【大数据】Flink 详解(一):基础篇
Flink 详解(一):基础篇
1、什么是 Flink ?

Flink 是一个以 流 为核心的高可用、高性能的分布式计算引擎。具备 流批一体,高吞吐、低延迟,容错能力,大规模复杂计算等特点,在数据流上提供 数据分发、通信等功能。
2、能否详细解释一下其中的 数据流、流批一体、容错能力 等概念?
数据流:所有产生的 数据 都天然带有 时间概念,把 事件 按照时间顺序排列起来,就形成了一个事件流,也被称作数据流。
流批一体:
首先必须先明白什么是 有界数据 和 无界数据:

- 有界数据:就是在一个确定的时间范围内的数据流,有开始,有结束,一旦确定就不会再改变,一般 批处理 用来处理有界数据,如上图的
bounded stream。 - 无界数据:就是持续产生的数据流,数据是无限的,有开始,无结束,一般 流处理 用来处理无界数据。如图
unbounded stream。
Flink 的设计思想是以 流 为核心,批是流的特例,擅长处理 无界 和 有界 数据, Flink 提供 精确的时间控制能力 和 有状态 计算机制,可以轻松应对无界数据流,同时提供 窗口 处理有界数据流。所以被成为流批一体。
容错能力:在分布式系统中,硬件故障、进程异常、应用异常、网络故障等异常无处不在,Flink 引擎必须保证故障发生后 不仅可以 重启应用程序,还要 确保其内部状态保持一致,从最后一次正确的时间点重新出发。
Flink 提供 集群级容错 和 应用级容错 能力:
- 集群级容错: Flink 与 集群管理器 紧密连接,如 YARN、Kubernetes,当进程挂掉后,自动重启新进程接管之前的工作。同时具备 高可用性 ,可消除所有单点故障,
- 应用级容错:Flink 使用 轻量级分布式快照,设计检查点(
checkpoint)实现可靠容错。
Flink 利用检查点特性,在框架层面提供 Exactly-once 语义,即端到端的一致性,确保数据仅处理一次,不会重复也不会丢失,即使出现故障,也能保证数据只写一次。
3、Flink 和 Spark Streaming 的区别?
Flink 和 Spark Sreaming 最大的区别在于:Flink 是标准的实时处理引擎,基于事件驱动,以流为核心;而 Spark Streaming 的 RDD 实际是一组小批次的 RDD 集合,是微批(Micro-Batch)的模型,以批为核心。
下面我们介绍两个框架的主要区别:
1.架构模型
Spark Streaming 在运行时的主要角色包括:
- 服务架构集群和资源管理 Master / Yarn Application Master;
- 工作节点 Work / Node Manager;
- 任务调度器
Driver;任务执行器Executor。

Flink 在运行时主要包含:客户端 Client、作业管理 Jobmanager、任务管理 Taskmanager。

2. 任务调度
Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图 DAG,Spark Streaming 会依次创建 DStreamGraph、JobScheduler。

Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度,根据物理执行图部署到Taskmanager上形成具体的 Task 执行。

3. 时间机制
Spark Streaming 支持的时间机制有限,只支持 处理时间。
Flink 支持了流处理程序在时间上的三个定义:事件时间 EventTime、摄入时间 IngestionTime 、处理时间 ProcessingTime。同时也支持 watermark 机制来处理滞后数据。

4. 容错机制
- 对于 Spark Streaming 任务,我们可以设置
checkpoint,然后假如发生故障并重启,我们可以从上次checkpoint之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。 - Flink 则使用 两阶段提交协议 来解决这个问题。
4、Flink 的架构包含哪些?
Flink 架构分为 技术架构 和 运行架构 两部分。
5、简单介绍一下 Flink 的技术架构。
如下图为 Flink 技术架构:

Flink 作为流批一体的分布式计算引擎,必须提供面向开发人员的 API 层,同时还需要跟外部数据存储进行交互,需要 连接器,作业开发、测试完毕后,需要提交集群执行,需要 部署层,同时还需要运维人员能够管理和监控,还提供图计算、机器学习、SQL 等,需要 应用框架层。
6、详细介绍一下 Flink 的运行架构。
如下图为 Flink 运行架构:

Flink 集群采取 Master - Slave 架构,Master 的角色为 JobManager,负责集群和作业管理,Slave 的角色是 TaskManager,负责执行计算任务,同时,Flink 提供客户端 Client 来管理集群和提交任务,JobManager 和 TaskManager 是集群的进程。
- Client:Flink 客户端是 Flink 提供的 CLI 命令行工具,用来提交 Flink 作业到 Flink 集群,在客户端中负责 StreamGraph(流图)和 JobGraph(作业图)的构建。
- JobManager:JobManager 根据并行度将 Flink 客户端提交的 Flink 应用分解为子任务,从资源管理器 ResourceManager 申请所需的计算资源,资源具备之后,开始分发任务到 TaskManager 执行 Task,并负责应用容错,跟踪作业的执行状态,发现异常则恢复作业等。
- TaskManager:TaskManager 接收 JobManage 分发的子任务,根据自身的资源情况 管理子任务的启动、 停止、销毁、异常恢复等生命周期阶段。Flink 程序中必须有一个 TaskManager。
7、介绍一下 Flink 的并行度。
Flink 程序在执行的时候,会被映射成一个 Streaming Dataflow。一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成的。在启动时从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
Flink 程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个 operator 包含一个或多个 operator 子任务。操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。
operator 子任务的数量是这一特定 operator 的并行度。相同程序中的不同 operator 有不同级别的并行度。

一个 Stream 可以被分成多个 Stream 的分区,也就是 Stream Partition。一个 Operator 也可以被分为多个 Operator Subtask。如上图中,Source 被分成 Source1 和 Source2,它们分别为 Source 的 Operator Subtask。每一个 Operator Subtask 都是在不同的线程当中独立执行的。一个 Operator 的并行度,就等于 Operator Subtask 的个数。
上图 Source 的并行度为 2 2 2。而一个 Stream 的并行度就等于它生成的 Operator 的并行度。数据在两个 operator 之间传递的时候有两种模式:
- One to One 模式:两个 operator 用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的 Source1 到 Map1,它就保留的 Source 的分区特性,以及分区元素处理的有序性。
- Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个 operator subtask 会根据选择 transformation 把数据发送到不同的目标 subtasks,比如
keyBy()会通过 hashcode 重新分区,broadcast()和rebalance()方法会随机重新分区。
8、Flink 的并行度的怎么设置的?
我们在实际生产环境中可以从四个不同层面设置并行度:
- 操作算子层面(
Operator Level) - 执行环境层面(
Execution Environment Level) - 客户端层面(
Client Level) - 系统层面(
System Level)
需要注意的优先级:算子层面 > 环境层面 > 客户端层面 > 系统层面。
9、Flink 编程模型了解不?
Flink 应用程序主要由三部分组成,源 source、转换 transformation、目的地 sink。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个目的地(sink)结束。


10、Flink 作业中的 DataStream,Transformation 介绍一下?
Flink 作业中,包含两个基本的块:数据流(DataStream)和 转换(Transformation)。
DataStream 是逻辑概念,为开发者提供 API 接口,Transformation 是处理行为的抽象,包含了数据的读取、计算、写出。所以 Flink 作业中的 DataStream API 调用,实际上构建了多个由 Transformation 组成的数据处理流水线(Pipeline)。
DataStream API 和 Transformation 的转换如下图:

11、Flink 的分区策略了解吗?
数据分区 在 Flink 中叫作 Partition。本质上来说,分布式计算就是把 一个作业 切分成子任务 Task, 将不同的数据交给不同的 Task 计算。
在分布式存储中, Partition 分区的概念就是把数据集切分成块,每一块数据存储在不同的机器上。同样 ,对于分布式计算引擎,也需要将数据切分,交给位于不同物理节点上的 Task 计算。
StreamPartitioner 是 Flink 中的数据流分区抽象接口,决定了在实际运行中的数据流分发模式, 将数据切分交给 Task 计算,每个 Task 负责计算一部分数据流。所有的数据分区器都实现了ChannelSelector 接口,该接口中定义了负载均衡选择行为。
// ChannelSelector 接口定义
public interfaceChannelSelector<T extends IOReadablewritable> { //下游可选 Channel 的数量void setup (intnumberOfChannels); //选路方法int selectChannel (T record); //是否向下游广播boolean isBroadcast();}
在该接口中可以看到,每一个分区器都知道下游通道数量,该通道在一次作业运行中是固定的,除非修改作业的并行度,否则该值不会改变。
目前 Flink 支持 8 8 8 种分区策略的实现,数据分区体系如下图:

(1)GlobalPartitioner
数据会被分发到下游算子的第一个实例中进行处理。
(2)ForwardPartitioner
在 API 层面上 ForwardPartitioner 应用在 DataStream 上,生成一个新的 DataStream。
该 Partitioner 比较特殊,用于在同一个 OperatorChain 中上下游算子之间的数据转发,实际上数据是直接传递给下游的,要求上下游并行度一样。
(3)ShufflePartitioner
随机的将元素进行分区,可以确保下游的 Task 能够均匀地获得数据,使用代码如下:
dataStream.shuffle();
(4)RebalancePartitioner
以 Round-robin 的方式为每个元素分配分区,确保下游的 Task 可以均匀地获得数据,避免数据倾斜。使用代码如下:
dataStream.rebalance();
(5)RescalePartitioner
根据上下游 Task 的数量进行分区, 使用 Round-robin 选择下游的一个Task 进行数据分区,如上游有 2 2 2 个 Source.,下游有 6 6 6 个 Map,那么每个 Source 会分配 3 3 3 个固定的下游 Map,不会向未分配给自己的分区写入数据。这一点与 ShufflePartitioner 和 RebalancePartitioner 不同, 后两者会写入下游所有的分区。

运行代码如下:
dataStream.rescale();
(6)BroadcastPartitioner
将该记录广播给所有分区,即有 N N N 个分区,就把数据复制 N N N 份,每个分区 1 1 1 份,其使用代码如下:
dataStream.broadcast();
(7)KeyGroupStreamPartitioner
在 API 层面上,KeyGroupStreamPartitioner 应用在 KeyedStream上,生成一个新的 KeyedStream。
KeyedStream 根据 keyGroup 索引编号进行分区,会将数据按 Key 的 Hash 值输出到下游算子实例中。该分区器不是提供给用户来用的。
KeyedStream 在构造 Transformation 的时候默认使用 KeyedGroup 分区形式,从而在底层上支持作业 Rescale 功能。
(8)CustomPartitionerWrapper
用户自定义分区器。需要用户自己实现 Partitioner 接口,来定义自己的分区逻辑。
static class CustomPartitioner implements Partitioner<String> {@Overridepublic int partition(String key, int numPartitions) {switch (key){case "1":return 1;case "2":return 2;case "3":return 3;default:return 4;}}}
12、描述一下 Flink Wordcount 执行包含的步骤有哪些?
主要包含以下几步:
- 获取运行环境 StreamExecutionEnvironment;
- 接入 source 源 ;
- 执行转换操作,如
map()、flatmap()、keyby()、sum(); - 输出 sink 源,如 print();
- 执行 execute。
提供一个示例:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;public class WordCount {public static void main(String[] args) throws Exception {//定义socket的端口号int port;try{ParameterTool parameterTool = ParameterTool.fromArgs(args);port = parameterTool.getInt("port");}catch (Exception e){System.err.println("没有指定port参数,使用默认值9000");port = 9000;}//获取运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//连接socket获取输入的数据DataStreamSource<String> text = env.socketTextStream("10.192.12.106", port, "\n");//计算数据DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {public void flatMap(String value, Collector<WordWithCount> out) throws Exception {String[] splits = value.split("\\s");for (String word:splits) {out.collect(new WordWithCount(word,1L));}}})//打平操作,把每行的单词转为<word,count>类型的数据.keyBy("word")//针对相同的word数据进行分组.timeWindow(Time.seconds(2),Time.seconds(1))//指定计算数据的窗口大小和滑动窗口大小.sum("count");//把数据打印到控制台windowCount.print().setParallelism(1);//使用一个并行度// 注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行env.execute("streaming word count");}/*** 主要为了存储单词以及单词出现的次数*/public static class WordWithCount{public String word;public long count;public WordWithCount(){}public WordWithCount(String word, long count) {this.word = word;this.count = count;}@Overridepublic String toString() {return "WordWithCount{" + "word='" + word + '\'' +", count=" + count +'}';}}
}
13、Flink 常用的算子有哪些?
分两部分:
(1)数据读取,这是 Flink 流计算应用的起点,常用算子有:
- 从内存读:
fromElements - 从文件读:
readTextFile - Socket 接入 :
socketTextStream - 自定义读取:
createInput
(2)处理数据的算子,主要用于 转换 过程,常用的算子包括:
- 单输入单输出:
Map - 单输入、多输出:
FlatMap - 过滤:
Filter - 分组:
KeyBy - 聚合:
Reduce - 窗口:
Window - 连接:
Connect - 分割:
Split
【1】Apache Flink - 数据流上的有状态计算:https://flink.apache.org/zh/
【2】Apache Flink 文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/
【3】Flink大全 - 洋群满满のBlog
【4】史上最全干货!Flink面试大全总结
相关文章:
【大数据】Flink 详解(一):基础篇
Flink 详解(一):基础篇 1、什么是 Flink ? Flink 是一个以 流 为核心的高可用、高性能的分布式计算引擎。具备 流批一体,高吞吐、低延迟,容错能力,大规模复杂计算等特点,在数据流上提…...

ChatGPT 作为 Python 编程助手
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景 简单的数据处理脚本 我认为一个好的起点是某种数据处理脚本。由于我打算让 ChatGPT 之后使用各种 Python 库编写一些机器学习脚本,这似乎是一个合理的起点。 目标 首先,我想尝试…...

饿了么输入框限制只能输入数字,并且保留小数
可以使用饿了么ui中的input-number组件实现输入框只能输入数字,这样就不能输入数字以外的,controls隐藏输入框左右俩边的加减按钮,precision小数点保留多少位,2则是俩位,但是会导致默认值为0.00的情况,俩种…...

kylin-Desktop gsettings 获取或设置系统配置
gsettings提供了对GSetings的命令行操作。GSetings实际上是一套高级API,用来操作dconf。 dconf存储着GNOME3的配置,是二进制格式。它做为GSettings的后端系统存在,暴露出低级API。在GNOME2时代,类似的角色是gconf,但它是以XML文本形式存储。 更接地气的说法是,dconf是G…...

setmap使用
目录 set使用 set的模板参数 构造函数 成员函数 insert iterator 编辑 find count pair pair 的模板参数 make_pair multiset使用 multiset 的模板参数 set 与 multiset 的区别 count map使用 map 的模板参数 构造函数 insert iterator find 编辑 cou…...

Python3 网络爬虫开发实战
JavaScript逆向爬虫 JavaScript接口加密技术,JavaScript有以下两个特点: JS代码运行在客户端,所以它必须在用户浏览器加载并运行JS代码公开透明,所以浏览器可以直接获取到正在运行的JS源码。 所以JS代码不安全,任何…...

docker: CMD和ENTRYPOINT的区别
ENTRYPOINT: 容器的执行命令(属于正统命令) 可以使用--build-arg ENVIROMENTintegration参数覆盖 ocker build --build-arg ENVIROMENTintegration 两者同时存在时 CMD作为ENTRYPOINT的默认参数使用外部提供参数会覆盖CMD提供的参数。 CMD单…...

DC电源模块对于定制的要求主要有这几点
BOSHIDA DC电源模块对于定制的要求主要有这几点 DC电源模块是一种将交流电转换成为稳定的直流电的装置。在现代工业生产中,DC电源模块被广泛应用于各种电子设备中,例如计算机、手机、电视等。为了满足不同用户需求,DC电源模块的定制需求也是…...

Kubernetes高可用集群二进制部署(六)Kubernetes集群节点添加
Kubernetes概述 使用kubeadm快速部署一个k8s集群 Kubernetes高可用集群二进制部署(一)主机准备和负载均衡器安装 Kubernetes高可用集群二进制部署(二)ETCD集群部署 Kubernetes高可用集群二进制部署(三)部署…...
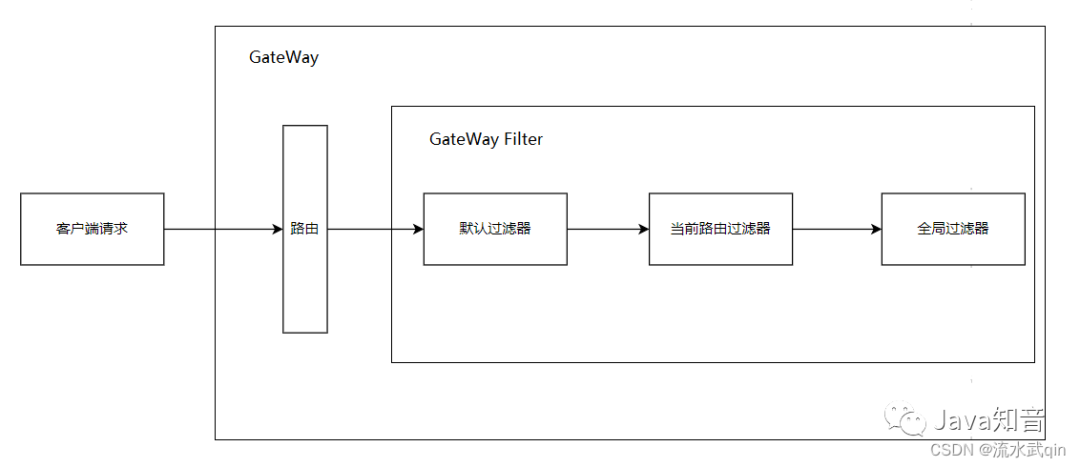
网关 GateWay 的使用详解、路由、过滤器、跨域配置
一、网关的基本概念 SpringCloudGateway网关是所有微服务的统一入口。 1.1 它的主要作用是: 反向代理(请求的转发) 路由和负载均衡 身份认证和权限控制 对请求限流 1.2 相比于Zuul的优势: SpringCloudGateway基于Spring5中…...

vsocde里面远程连接服务器报could not esatablish connection xxxx
我在vscode里面远程连接服务器编辑代码时,正常我按F1选择了服务器IP地址,然后让我选在Linux,然后我再输入服务器密码,但是当我选择Linux系统之后直接没出让我输入服务器密码的输入框,而是直接报错 could not esatablis…...

Hi3798MV200 恩兔N2 NS-1 (二): HiNAS海纳思使用和修改
目录 Hi3798MV200 恩兔N2 NS-1 (一): 设备介绍和刷机说明Hi3798MV200 恩兔N2 NS-1 (二): HiNAS海纳思使用和修改Hi3798MV200 恩兔N2 NS-1 (三): 制作 Ubuntu rootfsHi3798MV200 恩兔N2 NS-1 (四): 制作 Debian rootfs 关于 海纳思全称是海思机顶盒NAS系统, 网站 https://www…...

无涯教程-Perl - foreach 语句函数
foreach 循环遍历列表值,并将控制变量(var)依次设置为列表的每个元素- foreach - 语法 Perl编程语言中的 foreach 循环的语法是- foreach var (list) { ... } foreach - 流程图 foreach - 示例 #!/usr/local/bin/perllist(2, 20, 30, 40, 50);# foreach loop ex…...

easyWechat 5.x 复写代码 获取企业微信授权用户敏感信息
复写 (new SocialiteManager($config))->extend(wework, function ($config) {return new \App\Extend\EasyWechat\Work\WeWork($config);});创建的 \App\Extend\EasyWechat\Work\WeWork是我们需要复写的类 <?phpnamespace App\Extend\EasyWechat\Work;use Overtrue\So…...
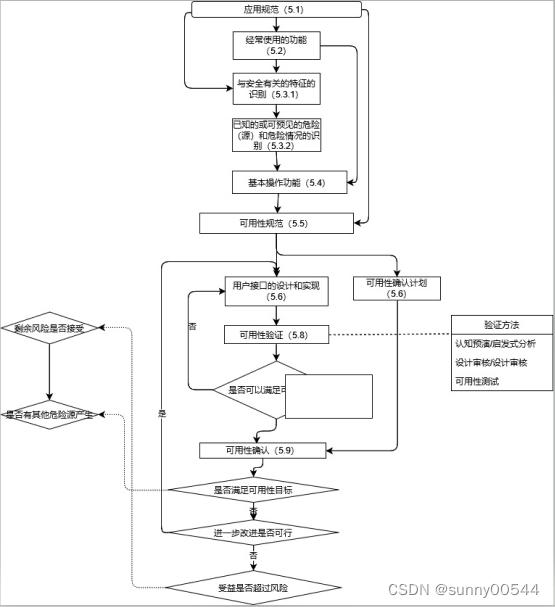
医疗器械研发中的可用性工程实践(一)
致读者:以前看《楚门的世界》,《蝴蝶效应》,《肖申克的救赎》,《教父》,《横道世之介》,《老友记》,一个人的一生匆匆。作为平凡人就是历史大河中的浪花,顺势而为,起起伏…...

LNMP搭建
LNMP:目前成熟的企业网站的应用模式之一,指的是一套协同工作的系统和相关软件 能够提供静态页面服务,也可以提供动态web服务。 这是一个缩写 L linux系统,操作系统。 N nginx网站服务,也可也理解为前端,…...

软件测试分类总结
目录 1.根据源代码可见度划分 1.1黑盒测试 1.2白盒测试 1.3灰盒测试 2.根据开发阶段划分 2.1单元测试 2.2集成测试 2.3系统测试 2.4验收测试 3.按照实施组织划分 3.1α测试 3.2β测试 3.3第三方测试 4.按照是否运行程序划分 4.1静态测试 4.2动态测试 5.根据软件测试工作的…...
模糊PID(三角隶属度函数模糊化CODESYS ST代码)
三角隶属度函数的详细算法介绍,之前的专栏有详细介绍,这里不再展开讨论。相关文章链接如下: 博途三角隶属度函数FC 博途PLC模糊PID三角隶属度函数指令(含Matlab仿真)_博图模糊pid控制_RXXW_Dor的博客-CSDN博客三角隶属度函数FC,我们采用兼容C99标准的函数返回值写法,在…...

探索人工智能 | 计算机视觉 让计算机打开新灵之窗
前言 计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。 文章目录 前言…...
7.物联网操作系统互斥信号量
1.使用互斥信号量解决信号量导致的优先级反转, 2.使用递归互斥信号量解决互斥信号量导致的死锁。 3.高优先级主函数中多次使用同一信号量的使用,使用递归互斥信号量,但要注意每个信号量的使用要对应一个释放 优先级翻转问题 优先级翻转功能需…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...