Huggingface使用
文章目录
- 前置安装
- Huggingface介绍
- NLP模块分类
- transformer流程
- 模块使用详细讲解
- tokennizer
- model
- datasets
- Trainer
- Huggingface使用
- 网页直接体验
- API调用
- 本地调用(pipline)
- 本地调用(非pipline)
前置安装
-
anaconda安装
-
使用conda创建一个新环境并安装
pytorch打开链接 https://pytorch.org/get-started/locally/, 选择对应的系统即可
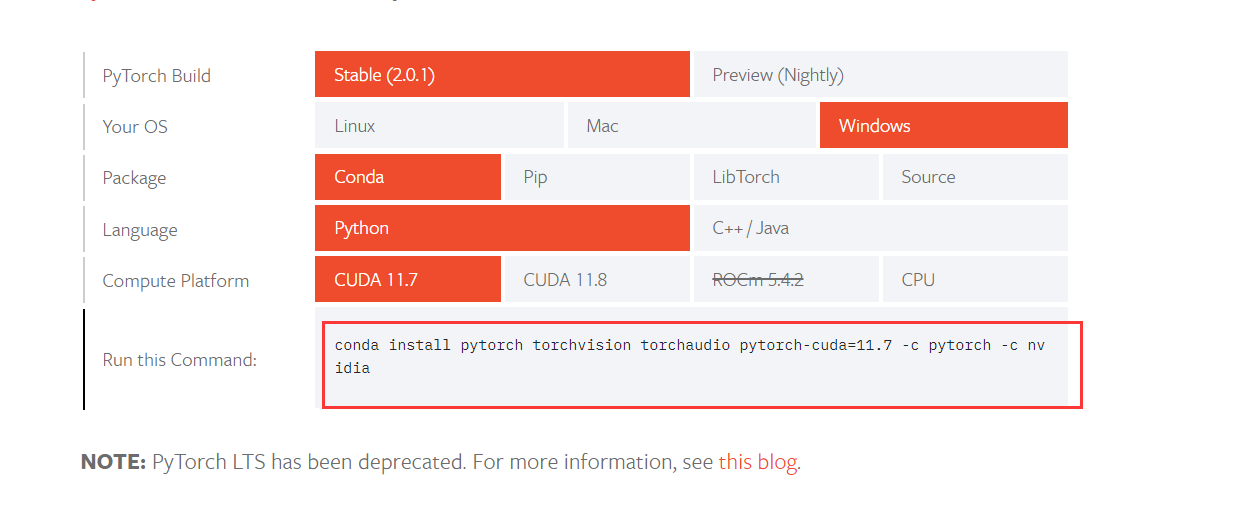
-
安装
transformers和datasets
pip install transformers
pip install datasets
这两个是huggingface最核心的模块
- 安装
torch
pip install torch
Huggingface介绍
本次只介绍 NLP(Natural Language Processing)相关的模型,其他的,如 文本生成语音,文本生成图片相关的模型不做过多介绍,使用起来基本都大差不差的。也可以直接阅读Huggingface提供的官方文档:https://huggingface.co/learn/nlp-course/zh-CN/chapter0/1?fw=pt
NLP模块分类
NLP 一共有以下几大模型类别,每个类别下模型做的事情也不一样,有的是用来翻译的,有的是分类,而有的是文本生成,具体有那些可通过这个链接查看:https://huggingface.co/models
- text-classification 文本分类,给一段文本进行打标分类
- feature-extraction 特征提取:把一段文字用一个向量来表示
- fill-mask 填词:把一段文字的某些部分mask住,然后让模型填空
- ner 命名实体识别:识别文字中出现的人名地名的命名实体
- question-answering 问答:给定一段文本以及针对它的一个问题,从文本中抽取答案
- summarization 摘要:根据一段长文本中生成简短的摘要
- text-generation文本生成:给定一段文本,让模型补充后面的内容
- translation 翻译:把一种语言的文字翻译成另一种语言
transformer流程
一般transformer模型有三个部分组成:1.tokennizer,2.Model,3.Post processing

- 分词器将我们输入的信息转成 Input IDs
- 将Input IDs输入到模型中,模型返回预测值
- 将预测值输入到后置处理器中,返回我们可以看懂的信息
模块使用详细讲解
tokennizer
官网文档地址
分词器的职责
- 将输入拆分为单词、子单词或符号(如标点符号),称为标记(token)
- 将每个标记(token)映射到一个整数
- 添加可能对模型有用的其他输入
代码使用
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)raw_inputs = ["I love you","I love you so much",
]
inputs = tokenizer(raw_inputs, max_length=8, padding=True, truncation=True, return_tensors="pt")
print(inputs)
'''
输出{'input_ids': tensor([[ 101, 1045, 2293, 2017, 102, 0, 0],[ 101, 1045, 2293, 2017, 2061, 2172, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1]])}
'''# 将ids反解码
output = tokenizer.decode([ 101, 1045, 2293, 2017, 102])
print(output )
## 输出:[CLS] i love you [SEP]
输出结果说明
input_ids: 也就是输入到模型里的数据,每次数字都对应我们输入的一个词,这里可以看到 我们输入了 3个词,但输出了8个数字,这是因为 最两个0是用来补齐到最大长度的,而 除此之外的 首尾 数字 是个标识符,101标识这是做文本分类,102表示这行句子结束了attention_mask: 是有效运算字符标识,1表示ids里这个位置的字符是有效的,0表示这个位置是补齐的
tokenizer参数说明
max_length: 表示每一个的ids数组的最大长度padding: 表示是否需要补齐位数truncation: 表示超过最大长度后是否需要阶段return_tensors:表示返回的tensor为pytorch,也可以写tf表示 tensorflow
model
通过该地址可查看Huggingface的所有模型:https://huggingface.co/models
模型职责
模型Head将隐藏状态的高维向量作为输入,并将其投影到不同的维度。它们通常由一个或几个线性层组成。下图是模型的基本逻辑

在此图中,模型由其嵌入层和后续层表示。嵌入层将标记化输入中的每个输入ID转换为表示关联标记(token)的向量。后续层使用注意机制操纵这些向量,以生成句子的最终表示。
代码使用
## 最简单的使用
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
如果我们需要一个带有序列分类头的模型(能够将句子分类为肯定或否定)。我们实际上不会直接使用AutoModel类,而是使用AutoModelForSequenceClassification:
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
import torchcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
# 文本输入
raw_inputs = ["I love you","I love you so much",
]
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 执行分词器
inputs = tokenizer(raw_inputs, max_length=8, padding=True, truncation=True, return_tensors="pt")
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
# 为了获得每个位置对应的标签,我们可以检查模型配置的id2label属性(下一节将对此进行详细介绍):
print(model.config.id2label)
# 输出 {0: 'NEGATIVE', 1: 'POSITIVE'} 表示越靠近0是负面的,越靠近1是正向的
# 调用模型输出
outputs = model(**inputs)
## 将模型输出的预测值logits给到torch,返回我们可以看懂的数据
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
# 输出 tensor([[1.3436e-04, 9.9987e-01],[1.3085e-04, 9.9987e-01]], grad_fn=<SoftmaxBackward0>)
# 第一句话,NEGATIVE=0.0001, POSITIVE=0.99 所以第一句话大概率是正向的
Transformers中有许多不同的体系结构,每种体系结构都是围绕处理特定任务而设计的。以下是一个非详尽的列表:
- *Model (retrieve the hidden states)
- *ForCausalLM
- *ForMaskedLM
- *ForMultipleChoice
- *ForQuestionAnswering
- *ForSequenceClassification
- *ForTokenClassification
- 其他
datasets
通过该地址可查看Huggingface的所有数据集:https://huggingface.co/datasets
加载数据集
from datasets import load_datasetdataset = load_dataset("glue", "mrpc")
print(dataset)
'''
输出
DatasetDict({//训练的数据集train: Dataset({features: ['sentence1', 'sentence2', 'label', 'idx'],num_rows: 3668})// 校验数据集validation: Dataset({features: ['sentence1', 'sentence2', 'label', 'idx'],num_rows: 408})// 测试数据集test: Dataset({features: ['sentence1', 'sentence2', 'label', 'idx'],num_rows: 1725})
})
'''
加载本地或远端数据集
from datasets import load_dataset## 加载本地数据集
local_data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=local_data_files , field="data")## 加载外部远端上数据集
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {"train": url + "SQuAD_it-train.json.gz","test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
数据集操作
官方文档:https://huggingface.co/learn/nlp-course/zh-CN/chapter3/2?fw=pt
from datasets import load_datasetdrug_sample= load_dataset("glue", "mrpc")
print(drug_sample)# 抽样1000个数据,并打印前3个
print(drug_sample["train"].shuffle(seed=42).select(range(1000))[:3])def tokenizer_datset(data):return tokenizer(data["sentence1"], data["sentence2"], truncation=True)
# 对集合里每个数据进行分词处理
drug_sample = drug_sample.map(tokenizer_datset, batched=True)
print(drug_sample)
'''
输出, 可以看到分词器产生的列(input_ids,attention_mask)已经加到数据集里了
Dataset({features: ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'attention_mask'],num_rows: 1000
})
'''
# 移除不需要的列
drug_sample = drug_sample.remove_columns(["sentence1", "sentence2", "idx"])
# 对列进行改名, label => labels
drug_sample = drug_sample.rename_column("label", "labels")
Trainer
官网文档:https://huggingface.co/learn/nlp-course/zh-CN/chapter3/3?fw=pt
代码使用
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding,TrainingArguments, AutoModelForSequenceClassification, Trainer# 获取数据集
raw_datasets = load_dataset("glue", "mrpc")# 加载分词器
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)# 对集合里的数据进行分词
def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)# 数据打包器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)# 获取train参数
training_args = TrainingArguments("test-trainer")
trainer = Trainer(model,training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,
)# 开始训练
trainer.train()
为了查看模型在每个训练周期结束的好坏,我们可以使用compute_metrics()函数定义一个新的 Trainer
# 测算模型的准确率
import evaluatedef compute_metrics(eval_preds):metric = evaluate.load("glue", "mrpc")logits, labels = eval_predspredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)# evaluation_strategy,设置评估环节为epoch,这样每个训练周期结束就会测算下目前模型的准确率
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")trainer = Trainer(model,training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,compute_metrics=compute_metrics,
)
自定义Trainer
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
from tqdm.auto import tqdm
import torch
from torch.utils.data import DataLoader# 模型
checkpoint = "bert-base-uncased"# 定义数据集
raw_datasets = load_dataset("glue", "mrpc")# 定义分词器
tokenizer = AutoTokenizer.from_pretrained(checkpoint)# 数据集预处理
def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 训练数据集加载器
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
# 评估数据集加载器
eval_dataloader = DataLoader(tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)# 优化器和学习率调度器,学习率调度器只是从最大值 (3e-5) 到 0 的线性衰减
optimizer = AdamW(model.parameters(), lr=3e-5)# 如果支持GPT则使用GPU进行训练
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)# 训练周期为3个
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,
)# 加个进度条
progress_bar = tqdm(range(num_training_steps))model.train()
for epoch in range(num_epochs):for batch in train_dataloader:batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)
分布式训练
使用
Accelerator进行分布式训练
from accelerate import Acceleratorfrom transformers import AdamW, AutoModelForSequenceClassification, get_schedulermodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)accelerator = Accelerator()train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader, eval_dataloader, model, optimizer
)num_epochs = 3num_training_steps = num_epochs * len(train_dataloader)lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)progress_bar = tqdm(range(num_training_steps))model.train()for epoch in range(num_epochs):for batch in train_dataloader:outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)
Huggingface使用
网页直接体验
可以在某个模型下直接体验该模型的效果
API调用
这个调用每天有量级限制
- 获取token
- 通过API访问
import os, requests, json
API_TOKEN = os.environ.get("HUGGINGFACE_API_KEY")
model = "google/flan-t5-xxl"
API_URL = f"https://api-inference.huggingface.co/models/{model}"
headers = {"Authorization": f"Bearer {API_TOKEN}", "Content-Type": "application/json"}def query(payload, api_url=API_URL, headers=headers): data = json.dumps(payload) response = requests.request("POST", api_url, headers=headers, data=data) return json.loads(response.content.decode("utf-8"))question = "Please answer the following question. What is the capital of France?"
data = query({"inputs" : question})
print(data)
本地调用(pipline)
本地调用需要将model下载到本地,好处是可以自己训练,微调参数
不过有的模型比较大,下载起来会比较慢
pipline 背后的流程: tokenizer => model => post-processing
from transformers import pipeline
# 进行文本分类,模型为:finiteautomata/bertweet-base-sentiment-analysis
classifier = pipeline("text-classification", model="finiteautomata/bertweet-base-sentiment-analysis")
res = classifier(["I'd love to learn the HuggingFace course", "fuck you"])
print(res)
本地调用(非pipline)
如果不使用pipeline 也可以一步一步调用
from transformers import AutoTokenizer
from transformers import AutoModel
import torch# 定义使用的模型
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"## 我们的输入
raw_inputs = ["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",
]
# tokenizer 定义分词词,一般分词器和model是一一对应的
tokenizer = AutoTokenizer.from_pretrained(checkpoint)# 用分词器进行分词
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")# 加载模型
model = AutoModel.from_pretrained(checkpoint)
## 调用模型
outputs = model(**inputs)print(outputs.last_hidden_state.shape)# post-processing, 后置处理,将模型输出的信息转成我们可以看懂的数据
predictions = torch.nn.functional.softmax(outputs[0], dim=-1)
print(predictions)
相关文章:

Huggingface使用
文章目录 前置安装Huggingface介绍NLP模块分类transformer流程模块使用详细讲解tokennizermodeldatasetsTrainer Huggingface使用网页直接体验API调用本地调用(pipline)本地调用(非pipline) 前置安装 anaconda安装 使用conda创建一个新环境并安装pytorc…...
Android 刷新与显示
目录 屏幕显示原理: 显示刷新的过程 VSYNC机制具体实现 小结: 屏幕显示原理: 过程描述: 应用向系统服务申请buffer 系统服务返回一个buffer给应用 应用开始绘制,绘制完成就提交buffer,系统服务把buffer数据…...

三行命令在CentOS 8上安装FFmpeg
添加RPMfusion仓库 yum install https://download1.rpmfusion.org/free/el/rpmfusion-free-release-8.noarch.rpm 安装SDL yum install http://rpmfind.net/linux/epel/7/x86_64/Packages/s/SDL2-2.0.14-2.el7.x86_64.rpm 安装FFmpeg yum install ffmpeg 执行命令测试 [rootVM…...

【前端】html
HTML标签(上) 目标: -能够说出标签的书写注意规范 -能够写出HTML骨架标签 -能够写出超链接标签 -能够写出图片标签并说出alt和title的区别 -能够说出相对路径的三种形式 目录: HTML语法规范HTML基本结构标签开发工具HTML常用标…...

【RealTek sdk-3.4.14b】Realtek WiFi开发调试指令总结
格式说明 RTL8192cd 驱动程序提供 MIB 接口,可通过“iwpriv”命令获取/设置参数。 set_mib iwpriv set_mib namevalue1[,value2,value3…]” Iface: “wlan0” value: 1.值可以是单个字段,也可以是用“,”分隔的多个字段,字…...

基于Vue 的文本类弹框代码Demo
<template><div class"text-popup" v-if"showPopup"><h2>{{ title }}</h2><p>{{ content }}</p><button click"closePopup">关闭</button></div><div class"main-content"&…...

2023.08.01 驱动开发day8
驱动层 #include <linux/init.h> #include <linux/module.h> #include <linux/of.h> #include <linux/of_irq.h> #include <linux/interrupt.h> #include <linux/fs.h> #include <linux/gpio.h> #include <linux/of_gpio.h>#…...

计算机视觉--距离变换算法的实战应用
前言: Hello大家好,我是Dream。 计算机视觉CV是人工智能一个非常重要的领域。 在本次的距离变换任务中,我们将使用D4距离度量方法来对图像进行处理。通过这次实验,我们可以更好地理解距离度量在计算机视觉中的应用。希望大家对计算…...
MIT 6.824 -- MapReduce -- 01
MIT 6.824 -- MapReduce -- 01 引言抽象和实现可扩展性可用性(容错性)一致性MapReduceMap函数和Reduce函数疑问 课程b站视频地址: MIT 6.824 Distributed Systems Spring 2020 分布式系统 推荐伴读读物: 极客时间 – 大数据经典论文解读DDIA – 数据密集型应用大数据相关论文…...
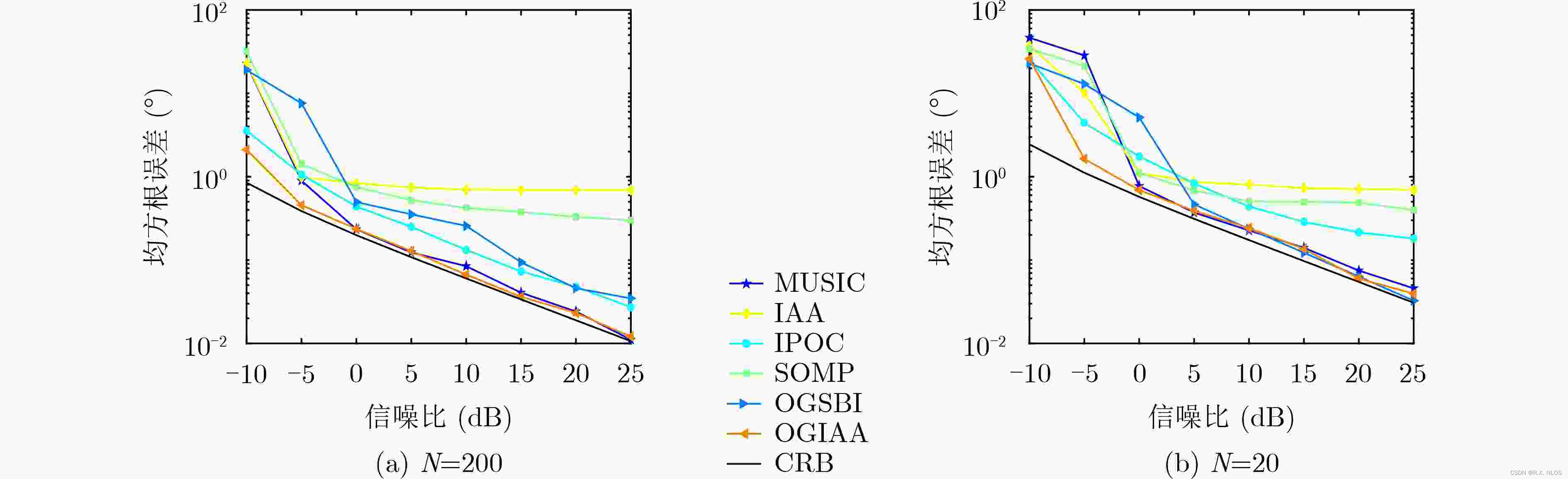
概念解析 | 利用IAA迭代自适应方法实现高精度角度估计
利用IAA迭代自适应方法实现高精度角度估计 注1:本文系“概念辨析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:IAA迭代自适应方法在雷达角度估计中的应用。 背景介绍 在雷达目标检测与定位中,准确估计目标角度是实现高精度定位的关键。传统的基于…...

正则表达式必知必会
文章目录 前言匹配单个字符匹配任意字符匹配一组字符取非匹配元字符匹配数字匹配所有字母和数字匹配空白字符重复匹配避免过度匹配边界匹配字符串边界子表达式回溯引用回溯引用中的替换操作向前查找向后查找 前言 在工作中使用正则表达式可以提高我们的效率,这篇博…...

[SQL系列] 从头开始学PostgreSQL 分库分表
什么是分库分表 分库分表是一种数据库架构设计的方法,用于应对大规模数据的存储和查询。当单个数据库的存储容量或查询性能无法满足需求时,可以通过将数据分散存储在多个数据库服务器上,以提高系统的可扩展性和性能。 分库分表通常包…...

【VScode】Remote-SSH XHR failed无法访问远程服务器
问题概述 当使用VScode连接远程服务器时,往往需要使用Remote-SSH这个插件。而该插件有一个小bug,当远程服务器网络不佳时容易出现。 在控制台会出现下述语句: Resolver error: Error: XHR failed at y.onerror (vscode-file://vscode-app/…...
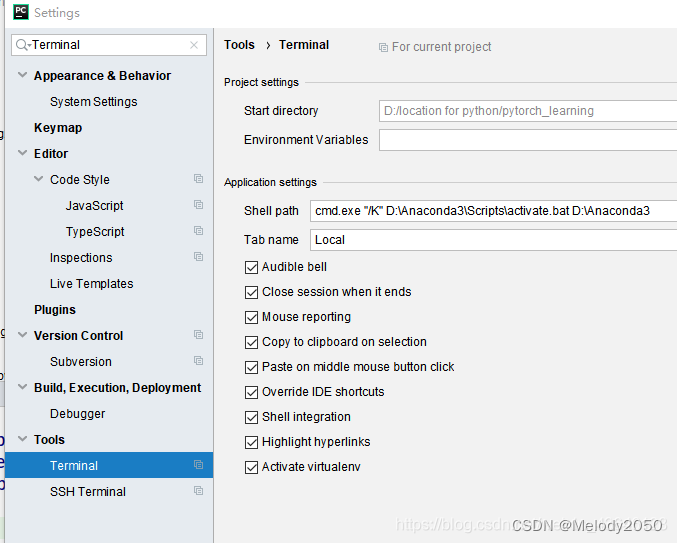
pycharm打开terminal报错
Pycharm打开终端报错如何解决?估计是终端启动conda不顺利,需要重新设置路径。参考以下文章的做法即可。 Windows下Pycharm中Terminal无法进入conda环境和Python Console 不能使用 给pycharm中Terminal 添加新的shell,才可以使用conda环境 W…...
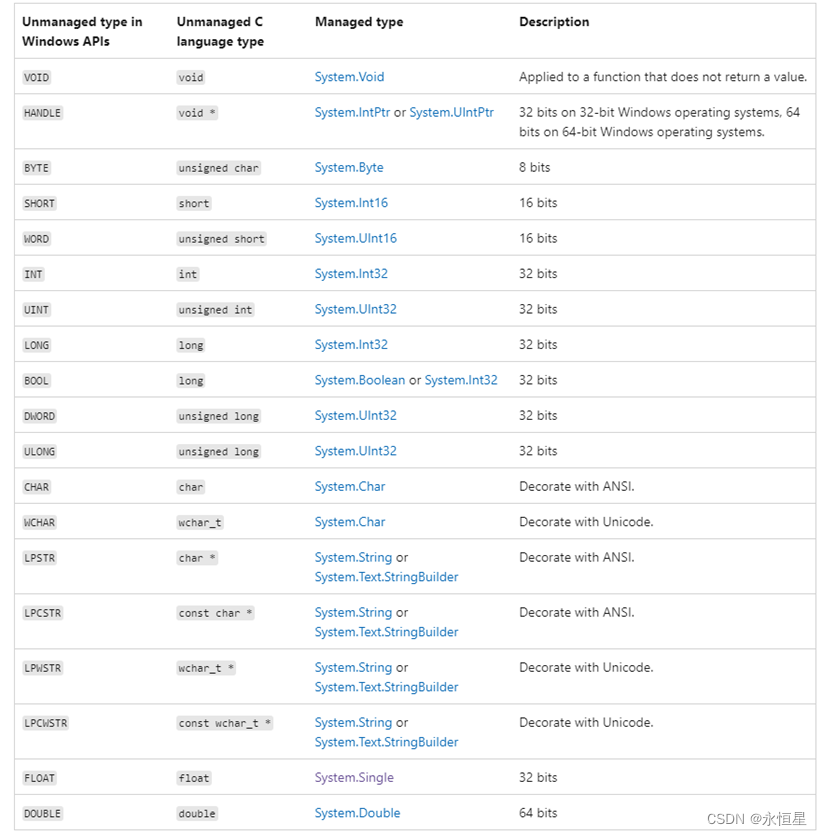
C#与C/C++交互(1)——需要了解的基础知识
【前言】 C#中用于实现调用C/C的方案是P/Invoke(Platform Invoke),让托管代码可以调用库中的函数。类似的功能,JAVA中叫JNI,Python中叫Ctypes。 常见的代码用法如下: [DllImport("Test.dll", E…...

LeetCode笔记:Weekly Contest 356
LeetCode笔记:Weekly Contest 356 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/weekly-contest-356/ 1. 题目一…...

2 Python的基础语法
概述 在上一节的内容中,我们介绍了Python的诞生、发展历程、特色、缺点和应用领域。从本节开始,我们将正式学习Python。Python是一门简洁和优雅的语言,有自己特殊的一些语法规则。因此,在介绍Python编程的有关知识之前,…...
抖音seo矩阵系统源代码开发搭建技术分享
抖音SEO矩阵系统是一个较为复杂的系统,其开发和搭建需要掌握一定的技术。以下是一些技术分享: 技术分享 抖音SEO矩阵系统的源代码可以使用JAVA、Python、PHP等多种语言进行开发。其中,JAVA语言的应用较为广泛,因为JAVA语言有良好…...

python#django数据库一对一/一对多/多对多
一对一OneToOneField 用户和用户信息 搭建 # 一对一 class TestUser(models.Model): usernamemodels.CharField(max_length32) password models.CharField(max_length32) class TestInfo(models.Model): mick_namemodels.CharField(max_length32) usermode…...

记RT-Thread rt_timer_start函数的问题
我使用的RT-Thread版本为4.0.3。 我看了5.0.1的代码,此问已经被修复。 在4.0.3版本中的rt_timer_start函数源码如下: rt_err_t rt_timer_start(rt_timer_t timer) {unsigned int row_lvl;rt_list_t *timer_list;register rt_base_t level;rt_list_t *r…...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

Kubernetes原生自动化部署工具Keel:实现容器镜像自动更新的最后一公里
1. 项目概述:什么是Keel,以及它解决了什么问题如果你和我一样,在团队里负责过一段时间的应用部署和更新,那你一定对“发布日”的紧张感深有体会。开发那边代码一提交,这边就得开始手动拉取镜像、更新Kubernetes的Deplo…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...

基于GitHub Actions的自动化代码质量守护:CodeBuddy实战指南
1. 项目概述与核心价值最近在和一些团队做代码评审和协作时,我经常遇到一个痛点:大家写的代码风格各异,注释要么缺失要么过时,一些潜在的安全漏洞和性能问题在提交前很难被系统性地发现。虽然市面上有各种静态分析工具,…...

Python Reddit数据采集与分析实战:从API调用到舆情监控
1. 项目概述与核心价值最近在开源社区里,一个名为openshrug/reddit-intel的项目引起了我的注意。乍一看,这像是一个针对 Reddit 平台的数据抓取或分析工具,但深入探究后,我发现它的定位远不止于此。它更像是一个为开发者、数据分析…...

面向开发者的轻量级计划管理工具:配置驱动与命令行优先
1. 项目概述:一个为开发者而生的计划管理工具在软件开发的世界里,我们每天都在与各种“计划”打交道:版本迭代计划、个人学习计划、项目里程碑、甚至是每日的待办清单。然而,一个尴尬的现实是,市面上大多数项目管理工具…...