PostgreSQL常用函数
PostgreSQL常用函数
内置函数
PostgreSQL 内置函数也称为聚合函数,用于对字符串或数字数据执行处理。
下面是所有通用 PostgreSQL 内置函数的列表:
- COUNT 函数:用于计算数据库表中的行数。
- MAX 函数:用于查询某一特定列中最大值。
- MIN 函数:用于查询某一特定列中最小值。
- AVG 函数:用于计算某一特定列中平均值。
- SUM 函数:用于计算数字列所有值的总和。
- ARRAY 函数:用于输入值(包括null)添加到数组中。
- Numeric 函数:完整列出一个 SQL 中所需的操作数的函数。
- String 函数:完整列出一个 SQL 中所需的操作字符的函数。
时间/日期函数
时间/日期操作符
下表演示了基本算术操作符的行为(+,*, 等):
| 操作符 | 例子 | 结果 |
|---|---|---|
+ | date '2001-09-28' + integer '7' | date '2001-10-05' |
+ | date '2001-09-28' + interval '1 hour' | timestamp '2001-09-28 01:00:00' |
+ | date '2001-09-28' + time '03:00' | timestamp '2001-09-28 03:00:00' |
+ | interval '1 day' + interval '1 hour' | interval '1 day 01:00:00' |
+ | timestamp '2001-09-28 01:00' + interval '23 hours' | timestamp '2001-09-29 00:00:00' |
+ | time '01:00' + interval '3 hours' | time '04:00:00' |
- | - interval '23 hours' | interval '-23:00:00' |
- | date '2001-10-01' - date '2001-09-28' | integer '3' (days) |
- | date '2001-10-01' - integer '7' | date '2001-09-24' |
- | date '2001-09-28' - interval '1 hour' | timestamp '2001-09-27 23:00:00' |
- | time '05:00' - time '03:00' | interval '02:00:00' |
- | time '05:00' - interval '2 hours' | time '03:00:00' |
- | timestamp '2001-09-28 23:00' - interval '23 hours' | timestamp '2001-09-28 00:00:00' |
- | interval '1 day' - interval '1 hour' | interval '1 day -01:00:00' |
- | timestamp '2001-09-29 03:00' - timestamp '2001-09-27 12:00' | interval '1 day 15:00:00' |
* | 900 * interval '1 second' | interval '00:15:00' |
* | 21 * interval '1 day' | interval '21 days' |
* | double precision '3.5' * interval '1 hour' | interval '03:30:00' |
/ | interval '1 hour' / double precision '1.5' | interval '00:40:00' |
日期/时间函数
| 函数 | 返回类型 | 描述 | 例子 | 结果 |
|---|---|---|---|---|
age(timestamp, timestamp) | interval | 减去参数后的"符号化"结果,使用年和月,不只是使用天 | age(timestamp '2001-04-10', timestamp '1957-06-13') | 43 years 9 mons 27 days |
age(timestamp) | interval | 从current_date减去参数后的结果(在午夜) | age(timestamp '1957-06-13') | 43 years 8 mons 3 days |
clock_timestamp() | timestamp with time zone | 实时时钟的当前时间戳(在语句执行时变化) | ||
current_date | date | 当前的日期; | ||
current_time | time with time zone | 当日时间; | ||
current_timestamp | timestamp with time zone | 当前事务开始时的时间戳; | ||
date_part(text, timestamp) | double precision | 获取子域(等效于extract); | date_part('hour', timestamp '2001-02-16 20:38:40') | 20 |
date_part(text, interval) | double precision | 获取子域(等效于extract); | date_part('month', interval '2 years 3 months') | 3 |
date_trunc(text, timestamp) | timestamp | 截断成指定的精度; | date_trunc('hour', timestamp '2001-02-16 20:38:40') | 2001-02-16 20:00:00 |
date_trunc(text, interval) | interval | 截取指定的精度, | date_trunc('hour', interval '2 days 3 hours 40 minutes') | 2 days 03:00:00 |
extract(field from timestamp) | double precision | 获取子域; | extract(hour from timestamp '2001-02-16 20:38:40') | 20 |
extract(field from interval) | double precision | 获取子域; | extract(month from interval '2 years 3 months') | 3 |
isfinite(date) | boolean | 测试是否为有穷日期(不是 +/-无穷) | isfinite(date '2001-02-16') | true |
isfinite(timestamp) | boolean | 测试是否为有穷时间戳(不是 +/-无穷) | isfinite(timestamp '2001-02-16 21:28:30') | true |
isfinite(interval) | boolean | 测试是否为有穷时间间隔 | isfinite(interval '4 hours') | true |
justify_days(interval) | interval | 按照每月 30 天调整时间间隔 | justify_days(interval '35 days') | 1 mon 5 days |
justify_hours(interval) | interval | 按照每天 24 小时调整时间间隔 | justify_hours(interval '27 hours') | 1 day 03:00:00 |
justify_interval(interval) | interval | 使用justify_days和justify_hours调整时间间隔的同时进行正负号调整 | justify_interval(interval '1 mon -1 hour') | 29 days 23:00:00 |
localtime | time | 当日时间; | ||
localtimestamp | timestamp | 当前事务开始时的时间戳; | ||
make_date(year int, month int, day int) | date | 为年、月和日字段创建日期 | make_date(2013, 7, 15) | 2013-07-15 |
make_interval(years int DEFAULT 0, months int DEFAULT 0, weeks int DEFAULT 0, days int DEFAULT 0, hours int DEFAULT 0, mins int DEFAULT 0, secs double precision DEFAULT 0.0) | interval | 从年、月、周、天、小时、分钟和秒字段中创建间隔 | make_interval(days := 10) | 10 days |
make_time(hour int, min int, sec double precision) | time | 从小时、分钟和秒字段中创建时间 | make_time(8, 15, 23.5) | 08:15:23.5 |
make_timestamp(year int, month int, day int, hour int, min int, sec double precision) | timestamp | 从年、月、日、小时、分钟和秒字段中创建时间戳 | make_timestamp(2013, 7, 15, 8, 15, 23.5) | 2013-07-15 08:15:23.5 |
make_timestamptz(year int, month int, day int, hour int, min int, sec double precision, [ timezone text ]) | timestamp with time zone | 从年、月、日、小时、分钟和秒字段中创建带有时区的时间戳。 没有指定timezone时,使用当前的时区。 | make_timestamptz(2013, 7, 15, 8, 15, 23.5) | 2013-07-15 08:15:23.5+01 |
now() | timestamp with time zone | 当前事务开始时的时间戳; | ||
statement_timestamp() | timestamp with time zone | 实时时钟的当前时间戳; | ||
timeofday() | text | 与clock_timestamp相同,但结果是一个text 字符串; | ||
transaction_timestamp() | timestamp with time zone | 当前事务开始时的时间戳; |
字符串/日期相互格式化函数
| 函数 | 返回类型 | 描述 | 例子 |
|---|---|---|---|
| to_char(timestamp, text) | text | 把时间戳转换成字串 | to_char(current_timestamp, ‘HH12:MI:SS’) |
| to_char(interval, text) | text | 把时间间隔转为字串 | to_char(interval ‘15h 2m 12s’, ‘HH24:MI:SS’) |
| to_char(int, text) | text | 把整数转换成字串 | to_char(125, ‘999’) |
| to_char(double precision, text) | text | 把实数/双精度数转换成字串 | to_char(125.8::real, ‘999D9’) |
| to_char(numeric, text) | text | 把numeric转换成字串 | to_char(-125.8, ‘999D99S’) |
| to_date(text, text) | date | 把字串转换成日期 | to_date(‘05 Dec 2000’, ‘DD Mon YYYY’) |
| to_timestamp(text, text) | timestamp | 把字串转换成时间戳 | to_timestamp(‘05 Dec 2000’, ‘DD Mon YYYY’) |
| to_timestamp(double) | timestamp | 把UNIX纪元转换成时间戳 | to_timestamp(200120400) |
| to_number(text, text) | numeric | 把字串转换成numeric | to_number(‘12,454.8-’, ‘99G999D9S’) |
日期/时间格式化的占位符
| 占位符 | 描述 |
|---|---|
| HH | 一天的小时数(01-12) |
| HH12 | 一天的小时数(01-12) |
| HH24 | 一天的小时数(00-23) |
| MI | 分钟(00-59) |
| SS | 秒(00-59) |
| MS | 毫秒(000-999) |
| US | 微秒(000000-999999) |
| AM | 正午标识(大写) |
| Y,YYY | 带逗号的年(4和更多位) |
| YYYY | 年(4和更多位) |
| YYY | 年的后三位 |
| YY | 年的后两位 |
| Y | 年的最后一位 |
| MONTH | 全长大写月份名(空白填充为9字符) |
| Month | 全长混合大小写月份名(空白填充为9字符) |
| month | 全长小写月份名(空白填充为9字符) |
| MON | 大写缩写月份名(3字符) |
| Mon | 缩写混合大小写月份名(3字符) |
| mon | 小写缩写月份名(3字符) |
| MM | 月份号(01-12) |
| DAY | 全长大写日期名(空白填充为9字符) |
| Day | 全长混合大小写日期名(空白填充为9字符) |
| day | 全长小写日期名(空白填充为9字符) |
| DY | 缩写大写日期名(3字符) |
| Dy | 缩写混合大小写日期名(3字符)dy缩写小写日期名(3字符) |
| DDD | 一年里的日子(001-366) |
| DD | 一个月里的日子(01-31) |
| D | 一周里的日子(1-7;周日是1) |
| W | 一个月里的周数(1-5)(第一周从该月第一天开始) |
| WW | 一年里的周数(1-53)(第一周从该年的第一天开始) |
数学函数
下面是PostgreSQL中提供的数学函数列表,需要说明的是,这些函数中有许多都存在多种形式,区别只是参数类型不同。除非特别指明,任何特定形式的函数都返回和它的参数相同的数据类型。
| 函数 | 返回类型 | 描述 | 例子 | 结果 |
|---|---|---|---|---|
| abs(x) | 绝对值 | abs(-17.4) | 17.4 | |
| cbrt(double) | 立方根 | cbrt(27.0) | 3 | |
| ceil(double/numeric) | 不小于参数的最小的整数 | ceil(-42.8) | -42 | |
| degrees(double) | 把弧度转为角度 | degrees(0.5) | 28.6478897565412 | |
| exp(double/numeric) | 自然指数 | exp(1.0) | 2.71828182845905 | |
| floor(double/numeric) | 不大于参数的最大整数 | floor(-42.8) | -43 | |
| ln(double/numeric) | 自然对数 | ln(2.0) | 0.693147180559945 | |
| log(double/numeric) | 10为底的对数 | log(100.0) | 2 | |
| log(b numeric,x numeric) | numeric | 指定底数的对数 | log(2.0, 64.0) | 6.0000000000 |
| mod(y, x) | 取余数 | mod(9,4) | 1 | |
| pi() | double | "π"常量 | pi() | 3.14159265358979 |
| power(a double, b double) | double | 求a的b次幂 | power(9.0, 3.0) | 729 |
| power(a numeric, b numeric) | numeric | 求a的b次幂 | power(9.0, 3.0) | 729 |
| radians(double) | double | 把角度转为弧度 | radians(45.0) | 0.785398163397448 |
| random() | double | 0.0到1.0之间的随机数值 | random() | |
| round(double/numeric) | 圆整为最接近的整数 | round(42.4) | 42 | |
| round(v numeric, s int) | numeric | 圆整为s位小数数字 | round(42.438,2) | 42.44 |
| sign(double/numeric) | 参数的符号(-1,0,+1) | sign(-8.4) | -1 | |
| sqrt(double/numeric) | 平方根 | sqrt(2.0) | 1.4142135623731 | |
| trunc(double/numeric) | 截断(向零靠近) | trunc(42.8) | 42 | |
| trunc(v numeric, s int) | numeric | 截断为s小数位置的数字 | trunc(42.438,2) | 42.43 |
三角函数
| 函数 | 描述 |
|---|---|
| acos(x) | 反余弦 |
| asin(x) | 反正弦 |
| atan(x) | 反正切 |
| atan2(x, y) | 正切 y/x 的反函数 |
| cos(x) | 余弦 |
| cot(x) | 余切 |
| sin(x) | 正弦 |
| tan(x) | 正切 |
字符串函数和操作符
下面是 PostgreSQL 中提供的字符串操作符列表:
| 函数 | 返回类型 | 描述 | 例子 | 结果 |
|---|---|---|---|---|
| string 丨丨 string | text | 字串连接 | ‘Post’ 丨丨 ‘greSQL’ | PostgreSQL |
| bit_length(string) | int | 字串里二进制位的个数 | bit_length(‘jose’) | 32 |
| char_length(string) | int | 字串中的字符个数 | char_length(‘jose’) | 4 |
| convert(string using conversion_name) | text | 使用指定的转换名字改变编码。 | convert(‘PostgreSQL’ using iso_8859_1_to_utf8) | ‘PostgreSQL’ |
| lower(string) | text | 把字串转化为小写 | lower(‘TOM’) | tom |
| octet_length(string) | int | 字串中的字节数 | octet_length(‘jose’) | 4 |
| overlay(string placing string from int [for int]) | text | 替换子字串 | overlay(‘Txxxxas’ placing ‘hom’ from 2 for 4) | Thomas |
| position(substring in string) | int | 指定的子字串的位置 | position(‘om’ in ‘Thomas’) | 3 |
| substring(string [from int] [for int]) | text | 抽取子字串 | substring(‘Thomas’ from 2 for 3) | hom |
| substring(string from pattern) | text | 抽取匹配 POSIX 正则表达式的子字串 | substring(‘Thomas’ from ‘…$’) | mas |
| substring(string from pattern for escape) | text | 抽取匹配SQL正则表达式的子字串 | substring(‘Thomas’ from ‘%#“o_a#”_’ for ‘#’) | oma |
| trim([leading丨trailing 丨 both] [characters] from string) | text | 从字串string的开头/结尾/两边/ 删除只包含characters(默认是一个空白)的最长的字串 | trim(both ‘x’ from ‘xTomxx’) | Tom |
| upper(string) | text | 把字串转化为大写。 | upper(‘tom’) | TOM |
| ascii(text) | int | 参数第一个字符的ASCII码 | ascii(‘x’) | 120 |
| btrim(string text [, characters text]) | text | 从string开头和结尾删除只包含在characters里(默认是空白)的字符的最长字串 | btrim(‘xyxtrimyyx’,‘xy’) | trim |
| chr(int) | text | 给出ASCII码的字符 | chr(65) | A |
| convert(string text, [src_encoding name,] dest_encoding name) | text | 把字串转换为dest_encoding | convert( ‘text_in_utf8’, ‘UTF8’, ‘LATIN1’) | 以ISO 8859-1编码表示的text_in_utf8 |
| initcap(text) | text | 把每个单词的第一个子母转为大写,其它的保留小写。单词是一系列字母数字组成的字符,用非字母数字分隔。 | initcap(‘hi thomas’) | Hi Thomas |
| length(string text) | int | string中字符的数目 | length(‘jose’) | 4 |
| lpad(string text, length int [, fill text]) | text | 通过填充字符fill(默认为空白),把string填充为长度length。 如果string已经比length长则将其截断(在右边)。 | lpad(‘hi’, 5, ‘xy’) | xyxhi |
| ltrim(string text [, characters text]) | text | 从字串string的开头删除只包含characters(默认是一个空白)的最长的字串。 | ltrim(‘zzzytrim’,‘xyz’) | trim |
| md5(string text) | text | 计算给出string的MD5散列,以十六进制返回结果。 | md5(‘abc’) | |
| repeat(string text, number int) | text | 重复string number次。 | repeat(‘Pg’, 4) | PgPgPgPg |
| replace(string text, from text, to text) | text | 把字串string里出现地所有子字串from替换成子字串to。 | replace(‘abcdefabcdef’, ‘cd’, ‘XX’) | abXXefabXXef |
| rpad(string text, length int [, fill text]) | text | 通过填充字符fill(默认为空白),把string填充为长度length。如果string已经比length长则将其截断。 | rpad(‘hi’, 5, ‘xy’) | hixyx |
| rtrim(string text [, character text]) | text | 从字串string的结尾删除只包含character(默认是个空白)的最长的字 | rtrim(‘trimxxxx’,‘x’) | trim |
| split_part(string text, delimiter text, field int) | text | 根据delimiter分隔string返回生成的第field个子字串(1 Base)。 | split_part(‘abc@def@ghi’, ‘@’, 2) | def |
| strpos(string, substring) | text | 声明的子字串的位置。 | strpos(‘high’,‘ig’) | 2 |
| substr(string, from [, count]) | text | 抽取子字串。 | substr(‘alphabet’, 3, 2) | ph |
| to_ascii(text [, encoding]) | text | 把text从其它编码转换为ASCII。 | to_ascii(‘Karel’) | Karel |
| to_hex(number int/bigint) | text | 把number转换成其对应地十六进制表现形式。 | to_hex(9223372036854775807) | 7fffffffffffffff |
| translate(string text, from text, to text) | text | 把在string中包含的任何匹配from中的字符的字符转化为对应的在to中的字符。 | translate(‘12345’, ‘14’, ‘ax’) | a23x5 |
类型转换相关函数
| 函数 | 返回类型 | 描述 | 实例 |
|---|---|---|---|
| to_char(timestamp, text) | text | 将时间戳转换为字符串 | to_char(current_timestamp, ‘HH12:MI:SS’) |
| to_char(interval, text) | text | 将时间间隔转换为字符串 | to_char(interval ‘15h 2m 12s’, ‘HH24:MI:SS’) |
| to_char(int, text) | text | 整型转换为字符串 | to_char(125, ‘999’) |
| to_char(double precision, text) | text | 双精度转换为字符串 | to_char(125.8::real, ‘999D9’) |
| to_char(numeric, text) | text | 数字转换为字符串 | to_char(-125.8, ‘999D99S’) |
| to_date(text, text) | date | 字符串转换为日期 | to_date(‘05 Dec 2000’, ‘DD Mon YYYY’) |
| to_number(text, text) | numeric | 转换字符串为数字 | to_number(‘12,454.8-’, ‘99G999D9S’) |
| to_timestamp(text, text) | timestamp | 转换为指定的时间格式 time zone convert string to time stamp | to_timestamp(‘05 Dec 2000’, ‘DD Mon YYYY’) |
| to_timestamp(double precision) | timestamp | 把UNIX纪元转换成时间戳 | to_timestamp(1284352323) |
相关文章:

PostgreSQL常用函数
PostgreSQL常用函数 内置函数 PostgreSQL 内置函数也称为聚合函数,用于对字符串或数字数据执行处理。 下面是所有通用 PostgreSQL 内置函数的列表: COUNT 函数:用于计算数据库表中的行数。MAX 函数:用于查询某一特定列中最大值…...
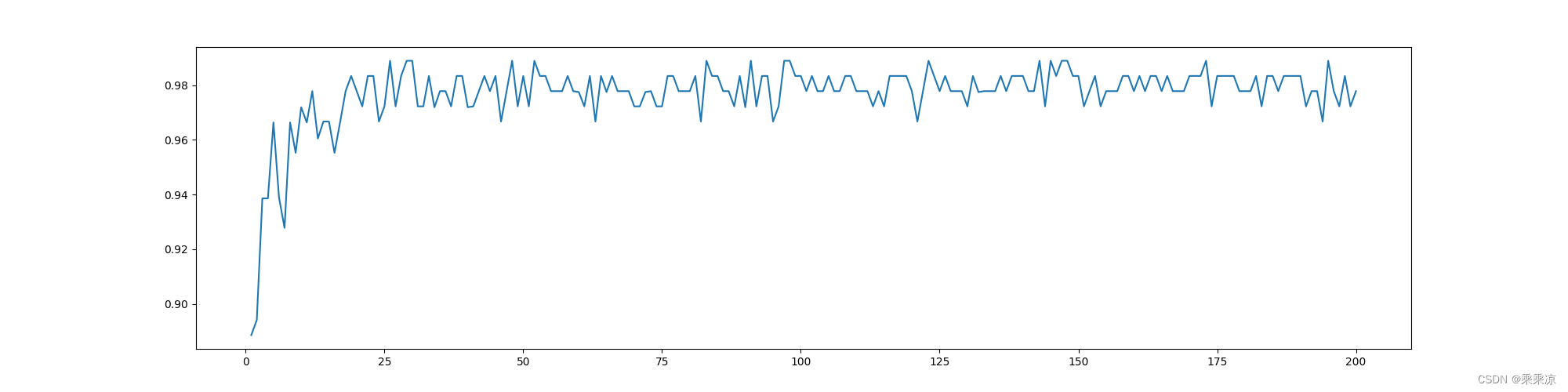
决策树和随机森林对比
1.用accuracy来对比 # -*-coding:utf-8-*-""" accuracy来对比决策树和随机森林 """ from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine#(178, 13…...
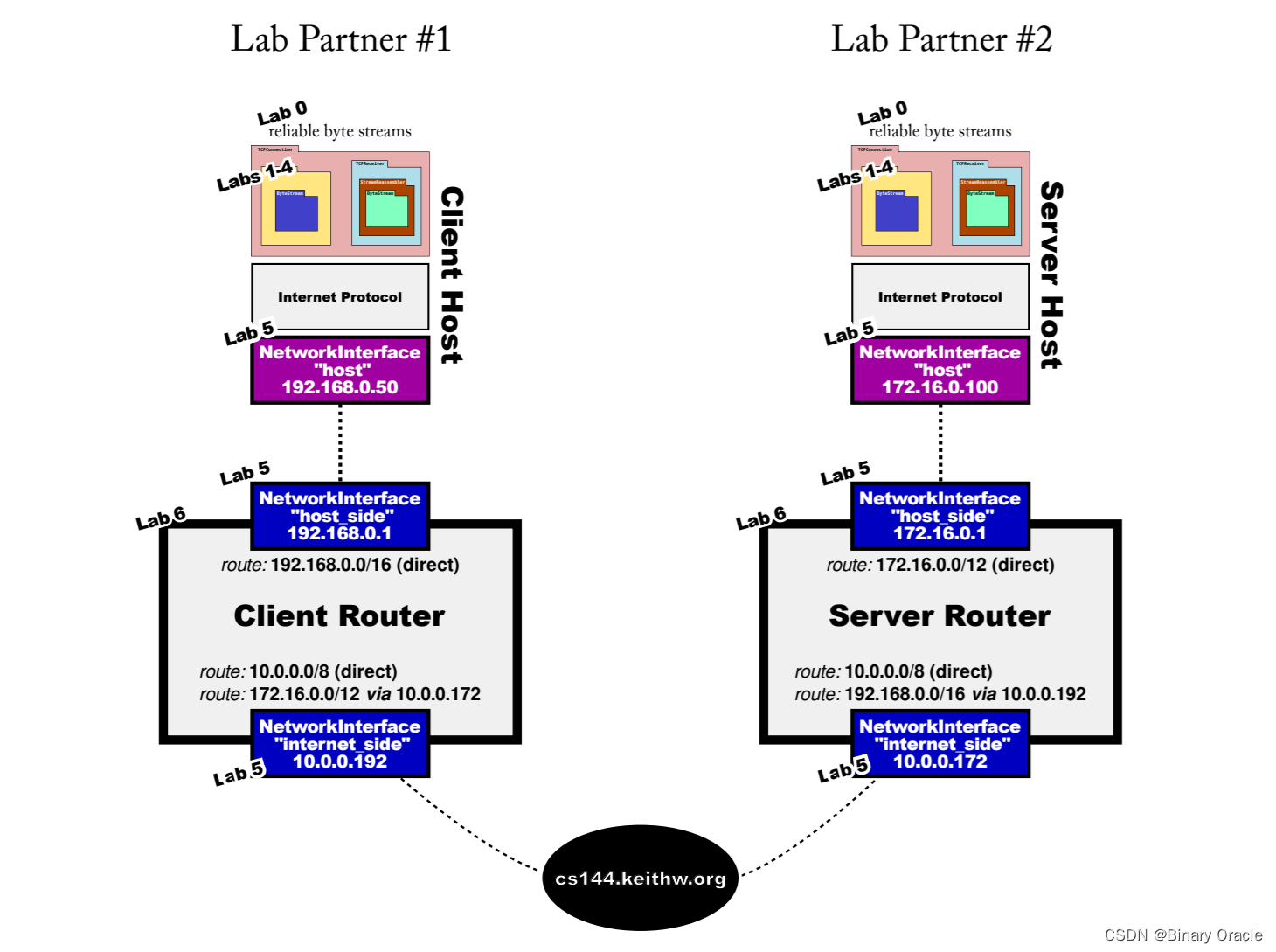
CS 144 Lab Seven -- putting it all together
CS 144 Lab Seven -- putting it all together 引言测试lab7.ccUDPSocketNetworkInterfaceAdapterTCPSocketLab7main方法子线程 小结 对应课程视频: 【计算机网络】 斯坦福大学CS144课程 Lab Six 对应的PDF: Checkpoint 6: putting it all together 引言 本实验无需进行任何编…...
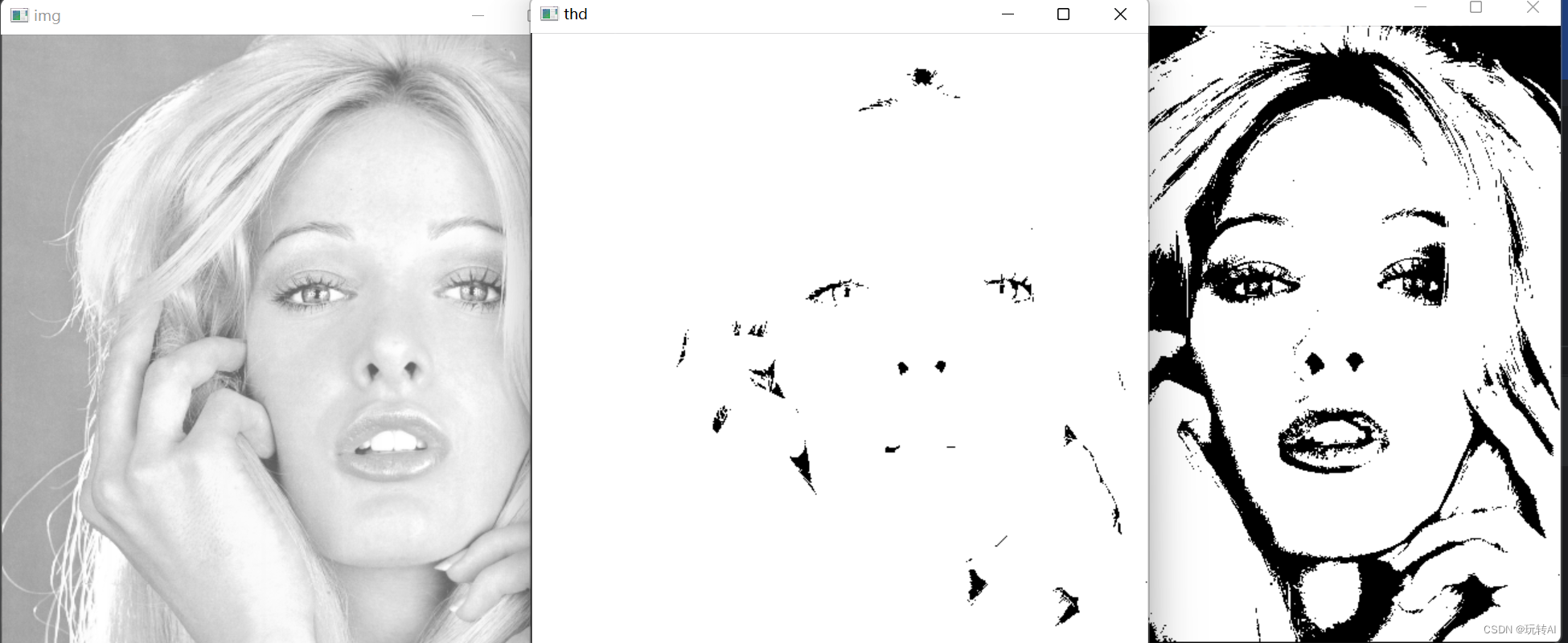
opencv基础-29 Otsu 处理(图像分割)
Otsu 处理 Otsu 处理是一种用于图像分割的方法,旨在自动找到一个阈值,将图像分成两个类别:前景和背景。这种方法最初由日本学者大津展之(Nobuyuki Otsu)在 1979 年提出 在 Otsu 处理中,我们通过最小化类别内…...

gcc-buildroot-9.3.0 和 gcc-arm-10.3 的区别
gcc-buildroot-9.3.0 和 gcc-arm-10.3 是两个不同的 GCC (GNU Compiler Collection) 版本,主要用于编译 C、C 和其他语言的程序。它们之间的区别主要体现在以下几个方面: 版本号:gcc-buildroot-9.3.0 对应的是 GCC 9.3.0 版本,而 …...
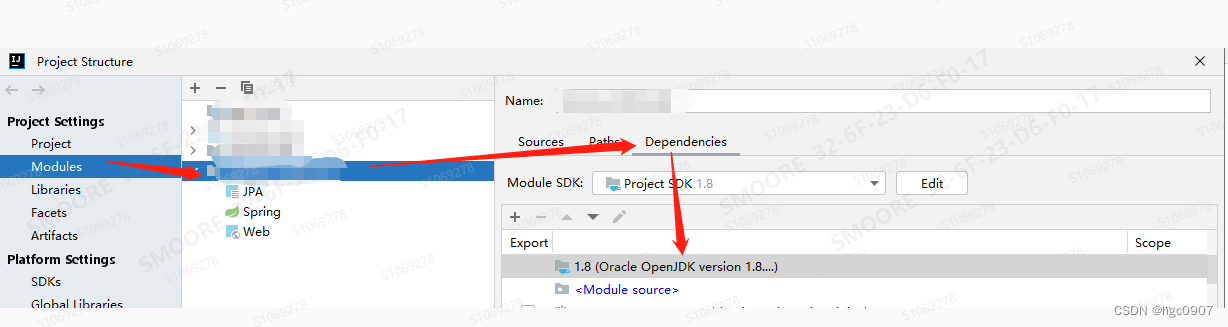
IDEA Run SpringBoot程序步骤原理
这个文章不是高深的原理文章,仅仅是接手一个外部提供的阉割版代码遇到过的一个坑,后来解决了,记录一下。 1、IDEA Run 一个SpringBoot一直失败,提示找不到类,但是maven install成功,并且java -jar能成功ru…...
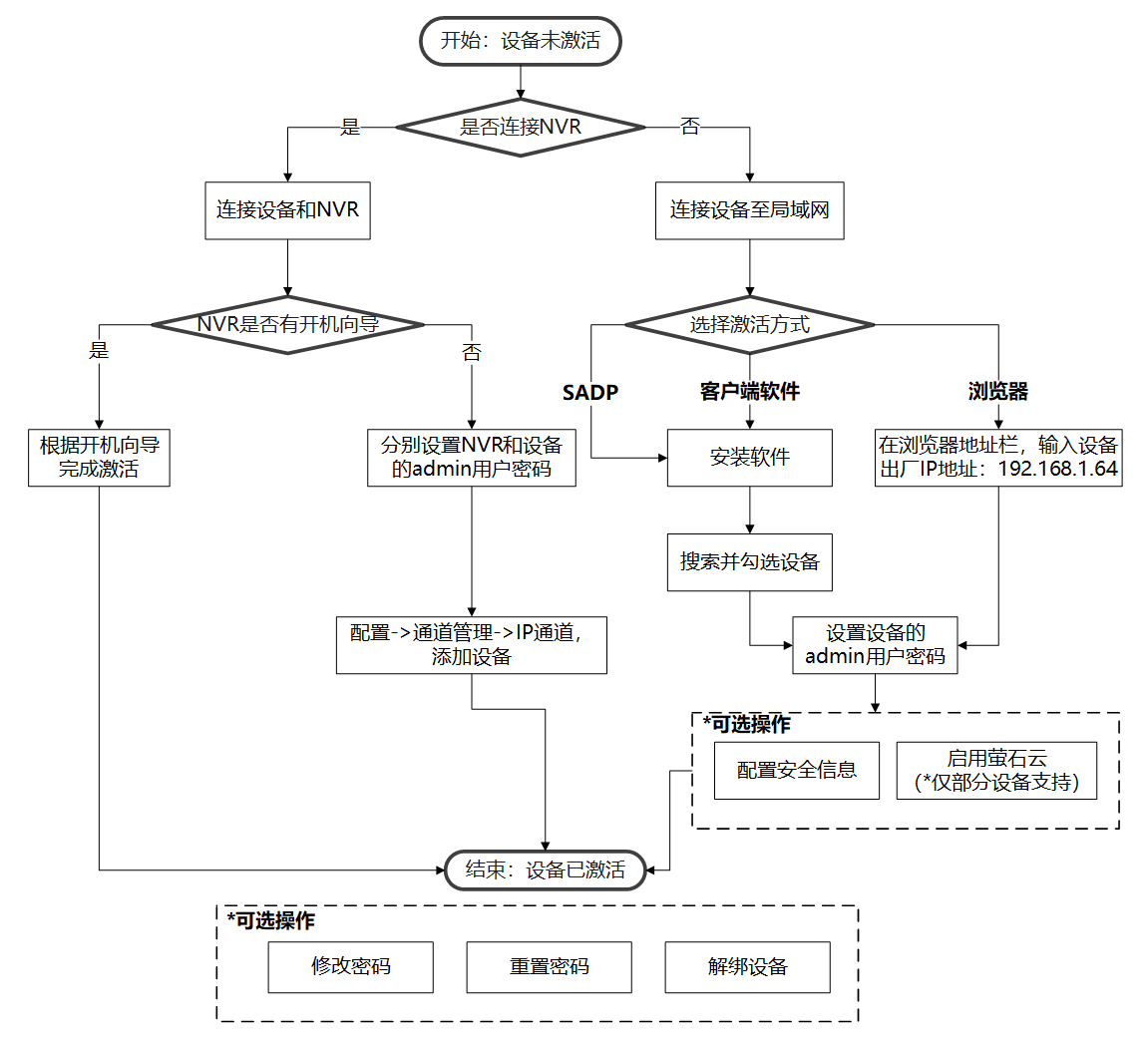
海康威视摄像头配置RTSP协议访问、onvif协议接入、二次开发SDK接入
一、准备工作 (1)拿到摄像头之后,将摄像头电源线插好,再将网线插入到路由器上。 (2)将自己的笔记本电脑也连接到路由器网络,与摄像头出在同一个局域网。 二、配置摄像头 2.1 激活方式选择 第一次使用设备需要激活,在进行配置。 最简单,最方便的方式是选择浏览器激…...

Android中的Parcelable 接口
Android中的Parcelable 接口 在Android中,Parcelable接口是用于实现对象序列化和反序列化的一种机制。它允许我们将自定义的Java对象转换成一个可传输的二进制数据流,以便在不同组件之间传递数据。通常在Activity之间传递复杂的自定义对象时,…...
Docker-Compose编排与部署
目录 Docker Compose Compose的优点 编排和部署 Compose原理 Compose应用案例 安装docker-ce 阿里云镜像加速器 安装docker-compose docker-compose用法 Yaml简介 验证LNMP环境 Docker Compose Docker Compose 的前身是 Fig,它是一个定义及运行多个 Dock…...

Linux JDK 安装
文章目录 安装步骤1、卸载openJDK1.1 查看当前Linux系统是否安装java,卸载openjdk1.2 卸载系统中已经存在的openJDK 2、在/usr/local目录下创建java目录3、上传JDK到Linux系统4、解压jdk5、配置Jdk环境变量6、重新加载/etc/profile文件,让配置生效7、测试安装是否成…...

JS中常用的数组拷贝技巧
我们都知道,数组也是属于对象,在JS中对象的存储方式则是引用的方式。我们想要拷贝一个数组,就不能只是变量之前的赋值拷贝,这样他们将共享同一个引用,而数组又具有可变性,所以无法将原数组和拷贝的数组的数…...
SAP ABAP程序性能优化-养成良好的代码习惯
ABAP程序基本上都需要从数据库里面抓数,所以性能很重要,同时有一些基本的,和优秀的写法是我们必须要掌握的,不然就会造成程序性能很差。下面给予总结(这里包括有很基本的,也包括有比较少用到的)…...
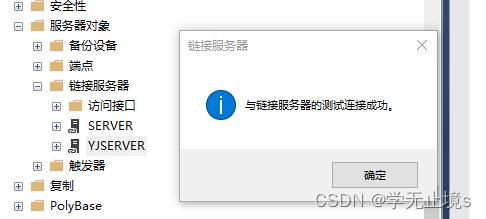
SQL SERVER ip地址改别名
SQL server在使用链接服务器时必须使用别名,使用ip地址就会把192.188.0.2这种点也解析出来 解决方案: 1、物理机ip 192.168.0.66 虚拟机ip 192.168.0.115 2、在虚拟机上找到 C:\Windows\System32\drivers\etc 下的 (我选中的文件&a…...

数据结构-1
1.2 线性结构树状结构网状结构(表 数 图) 数据:数值型 非数值型 1.2.3数据类型和抽象数据类型 1.3抽象数据类型 概念小结: 线性表: 如果在独立函数实现的 .c 文件中需要包含 stdlib.h 头文件,而主函数也需要包含 st…...

Java自定义校验注解实现List、set集合字段唯一性校验
文章目录 一: 使用场景二: 定义FieldUniqueValid注解2.1 FieldUniqueValid2.2 注解说明2.3 Constraint 注解介绍2.4 FieldUniqueValid注解使用 三:自定义FieldUniqueValidator校验类3.1 实现ConstraintValidator3.2 重写initialize方法3.3 重…...

xiaoweirobot.chat
目录 1 xiaoweirobot.chat 1.1 DetailList 2 HttpData 2.1 doInBackground 2.2 onPostExecute xiaoweirobot.chatpackage com.shrimp.xiaoweirobot.chat; DetailList <...
【无公网IP】本地电脑搭建个人博客网站(并发布公网访问 )和web服务器
【无公网IP】本地电脑搭建个人博客网站(并发布公网访问 )和web服务器 文章目录 【无公网IP】本地电脑搭建个人博客网站(并发布公网访问 )和web服务器前言1. 安装套件软件2. 创建网页运行环境 指定网页输出的端口号3. 让WordPress在…...
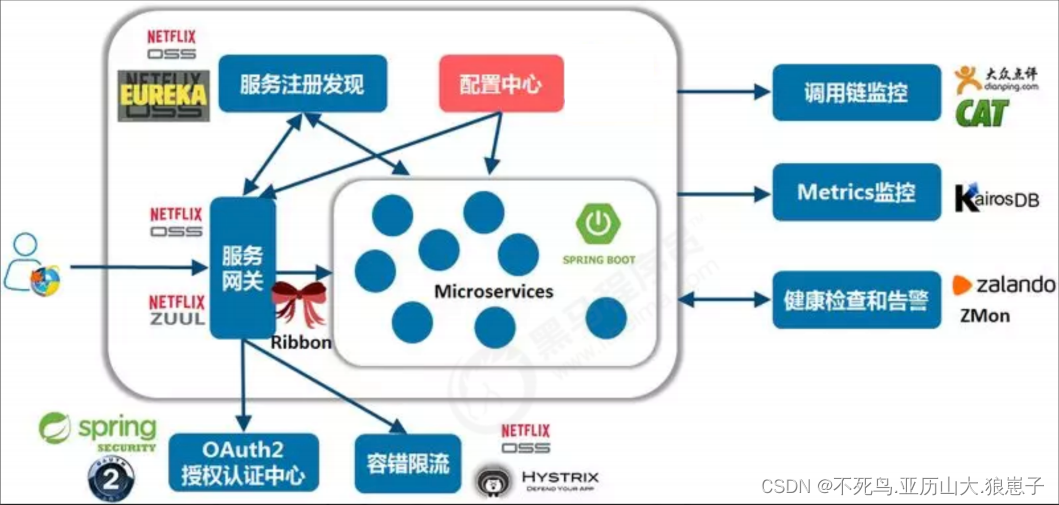
SpringCloud(29):Nacos简介
1 什么是配置中心 1.1 什么是配置 应用程序在启动和运行的时候往往需要读取一些配置信息,配置基本上伴随着应用程序的整个生命周期,比如:数据库连接参数、启动参数等。 配置主要有以下几个特点: 配置是独立于程序的只读变量 …...

freeBSD - 笔记
1 介绍 FreeBSD: FreeBSD是由FreeBSD项目团队开发的,最早可以追溯到1993年。它专注于性能、稳定性和可靠性,并在服务器和高性能计算环境中广泛使用。FreeBSD有着强大的网络性能和高度优化的TCP/IP协议栈,因此在网络服务器领域表…...
【Linux】网络基础——宏观认识计算机网络
1 计算机网络背景 网络发展 独立模式: 计算机之间相互独立; 一开始,计算机发明出来之后,一台计算机处理完的数据,数据会保存在软盘(物理),通过人之间的相互通信,把计算机A处理完的数据存储到软…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...

Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析
Autodesk Fusion 360在Linux上的技术实现与性能优化深度解析 【免费下载链接】Autodesk-Fusion-360-for-Linux This is a project, where I give you a way to use Autodesk Fusion 360 on Linux! 项目地址: https://gitcode.com/gh_mirrors/au/Autodesk-Fusion-360-for-Linu…...

从XAI到HXAI:构建以人为中心的可解释AI框架与实践
1. 项目概述:从“黑箱”到“白盒”,构建可信AI的演进之路在机器学习项目里摸爬滚打了十几年,我见过太多因为模型“说不清道不明”而引发的信任危机。一个在测试集上表现完美的信用评分模型,可能因为无法向风控专家解释“为什么拒绝…...

软件测试行业的未来趋势:这3类测试将成为主流
随着数字化转型的深入推进,软件已经成为驱动各行业变革的核心生产力,从自动驾驶汽车到企业级云原生平台,从智慧医疗设备到工业互联网系统,软件的复杂度、规模和对安全性的要求都在呈指数级增长。作为软件质量保障的核心环节&#…...