习率进行训练。
- 使用了 cosine 学习率下降策略 (Cosine LR scheduler)
- 采用了 EMA 更新权重(Exponential Moving Average)。相当于训练时给参数赋予一个动量,这样更新起来就会更加平滑。
- 使用了 amp 进行混合精度训练 (Mixed precision)。能够减少显存的占用并且加快训练速度,但是需要 GPU 支持。

相关文章:
YOLOv5基础知识入门(2)— YOLOv5核心基础知识讲解
前言:Hello大家好,我是小哥谈。YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,使检测性能得到更进一步的提升。YOLOv5算法作为目前工业界使用的最普遍的检测算法,存在着很多可以学习…...

免费的scrum敏捷开发管理工具
Scrum中非常强调公开、透明、直接有效的沟通,这也是“可视化的管理工具”在敏捷开发中如此重要的原因之一。通过“可视化的管理工具”让所有人直观的看到需求,故事,任务之间的流转状态,可以使团队成员更加快速适应敏捷开发流程。 …...
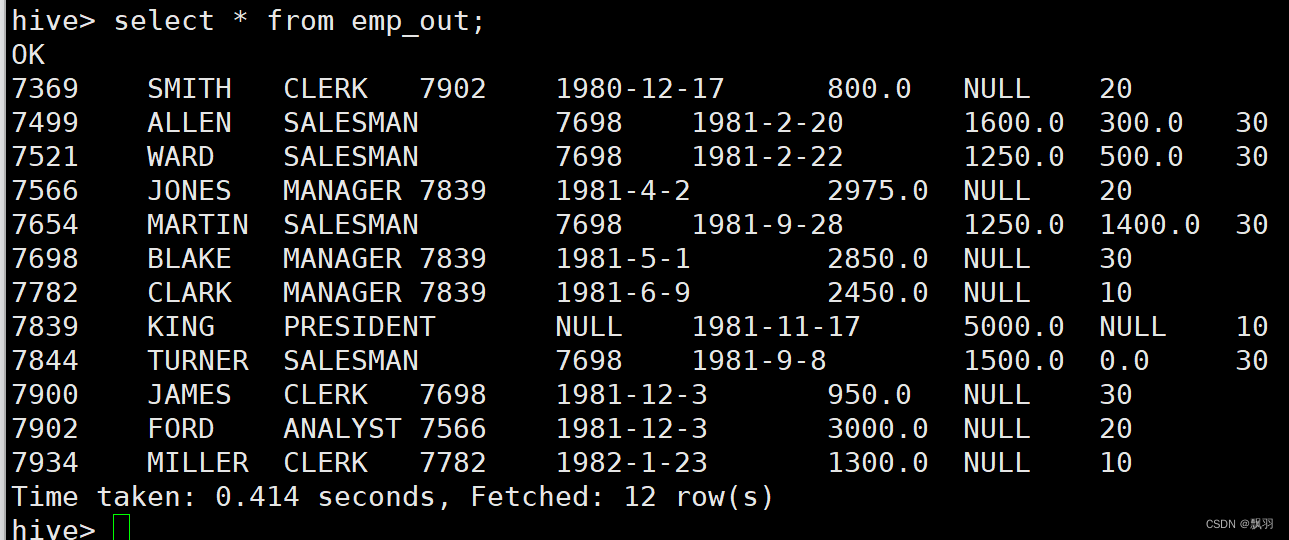
Hive创建外部表详细步骤
① 在hive中执行HDFS命令:创建/data目录 hive命令终端输入: hive> dfs -mkdir -p /data; 或者在linux命令终端输入: hdfs dfs -mkdir -p /data; ② 在hive中执行HDFS命令:上传/emp.txt至HDFS的data目录下,并命名为…...
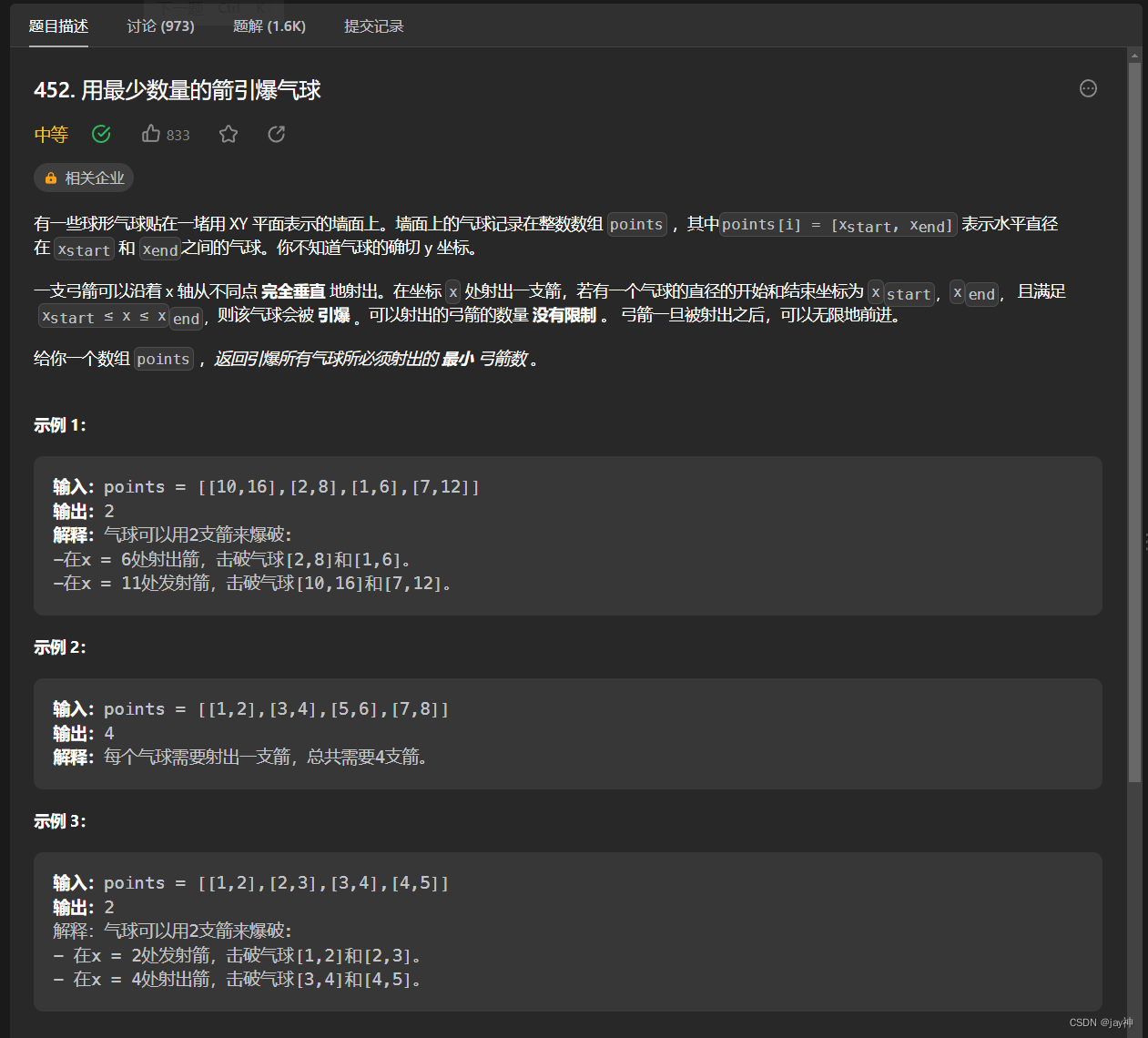
leetcode 452. 用最少数量的箭引爆气球
2023.8.2 本题思路先将二维数组points按照第一个维度排序, 然后初始化射箭数为1,因为题中提示说了最少有一个气球。 在遍历这些气球,看是否有重叠,如果没有重叠区域,射箭数;如果有重叠区域,更新…...
Pytorch Tutorial【Chapter 3. Simple Neural Network】
Pytorch Tutorial【Chapter 3. Simple Neural Network】 文章目录 Pytorch Tutorial【Chapter 3. Simple Neural Network】Chapter 3. Simple Neural Network3.1 Train Neural Network Procedure训练神经网络流程3.2 Build Neural Network Procedure 搭建神经网络3.3 Use Loss …...

2.虚拟机开启kali_linux
首先你应该搞一个虚拟机,搞虚拟机可以看一下这个 附录三 虚拟机的使用_Suyuoa的博客-CSDN博客 然后你需要搞一个 kali linux的镜像 Get Kali | Kali Linux 镜像下载好之后解压,你会得到一个文件夹包含下面这些文件 之后打开VMware,点击打开虚…...

【StyleGAN2论文精读CVPR_2020】Analyzing and Improving the Image Quality of StyleGAN
【StyleGAN2论文精读CVPR_2020】Analyzing and Improving the Image Quality of StyleGAN 一、前言Abstract1. Introduction2. Removing normalization artifacts2.1. Generator architecture revisited2.2. Instance normalization revisited 3. Image quality and generator …...

医学图像处理
医学图像处理 opencv批量分片高像素图像病理图像色彩特征提取病理图像细微特征提取自动数据标注分类场景下的医学图像分析分割场景下的医学图像分析检测场景下的医学图像分析 , i ] k 8 < * I opencv批量分片高像素图像 医学图像通常是大像素(1920x1080&…...
PyCharm安装使用2023年教程,PyCharm与现流行所有编辑器对比。
与PyCharm类似的功能和特性的集成开发环境(IDE)和代码编辑器有以下几种: Visual Studio Code(VS Code):由Microsoft开发,VS Code是一个高度可定制和可扩展的代码编辑器。它支持多种编程语言&am…...
vue3中CompositionApi理解与使用
CompositionApi,组合式API,相当于react中hooks,函数式。 优势:1,增加了代码的复用性(类似mixin,slot,高阶组件功能) 2,代码可读性更好。可以将处理逻辑和视图…...
【前瞻】视频技术的发展趋势讨论以及应用场景
视频技术的发展可以追溯到19世纪初期的早期实验。到20世纪初期,电视技术的发明和普及促进了视频技术的进一步发展。 1)数字化:数字化技术的发明和发展使得视频技术更加先进。数字电视信号具有更高的清晰度和更大的带宽,可以更快地…...

Visual Studio在Debug模式下,MFC工程中包含Eigen库时的定义冲突的问题
Visual Studio在Debug模式下,MFC工程中包含Eigen库时的定义冲突的问题 报错信息 Eigen\src\Core\PlainObjectBase.h(143,5): error C2061: 语法错误: 标识符“THIS_FILE” Eigen\src\Core\PlainObjectBase.h(143,1): error C2333: “Eigen::PlainObjectBase::opera…...
Java实现购买机票案例
Java实现购买机票案例 需求分析代码实现小结Time 需求分析 1.首先,考虑方法是否需要接收数据处理? 阅读需求我们会发现,不同月份、不同原价、不同舱位类型优惠方案都不一样; 所以,可以将原价、月份、舱位类型写成参数 …...

通用FIR滤波器的verilog实现(内有Lowpass、Hilbert参数生成示例)
众所周知,Matlab 中的 Filter Designer 可以直接生成 FIR 滤波器的 verilog 代码,可以方便地生成指定阶数、指定滤波器参数的高通、低通、带通滤波器,生成的 verilog 代码也可以指定输入输出信号的类型和位宽。然而其生成的代码实在算不上美观…...
有利于提高xenomai /PREEMPT-RT 实时性的一些配置建议
版权声明:转自: https://www.cnblogs.com/wsg1100 一、前言 1. 什么是实时 “实时”一词在许多应用领域中使用,人们它有不同的解释,并不总是正确的。人们常说,如果控制系统能够对外部事件做出快速反应,那么它就是实时运行的。根据这种解释,如果系统速度快,则系统被认…...
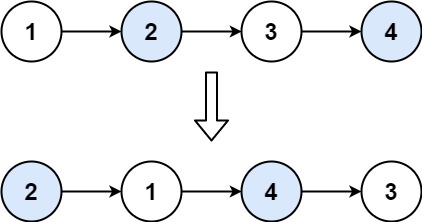
【LeetCode】24.两两交换链表中的节点
题目 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出:…...
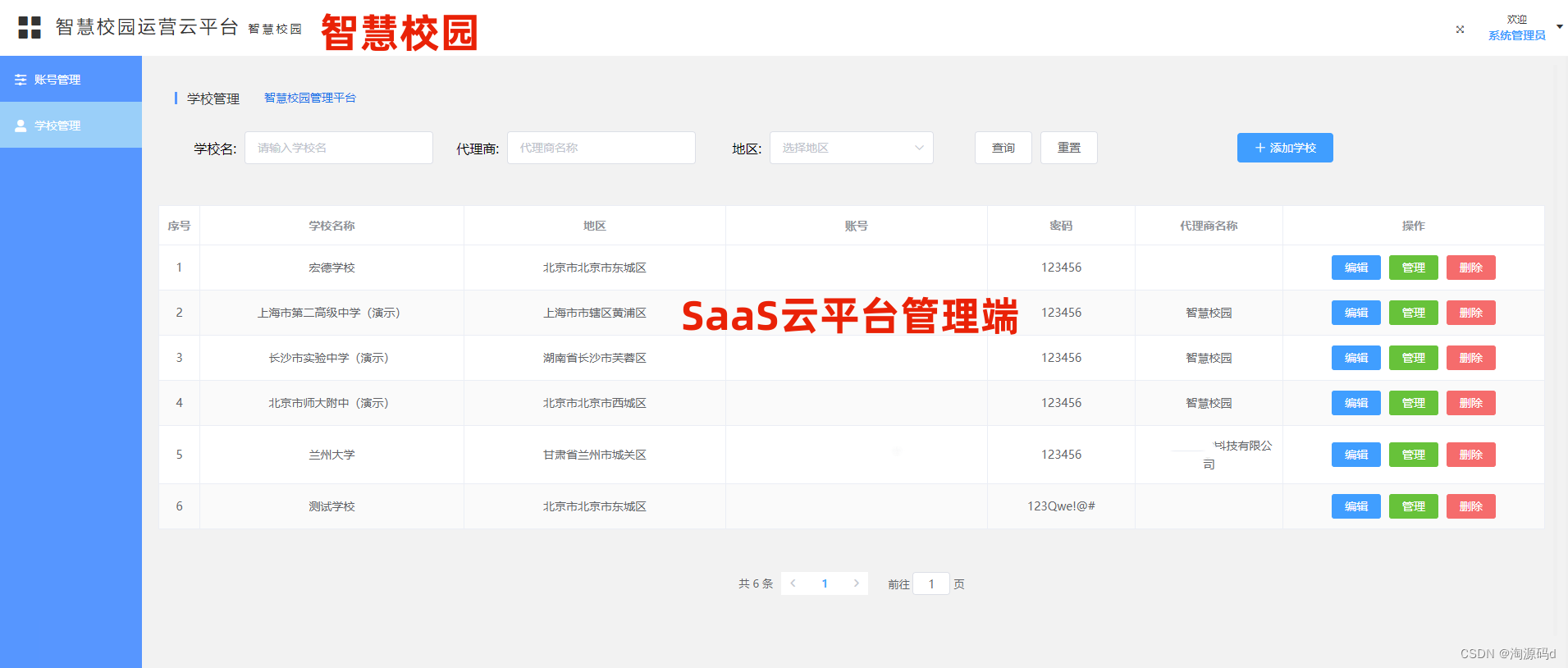
融合大数据、物联网和人工智能的智慧校园云平台源码 智慧学校源码
电子班牌系统用以展示各个班级的考勤信息、授课信息、精品课程、德育宣传、班级荣誉、校园电视台、考场信息、校园通知、班级风采,是智慧校园和智慧教室的对外呈现窗口,也是学校校园文化宣传和各种信息展示的重要载体。将大数据、物联网和人工智能等新兴…...

Spring Boot通过切面实现方法耗时情况
Spring Boot通过切面实现方法耗时情况 依赖 <dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId><version>1.9.9.1</version></dependency>自定义注解 package com.geekmice.springbootself…...
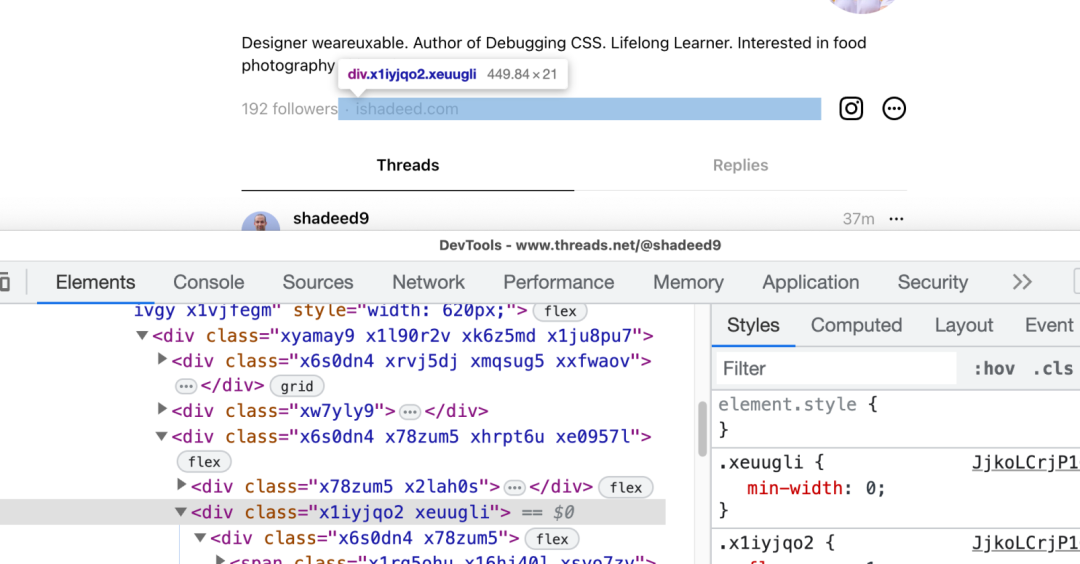
深挖 Threads App 帖子布局,我进一步加深了对CSS网格布局的理解
当我遇到一个新产品时,我首先想到的是他们如何实现CSS。当我遇到Meta的Threads时也不例外。我很快就探索了移动应用程序,并注意到我可以在网页上预览公共帖子。 这为我提供了一个深入挖掘的机会。我发现了一些有趣的发现,我将在本文中讨论。 …...

leetcode做题笔记54
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 思路一:模拟题意 int* spiralOrder(int** matrix, int matrixSize, int* matrixColSize, int* returnSize){int m matrixSize; int n matrixColSi…...

STM32F108C8T6小白入门特训营__1.4GPIO.C 代码分析
目录 1.只需要搞明白 cubemx 跟 代码对应关系就可以了 2.GPIO.C 代码加上注释 3.注意引脚的宏定义 1.只需要搞明白 cubemx 跟 代码对应关系就可以了 2.GPIO.C 代码加上注释 读懂注释部分代码即可 /* USER CODE BEGIN Header */ /*****************************************…...

HTML代码加密工具源码_在线网页加密解密_防复制源码
概述 在前端开发与网页设计中,保护原创代码不被轻易复制或篡改是许多开发者的核心诉求。无论是为了隐藏核心逻辑,还是防止样式被恶意盗用,一款高效、安全的加密工具都显得尤为重要。为此,幽络源源码网特别整理并分享这款HTML代码…...


数学科研效率提升300%,NotebookLM辅助建模全流程解析,含独家提示词矩阵与误差校验协议
更多请点击: https://intelliparadigm.com 第一章:NotebookLM数学研究辅助的范式革命 传统数学研究长期依赖纸笔推演、孤立文献查阅与手工公式验证,而NotebookLM通过其独特的“语义锚点双文档协同推理”机制,重构了从问题建模到定…...

书匠策AI官网www.shujiangce.com:论文降重降AIGC的隐藏玩法,99%的毕业生还不知道!
💀 论文人的"红色恐惧症",你中招了吗? 各位论文战士们,今天不聊选题、不聊框架,咱聊点真正让人血压飙升的事——查重报告上那片触目惊心的红色。 你有没有经历过这种场景:熬了两个通宵写完一章…...

Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列专业软件
Adobe-GenP 3.0终极指南:5分钟快速激活Adobe全系列专业软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专门为Adobe Creative Clou…...

Kilocode框架:轻量级代码组织与复用架构实践
1. 项目概述:一个面向开发者的轻量级代码组织与复用框架最近在和一些团队交流时,发现一个挺普遍的现象:随着项目迭代,代码库越来越臃肿,不同模块间的依赖关系变得混乱,想复用一段业务逻辑或者工具函数&…...

如何在卡片悬停时添加内边距而不引起布局偏移
本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略,在卡片 hover 时安全添加 padding,避免因盒模型计算导致的布局抖动或相邻卡片位移。 本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略&am…...

ARM中断控制器架构与配置实践详解
1. ARM中断控制器架构解析在嵌入式系统设计中,中断控制器作为处理器与外围设备间的关键枢纽,其性能直接影响系统的实时性和可靠性。ARM1176JZF-S处理器采用了两级中断控制架构:位于开发芯片中的TrustZone中断控制器(TZIC)和通用中断控制器(GI…...
LLM实战指南:从Transformer原理到微调部署的完整学习路径
1. 项目概述:一个面向实践者的LLM学习路线图最近在GitHub上看到一个叫mlabonne/llm-course的项目,热度非常高。点进去一看,这其实不是一个传统意义上的“课程”,而更像一份由社区驱动的、持续更新的“大型语言模型实战指南”。它的…...