ChatGPT 作为 Python 编程助手
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景
简单的数据处理脚本
我认为一个好的起点是某种数据处理脚本。由于我打算让 ChatGPT 之后使用各种 Python 库编写一些机器学习脚本,这似乎是一个合理的起点。
目标
首先,我想尝试加载数据集;确保所有数据集值都是数值,或将其转换为数值;检查缺失值;并将数据集拆分为训练集和测试集。
提示
编写一个 Python 脚本来执行以下操作:
- 将数据集从磁盘上的 csv 加载到 Pandas 数据帧- 确保数据集完全是数字;将字符串值转换为数字,并在字典中跟踪此转换以供以后
引用 - 检查数据帧中的缺失值,并为具有一个缺失值的任何记录插补缺失值;完全删除具有多个缺失值
的记录 - 将数据集拆分为测试和训练集
回应
import pandas as pd# Load dataset from csv to DataFrame
df = pd.read_csv('dataset.csv')# Initialize dictionary to track string to numeric conversions
conversions = {}# Convert string values to numeric and track conversions in dictionary
for col in df.columns:if df[col].dtype == object:conversions[col] = {val: i for i, val in enumerate(df[col].unique())}df[col] = df[col].map(conversions[col])# Check for missing values
missing_values = df.isna().sum()# Impute missing values for records with one missing value
for col in missing_values[missing_values == 1].index:df[col].fillna(df[col].median(), inplace=True)# Drop records with more than one missing value
df.dropna(thresh=len(df.columns) - 1, inplace=True)# Split dataset into test and training sets
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size=0.2)注意:脚本从csv文件名“dataset.csv”加载数据集,并将数据帧拆分为80/20比率的测试和训练集。如果要使用不同的文件名或比率,请相应地更改路径/比率。
分析之情
ChatGPT生成了一个有用的脚本。它决定了数据集名称以及训练/测试拆分百分比,并记录了这两个点以及如何根据需要更改它们。总的来说,任务完成了。
重构我们的代码
目标
现在我们有一个可以执行某些操作的脚本,让我们稍微重构一下。良好编码的基石是使用函数来逻辑地组织代码,促进重用,并确保您不会重复自己。
提示
重写上面的脚本以使用一系列有意义的函数
回应
import pandas as pd
from sklearn.model_selection import train_test_splitdef load_and_convert_data(file_path):# Load dataset from csv to DataFramedf = pd.read_csv(file_path)# Initialize dictionary to track string to numeric conversionsconversions = {}# Convert string values to numeric and track conversions in dictionaryfor col in df.columns:if df[col].dtype == object:conversions[col] = {val: i for i, val in enumerate(df[col].unique())}df[col] = df[col].map(conversions[col])return df, conversionsdef handle_missing_values(df):# Check for missing valuesmissing_values = df.isna().sum()# Impute missing values for records with one missing valuefor col in missing_values[missing_values == 1].index:df[col].fillna(df[col].median(), inplace=True)# Drop records with more than one missing valuedf.dropna(thresh=len(df.columns) - 1, inplace=True)return dfdef split_data(df, test_size):return train_test_split(df, test_size=test_size)# Use the functions
file_path = "dataset.csv"
df, conversions = load_and_convert_data(file_path)
df = handle_missing_values(df)
train_df, test_df = split_data(df, 0.2)在这里,我使用了三个函数:
1. load_and_convert_data(file_path) 加载 CSV 数据集并将字符串值转换为数字。
2. handle_missing_values(df) 处理数据集中的缺失值。
3. split_data(df,test_size)将数据集拆分为测试和训练集。
主脚本使用这些函数来加载、转换和清理数据集,然后将其拆分为测试和训练集。
数据集的路径和测试比率是这些函数的输入。
分析之情
如果你看一下 ChatGPT 输出的第一个脚本,你可能会看到一些相当明显的线条,你会画出哪些功能将被分成函数。我当然做到了。在这方面,ChatGPT 完全按照我的预期做了。同样,已经生成了一个称职的脚本。
扩展我们的代码
目标
好的,我们的脚本现在看起来好一点,因为它使用了一些函数进行组织。接下来,让我们稍微扩展脚本,以便用户可以在运行脚本时指定一些参数。
提示
重写上述程序,以参数的形式从命令行请求以下内容,并在程序中使用它们:
- 数据集 CSV 文件的
路径/名称 - 训练/测试拆分大小
- 每条记录要丢弃的缺失值数的阈值,之后删除整个记录,而不是插补缺失值
回应
import pandas as pd
import argparse
from sklearn.model_selection import train_test_splitdef load_and_convert_data(file_path):# Load dataset from csv to DataFramedf = pd.read_csv(file_path)# Initialize dictionary to track string to numeric conversionsconversions = {}# Convert string values to numeric and track conversions in dictionaryfor col in df.columns:if df[col].dtype == object:conversions[col] = {val: i for i, val in enumerate(df[col].unique())}df[col] = df[col].map(conversions[col])return df, conversionsdef handle_missing_values(df, threshold):# Check for missing valuesmissing_values = df.isna().sum()# Impute missing values for records with one missing valuefor col in missing_values[missing_values == 1].index:df[col].fillna(df[col].median(), inplace=True)# Drop records with more than threshold missing valuedf.dropna(thresh=len(df.columns) - threshold, inplace=True)return dfdef split_data(df, test_size):return train_test_split(df, test_size=test_size)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument("file_path", help="path/name of the dataset csv file")parser.add_argument("test_size", help="train/test split size", type=float)parser.add_argument("threshold", help="threshold for the number of missing values per record", type=int)args = parser.parse_args()# Use the functionsdf, conversions = load_and_convert_data(args.file_path)df = handle_missing_values(df, args.threshold)train_df, test_df = split_data(df, args.test_size)在此版本中,我使用 argparse 模块将文件路径、测试/训练拆分大小和每条记录缺失值数的阈值的输入作为命令行参数。用户必须使用正确的参数运行脚本,例如:
python script.py dataset.csv 0.2 1
这将使用“dataset.csv”文件运行脚本,test_size为 0.2,缺失值的阈值为 1。
主脚本在函数中使用这些参数来加载、转换和清理数据集,然后将其拆分为测试和训练集。
还值得一提的是,运行脚本时,应从命令行运行脚本,而不是从 IDE 运行脚本。
分析之情
老实说,这里不需要太多分析,因为 ChatGPT 解释了它做得很好的地方。我实际上会在这里注意到一些我以前没有的东西,并拍拍 ChatGPT 的后背,因为它的评论富有表现力和简洁。
将我们的代码转换为流光应用程序
目标
现在,假设我们想使这段代码“生产”准备就绪(幽默我)。让我们让 ChatGPT 将这些功能包装在 Streamlit 应用程序中。
提示
将上述程序重写为 Streamlit 应用程序,允许用户提供与上述命令行参数相同的参数
回应
import pandas as pd
import streamlit as st
from sklearn.model_selection import train_test_splitdef load_and_convert_data(file_path):# Load dataset from csv to DataFramedf = pd.read_csv(file_path)# Initialize dictionary to track string to numeric conversionsconversions = {}# Convert string values to numeric and track conversions in dictionaryfor col in df.columns:if df[col].dtype == object:conversions[col] = {val: i for i, val in enumerate(df[col].unique())}df[col] = df[col].map(conversions[col])return df, conversionsdef handle_missing_values(df, threshold):# Check for missing valuesmissing_values = df.isna().sum()# Impute missing values for records with one missing valuefor col in missing_values[missing_values == 1].index:df[col].fillna(df[col].median(), inplace=True)# Drop records with more than threshold missing valuedf.dropna(thresh=len(df.columns) - threshold, inplace=True)return dfdef split_data(df, test_size):return train_test_split(df, test_size=test_size)def main():st.set_page_config(page_title="Data Preprocessing", page_icon=":guardsman:", layout="wide")st.title("Data Preprocessing")file_path = st.text_input("Enter the path/name of the dataset csv file: ")test_size = st.number_input("Enter the train/test split size (decimal between 0 and 1): ", step=0.01, value=0.2)threshold = st.number_input("Enter the threshold for the number of missing values per record: ", step=1, value=1)if st.button("Process Data"):df, conversions = load_and_convert_data(file_path)df = handle_missing_values(df, threshold)train_df, test_df = split_data(df, test_size)st.success("Data preprocessing completed!")if __name__ == '__main__':main()此版本是一个 Streamlit 应用,允许用户提供与命令行参数相同的参数。它使用 Streamlit 库创建一个交互式 Web 应用,允许用户输入文件路径、测试/训练拆分大小和每条记录缺失值数的阈值。然后,用户可以单击“处理数据”按钮来运行脚本并预处理数据。它使用与以前版本的脚本相同的函数来加载、转换和清理数据集,然后将其拆分为测试和训练集。
要运行脚本,您需要安装 Streamlit,您可以在终端中运行命令 pip install streamlit。安装后,使用命令运行脚本。streamlit run script.py
分析之情
它做了它应该做的事情。ChatGPT采取了我们的功能...函数,并用它们构建了一个简单的 Streamlit 网络应用程序。

使用 ChatGPT 生成的脚本创建的 Streamlit Web 应用程序
总结
ChatGPT 在创建、重构、扩展和添加一个简单的数据预处理 Python 脚本的包装器方面做得非常称职,我们希望它根据我们提供的规范为我们编写。虽然它不是最复杂的程序,但它是朝着让 ChatGPT 作为编程助手真正有用的方向迈出的一步。结果在每一步都达到了目标。
下一次,我们将构建一个不太简单的程序,增加一些复杂性和额外的要求。我很高兴看到ChatGPT在压力下的表现如何。希望你也是。
原文链接:ChatGPT 作为 Python 编程助手 (mvrlink.com)
相关文章:
ChatGPT 作为 Python 编程助手
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景 简单的数据处理脚本 我认为一个好的起点是某种数据处理脚本。由于我打算让 ChatGPT 之后使用各种 Python 库编写一些机器学习脚本,这似乎是一个合理的起点。 目标 首先,我想尝试…...

饿了么输入框限制只能输入数字,并且保留小数
可以使用饿了么ui中的input-number组件实现输入框只能输入数字,这样就不能输入数字以外的,controls隐藏输入框左右俩边的加减按钮,precision小数点保留多少位,2则是俩位,但是会导致默认值为0.00的情况,俩种…...

kylin-Desktop gsettings 获取或设置系统配置
gsettings提供了对GSetings的命令行操作。GSetings实际上是一套高级API,用来操作dconf。 dconf存储着GNOME3的配置,是二进制格式。它做为GSettings的后端系统存在,暴露出低级API。在GNOME2时代,类似的角色是gconf,但它是以XML文本形式存储。 更接地气的说法是,dconf是G…...

setmap使用
目录 set使用 set的模板参数 构造函数 成员函数 insert iterator 编辑 find count pair pair 的模板参数 make_pair multiset使用 multiset 的模板参数 set 与 multiset 的区别 count map使用 map 的模板参数 构造函数 insert iterator find 编辑 cou…...

Python3 网络爬虫开发实战
JavaScript逆向爬虫 JavaScript接口加密技术,JavaScript有以下两个特点: JS代码运行在客户端,所以它必须在用户浏览器加载并运行JS代码公开透明,所以浏览器可以直接获取到正在运行的JS源码。 所以JS代码不安全,任何…...

docker: CMD和ENTRYPOINT的区别
ENTRYPOINT: 容器的执行命令(属于正统命令) 可以使用--build-arg ENVIROMENTintegration参数覆盖 ocker build --build-arg ENVIROMENTintegration 两者同时存在时 CMD作为ENTRYPOINT的默认参数使用外部提供参数会覆盖CMD提供的参数。 CMD单…...

DC电源模块对于定制的要求主要有这几点
BOSHIDA DC电源模块对于定制的要求主要有这几点 DC电源模块是一种将交流电转换成为稳定的直流电的装置。在现代工业生产中,DC电源模块被广泛应用于各种电子设备中,例如计算机、手机、电视等。为了满足不同用户需求,DC电源模块的定制需求也是…...

Kubernetes高可用集群二进制部署(六)Kubernetes集群节点添加
Kubernetes概述 使用kubeadm快速部署一个k8s集群 Kubernetes高可用集群二进制部署(一)主机准备和负载均衡器安装 Kubernetes高可用集群二进制部署(二)ETCD集群部署 Kubernetes高可用集群二进制部署(三)部署…...
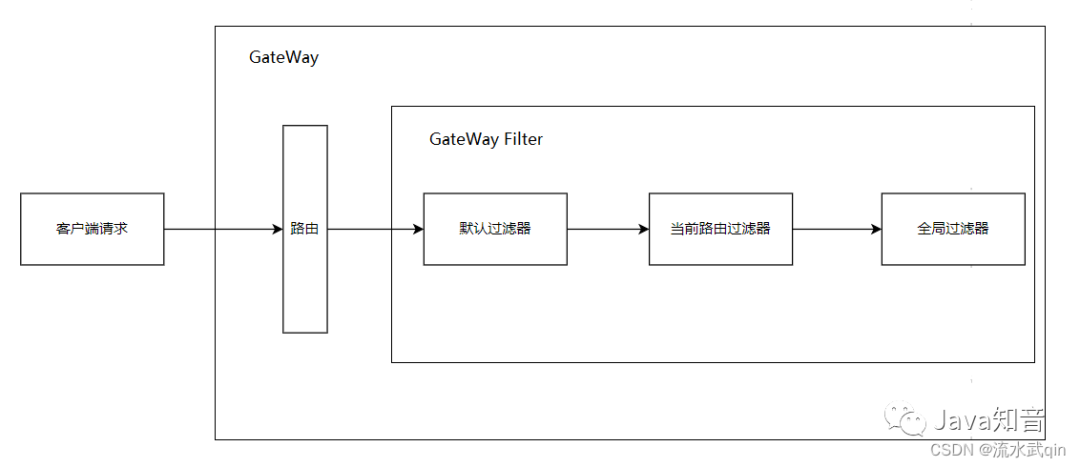
网关 GateWay 的使用详解、路由、过滤器、跨域配置
一、网关的基本概念 SpringCloudGateway网关是所有微服务的统一入口。 1.1 它的主要作用是: 反向代理(请求的转发) 路由和负载均衡 身份认证和权限控制 对请求限流 1.2 相比于Zuul的优势: SpringCloudGateway基于Spring5中…...

vsocde里面远程连接服务器报could not esatablish connection xxxx
我在vscode里面远程连接服务器编辑代码时,正常我按F1选择了服务器IP地址,然后让我选在Linux,然后我再输入服务器密码,但是当我选择Linux系统之后直接没出让我输入服务器密码的输入框,而是直接报错 could not esatablis…...

Hi3798MV200 恩兔N2 NS-1 (二): HiNAS海纳思使用和修改
目录 Hi3798MV200 恩兔N2 NS-1 (一): 设备介绍和刷机说明Hi3798MV200 恩兔N2 NS-1 (二): HiNAS海纳思使用和修改Hi3798MV200 恩兔N2 NS-1 (三): 制作 Ubuntu rootfsHi3798MV200 恩兔N2 NS-1 (四): 制作 Debian rootfs 关于 海纳思全称是海思机顶盒NAS系统, 网站 https://www…...

无涯教程-Perl - foreach 语句函数
foreach 循环遍历列表值,并将控制变量(var)依次设置为列表的每个元素- foreach - 语法 Perl编程语言中的 foreach 循环的语法是- foreach var (list) { ... } foreach - 流程图 foreach - 示例 #!/usr/local/bin/perllist(2, 20, 30, 40, 50);# foreach loop ex…...

easyWechat 5.x 复写代码 获取企业微信授权用户敏感信息
复写 (new SocialiteManager($config))->extend(wework, function ($config) {return new \App\Extend\EasyWechat\Work\WeWork($config);});创建的 \App\Extend\EasyWechat\Work\WeWork是我们需要复写的类 <?phpnamespace App\Extend\EasyWechat\Work;use Overtrue\So…...
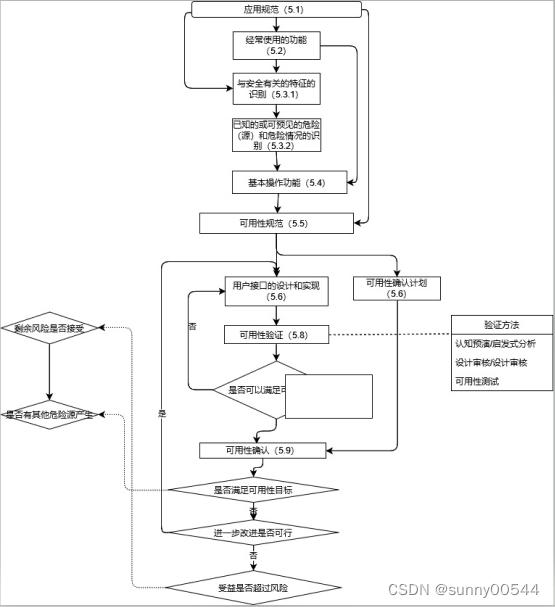
医疗器械研发中的可用性工程实践(一)
致读者:以前看《楚门的世界》,《蝴蝶效应》,《肖申克的救赎》,《教父》,《横道世之介》,《老友记》,一个人的一生匆匆。作为平凡人就是历史大河中的浪花,顺势而为,起起伏…...

LNMP搭建
LNMP:目前成熟的企业网站的应用模式之一,指的是一套协同工作的系统和相关软件 能够提供静态页面服务,也可以提供动态web服务。 这是一个缩写 L linux系统,操作系统。 N nginx网站服务,也可也理解为前端,…...

软件测试分类总结
目录 1.根据源代码可见度划分 1.1黑盒测试 1.2白盒测试 1.3灰盒测试 2.根据开发阶段划分 2.1单元测试 2.2集成测试 2.3系统测试 2.4验收测试 3.按照实施组织划分 3.1α测试 3.2β测试 3.3第三方测试 4.按照是否运行程序划分 4.1静态测试 4.2动态测试 5.根据软件测试工作的…...
模糊PID(三角隶属度函数模糊化CODESYS ST代码)
三角隶属度函数的详细算法介绍,之前的专栏有详细介绍,这里不再展开讨论。相关文章链接如下: 博途三角隶属度函数FC 博途PLC模糊PID三角隶属度函数指令(含Matlab仿真)_博图模糊pid控制_RXXW_Dor的博客-CSDN博客三角隶属度函数FC,我们采用兼容C99标准的函数返回值写法,在…...

探索人工智能 | 计算机视觉 让计算机打开新灵之窗
前言 计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。 文章目录 前言…...
7.物联网操作系统互斥信号量
1.使用互斥信号量解决信号量导致的优先级反转, 2.使用递归互斥信号量解决互斥信号量导致的死锁。 3.高优先级主函数中多次使用同一信号量的使用,使用递归互斥信号量,但要注意每个信号量的使用要对应一个释放 优先级翻转问题 优先级翻转功能需…...

Vue - Element el-form 表单对象多层嵌套校验
针对el-form的数据源是对象嵌套对象,在进行数据绑定和校验时和单层的对象有一点区别, 具体是下面两部分: 数据源: fromData: {name: ,health: {height: } }1、 给 el-form-item 的 prop设为:prop"health.height&…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

JavaScript语言精粹第三章解读 | 吃透JS对象核心!告别90%日常开发对象Bug
前言 最近重读《JavaScript语言精粹》,复盘JS对象基础的时候,我真的发现了自己多年的编码陋习。 写了好几年前端,每天都在和对象打交道:接口回参解析、页面状态存储、配置项封装,全是{},看似简单到不值一…...

AhMyth混淆技术:Android RAT的APK反编译保护与代码混淆全指南
AhMyth混淆技术:Android RAT的APK反编译保护与代码混淆全指南 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhM…...

后端开发者体验 AI 前端:用 TinyVue 做一个智能业务表单 Demo
摘要 作为 Java 后端开发者,我平时更多关注接口、SQL 和业务逻辑,但后台系统里也绕不开表单、列表和报表页面。本文结合 OpenTiny NEXT 学习体验,用 TinyVue 做一个智能业务表单 Demo,聊聊 AI 前端对后端开发者到底有没有实际帮助…...