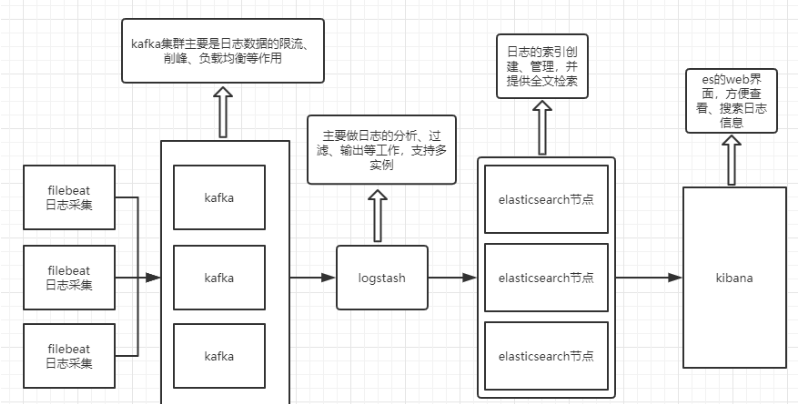
EFLFK——ELK日志分析系统+kafka+filebeat架构
环境准备
| node1节点 | 192.168.40.16 | elasticsearch | 2c/4G |
| node2节点 | 192.168.40.17 | elasticsearch | 2c/4G |
| Apache节点 | 192.168.40.170 | logstash/Apache/kibana | 2c/4G |
| filebeat节点 | 192.168.40.20 | filebeat | 2c/4G |
https://blog.csdn.net/m0_57554344/article/details/132059066?spm=1001.2014.3001.5501
接上期elk部署我们这次加一个filebeat节点
实验:
在filebeat节点上操作
1.安装 Filebeat
#上传软件包 filebeat-6.2.4-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.2.4-linux-x86_64.tar.gz
mv filebeat-6.2.4-linux-x86_64/ /usr/local/filebeat

2.设置 filebeat 的主配置文件
cd /usr/local/filebeatvim filebeat.yml
filebeat.prospectors:
- type: log #指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/messages #指定监控的日志文件- /var/log/*.logfields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: logservice_id: 192.168.40.20--------------Elasticsearch output-------------------
(全部注释掉)----------------Logstash output---------------------
output.logstash:hosts: ["192.168.40.170:5044"] #指定 logstash 的 IP 和端口#启动 filebeat
./filebeat -e -c filebeat.yml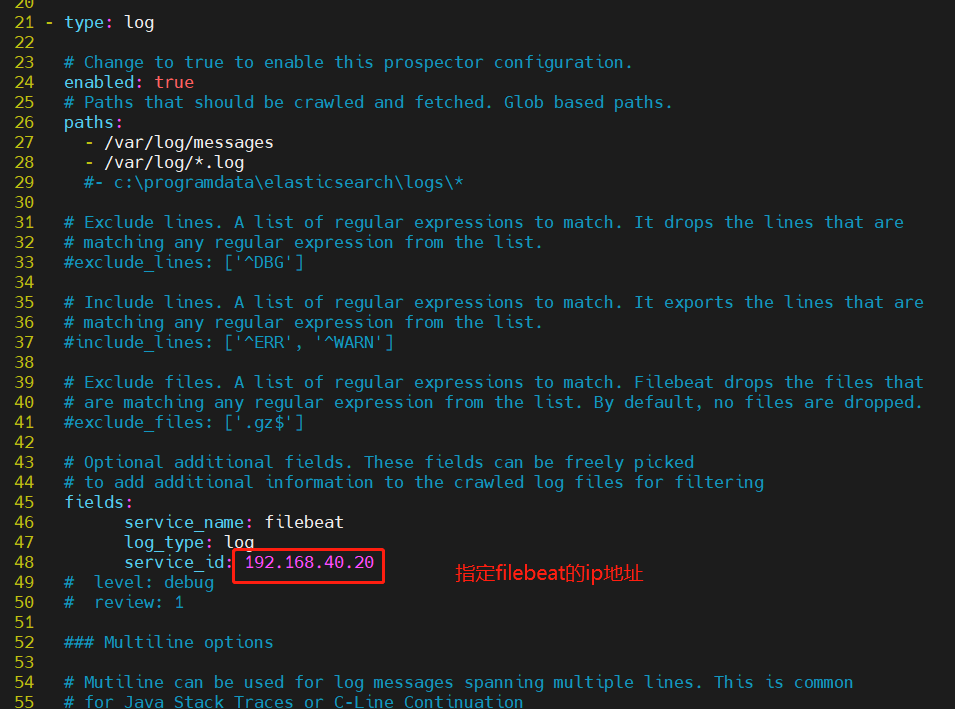

4.在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.dvim logstash.conf
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["192.168.40.16:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}#启动 logstash
logstash -f logstash.conf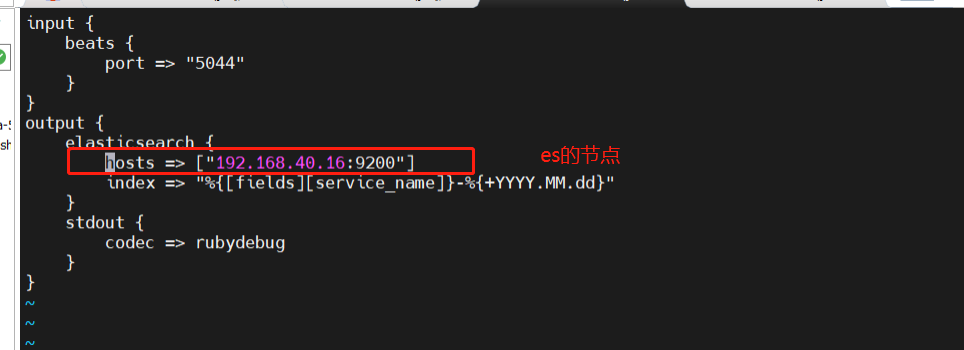
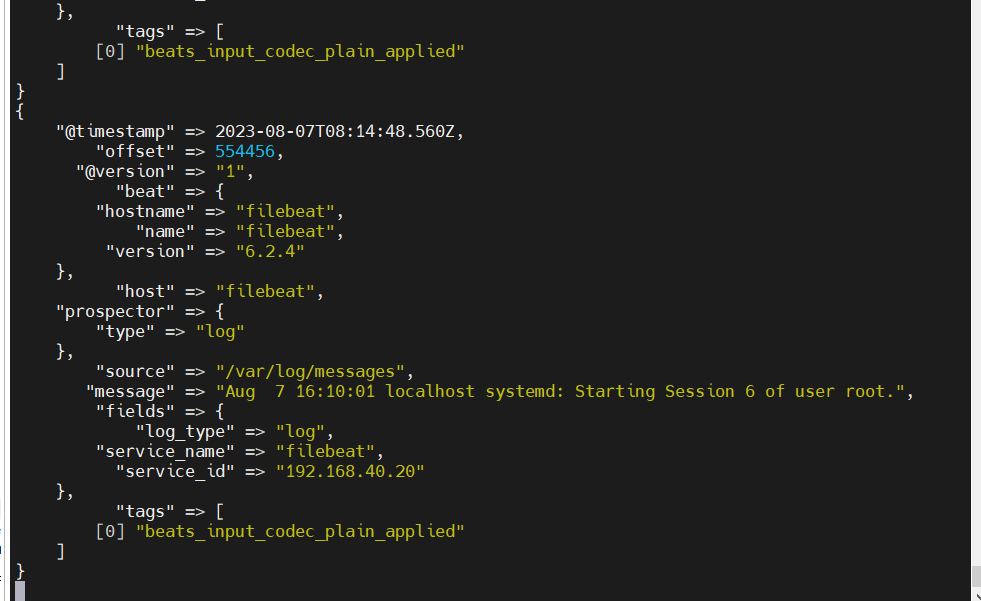
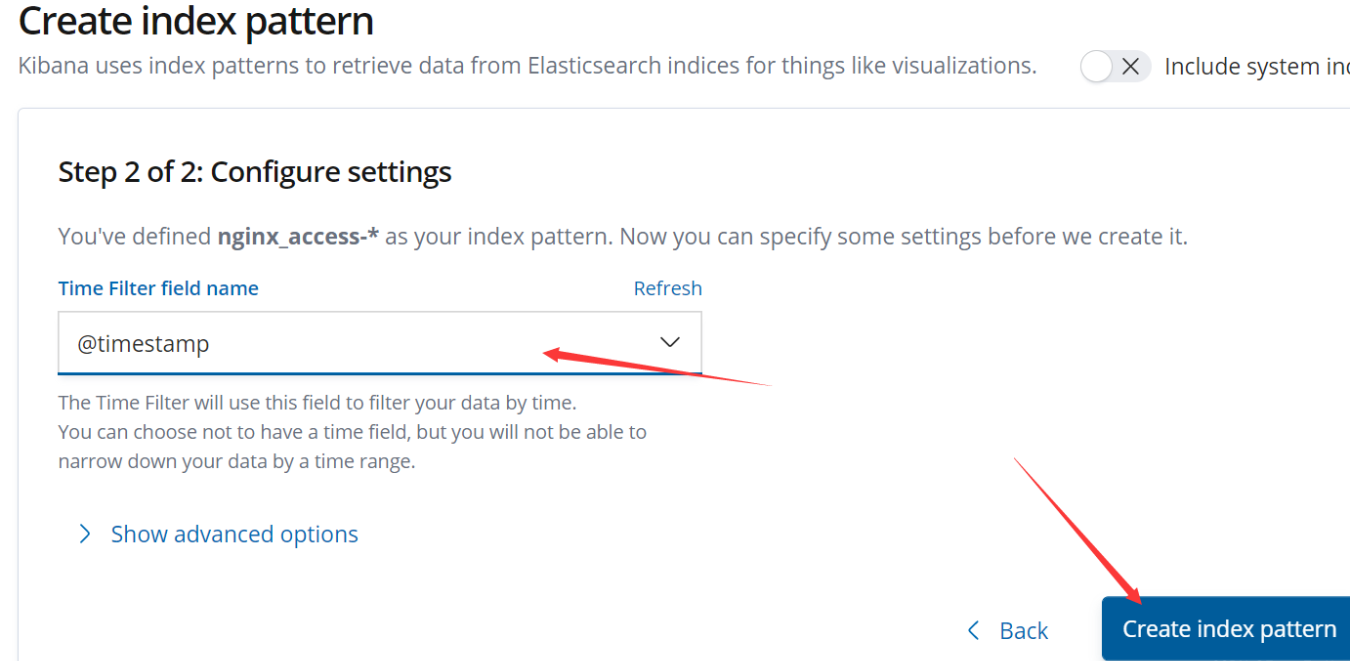
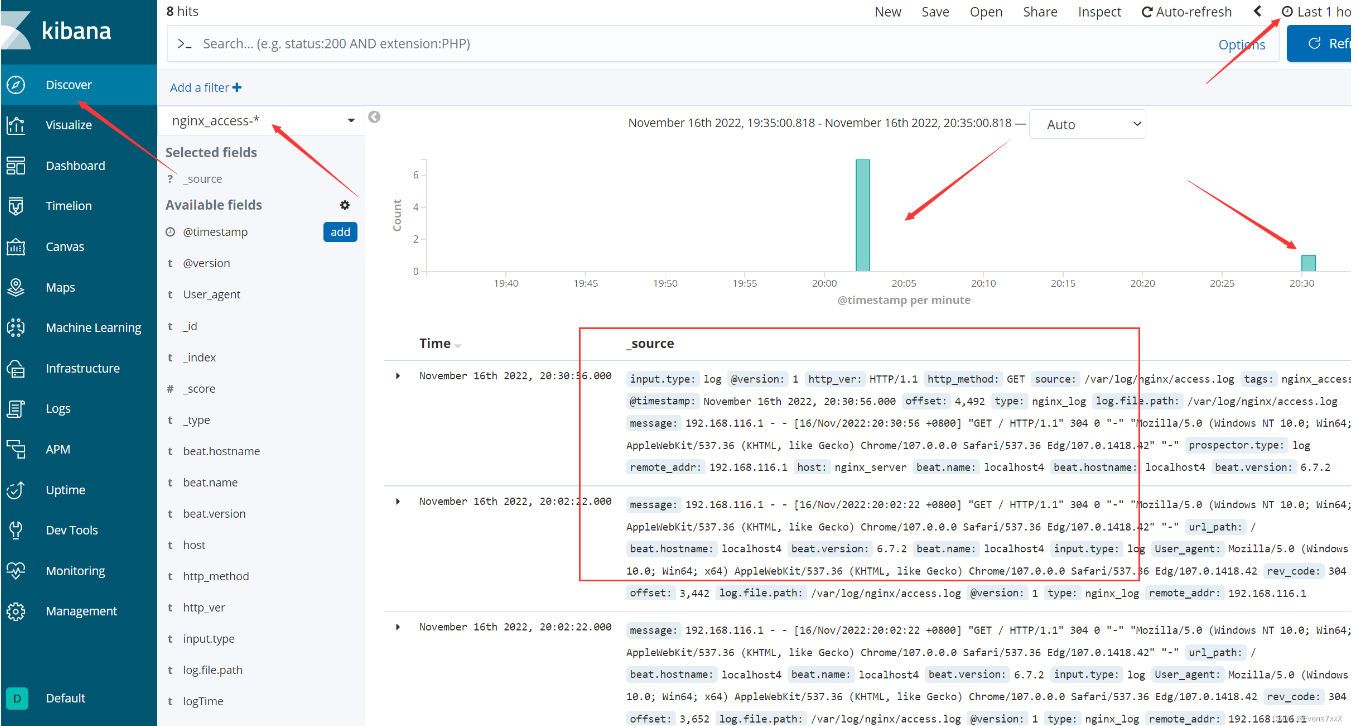
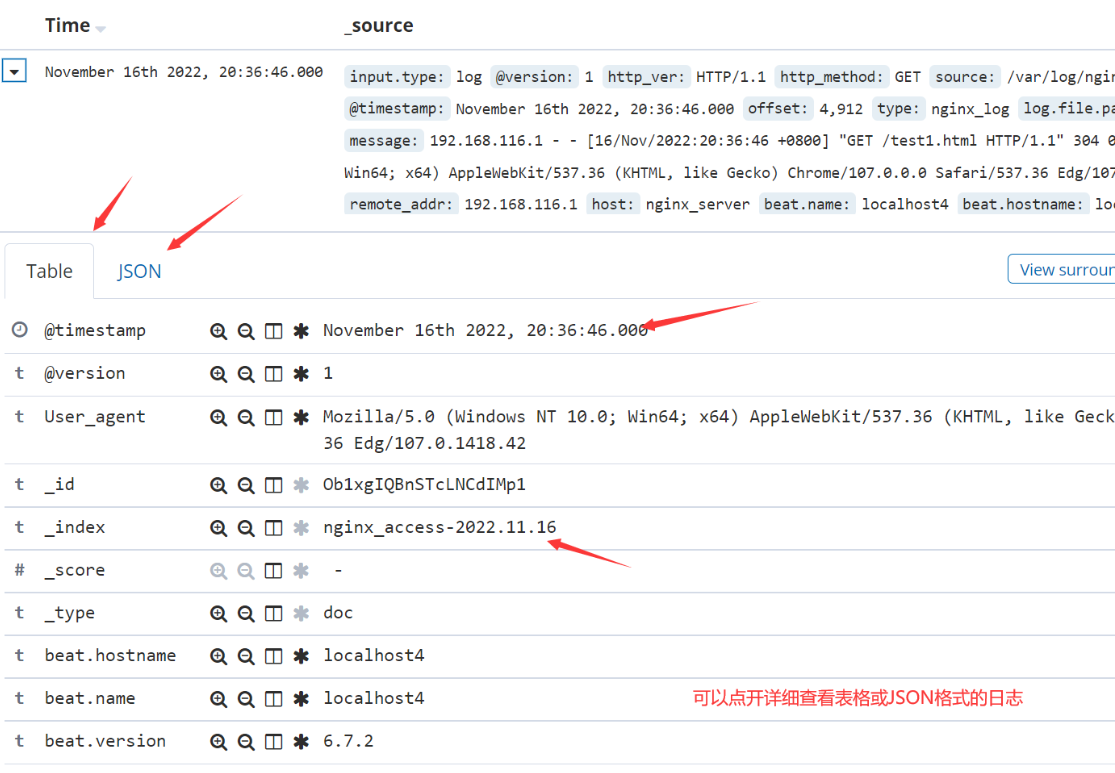
5.浏览器访问 http://192.168.40.170:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
二、ELFK+zookeeper+kafka
一 部署zookeeper集群
//准备 3 台服务器做 Zookeeper 集群
192.168.40.21
192.168.40.22
192.168.40.23
1.安装前准备
//关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0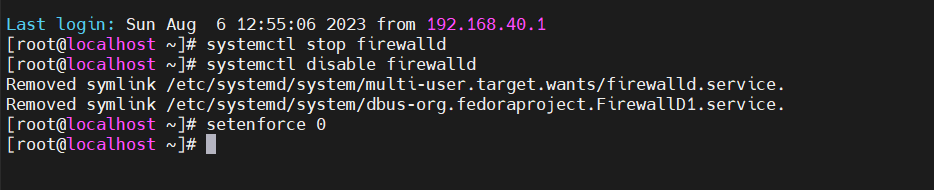
//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -versioncd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
2.安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7//修改配置文件
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.40.21:3188:3288
server.2=192.168.40.22:3188:3288
server.3=192.168.40.23:3188:3288

server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
//拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.40.22:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.40.23:/usr/local/zookeeper-3.5.7/conf/
//在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
//在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid
//配置 Zookeeper 启动脚本
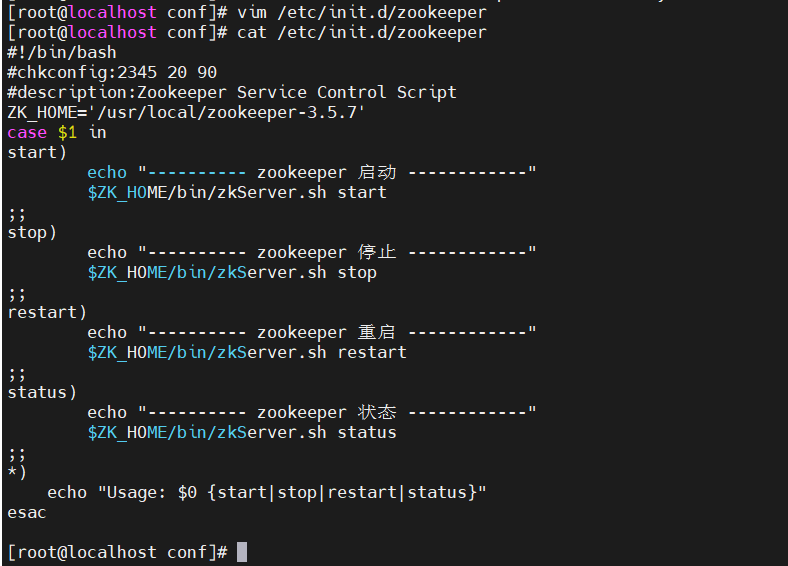
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac
// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper 
//分别启动 Zookeeper
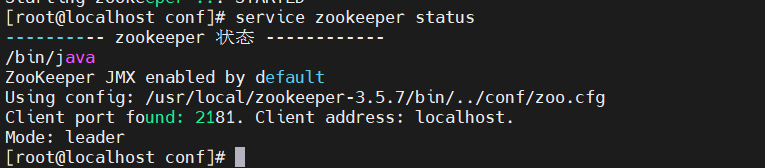
service zookeeper start//查看当前状态
service zookeeper status
三 部署 kafka 集群
1.下载安装包

2.安装 Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}

vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.17:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.40.21:2181,192.168.40.22:2181,192.168.40.23:2181 ●123行,配置连接Zookeeper集群地址
//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile


//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
service kafka start

四 部署Filebeat+Kafka+ELK
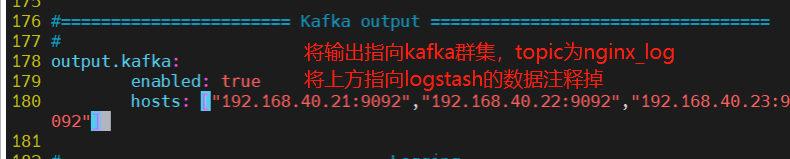
1.修改filebeat配置文件filebeat.yml收集日志转发(生产)给kafka
cd /usr/local/filebeatvim filebeat.yml
filebeat.prospectors:
- type: logenabled: truepaths:- /var/log/httpd/access_logtags: ["nginx_access"]- type: logenabled: truepaths:- /var/log/httpd/error_logtags: ["nginx_error"]......
#添加输出到 Kafka 的配置
output.kafka:enabled: truehosts: ["192.168.40.21:9092","192.168.40.22:9092","192.168.40.23:9092"] #指定 Kafka 集群配置topic: "httpd" #指定 Kafka 的 topic#启动 filebeat
./filebeat -e -c filebeat.yml



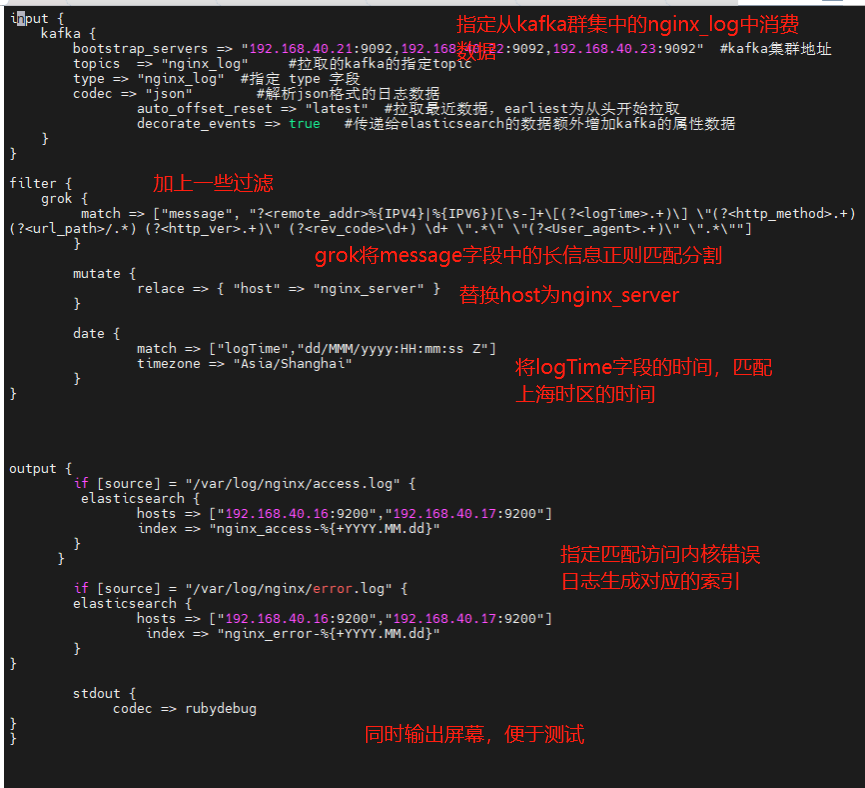
2.修改logstash配置从kafka中消费日志,并输出到kibana前端展示
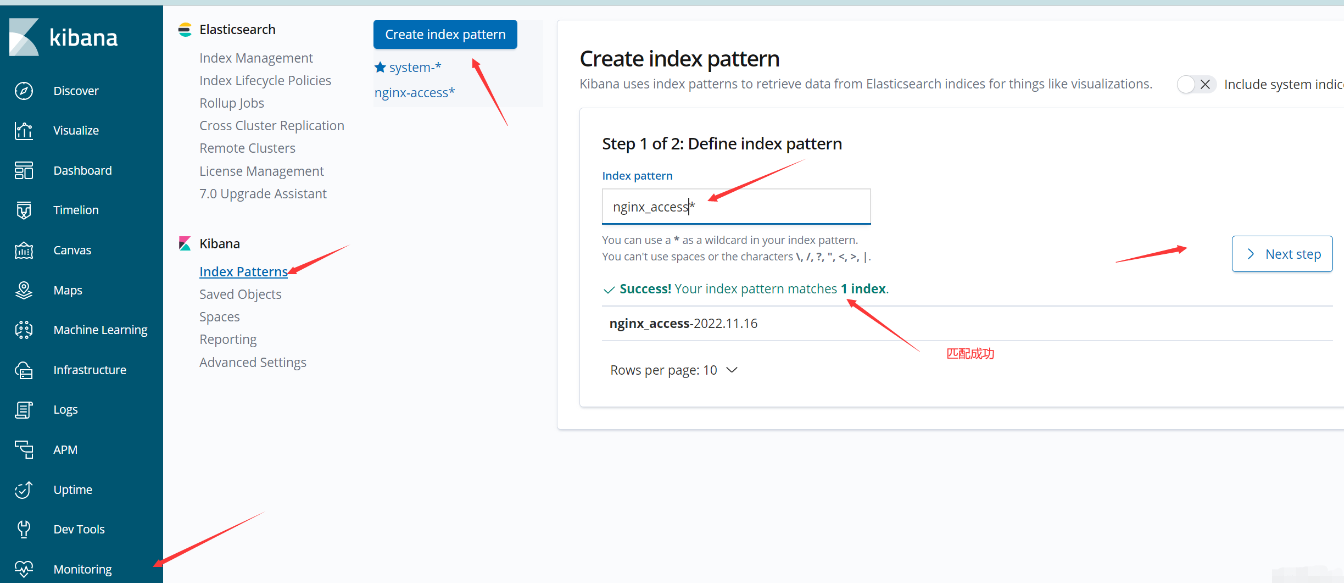
开启logstash,此时访问web测试页面,就可以在kibana对日志收集分析了

相关文章:
EFLFK——ELK日志分析系统+kafka+filebeat架构
环境准备 node1节点192.168.40.16elasticsearch2c/4Gnode2节点192.168.40.17elasticsearch2c/4GApache节点192.168.40.170logstash/Apache/kibana2c/4Gfilebeat节点192.168.40.20filebeat2c/4G https://blog.csdn.net/m0_57554344/article/details/132059066?spm1001.2014.30…...
)
C# MVC controller 上传附件及下载附件(笔记)
描述:Microsoft.AspNetCore.Http.IFormFileCollection 实现附件快速上传功能代码。 上传附件代码 [Route("myUploadFile")][HttpPost]public ActionResult MyUploadFile([FromForm] upLoadFile rfile){string newFileName Guid.NewGuid().ToString(&quo…...

安装element-plus报错:Conflicting peer dependency: eslint-plugin-vue@7.20.0
VSCode安装element-plus报错: D:\My Programs\app_demo>npm i element-plus npm ERR! code ERESOLVE npm ERR! ERESOLVE could not resolve npm ERR! npm ERR! While resolving: vue/eslint-config-standard6.1.0 npm ERR! Found: eslint-plugin-vue8.7.1 npm E…...

【操作系统】进程和线程对照解释
进程(Process)和线程(Thread)都是操作系统中用于执行任务的基本单位,但它们有着不同的特点和使用方式。 进程(Process): 进程是正在运行的程序的实例。一个程序在运行时会被操作系统…...
4用opencv玩转图像2
opencv绘制文字和几何图形 黑色底图 显示是一张黑色图片 使用opencv画圆形 #画一个圆 cv2.circle(imgblack_img,center(400,400),radius100,color(0,0,255),thickness10) 画实心圆 只需要把thickness-1。 cv2.circle(imgblack_img,center(500,600),radius50,color(0,0,255),t…...

Swagger的使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1 .介绍2. 使用步骤完整的WebMvcConfiguration.java 3. 常用注解 前言 1 .介绍 Swagger 是一个规范和完整的框架,用于生成、描述、调用和可视化 RE…...
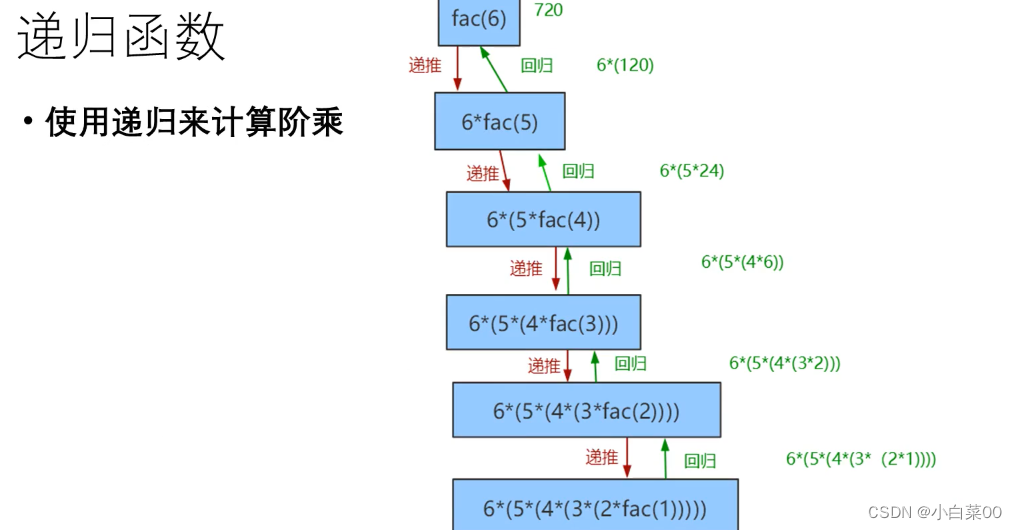
python高阶技巧
目录 设计模式 单例模式 具体用法 工厂模式 优点 闭包 案例 修改闭包外部变量 闭包优缺点 装饰器 装饰器原理 装饰器写法 递归 递归的调用过程 递归的优缺点 用递归计算阶乘 设计模式 含义:设计模式是一种编程套路,通过这种编程套路可…...

Linux和Windows安装MySQL服务
Linux和Windows安装MySQL服务 1 Linux安装MySQL服务1.1 安装1.2 服务端启动1.3 客户端连接 2 Windows安装MySQL服务2.1官网下载安装包(windows)并解压2.2 配置系统环境变量2.3 服务端启动(管理员DOS)2.4 客户端连接(管理员DOS) 3 修改密码4 Windows问题 1 Linux安装MySQL服务 …...

Vue3 第四节 自定义hook函数以及组合式API
1.自定义hook函数 2.toRef和toRefs 3.shallowRef和shallowReactive 4.readonly和shallowReadonly 5.toRaw和markRaw 6.customref 一.自定义hook函数 ① 本质是一个函数,把setup函数中使用的Composition API 进行了封装,类似于vue2.x中的mixin 自定义hook函数…...

门面模式(C++)
定义 为子系统中的一组接口提供一个一致(稳定) 的界面,Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用(复用)。 应用场景 上述A方案的问题在于组件的客户和组件中各种复杂的子系统有了过多的耦合,随着外部客户程序和各子…...

ASP.NET Core SignalR
ASP.NET Core SignalR是一个开发实时网络应用程序的框架,它使用WebSocket作为传输协议,并提供了一种简单和高效的方式来实现实时双向通信。 SignalR使用了一种称为"Hub"的概念来管理连接和消息的传递。开发者可以编写自己的Hub类,…...

auto-changelog的简单使用
auto-changelog的简单使用 自动化生成Git提交记录,CHANGELOG.md文件 github:https://github.com/cookpete/auto-changelog 安装 npm install -g auto-changelog配置脚本 package.json文件下 "scripts": {"changelog": "aut…...

map 比较(两个map的key,value 是否一样)
1. 用equals 比较 public static void main(String[] args) {List<Map<String,Object>> list new ArrayList<>();Map<String,Object> map1 new HashMap<>();map1.put("name","郭");map1.put("objId","1&quo…...

LayUI之入门
目录 1.什么是layui 2.layui、easyui与bootstrap的对比 有趣的对比方式,嘿嘿嘿.... easyuijqueryhtml4(用来做后台的管理界面) 半老徐娘 bootstrapjqueryhtml5 美女 拜金 layui 清纯少女 2.1 layui和bootstrap对比(这两个都属…...

【Linux】Linux下git的使用
文章目录 一、什么是git二、git发展史三、Gitee仓库的创建1.新建仓库2.复制仓库链接3.在命令行克隆仓库3.1仓库里的.gitignore是什么3.2仓库里的git是什么 三、git的基本使用1.将克隆仓库的新增文件添加到暂存区(本地仓库)2.将暂存区的文件添加到.git仓库中3.将.git仓库中的变化…...

QT读写配置文件
文章目录 一、概述二、使用步骤1.引入头文件2.头文件的public中定义配置文件对象3.初始化 一、概述 Qt中常见的配置文件为(.ini)文件,其中ini是Initialization File的缩写,即初始化文件。 配置文件的格式如下所示: 模…...
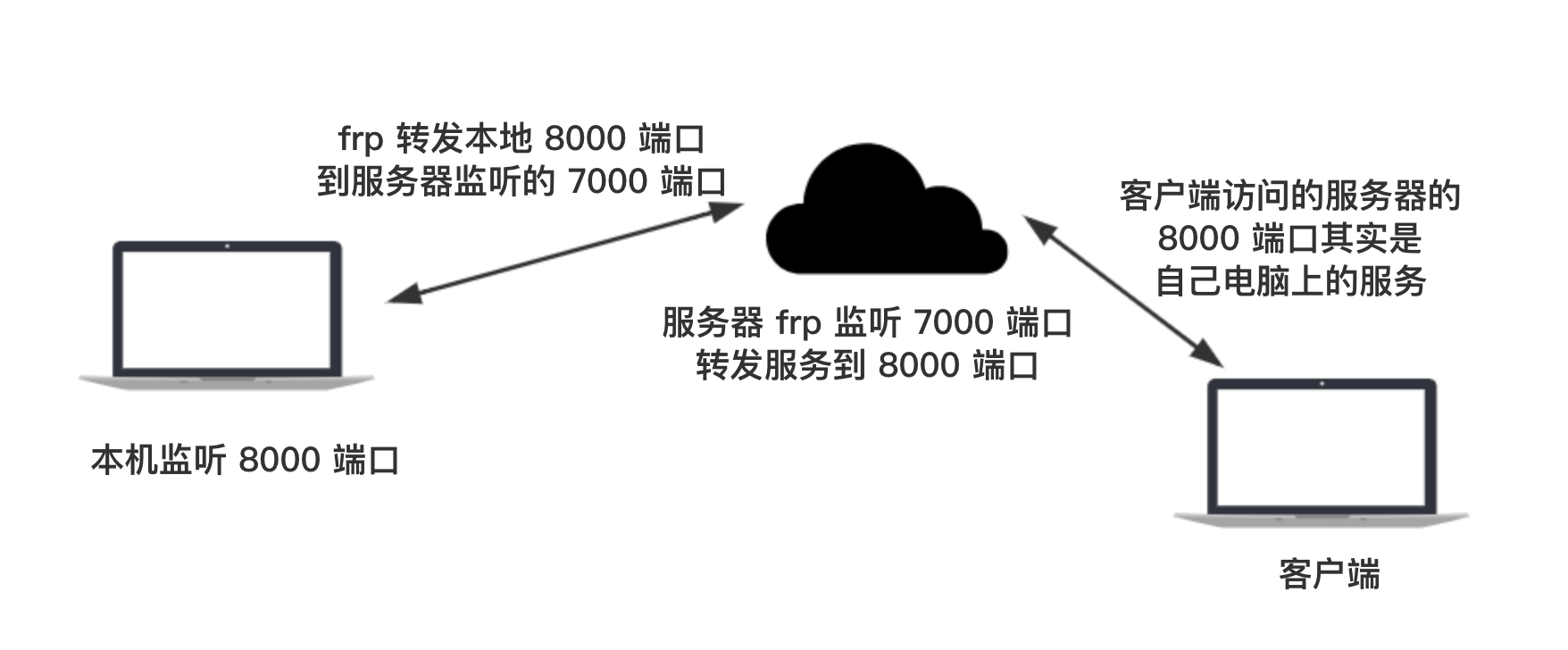
【计算机网络】12、frp 内网穿透
文章目录 一、服务端设置二、客户端设置 frp :A fast reverse proxy to help you expose a local server behind a NAT or firewall to the internet。是一个专注于内网穿透的高性能的反向代理应用,支持 TCP、UDP、HTTP、HTTPS 等多种协议,且…...

Pytest 重复执行用例插件----pytest-repeat
前言 在自动化过程中,想要重复执行一条脚本,查看他的稳定性,如果是在unittest框架中,可能会使用for一直循环这条用例,但是当我们使用pytest框架后,我们就可以通过某些插件来实现这个功能了。今天介绍的这个…...
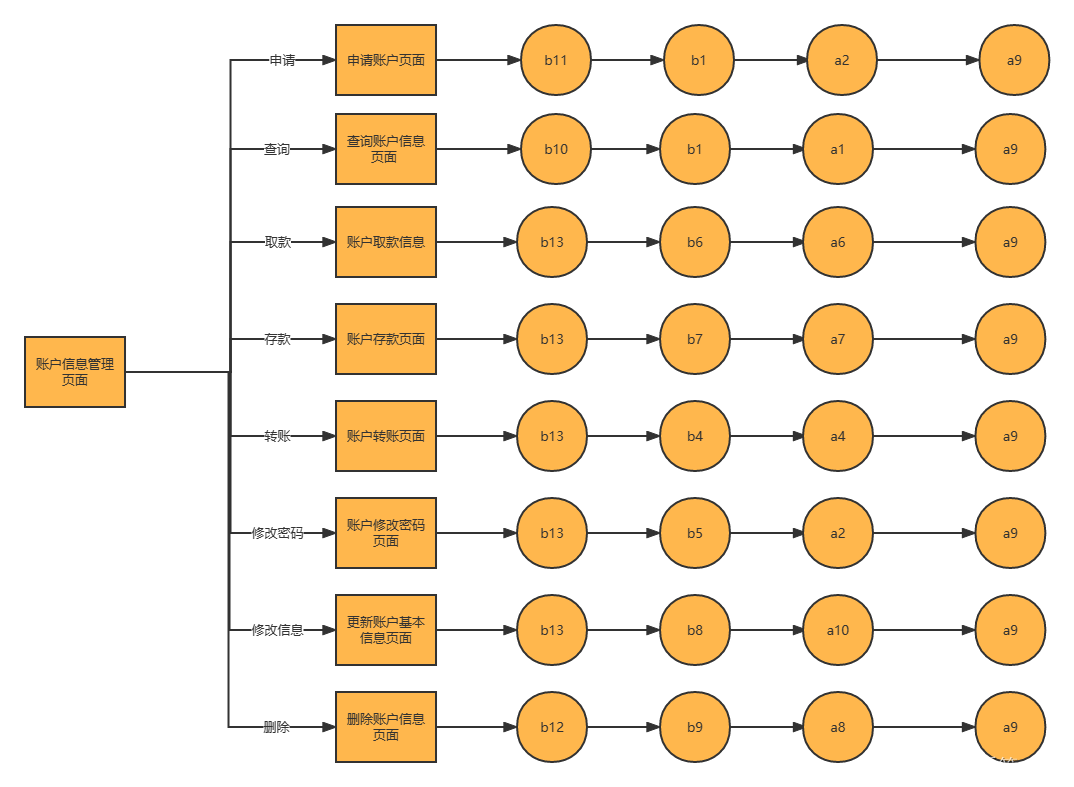
【软件工程】5 ATM系统测试
目录 5 ATM系统测试 5.1 单元测试 5.1.1 制定单元测试计划 5.1.2 设计单元测试用例 编辑 5.1.3 执行单元测试 5.1.4 单元测试报告 5.2 集成测试 5.2.1 制定集成测试计划 5.2.2 设计集成测试用例 5.2.3 执行集成测试 5.2.4 集成测试总结 5.3 系统测试 5.3.1 制定…...

opencv读取MP4文件和摄像头数据
文章目录 前言一、waitKey函数二、VideoCapture类总结前言 本篇文章来讲解opencv读取MP4文件和摄像头数据,opencv主要用于处理图像数据那么本篇文章就来讲解opencv读取MP4文件和摄像头数据。 一、waitKey函数 waitKey()函数是OpenCV中常用的一个函数,它用于等待用户按键输…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...

城通网盘解析工具终极指南:免费获取高速直连下载地址
城通网盘解析工具终极指南:免费获取高速直连下载地址 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的下载速度?每次下载文件都要面对漫长的等待…...

YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具
YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换
VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA开发领域,VHDL和Verilog是两大主流硬件描述语言,但团队协作或项目迁移时经常…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十三)用户指引自助教学源码—东方仙盟
代码<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge,chrome1"> <title>你的导师-未来之窗</title> <style>*…...

我给了智能体$100去赚钱,结果...
你看过那些演示。一个自主智能体启动,获得一个目标,然后——跳到两周后的 Twitter 帖子——它不知怎么地就在运营一个 Shopify 店铺、写通讯和炒币了。未来已来。AGI 即将降临。买课吧。 我想找出实际发生了什么。 所以我给了一个智能体 100 美元和一个…...

基于WebSocket的机械爪远程控制桥接系统设计与实战
1. 项目概述:一个连接物理世界与数字世界的“机械爪”远程控制桥最近在捣鼓一个挺有意思的开源项目,叫lucas-jo/openclaw-bridge-remote。光看名字,你可能觉得这又是一个关于机器人或者机械臂的遥控项目,但实际深入进去࿰…...