深度学习:Pytorch常见损失函数Loss简介
深度学习:Pytorch常见损失函数Loss简介
- L1 Loss
- MSE Loss
- SmoothL1 Loss
- CrossEntropy Loss
- Focal Loss
此篇博客主要对深度学习中常用的损失函数进行介绍,并结合Pytorch的函数进行分析,讲解其用法。
L1 Loss
L1 Loss计算预测值和真值的平均绝对误差。
L o s s ( y , y ^ ) = ∣ y − y ^ ∣ Loss(y,\hat{y}) = |y-\hat{y}| Loss(y,y^)=∣y−y^∣
Pytorch函数:
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
参数:
- size_average (bool, optional) – 此参数已弃用;
- reduce (bool, optional) – 此参数已弃用;
- reduction (str, optional) – 由以下三个参数选其一:‘none’ | ‘mean’ | ‘sum’. ‘none’:不对各个元素的误差处理, ‘mean’:输出是各个元素误差的平均值,‘sum’:输出是将各个元素的误差求和。 默认:‘mean’。
MSE Loss
MSE Loss计算预测值和真值的均方误差。
L o s s ( y , y ^ ) = ( y − y ^ ) 2 Loss(y,\hat{y}) = (y-\hat{y})^2 Loss(y,y^)=(y−y^)2
Pytorch函数:
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
参数:
- size_average (bool, optional) – 此参数已弃用。
- reduce (bool, optional) – 此参数已弃用。
- reduction (str, optional) – 由以下三个参数选其一:‘none’ | ‘mean’ | ‘sum’. ‘none’:不对各个元素的误差处理, ‘mean’:输出是各个元素误差的平均值,‘sum’:输出是将各个元素的误差求和。 默认:‘mean’。
SmoothL1 Loss
在训练初期,当预测值和真值相差较大时,损失函数的值较大,容易导致训练不稳定,为了防止梯度爆炸(梯度值是指损失函数对输入的导数,梯度爆炸是指梯度值很大),同时当预测值和真值相差较小时,梯度值足够小,可以使用SmoothL1 Loss,它可以视作L1 Loss和L2 Loss(MSE Loss)的结合,计算公式如下:
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ Loss(y,\hat{y}…
Pytorch函数:
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
参数:
- size_average (bool, optional) – 此参数已弃用。
- reduce (bool, optional) – 此参数已弃用。
- reduction (str, optional) – 由以下三个参数选其一:‘none’ | ‘mean’ | ‘sum’. ‘none’:不对各个元素的误差处理, ‘mean’:输出是各个元素误差的平均值,‘sum’:输出是将各个元素的误差求和。 默认:‘mean’。
- beta ( float ,optional) – 指定 L1 Loss和 L2 Loss之间变化的阈值。该值必须是非负数。默认值:1.0
CrossEntropy Loss
CrossEntropy Loss是在处理分类问题中常用的一种损失函数,如二分类和多分类。此函数来源于信息论中的交叉熵概念,用于衡量两个预估概率分布和真实概率分布之间的差异。交叉熵损失函数公式如下:
(1)对于二分类问题:
L o s s ( y , y ^ ) = − ∑ i = 1 n ( y i l o g ( y i ^ ) + ( 1 − y i ) l o g ( 1 − y i ^ ) ) Loss(y,\hat{y}) = -\sum_{i=1}^{n}(y_ilog(\hat{y_i})+(1-y_i)log(1-\hat{y_i})) Loss(y,y^)=−i=1∑n(yilog(yi^)+(1−yi)log(1−yi^))
其中, y y y是真值, y ^ \hat{y} y^是预测值,n是样本的数量,每个样本都会计算一个损失,如果reduction是‘mean’,那么会对所有样本的损失求平均;如果reduction是‘sum’,那么会对所有样本的损失求和。
(2)对于多分类问题:
L o s s ( y , y ^ ) = − ∑ i = 1 n ∑ j = 1 m y i j l o g ( y i j ^ ) Loss(y,\hat{y}) = - \sum_{i=1}^{n}\sum_{j=1}^{m}y_{ij}log(\hat{y_{ij}}) Loss(y,y^)=−i=1∑nj=1∑myijlog(yij^)
其中, y i j y_{ij} yij是第i个样本的真实标签在第j类的概率, y i j ^ \hat{y_{ij}} yij^是第i个样本预测为第j类的概率,n是样本数量,m是类别的数量,每个样本都会计算一个损失,如果reduction是‘mean’,那么会对所有样本的损失求平均;如果reduction是‘sum’,那么会对所有样本的损失求和。
Pytorch函数:
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0)
参数:
- weight (Tensor, optional) – 为每个类指定的手动缩放权重。如果给定,则必须是大小为C的张量。
- size_average (bool, optional) – 此参数已弃用。
- ignore_index (int, optional) – 指定被忽略且不会对输入梯度产生影响的目标值。
- reduce (bool, optional) – 此参数已弃用。
- reduction (str, optional) – 由以下三个参数选其一:‘none’ | ‘mean’ | ‘sum’. ‘none’:不对各个元素的误差处理, ‘mean’:输出是各个元素误差的平均值,‘sum’:输出是将各个元素的误差求和。 默认:‘mean’。
- label_smoothing (float, optional) – [0.0, 1.0] 中的浮点数。指定计算损失时的平滑量,其中 0.0 表示不平滑。默认值: 0.0.
Focal Loss
Focal Loss主要用来处理正负样本(特别是前景和背景样本的分类)不均衡的问题。样本不均衡会导致训练效率低,甚至可能会导致模型退化。Focal Loss可以视为对CrossENtropy Loss增加权重加以平衡(增加预测概率小的样本权重,其对应的损失函数值变大;反而降低预测概率大的样本权重,其对应的损失函数值变小)。参考公式如下:
L o s s ( y , y ^ ) = − ∑ i = 1 n ∑ j = 1 m ( 1 − y i j ^ ) γ y i j l o g ( y i j ^ ) Loss(y,\hat{y}) = - \sum_{i=1}^{n}\sum_{j=1}^{m}(1-\hat{y_{ij}})^{\gamma}y_{ij}log(\hat{y_{ij}}) Loss(y,y^)=−i=1∑nj=1∑m(1−yij^)γyijlog(yij^)
其中, γ \gamma γ常取2.
相关文章:

深度学习:Pytorch常见损失函数Loss简介
深度学习:Pytorch常见损失函数Loss简介 L1 LossMSE LossSmoothL1 LossCrossEntropy LossFocal Loss 此篇博客主要对深度学习中常用的损失函数进行介绍,并结合Pytorch的函数进行分析,讲解其用法。 L1 Loss L1 Loss计算预测值和真值的平均绝对…...

【Android-java】Parcelable 是什么?
Parcelable 是 Android 中的一个接口,用于实现将对象序列化为字节流的功能,以便在不同组件之间传递。与 Java 的 Serializable 接口不同,Parcelable 的性能更高,适用于 Android 平台。 要实现 Parcelable 接口,我们需…...
)
Spring整合MyBatis小实例(转账功能)
实现步骤 一,引入依赖 <!--仓库--><repositories><!--spring里程碑版本的仓库--><repository><id>repository.spring.milestone</id><name>Spring Milestone Repository</name><url>https://repo.spring.i…...

List集合的对象传输的两种方式
说明:在一些特定的情况,我们需要把对象中的List集合属性存入到数据库中,之后把该字段取出来转为List集合的对象使用(如下图) 自定义对象 public class User implements Serializable {/*** ID*/private Integer id;/*…...

海外媒体发稿:软文写作方法方式?一篇好的软文理应合理规划?
不同种类的软文会有不同的方式,下面小编就来来给大家分析一下: 方法一、要选定文章的突破点: 所说突破点就是这篇文章文章软文理应以什么样的视角、什么样的见解、什么样的语言设计理念、如何文章文章的标题来写。不同种类的传播效果&#…...
【秋招】算法岗的八股文之机器学习
目录 机器学习特征工程常见的计算模型总览线性回归模型与逻辑回归模型线性回归模型逻辑回归模型区别 朴素贝叶斯分类器模型 (Naive Bayes)决策树模型随机森林模型支持向量机模型 (Support Vector Machine)K近邻模型神经网络模型卷积神经网络(CNN)循环神经…...
为什么list.sort()比Stream().sorted()更快?
真的更好吗? 先简单写个demo List<Integer> userList new ArrayList<>();Random rand new Random();for (int i 0; i < 10000 ; i) {userList.add(rand.nextInt(1000));}List<Integer> userList2 new ArrayList<>();userList2.add…...

SQL账户SA登录失败,提示错误:18456
错误代码 18456 表示 SQL Server 登录失败。这个错误通常表示提供的凭据(用户名和密码)无法成功验证或者没有权限访问所请求的数据库。以下是一些常见的可能原因和解决方法: 1.错误的凭据:请确认提供的SA账户的用户名和密码是否正…...
Linux 终端操作命令(1)
Linux 命令 终端命令格式 command [-options] [parameter] 说明: command:命令名,相应功能的英文单词或单词的缩写[-options]:选项,可用来对命令进行控制,也可以省略parameter:传给命令的参…...

java与javaw运行jar程序
运行jar程序 一、java.exe启动jar程序 (会显示console黑窗口) 1、一般用法: java -jar myJar.jar2、重命名进程名称启动: echo off copy "%JAVA_HOME%\bin\java.exe" "%JAVA_HOME%\bin\myProcess.exe" myProcess -jar myJar.jar e…...

安装和配置 Home Assistant 教程 HACS Homkit 米家等智能设备接入
安装和配置 Home Assistant 教程 简介 Home Assistant 是一款开源的智能家居自动化平台,可以帮助你集成和控制各种智能设备,从灯光到温度调节器,从摄像头到媒体播放器。本教程将引导你如何在 Docker 环境中安装和配置 Home Assistant&#…...

解决 Android Studio 的 Gradle 面板上只有关于测试的 task 的问题
文章目录 问题描述解决办法 笔者出问题时的运行环境: Android Studio Flamingo | 2022.2.1 Android SDK 33 Gradle 8.0.1 JDK 17 问题描述 笔者最近发现一个奇怪的事情。笔者的 Android Studio 的 Gradle 面板上居然除了用于测试的 task 之外,其它什…...
安全杂记 - 复现nodejs沙箱绕过
目录 一. 配置环境1.下载nodejs2.nodejs配置3.报错解决方法 二. nodej沙箱绕过1. vm模块2.使用this或引用类型来进行沙箱绕过 一. 配置环境 1.下载nodejs 官网:https://nodejs.org/en2.nodejs配置 安装nodejs的msi文件,默认配置一直下一步即可&#x…...

信息安全事件分类分级指南
范围 本指导性技术文件为信息安全事件的分类分级提供指导,用于信息安全事件的防范与处置,为事前准备、事中应对、事后处理 提供一个基础指南,可供信息系统和基础信息传输网络的运营和使用单位以及信息安全主管部门参考使用。 术语和定义 下…...

Vue系列第八篇:echarts绘制柱状图和折线图
本篇将使用echarts框架进行柱状图和折线图绘制。 目录 1.绘制效果 2.安装echarts 3.前端代码 4.后端代码 1.绘制效果 2.安装echarts // 安装echarts版本4 npm i -D echarts4 3.前端代码 src/api/api.js //业务服务调用接口封装import service from ../service.js //npm …...
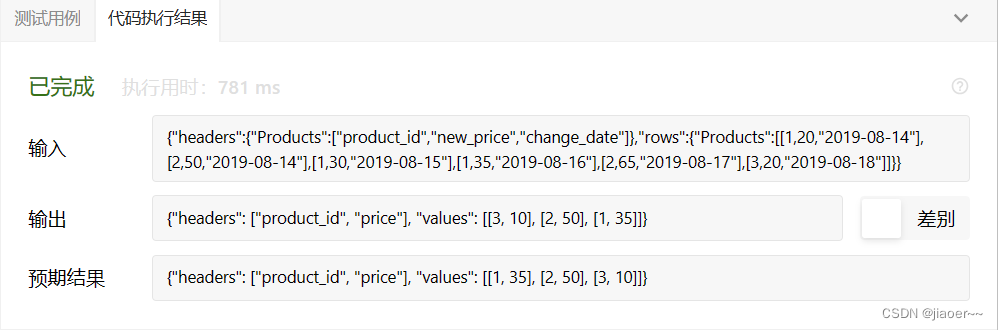
SQL-每日一题【1164. 指定日期的产品价格】
题目 产品数据表: Products 写一段 SQL来查找在 2019-08-16 时全部产品的价格,假设所有产品在修改前的价格都是 10 。 以 任意顺序 返回结果表。 查询结果格式如下例所示。 示例 1: 解题思路 1.题目要求我们查找在 2019-08-16 时全部产品的价格,假设所…...

memcpy、memmove、memcmp、memset函数的作用与区别
一、memcpy与memmove 1、memcpy 作用:从source的位置开始向后复制num个字节的数据到destination的内存位置。 注意: memcpy() 函数在遇到 ’\0’ 的时候不会停下来(strcpy字符串拷贝函数在遇到’\0’的时候会停下来);destination和source…...

socket 到底是个啥
我相信大家在面试过程中或多或少都会被问到这样一个问题:你能解释一下什么是 socket 吗 我记得我当初的回答很是浅显:socket 也叫套接字,用来负责不同主机程序之间的网络通信连接,socket 的表现方式由四元组(ip地址&am…...

奥威BI—数字化转型首选,以数据驱动企业发展
奥威BI系统BI方案可以迅速构建企业级大数据分析平台,可以将大量数据转化为直观、易于理解的图表和图形,推动和促进数字化转型的进程,帮助企业更好地了解自身的运营状况,及时发现问题并采取相应的措施,提高运营效率和质…...

vue中swiper使用
1.引包 说明:导入相应js引css import "Swiper" from "swiper" import "swiper/css/swiper.css"; import "swiper/js/swiper"; 2.结构 说明:必要的结构使用;直接封装成一个组件 <template>…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

【低功耗蓝牙】④ 蓝牙MIDI协议:从ESP32 MicroPython代码到智能乐器DIY
1. 蓝牙MIDI协议入门:从音乐小白到智能乐器开发者 第一次听说蓝牙MIDI协议时,我正盯着桌上的ESP32开发板发呆。作为一个只会弹几个和弦的编程爱好者,完全没想到自己能用代码"演奏"音乐。蓝牙MIDI就像音乐世界的通用语言,…...

避坑指南:Unity热重载插件内存占用高?可能是Windows Defender在搞鬼
Unity热重载性能优化:解决Windows Defender导致的资源占用问题 当你在Unity开发过程中频繁修改C#代码时,热重载(Hot Reload)功能无疑是提升效率的利器。它能让你在游戏运行状态下即时看到代码修改效果,避免反复重启带来的时间浪费。然而&…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...

All in Token,百度李彦宏指出:Token经济,阿里,百度,腾讯,字节,移动,电信,联通,华为,开启新的Token战争
当AI作为生产力已经成为确定性命题,我们当下应该如何衡量一家AI企业的价值?是看大模型跑分刷榜的能力,还是用户每天消耗的token数量?5月13日的Create2026大会上,百度创始人李彦宏提出了一个全新标准——DAA,…...

开源银行API模拟器Bankr Buddy:金融科技开发的本地化测试解决方案
1. 项目概述:一个为开发者准备的银行API模拟器如果你正在开发一个需要与银行账户数据打交道的应用,无论是个人财务管理工具、预算分析软件,还是企业级的财务聚合服务,你肯定遇到过同一个难题:如何在不触碰真实用户敏感…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...