snowboy+新一代kaldi(k2-fsa)sherpa-onnx实现离线语音识别【语音助手】
背景
本系列主要目标初步完成一款智能音箱的基础功能,包括语音唤醒、语音识别(语音转文字)、处理用户请求(比如查天气等,主要通过rasa自己定义意图实现)、语音合成(文字转语音)功能。
语音识别、语音合成采用离线方式实现。
语音识别使用sherpa-onnx,可以实现离线中英文语音识别。
本文用到的一些安装包在snowboy那一篇的必要条件中已经完成了部分构建,在离线语音识别安装完成之后也会把相关代码写到snowboy项目中,语音唤醒之后调用语音识别翻译用户说话的内容。
语音唤醒文章地址:
snowboy 自定义唤醒词 实现语音唤醒【语音助手】_殷长庆的博客-CSDN博客
参考文章
sherpa-onnx教程(强烈建议按官网的步骤安装):
Installation — sherpa 1.3 documentation
sherpa-onnx的预编译模型
Pre-trained models — sherpa 1.3 documentation
实践
下载安装sherpa-onnx
cd /home/testgit clone https://github.com/k2-fsa/sherpa-onnx
cd sherpa-onnx
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
make -j6安装完成之后会在bin目录下发现sherpa-onnx的可执行文件
下载预编译模型
我选择的是offline-paraformer版本的模型,因为他同时支持中英文的离线识别,这个离线识别是基于wav视频文件的,正好满足要求。
参考官网地址:
Paraformer models — sherpa 1.3 documentation
下面是操作步骤:
cd /home/test/sherpa-onnxGIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/csukuangfj/sherpa-onnx-paraformer-zh-2023-03-28
cd sherpa-onnx-paraformer-zh-2023-03-28
git lfs pull --include "*.onnx"检查是否下载成功,注意看模型文件的大小
sherpa-onnx-paraformer-zh-2023-03-28$ ls -lh *.onnx
-rw-r--r-- 1 kuangfangjun root 214M Apr 1 07:28 model.int8.onnx
-rw-r--r-- 1 kuangfangjun root 824M Apr 1 07:28 model.onnx可以看到两个模型文件,这俩模型本机测试感觉差距不是太大,我选择的是int8这个版本
测试语音识别
测试以下语音识别效果
cd /home/test/sherpa-onnx./build/bin/sherpa-onnx-offline \--tokens=./sherpa-onnx-paraformer-zh-2023-03-28/tokens.txt \--paraformer=./sherpa-onnx-paraformer-zh-2023-03-28/model.int8.onnx \./sherpa-onnx-paraformer-zh-2023-03-28/test_wavs/0.wav出现相应的正确打印就代表语音识别准备工作完成了
集成到snowboy
首先在sherpa-onnx目录的python-api-examples下有python的api,我们需要的是offline-decode-files.py这个文件,其中main()方法用来离线识别一个wav文件。
接下来我们对该文件进行一点点的修改,主要是把模型的默认参数配置好,然后识别完成之后返回识别内容
offlinedecode.py
把offline-decode-files.py文件更名为offlinedecode.py,或者是新建一个offlinedecode.py文件
touch offlinedecode.pyvim offlinedecode.py编辑文件的内容
#!/usr/bin/env python3
#
# Copyright (c) 2023 by manyeyes"""
This file demonstrates how to use sherpa-onnx Python API to transcribe
file(s) with a non-streaming model.
Please refer to
https://k2-fsa.github.io/sherpa/onnx/index.html
to install sherpa-onnx and to download the pre-trained models
used in this file.
"""
import time
import wave
from typing import List, Tupleimport numpy as np
import sherpa_onnxclass Constants:encoder="" # or 如果用zipformer模型需要修改成zipformer的 encoder-epoch-12-avg-4.int8.onnxdecoder="" # or 如果用zipformer模型需要修改成zipformer的decoder-epoch-12-avg-4.int8.onnxjoiner="" # or 如果用zipformer模型需要修改成zipformer的joiner-epoch-12-avg-4.int8.onnxtokens="/home/test/sherpa-onnx/sherpa-onnx-paraformer-zh-2023-03-28/tokens.txt" # 如果用zipformer模型需要修改成zipformer的tokens.txtnum_threads=1sample_rate=16000feature_dim=80decoding_method="greedy_search" # Or modified_ Beam_ Search, only used when the encoder is not emptycontexts="" # 关键词微调,只在modified_ Beam_ Search模式下有用context_score=1.5debug=Falsemodeling_unit="char"paraformer="/home/test/sherpa-onnx/sherpa-onnx-paraformer-zh-2023-03-28/model.int8.onnx" # 实际上使用的是该模型global args,contexts_list,recognizer
args = Constants()def encode_contexts(args, contexts: List[str]) -> List[List[int]]:tokens = {}with open(args.tokens, "r", encoding="utf-8") as f:for line in f:toks = line.strip().split()tokens[toks[0]] = int(toks[1])return sherpa_onnx.encode_contexts(modeling_unit=args.modeling_unit, contexts=contexts, sp=None, tokens_table=tokens)def read_wave(wave_filename: str) -> Tuple[np.ndarray, int]:"""Args:wave_filename:Path to a wave file. It should be single channel and each sample shouldbe 16-bit. Its sample rate does not need to be 16kHz.Returns:Return a tuple containing:- A 1-D array of dtype np.float32 containing the samples, which arenormalized to the range [-1, 1].- sample rate of the wave file"""with wave.open(wave_filename) as f:assert f.getnchannels() == 1, f.getnchannels()assert f.getsampwidth() == 2, f.getsampwidth() # it is in bytesnum_samples = f.getnframes()samples = f.readframes(num_samples)samples_int16 = np.frombuffer(samples, dtype=np.int16)samples_float32 = samples_int16.astype(np.float32)samples_float32 = samples_float32 / 32768return samples_float32, f.getframerate()# 初始化(因为用到的是paraformer,所以实际上初始化的是paraformer的识别)
def init():global argsglobal recognizerglobal contexts_listcontexts_list=[]if args.encoder:contexts = [x.strip().upper() for x in args.contexts.split("/") if x.strip()]if contexts:print(f"Contexts list: {contexts}")contexts_list = encode_contexts(args, contexts)recognizer = sherpa_onnx.OfflineRecognizer.from_transducer(encoder=args.encoder,decoder=args.decoder,joiner=args.joiner,tokens=args.tokens,num_threads=args.num_threads,sample_rate=args.sample_rate,feature_dim=args.feature_dim,decoding_method=args.decoding_method,context_score=args.context_score,debug=args.debug,)elif args.paraformer:recognizer = sherpa_onnx.OfflineRecognizer.from_paraformer(paraformer=args.paraformer,tokens=args.tokens,num_threads=args.num_threads,sample_rate=args.sample_rate,feature_dim=args.feature_dim,decoding_method=args.decoding_method,debug=args.debug,)# 语音识别
# *sound_files 要识别的音频路径
# return 识别后的结果
def asr(*sound_files):global argsglobal recognizerglobal contexts_liststart_time = time.time()streams = []total_duration = 0for wave_filename in sound_files:samples, sample_rate = read_wave(wave_filename)duration = len(samples) / sample_ratetotal_duration += durationif contexts_list:s = recognizer.create_stream(contexts_list=contexts_list)else:s = recognizer.create_stream()s.accept_waveform(sample_rate, samples)streams.append(s)recognizer.decode_streams(streams)results = [s.result.text for s in streams]end_time = time.time()for wave_filename, result in zip(sound_files, results):return f"{result}"编辑完成保存,把文件移动到snowboy的Python3目录下
mv offlinedecode.py /home/test/snowboy/examples/Python3/demo.py
修改snowboy的demo.py文件
cd /home/test/snowboy/examples/Python3/vim demo.py主要修改为snowboy唤醒设备之后,开始录音,当结束录音时调用sherpa-onnx识别语音内容,把demo.py修改为以下内容
import snowboydecoder
import signal
import os
import offlinedecodeinterrupted = Falsedef signal_handler(signal, frame):global interruptedinterrupted = Truedef interrupt_callback():global interruptedreturn interrupted# 初始化语音识别
offlinedecode.init()# 唤醒词模型文件
model = '../../model/hotword.pmdl'# capture SIGINT signal, e.g., Ctrl+C
signal.signal(signal.SIGINT, signal_handler)detector = snowboydecoder.HotwordDetector(model, sensitivity=0.5)
print('Listening... Press Ctrl+C to exit')# 录音之后的回调
# fname 音频文件路径
def audio_recorder_callback(fname):text = offlinedecode.asr(fname)# 打印识别内容print(text)# 删除录音文件if isinstance(fname, str) and os.path.exists(fname):if os.path.isfile(fname):os.remove(fname)# main loop
detector.start(detected_callback=snowboydecoder.play_audio_file,audio_recorder_callback=audio_recorder_callback,interrupt_check=interrupt_callback,sleep_time=0.03)detector.terminate()编辑完成保存,然后测试是否有识别成功
测试集成效果
cd /home/test/snowboy/examples/Python3/python demo.py成功之后会打印识别内容,然后删除本地录音文件。
相关文章:
sherpa-onnx实现离线语音识别【语音助手】)
snowboy+新一代kaldi(k2-fsa)sherpa-onnx实现离线语音识别【语音助手】
背景 本系列主要目标初步完成一款智能音箱的基础功能,包括语音唤醒、语音识别(语音转文字)、处理用户请求(比如查天气等,主要通过rasa自己定义意图实现)、语音合成(文字转语音)功能。 语音识别、语音合成采用离线方式实现。 语…...
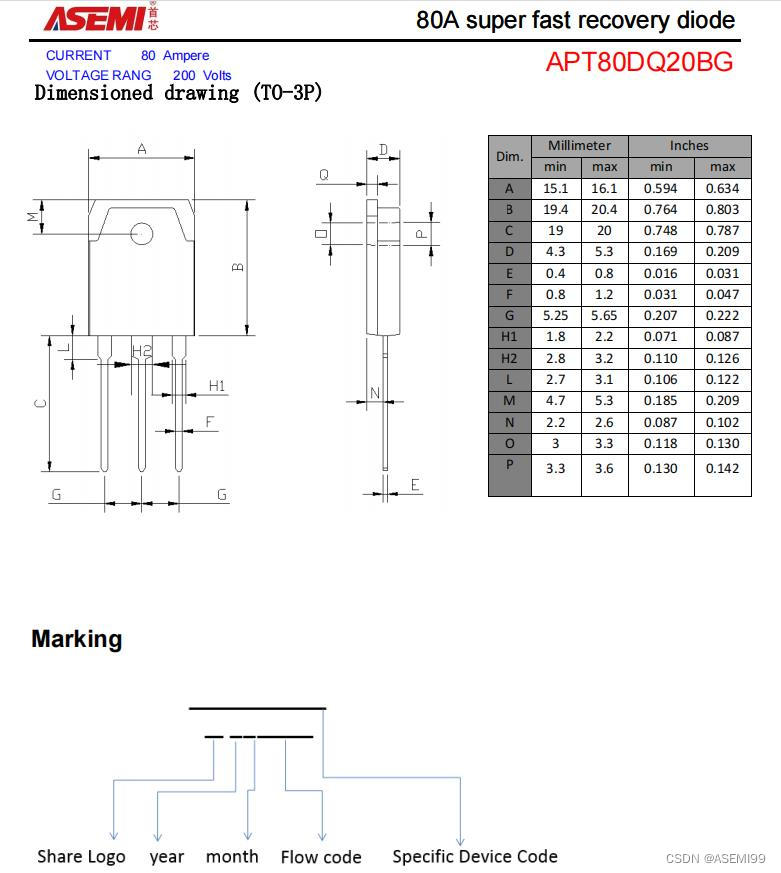
APT80DQ20BG-ASEMI快恢复二极管80A 200V
编辑:ll APT80DQ20BG-ASEMI快恢复二极管80A 200V 型号:APT80DQ20BG 品牌:ASEMI 芯片个数:双芯片 封装:TO-3P 恢复时间:≤50ns 工作温度:-55C~150C 浪涌电流:600A*2 正向电流…...

Go的任务调度单元与并发编程
摘要:本文由葡萄城技术团队于CSDN原创并首发。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 前言 本文主要介绍Go语言、进程、线程、协程的出现背景原因以及Go 语言如何解决协程的…...

PDFbox教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 PDFBox是一个开源Java库,支持PDF文档的开发和转换.使用此库,您可以开发用于创建,转换和操作PDF文档的Java程序.除此之外,PDFBox还包括一个命令行实用程序,用于使用可用的PDF对PDF执行各种操作Jar文件. PDFB…...

Node.js-模块化理解及基本使用
模块化的定义 讲一个复杂的程序文件按照一定的规则拆分成多个独立的小文件,这些小文件就是小模块,这就是模块化。 每个小模块内部的数据是私有的,可以暴露内部数据给外部其他模块使用。 模块化优点 减少命名的冲突提高复用性提高可维护性按需…...

arguments 和 剩余参数
加油 !! 💕 文章目录 前言一、arguments二、arguments转成array三、箭头函数不绑定arguments四、剩余参数 ... 前言 其实在es6之后不推荐使用 arguments , 建议使用剩余参数 一、arguments arguments 是一个 对应于 传递给函数的参数 的 类数…...
)
【BASH】回顾与知识点梳理(十二)
【BASH】回顾与知识点梳理 十二 十二. Linux 文件与目录管理12.1 目录与路径相对路径与绝对路径相对路径的用途绝对路径的用途 12.2 目录的相关操作cd (change directory, 变换目录)pwd (Print Working Directory, 显示目前所在的目录)mkdir (make directory, 建立新目录)rmdir…...
本地构建包含java和maven的镜像
目录 1.前提条件 2.下载 2.1.创建Dockerfile 3.构建镜像 参考文章 1.前提条件 本地环境需要的系统和软件 win10 Docker Desktop Powershell 图1 Win10安装Docker后,直接在Powershell使用Docker命令 有些Developer不习惯win10系统,却想要使用Lin…...

Programming abstractions in C阅读笔记:p76-p83
《Programming Abstractions In C》学习第42天,p76-p73总结。 一、技术总结 1.数组和指针 在C语言中,数组和指针非常相似,相似到必须将它们同时考虑,当看到数组就应该想到指针,当看到指针就应该想到数组。示例…...
|neo4j Failed authentication attempt for ‘meter‘ from 127.0.0.1)
已解决(三个问题)|neo4j Failed authentication attempt for ‘meter‘ from 127.0.0.1
问题1 py2neo.errors.ConnectionUnavailable: Connection has been closed 问题2 neo4j Failed authentication attempt for ‘meter’ from 127.0.0.1 问题3 py2neo.errors,ClientError: [Security.Unauthorized] Invalid username or password. 作者:xiao黄 博客地址:http…...

neo4j查询语言Cypher详解(二)--Pattern和类型
Patterns 图形模式匹配是Cypher的核心。它是一种用于通过应用声明性模式从图中导航、描述和提取数据的机制。在MATCH子句中,可以使用图模式定义要搜索的数据和要返回的数据。图模式匹配也可以在不使用MATCH子句的情况下在EXISTS、COUNT和COLLECT子查询中使用。 图…...

动态规划(用空间换时间的算法)原理逻辑代码超详细!参考自《算法导论》
动态规划(用空间换时间的算法)-实例说明和用法详解 动态规划(DP)思想实例说明钢条切割问题矩阵链乘法问题 应用满足的条件和场景 本篇博客以《算法导论》第15章动态规划算法为本背景,大量引用书中内容和实例࿰…...

Jmeter添加cookie的两种方式
jmeter中添加cookie可以通过配置HTTP Cookie Manager,也可以通过HTTP Header Manager,因为cookie是放在头文件里发送的。 实例:博客园点击添加新随笔 https://i.cnblogs.com/EditPosts.aspx?opt1 如果未登录,跳转登录页…...
【ArcGIS Pro二次开发】(58):数据的本地化存储
在做村规工具的过程中,需要设置一些参数,比如说导图的DPI,需要导出的图名等等。 每次导图前都需要设置参数,虽然有默认值,但还是需要不时的修改。 在使用的过程中,可能会有一些常用的参数,希望…...

React配置代理服务器的5种方法
五种方法的介绍 以下是五种在React项目中配置代理服务器的方法的使用场景和优缺点: 1. 使用 http-proxy-middleware 中间件: 使用场景:适用于大多数React项目,简单易用。优点:配置简单,易于理解和维护。…...

树莓派:5.jar程序自启运行
搞了好长时间才搞定,普通的jar文件好启动。神奇的在于在ssh里启动GPIO可以操作,但是自启动GPIO不能控制。第二天才想明白估计是GPIO的操作权限比较高,一试果然如此,特此记录。 1、copy程序文件和sh文件在Public下 piraspberrypi…...

Vivado中SmartConnect和InterConnect的区别
前言:本文章为FPGA问答系列,我们会定期整理FPGA交流群(包括其他FPGA博主的群)里面有价值的问题,并汇总成文章,如果问题多的话就每周整理一期,如果问题少就每两周整理一期,一方面是希…...

了解HTTP代理日志:解读请求流量和响应信息
嗨,爬虫程序员们!你们是否在了解爬虫发送的请求流量和接收的响应信息上有过困扰?今天,我们一起来了解一下。 首先,我们需要理解HTTP代理日志的基本结构和内容。HTTP代理日志是对爬虫发送的请求和接收的响应进行记录的文…...

排序-堆排序
给你一个整数数组 nums,请你将该数组升序排列。 输入:nums [5,2,3,1] 输出:[1,2,3,5] 输入:nums [5,1,1,2,0,0] 输出:[0,0,1,1,2,5] 思路直接看我录制的视频吧 算法-堆排序_哔哩哔哩_bilibili 实现代码如下所示&…...

挑战Open AI!!!马斯克宣布成立xAI.
北京时间7月13日凌晨,马斯克在Twitter上宣布:“xAI正式成立,去了解现实。”马斯克表示,推出xAI的原因是想要“了解宇宙的真实本质”。Ghat GPT横空出世已有半年,国内外“百模大战”愈演愈烈,AI大模型的现状…...

6000万美元拿下世界杯:FIFA终于清醒了?
5月15号下午,央视和国际足联官宣了新周期的版权合作。朋友圈里炸开了锅,大家都在讨论那个数字:6000万美元。这是2026年美加墨世界杯的中国区转播权价格。说实话,看到这个价格我有点意外。上一届卡塔尔世界杯,传闻中的版…...

基于电子纸与ESP32的物联网桌面日历制作指南
1. 项目概述:打造一个永不掉电的桌面物联网日历如果你和我一样,喜欢在桌面上放点既实用又有科技感的小玩意儿,那么这个基于电子纸的物联网日历绝对能让你眼前一亮。它不像普通屏幕那样需要一直插着电,显示完日历后,你甚…...
:含17个已验证失效词黑名单与8组高通过率--sref权重组合)
Midjourney极简艺术风格实战手册(2024V6.2最新适配版):含17个已验证失效词黑名单与8组高通过率--sref权重组合
更多请点击: https://intelliparadigm.com 第一章:Midjourney极简艺术风格的核心定义与美学边界 极简艺术风格在 Midjourney 中并非单纯减少元素,而是通过语义压缩、形式提纯与负空间策略构建高度凝练的视觉语言。其核心在于以最少的视觉单元…...

如何分析SQL嵌套查询瓶颈_使用执行计划查看开销
应优先分析子查询的执行耗时而非行数:PostgreSQL看Subquery Scan的Actual Total Time,MySQL用EXPLAIN FORMATJSON查SUBQUERY/DERIVED的rows与filtered,若rows大且filtered低则索引失效。怎么看 EXPLAIN 里哪个子查询最拖后腿嵌套查询慢&#…...

为什么FlicFlac是Windows用户必备的音频格式转换神器?
为什么FlicFlac是Windows用户必备的音频格式转换神器? 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备间的音频格式不兼容而烦…...

ARMv8-M架构安全扩展与嵌入式系统配置详解
1. ARM_AEMv8M架构概述ARM_AEMv8M是ARMv8-M架构的扩展实现,专为嵌入式系统设计,提供了硬件级的安全隔离能力。这个架构引入了TrustZone安全扩展和MPU内存保护机制,使得开发者能够在资源受限的嵌入式设备上实现强大的安全功能。1.1 核心特性解…...

BLE GATT客户端开发实战:从服务发现到数据解析
1. 项目概述与核心概念解析在物联网和可穿戴设备领域,蓝牙低功耗(BLE)技术因其低功耗和标准化协议栈,已成为短距离无线通信的首选方案。其核心通信模型基于GATT(通用属性配置文件),这是一种结构…...
)
新手也能搞定!用Simulink搭建晶闸管直流调速系统(附完整模型文件)
从零构建晶闸管直流调速系统的Simulink实战指南 电力电子领域的研究生和工程师们常常需要快速掌握经典电路仿真技能。本文将手把手带你完成晶闸管直流调速系统的建模全过程,从模块选择到参数调试,每个环节都配有详细说明和实用技巧。不同于传统教材偏重理…...

观察使用 Token Plan 套餐后月度模型调用成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用 Token Plan 套餐后月度模型调用成本的变化趋势 作为一名中小型项目的开发者,管理大模型 API 的调用成本是项目…...

在macOS上运行Windows应用:为什么传统方案失败而Whisky成功
在macOS上运行Windows应用:为什么传统方案失败而Whisky成功 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经面临这样的困境:手头有一款必须使用的W…...