【秋招】算法岗的八股文之机器学习
目录
- 机器学习
- 特征工程
- 常见的计算模型
- 总览
- 线性回归模型与逻辑回归模型
- 线性回归模型
- 逻辑回归模型
- 区别
- 朴素贝叶斯分类器模型 (Naive Bayes)
- 决策树模型
- 随机森林模型
- 支持向量机模型 (Support Vector Machine)
- K近邻模型
- 神经网络模型
- 卷积神经网络(CNN)
- 循环神经网络(RNN)
- 模型评估
推荐链接:
阿秀的学习笔记
JavaGuide中常见面试题总结
机器学习面试笔试求职必备八股文
朴素贝叶斯模型(naive bayes)
随机森林 – Random Forest | RF
机器学习
特征工程
-
特征归一化的意义:特征归一化是数据预处理中重要技术。因为特征间的单位(尺度)可能不同,为了便于后续的下游任务中特征距离计算,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。【把绝对值转为相对值,这样就能体现出哪一维特征的重要性】
-
特征 / 向量之间的距离计算方法
-
欧氏距离:衡量空间点的直线距离。n维向量之间的距离计算公式如下:
∑ i = 1 n ( x i − y i ) 2 \sqrt{\sum_{i=1}^{n}(x_i-y_i)^2 } i=1∑n(xi−yi)2 -
曼哈顿距离:两个点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)、 ( x 2 , y 2 ) (x_2,y_2) (x2,y2)之间的距离计算公式如下:
∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ \left | x_1-x_2 \right | + \left | y_1-y_2 \right | ∣x1−x2∣+∣y1−y2∣ -
切比雪夫距离:两个点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)、 ( x 2 , y 2 ) (x_2,y_2) (x2,y2)之间的距离定义为其各座标数值差绝对值的最大值。
m a x ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ ) max(\left | x_1-x_2 \right | ,\left | y_1-y_2 \right | ) max(∣x1−x2∣,∣y1−y2∣) -
余弦相似度:计算两个向量之间夹角的余弦值,余弦值接近1说明夹角趋近0,表示两个向量相似。余弦值越大表示向量越相似,取值区间[-1, 1]。多维向量之间的余弦值计算如下
c o s Θ = ∑ i = 1 n ( x i × y i ) ∑ i = 1 n x i 2 + ∑ i = 1 n y i 2 cos\Theta=\frac{\sum_{i=1}^{n}(x_i\times y_i) }{\sqrt{\sum_{i=1}^{n} x_i^2} +\sqrt{\sum_{i=1}^{n} y_i^2}} cosΘ=∑i=1nxi2+∑i=1nyi2∑i=1n(xi×yi)
以两个点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)、 ( x 2 , y 2 ) (x_2,y_2) (x2,y2)为例
c o s Θ ( ( x 1 , y 1 ) , ( x 2 , y 2 ) ) = x 1 x 2 + y 1 y 2 x 1 2 + y 1 2 × x 2 2 + y 2 2 cos\Theta((x_1,y_1), (x_2,y_2))=\frac{x_1x_2+y_1y_2}{\sqrt{x_1^2+y_1^2}\times\sqrt{x_2^2+y_2^2} } cosΘ((x1,y1),(x2,y2))=x12+y12×x22+y22x1x2+y1y2 -
余弦距离=1 - 余弦相似度
-
-
One-Hot编码的作用
之所以使用One-Hot编码,是因为在很多机器学习任务中,特征并不总是连续值,也有可能是离散值(如上表中的数据)。将这些数据用数字来表示,执行的效率会高很多。
常见的计算模型
总览
在机器学习中,常见的模型包括:
- 线性回归模型 (Linear Regression)与逻辑回归模型 (Logistic Regression):主要用于预测问题,例如对数值型数据进行预测。其主要目的是根据输入数据的特征,预测出一个数值型的输出结果。
- 决策树模型 (Decision Tree):一种监督学习算法,用于分类和回归分析。在分类问题中,决策树将根据数据的特征将数据分为不同的类别;在回归分析中,决策树用于预测连续值。
- 随机森林模型 (Random Forest):经典的Bagging方法,是一种基于决策树集成的机器学习算法,通常用于分类和回归问题。它通过在数据集中随机选择子集和特征,构建多个决策树,然后将它们合并来提高预测准确性,降低过拟合的风险。它的优点包括易于实现和解释、对缺失数据和异常值具有鲁棒性、准确率高等。
- 支持向量机模型 (Support Vector Machine):是一种监督学习算法,主要用于分类问题。它的目标是找到一个最优的超平面(可以是线性或非线性的),能够最大化不同类别之间的距离,从而对数据进行分类。
- 贝叶斯分类器模型 (Naive Bayes):利用因素之间的依赖关系来进行预测类别,其分类器模型不需要大量的数据和计算资源,能够高效地处理大量高维数据集。此外,贝叶斯分类器模型基于概率模型,因此它很容易被理解和解释,利于对模型进行优化和调整。同时,贝叶斯分类器还可以处理缺失数据,具有较强的鲁棒性和可靠性。
- K近邻模型 (K-Nearest Neighbor):是一种分类算法,通过找到与待分类样本特征最接近的K个训练样本,根据这K个样本所属类别的多数决定待分类样本的类别。KNN算法的主要优点是简单易懂,易于实现,但在处理大规模数据集时比较耗时。
- 神经网络模型 (Neural Network):基于神经元的计算模型,通过引入sigmoid激活函数使其拥有非线性的表达能力,解决许多复杂的机器学习问题如图像和语音识别。其中包括:卷积神经网络模型 (Convolutional Neural Network)、循环神经网络模型 (Recurrent Neural Network)、生成式对抗网络(Generative Adversarial Network,GAN)等等。不同类型的神经网络模型有各自的应用场景和侧重点,选择合适的模型可以在特定问题上获得更好的效果。
线性回归模型与逻辑回归模型
线性回归模型
- 模型假设:线性模型假设因变量和自变量之间存在线性关系。
- 模型定义:线性回归能将输入数据通过对各个维度的特征分配不同的权重来进行表征,使得所有特征协同作出最后的决策。注意,这种表征方式是拟合模型的输出结果,适用于其预测值为连续变量,其预测值在整个实数域中的情况,而不可以直接用于分类。
- 一般表达式:
h θ ( x ) = θ T X = θ 0 + θ 1 x 1 + ⋯ + θ n x n h_\theta (x)=\theta ^TX=\theta _0+\theta _1x_1+\cdots +\theta _nx_n hθ(x)=θTX=θ0+θ1x1+⋯+θnxn
其中,求解参数 θ \theta θ的代价函数是均方误差(Mean Square Error, MSE) - 代价函数:
J θ = 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 J_\theta =\frac{1}{2m}\sum_{i=1}^{m}(h_\theta (x^i)-y^i)^2 Jθ=2m1i=1∑m(hθ(xi)−yi)2 - 特点:由于MSE对特征值的范围比较敏感,导致线性回归模型对离群点非常敏感。一般情况下对会采用特征工程对特征进行归一化处理。在实际参数求解时,涉及到误差估计,所以求解时用的最小二乘法。
逻辑回归模型
-
模型假设:自变量的变化对因变量的影响是通过一个逻辑函数(sigmoid函数)体现的。
-
定义:逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数(又称对数几率函数(Logistic Function))引入了非线性因素,因此在线性回归基础上,主要解决分类问题。
-
一般表达式:
h θ ( x ) = g ( θ T x ) , g ( z ) = 1 1 + e − z h_\theta (x)=g(\theta ^Tx),g(z)=\frac{1}{1+e^{-z}} hθ(x)=g(θTx),g(z)=1+e−z1
其中, g ( z ) g(z) g(z)表示激活函数,【激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。】这里求解参数 θ \theta θ的代价函数是交叉熵函数。
交叉熵函数的定义:
J θ = 1 m ∑ i = 1 m ( − y i l o g ( h θ ( x i ) ) − ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ) J_\theta =\frac{1}{m}\sum_{i=1}^{m}(-y^ilog(h_\theta (x^i))-(1-y^i)log(1-h_\theta (x^i))) Jθ=m1i=1∑m(−yilog(hθ(xi))−(1−yi)log(1−hθ(xi)))
用**极大似然估计(Maximum Likelihood Estimation,MLE)**求解的最优参数:
KaTeX parse error: Undefined control sequence: \sideset at position 10: \hat{w}=\̲s̲i̲d̲e̲s̲e̲t̲{}{}{argmax}_w\…
观察上面两式可知, M L E ( m a x ) MLE(max) MLE(max)等价于 J θ ( m i n ) J_\theta(min) Jθ(min) -
特点:逻辑回归模型可以视为加了Sigmoid的线性模型。至于为什么要使用Sigmoid函数中的对数几率函数,这涉及到伯努利分布的指数族形式,最大熵理论等。这里的参数估计是通过最优化方法来确定最佳拟合数据的模型参数。在二分类问题中,负对数似然函数正是我们所说的交叉熵损失函数。然而,交叉熵损失函数的构建并非只能通过似然函数。
区别
- 线性回归和逻辑回归都是广义线性回归模型的特例。他们俩是兄弟关系,都是广义线性回归的亲儿子
- 线性回归只能用于回归问题,逻辑回归用于分类问题(二分类、多分类)
- 线性回归无联系函数或不起作用,逻辑回归的联系函数是对数几率函数,属于Sigmoid函数。
- 线性回归使用最小二乘法作为参数估计方法,逻辑回归使用极大似然法作为参数估计方法
朴素贝叶斯分类器模型 (Naive Bayes)
- 模型假设:假设特征之间是条件独立的,即给定目标值时,一个特征的存在不会影响其他特征的存在。
- 模型定义:是基于贝叶斯定理和特定假设(特征之间相互独立)的一种分类方法。
- 一般表达式:
P ( y ∣ x ) = p ( x ∣ y ) ⋅ p ( y ) p ( x ) P(y|x)=\frac{p(x|y)\cdot p(y)}{p(x)} P(y∣x)=p(x)p(x∣y)⋅p(y)
其中, P ( y ) P(y) P(y)是先验概率【是指在没有考虑任何特征的情况下,类别出现的概率。】, P ( x ∣ y ) P(x|y) P(x∣y)是样本 x x x相对于类别 y y y的条件概率【也成为似然(likelihood),这里样本通常有很多 x = x 1 + ⋯ + x n x=x_1+\cdots+x_n x=x1+⋯+xn表示多个特征】, p ( x ) p(x) p(x)是与 y y y无关的归一化因子。 - 由于求解以上公式复杂度高,因此朴素贝叶斯给出了一个神假设:假设特征之间是独立的。所谓 “朴素” 二字就体现在这个地方,但是根据我们的常识也知道,样本的特征之间几乎不太可能是相互独立的,因此朴素贝叶斯效果肯定不好,但结果却恰恰相反,无数的实验证明朴素贝叶斯对于文本分类任务效果都很好。
- 特点:
- 朴素贝叶斯是一种典型的生成式模型,生成式模型实际上是建立一个多模型(有多少类就建多少个模型),然后算出新样本在每个类别的后验概率,然后看哪个最大,就把新样本分到哪个类中。而判别式模型只有一个模型,由数据直接学习 P ( y ∣ x ) P( y ∣ x ) P(y∣x) 来预测 y y y。
- 朴素贝叶斯模型不需要训练,而是直接用新样本去数据集(训练集)去算后验概率,然后分类。
- 在朴素贝叶斯中,对于连续值,假设其符合高斯分布。
- 举例计算步骤(转自朴素贝叶斯模型(naive bayes))

决策树模型
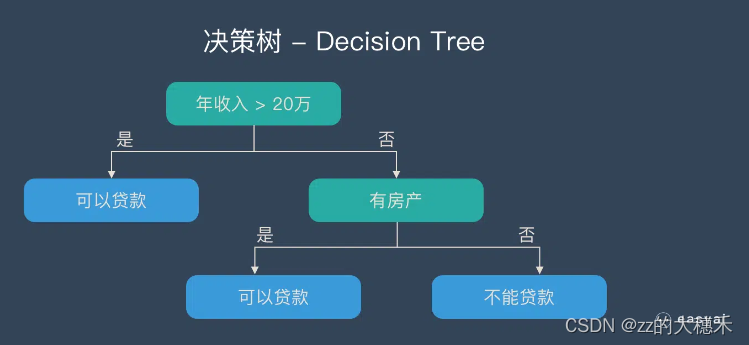
- 模型假设:每个决策节点只考虑一个特征,并基于特征对样本进行划分。
- 模型定义:决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。决策树通过树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。
- 模型建立:最新的CART算法既可以生成回归树解决连续变量的预测,又可以生成分类树解决离散变量的分类。【回归树生成的核心思想】预测误差最小化,所以我们的目的就是找到一个分界点,以这个点作为分界线将训练集D分成两部分D1和D2,并且使数据集D1和D2中各自的平方差最小。【分类树生成的核心思想】通过计算信息增益/Gini系数来生成特征的重要等级,核心思想是选取重要的能提供更多信息(信息增益大)、数据一致性强(不纯度低)的特征来建树。
- 特点:
- 【优点】简单的理解和解释,树木可以可视化;需要很少的数据准备,其他技术通常需要归一化。
- 【缺点】决策树学习者可以创建不能很好的推广数据的过于复杂的数,因为会产生过拟合。而随机森林在此基础上克服了这个缺点。
随机森林模型
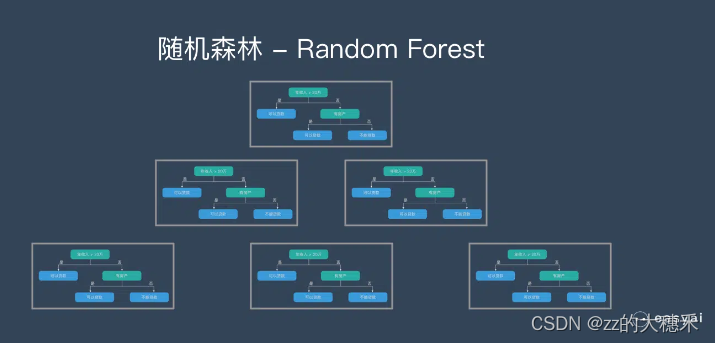
- 模型假设:【其模型假设与决策树相似,但存在一些不同之处。】随机森林模型假设在样本和特征上存在一定的随机性,即每个决策树只用部分样本和部分特征进行训练,以减少过拟合的风险。需要注意的是,随机森林的模型假设相较于单一决策树更为健壮,不需要对样本的特征之间是否相互独立做出假设。因此,随机森林模型可以处理变量间存在一定相关性的情形。
- 模型定义:随机森林是由很多决策树构成的,不同决策树之间没有关联。既可以用于分类问题,也可用于回归问题。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
- 模型建立:
- 一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
- 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
- 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
- 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
- 特点:
- 【优点】它可以处理很高维度(特征很多)的数据,并且不用降维,无需做特征选择;它可以判断特征的重要程度;可以判断出不同特征之间的相互影响;不容易过拟合;训练速度比较快,容易做成并行方法;实现起来比较简单;对于不平衡的数据集来说,它可以平衡误差。;如果有很大一部分的特征遗失,仍可以维持准确度。
- 【缺点】随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合;对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
支持向量机模型 (Support Vector Machine)
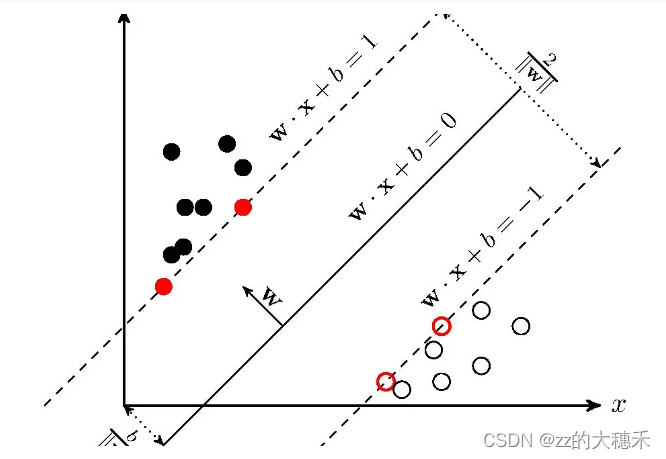
- 模型假设:
- 假设所有的样本都在高维空间中,并且样本能够被一个超平面正确地分开。
- 假设最优的超平面是距离两侧最近的样本点最大化的线性分类器。
- 假设线性不可分的样本可以通过在高维空间中进行映射,使它们在高维空间中线性可分。
- 模型定义:是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机(感知机找到任意一个使数据点可以线性可分的平面)。支持向量算法的目的是找到距离超平面间隔最大的点(这些点被称为支持向量)。SVM还包括核技巧,把当前样本点通过特征映射(如高斯核)将特征映射到高维空间进行计算,这使它成为实质上的非线性分类器。
- 线性支持向量机学习算法与 非线性SVM算法(详细推导过程见https://www.zhihu.com/tardis/zm/art/31886934?source_id=1005)。
- 特点
- 【优点】可以解决高维问题,即大型特征空间;解决小样本下机器学习问题;能够处理非线性特征的相互作用;无局部极小值问题(相对于神经网络等算法);无需依赖整个数据(找到支持向量是关键);泛化能力比较强;
- 【缺点】当观测样本很多时,效率并不是很高;对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;对于核函数的高维映射解释力不强,尤其是径向基函数;常规SVM只支持二分类;
对缺失数据敏感;
K近邻模型
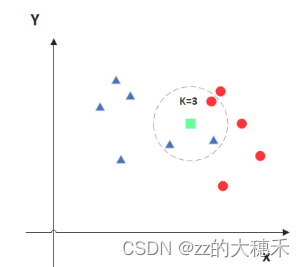
- 模型假设:样本之间的距离度量是可用的,通常使用欧氏距离、曼哈顿距离等方法来度量。
- 模型定义:是一种基于实例的学习方法,在提前定义好距离与K值的前提下,对于任意一个新的样本,将其分类为与该样本距离最近的K个样本中类别最多的那个类别。当k=1时表示最近邻算法。
- k近邻法 三个基本要素:k 值的选择、距离度量及分类决策规则。
- **K值选择:**通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的 K 值开始,不断增加 K 的值,然后计算验证集合的方差,最终找到一个比较合适的 K 值。
- 算法步骤:
- 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
- 对上面所有的距离值进行排序;
- 选前k个最小距离的样本;
- 根据这k个样本的标签进行投票,得到最后的分类类别;
- 特点:
- 【优点】不需要训练;简单易用。相比其他算法,KNN 算是比较简洁明了的算法,即使没有很高的数学基础也能搞清楚它的原理。;对异常值不敏感。
- 【缺点】没有明显的训练过程,它是 "懒惰学习"的典型代表,它在训练阶段所做的仅仅是将样本保存起来,如果训练集很大,必须使用大量的存储空间,训练时间开销为零;KNN必须对每一个测试点来计算到每一个训练数据点的距离, 并且这些距离点涉及到所有的特征,当数据的维度很大,数据量也很大的时候,KNN的计算会成为诅咒
神经网络模型
这个模型中包含了许多不同的网络模型,以下将根据他们之间的应用侧重来浅显的解析概念。
卷积神经网络(CNN)
- 适用场景:基于图像的任务。目标事物的特征主要体现在像素与像素之间的关系。而视频是图像的叠加,所以同样擅长处理视频内容。例如目标检测、目标分割等等
- 特点:
- 得益于卷积核的加权+池化,能够有效的将大数据量的图片姜维成小数据量。
- 卷积的特点:局部感知、参数共享、多核
- 卷积神经网络的平移不变性。简单地说,卷积+最大池化约等于局部平移不变性。用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
- 基本原理:典型的 CNN 由3个部分构成:
- 卷积层:负责提取图像中的局部特征;
- 池化层:又称下采样,可以大幅降低参数量级(降维),防止过拟合。之所以这么做的原因,是因为即使做完了卷积,图像仍然很大(因为卷积核比较小),所以为了降低数据维度,就进行下采样。池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
- 全连接层:类似传统神经网络的部分,用来输出想要的结果。经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
- 存在的问题:
- 反向传播算法并不是一个深度学习中的高效算法,因为它对数据量的需求很大。
- 如果是检测目标从图片左上角到右下角之后,且相对位置发生变化时,池化后的特征变化剧烈,以至于影响神经元权重导致不正确的识别。
- 需要将数据集归一化。不同的尺寸混合在一起难以训练。
- 池化层的存在会导致许多非常有价值的信息的丢失,同时也会忽略掉整体与部分之间的关联。
- 没有记忆功能,对于视频的检测是基于靠单帧的图片检测完成的。
- 改进:在CNN中增加模型对图像中的像素位置感知。例如CoordConv、Transformer。
循环神经网络(RNN)
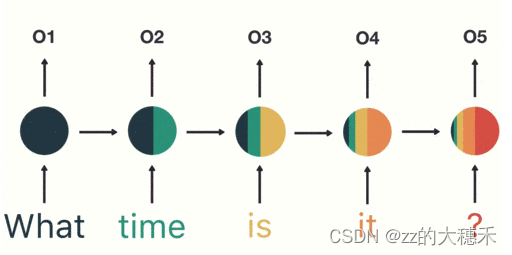
- 适用场景:需要处理「序列数据 – 一串相互依赖的数据流」,如文字、音频等序列数据。
- 特点:如上图可知,“?”所生成的特征包含了以往词的特征,表示前面的所有输入都会对未来的输出产生影响。并且随着序列的推进,越以前的数据对当前的影响越小。
- 存在的问题:
- 短期的记忆影响较大(如橙色区域),但是长期的记忆影响就很小(如黑色和绿色区域),这就是 RNN 存在的短期记忆问题:RNN 有短期记忆问题,无法处理很长的输入序列;
- 训练 RNN 需要投入极大的成本
- 改进:LSTM(Long Short Term Memory (长短期记忆) )适合处理和预测时间序列中间隔和延迟长的重要事件。
模型评估
- 过拟合和欠拟合
- 概念解析
- 过拟合: 模型在训练集上表现很好,测试集上表现很差。导致模型泛化性能下降。
- 欠拟合:模型对训练样本的一般性质尚未学好。在训练集及测试集上的表现都不好。
- 原因和解决方法:
- 过拟合:从数据的角度上看,原来的训练数据本身就缺乏多样性,所以可以增加数据量,使用多种数据增强方法;从模型特征上看,因为特征对数据中各种细节都拟合了,所以可以减少模型特征来缓解;引入正则化,避免当特征很多的时候,某些特征占主导。
- 欠拟合:从模型特征上看,特征对数据中的特点没学到,所以通过特征组合等增加特征维度;使用Boosting方法把当前弱模型进行组合成一个强模型。
- 概念解析
- 正则化:L1正则化和L2正则化
∥ x ∥ p = ( ∑ i = 1 n ∣ x i ∣ p ) 1 p \left \| x \right \| _p=(\sum_{i=1}^{n}\left | x_i \right |^p )^\frac{1}{p} ∥x∥p=(i=1∑n∣xi∣p)p1- L1正则化服从拉普拉斯分布, 当 p = 1 p=1 p=1,该公式表示L1范数,表示向量中所有元素的绝对值之和。
- 作用:L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以保证模型的稀疏性,也就是某些参数等于0,可以用于特征选择;
- 实际应用:线形回归的L1正则化通常称为Lasso回归,它和一般线形回归的区别是在损失函数上增加了一个L1正则化的项,L1正则化的项有一个常数系数alpha来调节损失函数的均方差项和正则化项的权重。Lasso回归可以使一些特征的系数变小,甚至还是一些绝对值较小的系数直接变为0,增强模型的泛化能力。
- L2正则化服从高斯分布,可以保证模型的稳定性,也就是参数的值不会太大或太小。。
- 实际应用:线形回归的L2正则化通常称为Ridge回归,它和一般线形回归的区别是在损失函数上增加了一个L2正则化的项。Ridge回归(岭回归)在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但和Lasso回归相比,这会使得模型的特征留的特别多,模型解释性差。
- L1正则化服从拉普拉斯分布, 当 p = 1 p=1 p=1,该公式表示L1范数,表示向量中所有元素的绝对值之和。
相关文章:
【秋招】算法岗的八股文之机器学习
目录 机器学习特征工程常见的计算模型总览线性回归模型与逻辑回归模型线性回归模型逻辑回归模型区别 朴素贝叶斯分类器模型 (Naive Bayes)决策树模型随机森林模型支持向量机模型 (Support Vector Machine)K近邻模型神经网络模型卷积神经网络(CNN)循环神经…...
为什么list.sort()比Stream().sorted()更快?
真的更好吗? 先简单写个demo List<Integer> userList new ArrayList<>();Random rand new Random();for (int i 0; i < 10000 ; i) {userList.add(rand.nextInt(1000));}List<Integer> userList2 new ArrayList<>();userList2.add…...

SQL账户SA登录失败,提示错误:18456
错误代码 18456 表示 SQL Server 登录失败。这个错误通常表示提供的凭据(用户名和密码)无法成功验证或者没有权限访问所请求的数据库。以下是一些常见的可能原因和解决方法: 1.错误的凭据:请确认提供的SA账户的用户名和密码是否正…...
Linux 终端操作命令(1)
Linux 命令 终端命令格式 command [-options] [parameter] 说明: command:命令名,相应功能的英文单词或单词的缩写[-options]:选项,可用来对命令进行控制,也可以省略parameter:传给命令的参…...

java与javaw运行jar程序
运行jar程序 一、java.exe启动jar程序 (会显示console黑窗口) 1、一般用法: java -jar myJar.jar2、重命名进程名称启动: echo off copy "%JAVA_HOME%\bin\java.exe" "%JAVA_HOME%\bin\myProcess.exe" myProcess -jar myJar.jar e…...

安装和配置 Home Assistant 教程 HACS Homkit 米家等智能设备接入
安装和配置 Home Assistant 教程 简介 Home Assistant 是一款开源的智能家居自动化平台,可以帮助你集成和控制各种智能设备,从灯光到温度调节器,从摄像头到媒体播放器。本教程将引导你如何在 Docker 环境中安装和配置 Home Assistant&#…...

解决 Android Studio 的 Gradle 面板上只有关于测试的 task 的问题
文章目录 问题描述解决办法 笔者出问题时的运行环境: Android Studio Flamingo | 2022.2.1 Android SDK 33 Gradle 8.0.1 JDK 17 问题描述 笔者最近发现一个奇怪的事情。笔者的 Android Studio 的 Gradle 面板上居然除了用于测试的 task 之外,其它什…...
安全杂记 - 复现nodejs沙箱绕过
目录 一. 配置环境1.下载nodejs2.nodejs配置3.报错解决方法 二. nodej沙箱绕过1. vm模块2.使用this或引用类型来进行沙箱绕过 一. 配置环境 1.下载nodejs 官网:https://nodejs.org/en2.nodejs配置 安装nodejs的msi文件,默认配置一直下一步即可&#x…...

信息安全事件分类分级指南
范围 本指导性技术文件为信息安全事件的分类分级提供指导,用于信息安全事件的防范与处置,为事前准备、事中应对、事后处理 提供一个基础指南,可供信息系统和基础信息传输网络的运营和使用单位以及信息安全主管部门参考使用。 术语和定义 下…...

Vue系列第八篇:echarts绘制柱状图和折线图
本篇将使用echarts框架进行柱状图和折线图绘制。 目录 1.绘制效果 2.安装echarts 3.前端代码 4.后端代码 1.绘制效果 2.安装echarts // 安装echarts版本4 npm i -D echarts4 3.前端代码 src/api/api.js //业务服务调用接口封装import service from ../service.js //npm …...
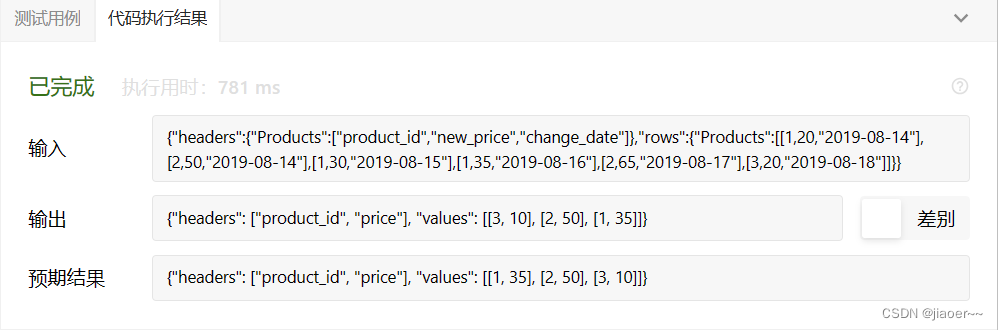
SQL-每日一题【1164. 指定日期的产品价格】
题目 产品数据表: Products 写一段 SQL来查找在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10 。 以 任意顺序 返回结果表。 查询结果格式如下例所示。 示例 1: 解题思路 1.题目要求我们查找在 2019-08-16 时全部产品的价格,假设所…...

memcpy、memmove、memcmp、memset函数的作用与区别
一、memcpy与memmove 1、memcpy 作用:从source的位置开始向后复制num个字节的数据到destination的内存位置。 注意: memcpy() 函数在遇到 ’\0’ 的时候不会停下来(strcpy字符串拷贝函数在遇到’\0’的时候会停下来);destination和source…...

socket 到底是个啥
我相信大家在面试过程中或多或少都会被问到这样一个问题:你能解释一下什么是 socket 吗 我记得我当初的回答很是浅显:socket 也叫套接字,用来负责不同主机程序之间的网络通信连接,socket 的表现方式由四元组(ip地址&am…...

奥威BI—数字化转型首选,以数据驱动企业发展
奥威BI系统BI方案可以迅速构建企业级大数据分析平台,可以将大量数据转化为直观、易于理解的图表和图形,推动和促进数字化转型的进程,帮助企业更好地了解自身的运营状况,及时发现问题并采取相应的措施,提高运营效率和质…...

vue中swiper使用
1.引包 说明:导入相应js引css import "Swiper" from "swiper" import "swiper/css/swiper.css"; import "swiper/js/swiper"; 2.结构 说明:必要的结构使用;直接封装成一个组件 <template>…...

webpack与vite区别
webpack和Vite作为两种常用的前端构建工具,主要有以下几点区别: 构建速度 webpack采用“打包”的方式构建,需要将所有模块打包成几个大的bundle文件,构建速度较慢。 Vite采用了“按需编译”的方式,只在浏览器请求时才编译对应模块,启动速度更快。 dev server webpack dev s…...
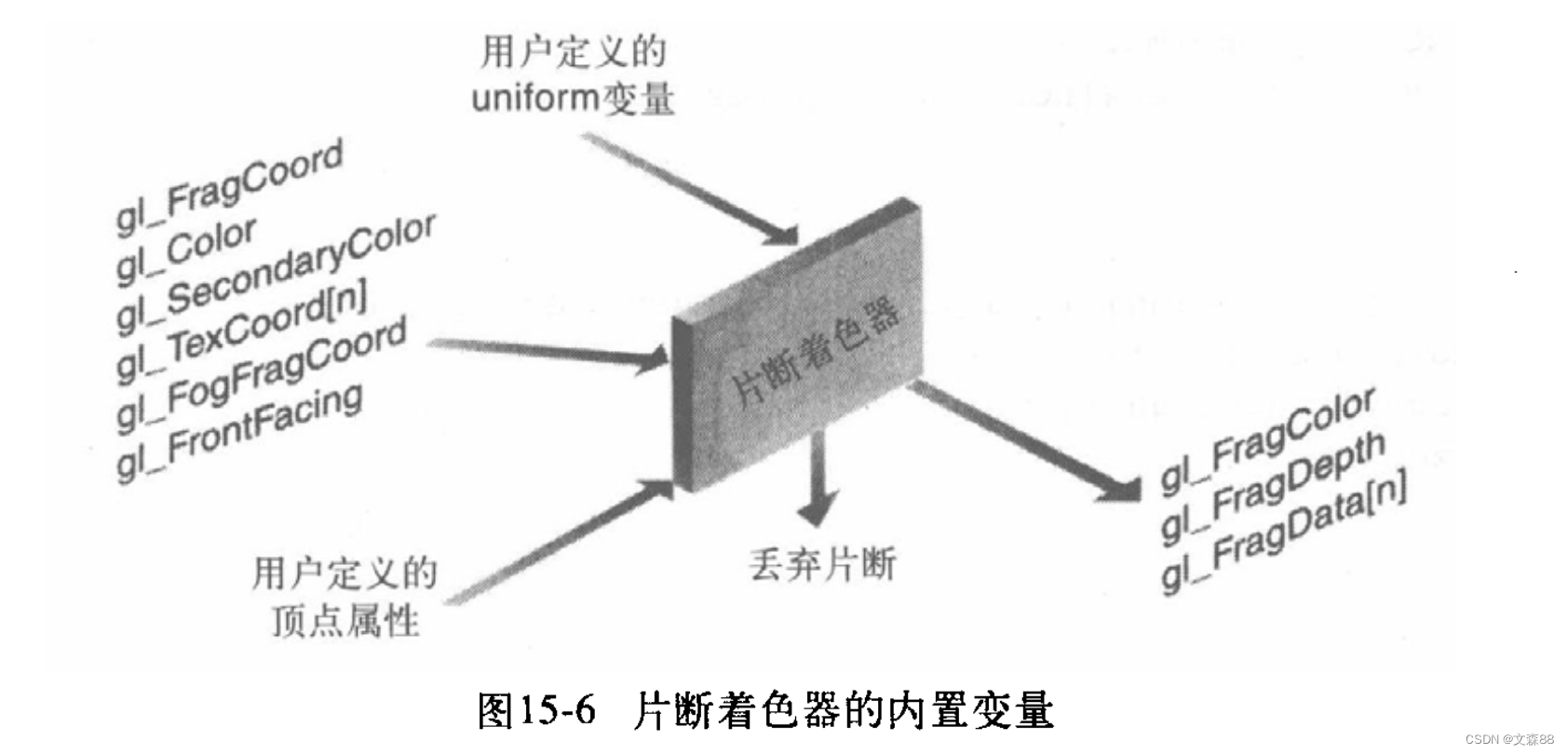
GLSL用于图像处理
Pipeline 硬件处理顶点和片段的Pipeline 软件的输入 顶点着色器 顶点的glsl 输入–特殊全局变量 变量 类型 指定函数 描述 gl_ Vertex vec4 glVertex 顶点的全局空间坐标 gl_Color vec4 glColor 主颜色值 gl_SecondaryColor vec4 glSecondaryColor 辅助颜色值 gl_Normal …...

即将发布的 Kibana 版本可运行 Node.js 18
作者:Thomas Watson Kibana 构建在 Node.js 框架之上。 为了确保每个 Kibana 版本的稳定性和使用寿命,我们始终将捆绑的 Node.js 二进制文件保持为最新的最新长期支持 (LTS) 版本。 当 Node.js 版本 18 升级到 LTS 时,我们开始将 Kibana 升级…...

基于遗传算法改进的支持向量机多分类仿真,基于GA-SVM的多分类预测,支持相机的详细原理
目录 背影 支持向量机SVM的详细原理 SVM的定义 SVM理论 遗传算法的原理及步骤 SVM应用实例,基于遗传算法优化SVM的多分类预测 完整代码包括SVM工具箱:https://download.csdn.net/download/abc991835105/88175549 代码 结果分析 展望 背影 多分类预测对现代智能化社会拥有重…...
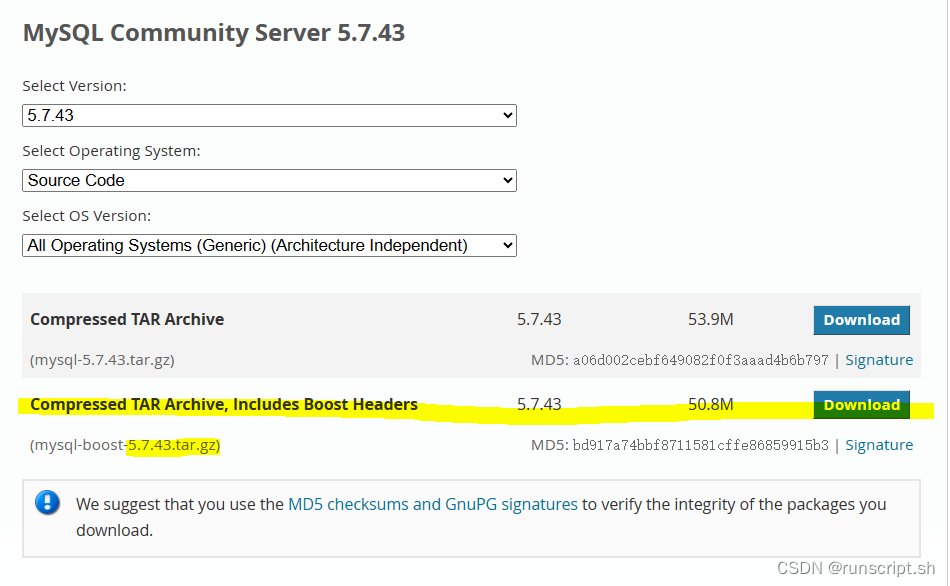
MySQL5.7源码编译Debug版本
编译环境Ubuntu22.04LTS 1 官方下载MySQL源码 https://dev.mysql.com/downloads/mysql/?spma2c6h.12873639.article-detail.4.68e61a14ghILh5 2 安装基础软件 cmakeclangpkg-configperl 参考:https://dev.mysql.com/doc/refman/5.7/en/source-installation-prere…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...

gwadd:轻量级Git仓库组管理工具,提升多项目开发效率
1. 项目概述:一个被低估的Git仓库管理利器如果你和我一样,日常工作中需要频繁地在多个Git仓库之间穿梭,处理各种依赖、子模块,或者仅仅是同步一堆相关的项目代码,那么你一定对那种重复、繁琐的切换和操作感到头疼。今天…...