【IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建鸢尾花决策树分类预测模型】
决策树进行鸢尾花分类的案例
背景说明:
通过IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建鸢尾花决策树分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。
依赖
ThisBuild / version := "0.1.0-SNAPSHOT" ThisBuild / scalaVersion := "2.13.11" lazy val root = (project in file(".")) .settings( name := "SparkLearning", idePackagePrefix := Some("cn.lh.spark"), libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1", libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1", libraryDependencies += "org.apache.hadoop" % "hadoop-auth" % "3.3.6", libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.4.1", libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.4.1", libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.4.1", libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.30"
)
完整代码
package cn.lh.spark import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession} /** * 决策树分类器,实现鸢尾花分类 */ //case class Iris(features: org.apache.spark.ml.linalg.Vector, label: String) // MLlibLogisticRegression 中存在该样例类,这里不用写,一个包里不存在这个样例类时需要写object MLlibDecisionTreeClassifier { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().master("local[2]") .appName("Spark MLlib DecisionTreeClassifier").getOrCreate() val irisRDD: RDD[Iris] = spark.sparkContext.textFile("F:\\niit\\2023\\2023_2\\Spark\\codes\\data\\iris.txt") .map(_.split(",")).map(p => Iris(Vectors.dense(p(0).toDouble, p(1).toDouble, p(2).toDouble, p(3).toDouble), p(4).toString())) import spark.implicits._ val data: DataFrame = irisRDD.toDF() data.show() data.createOrReplaceTempView("iris") val df: DataFrame = spark.sql("select * from iris") println("鸢尾花原始数据如下:") df.map(t => t(1)+":"+t(0)).collect().foreach(println) // 处理特征和标签,以及数据分组 val labelIndexer: StringIndexerModel = new StringIndexer().setInputCol("label").setOutputCol( "indexedLabel").fit(df) val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features") .setOutputCol("indexedFeatures").setMaxCategories(4).fit(df) //这里我们设置一个labelConverter,目的是把预测的类别重新转化成字符型的 val labelConverter: IndexToString = new IndexToString().setInputCol("prediction") .setOutputCol("predictedLabel").setLabels(labelIndexer.labels) //接下来,我们把数据集随机分成训练集和测试集,其中训练集占70%。 val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3)) val dtClassifier: DecisionTreeClassifier = new DecisionTreeClassifier() .setLabelCol("indexedLabel").setFeaturesCol("indexedFeatures") //在pipeline中进行设置 val pipelinedClassifier: Pipeline = new Pipeline() .setStages(Array(labelIndexer, featureIndexer, dtClassifier, labelConverter)) //训练决策树模型 val modelClassifier: PipelineModel = pipelinedClassifier.fit(trainingData) //进行预测 val predictionsClassifier: DataFrame = modelClassifier.transform(testData) predictionsClassifier.select("predictedLabel", "label", "features").show(5) // 评估决策树分类模型 val evaluatorClassifier: MulticlassClassificationEvaluator = new MulticlassClassificationEvaluator() .setLabelCol("indexedLabel") .setPredictionCol("prediction").setMetricName("accuracy") val accuracy: Double = evaluatorClassifier.evaluate(predictionsClassifier) println("Test Error = " + (1.0 - accuracy)) val treeModelClassifier: DecisionTreeClassificationModel = modelClassifier.stages(2) .asInstanceOf[DecisionTreeClassificationModel] println("Learned classification tree model:\n" + treeModelClassifier.toDebugString) spark.stop() } }
![![[Pasted image 20230807184336.png]]](https://img-blog.csdnimg.cn/584ca5ebdbe045999dcd3fa55c5a2e21.png)
相关文章:
【IDEA + Spark 3.4.1 + sbt 1.9.3 + Spark MLlib 构建鸢尾花决策树分类预测模型】
决策树进行鸢尾花分类的案例 背景说明: 通过IDEA Spark 3.4.1 sbt 1.9.3 Spark MLlib 构建鸢尾花决策树分类预测模型,这是一个分类模型案例,通过该案例,可以快速了解Spark MLlib分类预测模型的使用方法。 依赖 ThisBuild /…...
亚马逊 EC2服务器下部署java环境
1. jdk 1.8 安装 1.1 下载jdk包 官网 Java Downloads | Oracle tar.gz 包 下载下来 1.2 本地连接 服务器 我用的是亚马逊的ec2 系统是 ubuntu 的 ssh工具是 Mobaxterm , 公有dns 创建实例时的秘钥 链接 Mobaxterm 因为使用的 ubuntu 所以登录的 名称 就是 ubuntu 然后 …...
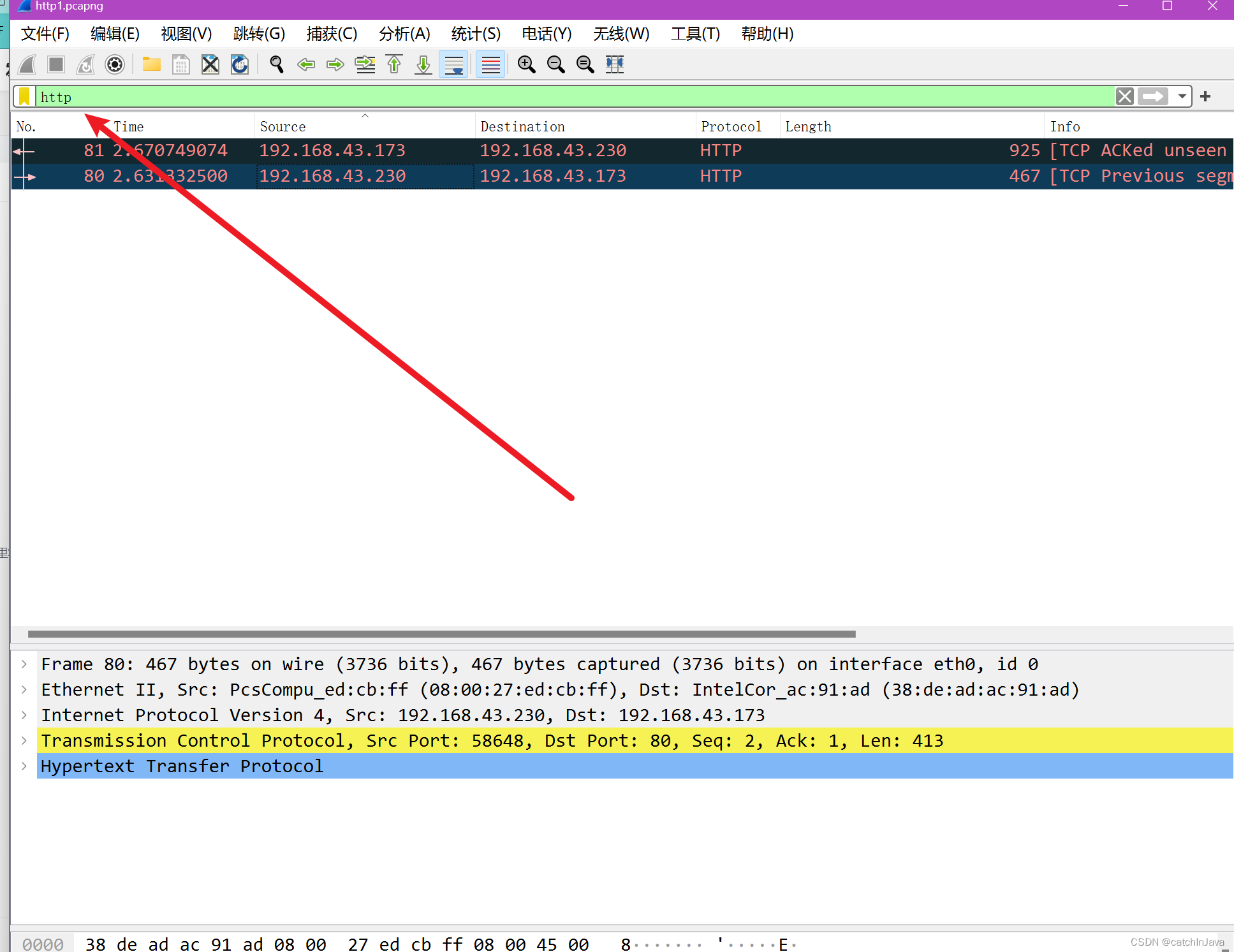
CTF流量题解http1.pcapng
使用Wireshark工具打开流量文件http1.pcapng,如下图所示。 在过滤检索栏输入http,wireshark自动进行过滤。...

若依vue前端有全局用户信息变量吗
"若依"是一个基于SpringBoot和Vue的前后端分离的开源项目。在前端Vue部分,全局用户信息通常保存在Vuex中,Vuex是Vue.js的状态管理模式。它提供了一个集中式存储来管理所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生…...
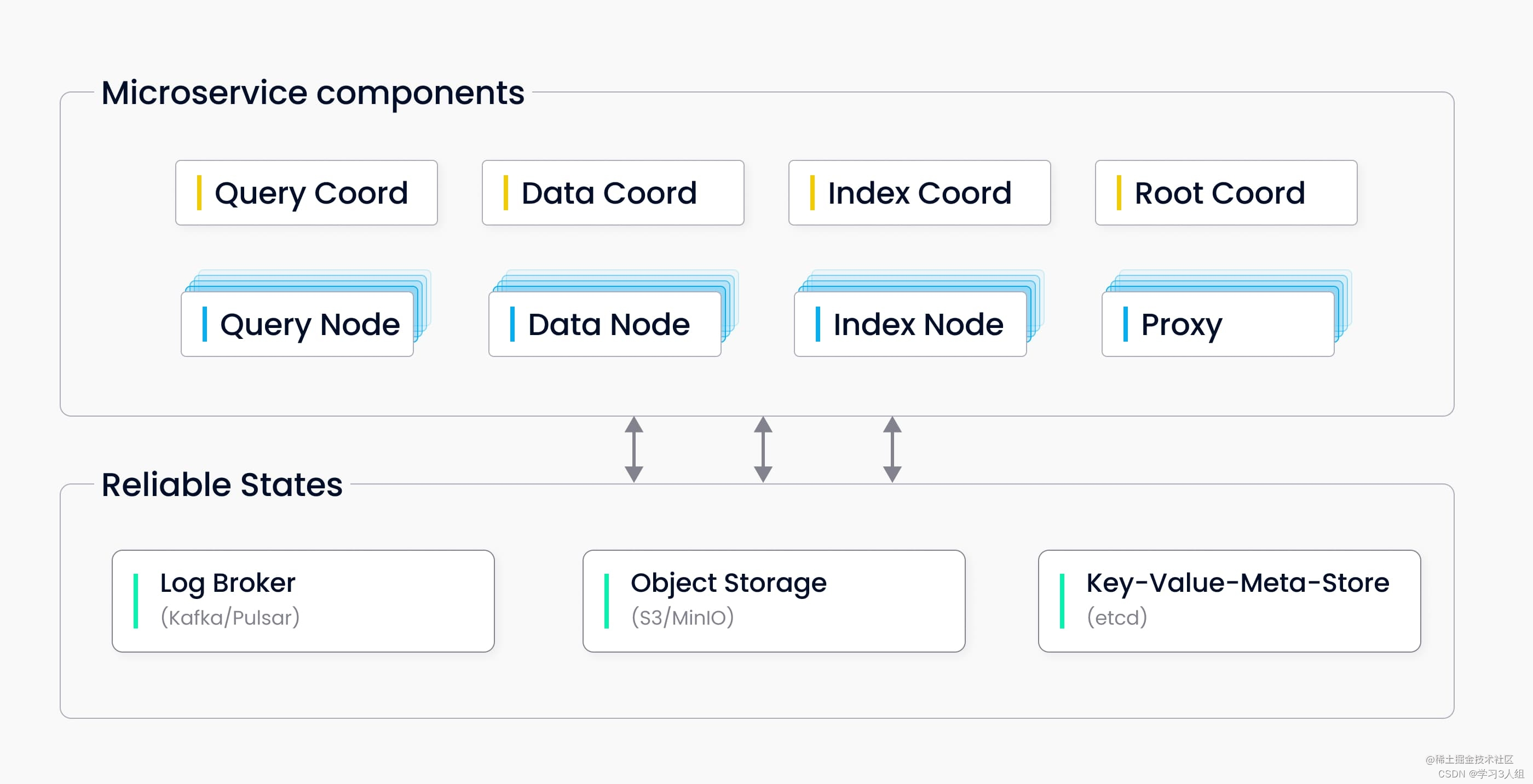
什么是Milvus
原文出处:https://www.yii666.com/blog/393941.html 什么是Milvus Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。 Milvus 基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是…...

如何快速实现三菱FX3U程序的无线下载?
1.系统概述 三菱PLC FX3u可以使用专用下载线通过计算机串口下载程序,同样也可以使用自制下载线缆,连接无线模块 DTD435M进行远程无线下载程序,计算机端采用RS232或者RS485 将计算机端与无线模块连接,PLC端同样使用RS232转RS485将…...

Flink源码之RPC
Flink是一个典型的Master/Slave分布式实时处理系统,分布式系统组件之间必然涉及通信,也即RPC,以下图展示Flink组件之间的关系: RPCGateWay 一般RPC框架可根据用户业务类生成客户端和服务器端通信底层代码,此时只需定…...
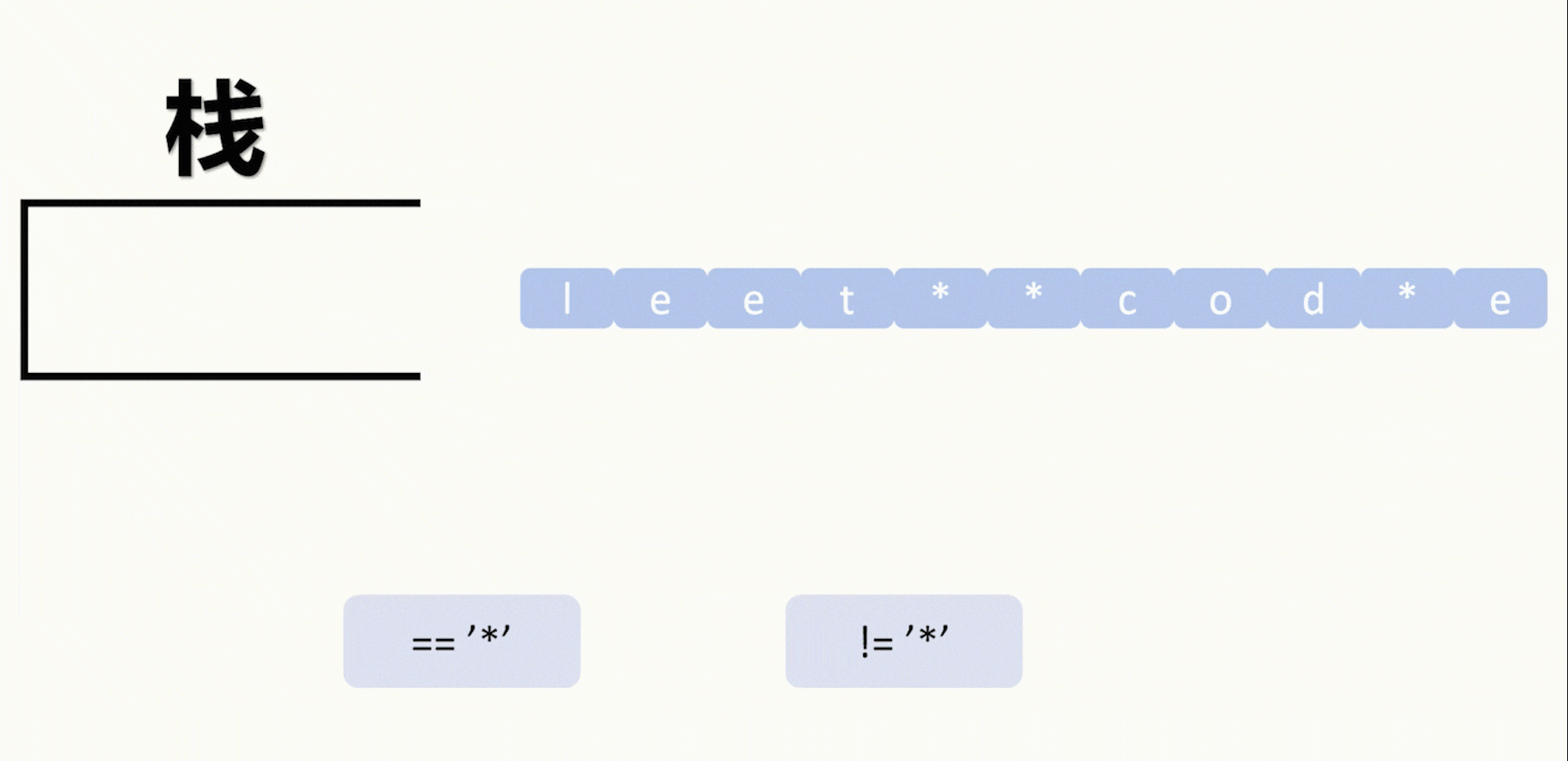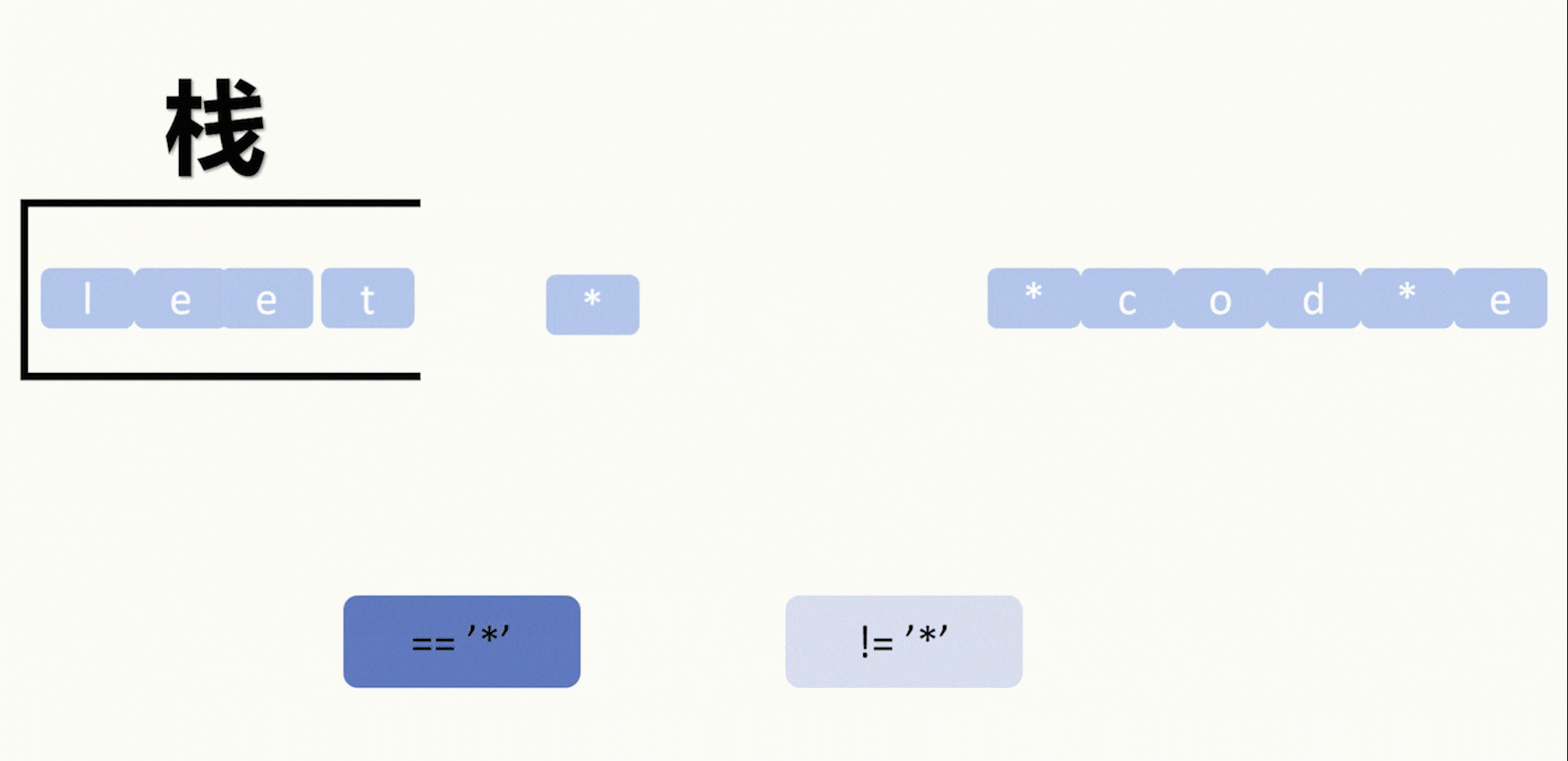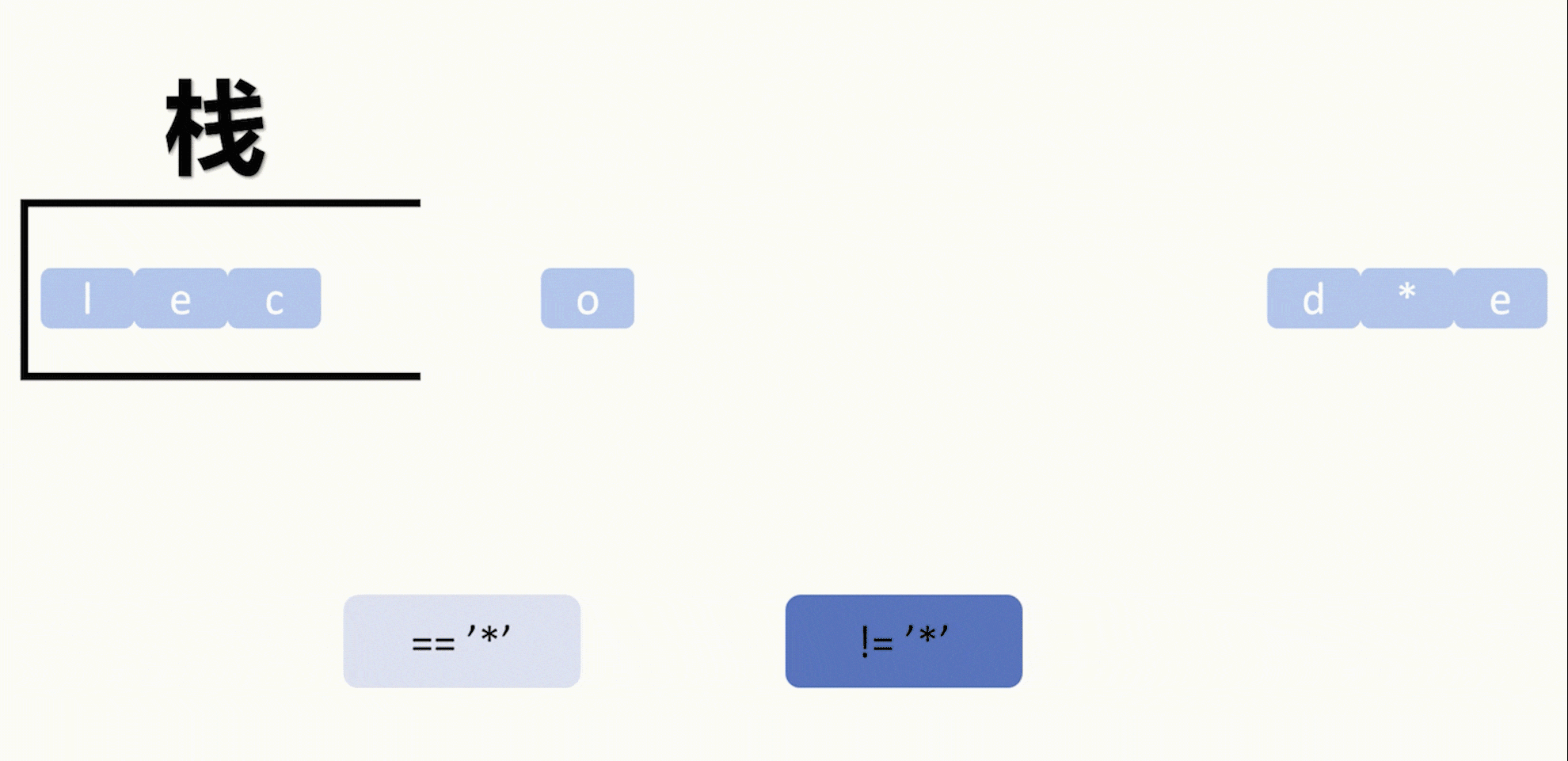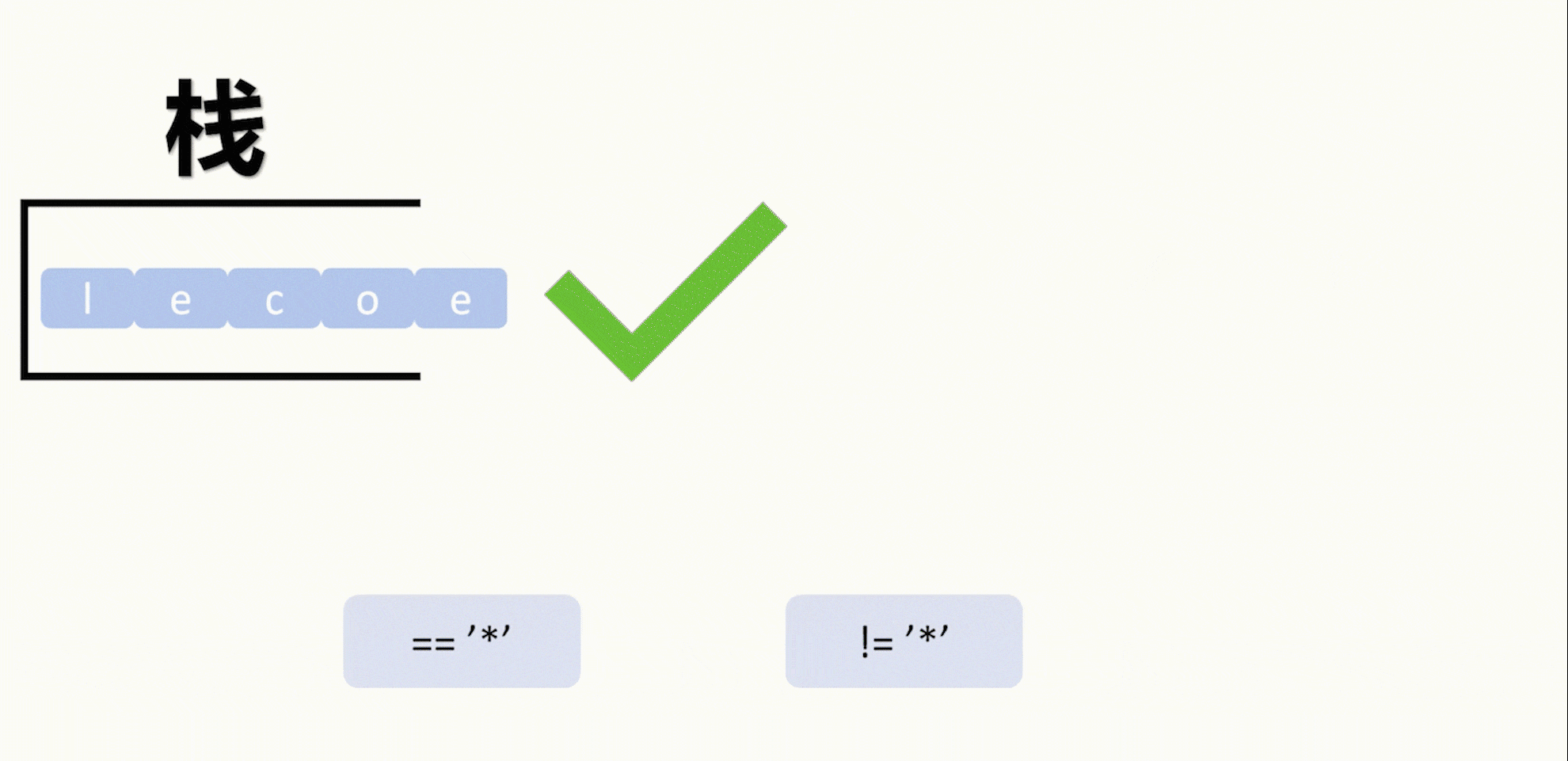
【LeetCode 75】第二十四题(2390)从字符串中移除星号
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 题目给我们一个字符串,然后字符串中包含星号*,要求每个星号消除一个从星号左边起最近的一个字符…...
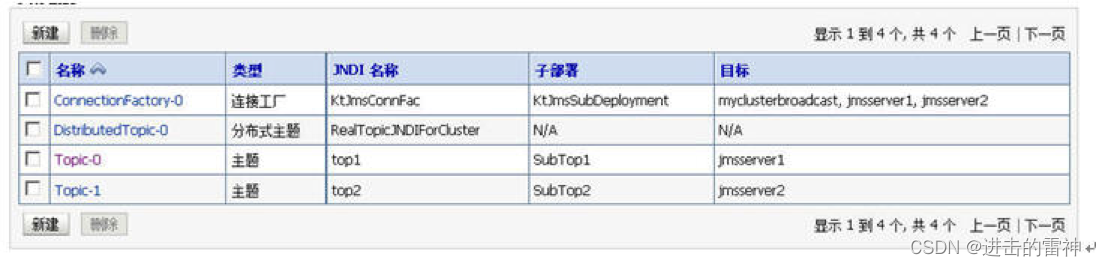
通向架构师的道路之weblogic的集群与配置
一、Weblogic的集群 还记得我们在第五天教程中讲到的关于Tomcat的集群吗? 两个tomcat做node即tomcat1, tomcat2,使用Apache HttpServer做请求派发。 现在看看WebLogic的集群吧,其实也差不多。 区别在于: Tomcat的集群的实现为两个物理上…...
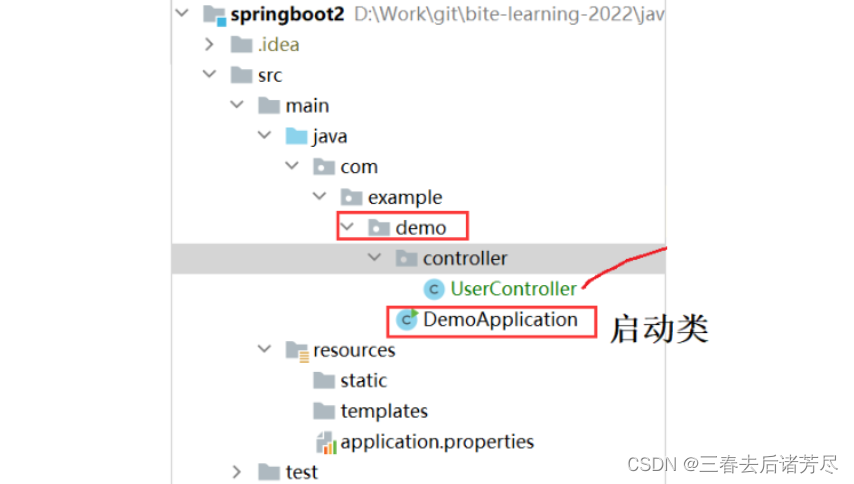
SpringBoot 项目创建与运行
一、Spring Boot 1、什么是Spring Boot?为什么要学 Spring Boot Spring 的诞生是为了简化 Java 程序的开发的,而 Spring Boot 的诞生是为了简化 Spring 程序开发的。 Spring Boot 翻译一下就是 Spring 脚手架 盖房子的这个架子就是脚手架,…...

FOHEART H1数据手套:连接虚拟与现实,塑造智能交互新未来
在全新交互时代背景中,数据手套无疑是一种重要的科技产物。它不仅彻底改变了我们与虚拟世界的互动方式,更为我们提供了一种全新、更为直观的交互形式。 FOHEART H1数据手套结合了虚拟现实、手势识别等高新技术,用先进的传感技术和精准的数据…...

MyBatis学习笔记3
日志 1.日志工厂 如果一个数据库的操作,出现了异常,我们需要排错。日志就是最好的工具。 日志工厂:SLF4JLOG4J(掌握)LOG4J2JDK_LOGGINGCOMMONS_LOGGINGSTDOUT_LOGGING(掌握)NO_LOGGING 2.分页 减少数据…...

ES6学习-Symbol
Symbol 数据类型Symbol,表示独一无二的值。 对象的属性名可有两种类型,一种是原来的字符串,另一种是新增的 Symbol 类型 可以保证不与其他属性名产生冲突。 let s1 Symbol() let s2 Symbol() console.log(s1, s2, s1 s2)//Symbol() Sy…...
【Redis】使用Docker镜像配置集群时的Operation timed out问题
不知道有没有小伙伴跟我一样是使用的Docker镜像进行Redis集群案例模拟的(三台虚拟机确实带不动 ),然后我遇到了一个问题:Could not connect to Redis at 172.17.0.2:6379: Operation timed out 172.17.0.2是我其中一个Redis实例的…...

Java 生产初学常用注解
目录 0. 基础语法逻辑运算符继承抛出异常获取数据方式泛型 1. 接收前端数据(controller)mybatis1. QueryWrapper获取和赋值 2. service 层注解 3. Dao 层(与数据库交互)3.1 mybatis-plus中BaseMapper 4. ELK框架es配置sql参数logs…...

mousedown拖拽功能(vue3+ts)
因为项目有rem适配,使用第三方插件无法处理适配问题,所有只能自己写拖拽功能了 拖拽一般都会想到按下,移动,放开,但是本人亲测,就在div绑定一个按下事件就行了(在事件里面写另外两个事件&#x…...

【论文阅读】基于深度学习的时序异常检测——TransAD
系列文章链接 数据基础:多维时序数据集简介 论文一:2022 Anomaly Transformer:异常分数预测 论文二:2022 TransAD:异常分数预测 论文链接:TransAD.pdf 代码库链接:https://github.com/imperial…...

NLPCC 出版部分相关源码记录
目录 Download Unzip Author Title Affiliation Check number of tex Zip Rename Delete Download import requests from bs4 import BeautifulSoup# 登录网站并获取登录后的 session def login(username, password):login_url https://example.com/loginsession re…...

【Windbg】通过网络调试windows内核
环境 windows版本:win10_x64 1901 windbg版本:1.2306.12001.0 HOST 1、windbg软件设置。 点击菜单文件,然后如下图操作。 2、等待连接。 ************* Waiting for Debugger Extensions Gallery to Initialize **************>>&…...
代码随想录算法训练营之JAVA|第二十四天| 93. 复原 IP 地址
今天是第24天刷leetcode,立个flag,打卡60天。 算法挑战链接 93. 复原 IP 地址https://leetcode.cn/problems/restore-ip-addresses/ 第一想法 题目理解:将一串数字字符串变成正确的ip格式的字符串。 这类题目是切分字符串,ip一…...

GBase 8a之listagg/string_agg 函数的反函数实现
GBase8a数据库中 listagg/string_agg 函数的反函数实现一、业务场景背景 在日常数据开发中,我们经常会遇到这种场景:某张表的字段里存储了用逗号(或其他分隔符)拼接的多个值,比如商品分类、标签、关联系统名称等&#…...

别再乱加“impressionism”!Midjourney印象派风格生效的3个前置条件,90%新手忽略第2条
更多请点击: https://codechina.net 第一章:印象派风格在Midjourney中的本质误读与认知纠偏 当用户在 Midjourney 中输入 --style raw --s 750 并附加诸如 “impressionist painting” 或 “Monet style” 等提示词时,模型实际响应的并非印…...

从elm-react-native学习React Native最佳实践:10个关键开发技巧
从elm-react-native学习React Native最佳实践:10个关键开发技巧 【免费下载链接】elm-react-native A react native app simulating eleme app,run ios and android. 项目地址: https://gitcode.com/gh_mirrors/el/elm-react-native 想要快速掌握…...

为OpenClaw智能体工作流配置Taotoken作为稳定的模型供应后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为稳定的模型供应后端 在构建基于OpenClaw的复杂自动化工作流时,一个稳定且模型…...

太空算力产业正崛起
未来,渔民只需通过手机App向卫星发起查询,卫星便可借助高光谱相机精准定位金枪鱼位置,再通过在轨“智慧大脑”分析处理,将鱼群坐标、渔具使用建议及销售渠道指导等实用信息,精准传回渔民手中。这一充满“黑科技”色彩的…...

企业盈利密码,商业模式必读经典书籍推荐
很多人一提到“商业模式”,脑子里马上会想到诸如盈利、流量、融资、裂变、风口等一类的关键词。但真正问一句:“商业模式到底是什么?”往往又说不清。有人把商业模式理解成赚钱的方法;有人觉得是营销套路;还有人认为只…...

别再手动一个个改了!ArcGIS属性表字段批量删除与数据裁剪的‘偷懒’技巧
ArcGIS高效工作流:属性表与数据批处理的进阶技巧 在GIS工程师的日常工作中,最令人头疼的莫过于那些看似简单却需要重复上百次的操作——删除几十个无用字段、裁剪数百个栅格图层、批量修改投影坐标系。这些机械性劳动不仅消耗时间,更消磨创造…...

使用Taotoken的Python SDK快速接入大模型API教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken的Python SDK快速接入大模型API教程 对于希望快速将大模型能力集成到Python应用中的开发者而言,直接对接多…...

从SEO到GEO的技术跃迁:如何利用本地化RAG架构解决企业私域数据的“幻觉”难题?
在2026年的今天,传统的SEO(搜索引擎优化)正在经历一场前所未有的降维打击。当用户习惯从百度跳转至豆包、DeepSeek或Kimi等生成式AI提问时,流量的分发逻辑已经从“点击网页”变成了“AI直接生成答案”。这就是我们常说的 GEO&…...

Red Hat Enterprise Linux 10.2 和 9.8 发布,命令行 AI 辅助增强,多工具集性能升级
Red Hat Enterprise Linux (RHEL) 10.2 和 9.8 正式发布,带来增强的命令行 AI 辅助和基础架构更新,提升用户信息获取速度与工具性能。命令行 AI 辅助升级面向高级用户推出 goose 命令,它是高级可选命令行 AI 助手,连接可信 AI 后端…...