Pyspark
2、DataFrame
2.1 介绍
在Spark语义中,DataFrame是一个分布式的行集合,可以想象为一个关系型数据库的表,或者一个带有列名的Excel表格。它和RDD一样,有这样一些特点:
- Immuatable:一旦RDD、DataFrame被创建,就不能更改,只能通过transformation生成新的RDD、DataFrame
- Lazy Evaluations:只有action才会触发Transformation的执行
- Distributed:DataFrame和RDD一样都是分布式的
- dataframe和dataset统一,dataframe只是dataset[ROW]的类型别名。由于Python是弱类型语言,只能使用DataFrame
DataFrame vs RDD
- RDD:分布式的对象的集合,Spark并不知道对象的详细模式信息
- DataFrame:分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某些形式的执行优化。
- DataFrame和普通的RDD的逻辑框架区别如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qMpnxi2C-1691306807806)(pics/s13.png)]](https://img-blog.csdnimg.cn/ba94de850cfb43eabaa732d5713867d5.png)
-
左侧的RDD Spark框架本身不了解 Person类的内部结构。
-
右侧的DataFrame提供了详细的结构信息(schema——每列的名称,类型)
-
DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id, name from xx_table where …)。
-
DataFrame还引入了off-heap,意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。
-
RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
-
DataFrame的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了
-
通过DataFrame API或SQL处理数据,会自动经过Spark 优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快。
-
DataFrame相当于是一个带着schema的RDD
Pandas DataFrame vs Spark DataFrame
- Cluster Parallel:集群并行执行
- Lazy Evaluations: 只有action才会触发Transformation的执行
- Immutable:不可更改
- Pandas rich API:比Spark SQL api丰富
2.2 创建DataFrame
1,创建dataFrame的步骤
调用方法例如:spark.read.xxx方法
2,其他方式创建dataframe
-
createDataFrame:pandas dataframe、list、RDD
-
数据源:RDD、csv、json、parquet、orc、jdbc
jsonDF = spark.read.json("xxx.json")jsonDF = spark.read.format('json').load('xxx.json')parquetDF = spark.read.parquet("xxx.parquet")jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/db_name").option("dbtable","table_name").option("user","xxx").option("password","xxx").load() -
Transformation:延迟性操作
-
action:立即操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pdJJY02F-1691306807807)(pics/s14.png)]](https://img-blog.csdnimg.cn/4aa900d6fdfc4329aa2570e4a88a23c2.png)
2.3 DataFrame API实现
基于RDD创建
from pyspark.sql import SparkSession
from pyspark.sql import Rowspark = SparkSession.builder.appName('test').getOrCreate()
sc = spark.sparkContext
# spark.conf.set("spark.sql.shuffle.partitions", 6)
# ================直接创建==========================
l = [('Ankit',25),('Jalfaizy',22),('saurabh',20),('Bala',26)]
rdd = sc.parallelize(l)
#为数据添加列名
people = rdd.map(lambda x: Row(name=x[0], age=int(x[1])))
#创建DataFrame
schemaPeople = spark.createDataFrame(people)
从csv中读取数据
# ==================从csv读取======================
#加载csv类型的数据并转换为DataFrame
df = spark.read.format("csv"). \option("header", "true") \.load("iris.csv")
#显示数据结构
df.printSchema()
#显示前10条数据
df.show(10)
#统计总量
df.count()
#列名
df.columns
增加一列
# ===============增加一列(或者替换) withColumn===========
#定义一个新的列,数据为其他某列数据的两倍
#如果操作的是原有列,可以替换原有列的数据
df.withColumn('newWidth',df.SepalWidth * 2).show()
删除一列
# ==========删除一列 drop=========================
#删除一列
df.drop('cls').show()
统计信息
#================ 统计信息 describe================
df.describe().show()
#计算某一列的描述信息
df.describe('cls').show()
提取部分列
# ===============提取部分列 select==============
df.select('SepalLength','SepalWidth').show()
基本统计功能
# ==================基本统计功能 distinct count=====
df.select('cls').distinct().count()
分组统计
# 分组统计 groupby(colname).agg({'col':'fun','col2':'fun2'})
df.groupby('cls').agg({'SepalWidth':'mean','SepalLength':'max'}).show()# avg(), count(), countDistinct(), first(), kurtosis(),
# max(), mean(), min(), skewness(), stddev(), stddev_pop(),
# stddev_samp(), sum(), sumDistinct(), var_pop(), var_samp() and variance()
自定义的汇总方法
# 自定义的汇总方法
import pyspark.sql.functions as fn
#调用函数并起一个别名
df.agg(fn.count('SepalWidth').alias('width_count'),fn.countDistinct('cls').alias('distinct_cls_count')).show()
拆分数据集
#====================数据集拆成两部分 randomSplit ===========
#设置数据比例将数据划分为两部分
trainDF, testDF = df.randomSplit([0.6, 0.4])
采样数据
# ================采样数据 sample===========
#withReplacement:是否有放回的采样
#fraction:采样比例
#seed:随机种子
sdf = df.sample(False,0.2,100)
查看两个数据集在类别上的差异
#查看两个数据集在类别上的差异 subtract,确保训练数据集覆盖了所有分类
diff_in_train_test = testDF.select('cls').subtract(trainDF.select('cls'))
diff_in_train_test.distinct().count()
交叉表
# ================交叉表 crosstab=============
df.crosstab('cls','SepalLength').show()
udf
udf:自定义函数
#================== 综合案例 + udf================
# 测试数据集中有些类别在训练集中是不存在的,找到这些数据集做后续处理
trainDF,testDF = df.randomSplit([0.99,0.01])diff_in_train_test = trainDF.select('cls').subtract(testDF.select('cls')).distinct().show()#首先找到这些类,整理到一个列表
not_exist_cls = trainDF.select('cls').subtract(testDF.select('cls')).distinct().rdd.map(lambda x :x[0]).collect()#定义一个方法,用于检测
def should_remove(x):if x in not_exist_cls:return -1else :return x#创建udf,udf函数需要两个参数:
# Function
# Return type (in my case StringType())#在RDD中可以直接定义函数,交给rdd的transformatioins方法进行执行
#在DataFrame中需要通过udf将自定义函数封装成udf函数再交给DataFrame进行调用执行from pyspark.sql.types import StringType
from pyspark.sql.functions import udfcheck = udf(should_remove,StringType())resultDF = trainDF.withColumn('New_cls',check(trainDF['cls'])).filter('New_cls <> -1')resultDF.show()
相关文章:
Pyspark
2、DataFrame 2.1 介绍 在Spark语义中,DataFrame是一个分布式的行集合,可以想象为一个关系型数据库的表,或者一个带有列名的Excel表格。它和RDD一样,有这样一些特点: Immuatable:一旦RDD、DataFrame被创…...

Spring Boot 项目五维度九层次分层架构实现实践研究——持续更新中
说明:本博文主要参考来自 https://blog.csdn.net/BASK2311/article/details/128198005 据实践内容及代码持续总结更新中。 五个分层维度:SpringBoot工程分层实战 1 分层思想 计算机领域有一句话:计算机中任何问题都可通过增加一个虚拟层解…...
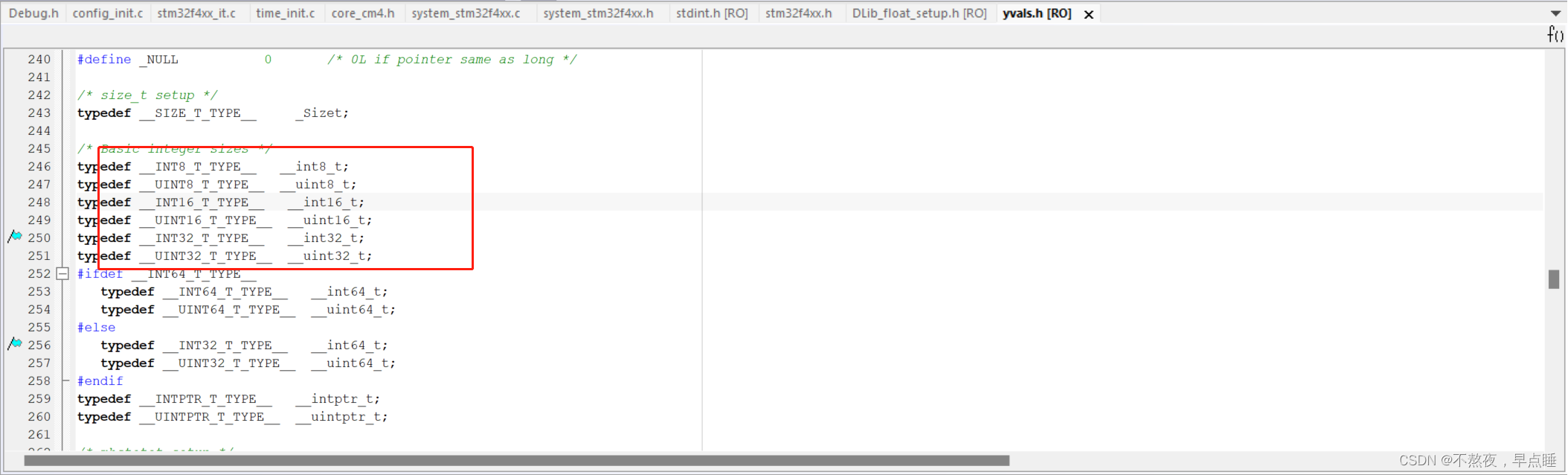
stm32常见数据类型
stm32的数据类型的字节长度 s8 占用1个byte,数据范围 -2^7 到 (2^7-1) s16 占用2个byte,数据范围 -2^15 到 (2^15-1) s32 占用 4个byte,数据范围 -2^31 到 (231-1)231 2147483647 int64_t占用8个byte,数据范围 -2^63 到 (2^63-1)…...

mac m1使用docker安装kafka
1.拉取镜像 docker pull zookeeper docker pull wurstmeister/kafka 2.启动zookeeper docker run -d --name zookeeper -p 2181:2181 zookeeper 3.设置zookeeper容器对外服务的ip Zookeeper_Server_IP$(docker inspect zookeeper --format{{ .NetworkSettings.IPAddress }}…...
SpringBoot核心配置和注解
目录 一、注解 元注解 基本注解 启动注解 二、配置 格式介绍 读取配置文件信息 案例演示1 嵌套读取bean信息 案例演示2 读取Map,List 以及 Array 类型配置数据 案例演示3 三、总结 一、注解 之前我们了解了SpringBoot基础和AOP简单应用,这期来讲…...
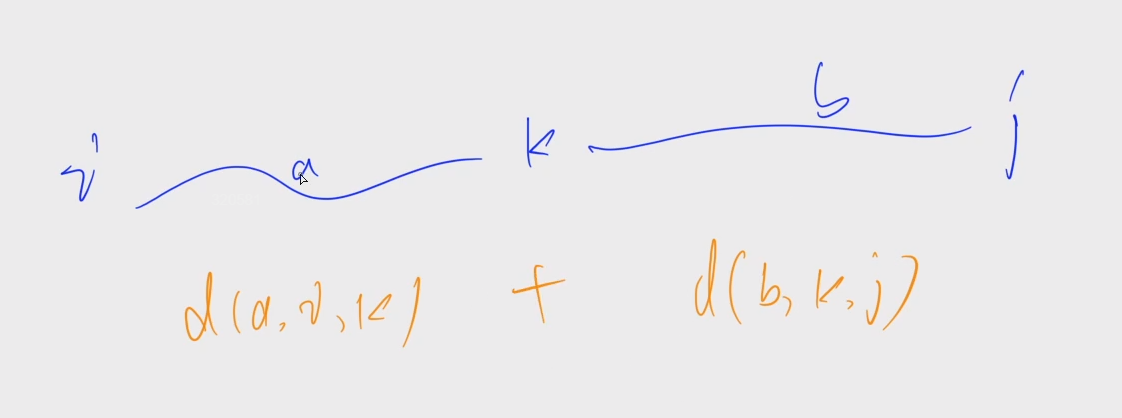
第三章 图论 No.3 flody之多源汇最短路,传递闭包,最小环与倍增
文章目录 多源汇最短路:1125. 牛的旅行传递闭包:343. 排序最小环:344. 观光之旅345. 牛站 flody的四个应用: 多源汇最短路传递闭包找最小环恰好经过k条边的最短路 倍增 多源汇最短路:1125. 牛的旅行 1125. 牛的旅行 …...
Leetcode-每日一题【剑指 Offer 17. 打印从1到最大的n位数】
题目 输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。 示例 1: 输入: n 1输出: [1,2,3,4,5,6,7,8,9] 说明: 用返回一个整数列表来代替打印 n 为正整数 解题思路 前置知识 M…...
远程调试MySQL内核
1 vscode 需要安装remote-ssh插件 安装成功后,登录: 默认远程服务器的登录 ssh rootip注意,Linux需要设置root远程登录; 2 安装debug扩展 C\C extemsion Pack C\C3 设置Attach进程 {// Use IntelliSense to learn about poss…...
前端学习---vue2--选项/数据--data-computed-watch-methods-props
写在前面: vue提供了很多数据相关的。 文章目录 data 动态绑定介绍使用使用数据 computed 计算属性介绍基础使用计算属性缓存 vs 方法完整使用 watch 监听属性介绍使用 methodspropspropsData data 动态绑定 介绍 简单的说就是进行双向绑定的区域。 vue实例的数…...
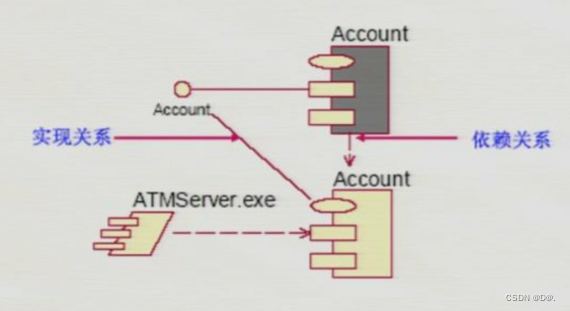
UML-构件图
目录 1.概述 2.构件的类型 3.构件和类 4.构件图 1.概述 构件图主要用于描述各种软件之间的依赖关系,例如,可执行文件和源文件之间的依赖关系,所设计的系统中的构件的表示法及这些构件之间的关系构成了构件图 构件图从软件架构的角度来描述…...

uniapp使用视频地址获取视频封面
很多时候我们都需要使用视频的第一帧当作视频的封面,今天我们从uni-app的安卓app这个环境来实现下这个需求。文中需要你对uniapp的renderjs有一定了解,可以先看我的这篇文章初识renderjs uniapp 安卓APP端(ios未测试) 方法&…...

java操作PDF:转换、合成、切分
将PDF每一页切割成图片 PDFUtils.cutPNG("D:/tmp/1.pdf","D:/tmp/输出图片路径/"); 将PDF转换成一张长图片 PDFUtils.transition_ONE_PNG("D:/tmp/1.pdf"); 将多张图片合并成一个PDF文件 PDFUtils.merge_PNG("D:/tmp/测试图片/"); 将多…...
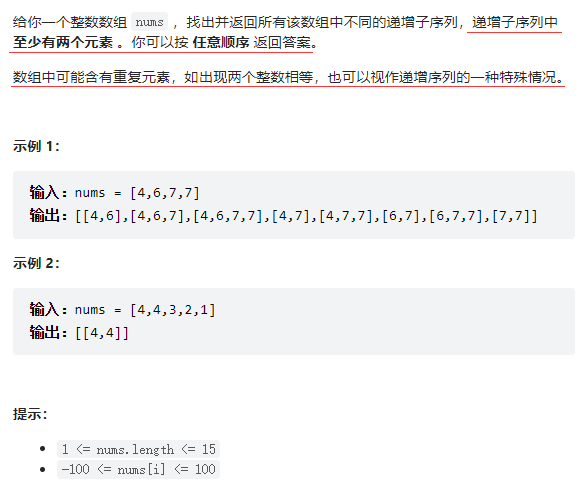
递增子序列——力扣491
文章目录 题目描述递归枚举 + 减枝题目描述 递归枚举 + 减枝 递归枚举子序列的通用模板 vector<vector<int>> ans; vector<int> temp; void dfs(int cur...

解密!品牌独立站为何能成为外国消费者的心头爱?
中国人做事强调要知其然、知其所以然、知其所以必然。这一理念非常符合新时代中国跨境出海品牌独立站的发展思路。在做好品牌独立站之前,我们也必须知其然(什么是独立站?),知其所以然(为什么要建独立站&…...
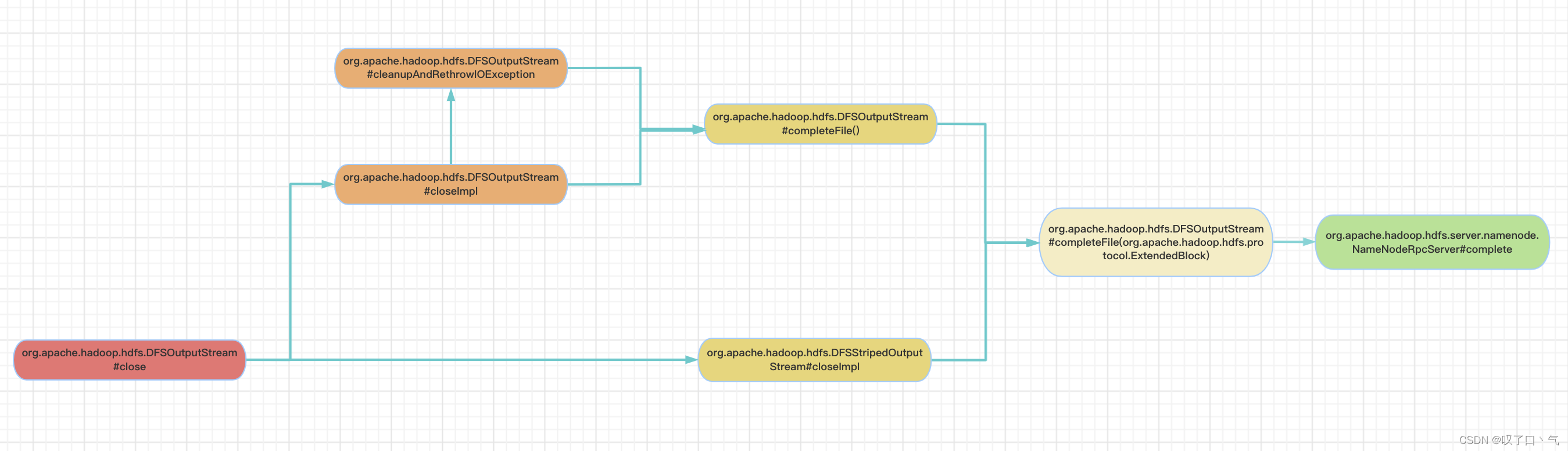
【HDFS】每天一个RPC系列----complete(二):客户端侧
上图给出了最终会调用到complete RPC的客户端侧方法链路(除去Router那条线了)。 org.apache.hadoop.hdfs.DFSOutputStream#completeFile(org.apache.hadoop.hdfs.protocol.ExtendedBlock): 下面这个方法在complete rpc返回true之前,会进行重试,直到超过最大重试次数抛异…...
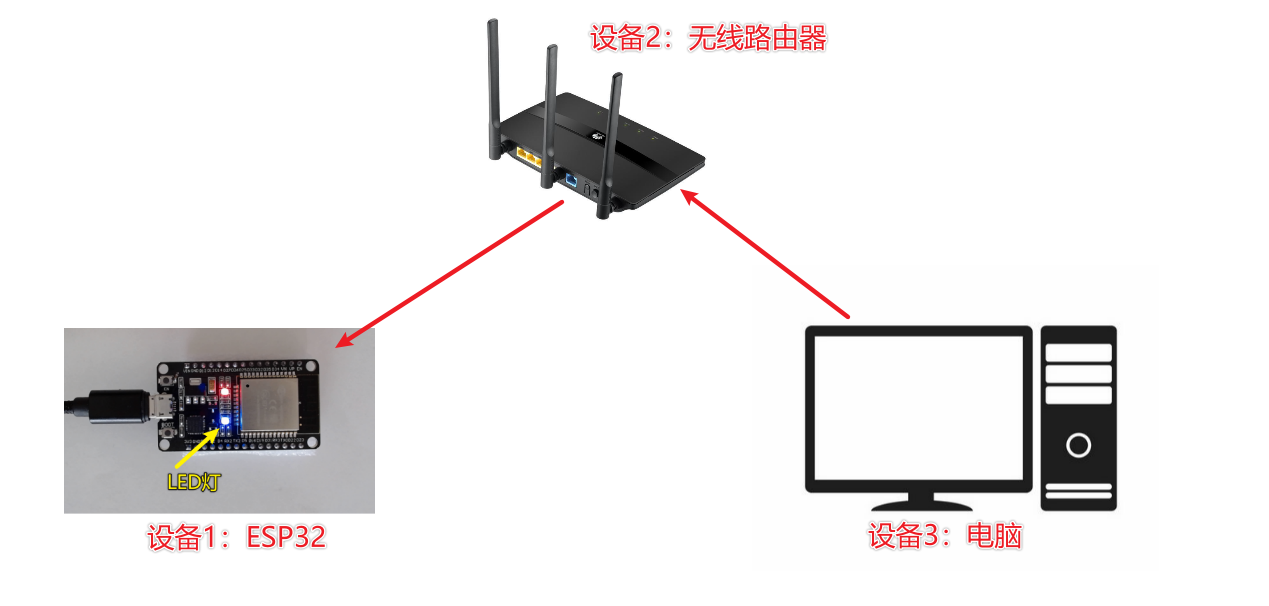
五、PC远程控制ESP32 LED灯
1. 整体思路 2. 代码 # 整体流程 # 1. 链接wifi # 2. 启动网络功能(UDP) # 3. 接收网络数据 # 4. 处理接收的数据import socket import time import network import machinedef do_connect():wlan = network.WLAN(network.STA_IF)wlan.active(True)if not wlan.isconnected(…...

详解PHP反射API
PHP中的反射API就像Java中的java.lang.reflect包一样。它由一系列可以分析属性、方法和类的内置类组成。它在某些方面和对象函数相似,比如get_class_vars(),但是更加灵活,而且可以提供更多信息。反射API也可与PHP最新的面向对象特性一起工作&…...

打开虚拟机进行ip addr无网络连接
打开虚拟机进行ip addr无网络连接 参考地址:https://www.cnblogs.com/Courage129/p/16796390.html 打开虚拟机进行ip addr无网络连接。 输入下面的命令, sudo dhclient ens33 会重新分配一个新的ip地址,但是此时的ip地址已经不是我原先在虚…...
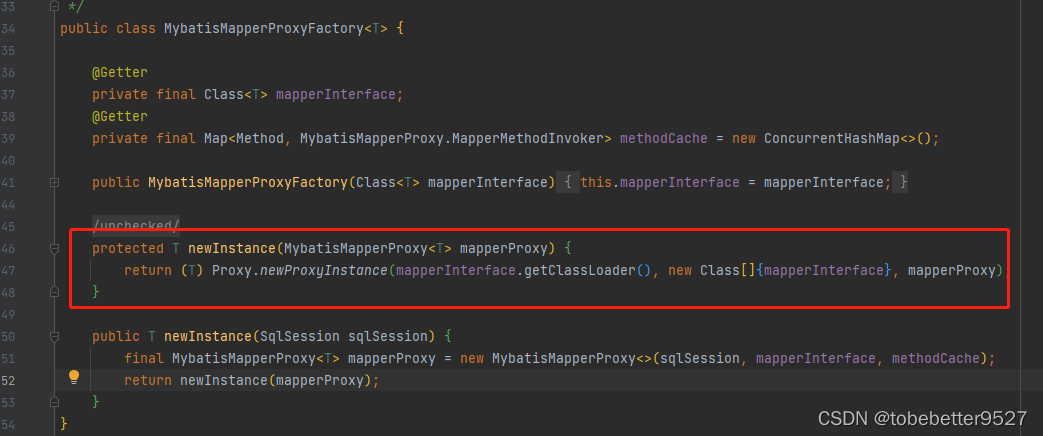
Spring Boot如何整合mybatisplus
文章目录 1. 相关配置和代码2. 整合原理2.1 spring boot自动配置2.2 MybatisPlusAutoConfiguration2.3 debug流程2.3.1 MapperScannerRegistrar2.3.2MapperScannerConfigurer2.3.3 创建MybatisPlusAutoConfiguration2.3.4 创建sqlSessionFactory2.3.5 创建SqlSessionTemplate2.…...
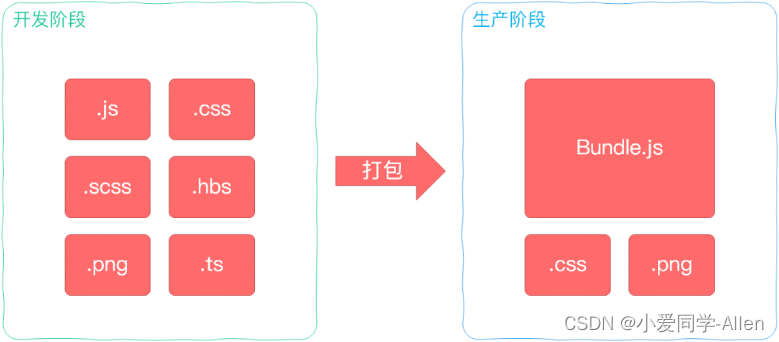
webpack基础知识一:说说你对webpack的理解?解决了什么问题?
一、背景 Webpack 最初的目标是实现前端项目的模块化,旨在更高效地管理和维护项目中的每一个资源 模块化 最早的时候,我们会通过文件划分的形式实现模块化,也就是将每个功能及其相关状态数据各自单独放到不同的JS 文件中 约定每个文件是一…...

AI与XR融合实战:Mosaic-Bridge中间件架构与性能调优
1. 项目概述:一个连接AI与XR世界的桥梁 最近在探索AI与扩展现实(XR)融合的落地场景时,我遇到了一个非常有意思的开源项目—— MosaicXR-AI/mosaic-bridge 。乍一看这个标题,你可能会觉得它只是一个普通的“桥接”工…...

出库篇:仓库里的货往哪去?——WMS出库方式全解析,物流新人必读
仓库里的货往哪去?——WMS出库方式全解析,物流新人必读 摘要:货品有进必有出。上一期我们聊了WMS中货品的四大来源(采购、生产、退货、调拨入库),这一期我们来看看货品是怎么“出”去的——销售出库、采购退…...

杰理之智能充电舱通信模块【篇】
固定 VOUT0/1 使用的通信 IO 为 P10/P11,固定使用 UART0。 SDK公版已经做好智能仓的基本通信交互了,耳机电量获取,状态获取,耳机配对等...

如何快速实现文献元数据智能转换:Zotero插件终极指南
如何快速实现文献元数据智能转换:Zotero插件终极指南 【免费下载链接】zotero-format-metadata Linter for Zotero. A plugin for Zotero to format item metadata. Shortcut to set title rich text; set journal abbreviations, university places, and item lang…...

智能体编排框架实战:构建可控可观测的多AI协同工作流
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想把多个大语言模型(LLM)和工具(Tools)组合起来,搞点自动化流程。市面上现成的框架不少,但要么太重,要么太“黑盒”,想…...

基于LLM的智能网页自动化:从意图理解到工程实践
1. 项目概述:当AI学会“看”和“点”,自动化进入新阶段如果你还在为那些需要手动点击、填写表单、抓取数据的重复性网页任务感到头疼,那么browser-use这个项目可能会让你眼前一亮。简单来说,它不是一个普通的浏览器自动化工具&…...

3分钟搞定Windows安卓应用:APK安装器让你的电脑秒变安卓设备!
3分钟搞定Windows安卓应用:APK安装器让你的电脑秒变安卓设备! 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你知道吗?现在无需安装…...

学Simulink——微电网中双向DC-AC逆变器的孤岛检测与运行控制仿真
目录 手把手教你学Simulink——微电网中双向DC-AC逆变器的孤岛检测与运行控制仿真 一、背景与挑战 1.1 什么是孤岛?为什么它是“安全隐患”? 1.2 核心痛点与设计目标 二、系统架构与核心控制推导 2.1 整体架构:感知、决策与执行的分层设计 2.2 核心数学推导:孤岛检测…...

Space Thumbnails:Windows资源管理器的终极3D模型预览解决方案
Space Thumbnails:Windows资源管理器的终极3D模型预览解决方案 【免费下载链接】space-thumbnails Generates preview thumbnails for 3D model files. Provide a Windows Explorer extensions that adds preview thumbnails for 3D model files. 项目地址: https…...

Real-is-Sim框架:动态数字孪生在机器人控制中的创新应用
1. Real-is-Sim框架概述:动态数字孪生的创新实践在机器人控制领域,仿真到现实的迁移(sim-to-real)一直是个棘手难题。传统方法往往面临"仿真太完美,现实太复杂"的困境——在虚拟环境中训练的策略,…...