mysql高级三:sql性能优化+索引优化+慢查询日志
内容介绍
单表索引失效案例
| 0、思考题:如果把100万数据插入MYSQL ,如何提高插入效率 (1)关闭自动提交,只手动提交一次 (2)删除除主键索引外其他索引 (3)拼写mysql可以执行的长sql,批量插入数据 (4)使用java多线程 (5)使用框架,设置属性,实现批量插入 1、计算、函数导致索引失效 CREATE INDEX idx_name ON emp (NAME); EXPLAIN SELECT * FROM emp WHERE emp.name LIKE 'abc%'; EXPLAIN SELECT * FROM emp WHERE LEFT(emp.name,3) = 'abc'; ----索引失效 2 LIKE以%开头索引失效 EXPLAIN SELECT * FROM emp WHERE NAME LIKE '%ab%'; ----索引失效 3、不等于(!= 或者<>)索引失效 EXPLAIN SELECT * FROM emp WHERE emp.name = 'abc' ; EXPLAIN SELECT * FROM emp WHERE emp.name <> 'abc' ; ----索引失效 4、IS NOT NULL 和 IS NULL EXPLAIN SELECT * FROM emp WHERE emp.name IS NULL; EXPLAIN SELECT * FROM emp WHERE emp.name IS NOT NULL; ----索引失效 5、类型转换导致索引失效 EXPLAIN SELECT * FROM emp WHERE NAME='123'; EXPLAIN SELECT * FROM emp WHERE NAME= 123; ----索引失效 6、全值匹配我最爱 EXPLAIN SELECT * FROM emp WHERE emp.age = 30 AND deptid = 4 AND emp.name = 'abcd'; CREATE INDEX idx_age ON emp(age); CREATE INDEX idx_age_deptid ON emp(age,deptid); CREATE INDEX idx_age_deptid_name ON emp(age,deptid,`name`); 7、最佳左前缀法则 EXPLAIN SELECT * FROM emp WHERE emp.age=30 AND emp.name = 'abcd' ; CREATE INDEX idx_age_name ON emp (age,NAME); EXPLAIN SELECT * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd'; EXPLAIN SELECT * FROM emp WHERE emp.age = 30 AND emp.deptid=1 AND emp.name = 'abcd'; CREATE INDEX idx_age_deptid_name ON emp(age,deptid,`name`); EXPLAIN SELECT * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd' AND emp.age = 30; 8、索引中范围条件右边的列失效 CREATE INDEX idx_age_deptid_name ON emp(age,deptid,`name`); EXPLAIN SELECT * FROM emp WHERE emp.age=30 AND emp.name = 'abc' AND emp.deptId>1000 ; CREATE INDEX idx_age_name_deptid ON emp(age,`name`,deptid); |
关联查询优化
| 1、数据准备 2、左外连接实例 (1)明确角色
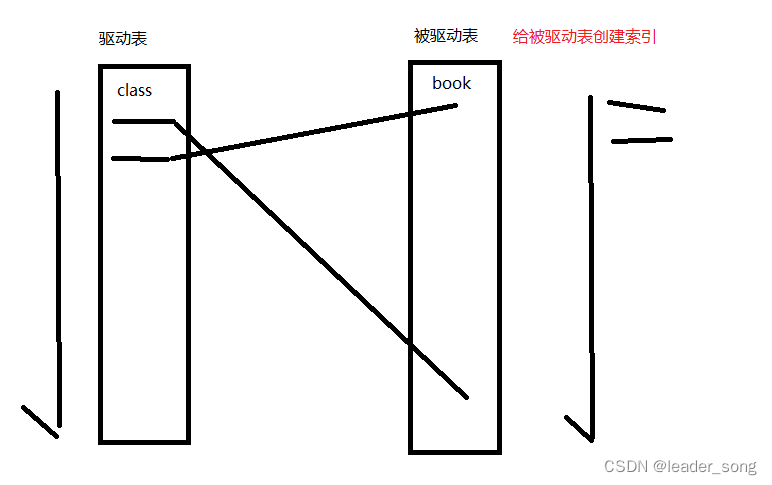
(2)优化 EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card; CREATE INDEX idx_class_card ON class(card); CREATE INDEX idx_book_card ON book(card); *使用LEFT JOIN,前面的是驱动表、后面是被驱动表 针对两张表的连接条件涉及的列,索引要创建在被驱动表上,驱动表尽量是小表
3、内连接实例 EXPLAIN SELECT * FROM class INNER JOIN book ON class.card = book.card; CREATE INDEX idx_class_card ON class(card); CREATE INDEX idx_book_card ON book(card); *使用INNER JOIN,驱动表、被驱动表不固定,mysql选择 MySQL优化器也会自动选择驱动表,自动选择驱动表的原则是:索引创建在被驱动表上,驱动表是小表。 4、分析4种查询sql(mysql5) 5、总结
|
其他优化
| 1、子查询优化 (1)获取非掌门人成员 #获取非掌门人成员 CALL proc_drop_index("atguigudb","emp"); CALL proc_drop_index("atguigudb","dept"); SELECT * FROM t_emp a WHERE a.id NOT IN (SELECT b.ceo FROM t_dept b WHERE b.ceo IS NOT NULL); EXPLAIN SELECT * FROM emp a WHERE a.id NOT IN (SELECT b.ceo FROM dept b WHERE b.ceo IS NOT NULL); #子查询优化NOT IN EXPLAIN SELECT * FROM emp a LEFT JOIN dept b ON a.id = b.ceo WHERE b.id IS NULL; (2)结论 尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx = xx WHERE xx IS NULL替代 2、排序优化 (1)实例 CALL proc_drop_index("atguigudb","emp"); CALL proc_drop_index("atguigudb","dept"); CREATE INDEX idx_age_deptid_name ON emp (age,deptid,`name`); #无过滤,不索引 EXPLAIN SELECT * FROM emp ORDER BY age,deptid; EXPLAIN SELECT * FROM emp ORDER BY age,deptid LIMIT 10; EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid; #顺序错,不索引 EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid, `name`; EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid, empno; CREATE INDEX idx_age_deptid_empno ON emp (age,deptid,`empno`); EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY `name`, deptid; EXPLAIN SELECT * FROM emp WHERE deptid=45 ORDER BY age; #方向反,不索引 EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid DESC, `name` DESC; EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid ASC, `name` DESC;
无过滤,不索引 顺序错,不索引 方向反,不索引 3、mysql索引选择 EXPLAIN SELECT * FROM emp WHERE age =30 AND empno <101000 ORDER BY `name`; CREATE INDEX idx_age_empno ON emp (age,`empno`); CREATE INDEX idx_age_name ON emp (age,NAME);
*当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。 也可以将选择权交给MySQL:索引同时存在,mysql自动选择最优的方案:(对于这个例子,mysql选择idx_age_empno),但是,随着数据量的变化,选择的索引也会随之变化的。 4、双路排序和单路排序 (1)双路排序(慢)
(2)单路排序(快) 它的效率更快一些,因为 5、分组优化
6、覆盖索引优化 总结
|

慢查询日志
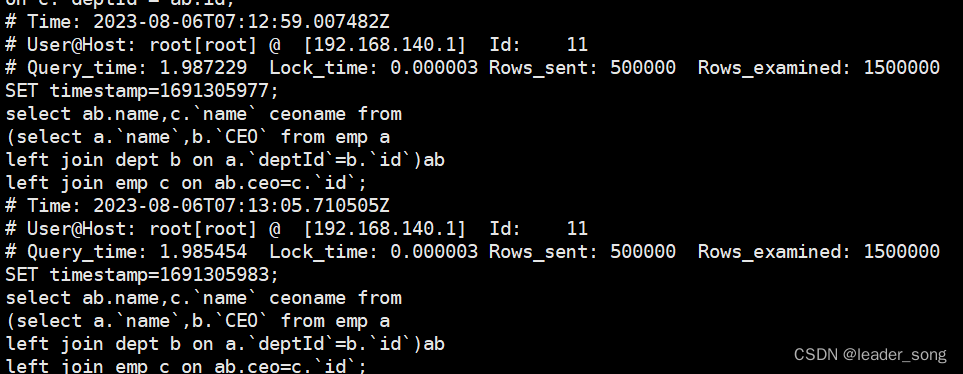
| 1、如何对系统查询慢做索引优化 (1)找运维人员开启生产数据库慢查询日志 (2)等待1-2周时间,积累慢查询日志 (3)借助工具获取慢查询次数最多和查询时间最长的几个sql进行优化 (4)在生产数据库,使用EXPLAIN进行sql分析,找到瓶颈,创建索引优化 (5)关闭慢查询日志。 2、是什么 一种日志记录,查看哪些SQL超出了我们的最大忍耐时间值。 3、使用 (1)开启slow_query_log SET GLOBAL slow_query_log=1; SHOW VARIABLES LIKE '%slow_query_log%'; (2)修改long_query_time阈值 SHOW VARIABLES LIKE '%long_query_time%'; -- 查看值:默认10秒 SET GLOBAL long_query_time=0.1; -- 设置一个比较短的时间,便于测试 (3)运行sql (4)查看慢查询日志
(5)使用工具分析慢查询日志 -- 查看mysqldumpslow的帮助信息 mysqldumpslow --help -- 工作常用参考 -- 1.得到返回记录集最多的10个SQL mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log -- 2.得到访问次数最多的10个SQL mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log -- 3.得到按照时间排序的前10条里面含有左连接的查询语句 mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log -- 4.另外建议在使用这些命令时结合 | 和more 使用 ,否则语句过多有可能出现爆屏情况 mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more |

| 1、单表索引失效案例 2、关联查询优化 3、其他优化 4、慢查询日志 5、视图 6、高性能架构模式 |
相关文章:
mysql高级三:sql性能优化+索引优化+慢查询日志
内容介绍 单表索引失效案例 0、思考题:如果把100万数据插入MYSQL ,如何提高插入效率 (1)关闭自动提交,只手动提交一次 (2)删除除主键索引外其他索引 (3)拼写mysql可以执…...
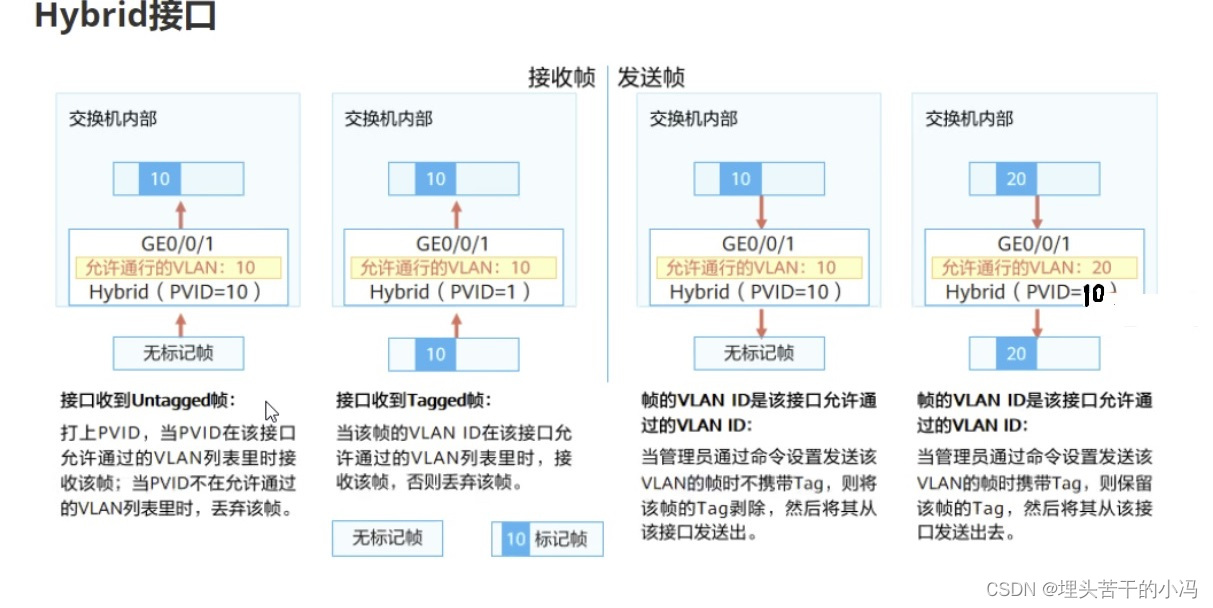
HCIP VLAN--Hybrid接口
一、VLAN的特点 1、一个VLAN就是一个广播域,所以在同一个VLAN内部,计算机可以直接进行二层通信;而不同VLAN内的计算机,无法直接进行二层通信,只能进行三层通信来传递信息,即广播报文被限制在一个VLAN内。 …...

大数据开发面试必问:Hive调优技巧系列二
接上次分享的Hive调优技巧系列一: 数据倾斜、HiveJob优化 第1章 数据倾斜(重点) 绝大部分任务都很快完成,只有一个或者少数几个任务执行的很慢甚至最终执行失败,这样的现象为数据倾斜现象。 一定要和数据过量导致的…...

【C++】STL——list的模拟实现、构造函数、迭代器类的实现、运算符重载、增删查改
文章目录 1.模拟实现list1.1构造函数1.2迭代器类的实现1.3运算符重载1.4增删查改 1.模拟实现list list使用文章 1.1构造函数 析构函数 在定义了一个类模板list时。我们让该类模板包含了一个内部结构体_list_node,用于表示链表的节点。该结构体包含了指向前一个节点…...

vscode 插件::EIDE
最新最全 VSCODE 插件推荐(2023版)_vscode_白墨石-华为云开发者联盟 (csdn.net) 超好用的开发工具-VScode插件EIDE_vscode eide_桃成蹊2.0的博客-CSDN博客 Setup | Embedded IDE For VSCode (em-ide.com)...

Python 网络编程
Python 网络编程 Python 提供了两个级别访问的网络服务: 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。高级别的网络服务模块 SocketServer, 它提供了服务器…...
SQL 数据科学:了解和利用联接
推荐:使用 NSDT场景编辑器助你快速搭建可编辑的3D应用场景 什么是 SQL 中的连接? SQL 联接允许您基于公共列合并来自多个数据库表的数据。这样,您就可以将信息合并在一起,并在相关数据集之间创建有意义的连接。 SQL 中的连接类型…...
第五章决策树——四五节:决策树的剪枝,CART算法)
(统计学习方法|李航)第五章决策树——四五节:决策树的剪枝,CART算法
目录 一,决策数的剪枝 二,CART算法 1.CART生成 (1)回归树的生成 (2)分类树的生成 2.CART剪枝 (1)剪枝,形成一个子树序列 (2)在剪枝得到的子…...

C语言--结构体定义
整型数,浮点数,字符串是分散的数据表示,有时候我们需要很多类型表示一个整体,比如学生信息。 数组是元素类型一样的数据集合,如果是元素类型不同的数据集合,就要用到结构体 结构体一般是个模板,…...

解决Element Plus中Select在El Dialog里层级过低的问题(修改select选项框样式)
Element Plus是Vue.js的一套基于Element UI的组件库,提供了丰富的组件用于构建现代化的Web应用程序。其中,<el-select>是一个常用的下拉选择器组件,但在某些情况下,当<el-select>组件嵌套在<el-dialog>…...
【数据结构】二叉树 链式结构的相关问题
本篇文章来详细介绍一下二叉树链式结构经常使用的相关函数,以及相关的的OJ题。 目录 1.前置说明 2.二叉树的遍历 2.1 前序、中序以及后序遍历 2.2 层次遍历 3.节点个数相关函数实现 3.1 二叉树节点个数 3.2 二叉树叶子节点个数 3.3 二叉树第k层节点个数 3…...
【无标题】云原生在工业互联网的落地及好处!
什么是工业互联网? 工业互联网(Industrial Internet)是新一代信息通信技术与工业经济深度融合的新型基础设施、应用模式和工业生态,通过对人、机、物、系统等的全面连接,构建起覆盖全产业链、全价值链的全新制造和服务…...

人工智能在心电信号分类中的应用
目录 1 引言 2 传统机器学习中的特征提取与选择 3 深度学习中的特征提取与选择...
【Linux 网络】网络层协议之IP协议
IP协议 IP协议所处的位置网络层要解决的问题IP协议格式分片与组装网段划分特殊的IP地址IP地址的数量限制私网IP地址和公网IP地址路由 IP协议所处的位置 IP指网际互连协议,Internet Protocol的缩写,是TCP/IP体系中的网络层协议。 网络层要解决的问题 网络…...

.meta 文件
.meta 文件的作用简单来说是建立 Unity 与资源之间的“桥梁”。 在游戏中引用一个游戏资源,Unity 并不是直接按照文件的路径或者名称,而是使用一个独一无二的 GUID 来指向工程里该资源文件。 这个 GUID 就是存储在 Unity 工程为每一个资源和文件…...
CRITICAL_SECTION 用法
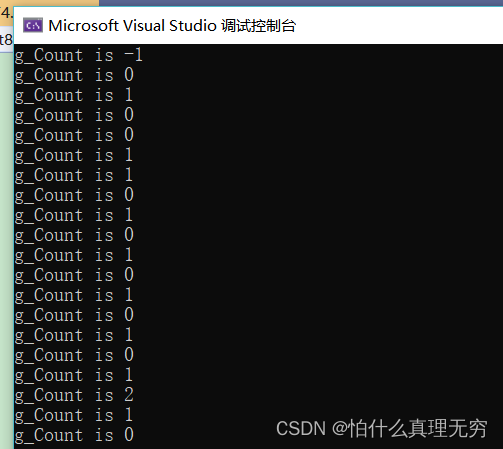
#include <stdio.h> #include <windows.h> typedef RTL_CRITICAL_SECTION CRITICAL_SECTION; CRITICAL_SECTION g_cs; //声明关键段 // 共享资源 char g_cArray[10]; unsigned int g_Count 0; DWORD WINAPI ThreadProc10(LPVOID pParam) { // 进入临界区 …...
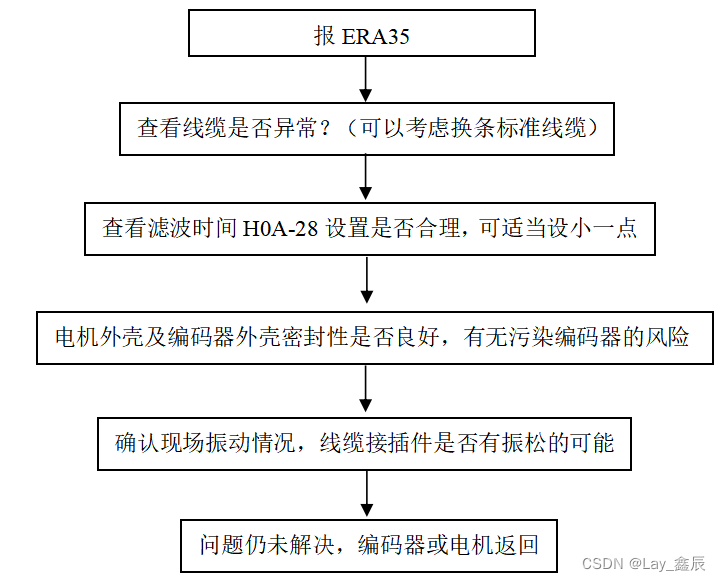
汇川运动控制产品故障排查
针对汇川伺服产品(IS600/IS620)的基本检测和一些出现频率较高的故障进行检测判断方法,适用于服务人员在现场排查/判断机器故障时,准确定位问题。 一、简单故障排查 注1:接线错误:1、UVW相序是否正确&#…...
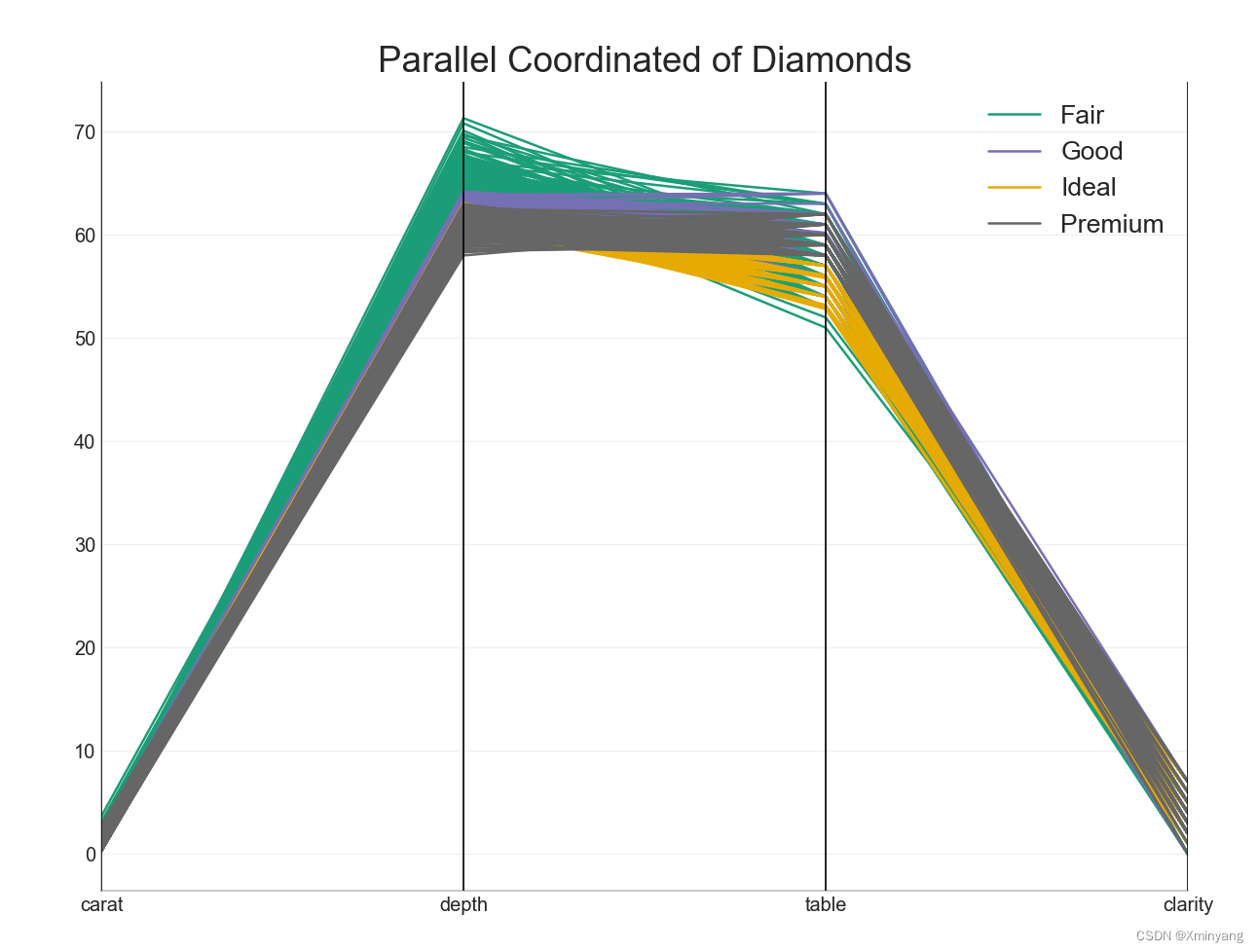
【Groups】50 Matplotlib Visualizations, Python实现,源码可复现
详情请参考博客: Top 50 matplotlib Visualizations 因编译更新问题,本文将稍作更改,以便能够顺利运行。 1 Dendrogram 树状图根据给定的距离度量将相似的点组合在一起,并根据点的相似性将它们组织成树状的链接。 新建文件Dendrogram.py: …...
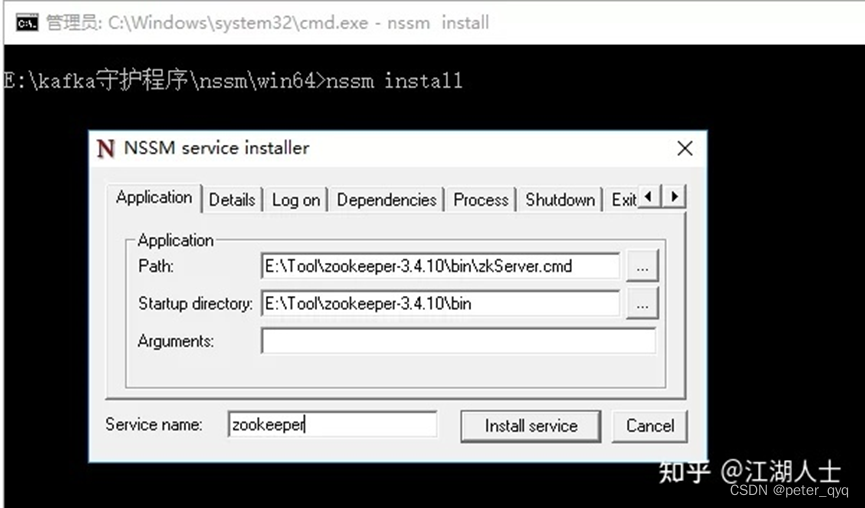
windows安装kafka配置SASL-PLAIN安全认证
目录 1.Windows安装zookeeper: 1.1下载zookeeper 1.2 解压之后如图二 1.3创建日志文件 1.4复制 “zoo_sample.cfg” 文件 1.5更改 “zoo.cfg” 配置 1.6新建zk_server_jaas.conf 1.7修改zkEnv.cmd 1.8导入相关jar 1.9以上配置就配好啦,接下来启…...
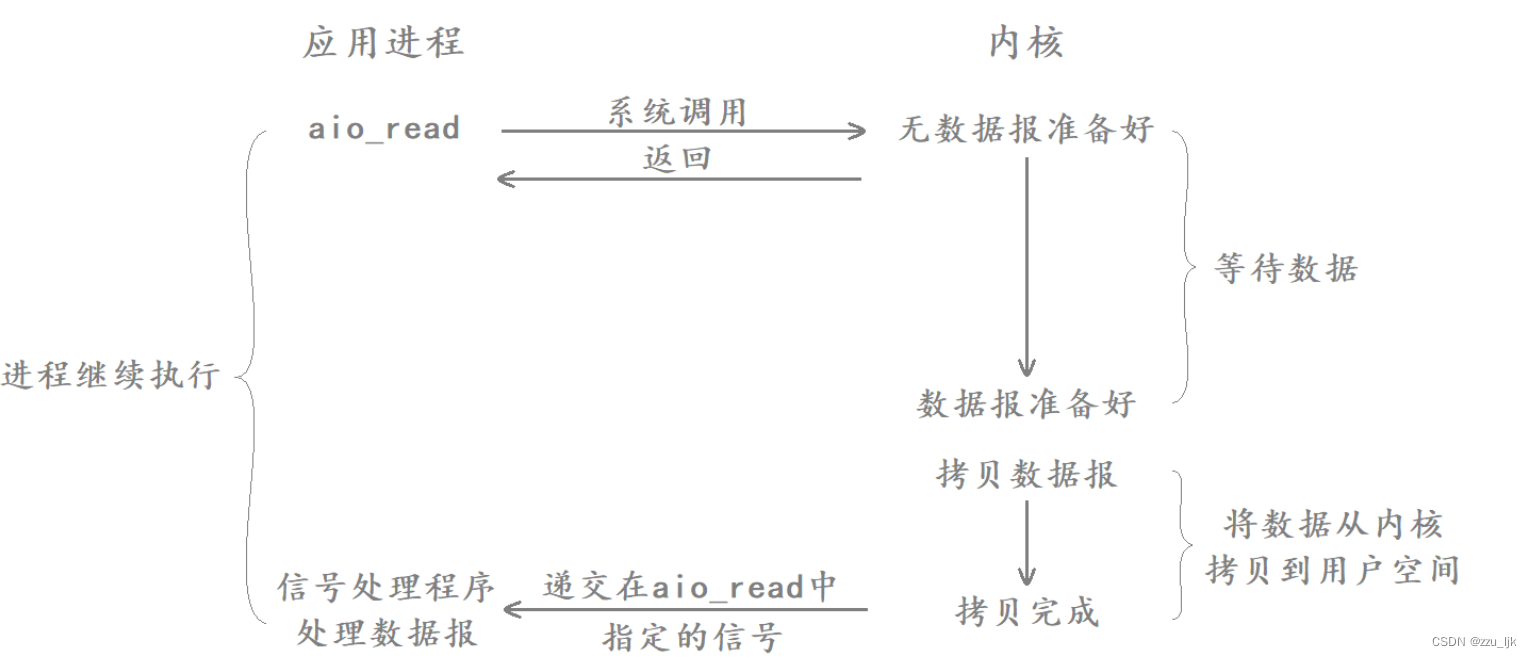
【Linux】五种IO模型
文章目录 1. IO基本概念2. 五种IO模型2.1 五个钓鱼的例子2.2 五种IO模型2.2.1 阻塞IO2.2.2 非阻塞IO2.2.3 信号驱动IO2.2.4 IO多路转接2.2.5 异步IO 1. IO基本概念 认识IO IO就是输入和输出,在冯诺依曼体系结构中,将数据从输入设备拷贝到内存就叫输入&am…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...