机器学习参数调优
手动调参
分析影响模型的参数,设计步长进行交叉验证
我们以随机森林为例:
本文将使用sklearn自带的乳腺癌数据集,建立随机森林,并基于泛化误差(Genelization Error)与模型复杂度的关系来对模型进行调参,从而使模型获得更高的得分。
泛化误差是机器学习中,用来衡量模型在未知数据上的准确率的指标;
1、导入相关包
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt2、导入乳腺癌数据集,建立模型
由于sklearn自带的数据集已经很工整了,所以无需做预处理,直接使用。
# 导入乳腺癌数据集
data = load_breast_cancer()# 建立随机森林
rfc = RandomForestClassifier(n_estimators=100, random_state=90)用交叉验证计算得分
score_pre = cross_val_score(rfc, data.data, data.target, cv=10).mean()
score_pre3、调参
随机森林主要的参数有n_estimators(子树的数量)、max_depth(树的最大生长深度)、min_samples_leaf(叶子的最小样本数量)、min_samples_split(分支节点的最小样本数量)、max_features(最大选择特征数)。它们对随机森林模型复杂度的影响如下图所示:
n_estimators是影响程度最大的参数,我们先对其进行调整
# 调参,绘制学习曲线来调参n_estimators(对随机森林影响最大)
score_lt = []# 每隔10步建立一个随机森林,获得不同n_estimators的得分
for i in range(0,200,10):rfc = RandomForestClassifier(n_estimators=i+1,random_state=90)score = cross_val_score(rfc, data.data, data.target, cv=10).mean()score_lt.append(score)
score_max = max(score_lt)
print('最大得分:{}'.format(score_max),'子树数量为:{}'.format(score_lt.index(score_max)*10+1))# 绘制学习曲线
x = np.arange(1,201,10)
plt.subplot(111)
plt.plot(x, score_lt, 'r-')
plt.show()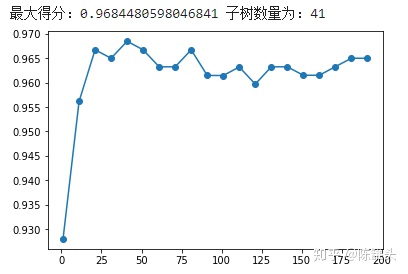
如图所示,当n_estimators从0开始增大至21时,模型准确度有肉眼可见的提升。这也符合随机森林的特点:在一定范围内,子树数量越多,模型效果越好。而当子树数量越来越大时,准确率会发生波动,当取值为41时,获得最大得分。
框架自动调参
Optuna是一个自动化的超参数优化软件框架,专门为机器学习而设计。 这里对其进行简单的入门介绍,详细的学习可以参考:https://github.com/optuna/optuna
optuna是一个使用python编写的超参数调节框架。一个极简的 optuna 的优化程序中只有三个最核心的概念,目标函数(objective),单次试验(trial),和研究(study)。其中 objective 负责定义待优化函数并指定参/超参数数范围,trial 对应着 objective 的单次执行,而 study 则负责管理优化,决定优化的方式,总试验的次数、试验结果的记录等功能。
- objective:根据目标函数的优化Session,由一系列的trail组成。
- trail:根据目标函数作出一次执行。
- study:根据多次trail得到的结果发现其中最优的超参数。
随机森林iris数据集调优
from sklearn.datasets import load_iris
x, y = load_iris().data, load_iris().target
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
def objective(trial):global x, yX_train, X_test, y_train, y_test=train_test_split(x, y, train_size=0.3)# 数据集划分param = {"n_estimators": trial.suggest_int('n_estimators', 5, 20),"criterion": trial.suggest_categorical('criterion', ['gini','entropy'])}dt_clf = RandomForestClassifier(**param)dt_clf.fit(X_train, y_train)pred_dt = dt_clf.predict(X_test)score = (y_test==pred_dt).sum() / len(y_test)return score
study=optuna.create_study(direction='maximize')
n_trials=20 # try50次
study.optimize(objective, n_trials=n_trials)
print(study.best_value)
print(study.best_params)
#######################################结果######################################
[32m[I 2021-04-12 16:20:13,627][0m A new study created in memory with name: no-name-47fe20d7-e9c0-4bed-bc6d-8113edae0bec[0m
[32m[I 2021-04-12 16:20:13,652][0m Trial 0 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 15, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,662][0m Trial 1 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 5, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,680][0m Trial 2 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 15, 'criterion': 'entropy'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,689][0m Trial 3 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 7, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,704][0m Trial 4 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 14, 'criterion': 'gini'}. Best is trial 0 with value: 0.9523809523809523.[0m
[32m[I 2021-04-12 16:20:13,721][0m Trial 5 finished with value: 0.9714285714285714 and parameters: {'n_estimators': 14, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,733][0m Trial 6 finished with value: 0.9619047619047619 and parameters: {'n_estimators': 10, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,753][0m Trial 7 finished with value: 0.9619047619047619 and parameters: {'n_estimators': 18, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,764][0m Trial 8 finished with value: 0.9714285714285714 and parameters: {'n_estimators': 8, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,771][0m Trial 9 finished with value: 0.9333333333333333 and parameters: {'n_estimators': 5, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,795][0m Trial 10 finished with value: 0.9333333333333333 and parameters: {'n_estimators': 20, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,809][0m Trial 11 finished with value: 0.9333333333333333 and parameters: {'n_estimators': 9, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,827][0m Trial 12 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 12, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,842][0m Trial 13 finished with value: 0.9238095238095239 and parameters: {'n_estimators': 11, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,855][0m Trial 14 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 8, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,880][0m Trial 15 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 18, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,899][0m Trial 16 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 13, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,911][0m Trial 17 finished with value: 0.9714285714285714 and parameters: {'n_estimators': 7, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,933][0m Trial 18 finished with value: 0.9428571428571428 and parameters: {'n_estimators': 17, 'criterion': 'entropy'}. Best is trial 5 with value: 0.9714285714285714.[0m
[32m[I 2021-04-12 16:20:13,948][0m Trial 19 finished with value: 0.9523809523809523 and parameters: {'n_estimators': 11, 'criterion': 'gini'}. Best is trial 5 with value: 0.9714285714285714.[0m0.9714285714285714
{'n_estimators': 14, 'criterion': 'gini'}
##################################################################################相关文章:
机器学习参数调优
手动调参 分析影响模型的参数,设计步长进行交叉验证 我们以随机森林为例: 本文将使用sklearn自带的乳腺癌数据集,建立随机森林,并基于泛化误差(Genelization Error)与模型复杂度的关系来对模型进行调参&…...

[Java基础]面向对象-关键字分析:this,static,final,super
系列文章目录 【Java基础】Java总览_小王师傅66的博客-CSDN博客 [Java基础]基本概念(上)(标识符,关键字,基本数据类型)_小王师傅66的博客-CSDN博客 [Java基础]基本概念(下)运算符,表达式和语句,分支,循环,方法,变量的作用域,递归调用_小王师傅66的博客-CSDN博客 [Java基础]…...

数据结构初阶--二叉树的顺序结构之堆
目录 一.堆的概念及结构 1.1.堆的概念 1.2.堆的存储结构 二.堆的功能实现 2.1.堆的定义 2.2.堆的初始化 2.3.堆的销毁 2.4.堆的打印 2.5.堆的插入 向上调整算法 堆的插入 2.6.堆的删除 向下调整算法 堆的删除 2.7.堆的取堆顶元素 2.8.堆的判空 2.9.堆的求堆的…...

NVM Command学习
ubuntu系统安装nvme-cli,可以在应用层发起命令。 sudo apt install nvme-cli$ sudo nvme --help nvme-1.9 usage: nvme <command> [<device>] [<args>]The <device> may be either an NVMe character device (ex: /dev/nvme0) or an nvme …...
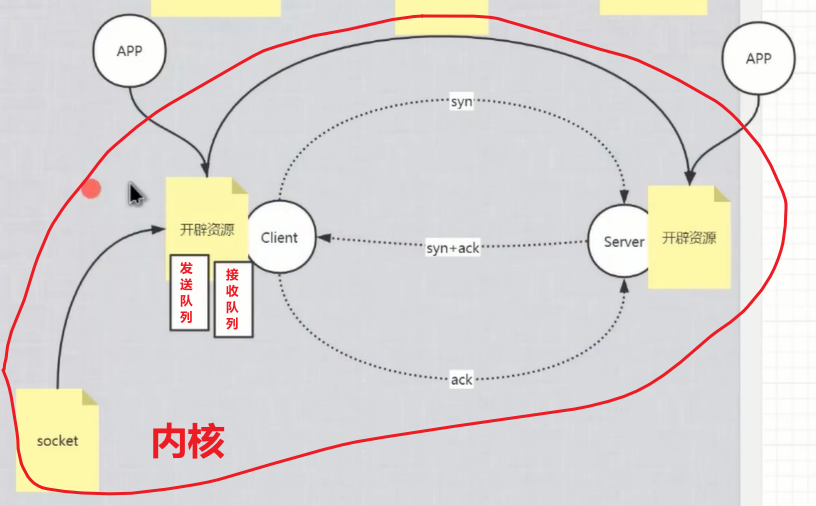
TCP Socket 基础知识点(实例是以Java进行演示)
本篇根据TCP & Socket 相关知识点和学习所得进行整理所得。 文章目录 前言1. TCP相关知识点1.1 双工/单工1.2 TCP协议的主要特点1.3 TCP的可靠性原理1.4 报文段1.4.1 端口1.4.2 seq序号1.4.3 ack确认号1.4.4 数据偏移1.4.5 保留1.4.6 控制位1.4.7 窗口1.4.8 校验和1.4.9 紧…...
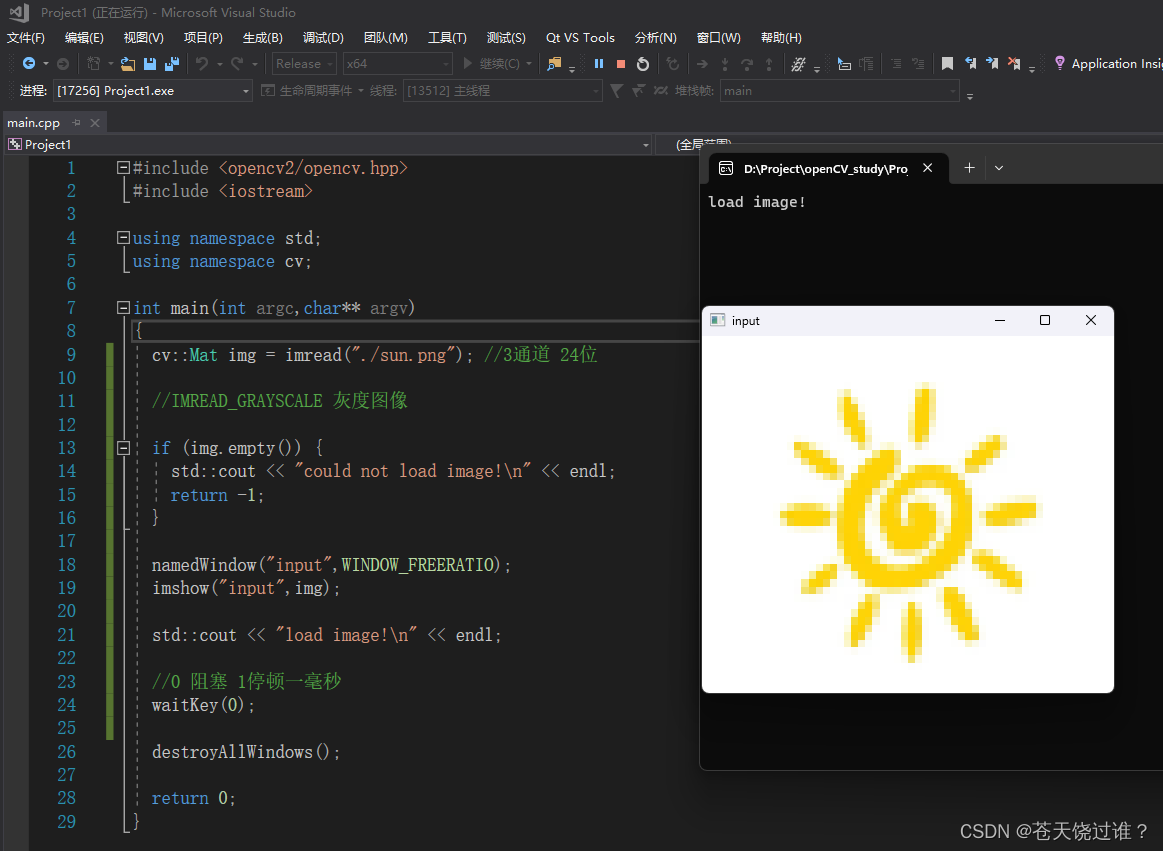
openCV图像读取和显示
文章目录 一、imread二、namedWindow三、imshow #include <opencv2/opencv.hpp> #include <iostream>using namespace std; using namespace cv;int main(int argc,char** argv) {cv::Mat img imread("./sun.png"); //3通道 24位if (img.empty()) {std:…...

requests 方法总结
当使用 requests 库进行接口自动化测试时,以下是一些详细的步骤和方法总结: 1. **安装 requests 库**:首先,确保你已经安装了 requests 库。可以使用 pip 命令进行安装:pip install requests。 2. **导入库**&#x…...

Go语言删除文本文件中的指定行
GO语言删除文本文件中的指定行 1. 思路2. 处理文件3. 处理后的文本文件 1. 思路 假设现在有一个文本文件,我们需要删除文件中乱码的行。我们可以使用go的os库来处理文件,遍历整个文件然后将除过乱码的行写入一个新文件,以此来实现我们的需求…...
Arthas GC日志-JVM(十八)
上篇文章说jvm的实际运行情况。 Jvm实际运行情况-JVM(十七) Arthas介绍 因为arthas完全是java代码写的,我们直接用命令启动: Java -jar arthas-boot.jar 启动成功后,选择我们项目的进程。 进入我们可用dashboard…...

ISC 2023︱诚邀您参与赛宁“安全验证评估”论坛
8月9日-10日,第十一届互联网安全大会(简称ISC 2023)将在北京国家会议中心举办。本次大会以“安全即服务,开启人工智能时代数字安全新范式”为主题,打造全球首场AI数字安全峰会,赋予安全即服务新时代内涵…...

分享一个计算器
先看效果: 再看代码(查看更多): <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>计算器</title><style>* {box-sizing: border-box;}body…...

Android 13 Launcher——长按图标弹窗背景变暗
目录 一.背景 二.修改代码 一.背景 客户定制需要长按图标弹窗让其背景变暗,所以需要进行定制,如下是定制流程,本篇是接上篇https://gonglipeng.blog.csdn.net/article/details/132171100 的内容 二.修改代码 主要代码逻辑在ArrowPopup中的reorderAndShow方法和closeCom…...

Elasticsearch概述和DSL查询总结
目录 Elasticsearch概述 1. 什么是Elasticsearch 2. 作用 3. 特点 DSL(Domain Specifit Language)特定领域语言: 概念和作用 查询代码总结 最后附项目准备 1.创建搜索工程(maven工程) 2.配置文件 application…...
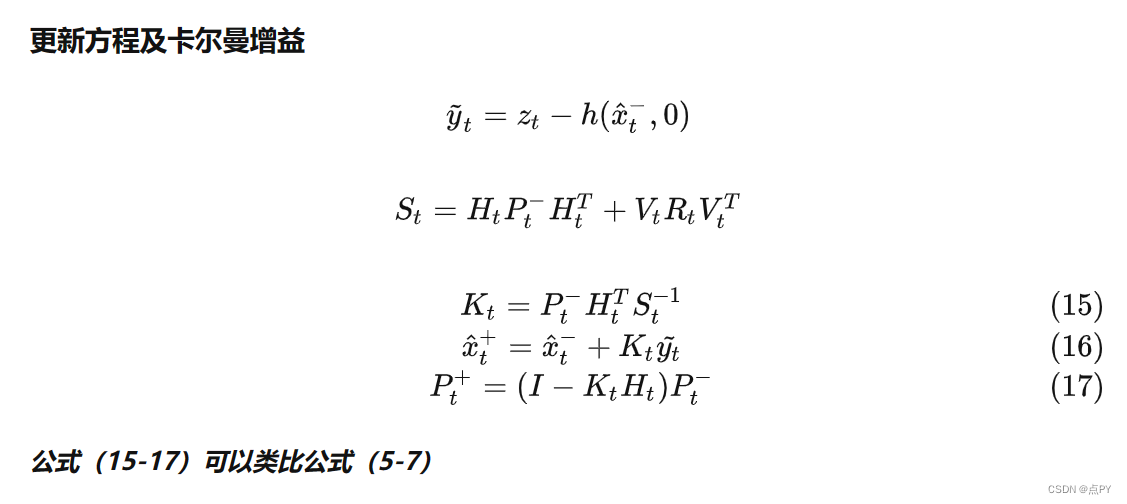
扩展卡尔曼滤波器代码
文章目录 前言问题状态向量和观测向量加性噪声的形式状态方程及求导观测方程及求导状态初始化过程噪声和观测噪声卡尔曼滤波过程code 前言 卡尔曼滤波器在1960年被卡尔曼发明之后,被广泛应用在动态系统预测。在自动驾驶、机器人、AR领域等应用广泛。卡尔曼滤波器使…...

9:00开始面试,9:08就出来了,这问题问的实在是····
外包工作3年,今年裸辞跳槽,很幸运的是找到了下家,不过 自从加入到这家公司,每天不是在加班就是在加班的路上,薪资倒是给的不少,所以我也就忍了。没想到6月一纸通知,所有人都不许加班࿰…...

揭秘:5个美国程序员与日本程序员的差异
大家好,这里是程序员晚枫。想了解更多精彩内容,快来关注程序员晚枫 今天以美国和日本程序员为例,给大家分享一下国外程序员的生活。 以下是五个美国程序员和日本程序员的的区别: 工作方式:美国程序员通常更注重自由和…...

Springboot实现简单JWT登录鉴权
登录为啥需要鉴权? 登录需要鉴权是为了保护系统的安全性和用户的隐私。在一个 Web 应用中,用户需要提供一定的身份信息(例如用户名和密码)进行登录,登录后系统会为用户生成一个身份令牌(例如 JWT Token&am…...

C++设计模式创建型之工厂模式整理
一、工厂模式分类 工厂模式属于创建型模式,一般可以细分为简单工厂模式、工厂模式和抽象工厂模式。每种都有不同的特色和应用场景。 二、工厂模式详情 1、简单工厂模式 1)概述 简单工厂模式相对来说,在四人组写的《设计模式------可复用面…...
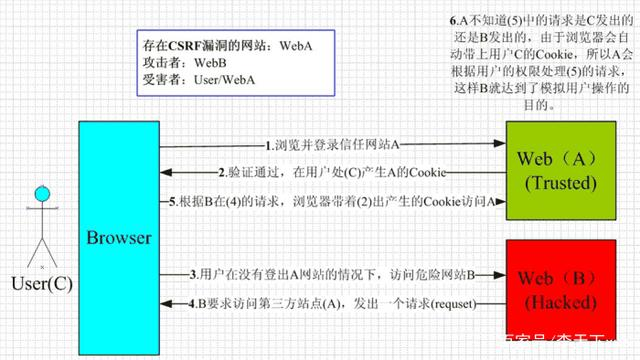
前端安全XSS和CSRF讲解
文章目录 XSSXSS攻击原理常见的攻击方式预防措施 CSRFCSRF攻击原理常见攻击情景预防措施: CSRF和XSS的区别 XSS 全称Cross Site Scripting,名为跨站脚本攻击。为啥不是单词第一个字母组合CSS,大概率与样式名称css进行区分。 XSS攻击原理 不…...

本地化部署自建类ChatGPT服务远程访问
本地化部署自建类ChatGPT服务远程访问 文章目录 本地化部署自建类ChatGPT服务远程访问前言系统环境1. 安装Text generation web UI2.安装依赖3. 安装语言模型4. 启动5. 安装cpolar 内网穿透6. 创建公网地址7. 公网访问8. 固定公网地址 🍀小结🍀 前言 Te…...
数字化IT架构蓝图规划设计方案(附下载方式))
(122页PPT)数字化IT架构蓝图规划设计方案(附下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2501_92796370/92683861 资料解读:数字化 IT 架构蓝图规划设计方案 详细资料请看本解读文章的最后内容 在数字化转型浪潮下,运营商…...

仅限首批200名DevOps工程师解密:DeepSeek内部CI/CD可观测性看板DSL语法与12个预置PromQL故障模式模板
更多请点击: https://intelliparadigm.com 第一章:DeepSeek CI/CD流水线的可观测性演进与战略定位 可观测性已从传统监控的“事后响应”范式,跃迁为DeepSeek CI/CD流水线的核心设计原则与战略支点。它不再仅关注指标(Metrics&…...
)
【Midjourney批量生成黄金工作流】:20年AI工程实战总结的7步标准化流水线(附可复用Prompt模板库)
更多请点击: https://intelliparadigm.com 第一章:Midjourney批量生成工作流的底层逻辑与范式演进 Midjourney 的批量生成并非简单重复调用 /imagine,其本质是围绕提示工程(Prompt Engineering)、状态管理(…...

ROS2实战:在Ubuntu 22.04上配置思岚A2激光雷达与Humble环境
1. 环境准备与硬件连接 第一次在Ubuntu 22.04上配置思岚A2激光雷达时,我踩过不少坑。现在把这些经验整理成保姆级教程,帮你避开那些让人抓狂的报错。首先需要确认你的开发环境:一台安装好Ubuntu 22.04的电脑(建议物理机࿰…...

CC2530开发避坑指南:IAR for 8051 10.10.1新建工程到流水灯调试的完整流程
CC2530开发实战:IAR for 8051 10.10.1工程搭建与调试全解析 第一次接触CC2530和IAR开发环境时,我盯着满屏的编译错误和无法识别的仿真器,深刻理解了什么叫"从入门到放弃"。这种经历在嵌入式开发领域太常见了——特别是当你面对的是…...

如何快速完成Windows系统部署:高效自动化工具完整指南
如何快速完成Windows系统部署:高效自动化工具完整指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat Wind…...

Synabun:Node.js 高可靠 HTTP 请求策略引擎详解
1. 项目概述:一个被低估的HTTP请求库如果你经常在Node.js环境下处理HTTP请求,大概率用过axios、node-fetch或者原生的http模块。这些工具各有优劣,但当你需要处理复杂的重试逻辑、精细的速率限制、或者想在一个统一的接口下管理多种请求策略时…...

5个实用技巧解决AKShare金融数据接口的HTTP API调用问题
5个实用技巧解决AKShare金融数据接口的HTTP API调用问题 【免费下载链接】aktools AKTools is an elegant and simple HTTP API library for AKShare, built for AKSharers! 项目地址: https://gitcode.com/gh_mirrors/ak/aktools 在量化投资和金融数据分析领域…...

基于SpringBoot+Vue的CRM客户管理系统毕设
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的CRM客户管理系统以解决传统客户关系管理中存在的信息孤岛现象与业务流程低效问题。当前企业客户管理普遍面临数据…...

CPU Cache初始化:从硬件复位到软件使能的底层原理与工程实践
1. 项目概述:从开机到高速缓存就绪当按下电脑的电源键,屏幕上开始跑起一行行代码时,我们看到的通常是BIOS自检、操作系统加载的宏大叙事。但在这背后,有一个对性能影响巨大却又极其低调的“幕后英雄”正在悄然启动,它就…...