【深度学习】采用自动编码器生成新图像
一、说明
你知道什么会很酷吗?如果我们不需要所有这些标记的数据来训练 我们的模型。我的意思是标记和分类数据需要太多的工作。 不幸的是,大多数现有模型从支持向量机到卷积神经网,没有它们,卷积神经网络就无法训练。无监督学习不需要标注。无监督学习从未标记推断函数 数据本身。最著名的无监督算法是K-Means,它具有 广泛用于将数据聚类到组中和 PCA,这是首选 降维解决方案。K-Means和PCA可能是最好的两个 曾经构思过的机器学习算法。让他们变得更好的是 他们的简单性。我的意思是,如果你抓住它们,你会说:“我为什么不这样做?
二、自动编码器。
为了更好地理解自动编码器,我将提供一些代码以及解释。请注意,我们将使用 Pytorch 来构建和训练我们的模型。
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.nn import functional as F自动编码器是简单的神经网络,它们的输出就是它们的输入。简单 就这样。他们的目标是学习如何重建输入数据。但是怎么样 有益的?诀窍在于它们的结构。网络的第一部分是我们 称为编码器。它接收输入并将其编码为潜在 较低维度的空间。第二部分(解码器)采用该向量和 对其进行解码以生成原始输入。
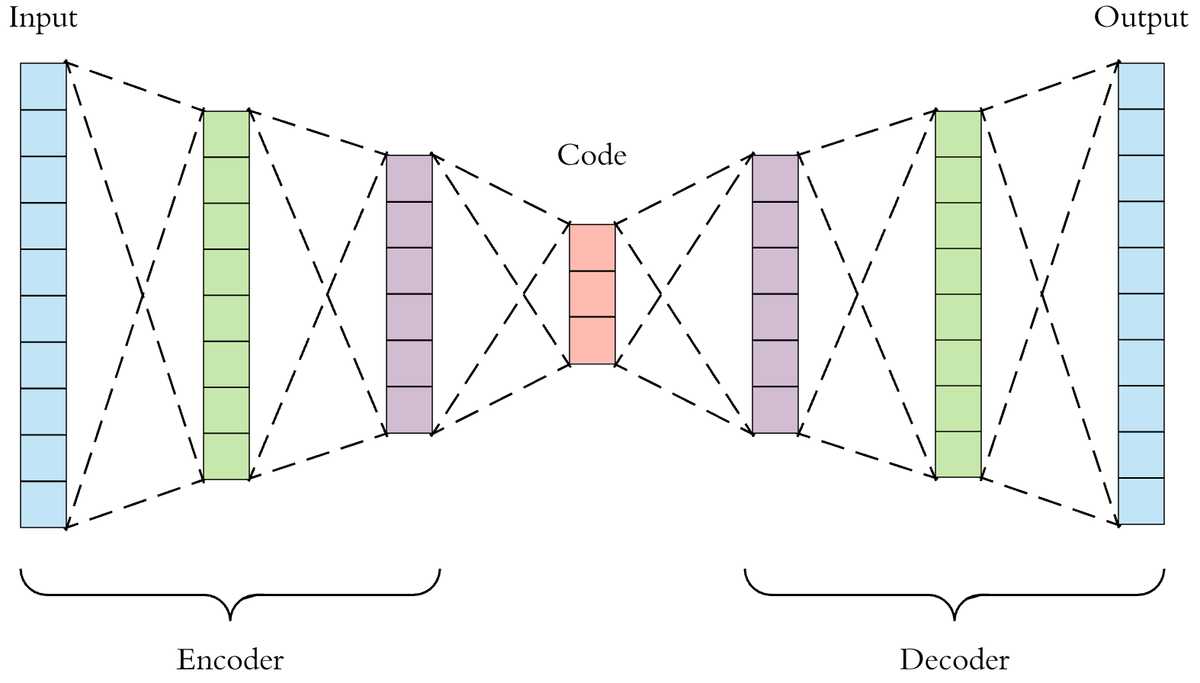
用于基于ECG的生物特征识别中异常值校正的自动编码器神经网络
中间的潜在向量是我们想要的,因为它是输入的压缩表示。并且应用非常丰富,例如:
-
压缩
-
降维
此外,很明显,我们可以应用它们来重现相同的内容,但 数据几乎没有不同,甚至更好。例如:
-
数据去噪:用嘈杂的图像馈送它们,并训练它们输出 图像相同,但没有噪点
-
训练数据增强
-
异常检测:在单个类上训练它们,以便每个异常都给出 重建误差大。
然而,自动编码器面临着与大多数神经网络相同的问题。他们 倾向于过度拟合,他们遭受梯度消失问题的困扰。有没有 溶液?
三、变分自动编码器 (VAE)
变分自动编码器是一个相当不错和优雅的努力。它 本质上增加了随机性,但并不完全正确。
让我们进一步解释一下。变分自动编码器经过训练以学习 对输入数据进行建模的概率分布,而不是对 映射输入和输出。然后,它从此分布中采样点 并将它们馈送到解码器以生成新的输入数据样本。但是等一下 分钟。当我听到概率分布时,只有一件事来了 想到:贝叶斯。是的,贝叶斯规则再次成为主要原则。由 方式,我不是要夸大其词,但贝叶斯公式是唯一最好的方程 曾经创建过。我不是在开玩笑。它无处不在。如果你不知道什么 是,请查一下。抛弃那篇文章,了解贝叶斯是什么。我会原谅的 你。
回到变分自动编码器。我认为下面的图像清楚地说明了问题:
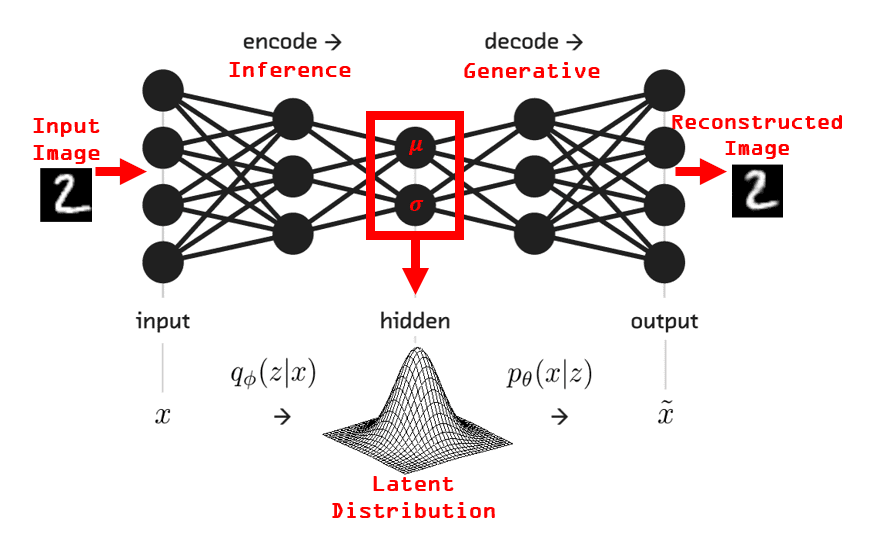
使用循环变分自动编码器进行纹理合成
你有它。随机神经网络。在我们构建示例之前,我们的 自己生成新图像,讨论更多细节是合适的。
VAE的一个关键方面是损失函数。最常见的是,它包括 两个组件。重建损失衡量的是 重建的数据来自原始数据(例如二进制交叉熵)。 KL-散度试图使过程正规化并保持重建 数据尽可能多样化。
def loss_function(recon_x, x, mu, logvar) -> Variable:BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784))KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())KLD /= BATCH_SIZE * 784return BCE + KLD另一个重要方面是如何训练模型。困难的发生是因为 变量是确定性的,但通常是随机和梯度下降的 不是那样工作的。为了解决这个问题,我们使用重新参数化。潜伏的 向量 (z) 将等于分布的学习均值 (μ) 加上 学习标准差 (σ) 乘以 epsilon (ε),其中 ε 遵循正态 分配。我们重新参数化样本,使随机性 与参数无关。
def reparameterize(self, mu: Variable, logvar: Variable) -> Variable:#mu : mean matrix#logvar : variance matrixif self.training:std = logvar.mul(0.5).exp_() # type: Variableeps = Variable(std.data.new(std.size()).normal_())return eps.mul(std).add_(mu)else:return mu四、使用自动编码器生成图像
在我们的示例中,我们将尝试使用变分自动编码器生成新图像。我们将使用MNIST数据集,重建的图像将是手写的数字。正如我已经告诉过你的,我使用 Pytorch 作为一个框架,除了熟悉之外,没有特别的原因。 首先,我们应该定义我们的层。
def __init__(self):super(VAE, self).__init__()# ENCODERself.fc1 = nn.Linear(784, 400)self.relu = nn.ReLU()self.fc21 = nn.Linear(400, 20) # mu layerself.fc22 = nn.Linear(400, 20) # logvariance layer# DECODERself.fc3 = nn.Linear(20, 400)self.fc4 = nn.Linear(400, 784)self.sigmoid = nn.Sigmoid()如您所见,我们将使用一个非常简单的网络,只有密集层(在pytorch的情况下是线性的)。 下一步是生成运行编码器和解码器的函数。
def encode(self, x: Variable) -> (Variable, Variable):h1 = self.relu(self.fc1(x))return self.fc21(h1), self.fc22(h1)def decode(self, z: Variable) -> Variable:h3 = self.relu(self.fc3(z))return self.sigmoid(self.fc4(h3))def forward(self, x: Variable) -> (Variable, Variable, Variable):mu, logvar = self.encode(x.view(-1, 784))z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvar这只是几行python代码。没什么大不了的。最后,我们可以训练我们的模型并查看我们生成的图像。
快速提醒:与tensorflow相比,Pytorch有一个动态图,这意味着代码是动态运行的。无需创建图然后编译执行它,Tensorflow 最近以其渴望的执行模式引入了上述功能。
optimizer = optim.Adam(model.parameters(), lr=1e-3)def train(epoch):model.train()train_loss = 0for batch_idx, (data, _) in enumerate(train_loader):data = Variable(data)optimizer.zero_grad()recon_batch, mu, logvar = model(data)loss = loss_function(recon_batch, data, mu, logvar)loss.backward()train_loss += loss.data[0]optimizer.step()def test(epoch):model.eval()test_loss = 0for i, (data, _) in enumerate(test_loader):data = Variable(data, volatile=True)recon_batch, mu, logvar = model(data)test_loss += loss_function(recon_batch, data, mu, logvar).data[0]for epoch in range(1, EPOCHS + 1):train(epoch)test(epoch)训练完成后,我们执行测试函数来检查模型的工作情况。 事实上,它做得很好,构建的图像与原始图像几乎相同,我相信没有人能够在不了解整个故事的情况下区分它们。
下图显示了第一行的原始照片和第二行中制作的照片。
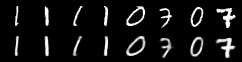
相当不错,不是吗?
有关自动编码器的更多详细信息,您应该查看edX的深度学习与Tensorflow课程的模块5。
在我们结束这篇文章之前,我想再介绍一个话题。正如我们所看到的,变分自动编码器能够生成新图像。这是生成模型的经典行为。生成模型正在生成新数据。另一方面,判别模型正在对类或类别中的现有数据进行分类或区分。
用一些数学术语来解释这一点: 生成模型学习联合概率分布 p(x,y),而判别模型学习条件概率分布 p(y|x)。
在我看来,生成模型更有趣,因为它们为从数据增强到可能的未来状态的模拟等许多可能性打开了大门。但在下一篇文章中会有更多内容。 可能是在一篇关于一种相对较新的生成模型类型的帖子上,称为生成对抗网络。
在那之前,继续学习人工智能。
相关文章:
【深度学习】采用自动编码器生成新图像
一、说明 你知道什么会很酷吗?如果我们不需要所有这些标记的数据来训练 我们的模型。我的意思是标记和分类数据需要太多的工作。 不幸的是,大多数现有模型从支持向量机到卷积神经网,没有它们,卷积神经网络就无法训练。无监督学习不…...

华为云交付
文章目录 一、华为云-公有云架构华为公有云的主要服务1.华为云服务—计算类2.华为云服务——存储类3.华为云服务—网络类4.华为云服务—管理和监督类5.华为云数据库 二、待续 一、华为云-公有云架构 华为公有云的主要服务 ECS:弹性云服务器( Elastic Cl…...
dns瞅一瞅
正向解析—域名到ip 反向解析–ip到域名 域名本身是从又往左来解释的 根域—最顶层的域,用null字符标识,通常会省略最后的点和null字符,但是应用程序会在解析dns之前添加这些字符 顶级域— 两种类型,一种国家、地区代码的顶级域…...
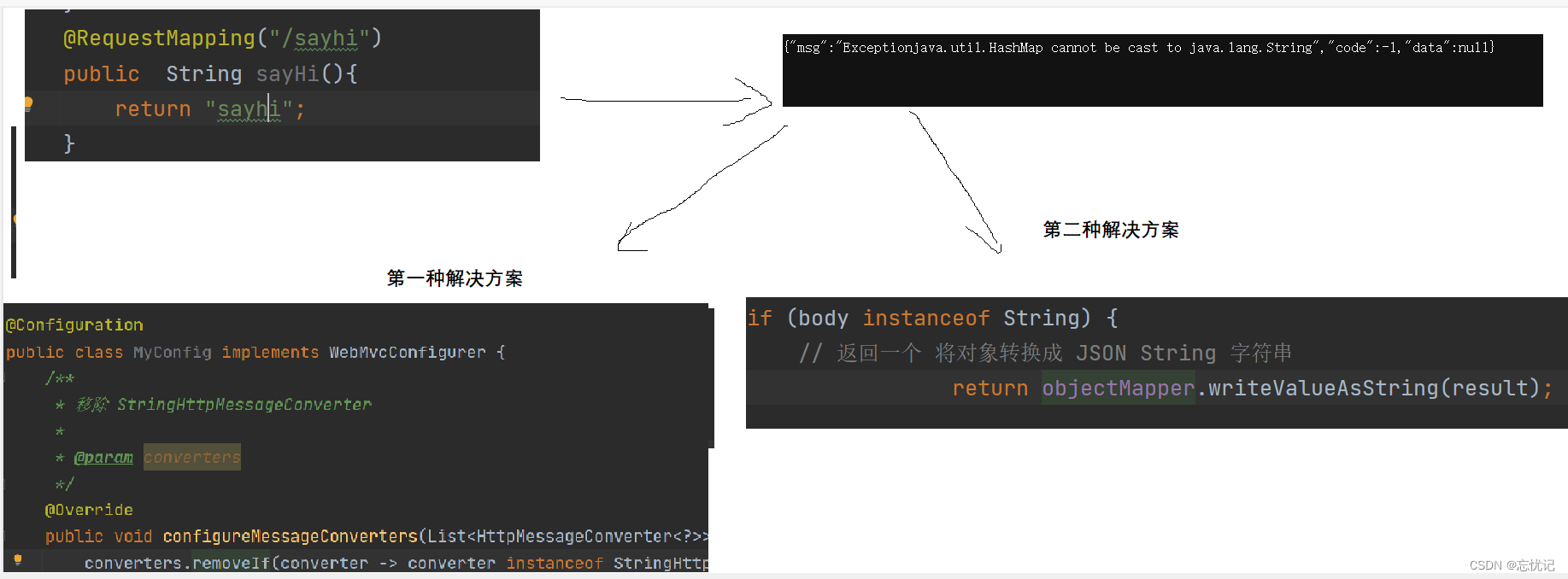
springAOP的实例
文章目录 前言一.用户登录权限校验1.1 spring 拦截器1.2 传统的用户登录权限验证1.3 使用拦截器的方式1.4 案例1.5 拦截器实现原理 三.统一异常处理3.1 什么是统一异常处理3.2 具体步骤 四.统⼀数据返回格式4.1 为什么需要统一的数据返回4.2 统一返回数据的格式4.3 统一移除处理…...
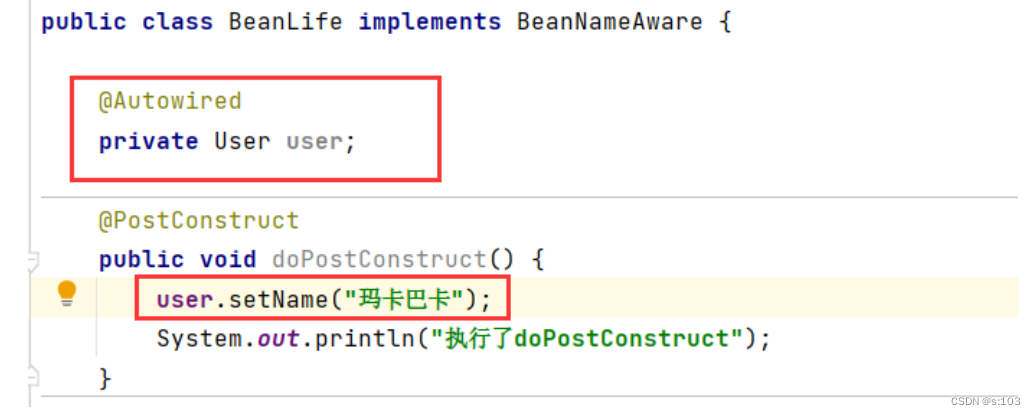
【JavaEE】深入了解Spring中Bean的可见范围(作用域)以及前世今生(生命周期)
【JavaEE】Spring的开发要点总结(4) 文章目录 【JavaEE】Spring的开发要点总结(4)1. Bean的作用域1.1 一个例子感受作用域的存在1.2 通过例子说明作用域的定义1.3 六种不同的作用域1.3.1 singleton单例模式(默认作用域…...
)
P1320 压缩技术(续集版)
题目描述 设某汉字由 N N N \times N NN 的 0 \texttt 0 0 和 1 \texttt 1 1 的点阵图案组成。 我们依照以下规则生成压缩码。连续一组数值:从汉字点阵图案的第一行第一个符号开始计算,按书写顺序从左到右,由上至下。第一个数表示连续有…...
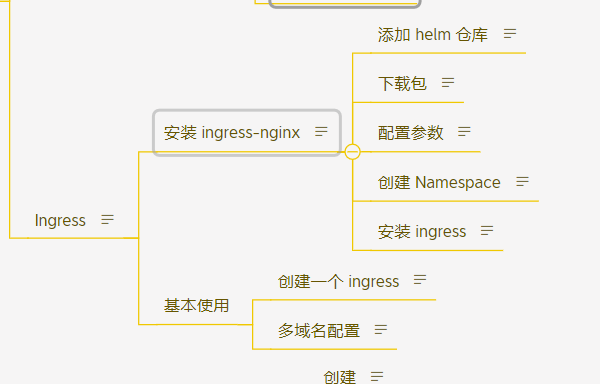
k8s(七) 叩丁狼 service Ingress
负责东西流量(同层级/内部服务网络通信)的通信 service的定义 apiVersion: v1 kind: Service metadata:name: nginx-svclabels:app: nginx-svc spec:ports:- name: http # service 端口配置的名称protocol: TCP # 端口绑定的协议,支持 TCP、…...
Android Studio 关于BottomNavigationView 无法预览视图我的解决办法
一、前言:最近在尝试一步一步开发一个自己的软件,刚开始遇到的问题就是当我们引用 com.google.android.material.bottomnavigation.BottomNavigationView出现了无法预览视图的现象,我也在网上查了很多中解决方法,最后在执行了如下…...
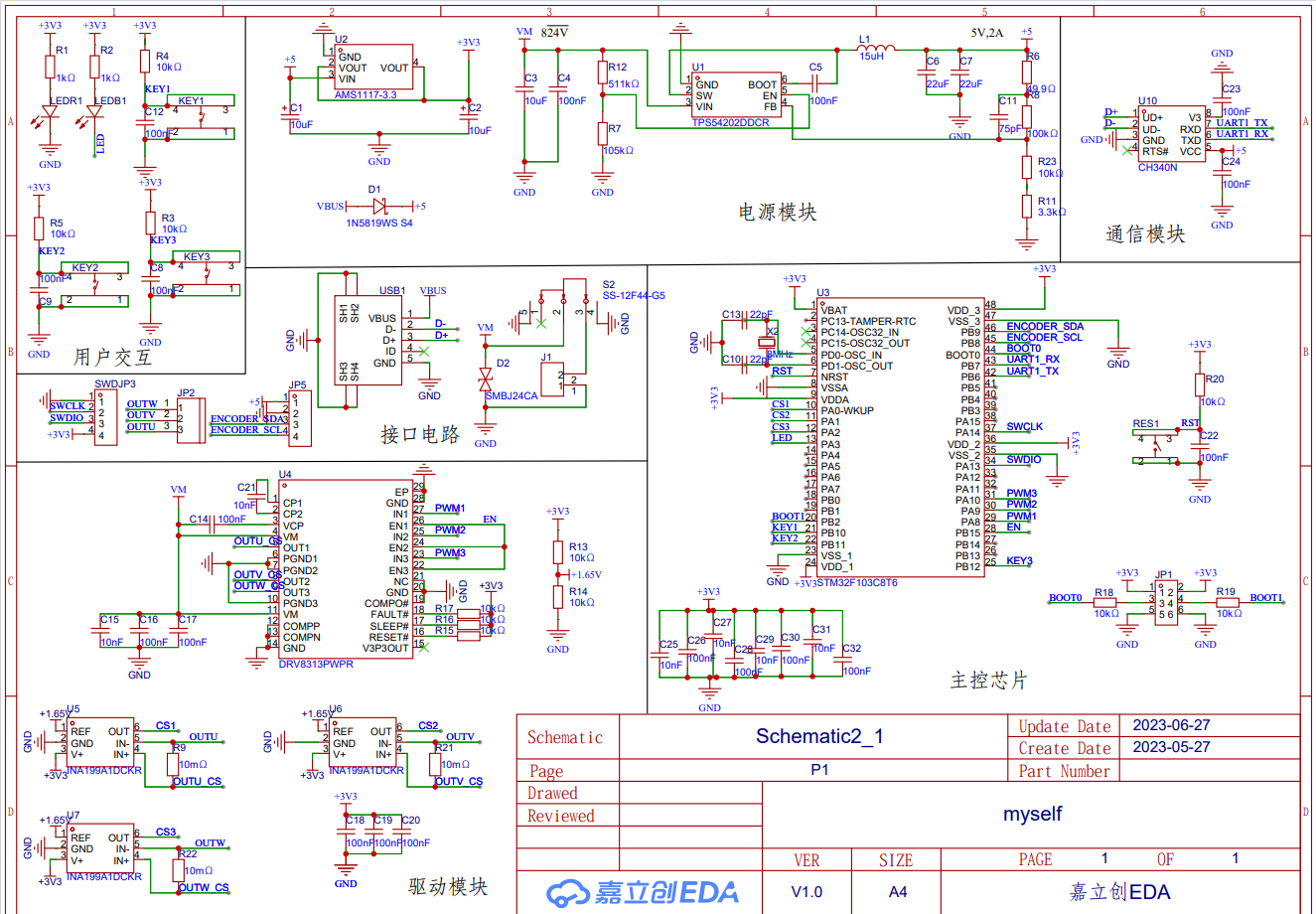
【STM32】小电流FOC驱控一体板(开源)
FOC驱控一体板 主控芯片stm32f103c8t6 驱动芯片drv8313 三相电流采样 根据B站一个UP主的改的(【【自制】年轻人的第一块FOC驱动器】),大多数元器件是0805,实验室具备且便于自己动手焊接 。 晶振用的是无源晶振,体…...
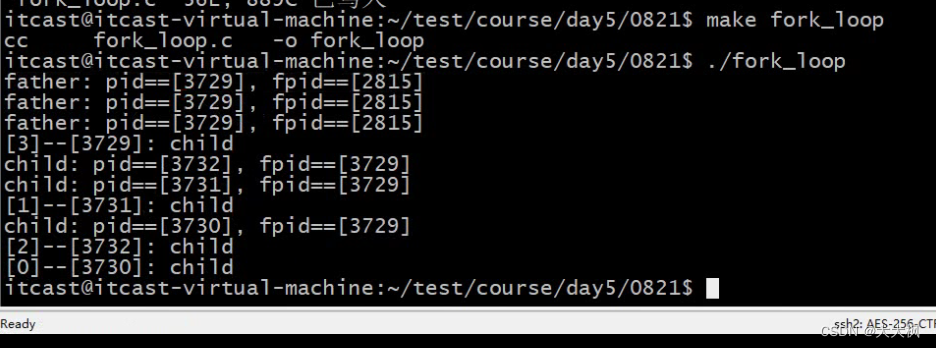
代码分析:循环创建N个子进程——为什么最后一个属于父进程?
黑马C/C 2018年32期代码分析 //循环创建n个子进程 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <unistd.h>int main() {int i 0;for(i0; i<3; i){//创建子进程pid_t pid fork();if(pid&…...

【SpringBoot面试题整理-超级有效】
文章目录 1.SpringBoot如何解决跨域问题?2.为什么要用Spring Boot?3. Spring Boot的约定优于配置,你的理解是什么?4. SpringBoot有哪些优点?5. Spring Boot中自动装配机制的原理?6.SpringBoot支持哪些日志框…...

岩土工程仪器多通道振弦传感器信号转换器应用于隧道安全监测
岩土工程仪器多通道振弦传感器信号转换器应用于隧道安全监测 多通道振弦传感器信号转换器VTI104_DIN 是轨道安装式振弦传感器信号转换器,可将振弦、温度传感器信号转换为 RS485 数字信号和模拟信号输出,方便的接入已有监测系统。 传感器状态 专用指示灯方…...

西瓜书读书笔记整理(五)—— 第四章 决策树
第四章 决策树 4.1 基本流程4.1.1 什么是决策树算法4.1.2 决策树学习的目的4.1.3 决策树学习基本过程4.1.4 决策树学习基本算法4.1.5 递归结束的三种情况 4.2 划分选择4.2.1 信息增益(information gain)—— ID3 决策树学习算法属性划分准则4.2.2 信息增…...
STM32 4G学习
硬件连接 ATK-IDM750C模块可直接与正点原子 MiniSTM32F103开发板板载的ATK模块接口(ATK-MODULE)进行连接。 功能说明 ATK-IDM750C是正点原子(ALIENTEK)团队开发的一款高性能4G Cat1 DTU产品,支持移动4G、联通4G和…...

Golang 中实现实时聊天通讯
客户端代码 package mainimport ("fmt""log""net/url""os""os/signal""time""github.com/gorilla/websocket" )func main() {interrupt : make(chan os.Signal, 1)signal.Notify(interrupt, os.Interr…...
每天10个小知识点)
前端面试的性能优化部分(5)每天10个小知识点
目录 系列文章目录前端面试的性能优化部分(1)每天10个小知识点前端面试的性能优化部分(2)每天10个小知识点前端面试的性能优化部分(3)每天10个小知识点前端面试的性能优化部分(4)每天…...

【链表OJ 1】移除链表元素val
大家好,欢迎来到我的博客,此题是关于链表oj的第一题,此后还会陆续更新博客,如有错误,欢迎大家指正。 来源:https://leetcode.cn/problems/remove-linked-list-elements/description/ 题目: 方法一:定义prev和cur指针…...

复原 IP 地址——力扣93
文章目录 题目描述回溯题目描述 回溯 class Solution{public:static constexpr int seg_count=4<...
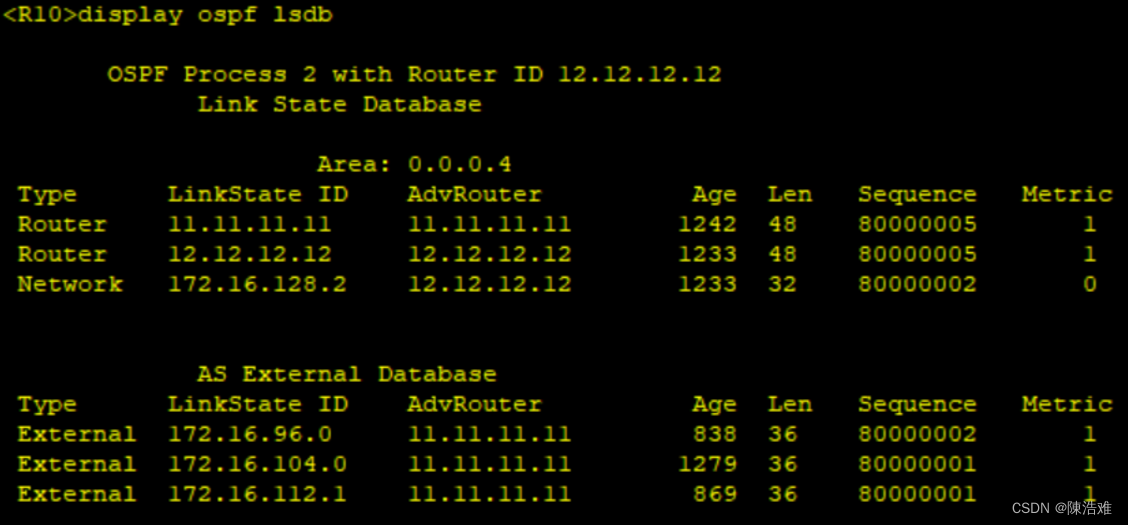
OSPF综合实验
实验题目如下: 实验拓扑如下: 实验要求如下: 【1】R4为ISP,其上只能配置IP地址: R4与其他所有直连设备间使用公有 【2】R3---R5/6/7为MGRE环境,R3为中心站点 【3】整个OSPF环境IP地址为172.16.0.0/16 【4】所有设备…...

安卓4G核心板开发板_MTK6785/MT6785(Helio G95)安卓手机主板方案
联发科MTK6785(Helio G95)安卓核心板采用八核 CPU 具有两个强大的 Arm Cortex-A76 处理器内核,主频高达 2.05GHz,外加六个 Cortex-A55 高效处理器。其强大的图形性能由 Arm Mali-G76 MC4 提供,速度可提升至 900MHz 。 …...

终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校
终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitco…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...

开源项目容器镜像全流程实践:从命名规范到生产部署
1. 项目概述:从镜像名到开源协作生态的深度解构看到mco-org/mco这个镜像名,很多人的第一反应可能是去 Docker Hub 或 GitHub 上搜索,看看它具体是什么。但今天,我想从一个更本质、更实战的角度来聊聊这个话题。mco-org/mco不是一个…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈
Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈 【免费下载链接】Qwen2.5-14B 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/Qwen2.5-14B 当开发者面对复杂的代码生成任务或技术文档分析需求时,往往会受限于云端API的延迟和…...

Git Worktree CLI工具:告别分支切换焦虑,实现高效并行开发
1. 项目概述与核心价值如果你和我一样,长期在多个Git分支间穿梭,同时维护着几个不同的功能特性或修复补丁,那你一定对那种在分支间反复切换、代码状态混乱、甚至不小心提交到错误分支的“切分支焦虑症”深有体会。传统的git checkout或git sw…...

【Midjourney极简艺术风格终极指南】:20年视觉设计专家亲授3大构图法则、5类禁用提示词与1套可复用Prompt模板
更多请点击: https://intelliparadigm.com 第一章:极简艺术风格的本质与Midjourney适配原理 极简艺术风格并非简单地“减少元素”,而是通过精准的留白、克制的色彩、几何化的形态与高度凝练的视觉语法,实现信息密度与情绪张力的平…...