PCA和自动编码器:每个人都能理解的算法
一、说明
二、pca降维和自编码
2.1 pca和自编码的共同点
自动编码器通过组合数据最重要的特征,将馈送的数据映射到低维空间。他们将原始数据编码为更紧凑的表示形式,并决定如何组合数据,因此自动编码器中的自动。这些编码特征通常称为潜在变量。
这样做可能有用的有几个原因:
1. 降维可以减少训练时间
2. 使用潜在特征表示可以增强模型性能
像机器学习中的许多概念一样,自动编码器似乎很深奥。如果您不熟悉潜在变量,则潜在变量本质上是某些数据的隐式特征。这是一个不直接观察或测量的变量。例如,幸福是一个潜在的变量。我们必须使用像问卷这样的方法来推断个人幸福的程度。
与自动编码器模型一样,主成分分析(PCA)也被广泛用作降维技术。但是,PCA 算法映射输入数据的方式与自动编码器不同。
2.2 直觉
假设您有一个很棒的跑车乐高套装,您想在朋友生日时送给他们,但您拥有的盒子不够大,无法容纳所有乐高积木。与其根本不发送,不如决定打包最重要的乐高积木——对制造汽车贡献最大的积木。所以,你扔掉一些琐碎的部件,如门把手和挡风玻璃刮水器,并打包一些像车轮和框架这样的部件。然后,您将盒子运送给您的朋友。收到包裹后,您的朋友对没有说明的杂七杂八的乐高积木感到困惑。尽管如此,他们还是组装了这套设备,并能够识别出它是一辆可驾驶的车辆。它可能是沙丘越野车,赛车或轿车 - 他们不知道。
上面的类比是有损数据压缩算法的一个例子。数据的质量没有得到完全保留。这是一种有损算法,因为一些原始数据(即乐高积木)已经丢失。虽然使用PCA和Autoencoders进行降维是有损的,但这个例子并没有完全描述这些算法——它描述了一种特征选择算法。特征选择算法会丢弃数据的某些特征并保留显著特征。选择它们保留的要素通常是出于统计原因,例如属性与目标标签之间的相关性。
三、主成分分析
假设一年过去了,你朋友的生日又快到了。你决定给他们买另一套乐高汽车,因为他们去年告诉你他们有多喜欢他们的礼物。你也因为购买了一个太小的盒子而再次犯了错误。这一次,您认为可以通过系统地将它们切成更小的碎片来更好地利用乐高积木。乐高积木的粒度更精细,让您比上次更多地填充盒子。以前,无线电天线太高,无法放入盒子,但现在您将其切成三份,包括三部分中的两部分。当您的朋友收到邮件中的礼物时,他们会通过将某些部件粘合在一起来组装汽车。他们能够将扰流板和一些轮毂盖粘在一起,因此汽车更容易识别。接下来,我们将探讨这个类比背后的数学概念。

阐述
PCA 的工作原理是将输入数据投影到数据协方差矩阵的特征向量上。协方差矩阵量化数据的方差以及每个变量彼此之间的差异程度。特征向量只是通过线性变换保持其跨度的向量;也就是说,它们在转换之前和之后指向相同的方向。协方差矩阵将原始基向量变换为朝向每个变量之间的协方差方向。简单来说,特征向量允许我们重新构建原始数据的方向,以不同的角度查看它,而无需实际转换数据。我们本质上是在提取每个变量的分量,当我们将数据投影到这些向量上时,这些分量会导致最大的方差。然后,我们可以使用协方差矩阵的特征值选择主轴,因为它们反映了相应特征向量方向上的方差大小。
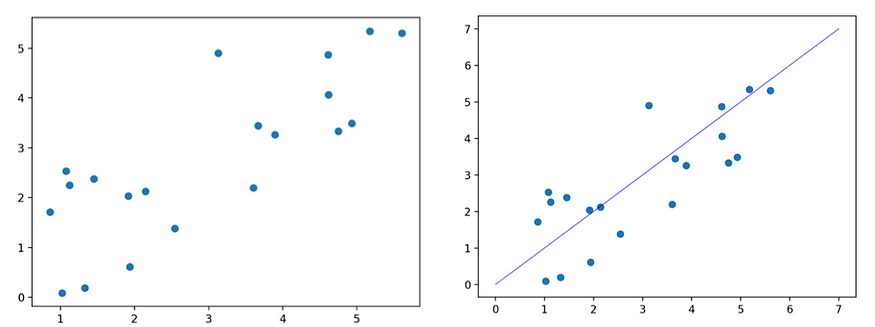
原始数据(左)第一主成分和数据(右)
这些投影产生了一个新的空间,其中每个基向量封装了最大的方差(即,具有最大特征值的特征向量的投影具有最大的方差,第二个特征向量上的投影具有第二大方差,依此类推)。这些新的基向量被称为主分量。我们希望主成分朝最大方差方向定向,因为属性值的方差越大,预测能力越好。例如,假设您正在尝试预测给定两个属性的汽车价格:颜色和品牌。假设所有的汽车都有相同的颜色,但其中有很多品牌。在这个例子中,根据汽车的颜色(一个零方差的特征)猜测汽车的价格是不可能的。但是,如果我们考虑一个差异更大的功能——品牌——我们将能够提出更好的价格估计,因为奥迪和法拉利的价格往往高于本田和丰田。由 PCA 产生的主成分是输入变量的线性组合——就像粘合的乐高积木是原始积木的线性组合一样。这些主成分的线性性质也使我们能够解释转换后的数据。

PCA 优点:
- 降低维度
- 解释
- 快速运行时间
PCA 缺点:
- 无法学习非线性特征表示
四、自动编码器
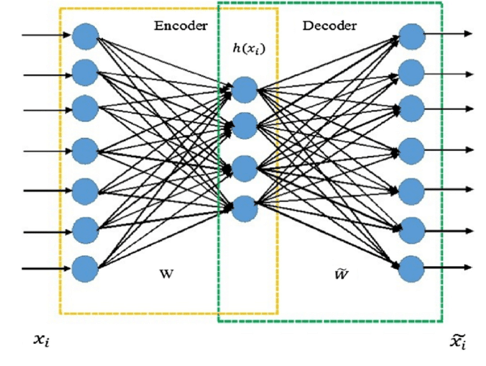
自动编码器的事情变得有点奇怪。您不只是切割零件,而是开始完全融化、拉长和弯曲乐高积木,以便最终的零件代表汽车最重要的特征,但又符合盒子的限制。这样做不仅可以让您在盒子中放入更多乐高积木,还可以创建自定义积木。这很好,但是您的好友不知道包裹到达时如何处理。对他们来说,它看起来像一堆随机操纵的乐高积木。事实上,这些部件是如此不同,以至于您需要在几辆车上重复这个过程无数次,以系统的方式将原始部件转化为可以由您的朋友组装到汽车中的部件。
阐述
希望上面的类比有助于理解自动编码器与PCA的相似之处。在自动编码器的上下文中,您是编码器,您的朋友是解码器。您的工作是以解码器可以解释和重建的方式转换数据,并且误差最小。
自动编码器只是一个重新利用的前馈神经网络。我不打算在这里深入研究细节,但请随时查看 Piotr Skalski 的精彩文章或深度学习书籍,以更全面地了解神经网络。
虽然它们能够学习复杂的特征表示,但自动编码器的最大缺陷在于它们的可解释性。就像您的朋友在收到扭曲的乐高积木时毫无头绪一样,我们不可能可视化和理解非视觉数据的潜在特征。接下来,我们将研究稀疏自动编码器。
自动编码器优点
- 能够学习非线性特征表示
- 降低维度
自动编码器缺点
- 训练计算成本高
- 无法解释
- 更复杂
- 容易过度拟合,尽管这可以通过正则化来缓解
稀疏自动编码器
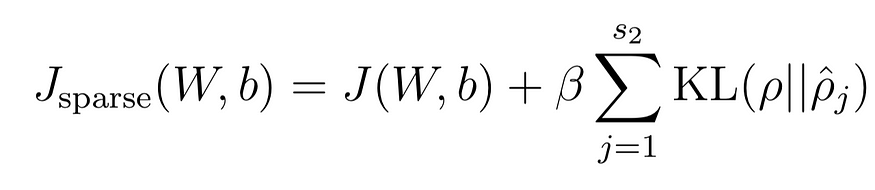
人类未充分利用大脑力量的观点是基于神经科学研究的误解,该研究表明最多有1-4%的神经元在大脑中同时放电。人脑中神经元的稀疏放电可能有几个很好的进化原因。如果所有神经元同时放电,我们能够“释放大脑的真正潜力”,它可能看起来像这样。我希望你喜欢题外话。回到神经网络。大脑中突触的稀疏性可能是稀疏自动编码器的灵感来源。神经网络中的隐藏神经元学习输入数据的分层特征表示。当神经元看到它正在寻找的输入数据的特征时,我们可以认为它“放电”。原版自动编码器通过其不完整的架构(不完整意味着隐藏层包含的单元少于输入层)强制学习潜在特征。稀疏自动编码器背后的想法是,我们可以强制模型通过与架构无关的约束(稀疏性约束)来学习潜在特征表示。
稀疏性约束是我们希望的平均隐藏层激活,通常是接近零的浮点值。稀疏性约束超高计在上面的函数中用希腊字母 rho 表示。Rho hat j 表示隐藏单元 j 的平均激活。
我们使用KL散度将此约束强加于模型,并通过β加权。简而言之,KL 散度衡量两个分布的相异性。将此项添加到我们的损失函数中可激励模型优化参数,从而使激活值分布与稀疏性参数均匀分布之间的KL分歧最小化。
限制接近零的激活意味着神经元只会在优化准确性最关键的时候触发。KL发散项意味着神经元也将因过于频繁地放电而受到惩罚。如果您有兴趣了解有关稀疏自动编码器的更多信息,我强烈建议您阅读本文。吴恩达的这些讲座(讲座1,讲座2)也是一个很好的资源,帮助我更好地理解了支撑自动编码器的理论。
五、结论
在本文中,我们深入研究了PCA和自动编码器背后的概念。不幸的是,没有灵药。PCA和自动编码器模型之间的决定是间接的。在许多情况下,PCA 是优越的 - 它更快,更易于解释,并且可以像自动编码器一样降低数据的维度。如果你可以使用PCA,你应该这样做。但是,如果您处理的数据需要高度非线性的特征表示才能获得足够的性能或可视化效果,则 PCA 可能达不到要求。在这种情况下,训练自动编码器可能是值得的。再说一次,即使自动编码器产生的潜在特征提高了模型性能,这些特征的模糊性也会对知识发现构成障碍。
相关文章:
PCA和自动编码器:每个人都能理解的算法
一、说明 本文的主要重点是提供主成分分析 (PCA) 和自动编码器数据转换技术的直观信息。我不打算深入研究支撑这些模型的数学理论,因为已经有大量的资源可用。 二、pca降维和自编码 2.1 pca和自编码的共同点 自动编码器通过组合数据最重要的特…...

C++——STL容器【priority_queue】模拟实现
本章代码:优先级队列模拟实现、priority_queue文档 文章目录 🐈1. priority_queue介绍🦄2. priority_queue模拟实现🐧2.1 构造函数🐧2.2 建堆向下调整向上调整 🐧2.3 仿函数🐧2.4 push & po…...
SpringBoot实现文件记录日志,日志文件自动归档和压缩
😊 作者: Eric 💖 主页: https://blog.csdn.net/weixin_47316183?typeblog 🎉 主题:SpringBoot实现文件记录日志,日志文件自动归档和压缩 ⏱️ 创作时间: 2023年08月06日 文章目…...
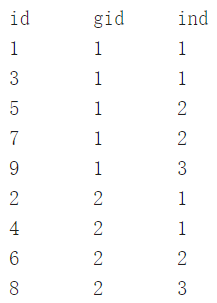
MySQL 窗口函数
聚合函数作为窗口函数 设聚合函数为op语法结构: op(字段名A) over(partition by 字段名B order by 字段名C rows between D1 and D2) 其中: partition by:按照某一字段将数据进行分组 order by:按照某一字段将数据进行排序&…...
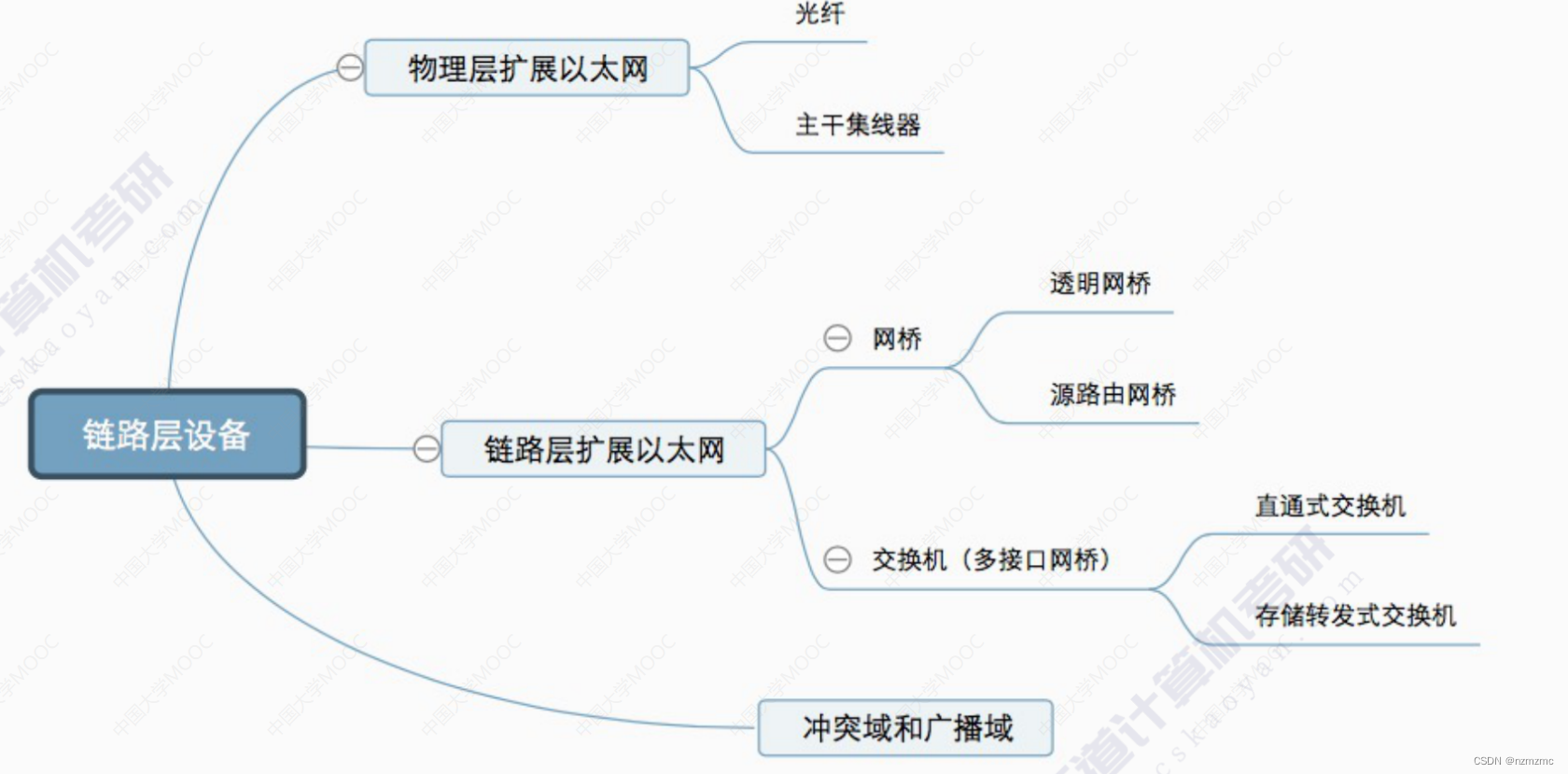
0140 数据链路层2
目录 3.数据链路层 3.6局域网 3.7广域网 3.8数据链路层设备 部分习题 3.数据链路层 3.6局域网 3.7广域网 3.8数据链路层设备 部分习题 1.如果使用5类UTP来设计一个覆盖范围为200m的10BASE-T以太网,需要采用的设备是() A.放大器 …...

Python字典的应用场景
Python字典是一种无序、可变的数据类型,它由键值对组成。字典在Python中被广泛应用,以下是一些常见的应用场景: 数据存储和检索:字典可以用来存储和检索大量的数据,通过使用键来快速访问对应的值。例如,可以…...
关于外贸跟进客户过程中需要注意的地方
如果你感觉业务进展困难,多去看一些书,多去链接一些人,特别是优秀的人,多交流会让你思维更加开阔,笔记做好实践起来,就会有收获! 我记得汪老师说过:跟进客户,当你准备好…...

AI绘画:两组赛博咒语和ComfyUI使用方法
虽迟但到啊,上次说过要发,必然是要发滴! 本来我是可以直接发的,但是我又想着发关键词的同时,最好是讲解一下用法,这样更友好。所以就拖了一天! 下面先展示一下两套咒语的效果: 这套…...

Nacos源码 (2) 核心模块
返回目录 整体架构 服务管理:实现服务CRUD,域名CRUD,服务健康状态检查,服务权重管理等功能配置管理:实现配置管CRUD,版本管理,灰度管理,监听管理,推送轨迹,聚…...

MySQL之深入InnoDB存储引擎——Buffer Pool
文章目录 一、空闲链表的管理二、缓冲页的哈希处理三、Flush链表的管理四、LRU链表的管理五、脏页刷新六、多Buffer Pool实例 InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。在数据库系统中,由于CPU速度与磁盘速度之间的鸿沟&…...

网络安全(秋招)如何拿到offer?(含面试题)
以下为网络安全各个方向涉及的面试题,星数越多代表问题出现的几率越大,祝各位都能找到满意的工作。 注:本套面试题,已整理成pdf文档,但内容还在持续更新中,因为无论如何都不可能覆盖所有的面试问题…...
)
笙默考试管理系统-MyExamTest----classranking(2)
笙默考试管理系统-MyExamTest----classranking(2) 目录 笙默考试管理系统-MyExamTest----classranking(2) 一、 笙默考试管理系统-MyExamTest----classranking 二、 笙默考试管理系统-MyExamTest----classranking 三、 笙…...

基于python的一个元素多种定位方式
基于 Python 的 Page Factory 设计模式测试库, 类似于Java的Page Factory模式,旨在减少代码冗余,简单易用,具有高度的可扩展能力。 支持以annotation的方式定义元素 支持同一个元素多种定位方式 支持动态的定位方式 安装 pip install pyth…...
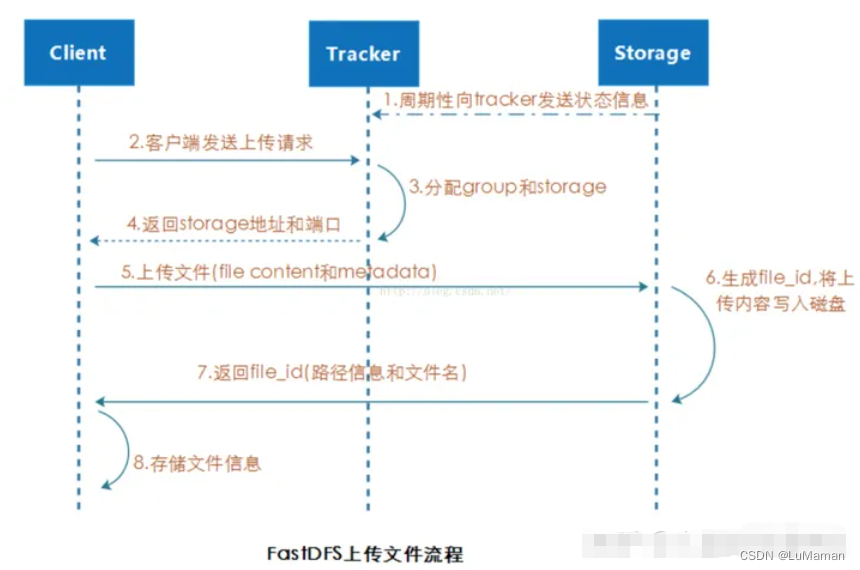
Fastdfs集群搭建
一、简单介绍: FastDFS是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。主要解决了海量数据存储问题,特别适合以中小文件&…...

【深度学习】Vision Transformer论文,ViT的一些见解《 一幅图像抵得上16x16个词:用于大规模图像识别的Transformer模型》
必看文章:https://blog.csdn.net/qq_37541097/article/details/118242600 论文名称: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale 论文下载:https://arxiv.org/abs/2010.11929 官方代码:https:…...
在centos7上使用非编译方式安装ffmpeg
很多在centos7上安装ffmpeg的教程都需要使用编译方式的安装;编译时间较长而且需要配置; 后来搜索到可以通过加载rpm 源的方式实现快速便捷操作 第一种方式: 首先需要安装yum源: yum install epel-release yum install -y https://mirrors.…...

【微信小程序】导出Excel文件
// 导出 doOutExcel() {let fileName 考勤列表wx.request({url: XXX,method: POST,header: {"content-type": "application/json","Authorization": "token " wx.getStorageSync(userInfo).token},data: {}, // 请求参数responseTyp…...

接口测试—知识速查(Postman)
文章目录 接口测试1. 概念2. 原理3. 测试流程4. HTTP协议4.1 URL的介绍4.2 HTTP请求4.2.1 请求行4.2.2 请求头4.2.3 请求体4.2.4 完整的HTTP请求示例 4.3 HTTP响应4.3.1 状态行4.3.2 响应头4.3.3 响应体4.3.4 完整的HTTP请求示例 5. RESTful接口规范6. 测试用例的设计思路6.1 单…...

机器学习深度学习——序列模型(NLP启动!)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——卷积神经网络(LeNet) 📚订阅专栏:机器学习&&深度…...

小白到运维工程师自学之路 第六十四集 (dockerfile构建tomcat、mysql、lnmp、redis镜像)
一、tomcat(更换jdk) mkdir tomcat cd tomcat/ tar xf jdk-8u191-linux-x64.tar.gz tar xf apache-tomcat-8.5.40.tar.gzvim Dockerfile FROM centos:7 MAINTAINER Crushlinux <syh163.com> ADD jdk1.8.0_191 /usr/local/java ENV JAVA_HOME /us…...

FineBI组件制作-表格
FineBI 为用户提供了三种表格类型:明细表、分组表、交叉表。 明细表 明细表将表格中的所有数据一条一条都罗列出来,用于展示明细数据,通常包含了大量的数据记录,可以用于进行分析、查询等操作。特点: 可以展示数据的详…...

告别小屏幕!5个专业技巧让你在Windows大屏上高效刷酷安
告别小屏幕!5个专业技巧让你在Windows大屏上高效刷酷安 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在忍受手机小屏幕刷酷安的酸涩感吗?想象一下,…...

2026数字营销岗位需要具备的能力有哪些
数字营销这几年变化很快,到了2026年,岗位要求已经不再只是“会投放、会写文案、会做表格”这么简单了。很多职场人都能明显感觉到:过去靠经验拍脑袋做营销,越来越难;未来真正有竞争力的人,往往是那些既懂业…...

抖音批量下载终极指南:免费高效获取无水印视频与音乐
抖音批量下载终极指南:免费高效获取无水印视频与音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...
)
仅限首批50家申请者:ElevenLabs潮州话语音定制音色内测通道开放(含潮汕非遗传承人声纹授权协议模板)
更多请点击: https://kaifayun.com 第一章:ElevenLabs潮州话语音定制音色内测计划概览 ElevenLabs 正式启动潮州话语音合成能力的定向内测,聚焦方言语音建模、声学特征保留与文化语境适配三大技术维度。本次内测面向具备潮州话母语能力的开发…...

国密 TLCP 实战:GmSSL / OCL / Nginx 版本选型与全部调试修改说明
本文面向发布到 CSDN,汇总本人在 Windows WSL2 编译、Docker 部署、CentOS 生产环境跑通 Nginx 国密 HTTPS(TLCP) 时使用的源码版本、目录布局,以及为调通而做的全部修改(含配置、脚本、证书处理;不含对 N…...

告别 API 收费!OpenClaw 对接 Ollama,本地大模型免费无限用
OpenClaw 连接 Ollama 本地模型教程 前置准备 已安装并能正常打开 OpenClaw Windows 客户端OpenClaw 顶部 Gateway 状态保持在线电脑可正常联网,能访问 Ollama 官网磁盘空间充足(本地模型占用空间较大)提前确认待下载的模型名称(…...

别再一股脑塞Prompt了!Claude/GPT-3.5-Turbo-16k实测:关键信息放开头还是结尾?
大模型长文本处理实战:关键信息位置对生成效果的影响机制与优化策略 当开发者面对Claude、GPT-3.5-Turbo-16k这类支持长上下文的大语言模型时,常陷入一个典型困境:明明已将全部资料塞入上下文窗口,模型却依然遗漏关键信息或给出偏…...

如何高效管理中文文献:Zotero茉莉花插件完整使用指南
如何高效管理中文文献:Zotero茉莉花插件完整使用指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zotero处理…...

电子书转有声书终极指南:一键生成多语言AI有声读物
电子书转有声书终极指南:一键生成多语言AI有声读物 【免费下载链接】ebook2audiobook Generate audiobooks from e-books, voice cloning & 1158 languages! 项目地址: https://gitcode.com/GitHub_Trending/eb/ebook2audiobook 将你的电子书库变成随时可…...