探索Python数据容器之乐趣:列表与元组的奇妙旅程!
文章目录
- 零 数据容器入门
- 一 数据容器:list(列表)
- 1.1 列表的定义
- 1.2 列表的下表索引
- 1.3 列表的常用操作
- 1.3.1 列表的查询功能
- 1.3.2 列表的修改功能
- 1.3.3 列表常用方法总结
- 1.4 补充:append与extend对比
- 1.5 list(列表)的遍历
- 1.6 补充:while循环和for循环对比
- 二 数据容器:tuple(元组)
- 2.1 元组的定义
- 2.2 疑惑解答
- 2.3 元组的操作
- 2.4 注意事项
- 2.5 练习案例:元组的基本操作
零 数据容器入门
-
Python中的数据容器:
- 一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素
- 每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
-
数据容器根据特点的不同,如:是否支持重复元素、是否可以修改、是否有序,等分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
一 数据容器:list(列表)
1.1 列表的定义
- 在Python中,
list(列表)是一种常用的数据容器,用于存储多个元素。列表是可变(mutable)的,可以在创建后随时修改它,添加或删除元素。 - 列表可以包含不同类型的元素,例如整数、字符串、浮点数等,甚至可以包含其他列表。
- 创建列表的语法为用方括号
[]括起来的一系列元素,每个元素之间用逗号,分隔。例如:
my_list = [1, 2, 3, "hello", 3.14]
# 列表[下标索引], 从前向后从0开始,每次+1, 从后向前从-1开始,每次-1
print(my_list[0])
print(my_list[1])
print(my_list[2])
# 错误示范;通过下标索引取数据,一定不要超出范围
# print(my_list[3])
- 列表索引从0开始,所以第一个元素可以通过
my_list[0]来访问,第二个元素通过my_list[1],依此类推。
列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套
# 定义一个嵌套的列表
my_list = [ [1, 2, 3], [4, 5, 6]]
print(my_list)
print(type(my_list))
1.2 列表的下表索引
- 列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增

- 可以反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3…)

- 如果列表是嵌套的列表,同样支持下标索引

- 演示
# 列表[下标索引], 从前向后从0开始,每次+1, 从后向前从-1开始,每次-1
print(my_list[0])
print(my_list[1])
print(my_list[2])
# 错误示范;通过下标索引取数据,一定不要超出范围
# print(my_list[3])# 通过下标索引取出数据(倒序取出)
print(my_list[-1])
print(my_list[-2])
print(my_list[-3])# 取出嵌套列表的元素
my_list = [ [1, 2, 3], [4, 5, 6]]
print(my_list[1][1])
1.3 列表的常用操作
1.3.1 列表的查询功能
-
使用
index()方法来查找列表中某个元素第一次出现的索引(下标)。 -
index()方法接受一个参数,即要查找的元素的值,并返回该元素在列表中的索引值。如果该元素不存在于列表中,该方法将引发一个ValueError异常。 -
index()方法查找元素的示例:my_list = [10, 20, 30, 40, 50]# 查找元素的索引 index_30 = my_list.index(30) print(index_30) # 输出: 2index_40 = my_list.index(40) print(index_40) # 输出: 3# 查找不存在的元素会引发异常 try:index_60 = my_list.index(60) except ValueError as e:print("元素不存在:", e) # 输出: 元素不存在: 60 is not in list -
请注意,
index()方法只会返回找到的第一个匹配项的索引。
- 如果有多个相同的元素,可能需要使用循环来找到所有匹配项的索引。
my_list = [10, 20, 30, 40, 30, 50]# 找到所有匹配项的索引
target = 30
indices = []
for i in range(len(my_list)):if my_list[i] == target:indices.append(i)print(indices) # 输出: [2, 4]1.3.2 列表的修改功能
- 修改元素:通过索引来修改列表中的元素。
my_list = [1, 2, 3, "hello", 3.14] my_list[2] = 42 print(my_list) # 输出: [1, 2, 42, 'hello', 3.14] my_list[-1]=-1 print(my_list) # 输出: [1, 2, 42, 'hello', -1] - 插入元素:使用
insert()方法在指定位置插入指定元素- 第一个参数是要插入的索引,第二个参数是要插入的元素。
my_list = [1, 2, 3, 5]
my_list.insert(3, 4)
print(my_list) # 输出: [1, 2, 3, 4, 5]
-
添加元素
- 使用
append()方法在列表末尾添加元素。 append()方法没有返回值(即返回值为None),它会直接在原列表上进行修改。
my_list = [1, 2, 3, "hello", 3.14] my_list.append("world") print(my_list) # 输出: [1, 2, 42, 'hello', 3.14, 'world']- 使用
extend()方法,将其它数据容器的内容取出,依次追加到列表尾部 - 列表的 extend() 方法用于将一个可迭代对象的元素添加到列表的末尾。可迭代对象可以是另一个列表、元组、字符串,或者任何支持迭代的数据类型。extend() 方法会逐个迭代可迭代对象,并将其中的元素依次添加到列表中。
# 列表扩展 list1 = [1, 2, 3] list2 = [4, 5, 6] list1.extend(list2) print(list1) # 输出: [1, 2, 3, 4, 5, 6]# 字符串扩展 my_list = [1, 2, 3] my_string = "hello" my_list.extend(my_string) print(my_list) # 输出: [1, 2, 3, 'h', 'e', 'l', 'l', 'o']# 可迭代对象扩展 my_list = [1, 2, 3] my_tuple = (4, 5, 6) my_list.extend(my_tuple) print(my_list) # 输出: [1, 2, 3, 4, 5, 6] - 使用
-
删除元素:
remove()方法:通过值删除元素。该方法将从列表中删除第一个匹配到的值。如果要删除所有匹配的值,可以使用循环结合remove()方法来实现。
my_list = [1, 2, 3, 2, 4] my_list.remove(2) print(my_list) # 输出: [1, 3, 2, 4]my_list = [1, 2, 3, 2, 4]# 删除所有匹配的值 value_to_remove = 2 while value_to_remove in my_list:my_list.remove(value_to_remove)print(my_list) # 输出: [1, 3, 4]pop()方法:通过索引删除元素,并返回被删除的元素。如果不提供索引,它将删除并返回列表的最后一个元素。
my_list = [1, 2, 3, 4] deleted_element = my_list.pop(1) print(deleted_element) # 输出: 2 print(my_list) # 输出: [1, 3, 4]deleted_element = my_list.pop() print(deleted_element) # 输出: 4 print(my_list) # 输出: [1, 3]del语句:通过索引使用del语句删除元素。与pop()方法不同,del语句不返回被删除的元素。
my_list = [1, 2, 3, 4] del my_list[1] print(my_list) # 输出: [1, 3, 4]- 使用切片删除多个元素:通过切片语法删除多个元素。
-
my_list[:2]:这是一个切片操作,表示获取从索引0到索引2(不包括索引2)的子列表。这将返回[1, 2],这是原列表my_list中索引为0和1的元素组成的子列表。 -
my_list[3:]:这也是一个切片操作,表示获取从索引3到列表末尾的子列表。这将返回[4, 5],这是原列表my_list中索引为3和4的元素组成的子列表。
-
my_list = [1, 2, 3, 4, 5] my_list = my_list[:2] + my_list[3:] print(my_list) # 输出: [1, 2, 4, 5]- 清空列表:使用 clear() 方法可以清空列表中的所有元素。
my_list = [1, 2, 3, 4, 5] my_list.clear() print(my_list) # 输出: []- 统计某元素在列表内的数量:
.count(元素)方法统计元素在列表中的个数
mylist = ["itcast", "itheima", "itcast", "itheima", "python"] count = len(mylist) print(f"列表的元素数量总共有:{count}个")- 统计元素个数:
len()方法用于获取列表(或其他可迭代对象)的长度,即列表中包含的元素个数len()方法是一个内置函数,它不仅可以用于列表,还可以用于字符串、元组、集合等可迭代对象。
my_list = [1, 2, 3, 4, 5] length = len(my_list) print(length) # 输出: 5
1.3.3 列表常用方法总结
| 方法 | 描述 | 示例 |
|---|---|---|
append() | 在列表末尾添加一个元素 | my_list.append(10) |
extend() | 将一个可迭代对象中的元素逐个添加到列表末尾 | my_list.extend([20, 30, 40]) |
insert() | 在指定位置插入一个元素 | my_list.insert(1, 15) |
remove() | 删除第一个匹配的元素 | my_list.remove(30) |
pop() | 删除并返回指定索引的元素(默认为最后一个元素) | my_list.pop(1) |
del 语句 | 通过索引删除元素 | del my_list[0] |
clear() | 删除列表中的所有元素 | my_list.clear() |
index() | 返回指定元素的索引(第一个匹配项) | index = my_list.index(40) |
count() | 统计指定元素在列表中出现的次数 | count = my_list.count(20) |
sort() | 对列表进行排序(原地排序,不返回新列表) | my_list.sort() |
reverse() | 反转列表中的元素顺序 | my_list.reverse() |
| 切片操作 | 从列表中获取子列表或修改多个元素 | sub_list = my_list[1:4], my_list[1:4] = [8, 9, 10] |
1.4 补充:append与extend对比
append()和extend()方法是两个常用的方法,但它们有着不同的用途和行为。
append()方法:
- 用途:
append()方法用于将指定的元素作为一个整体添加到列表的末尾。 - 参数:
append()方法接受一个参数,即要添加到列表末尾的元素。 - 返回值:
append()方法没有返回值,其返回值为None。 - 修改原列表:
append()方法直接在原列表上进行修改,将指定的元素添加到列表的末尾。 - 示例:
my_list = [1, 2, 3]
my_list.append(4)
print(my_list) # 输出: [1, 2, 3, 4]my_list.append([5, 6])
print(my_list) # 输出: [1, 2, 3, 4, [5, 6]]extend()方法:
- 用途:
extend()方法用于将一个可迭代对象的元素逐个添加到列表的末尾。 - 参数:
extend()方法接受一个可迭代对象作为参数,例如列表、元组、字符串等。 - 返回值:
extend()方法没有返回值,其返回值为None。 - 修改原列表:
extend()方法直接在原列表上进行修改,将可迭代对象中的元素逐个添加到列表的末尾。 - 示例:
my_list = [1, 2, 3]
my_list.extend([4, 5, 6])
print(my_list) # 输出: [1, 2, 3, 4, 5, 6]
总结:
-
使用
append()方法,您可以将一个元素作为整体添加到列表的末尾。 -
使用
extend()方法,您可以将一个可迭代对象中的元素逐个添加到列表的末尾。 -
两种方法都直接在原列表上进行修改,而且它们没有返回值,其返回值为
None。 -
选择使用
append()还是extend()取决于您要添加的元素类型和添加的方式。如果您要将一个单一元素作为整体添加到列表,使用append()。如果您有一个可迭代对象,希望将其中的所有元素逐个添加到列表,使用extend()。
1.5 list(列表)的遍历
- 在Python中,列表是一种可迭代对象,可以通过遍历来访问其中的元素。有几种方式可以对Python列表进行遍历:
- 使用for循环:
my_list = [1, 2, 3, 4, 5]for item in my_list:print(item)
- 使用索引和range函数:
my_list = [1, 2, 3, 4, 5]for i in range(len(my_list)):print(my_list[i])
- 使用enumerate函数(同时获取索引和元素):
my_list = [1, 2, 3, 4, 5]for index, item in enumerate(my_list):print(f"Index: {index}, Item: {item}")
- 使用while循环和索引:
my_list = [1, 2, 3, 4, 5] index = 0while index < len(my_list):print(my_list[index])index += 1
1.6 补充:while循环和for循环对比
while循环和for循环,都是循环语句,但细节不同:
在循环控制上:
- while循环可以自定循环条件,并自行控制
- for循环不可以自定循环条件,只可以一个个从容器内取出数据
在无限循环上:
- while循环可以通过条件控制做到无限循环
- for循环理论上不可以,因为被遍历的容器容量不是无限的
在使用场景上:
- while循环适用于任何想要循环的场景
- for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
二 数据容器:tuple(元组)
2.1 元组的定义
- 元组同列表一样,都是可以封装多个、不同类型的元素在内。但最大的不同点在于:元组一旦定义完成,就不可修改
- 元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
# 定义元组字面量
(元素,元素,元素,...)
# 定义元组变量
变量名称=(元素,元素,元素,...)
# 定义空元组
变量名称=()
变量名称=tuple()
# 定义一个空元组
empty_tuple = ()# 定义一个包含多个元素的元组
my_tuple = (1, 2, "Hello", 3.14, [4, 5])# 元组中也可以包含其他元组
nested_tuple = (1, (2, 3), ("a", "b", "c"))# 单个元素的元组需要在元素后面加上逗号,以区分其与括号运算符的使用
single_element_tuple = (42,)
2.2 疑惑解答
-
元组只有一个数据,这个数据后面要添加逗号。
-
在Python中,如果要定义只有一个元素的元组,需要在元素后面添加逗号,否则Python会将其视为其他数据类型而不是元组。
-
这是因为在使用圆括号时,Python解释器需要通过逗号来区分表达式和元组。当只有一个元素且没有逗号时,解释器无法确定它是一个元组还是一个普通的表达式。
- 以下是正确定义只包含一个元素的元组的示例:
# 只包含一个元素的元组,需要在元素后面添加逗号 single_element_tuple = (42,) print(type(single_element_tuple)) # 输出:<class 'tuple'>- 如果没有添加逗号:
# 没有添加逗号,解释器将不会将其识别为元组 not_a_tuple = (42) print(type(not_a_tuple)) # 输出:<class 'int'>- 所以,为了确保只包含一个元素的表达式被正确解释为元组,必须添加逗号。
2.3 元组的操作
- 元组由于不可修改的特性,所以其操作方法非常少
- Python元组的常见操作:
| 操作 | 示例 | 描述 |
|---|---|---|
| 访问元素 | my_tuple[0] | 使用索引访问元组中的元素。 |
| 切片 | my_tuple[1:4] | 使用切片获取元组中的子集。 |
| 连接 | tuple1 + tuple2 | 使用加号(+)将两个元组连接起来。 |
| 复制 | my_tuple * 3 | 使用乘号(*)复制元组。 |
| 元素检查 | element in my_tuple | 使用in关键字检查元素是否在元组中。 |
| 元素个数 | len(my_tuple) | 使用len()函数获取元组中元素的个数。 |
| 元素最值 | min(my_tuple)max(my_tuple) | 使用min()和max()函数获取元组中的最小和最大值。 |
| 元组解包 | a, b, c = my_tuple | 将元组的元素解包到多个变量中。 |
| 查找元素索引 | my_tuple.index(element) | 返回元素在元组中第一次出现的索引。 |
| 统计元素出现次数 | my_tuple.count(element) | 返回元素在元组中出现的次数。 |
感谢您的提醒,这些方法是在处理元组时非常有用的功能,使得我们可以更方便地对元组进行操作和查询。
- 访问元素:可以使用索引来访问元组中的元素。
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[0]) # 输出:1
- 切片:可以使用切片来获取元组中的子集。
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[1:4]) # 输出:(2, 3, 4)
- 连接:可以使用加号(+)将两个元组连接起来。
tuple1 = (1, 2, 3)
tuple2 = (4, 5, 6)
concatenated_tuple = tuple1 + tuple2
print(concatenated_tuple) # 输出:(1, 2, 3, 4, 5, 6)
- 复制:可以使用乘号(*)复制元组。
my_tuple = (1, 2, 3)
duplicated_tuple = my_tuple * 3
print(duplicated_tuple) # 输出:(1, 2, 3, 1, 2, 3, 1, 2, 3)
- 元素检查:可以使用
in关键字检查元素是否在元组中。
my_tuple = (1, 2, 3)
print(2 in my_tuple) # 输出:True
print(4 in my_tuple) # 输出:False
- 元素个数:使用
len()函数可以获取元组中元素的个数。
my_tuple = (1, 2, 3)
print(len(my_tuple)) # 输出:3
- 元素最值:可以使用
min()和max()函数获取元组中的最小和最大值。
my_tuple = (5, 2, 8, 1, 3)
print(min(my_tuple)) # 输出:1
print(max(my_tuple)) # 输出:8
- 元组解包:可以将元组的元素解包到多个变量中。
my_tuple = (1, 2, 3)
a, b, c = my_tuple
print(a) # 输出:1
print(b) # 输出:2
print(c) # 输出:3
- 查找元素索引:
index()方法用于查找元组中指定元素的索引(第一次出现的位置)。如果元素不存在于元组中,会引发 ValueError 错误。
my_tuple = (10, 20, 30, 40, 20, 50)index_20 = my_tuple.index(20)
print("Index of 20:", index_20) # 输出:Index of 20: 1index_60 = my_tuple.index(60) # 元素 60 不在元组中,会引发 ValueError 错误
- 统计元素出现次数:
count()方法用于统计元组中指定元素的出现次数
my_tuple = (10, 20, 30, 40, 20, 50)count_20 = my_tuple.count(20)
print("Count of 20:", count_20) # 输出:Count of 20: 2count_60 = my_tuple.count(60)
print("Count of 60:", count_60) # 输出:Count of 60: 02.4 注意事项
- 如果元组中包含可变对象,例如列表,那么列表内的内容是可以修改的。虽然元组本身不能变,但是列表是可变的,因此可以对列表内的元素进行修改。
- 可以修改元组内的list的内容(修改元素、增加、删除、反转等)
# 创建一个包含列表的元组 my_tuple = ([1, 2, 3], [4, 5, 6])# 修改元组中列表的元素 my_tuple[0][1] = 100 my_tuple[1].append(7) my_tuple[1].remove(4)print(my_tuple) # 输出:([1, 100, 3], [5, 6, 7]) - 元组中list不可以替换list为其它list或其它类型
# 创建一个包含列表的元组 my_tuple = ([1, 2, 3], [4, 5, 6])# 尝试替换元组中的列表为其他列表 new_list = [7, 8, 9] my_tuple[0] = new_list # 会引发 TypeError 错误,元组不可赋值修改# 尝试直接替换列表为其他类型 my_tuple[1] = "Hello" # 会引发 TypeError 错误,元组不可赋值修改# 尝试修改元组内列表的元素 my_tuple[0][1] = 100 # 这是可以的,因为元组中的列表是可变对象print(my_tuple)
2.5 练习案例:元组的基本操作
-
定义一个元组,内容是:(‘周杰轮’, 11, [‘football’, ‘music’]),记录的是一个学生的信息(姓名、年龄、爱好)
-
请通过元组的功能(方法),对其进行
- 查询其年龄所在的下标位置
- 查询学生的姓名
- 删除学生爱好中的football
- 增加爱好:coding到爱好list内
-
示例代码:
student_info = ('周杰轮', 11, ['football', 'music'])# 1. 查询年龄所在的下标位置 age_index = student_info.index(11) print("年龄所在的下标位置:", age_index)# 2. 查询学生的姓名 name = student_info[0] print("学生的姓名:", name)# 3. 删除学生爱好中的football hobbies = student_info[2] if 'football' in hobbies:hobbies.remove('football') print("删除后的爱好列表:", hobbies)# 4. 增加爱好:coding到爱好list内 hobbies.append('coding') print("增加爱好后的列表:", hobbies)# 最终的学生信息元组 updated_student_info = (name, 11, hobbies) print("最终的学生信息元组:", updated_student_info) -
运行结果:
年龄所在的下标位置: 1 学生的姓名: 周杰轮 删除后的爱好列表: ['music'] 增加爱好后的列表: ['music', 'coding'] 最终的学生信息元组: ('周杰轮', 11, ['music', 'coding'])
相关文章:
探索Python数据容器之乐趣:列表与元组的奇妙旅程!
文章目录 零 数据容器入门一 数据容器:list(列表)1.1 列表的定义1.2 列表的下表索引1.3 列表的常用操作1.3.1 列表的查询功能1.3.2 列表的修改功能1.3.3 列表常用方法总结 1.4 补充:append与extend对比1.5 list(列表)的遍历1.6 补…...
Python自动化实战之使用Pytest进行API测试详解
概要 每次手动测试API都需要重复输入相同的数据,而且还需要跑多个测试用例,十分繁琐和无聊。那么,有没有一种方法可以让你更高效地测试API呢?Pytest自动化测试!今天,小编将向你介绍如何使用Pytest进行API自…...
TCP的三次握手以及四次断开
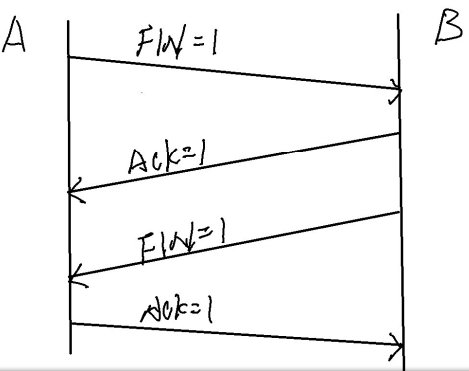
TCP的三次握手和四次断开,就是TCP通信建立连接以及断开的过程 目录 【1】TCP的三次握手过程 ---- TCP建立连接的过程 【2】TCP的四次挥手 ---- TCP会话的断开 注意: 【1】TCP的三次握手过程 ---- TCP建立连接的过程 三次握手的过程:…...

目标检测YOLO实战应用案例100讲-基于视觉与激光雷达信息融合的智能车辆目标检测研究
目录 前言 传感器选型及同步 2.1 各传感器工作原理及性能对比 2.1.1 视觉传感器...

Day 22 C++ STL常用容器——string容器
string容器 概念本质string和char 区别:特点string构造函数构造函数原型 string赋值操作赋值的函数原型示例 string字符串拼接函数原型:示例 string查找和替换函数原型示例 string字符串比较比较方式 字符串比较是按字符的ASCII码进行对比函数原型示例 s…...

使用Socket实现UDP版的回显服务器
文章目录 1. Socket简介2. DatagramSocket3. DatagramPacket4. InetSocketAddress5. 实现UDP版的回显服务器 1. Socket简介 Socket(Java套接字)是Java编程语言提供的一组类和接口,用于实现网络通信。它基于Socket编程接口,提供了…...

【MCU学习】GD32F427VG开发
(一)学习文档和例程 兆易创新GD32 MCU参考资料下载 1.GD232F4xx的Keil芯片支持包 2.标准固件库和示例程序 3.GD32F4xx_固件库使用指南_Rev1.2 4.用户手册:GD32F4xx_User_Manual_Rev2.8_CN 5.数据手册:GD32F427xx_Datasheet_Rev…...

Acwing.877 扩展欧几里得算法
题目 给定n对正整数ai , bi,对于每对数,求出一组ai ,g,使其满足ai* xi bi * yi gcd(ai ,bi)。 输入格式 第一行包含整数n。 接下来n行,每行包含两个整数ai , bi。 输出格式 输出共n行,对于每组ai, bi,…...
基于自组织竞争网络的患者癌症发病预测(matlab代码)
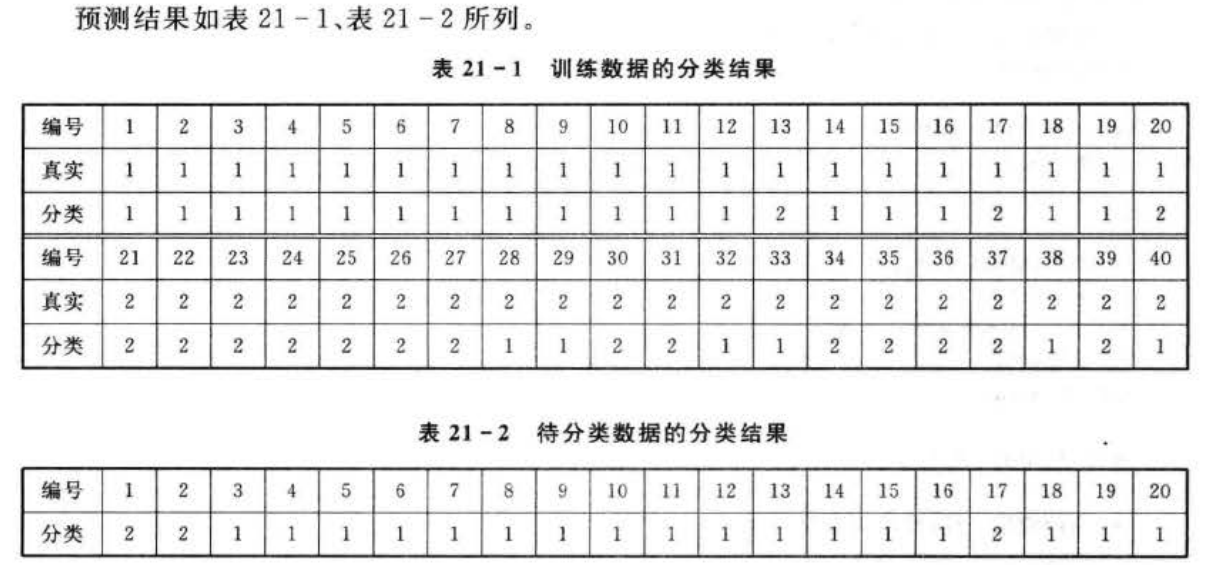
1.案例背景 1.1自组织竞争网络概述 前面案例中讲述的都是在训练过程中采用有导师监督学习方式的神经网络模型。这种学习方式在训练过程中,需要预先给网络提供期望输出,根据期望输出来调整网络的权重,使得实际输出和期望输出尽可能地接近。但是在很多情况下,在人们认知的过程中…...

golang mongodb
看代码吧 package main// 链接案例 https://www.mongodb.com/docs/drivers/go/current/fundamentals/connection/#connection-example // 快速入门 https://www.mongodb.com/docs/drivers/go/current/quick-start/ import ("context""fmt""log"…...
docker中的jenkins去配置sonarQube
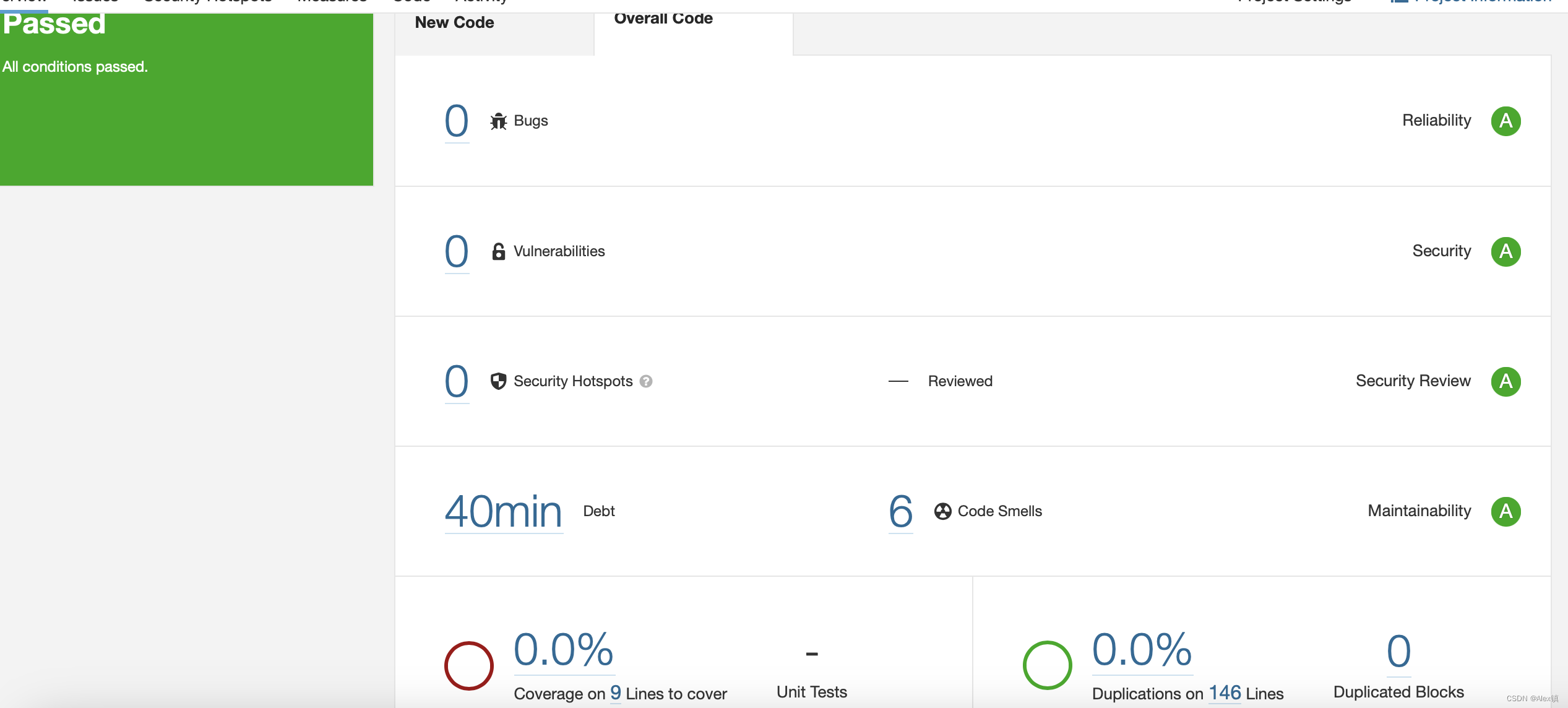
docker中的jenkins去配置sonarQube 1、拉取sonarQube macdeMacBook-Pro:~ mac$ docker pull sonarqube:8.9.6-community 8.9.6-community: Pulling from library/sonarqube 8572bc8fb8a3: Pull complete 702f1610d53e: Pull complete 8c951e69c28d: Pull complete f95e4f8…...

企业如何实现自己的AI垂直大模型
文章目录 为什么要训练垂直大模型训练垂直大模型有许多潜在的好处训练垂直大模型也存在一些挑战 企业如何实现自己的AI垂直大模型1.确定需求2.收集数据3.准备数据4.训练模型5.评估模型6.部署模型 如何高效实现垂直大模型 ✍创作者:全栈弄潮儿 🏡 个人主页…...

Maven可选依赖和排除依赖简单使用
可选依赖 可选依赖指对外隐藏当前所依赖的资源 在maven_04_dao的pom.xml,在引入maven_03_pojo的时候,添加optional <dependency><groupId>com.rqz</groupId><artifactId>maven_03_pojo</artifactId><version>1.0-SNAPSHOT&…...

“深入探索JVM:Java虚拟机的工作原理解析“
标题:深入探索JVM:Java虚拟机的工作原理解析 摘要:本文将深入探索Java虚拟机(JVM)的工作原理,从类加载、内存管理、垃圾回收、即时编译器等方面进行详细解析,帮助读者更好地理解JVM的内部机制。…...

Prometheus-各种exporter
文章目录 一、 nginx-prometheus-exporter1 nginx 配置1.1 Nginx 模块支持1.2 Nginx 配置文件配置2 部署 nginx-prometheus-exporter2.1 二进制方式部署2.1.1 解压部署2.1.2 配置 systemd2.1.3 添加 prometheus 的配置2.1.4 Dashborad2.2 docker-compose 方式部署3 可配置的指标…...
小程序的 weiui的使用以及引入
https://wechat-miniprogram.github.io/weui/docs/quickstart.html 网址 1.点进去,在app.json里面配置 在你需要的 页面的 json里面配置,按需引入 然后看文档,再在你的 wxml里面使用就好了...
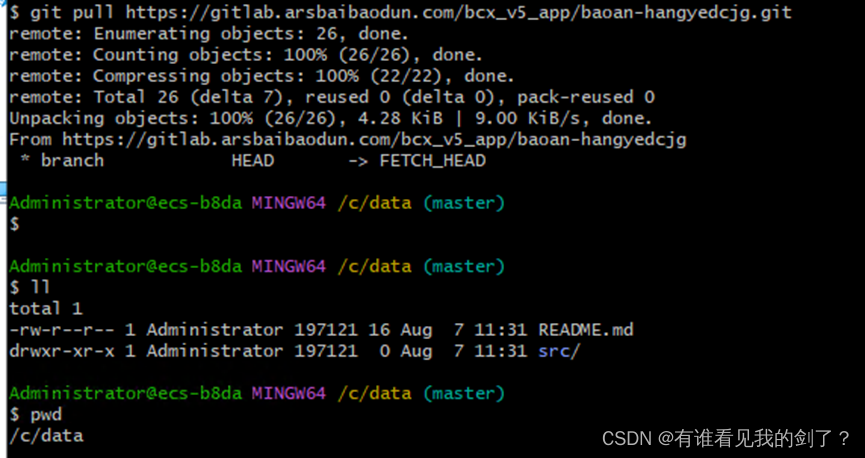
git目录初始化,并拉取最新代码
现有C:\data目录,将目录初始化,并拉取代码在这里插入代码片 https://gitlab.arsbaibaodun.com/bcx_v5_app/baoan-hangyedcjg.git 1、 git init生成 .git 目录即目录初始化完成,可以进行拉取代码 代码成功拉取到了data目录,默认…...
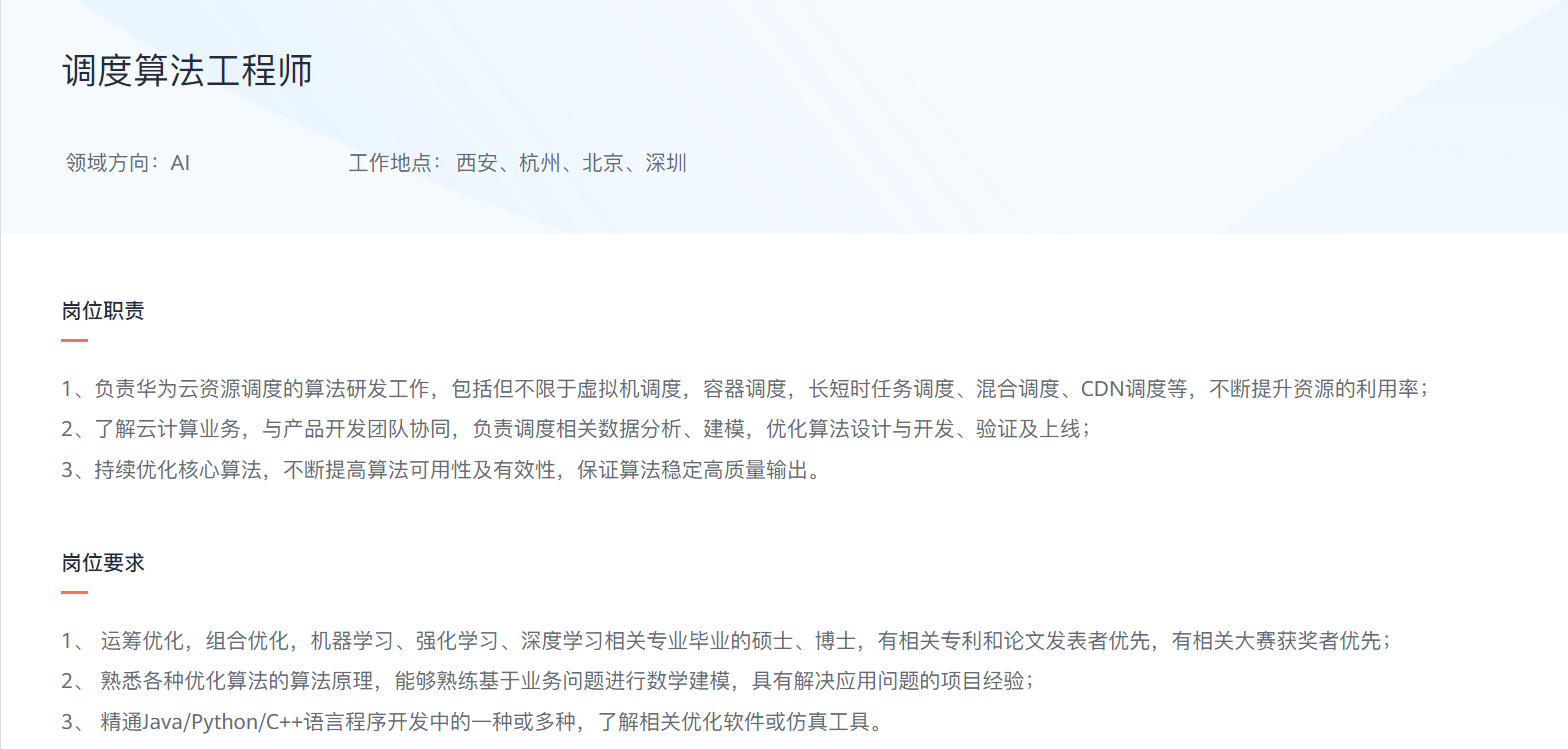
运筹调度算法工程式招聘情况:技能要求、薪资、工作地
目录 一、前言二、岗位信息三、总结 一、前言 前一段时间,常看到运筹学的老师们在朋友圈转发下面的图片。今天忽然想起这件事,顺势查了一下“调度算法工程师”在Boss直聘上的岗位信息,也整理一下招聘企业所需的“调度”技能。 二、岗位信息…...

css2-BFC是什么?
1、BFC是什么? 在页面布局时,经常会出现以下几种情况: 这个元素高度怎末没了? 这两栏布局怎末没法自适应? 这两个元素的间距怎末有点奇怪的样子? … 原因就是元素之间互相影响,导致了意料之外的…...
库操作)
Flutter Dart语言(04)库操作
0 说明 该系列教程主要是为有一定语言基础 C/C的程序员,快速学习一门新语言所采用的方法,属于在C/C基础上扩展新语言的模式。 1 自定义库 & 系统自定义库 引入代码如下所示: import xxx.dart; //自定义库引入,xxx为本…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...