图像识别模型与训练策略
图像预处理
1.需要将图像Resize到相同大小输入到卷积网络中
2.翻转、裁剪、色彩偏移等操作
3.转化为Tensor数据格式
4.对RGB三种颜色通道进行标准化
data_transforms = {'train': transforms.Compose([transforms.Resize([96, 96]),transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选transforms.CenterCrop(64),#从中心开始裁剪transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差]),'valid': transforms.Compose([transforms.Resize([64, 64]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}
读取数据
将训练集中各个类别文件夹中的数据经过Transforms增强后进行统一读取封装
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
batch_size = 128image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes
迁移学习
使用官方发布的模型和参数,将参数冻住不更新
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = Falsemodel_ft = models.resnet18()#18层的能快点,条件好点的也可以选152
model_ft
修改输出层
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):model_ft = models.resnet18(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs, 102)#类别数自己根据自己任务来input_size = 64#输入大小根据自己配置来return model_ft, input_size
更新输出层参数
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)#GPU还是CPU计算
model_ft = model_ft.to(device)# 模型保存,名字自己起
filename='checkpoint.pth'# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:params_to_update = []for name,param in model_ft.named_parameters():if param.requires_grad == True:params_to_update.append(param)print("\t",name)
else:for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)
优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)#要训练啥参数,你来定
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)#学习率每7个epoch衰减成原来的1/10
criterion = nn.CrossEntropyLoss()
训练策略
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25,filename='best.pt'):#咱们要算时间的since = time.time()#也要记录最好的那一次best_acc = 0#模型也得放到你的CPU或者GPUmodel.to(device)#训练过程中打印一堆损失和指标val_acc_history = []train_acc_history = []train_losses = []valid_losses = []#学习率LRs = [optimizer.param_groups[0]['lr']]#最好的那次模型,后续会变的,先初始化best_model_wts = copy.deepcopy(model.state_dict())#一个个epoch来遍历for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 训练和验证for phase in ['train', 'valid']:if phase == 'train':model.train() # 训练else:model.eval() # 验证running_loss = 0.0running_corrects = 0# 把数据都取个遍for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)#放到你的CPU或GPUlabels = labels.to(device)# 清零optimizer.zero_grad()# 只有训练的时候计算和更新梯度outputs = model(inputs)loss = criterion(outputs, labels)_, preds = torch.max(outputs, 1)# 训练阶段更新权重if phase == 'train':loss.backward()optimizer.step()# 计算损失running_loss += loss.item() * inputs.size(0)#0表示batch那个维度running_corrects += torch.sum(preds == labels.data)#预测结果最大的和真实值是否一致epoch_loss = running_loss / len(dataloaders[phase].dataset)#算平均epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - since#一个epoch我浪费了多少时间print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 得到最好那次的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),#字典里key就是各层的名字,值就是训练好的权重'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)#scheduler.step(epoch_loss)#学习率衰减if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))LRs.append(optimizer.param_groups[0]['lr'])print()scheduler.step()#学习率衰减time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# 训练完后用最好的一次当做模型最终的结果,等着一会测试model.load_state_dict(best_model_wts)return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
相关文章:

图像识别模型与训练策略
图像预处理 1.需要将图像Resize到相同大小输入到卷积网络中 2.翻转、裁剪、色彩偏移等操作 3.转化为Tensor数据格式 4.对RGB三种颜色通道进行标准化 data_transforms {train: transforms.Compose([transforms.Resize([96, 96]),transforms.RandomRotation(45),#随机旋转&…...
)
算法工程师-机器学习面试题总结(3)
FM模型 FM模型与逻辑回归相比有什么优缺点? FM(因子分解机)模型和逻辑回归是两种常见的预测建模方法,它们在一些方面有不同的优缺点。 FM模型的优点: 1. 能够捕获特征之间的交互作用:FM模型通过对特征向量…...
进程内topic高效通信)
ROS2学习(五)进程内topic高效通信
对ROS2有一定了解后,我们会发现ROS2中节点和ROS1中节点的概率有很大的区别。在ROS1中节点是最小的进程单元。在ROS2中节点与进程和线程的概念完全区分开了。具体区别可以参考 ROS2学习(四)进程,线程与节点的关系。 在ROS2中同一个进程中可能存在多个节点…...

算法-最大数
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。 注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。 输入:nums [10,2] 输出:"210&…...

Spark中使用RDD算子GroupBy做词频统计的方法
测试文件及环境 测试文件在本地D://tmp/spark.txt,Spark采用Local模式运行,Spark版本3.2.0,Scala版本2.12,集成idea开发环境。 hello world java world java java实验代码 import org.apache.spark.rdd.RDD import org.apache.…...
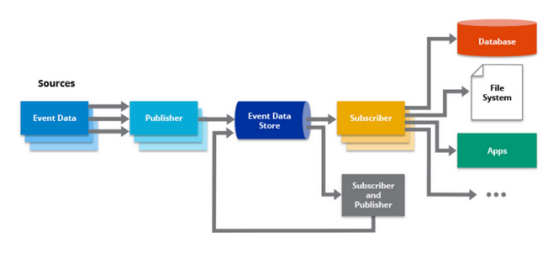
如何使用Kafka构建事件驱动的架构
事件驱动的架构(EDA)是一种软件设计模式,它关注事件的生成、检测和使用,以支持高效和可扩展的系统。在EDA中,事件是组件之间通信的主要手段,允许它们实时交互和响应更改。这种架构促进了松散耦合、可扩展性和响应性,使…...

ES6 解构赋值
解构赋值 解构赋值是一种在编程中常见且方便的语法特性,它可以让你从数组或对象中快速提取数据,并将数据赋值给变量。在许多编程语言中都有类似的特性。 在 JavaScript 中,解构赋值使得从数组或对象中提取数据变得简单。它可以用于数组和对…...

HTML5注册页面
分析 注册界面实际上是一个表格(对齐),一行有两个单元格。 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevic…...

python中的JSON模块详解
简介 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写 同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互 网址 官方文档 json — JSON encoder and dec…...
Syncfusion Essential Edit for WPF Crack
Syncfusion Essential Edit for WPF Crack 在任何WPF应用程序中启用语法高亮显示。 Syncfusion Essential Edit for WPF是一款具有所有基本功能的编辑器,如文本编辑、剪切、复制和粘贴。它允许用户从各种文件格式打开文件并将其保存为各种文件格式。Syncfusion Esse…...
机器学习深度学习——卷积神经网络(LeNet)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——池化层 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 卷积神…...

Pytorch Tutorial【Chapter 2. Autograd】
Pytorch Tutorial 文章目录 Pytorch TutorialChapter 2. Autograd1. Review Matrix Calculus1.1 Definition向量对向量求导1.2 Definition标量对向量求导1.3 Definition标量对矩阵求导 2.关于autograd的说明3. grad的计算3.1 Manual手动计算3.2 backward()自动计算 Reference C…...

Python第三方库国内镜像下载地址
Python第三方库国内镜像下载地址 一、清华大学二、中国科技大学三、安装方法 一、清华大学 https://pypi.tuna.tsinghua.edu.cn/simple 二、中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple 三、安装方法 例如 pyhook3 插件的安装方法,执行下面命令安装…...
服务端机器一般部署在哪里)
从浏览器输入url到页面加载(七)服务端机器一般部署在哪里
前言 上一节,我们说到了CDN和路由器的关系,说到了公有地址,说到了通信线路服务,这一节跳过那些看不懂的深层知识,直接开始说web服务器。 1. 服务端机器为什么不部署在公司内部 记得在之前的一段时间里,公…...
Pytorch深度学习-----神经网络之Sequential的详细使用及实战详解
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
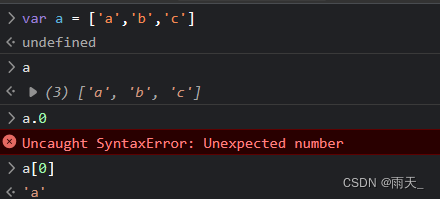
安全基础 --- https详解 + 数组(js)
CIA三属性:完整性(Confidentiality)、保密性(Integrity)、可用性(Availability),也称信息安全三要素。 https 核心技术:用非对称加密传输对称加密的密钥,然后…...

vue加载大量数据优化
在Vue中加载大量数据并形成列表时,可以通过以下方法来优化性能: 分页加载:不要一次性加载所有的数据,而是分批加载数据,每次只加载当前页需要显示的数据量。可以使用第三方库如vue-infinite-loading来实现无限滚动加载…...

WebRTC 之音视频同步
在网络视频会议中, 我们常会遇到音视频不同步的问题, 我们有一个专有名词 lip-sync 唇同步来描述这类问题,当我们看到人的嘴唇动作与听到的声音对不上的时候,不同步的问题就出现了 而在线会议中, 听见清晰的声音是优先…...
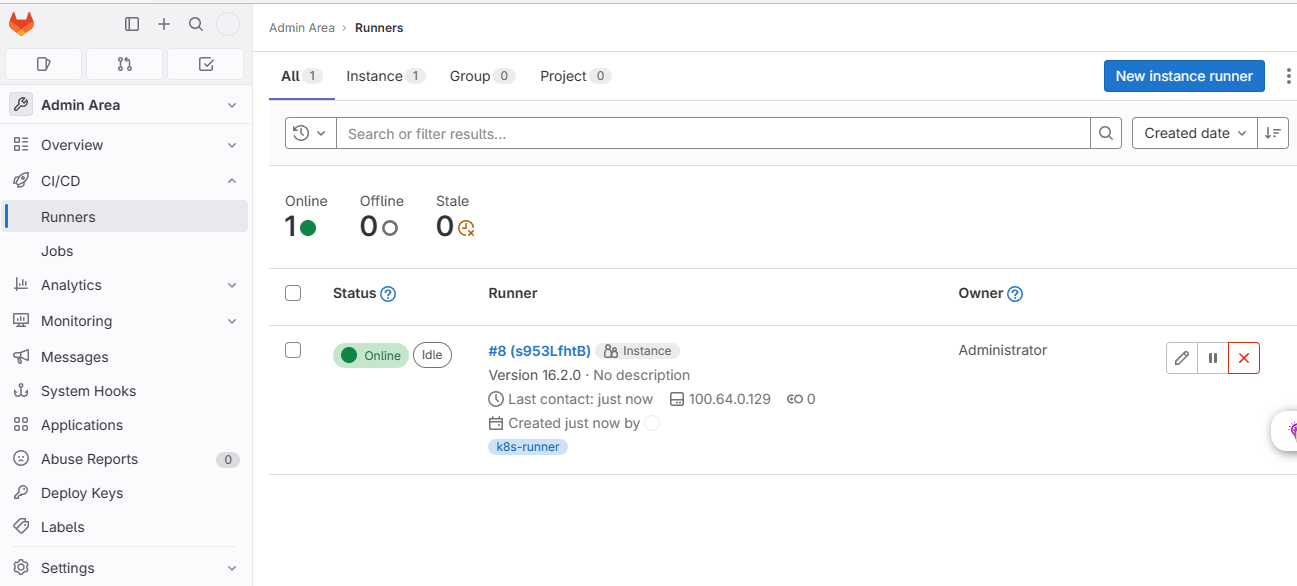
kubernetes基于helm部署gitlab-runner
kubernetes基于helm部署gitlab-runner 这篇博文介绍如何在 Kubernetes 中使用helm部署 GitLab-runner。 先决条件: 已运行的 Kubernetes 集群已运行的 gitlab 实例 项目地址:https://gitlab.com/gitlab-org/charts/gitlab-runner 官方文档ÿ…...

深度学习和OpenCV的对象检测(MobileNet SSD图像识别)
基于深度学习的对象检测时,我们主要分享以下三种主要的对象检测方法: Faster R-CNN(后期会来学习分享)你只看一次(YOLO,最新版本YOLO3,后期我们会分享)单发探测器(SSD,本节介绍,若你的电脑配置比较低,此方法比较适合R-CNN是使用深度学习进行物体检测的训练模型; 然而,…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...

开源智能体技术解析:从LangChain到自主抓取,构建自动化工作流
1. 项目概述:从“Awesome”列表看开源智能体生态的演进 最近在梳理一些前沿的自动化工具链时,又翻到了 mergisi/awesome-openclaw-agents 这个仓库。对于长期关注AI Agent(智能体)和自动化工作流开发的同行来说,这类…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

婚礼技能库:用开源协作与项目管理思维打造个性化婚礼
1. 项目概述:婚礼技能库的诞生与价值婚礼,对大多数人来说,是人生中为数不多的、需要同时扮演项目经理、创意总监、财务主管和情感联络员的高压事件。筹备过程琐碎繁杂,从场地布置、流程设计,到妆发造型、摄影摄像&…...
深入Transformer内部:LoRA到底改动了哪部分权重才让模型“学会”新任务?
深入Transformer内部:LoRA如何通过低秩更新重塑大模型能力 在自然语言处理领域,大型预训练模型的微调一直是个计算密集型任务。传统全参数微调需要更新数十亿甚至数千亿参数,这对大多数研究者和企业来说都是难以承受的负担。低秩适应(LoRA)技…...

Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案
Sketchfab数据提取终极指南:打破在线3D模型下载壁垒的完整解决方案 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 你是否曾在Sketchfab上发现完美的3D…...

C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南
C语言结构体、枚举、联合体:从内存布局看区别,新手避坑指南 在C语言开发中,结构体、枚举和联合体是构建复杂数据模型的三大基石。但很多开发者在实际项目中常遇到这样的困惑:为什么结构体占用的内存比预期大?枚举变量在…...

飞书自动化脚本开发指南:从API集成到智能审批机器人实战
1. 项目概述:飞书自动化,从“手动”到“自动”的效能革命 如果你每天的工作,有超过30%的时间是在飞书里重复点击、复制粘贴、手动发送消息和整理表格,那么“cicbyte/feishu-atuo”这个项目,很可能就是你一直在寻找的“…...

基于Rust与Candle的AI推理引擎cria:简化大模型本地部署与优化
1. 项目概述:从“左移”到“创造”的AI推理引擎 最近在折腾AI模型本地部署和推理优化的朋友,可能都绕不开一个名字: cria 。这个由 leftmove 开源的项目,全称是“Cria: The AI Inference Engine”,直译过来就是“创…...

ComfyUI ControlNet Aux 终极指南:30+种预处理器让AI图像生成更精准
ComfyUI ControlNet Aux 终极指南:30种预处理器让AI图像生成更精准 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想让您的AI图像生成具备真实…...