【机器学习】处理样本不平衡的问题
文章目录
- 样本不均衡的概念及影响
- 样本不均衡的解决方法
- 样本层面
- 欠采样 (undersampling)
- 过采样
- 数据增强
- 损失函数层面
- 模型层面
- 采样+集成学习
- 决策及评估指标
样本不均衡的概念及影响
机器学习中,样本不均衡问题经常遇到,比如在金融风险人员二分类问题中,绝大部分的样本均为正常人群,可用的风险样本较少。如果拿全量样本去训练一个严重高准确率的二分类模型,那结果毫无疑问会严重偏向于正常人群,从而导致模型的失效,所以说,训练样本比例均衡对模型的结果准确性至关重要。
首先来看概念:
【样本不均衡】所谓的样本不平衡问题指的是数据集中正负样本比例极不均衡,样本比例超过4:1的数据就可以称为不平衡数据。
样本不均衡的解决方法
常用的解决方法主要从样本层面、损失函数层面、模型层面以及评价指标等4方面进行优化。
样本层面
欠采样 (undersampling)
imblearn
imblearn库中的欠采样方法包含:

- 随机欠采样
下面是一个使用随机欠采样的示例代码:
from imblearn.under_sampling import RandomUnderSampler# 创建RandomUnderSampler对象
sampler = RandomUnderSampler(random_state=42)# 对训练数据进行欠采样
X_resampled, y_resampled = sampler.fit_resample(X_train, y_train)
在上述代码中,X_train和y_train分别表示训练数据的特征和标签。fit_resample()方法将返回欠采样后的特征和标签。
2.集群中心欠采样
集群中心选择欠采样(Cluster Centroids Undersampling):这是一种基于聚类的欠采样方法,它通过聚类算法将多数类别样本聚集到少数类别样本的中心点,从而减少多数类别的数量。同样地,可以使用imbalanced-learn库来实现集群中心选择欠采样。
下面是一个使用集群中心选择欠采样的示例代码:
from imblearn.under_sampling import ClusterCentroids# 创建ClusterCentroids对象
sampler = ClusterCentroids(random_state=42)# 对训练数据进行欠采样
X_resampled, y_resampled = sampler.fit_resample(X_train, y_train)
在上述代码中,X_train和y_train分别表示训练数据的特征和标签。fit_resample()方法将返回欠采样后的特征和标签。
这些方法都可以根据具体情况选择合适的欠采样策略。值得注意的是,欠采样可能会导致信息丢失,因此在应用欠采样之前,需要仔细评估其对模型性能的影响,并选择适当的评估指标来评估模型的效果。
过采样
过采样(Oversampling)是一种处理样本不均衡问题的方法,它通过增加少数类别样本的数量来平衡数据集。在Python中,有多种过采样方法可供选择。以下是几种常用的过采样方法及其示例代码:
1. 复制样本(Duplicate Samples):这是一种简单直接的过采样方法,它通过复制少数类别样本来增加其数量。
import numpy as np# 找出少数类别样本的索引
minority_indices = np.where(y == minority_class_label)[0]# 复制少数类别样本
duplicated_samples = X[minority_indices]# 将复制的样本添加到原始数据集中
X_oversampled = np.concatenate((X, duplicated_samples), axis=0)
y_oversampled = np.concatenate((y, np.ones(len(duplicated_samples))), axis=0)
在上述代码中,X和y分别表示原始数据集的特征和标签。minority_class_label是少数类别的标签。通过复制少数类别样本并将其添加到原始数据集中,我们可以实现过采样。
2.SMOTE(Synthetic Minority Over-sampling Technique):SMOTE是一种基于合成样本的过采样方法,它通过在特征空间中插入新的合成样本来增加少数类别样本的数量。
from imblearn.over_sampling import SMOTE# 创建SMOTE对象
smote = SMOTE(random_state=42)# 对训练数据进行过采样
X_oversampled, y_oversampled = smote.fit_resample(X_train, y_train)
在上述代码中,X_train和y_train分别表示训练数据的特征和标签。fit_resample()方法将返回过采样后的特征和标签。
3. ADASYN(Adaptive Synthetic Sampling):ADASYN是一种基于合成样本的自适应过采样方法,它根据样本密度来生成合成样本,更关注于那些在决策边界附近的少数类别样本。
from imblearn.over_sampling import ADASYN# 创建ADASYN对象
adasyn = ADASYN(random_state=42)# 对训练数据进行过采样
X_oversampled, y_oversampled = adasyn.fit_resample(X_train, y_train)
在上述代码中,X_train和y_train分别表示训练数据的特征和标签。fit_resample()方法将返回过采样后的特征和标签。
这些方法都可以根据具体情况选择合适的过采样策略。需要注意的是,过采样可能会导致模型对少数类别样本过拟合的问题,因此在应用过采样之前,需要仔细评估其对模型性能的影响,并选择适当的评估指标来评估模型的效果。
数据增强
损失函数层面
损失函数层面主流的方法也就是常用的代价敏感学习(cost-sensitive),为不同的分类错误给予不同惩罚力度(权重),在调节类别平衡的同时,也不会增加计算复杂度。如下常用方法:
这最常用也就是scikit模型的’class weight‘方法,If ‘balanced’, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform.,class weight可以为不同类别的样本提供不同的权重(少数类有更高的权重),从而模型可以平衡各类别的学习。如下图通过为少数类做更高的权重,以避免决策偏重多数类的现象(类别权重除了设定为balanced,还可以作为一个超参搜索。示例代码请见github.com/aialgorithm):

clf2 = LogisticRegression(class_weight={0:1,1:10}) # 代价敏感学习
模型层面
模型方面主要是选择一些对不均衡比较不敏感的模型,比如,对比逻辑回归模型(lr学习的是全量训练样本的最小损失,自然会比较偏向去减少多数类样本造成的损失),决策树在不平衡数据上面表现相对好一些,树模型是按照增益递归地划分数据(如下图),划分过程考虑的是局部的增益,全局样本是不均衡,局部空间就不一定,所以比较不敏感一些(但还是会有偏向性).
采样+集成学习
BalanceCascade
BalanceCascade基于Adaboost作为基分类器,核心思路是在每一轮训练时都使用多数类与少数类数量上相等的训练集,然后使用该分类器对全体多数类进行预测,通过控制分类阈值来控制FP(False Positive)率,将所有判断正确的类删除,然后进入下一轮迭代继续降低多数类数量。
在Python中,BalanceCascade是一个用于处理样本不均衡问题的集成学习方法,它基于级联分类器。BalanceCascade通过多次迭代地训练和删除错误分类的样本来减少多数类别的数量,从而实现欠采样。
你可以使用imbalanced-learn库来实现BalanceCascade方法。下面是一个使用BalanceCascade的示例代码:
python
from imblearn.ensemble import BalanceCascade
from sklearn.tree import DecisionTreeClassifier# 创建BalanceCascade对象,并指定基分类器
bc = BalanceCascade(estimator=DecisionTreeClassifier(random_state=42))# 对训练数据进行欠采样
X_resampled, y_resampled = bc.fit_resample(X_train, y_train)
在上述代码中,X_train和y_train分别表示训练数据的特征和标签。fit_resample()方法将返回欠采样后的特征和标签。
BalanceCascade方法会自动进行多轮迭代,每轮迭代都会训练一个基分类器,并删除错误分类的样本。这样,多数类别的样本数量会逐步减少,直到达到平衡。
请注意,BalanceCascade方法可能需要较长的时间来运行,因为它涉及多轮迭代和训练多个分类器。此外,选择合适的基分类器也是很重要的,你可以根据具体情况选择适合的分类器。
你可以在imbalanced-learn官方文档中找到更多关于BalanceCascade方法的详细信息和示例代码。
EasyEnsemble
EasyEnsemble也是基于Adaboost作为基分类器,就是将多数类样本集随机分成 N 个子集,且每一个子集样本与少数类样本相同,然后分别将各个多数类样本子集与少数类样本进行组合,使用AdaBoost基分类模型进行训练,最后bagging集成各基分类器,得到最终模型。示例代码可见:http://www.kaggle.com/orange90/ensemble-test-credit-score-model-example
在Python中,EasyEnsemble是一种用于处理样本不均衡问题的集成学习方法。它通过将原始数据集划分为多个子集,并在每个子集上训练一个基分类器来实现欠采样。
你可以使用imbalanced-learn库来实现EasyEnsemble方法。下面是一个使用EasyEnsemble的示例代码:
from imblearn.ensemble import EasyEnsemble
from sklearn.tree import DecisionTreeClassifier# 创建EasyEnsemble对象,并指定基分类器和子集数量
ee = EasyEnsemble(n_estimators=10, base_estimator=DecisionTreeClassifier(random_state=42))# 对训练数据进行欠采样
X_resampled, y_resampled = ee.fit_resample(X_train, y_train)
在上述代码中,X_train和y_train分别表示训练数据的特征和标签。n_estimators参数表示要生成的子集数量,base_estimator参数表示用于训练每个子集的基分类器。
EasyEnsemble方法会生成多个子集,并在每个子集上训练一个基分类器。最终的预测结果是所有基分类器的投票结果或平均结果,以达到平衡样本不均衡的效果。
请注意,EasyEnsemble方法可能需要较长的时间来运行,因为它涉及生成多个子集并训练多个分类器。同样地,选择合适的基分类器也是很重要的,你可以根据具体情况选择适合的分类器。
你可以在imbalanced-learn官方文档中找到更多关于EasyEnsemble方法的详细信息和示例代码。
通常,在数据集噪声较小的情况下,可以用BalanceCascade,可以用较少的基分类器数量得到较好的表现(基于串行的集成学习方法,对噪声敏感容易过拟合)。噪声大的情况下,可以用EasyEnsemble,基于串行+并行的集成学习方法,bagging多个Adaboost过程可以抵消一些噪声影响。此外还有RUSB、SmoteBoost、balanced RF等其他集成方法可以自行了解。
决策及评估指标
在处理不平衡样本问题时,传统的评价指标(如准确率)可能会给出误导性的结果。因此,为了更准确地评估模型在不平衡数据上的性能,我们通常使用以下评价指标:
1.混淆矩阵(Confusion Matrix):混淆矩阵是一个二维矩阵,用于显示分类器在每个类别上的预测结果。它包含四个重要的指标:真阳性(True Positive, TP),真阴性(True Negative, TN),假阳性(False Positive, FP)和假阴性(False Negative, FN)。根据这些指标,可以计算其他评价指标。
2.精确率(Precision):精确率是指模型预测为正例的样本中,实际为正例的比例。它可以通过以下公式计算:Precision = TP / (TP + FP)。精确率越高,表示模型对于正例的判断越准确。
3.召回率(Recall):召回率是指实际为正例的样本中,模型正确预测为正例的比例。它可以通过以下公式计算:Recall = TP / (TP + FN)。召回率越高,表示模型对于正例的识别能力越强。
4.F1值(F1-Score):F1值是精确率和召回率的调和平均值,用于综合评估模型的性能。它可以通过以下公式计算:F1 = 2 * (Precision * Recall) / (Precision + Recall)。F1值越高,表示模型在精确率和召回率之间取得了更好的平衡。
5.ROC曲线和AUC(Receiver Operating Characteristic Curve and Area Under the Curve):ROC曲线是以假阳性率(False Positive Rate, FPR)为横轴,真阳性率(True Positive Rate, TPR)为纵轴绘制的曲线。AUC表示ROC曲线下的面积,用于衡量模型在不同阈值下的分类性能。AUC的取值范围在0到1之间,越接近1表示模型性能越好。
以上评价指标可以帮助我们更全面地评估模型在不平衡样本上的性能。根据具体问题的需求,选择适当的评价指标来评估模型的效果是非常重要的。
相关文章:
【机器学习】处理样本不平衡的问题
文章目录 样本不均衡的概念及影响样本不均衡的解决方法样本层面欠采样 (undersampling)过采样数据增强 损失函数层面模型层面采样集成学习 决策及评估指标 样本不均衡的概念及影响 机器学习中,样本不均衡问题经常遇到,比如在金融…...
Android前沿技术?Jetpack如何?
Jetpack Compose是Android开发领域的一项前沿技术,它提供了一种全新的方式来构建用户界面。近年来,Jetpack Compose在各大招聘等网站上的招聘岗位逐渐增多,薪资待遇也相应提高。本文将从招聘岗位的薪资与技术要求入手,分析Jetpack…...

为react项目添加开发/提交规范(前端工程化、eslint、prettier、husky、commitlint、stylelint)
因历史遗留原因,接手的项目没有代码提醒/格式化,包括 eslint、pretttier,也没有 commit 提交校验,如 husky、commitlint、stylelint,与其期待自己或者同事的代码写得完美无缺,不如通过一些工具来进行规范和…...
)
小研究 - MySQL 数据库安全加固技术的研究(一)
随着信息系统的日益普及,后台数据库的安全问题逐步被人们重视起来。以当下热门的MySQL 数据库为例,通过分析数据库的安全机制以及总结数据库面临的安全风险,针对性地提出了相应的加固策略,为数据库的安全加固工作提供了技术支撑。…...

linux安装redis带图详细
如何在Linux系统中卸载Redis 一、使用apt-get卸载Redis sudo apt-get purge redis-server如果使用apt-get安装Redis,可以使用apt-get purge命令完全卸载Redis。其中,purge命令会不仅仅删除Redis二进制文件,还会删除配置文件、数据文件和日志…...

MySql——数据库常用命令
一、关于数据库的操作 查看mysql中有哪些数据库 show databases;显示创建指定数据库MySQL语句 SHOW CREATE DATABASE 数据库名:使用指定数据库 use 数据库名;查看当前使用的是哪个数据库 select database();查看指定数据库下有哪些表 use 数据库名; -- 先选择…...
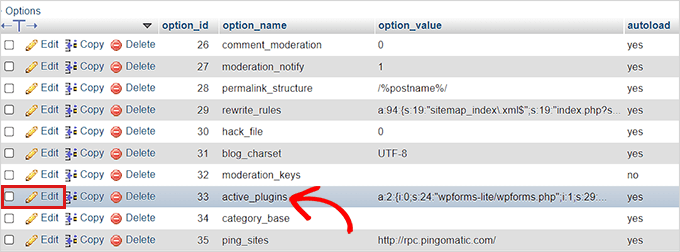
如何通过 WordPress 数据库启用插件?【进不去后台可用】
如果您无法访问 WordPress 后台并需要激活插件以恢复访问权限,则可以通过 WordPress 数据库来实现。本文将向您展示如何使用数据库轻松激活 WordPress 插件。 何时使用数据库激活 WordPress 插件? 许多常见的 WordPress 错误会阻止网站所有者访问 WordP…...

芯片热处理设备 HTR-4立式4寸快速退火炉
HTR-4立式4寸快速退火炉 HTR-4立式4寸快速退火炉(芯片热处理设备)广泛应用在IC晶圆、LED晶圆、MEMS、化合物半导体和功率器件等多种芯片产品的生产,和欧姆接触快速合金、离子注入退火、氧化物生长、消除应力和致密化等工艺当中,通…...

小研究 - 基于 MySQL 数据库的数据安全应用设计(一)
信息系统工程领域对数据安全的要求比较高,MySQL 数据库管理系统普遍应用于各种信息系统应用软件的开发之中,而角色与权限设计不仅关乎数据库中数据保密性的性能高低,也关系到用户使用数据库的最低要求。在对数据库的安全性进行设计时…...

mysql转sqlite3
在项目中需要将mysql迁移到sqlite3中,此时需要作数据转换 准备工作 下载mysql2sqlite转换工具 https://github.com/dumblob/mysql2sqlite/archive/refs/heads/master.zip 下载sqlite3 https://www.sqlite.org/download.html 转换 命令行中输入如下命令 1、cd …...

在linux中使用 ./configure 时报错
./configure --build编译平台 --host运行平台 --target目标平台 1. configure: error: cannot guess build type; you must specify one 解决办法:指定编译平台 ./configure --buildarm 2. configure: error: Either a previously installed…...

【LeetCode 算法】Reverse String 反转字符串
文章目录 Reverse String 反转字符串问题描述:分析代码双指针 Tag Reverse String 反转字符串 问题描述: 编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。 不要给另外的数组分配额外的空间,…...

linux sysctl.conf 常用参数配置
kernel.sysrq 0 kernel.core_uses_pid 1 kernel.msgmnb 65536#默认为16384,调高 kernel.msgmax 65536#默认为16384,调高 kernel.shmmax 68719476736#以sctl -a实际查询出的为准 kernel.shmall 4294967296#以sctl -a实际查询出的为准 net.ipv4.ip_f…...
【stm32】初识stm32—stm32环境的搭建
文章目录 🛸stm32资料分享🍔stm32是什么🎄具体过程🏳️🌈安装驱动🎈1🎈2 🏳️🌈建立Start文件夹 🛸stm32资料分享 我用夸克网盘分享了「STM32入门教程资料…...
:Web 开发)
Spring Boot3.0基础篇(二):Web 开发
Web 开发 Spring Boot Web 开发非常的简单,其中包括常用的 json 输出、filters、property、log 等 json 接口开发 在以前使用 Spring 开发项目,需要提供 json 接口时需要做哪些配置呢 添加 jackjson 等相关 jar 包配置 Spring Controller 扫描对接的方…...
音频轨)
【WebRTC---源码篇】(三:一)音频轨
音频轨的创建时序在Conductor::AddTracks()中 rtc::scoped_refptr<webrtc::AudioTrackInterface> audio_track(peer_connection_factory_->CreateAudioTrack(kAudioLabel, peer_connection_factory_->CreateAudioSource(cricket::AudioOptions()))); 通过代码我们…...

POM文件总体配置详细说明
今天跑一个项目,报错显示他的pom文件有问题,需要一个标准的pom文件对比,希望能帮到各位! <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" …...
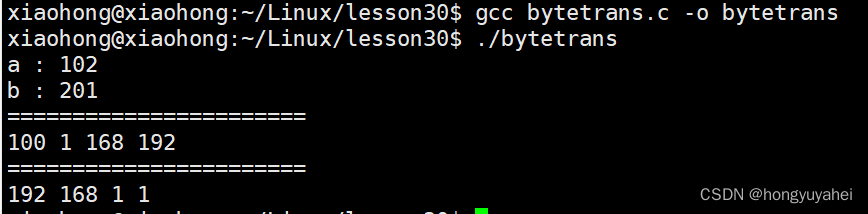
【项目 计网3】Socket介绍 4.9字节序 4.10字节序转换函数
文章目录 4.8 Socket介绍4.9字节序简介字节序举例 4.10字节序转换函数 4.8 Socket介绍 所谓 socket(套接字),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进…...

Spring Security 和 Apache Shiro 登录安全架构选型
Spring Security和Apache Shiro都是广泛使用的Java安全框架,它们都提供了许多功能来保护应用程序的安全性,包括身份验证、授权、加密、会话管理等。 Spring Security和Apache Shiro都是非常常用的登录安全框架,两者在登录安全架构的选型上各有特点: Sp…...
如何恢复已删除的 PDF 文件 - Windows 11、10
在传输数据或共享专业文档时,大多数人依赖PDF文件格式,但很少知道如何恢复意外删除或丢失的PDF文件。这篇文章旨在解释如何有效地恢复 PDF 文件。如果您身边有合适的数据恢复工具,PDF 恢复并不像看起来那么复杂。 便携式文档格式(…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

UE5项目打包后RenderTarget导出图片全黑?手把手教你解决伽马校正与资产打包问题
UE5打包后RenderTarget导出图片全黑的终极解决方案当你花了整整三天时间调试RenderTarget导出功能,终于在编辑器里看到完美的截图效果,却在打包成可执行文件后发现所有导出的图片都变成了一片漆黑——这种从云端跌入谷底的感觉,每个UE开发者都…...

AI专著生成必备工具,轻松撰写20万字专著,质量与效率双保障!
学术专著的写作是一个严谨的过程,其背后需要大量的资料和数据作为基础。搜集和整理这些资料与数据往往是写作过程中最繁琐且耗时的部分。研究人员需要广泛收集国内外的前沿文献,确保所用文献不仅具备权威性,还要与研究主题密切相关。同时&…...