使用线性回归预测票房收入 -- 机器学习项目基础篇(10)
当一部电影被制作时,导演当然希望最大化他/她的电影的收入。但是我们能通过它的类型或预算信息来预测一部电影的收入会是多少吗?这正是我们将在本文中学习的内容,我们将学习如何实现一种机器学习算法,该算法可以通过使用电影的类型和其他相关特征来预测票房收入。
数据集链接: https://drive.google.com/file/d/1D0iYGJJDUBeR8j33HUfHffEG2LJJfxIE/view
导入库和数据集
Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D数组格式加载数据框,并具有多个功能,可一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -此库用于绘制可视化。
- Sklearn -该模块包含多个库,这些库具有预实现的功能,可以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import metrics
from xgboost import XGBRegressorimport warnings
warnings.filterwarnings('ignore')
现在将数据集加载到panda的数据框中。
df = pd.read_csv('boxoffice.csv',encoding='latin-1')
df.head()
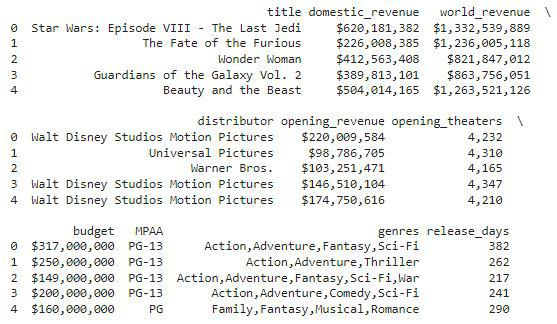
检查数据集的大小
df.shape
输出:
(2694, 10)
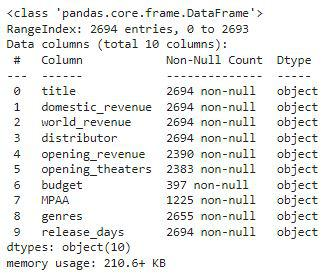
检查数据集的每列包含哪种类型的数据
df.info()
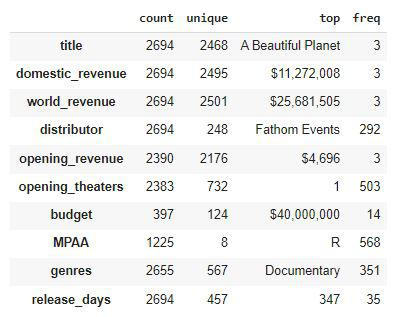
df.describe().T
数据清理
有时我们需要清理数据,因为原始数据包含大量噪声和不规则性,我们无法在这些数据上训练ML模型。因此,数据清理是任何机器学习的重要组成部分。
# We will be predicting only
# domestic_revenue in this article.to_remove = ['world_revenue', 'opening_revenue']
df.drop(to_remove, axis=1, inplace=True)
让我们检查每列中为空的条目的百分比是多少。
df.isnull().sum() * 100 / df.shape[0]
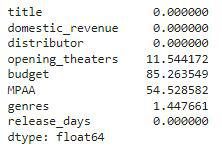
# Handling the null value columns
df.drop('budget', axis=1, inplace=True)for col in ['MPAA', 'genres']:df[col] = df[col].fillna(df[col].mode()[0])df.dropna(inplace=True)df.isnull().sum().sum()
输出:
0
df['domestic_revenue'] = df['domestic_revenue'].str[1:]for col in ['domestic_revenue', 'opening_theaters', 'release_days']:df[col] = df[col].str.replace(',', '')# Selecting rows with no null values# in the columns on which we are iterating.temp = (~df[col].isnull())df[temp][col] = df[temp][col].convert_dtypes(float)df[col] = pd.to_numeric(df[col], errors='coerce')
探索性数据分析(EDA)
EDA是一种使用可视化技术分析数据的方法。它用于发现趋势和模式,或在统计摘要和图形表示的帮助下检查假设。
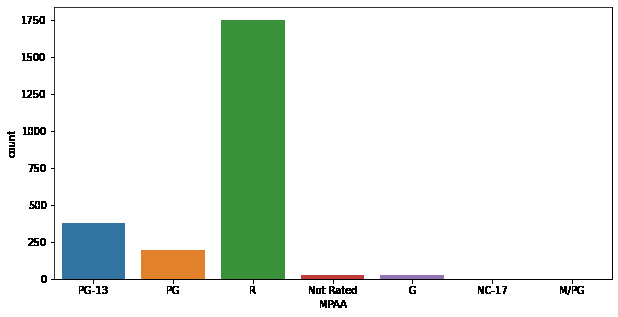
plt.figure(figsize=(10, 5))
sb.countplot(df['MPAA'])
plt.show()
df.groupby('MPAA').mean()['domestic_revenue']
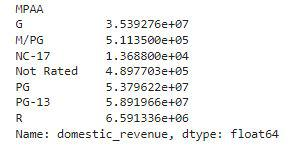
在这里,我们可以观察到PG或PG-13评级的电影通常比其他评级级别的电影收入更高。
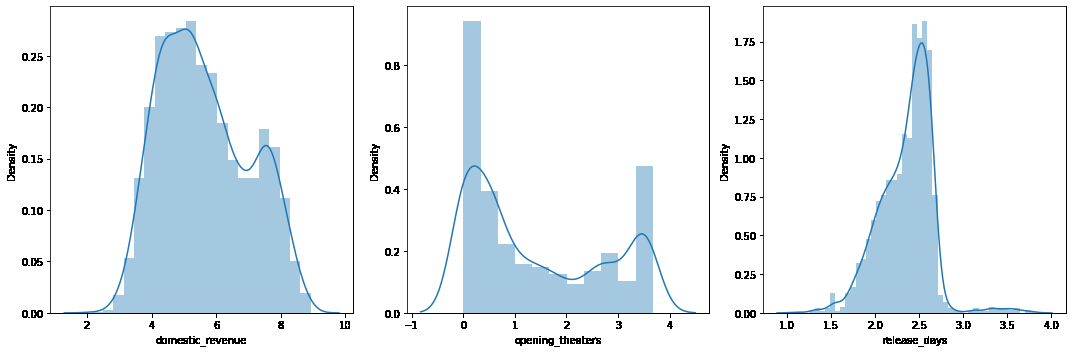
plt.subplots(figsize=(15, 5))features = ['domestic_revenue', 'opening_theaters', 'release_days']
for i, col in enumerate(features):plt.subplot(1, 3, i+1)sb.distplot(df[col])
plt.tight_layout()
plt.show()
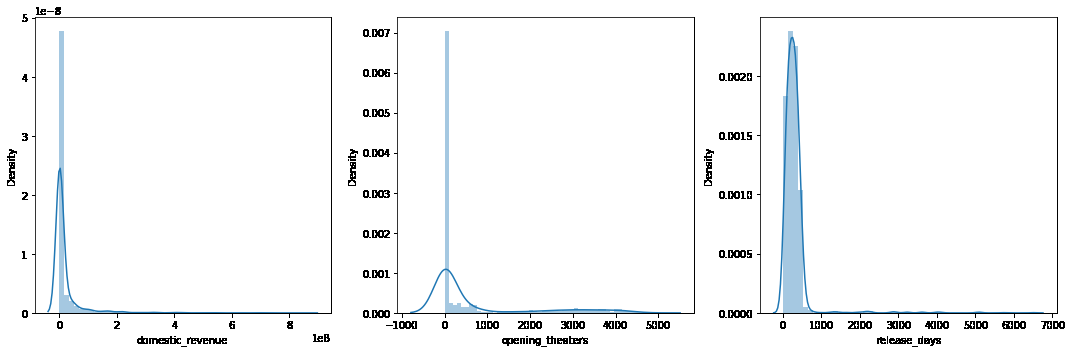
plt.subplots(figsize=(15, 5))
for i, col in enumerate(features):plt.subplot(1, 3, i+1)sb.boxplot(df[col])
plt.tight_layout()
plt.show()
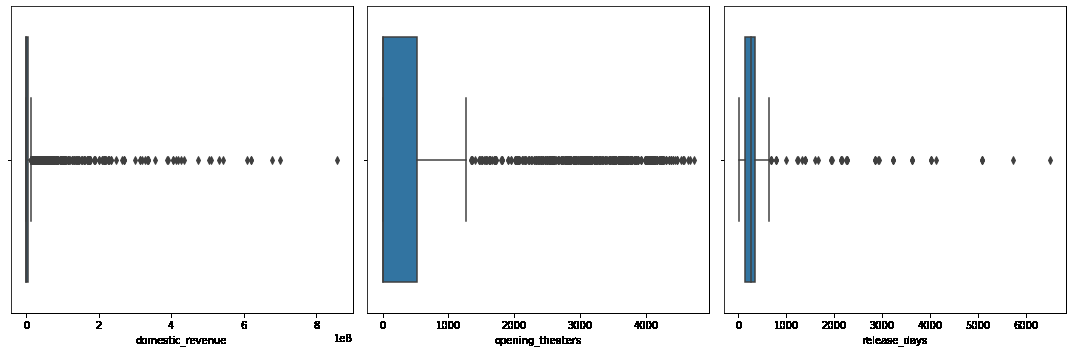
当然,在上述特征中有很多离群值。
for col in features:df[col] = df[col].apply(lambda x: np.log10(x))
现在,我们上面可视化的列中的数据应该接近正态分布。
plt.subplots(figsize=(15, 5))
for i, col in enumerate(features):plt.subplot(1, 3, i+1)sb.distplot(df[col])
plt.tight_layout()
plt.show()
从类型创建特征
vectorizer = CountVectorizer()
vectorizer.fit(df['genres'])
features = vectorizer.transform(df['genres']).toarray()genres = vectorizer.get_feature_names()
for i, name in enumerate(genres):df[name] = features[:, i]df.drop('genres', axis=1, inplace=True)
但是会有某些类型不那么频繁,这将导致不必要地增加模型的复杂性。因此,我们将删除那些非常罕见的类型。
removed = 0
for col in df.loc[:, 'action':'western'].columns:# Removing columns having more# than 95% of the values as zero.if (df[col] == 0).mean() > 0.95:removed += 1df.drop(col, axis=1, inplace=True)print(removed)
print(df.shape)
输出:
11
(2383, 24)
for col in ['distributor', 'MPAA']:le = LabelEncoder()df[col] = le.fit_transform(df[col])
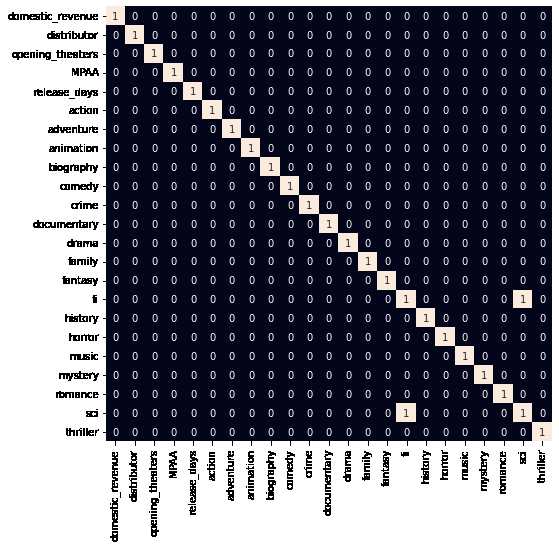
由于所有分类特征都已标记编码,让我们检查数据集中是否存在高度相关的特征。
plt.figure(figsize=(8, 8))
sb.heatmap(df.corr() > 0.8,annot=True,cbar=False)
plt.show()
模型建立
现在,我们将分离特征和目标变量,并将它们分为训练数据和测试数据,我们将使用这些数据来选择在验证数据上表现最好的模型。
features = df.drop(['title', 'domestic_revenue', 'fi'], axis=1)
target = df['domestic_revenue'].valuesX_train, X_val,\Y_train, Y_val = train_test_split(features, target,test_size=0.1,random_state=22)
X_train.shape, X_val.shape
输出:
((2144, 21), (239, 21))
# Normalizing the features for stable and fast training.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
XGBoost库模型在大多数情况下有助于实现最先进的结果,因此,我们还将训练此模型以获得更好的结果。
from sklearn.metrics import mean_absolute_error as mae
model = XGBRegressor()
model.fit(X_train, Y_train)
我们现在可以使用剩余的验证数据集来评估模型的性能。
train_preds = models[i].predict(X_train)
print('Training Error : ', mae(Y_train, train_preds))val_preds = models[i].predict(X_val)
print('Validation Error : ', mae(Y_val, val_preds))
输出:
Training Error : 0.42856612214280154
Validation Error : 0.4440195944190588
我们看到的平均绝对误差值介于预测值和实际值的对数之间,因此实际误差将高于我们上面观察到的值。
相关文章:
使用线性回归预测票房收入 -- 机器学习项目基础篇(10)
当一部电影被制作时,导演当然希望最大化他/她的电影的收入。但是我们能通过它的类型或预算信息来预测一部电影的收入会是多少吗?这正是我们将在本文中学习的内容,我们将学习如何实现一种机器学习算法,该算法可以通过使用电影的类型…...

一文读懂|RDMA原理
什么是DMA DMA全称为Direct Memory Access,即直接内存访问。意思是外设对内存的读写过程可以不用CPU参与而直接进行。我们先来看一下没有DMA的时候: 无DMA控制器时I/O设备和内存间的数据路径 假设I/O设备为一个普通网卡,为了从内存拿到需要…...
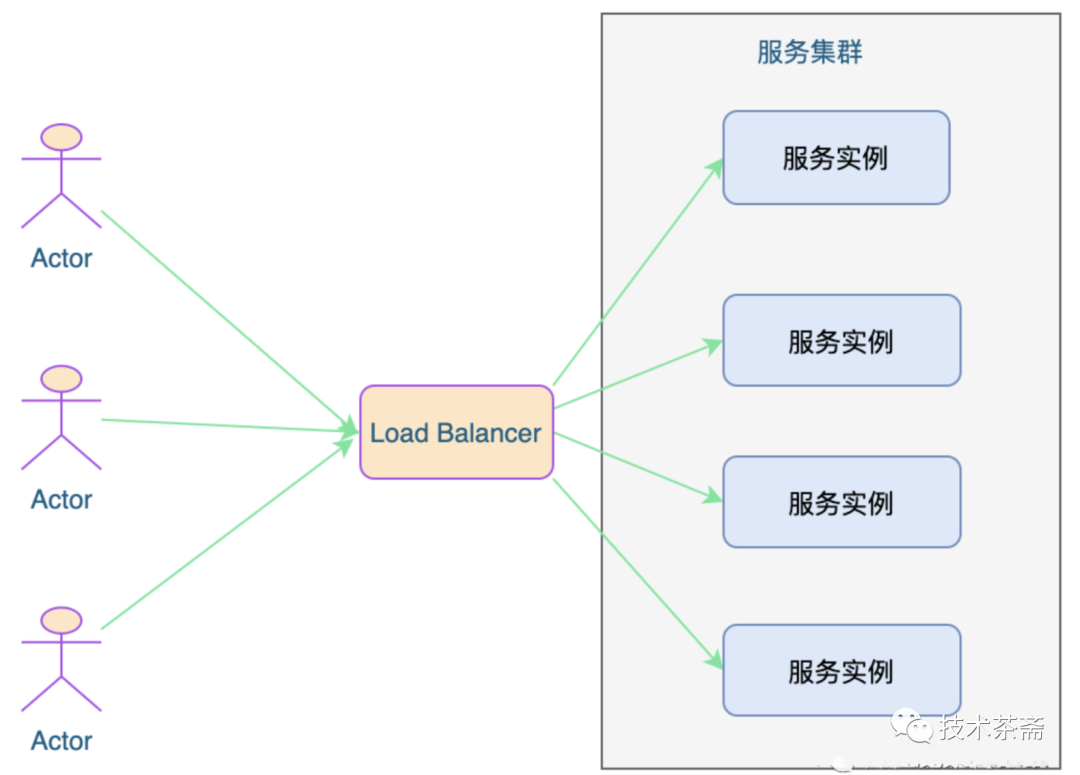
深入理解负载均衡原理及算法
1. 前言 在互联网早期,网络还不是很发达,上网用户少,流量相对较小,系统架构以单体架构为主。但如今在互联网发达的今天,流量请求动辄百亿、甚至上千亿,单台服务器或者实例已完全不能满足需求,这就有了集群。不论是为了实现高可用还是高性能,都需要用到多台机器来扩展服…...
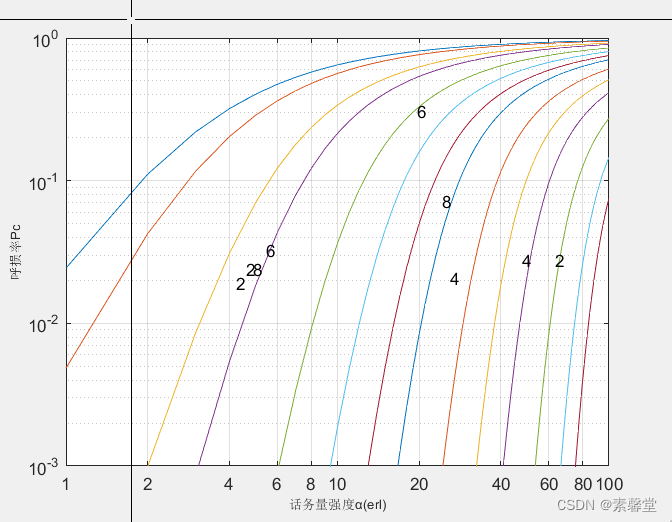
44.实现爱尔兰B公式计算并输出表格(matlab程序)
1.简述 1.话务量定义 话务量指在一特定时间内呼叫次数与每次呼叫平均占用时间的乘积。 话务量反映了电话负荷的大小,与呼叫强度和呼叫保持时间有关。呼叫强度是单位时间内发生的呼叫次数,呼叫保持时间也就是占用时间。 话务量计算方法 话务量公式为…...

【Linux】-- 进程间通信
目录 一、进程间通信介绍 二、管道 1.什么是管道(pipe) 2.重定向和管道 (1)为什么要有管道的存在 (2)重定向和管道的区别 3.匿名管道 (1)匿名管道原理 (2&…...

[PyTorch][chapter 48][LSTM -3]
简介: 主要介绍一下 sin(x): 为 数据 cos(x): 为对应的label 项目包括两个文件 main.py: 模型的训练,验证,参数保存 lstm.py 模型的构建 目录: lstm.py main.py 一 lstm.py # -*- coding: utf-8 -*- "&q…...

xss csrf 攻击
介绍 xss csrf 攻击 XSS: XSS 是指跨站脚本攻击。攻击者利用站点的漏洞,在表单提交时,在表单内容中加入一些恶意脚本,当其他正常用户浏览页面,而页面中刚好出现攻击者的恶意脚本时,脚本被执行,从…...
如何使用win10专业版系统自带远程桌面公司内网电脑,从而实现居家办公?
使用win10专业版自带远程桌面公司内网电脑 文章目录 使用win10专业版自带远程桌面公司内网电脑 在现代社会中,各类电子硬件已经遍布我们身边,除了应用在个人娱乐场景的消费类电子产品外,各项工作也离不开电脑的帮助,特别是涉及到数…...

leetcode做题笔记62
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径? 思路一…...

图论 <最短路问题>模板
图论 <最短路问题> 有向图 1.邻接矩阵,稠密图 2.邻接表 (常用)单链表,每一个点都有一个单链表 ,插入一般在头的地方插, 图的邻接表的存储方式 树的深度优先遍历 特殊的深度优先搜索,…...
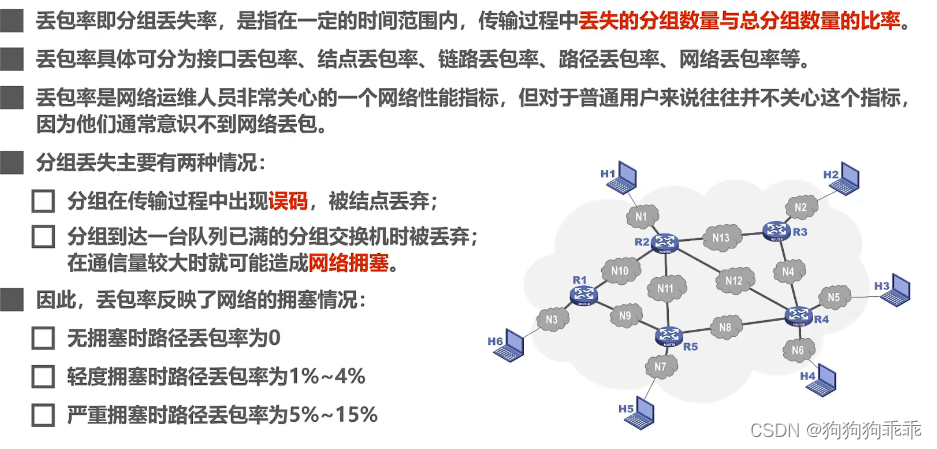
计算机网络性能指标
比特:数据量的单位 KB 2^10B 2^13 bit 比特率:连接在计算机网络上的主机在数字通道上传送比特的速率 kb/s 10^3b/s 带宽:信号所包含的各种频率不同的成分所占据的频率范围 Hz 表示在网络中的通信线路所能传送数据的能力(…...

vue + elementUI 实现下拉树形结构选择部门,支持多选,支持检索
vue elementUI 实现下拉树形结构选择部门,支持多选,支持检索 <template><div><el-select v-model"multiple?choosedValue:choosedValue[0]" element-loading-background"rgba(0,0,0,0.8)":disabled"disableFl…...
招投标系统简介 企业电子招投标采购系统源码之电子招投标系统 —降低企业采购成本 tbms
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外…...
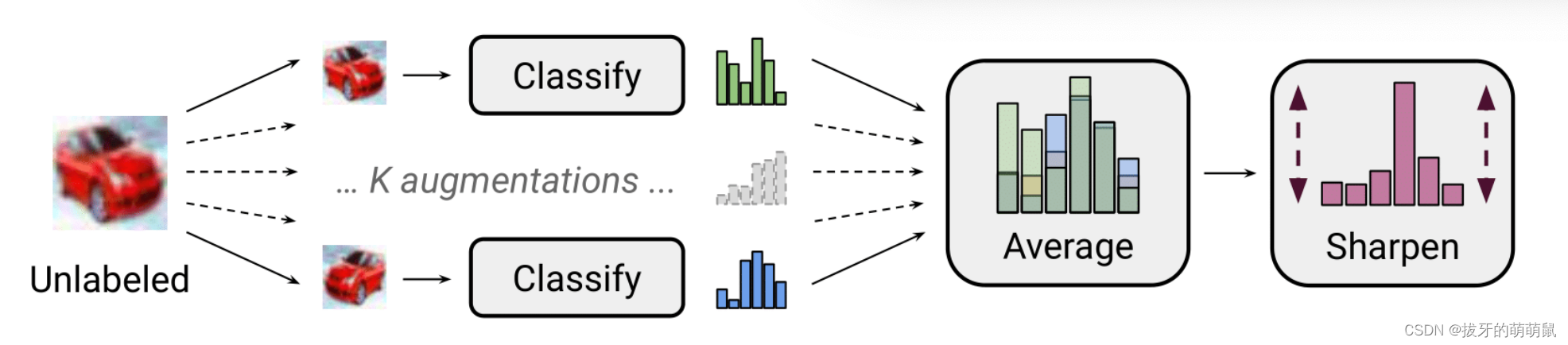
半监督学习(主要伪标签方法)
半监督学习 1. 引言 应用场景:存在少量的有标签样本和大量的无标签样本的场景。在此应用场景下,通常标注数据是匮乏的,成本高的,难以获取的,与之相对应的是却存在大量的无标注数据。半监督学习的假设:决策…...
)
datePicker一个或多个日期组件,如何快捷选择多个日期(时间段)
elementUI的组件文档中没有详细说明type"dates"如何快捷选择一个时间段的日期,我们可以通过picker-options参数来设置快捷选择: <div class"block"><span class"demonstration">多个日期</span><el…...

【语音合成】微软 edge-tts
目录 1. edge-tts 介绍 2. 代码示例 1. edge-tts 介绍 https://github.com/rany2/edge-tts 在Python代码中使用Microsoft Edge的在线文本到语音服务 2. 代码示例 import asyncio # pip install edge_tts import edge_tts TEXT """给我放首我喜欢听的歌曲…...

elevation mapping学习笔记3之使用D435i相机离线或在线订阅点云和tf关系生成高程图
文章目录 0 引言1 数据1.1 D435i相机配置1.2 协方差位姿1.3 tf 关系2 离线demo2.1 yaml配置文件2.2 launch启动文件2.3 数据录制2.4 离线加载点云生成高程图3 在线demo3.1 launch启动文件3.2 CMakeLists.txt3.3 在线加载点云生成高程图0 引言 elevation mapping学习笔记1已经成…...
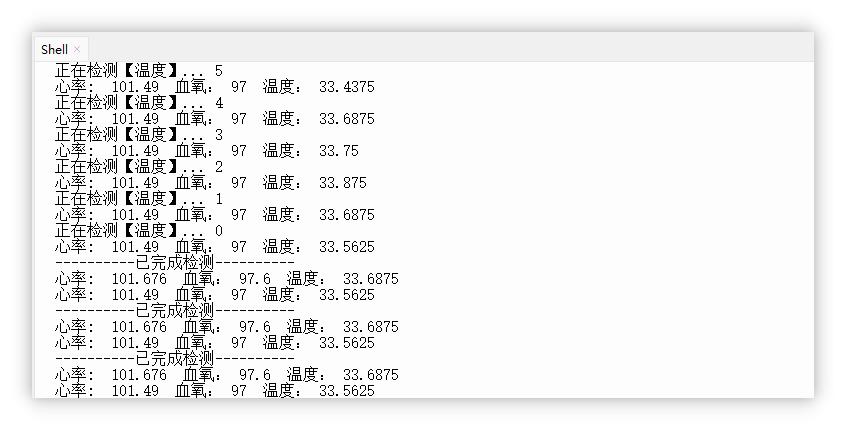
ESP32 Max30102 (3)修复心率误差
1. 运行效果 2. 新建修复心率误差.py 代码如下: from machine import sleep, SoftI2C, Pin, Timer from utime import ticks_diff, ticks_us from max30102 import MAX30102, MAX30105_PULSE_AMP_MEDIUM from hrcalc import calc_hr_and_spo2BEATS = 0 # 存储心率 FINGER_F…...

16-4_Qt 5.9 C++开发指南_Qt 应用程序的发布
文章目录 1. 应用程序发布方式2. Windows 平台上的应用程序发布 1. 应用程序发布方式 用 Qt 开发一个应用程序后,将应用程序提供给用户在其他计算机上使用就是应用程序的发布。应用程序发布一般会提供一个安装程序,将应用程序的可执行文件及需要的运行库…...

oracle容灾备份怎么样Oracle容灾备份
随着科学技术的发展和业务的增长,数据安全问题越来越突出。为了保证数据的完整性、易用性和保密性,公司需要采取一系列措施来防止内容丢失的风险。 Oracle是一个关系数据库管理系统(RDBMS),OracleCorporation是由美国软件公司开发和维护的。该系统功能…...

3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南
3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期而烦恼吗?想免费使用这款强…...

MoE大模型核心揭秘:Router路由机制与活跃参数原理
1. 这不是“参数越多越强”的简单故事:拆解大模型里那个被悄悄藏起来的“开关”你肯定见过这类标题:“GPT-4参数量达1.8万亿!”、“DeepSeek-R1狂堆6710亿参数!”——光看数字,像在比谁家粮仓更大。但真正干过模型部署…...

E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南
E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 还在为手动保存上百张漫画图片而烦恼吗&am…...

工业 CAN 通信利器!六通道隔离集线器,中继滤波稳组网
工业 CAN 总线距离受限、速率不匹配、数据拥堵、故障难排查?三格电子SG-CanHub-600 六通道 CAN 集线器,工业级隔离中继,信号再生 智能滤波,轻松解决 CAN 网络通信难题!⚙️ 硬核实力,工业通信强支撑✅ 六通…...

别再装ModelSim了!用HDLBits网页版5分钟搞定Verilog仿真和波形图
5分钟极速验证:用HDLBits网页版替代传统Verilog仿真工具 在图书馆公用电脑上突然有了个FPGA设计灵感,却发现自己没装ModelSim?公司电脑没有管理员权限,无法安装Vivado Simulator?别急着放弃——打开浏览器,…...

【Midjourney拟物化风格实战指南】:20年视觉设计专家亲授3大材质渲染公式与5步出图工作流
更多请点击: https://kaifayun.com 第一章:拟物化风格的本质与Midjourney语义解码 拟物化(Skeuomorphism)并非简单的视觉仿拟,而是一种通过材质、光影、物理反馈等多维语义锚点唤起用户认知惯性的交互范式。在AI图像生…...

【Linux驱动开发】第10天:设备树零基础入门——DTS/DTB/DTC全解+编译流程
目录 为什么需要设备树?传统驱动的终极痛点DTS/DTB/DTC 大白话定义核心区别三者关系完整编译流程图最简单的DTS示例语法解析设备树编译与反编译实操命令内核如何加载和使用设备树核心总结面试必背考点 1. 为什么需要设备树?传统驱动的终极痛点 在设备树…...

YOLOv11养殖场羊群目标检测数据集-66张-sheep-1_3
YOLOv11养殖场羊群目标检测数据集 📊 数据集基本信息 目标类别: [‘sheep-1’, ‘sheep-10’, ‘sheep-11’, ‘sheep-2’, ‘sheep-3’, ‘sheep-4’, ‘sheep-5’, ‘sheep-6’, ‘sheep-7’, ‘sheep-8’, ‘sheep-9’]中文类别:[‘羊-1’…...

实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本
实战指南:5个关键技术揭秘PUBG罗技鼠标宏后坐力控制脚本 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg logitech-pubg是一个针对《绝…...

UE5下载安装避坑指南:硬件驱动、VS环境与版本管理实战
1. 这不是“点几下就能好”的安装,而是UE5项目生命周期的第一次关键决策很多人点开Epic Games Launcher,看到那个醒目的“Install”按钮,下意识就点了下去——结果十分钟后卡在98%,或者装完打开编辑器直接报错“Failed to load mo…...