【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试
相关博客
【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试
【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装mappings
【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
【深度学习】混合精度训练与显存分析
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
Megatron-DeepSpeed是DeepSpeed版本的NVIDIA Megatron-LM。像BLOOM、GLM-130B等主流大模型都是基于Megatron-DeepSpeed开发的。这里以BLOOM版本的Megetron-DeepSpeed为例,介绍其模型并行代码mpu的细节(位于megatron/mpu下)。
理解该部分的代码需要对模型并行的原理以及集合通信有一定的理解,可以看文章:
- 【深度学习】【分布式训练】Collective通信操作及Pytorch示例
- 【深度学习】【分布式训练】一文捋顺千亿模型训练技术:流水线并行、张量并行和3D并行
- 【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
强烈建议阅读,不然会影响本文的理解:
- 【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
- 【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装mappings
阅读建议:
- 本文仅会解析核心代码,并会不介绍所有代码;
- 本文会提供一些测试脚本来展现各部分代码的功能;
- 建议实际动手实操来加深理解;
- 建议对Collective通信以及分布式模型训练有一定理解,再阅读本文;
一、总览
mpu目录下核心文件有:
- initialize.py:负责数据并行组、张量并行组和流水线并行组的初始化,以及获取与各类并行组相关的信息;
- data.py:实现张量并行中的数据广播功能;
- cross_entropy.py:张量并行版本的交叉熵;
- layers.py:并行版本的Embedding层,以及列并行线性层和行并行线性层;
- mappings.py:用于张量并行的通信操作;
二、1D张量并行原理
Megatron-DeepSpeed中的并行是1D张量并行,这里做简单的原理介绍。希望更深入全面的理解并行技术,可以阅读上面“千亿模型训练技术”的文章。
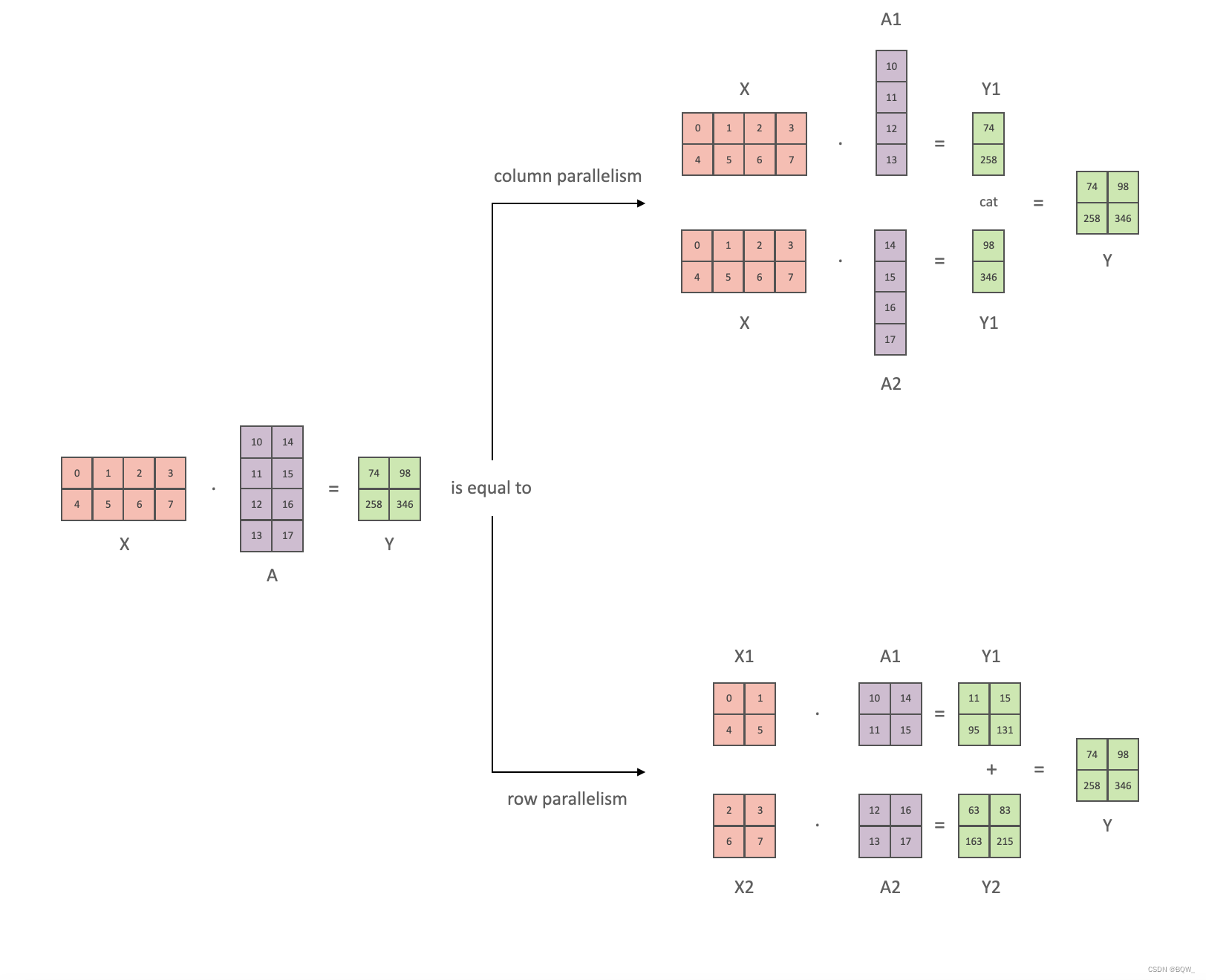
以全链接层 Y = X A Y=XA Y=XA为例,介绍1D张量并行。其中, X X X和 Y Y Y是输入和输出向量, A A A是权重矩阵。总量来说1D张量并行可以分为列并行和行并行(以权重矩阵的分割方式命名),上图展示了两种并行。
-
列并行
将矩阵行列划分为n份(不一定必须相等大小)可以表示为 A = [ A 1 , A 2 , … , A n ] A=[A_1,A_2, \dots, A_n] A=[A1,A2,…,An],那么矩阵乘法表示为
X A = X [ A 1 , A 2 , … , A n ] = [ X A 1 , X A 2 , … , X A n ] XA=X[A_1,A_2,\dots,A_n]=[XA_1,XA_2,\dots,XA_n] XA=X[A1,A2,…,An]=[XA1,XA2,…,XAn]
显然,仅需要对权重进行划分。 -
行并行
对权重进行划分,那么必须对输入矩阵也进行划分。假设要将 A A A水平划分为 n n n份,则输入矩阵 X X X必须垂直划分为 n n n份,矩阵乘法表示为
X A = [ X 1 , X 2 , … , X n ] [ A 1 A 2 … A n ] = X 1 A 1 + X 2 A 2 + ⋯ + X n A n XA=[X_1,X_2,\dots,X_n] \left[ \begin{array}{l} A_1 \\ A_2 \\ \dots \\ A_n \end{array} \right] = X_1A_1+X_2A_2+\dots+X_nA_n XA=[X1,X2,…,Xn] A1A2…An =X1A1+X2A2+⋯+XnAn
三、张量并行的实现及测试
1. 列并行
列并行在前向传播时,张量并行组中的进程独立前向传播即可。假设张量并行度为2,则神经网络的前向传播可以简单表示为:
loss = f ( Y ) = f ( [ Y 1 , Y 2 ] ) = f ( [ X A 1 , X A 2 ] ) \begin{aligned} \text{loss}&=f(Y) = f([Y_1,Y_2]) \\ &=f([XA_1,XA_2]) \\ \end{aligned} loss=f(Y)=f([Y1,Y2])=f([XA1,XA2])
反向传播时, loss \text{loss} loss对输入 X X X的梯度为
KaTeX parse error: Undefined control sequence: \part at position 8: \frac{\̲p̲a̲r̲t̲ ̲f}{\part X}=\fr…
因此,反向传播时需要对张量并行组中各个独立的梯度进行求和。
源代码
class ColumnParallelLinear(torch.nn.Module):"""列并行线性层.线性层定义为Y=XA+b. A沿着第二维进行并行,A = [A_1, ..., A_p]参数:input_size: 矩阵A的第一维度.output_size: 矩阵A的第二维度.bias: 若为true则添加bias.gather_output: 若为true,在输出上调用all-gather,使得Y对所有GPT都可访问.init_method: 随机初始化方法.stride: strided线性层."""def __init__(self, input_size, output_size, bias=True, gather_output=True,init_method=init.xavier_normal_, stride=1,keep_master_weight_for_test=False,skip_bias_add=False):super(ColumnParallelLinear, self).__init__()self.input_size = input_sizeself.output_size = output_sizeself.gather_output = gather_output# 获得张量并行组的world_sizeworld_size = get_tensor_model_parallel_world_size()# 按照张量并行度(world_size)划分输出维度self.output_size_per_partition = divide(output_size, world_size)self.skip_bias_add = skip_bias_add# Parameters.# Note: torch.nn.functional.linear 执行 XA^T+bargs = get_args()if args.use_cpu_initialization:# 初始化张量. 若完整权重矩阵A为n*m,张量并行度为k,这里初始化的张量为n*(m/k)# 也就是张量并行组中的进程各自初始化持有的部分张量self.weight = Parameter(torch.empty(self.output_size_per_partition,self.input_size,dtype=args.params_dtype))# 使用init_method对权重矩阵self.weight进行随机初始化(CPU版)# self.master_weight在测试中使用,这里不需要关注self.master_weight = _initialize_affine_weight_cpu(self.weight, self.output_size, self.input_size,self.output_size_per_partition, 0, init_method,stride=stride, return_master_weight=keep_master_weight_for_test)else:self.weight = Parameter(torch.empty(self.output_size_per_partition, self.input_size,device=torch.cuda.current_device(), dtype=args.params_dtype))# 使用init_method对权重矩阵self.weight进行随机初始化(GPU版)_initialize_affine_weight_gpu(self.weight, init_method,partition_dim=0, stride=stride)if bias:# 实例化一个biasif args.use_cpu_initialization:self.bias = Parameter(torch.empty(self.output_size_per_partition, dtype=args.params_dtype))else:self.bias = Parameter(torch.empty(self.output_size_per_partition,device=torch.cuda.current_device(),dtype=args.params_dtype))# 将张量并行的相关信息追加至self.biasset_tensor_model_parallel_attributes(self.bias, True, 0, stride)# bias初始化为0with torch.no_grad():self.bias.zero_()else:self.register_parameter('bias', None)def forward(self, input_):# 前向传播时input_parallel就等于input_# 反向传播时在张量并在组内将梯度allreduceinput_parallel = copy_to_tensor_model_parallel_region(input_)bias = self.bias if not self.skip_bias_add else Noneoutput_parallel = F.linear(input_parallel, self.weight, bias)if self.gather_output:# 收集张量并行组内的张量并进行拼接# 此时,output是非张量并行情况下前向传播的输出# 张量并行组中的进程都持有完全相同的outputoutput = gather_from_tensor_model_parallel_region(output_parallel)else:# 此时,output是张量并行情况下的前向传播输出# 张量并行组中的进程持有不同的outputoutput = output_paralleloutput_bias = self.bias if self.skip_bias_add else Nonereturn output, output_bias
测试代码
测试遵循文章【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化 中的设置,张量并行度为2,且流水线并行度为2。
def test_column_parallel_linear():global_rank = torch.distributed.get_rank()tensor_model_parallel_size = mpu.get_tensor_model_parallel_world_size()# 设置随机数种子seed = 12345set_random_seed(seed)# 张量并行组中,各个进程持有张量的input_sizeinput_size_coeff = 4 ## 张量并行组中,各个进程持有张量的output_sizeinput_size = input_size_coeff * tensor_model_parallel_sizeoutput_size_coeff = 2output_size = output_size_coeff * tensor_model_parallel_size# 初始化一个产生二维张量的模拟网络,输入的张量为(batch_size, input_size)batch_size = 6identity_layer = IdentityLayer2D(batch_size, input_size).cuda()# 初始化一个列并行线性层linear_layer = mpu.ColumnParallelLinear(input_size, output_size, keep_master_weight_for_test=True, gather_output=False).cuda()# 随机初始化一个loss权重# 主要是为了计算标量的loss,从而验证梯度是否正确loss_weight = torch.randn([batch_size, output_size]).cuda()## 前向传播input_ = identity_layer()# 此时,张量并行组中各个进程持有的output仅是完整输出张量的一部分output = linear_layer(input_)[0]if torch.distributed.get_rank() == 0:print(f"> Output size without tensor parallel is ({batch_size},{output_size})")torch.distributed.barrier()info = f"*"*20 + \f"\n> global_rank={global_rank}\n" + \f"> output size={output.size()}\n"print(info, end="")
测试结果
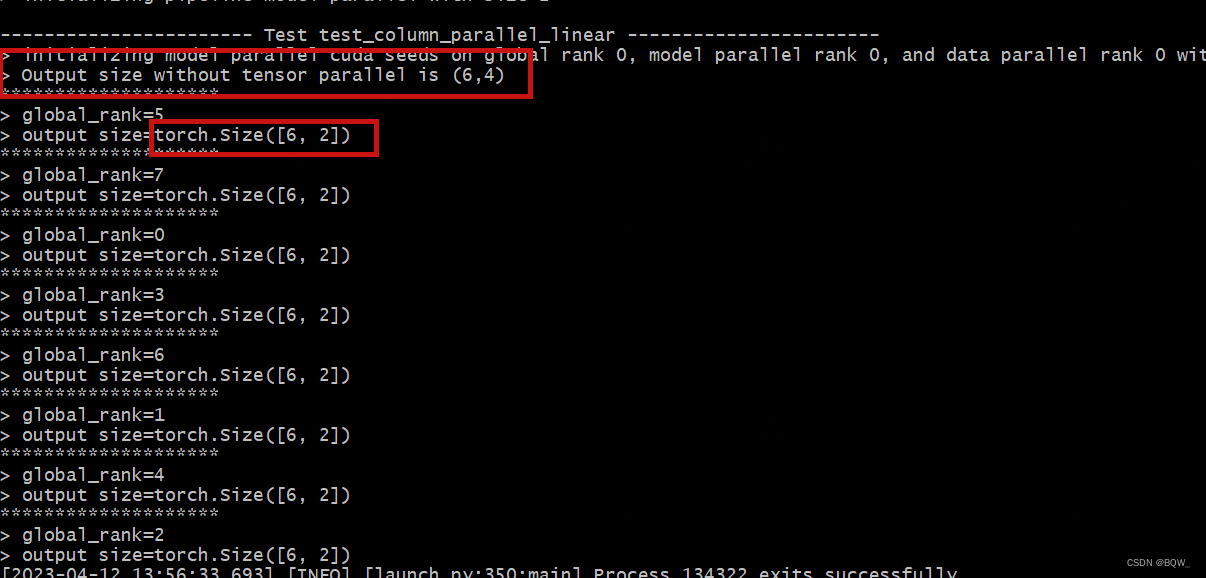
可以看到,没有并行情况下的期望输出为(6,4)。张量并行度为2的情况下,各个rank的输出维度为(6,2)。
2. 行并行
行并行在前向传播时,张量并行组中各个进程不仅要持有部分权重,也还持有部分的输入张量。前向传播的过程可以简单表示为
loss = f ( Y ) = f ( X A ) = f ( [ X 1 , X 2 ] [ A 1 A 2 ] ) = f ( [ X 1 A 1 + X 2 A 2 ] ) \begin{aligned} \text{loss}&=f(Y) =f(XA)\\ &= f([X_1,X_2]\left[ \begin{array}{l} A_1 \\ A_2 \\ \end{array} \right]) \\ &=f([X_1A_1+X_2A_2]) \\ \end{aligned} loss=f(Y)=f(XA)=f([X1,X2][A1A2])=f([X1A1+X2A2])
张量并行组中Rank0持有 X 1 X_1 X1和 A 1 A_1 A1,Rank1持有 X 2 X_2 X2和 A 2 A_2 A2,并在各自的GPU上完成前向传播后再合并起来。
反向传播的过程
KaTeX parse error: Undefined control sequence: \part at position 8: \frac{\̲p̲a̲r̲t̲ ̲f}{\part X_1} =…
源代码
class RowParallelLinear(torch.nn.Module):"""行并行线性层.线性层的定义为Y = XA + b. xA沿着第一个维度并行,X沿着第二个维度并行. 即- -| A_1 || . |A = | . | X = [X_1, ..., X_p]| . || A_p |- -参数:input_size: 矩阵A的第一维度.output_size: 矩阵A的第二维度.bias: 若为true则添加bias.input_is_parallel: 若为true,则认为输入应用被划分至各个GPU上,不需要进一步的划分.init_method: 随机初始化方法.stride: strided线性层."""def __init__(self, input_size, output_size, bias=True,input_is_parallel=False,init_method=init.xavier_normal_, stride=1,keep_master_weight_for_test=False,skip_bias_add=False):super(RowParallelLinear, self).__init__()self.input_size = input_sizeself.output_size = output_sizeself.input_is_parallel = input_is_parallel# 获得张量并行组的world_sizeworld_size = get_tensor_model_parallel_world_size()# 按照张量并行度(world_size)划分输出维度self.input_size_per_partition = divide(input_size, world_size)self.skip_bias_add = skip_bias_add# Parameters.# Note: torch.nn.functional.linear 执行 XA^T+bargs = get_args()if args.use_cpu_initialization:# 初始化张量. 若完整权重矩阵A为n*m,张量并行度为k,这里初始化的张量为n*(m/k)# 也就是张量并行组中的进程各自初始化持有的部分张量self.weight = Parameter(torch.empty(self.output_size,self.input_size_per_partition,dtype=args.params_dtype))# 使用init_method对权重矩阵self.weight进行随机初始化(CPU版)# self.master_weight在测试中使用,这里不需要关注self.master_weight = _initialize_affine_weight_cpu(self.weight, self.output_size, self.input_size,self.input_size_per_partition, 1, init_method,stride=stride, return_master_weight=keep_master_weight_for_test)else:self.weight = Parameter(torch.empty(self.output_size, self.input_size_per_partition,device=torch.cuda.current_device(), dtype=args.params_dtype))# 使用init_method对权重矩阵self.weight进行随机初始化(GPU版)_initialize_affine_weight_gpu(self.weight, init_method,partition_dim=1, stride=stride)if bias:# 实例化一个biasif args.use_cpu_initialization:self.bias = Parameter(torch.empty(self.output_size,dtype=args.params_dtype))else:self.bias = Parameter(torch.empty(self.output_size, device=torch.cuda.current_device(),dtype=args.params_dtype))# Always initialize bias to zero.with torch.no_grad():self.bias.zero_()else:self.register_parameter('bias', None)self.bias_tp_auto_sync = args.sync_tp_duplicated_parametersdef forward(self, input_):if self.input_is_parallel:input_parallel = input_else:# 前向传播时,将input_分片至张量并行组中的各个进程中# 反向传播时,将张量并行组中持有的部分input_梯度合并为完整的梯度# 此时,_input是完整的输入张量,input_parallel则是分片后的张量,即input_parallel!=_inputinput_parallel = scatter_to_tensor_model_parallel_region(input_)output_parallel = F.linear(input_parallel, self.weight)# 对张量并行组中的输出进行allreduce,即操作X1A1+X2A2output_ = reduce_from_tensor_model_parallel_region(output_parallel)if self.bias_tp_auto_sync:torch.distributed.all_reduce(self.bias, op=torch.distributed.ReduceOp.AVG, group=mpu.get_tensor_model_parallel_group())if not self.skip_bias_add:output = output_ + self.bias if self.bias is not None else output_output_bias = Noneelse:output = output_output_bias = self.biasreturn output, output_bias
测试代码
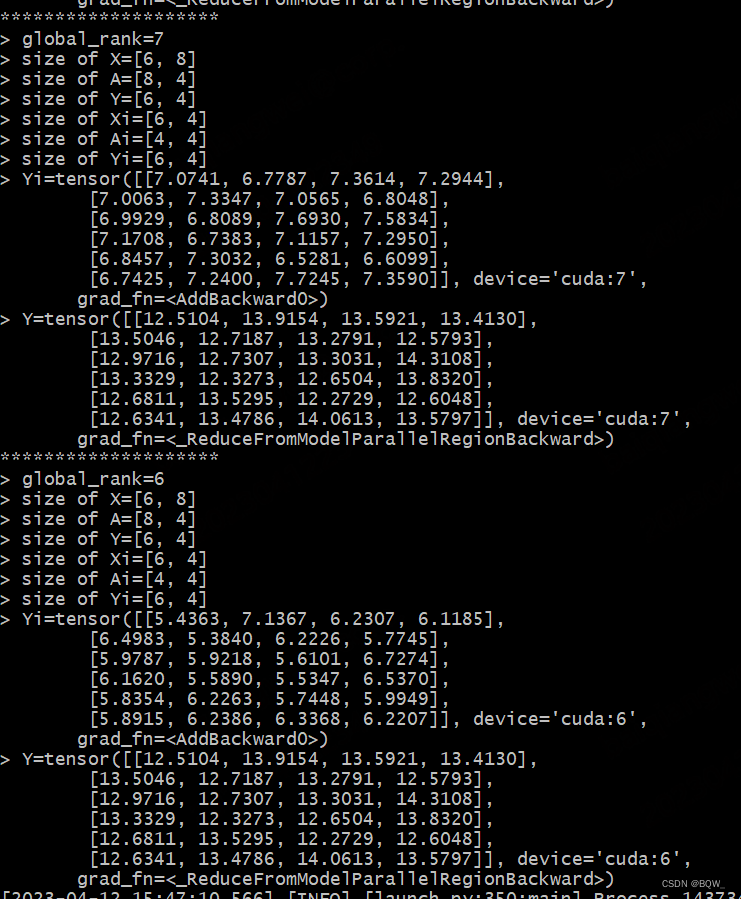
由于列并行层RowParallelLinear完成屏蔽了内部的并行细节,无法从输入输出中理解其执行过程。因此,这里的测试会对其forward方法进行重写,以便展现细节。
class MyRowParallelLinear(mpu.RowParallelLinear):def forward(self, input_):global_rank = torch.distributed.get_rank()# 输入X,权重A和输出Y的形状X_size = list(input_.size())A_size = [self.input_size, self.output_size]Y_size = [X_size[0], A_size[1]]if self.input_is_parallel:input_parallel = input_else:input_parallel = mpu.scatter_to_tensor_model_parallel_region(input_)Xi_size = list(input_parallel.size())Ai_size = list(self.weight.T.size())info = f"*"*20 + \f"\n> global_rank={global_rank}\n" + \f"> size of X={X_size}\n" + \f"> size of A={A_size}\n" + \f"> size of Y={Y_size}\n" + \f"> size of Xi={Xi_size}\n" + \f"> size of Ai={Ai_size}\n"output_parallel = F.linear(input_parallel, self.weight)# 通过在output_parallel保证不同rank的output_parallel,便于观察后续的结果output_parallel = output_parallel + global_rankYi_size = list(output_parallel.size())info += f"> size of Yi={Yi_size}\n" + \f"> Yi={output_parallel}\n"output_ = mpu.reduce_from_tensor_model_parallel_region(output_parallel)info += f"> Y={output_}"if self.bias_tp_auto_sync:torch.distributed.all_reduce(self.bias, op=torch.distributed.ReduceOp.AVG, group=mpu.get_tensor_model_parallel_group())if not self.skip_bias_add:output = output_ + self.bias if self.bias is not None else output_output_bias = Noneelse:output = output_output_bias = self.biasprint(info)return output, output_biasdef test_row_parallel_linear():global_rank = torch.distributed.get_rank()tensor_model_parallel_size = mpu.get_tensor_model_parallel_world_size()# 设置随机种子seed = 12345set_random_seed(seed)# 张量并行组中,各个进程持有张量的input_sizeinput_size_coeff = 4input_size = input_size_coeff * tensor_model_parallel_size# 张量并行组中,各个进程持有张量的output_sizeoutput_size_coeff = 2output_size = output_size_coeff * tensor_model_parallel_size# 初始化一个产生二维张量的模拟网络,输入的张量为(batch_size, input_size)batch_size = 6identity_layer = IdentityLayer2D(batch_size, input_size).cuda()# 初始化一个行并行线性层linear_layer = MyRowParallelLinear(input_size, output_size, keep_master_weight_for_test=True).cuda()# 前向传播input_ = identity_layer()output = linear_layer(input_)
测试结果
四、完整测试代码
# test_layers.py
import sys
sys.path.append("..")import os
import torch.nn.functional as F
from megatron import get_args
from megatron.mpu import layers
from megatron.initialize import _initialize_distributed
from megatron.global_vars import set_global_variables
from commons import set_random_seed
from commons import print_separator
from commons import initialize_distributed
import megatron.mpu as mpu
import torch.nn.init as init
from torch.nn.parameter import Parameter
import torch
import randomclass IdentityLayer2D(torch.nn.Module):"""模拟一个输入为二维张量的神经网络"""def __init__(self, m, n):super(IdentityLayer2D, self).__init__()self.weight = Parameter(torch.Tensor(m, n))torch.nn.init.xavier_normal_(self.weight)def forward(self):return self.weightdef test_column_parallel_linear():global_rank = torch.distributed.get_rank()tensor_model_parallel_size = mpu.get_tensor_model_parallel_world_size()# 设置随机数种子seed = 12345set_random_seed(seed)# 张量并行组中,各个进程持有张量的input_sizeinput_size_coeff = 4 ## 张量并行组中,各个进程持有张量的output_sizeinput_size = input_size_coeff * tensor_model_parallel_sizeoutput_size_coeff = 2output_size = output_size_coeff * tensor_model_parallel_size# 初始化一个产生二维张量的模拟网络,输入的张量为(batch_size, input_size)batch_size = 6identity_layer = IdentityLayer2D(batch_size, input_size).cuda()# 初始化一个列并行线性层linear_layer = mpu.ColumnParallelLinear(input_size, output_size, keep_master_weight_for_test=True, gather_output=False).cuda()# 随机初始化一个loss权重# 主要是为了计算标量的loss,从而验证梯度是否正确loss_weight = torch.randn([batch_size, output_size]).cuda()## 前向传播input_ = identity_layer()# 此时,张量并行组中各个进程持有的output仅是完整输出张量的一部分output = linear_layer(input_)[0]if torch.distributed.get_rank() == 0:print(f"> Output size without tensor parallel is ({batch_size},{output_size})")torch.distributed.barrier()info = f"*"*20 + \f"\n> global_rank={global_rank}\n" + \f"> output size={output.size()}\n"print(info, end="")class MyRowParallelLinear(mpu.RowParallelLinear):def forward(self, input_):global_rank = torch.distributed.get_rank()# 输入X,权重A和输出Y的形状X_size = list(input_.size())A_size = [self.input_size, self.output_size]Y_size = [X_size[0], A_size[1]]if self.input_is_parallel:input_parallel = input_else:input_parallel = mpu.scatter_to_tensor_model_parallel_region(input_)Xi_size = list(input_parallel.size())Ai_size = list(self.weight.T.size())info = f"*"*20 + \f"\n> global_rank={global_rank}\n" + \f"> size of X={X_size}\n" + \f"> size of A={A_size}\n" + \f"> size of Y={Y_size}\n" + \f"> size of Xi={Xi_size}\n" + \f"> size of Ai={Ai_size}\n"output_parallel = F.linear(input_parallel, self.weight)# 通过在output_parallel保证不同rank的output_parallel,便于观察后续的结果output_parallel = output_parallel + global_rankYi_size = list(output_parallel.size())info += f"> size of Yi={Yi_size}\n" + \f"> Yi={output_parallel}\n"output_ = mpu.reduce_from_tensor_model_parallel_region(output_parallel)info += f"> Y={output_}"if self.bias_tp_auto_sync:torch.distributed.all_reduce(self.bias, op=torch.distributed.ReduceOp.AVG, group=mpu.get_tensor_model_parallel_group())if not self.skip_bias_add:output = output_ + self.bias if self.bias is not None else output_output_bias = Noneelse:output = output_output_bias = self.biasprint(info)return output, output_biasdef test_row_parallel_linear():global_rank = torch.distributed.get_rank()tensor_model_parallel_size = mpu.get_tensor_model_parallel_world_size()# 设置随机种子seed = 12345set_random_seed(seed)# 张量并行组中,各个进程持有张量的input_sizeinput_size_coeff = 4input_size = input_size_coeff * tensor_model_parallel_size# 张量并行组中,各个进程持有张量的output_sizeoutput_size_coeff = 2output_size = output_size_coeff * tensor_model_parallel_size# 初始化一个产生二维张量的模拟网络,输入的张量为(batch_size, input_size)batch_size = 6identity_layer = IdentityLayer2D(batch_size, input_size).cuda()# 初始化一个行并行线性层linear_layer = MyRowParallelLinear(input_size, output_size, keep_master_weight_for_test=True).cuda()# 前向传播input_ = identity_layer()output = linear_layer(input_)def main():set_global_variables(ignore_unknown_args=True)_initialize_distributed()world_size = torch.distributed.get_world_size()print_separator('Test test_column_parallel_linear')test_column_parallel_linear()print_separator('Test test_row_parallel_linear')test_row_parallel_linear()if __name__ == '__main__':main()
启动脚本
# 除了tensor-model-parallel-size和pipeline-model-parallel-size以外,
# 其余参数仅为了兼容原始代码,保存没有报错.
options=" \--tensor-model-parallel-size 2 \--pipeline-model-parallel-size 2 \--num-layers 10 \--hidden-size 768 \--micro-batch-size 2 \--num-attention-heads 32 \--seq-length 512 \--max-position-embeddings 512\--use_cpu_initialization True"cmd="deepspeed test_layers.py $@ ${options}"eval ${cmd}
相关文章:
【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试
相关博客 【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试 【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化 【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装ma…...
【SpringBoot学习笔记】02. yaml配置注入
yaml配置注入 yaml基础语法 说明:语法要求严格! 1、空格不能省略 2、以缩进来控制层级关系,只要是左边对齐的一列数据都是同一个层级的。 3、属性和值的大小写都是十分敏感的。 yaml注入配置文件 1、在springboot项目中的resources目录…...

【初阶C语言】指针的妙用
前言:在C语言中,有一个非常重要的知识点,叫做指针,指针也是数据类型中的一种。在本节内容中,我们就一起来学习指针。 学习一个新知识的时候,我们需要从这几个方面:指针是什么,指针是…...
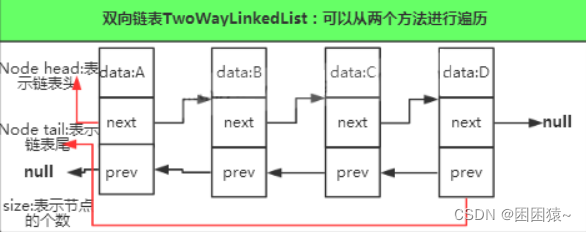
链表——LinkedList类的概述和实现
LinkedList类 1.1LinkedList类概述 LinkedList类底层是基于双向链表结构实现的,不同于ArrayList类和Vector类是基于数组实现的;LinkedList类是非线程安全的;LinkedList类元素允许为null,允许重复元素;LinkedList类插…...

快六一啦,学习CSS3实现一个冰淇淋动画特效
快六一啦,小时候顶多吃个小冰棍,或者是那种小冰袋,现在的小朋友真是好,动不动就能吃到冰淇淋,今天用CSS3实现一个冰淇淋的动画特效吧 目录 实现思路 桶身的实现 冰淇淋身体的实现 五彩颗粒的实现 HTML源码 CSS3源…...

VSCode CMake vcpkg 整合
VSCode 整合 CMake 调试 CMake 工程 // launch.json {"version": "0.2.0","configurations": [{"name": "(gdb) Launch","type": "cppdbg","request": "launch",// Resolved by …...

c++ | win vscode
vscode 适合新手做一些简单的单个的编译和调试 新手适合去配置c 环境,尤其是当涉及复杂一点的编程,如多文件、多线程,在调试的时候会头大,要求会高一点 但怎么说呢? c 编译和调试是最接近实际开发环境的,与…...

算法-快速排序
给你一个整数数组 nums,请你将该数组升序排列。 输入:nums [5,2,3,1] 输出:[1,2,3,5] 输入:nums [5,1,1,2,0,0] 输出:[0,0,1,1,2,5] 详细思路直接看我录制的视频吧 算法-快速排序_哔哩哔哩_bilibili class Soluti…...

SSM项目-博客系统
在线体验项目:登陆页面 项目连接:huhublog_ssm: 个人博客系统 技术栈:SpringBoot、SpringMVC、Mybatis、Redis、JQuery、Ajax、Json (gitee.com) 1.项目技术点分析 SpringBoot、SpringWeb(SpringMVC)、MyBatis、MySQL(8.x)、Redis(存储验…...

Android Gradle Plugin 编译
1. 源码下载: $ mkdir studio-main $ cd studio-main $ repo init -u https://android.googlesource.com/platform/manifest -b studio-main $ repo sync -c -j4 -q 这个官方网址让下载 studio-master-dev 分支,这个分支很老旧了,我这里直接…...
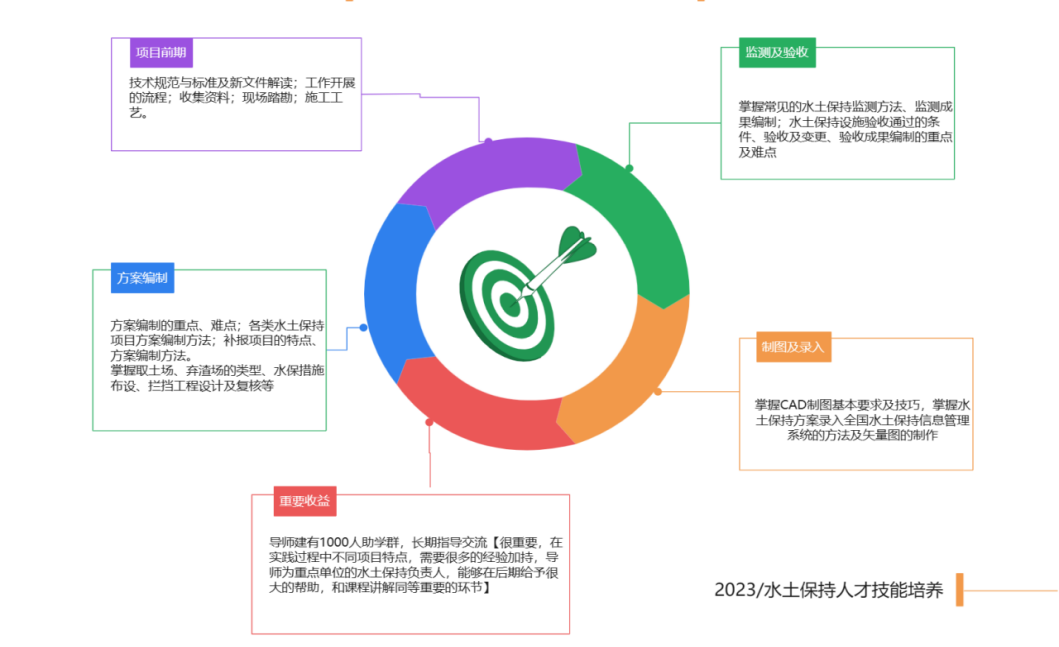
如何快速掌握水土保持方案编制
1、熟悉水土保持常用的主要法律法规、部委规章、规范性文件及技术规范与标准; 2、了解水土保持方案、监测及验收工作开展的流程; 3、熟悉水土保持方案、监测及验收工作需要收集的资料、现场踏勘注意事项; 4、熟悉常见水土保持工程施工工艺…...

前端笔试---acm模式
前言 之前一直刷力扣,昨天做了小红书笔试,发现是acm模式,不太熟悉,特此总结。其实如果是acm模式就需要自己写一下输入输出。前端一般有两个选择,一个是基于 V8 环境,另一个是基于 node。 V8 // 对于有多…...

国联易安网页防篡改保护系统“渠道招募”启动啦!
作为业内专注于保密与非密领域的分级保护、等级保护、业务连续性安全和大数据安全的领军企业,国联易安网页防篡改保护系统基于“高效同步”、“安全传输”两项技术,具备了独特的“五重防护”新特性,支持网页的全自动发布、网页监控、报警和自…...

JavaScript--WebStorage
目录 WebStorage概述 WebStorage分类 注意: localStorage方法 介绍: 常见方法: 案例演示: sessionStorage方法 介绍: 常见方法: 案例演示: WebStorage概述 WebStorage是HTML5中…...

elementui 的 dialog 常用逻辑总结
菜鸟最近写后台管理系统,发现不管是弹窗、还是编辑、查看、添加等功能,真的代码都差不多,但是每次都要重新写里面的关闭逻辑等,菜鸟就感觉不如搞一个模版,后面只关注于逻辑,其他都直接来这里复制了…...

ip网络广播系统网络音频解码终端公共广播SV-7101
SV-7101V网络音频终端产品简介 网络广播终端SV-7101V,接收网络音频流,实时解码播放。本设备只有网络广播功能,是一款简单的网络广播终端。提供一路线路输出接功放或有源音箱。 产品特点 ■ 提供固件网络远程升级■ 标准RJ45网络接口&…...

【Winform学习笔记(七)】Winform无边框窗体拖动功能
Winform无边框窗体拖动功能 前言正文1、设置无边框模式2、无边框窗体拖动方法1、通过Panel控件实现窗体移动2、通过窗体事件实现窗体移动3、调用系统API实现窗体移动4、重写WndProc()实现窗体移动 前言 在本文中主要介绍 如何将窗体设置成无边框模式、以及实现无边框窗体拖动功…...

【Nginx】静态资源部署、反向代理、负载均衡
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ nginx静态资源部署、反向代理、负载均衡 &…...

二、框架篇
框架篇 Spring 1. 基础核心技术 第1章-Spring的模块与应用场景 第2章-Spring基于XML配置的容器 第3章-Spring基于注解配置的容器 第4章-Spring基于Java配置的容器 第5章-Spring三种配置方式的混合和迁移 第6章-Spring同类型多个Bean的注入 第7章-Spring的Bean生命周期…...

[LitCTF 2023]Http pro max plus
打开环境后提示说,只允许在本地访问,本地访问,还是想到了XFF字段 好家伙的,直接被嘲讽,还是了解太少了,都不知道还有没有其他方式可以控制ip地址信息 经过查看wp,得知一种新的方式 Client-IP …...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...

从API Key管理视角看Taotoken平台的安全与审计功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API Key管理视角看Taotoken平台的安全与审计功能 对于依赖大模型API进行开发的团队而言,API Key的管理与安全是项目稳…...

如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造
如何快速上手Redux Dynamic Modules:5分钟完成Redux模块化改造 【免费下载链接】redux-dynamic-modules Modularize Redux by dynamically loading reducers and middlewares. 项目地址: https://gitcode.com/gh_mirrors/re/redux-dynamic-modules Redux Dyn…...