python爬虫2:requests库-原理
python爬虫2:requests库-原理
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
目录结构
文章目录
- python爬虫2:requests库-原理
- 1. 概述
- 2. response对象
- 2.1 encoding属性
- 2.2 url属性
- 2.3 status_code属性
- 2.4 cookies属性
- 2.5 request.headers属性
- 2.6 headers属性
- 2.7 text属性
- 2.8 content属性
- 3. GET请求
- 3.1 方法概述
- 3.2 常用参数
- 3.2 参数的用法举例
- 4. POST请求
- 5. 代理设置
- 6. 会话维持
- 7. ssl证书
- 8. 总结
1. 概述
python其实自带一个请求库,即urllib,不过这个库并不是很好使,因此大部人都还是采用的第三方库requests。
Request支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码。
在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作。
另外,requests的安装十分简单,仅需要pip一下即可:
pip install requests
如果网不好,还可以指定镜像源,下载更快:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
可以使用以下代码检验是否安装成功:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.content.decode('utf-8'))
返回结果如下:

2. response对象
当我们使用get、post或者其他方式去请求的时候,我们就会得到一个response对象(比如上面测试代码中get函数返回的对象),你可以称呼它为响应对象,下面我们来学习这个对象的常用属性和方法。
2.1 encoding属性
作用: 返回网页的编码格式。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.encoding)
打印结果为:
ISO-8859-1
这个结果也是编码的一种,不过是我们国内的标准,其他常见的有utf-8之类的。
2.2 url属性
作用: 返回响应服务器的url。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.url)
打印结果为:
https://www.baidu.com/
不要小瞧这个属性。有时候我们访问的是:http://www.test.com,但是由于这个网站有重定向,因此我们实际访问的是: http://www.good.com ,这样我们通过这个属性确定我们真实访问的网址。
2.3 status_code属性
作用: 返回响应的状态码。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.status_code)
打印结果为:
200
什么是状态码?
简单来说就是你访问的这个网站状态怎么样,是正常访问,还是说服务器错误,还是网络有问题等等。
这里介绍一下常见的相应状态码:
2xx | 正常
3xx | 重定向
4xx | 错误
5xx | 服务器错误
2.4 cookies属性
作用: 返回cookie对象。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.cookies)
打印结果:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
什么是cookie?
这里简单说明一下什么是cookie,可以简单理解为一个存在我们电脑本地的临时身份文件,比如你访问一个网站,你首次登录了它,然后你把这个网站关掉,再次打开,发现不需要重新登录,这就是cookie发挥了作用,当你登陆后,在本地创建了一个临时文件用于后期登录。
2.5 request.headers属性
作用: 返回请求头。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.request.headers)
打印的值为:
{'User-Agent': 'python-requests/2.31.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
什么是请求头?
简单来说,你访问一个网站,比如百度搜索,你肯定会搜索某个东西,那么自然你请求这个网站,发送给这个网站的信息中带有这个东西,我们一般称之为请求头,其包含了你所请求的所有信息。
从上面的返回值可以看出一点:百度网站知道你是python脚本,从'User-Agent': 'python-requests/2.31.0'就可以看出。因此,我们写爬虫的时候必须要做一定的伪装,不然直接就被识别出来是爬虫了。
2.6 headers属性
作用: 返回响应头。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.headers)
打印结果:
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Fri, 04 Aug 2023 05:36:28 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:23:55 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
什么是响应头?
响应头就是服务器/网站自身返回给我们的部分信息、
2.7 text属性
作用: 返回网页的源码,但是是按照chardet模块推测出的编码进行解码的结果(不准确)。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.text)
返回结果:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“</title></head> <body link=#0000cc> <div id=wrapper>
....# 部分结果
说明:text返回的是网页源码,但是解码时是推测的,有时候并不准确。因此,我们更加常用content属性,加上自己解码,更加准确。
2.8 content属性
作用: 返回网页源代码的bytes形式的结果。
代码:
import requests
# 网址
url = 'https://www.baidu.com'
# 请求
response = requests.get(url)
# 打印返回结果
print(response.content.decode('utf-8'))
打印的部分结果:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head>
....# 部分结果
如何判断网页编码形式?
这个简单,随便打开一个网页,比如百度,点击鼠标右键,查看源码,找到下图中的内容(html网页源码整体框架是固定的,因此你在任何网页上都可以找到类似的内容):

3. GET请求
3.1 方法概述
get请求是平时我们最常用的请求方式之一。在requests模块中,提供给我们了非常方便的get请求方式:
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(response.status_code)
3.2 常用参数
| 参数 | 作用 |
|---|---|
| url | 请求的地址 |
| headers | 请求头参数(字典) |
| params | 请求的参数(字典) |
| cookies | 请求的cookies参数(字典) |
| timeout | 超时时间设置 |
3.2 参数的用法举例
这里举一个简单的例子,来说明一下这些参数怎么用。
之前不是说了嘛,直接用脚本去访问百度网站,会被识别出是python脚本,因此我们可以利用请求头参数进行简单的伪装:
import requests
# 地址
url = 'https://www.baidu.com'
# 伪造请求头
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
# 访问
response = requests.get(url,headers=headers)
# 打印
print(response.request.headers)
注意:传入的参数必须为字典形式,内容必须符合请求头的内容。
打印的结果如下:
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
可以看出,确实伪造成功了。
如何正确书写请求头格式?
这一点很重要也很简单,你随便打开一个网页,鼠标右键,选择”检查“(Google浏览器为例),然后按下图操作,即可看见请求头内容:

这里我介绍一下最常见的请求头参数内容:
User-Agent : 客户端浏览器的版本信息
Host : 服务器的主机
Referer:表示从哪个页面跳转到当前的页面
Cookie:用于记录客户端的身份信息,例如通过cookie登录网站
x-forward-for:表示客户端的IP地址,一般被称为”XXF“头,服务器通过这个字段可以知道客户端的真实IP或代理IP
(params参数后面单独出一个案例讲解)
4. POST请求
post请求也是我们网站中最常用的请求方式之一,一般提交表单几乎都是post请求。而,在requests模块中,post请求与get请求的使用方法上差别在于参数(params变为了data,headers参数和其他参数是相同的):
data: 接收一个字典,里面爬虫发出的数据
5. 代理设置
使用代理,可以减少我们自己真实IP暴漏的概率。
简单来说,代理就是使用别人IP来访问网站,这样网站如果进行检测,只能检测到别人的IP地址,根本不知道其实是你在访问他的网站。
一般代理IP按照匿名程度分为:
- 高匿:
- 别人不知道你的真实IP
- 透明:
- 别人知道你的真实IP
而,在requests库中,get、post请求方法中都有一个参数 proxies ,这个参数就是设置代理使用的。
使用方法如下:
import requestsproxies = {'http/https':'http/https:ip:port','http/https':'http/https:ip:port','http/https':'http/https:ip:port','http/https':'http/https:ip:port'
}
requests.get(url,proxies=proxies)
当我们需要追求效率时,除了可以采用多任务的方式,还有一个方式就是使用代理。比如我们需要下载图片,为了不被网站检测出我们是爬虫,我们不得不牺牲效率,比如说每爬取一张图片就休息一秒钟,这样的效率显然很低。但是一旦我们一秒钟爬取个几百张图片,非常容易被网站检测出这个用户不是一个人,因为真正的人不可能一秒钟下载几百张图片,于是网站便会短时间封禁我们的ip,导致我们无法继续访问,以至于爬虫失效。
这时我们需要代理,这样我们就可以在爬取的时候使用不同的ip地址了。
那么总结一下,为什么需要代理呢?
- 减少自己真实IP暴漏的概率
- 可以使用多个代理IP来实现快速访问
因为,现在的网站几乎都会屏蔽速度过快的访问,比如一秒几十次乃至几百、上千万次的访问,这样的访问一看就不正常,因此站长几乎都会屏蔽乃至禁止你的IP,因此我们可以使用多个代理IP,比如我们使用100个,那么我们每秒就会访问100次都不会有任何的问题
6. 会话维持
我们有时候遇见一些网站会强制你登录才能去获取数据。此时你知道想要登录网站需要去使用post方式请求,但是当你请求成功后再用get方式去访问网站,你会发现你被拒绝了,这意味着你的get请求是一个新的请求,而不是在post请求成功后以post为基础的请求。如果你无法理解上面的话,你可以这样理解,一个get就是打开一个浏览器,两个浏览器之间是无法通信的,所以你第二次请求相当于打开一个新的浏览器,自然无法获取内容。
因此,我们需要一些方法来搞定这个问题。
参考代码如下:
#下面给出的是思路,不是具体的代码,具体的代码还是根据实际案例来讲
import requests#创建session对象
session = requests.session()
#使用session对象去发送post请求
session.post(.....) #这里post的用法和requests.post()用法一致
#请求成功后再用session对象去请求只有登录才能访问的页面
response = session.get(....) #这里post的用法和requests.get()用法一致
#接下来再去操作即可
(这个也会单独出一篇讲解案例)
7. ssl证书
有时候,我们的爬虫需要忽略ssl证书,即我们手动访问的时候会显示这个网页不安全/ssl证书过期等提示。
忽略的方法很简单,参考如下:
import requestsresponse = requests.get('https://www.baidu.com',verify=False)
print(response.status_code)
8. 总结
本篇文章主要梳理了requests常用方法,接下来的文章会对本文中涉及的一些方法进行举例说明。
相关文章:
python爬虫2:requests库-原理
python爬虫2:requests库-原理 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 目录结构 文章目录 python爬虫2:requests库-原理1. 概述2. re…...

纹理贴图和渲染
纹理贴图 纹理映射(也就是纹理图或者叫做纹理贴图)是一种在计算机图形学中常用的技术,它可以将二维的图像(纹理)映射到三维物体的表面上,以增强视觉效果。“atlas”通常是指纹理图集,也就是将多…...
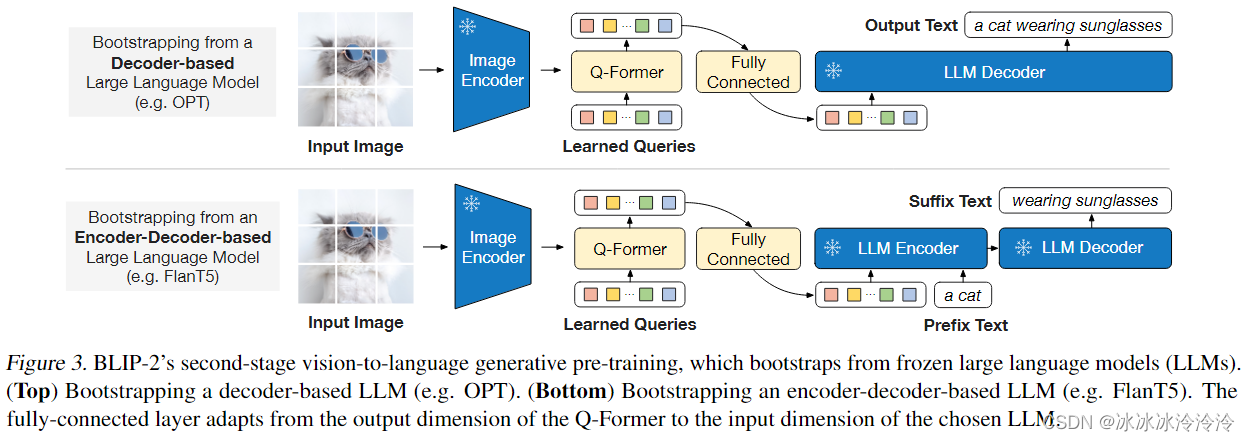
BLIP2
BLIP2的任务是基于已有的固定参数的图像encoder和语言大模型(LLM)搭建一个具有图像理解能力的图文模型,输入是图像和文本,输出是文本。 BLIP2基于Q-Former结构,如下图所示。Q-Former包含图像transformer和文本transfo…...

陀螺玩具跨境电商亚马逊CPC认证
陀螺指的是绕一个支点高速转动的刚体。陀螺是中国民间最早的娱乐工具之一.形状上半部分为圆形,下方尖锐。从前多用木头制成,现代多为塑料或铁制。玩时可用绳子缠绕,用力抽绳,使直立旋转。或利用发条的弹力旋转。传统古陀螺大致是木…...

TS学习02-接口
接口 ts原则之一就是对值所具有的结构进行类型检查。 结构的左右就是为了这些类型命名和代码定义契约 interface LabelValue {label: string } function point(label: LabelValue) {} let obj {label:标题,age: 18} point(obj)类型检查器不会去检查属性的顺序&a…...

WuThreat身份安全云-TVD每日漏洞情报-2023-08-09
漏洞名称:致远OA文件上传漏洞 漏洞级别:高危 漏洞编号:NULL 相关涉及:1. A6、A8、A8N的V8.0SP2、V8.1、V8.1SP1 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-19494 漏洞名称:Microsoft Exchange Server 欺骗漏洞 漏洞级别:高危 漏洞编号:CV…...

6. C++类的静态成员
一、对象的生产期 生存期:对象从诞生到结束的这段时间生存期分为静态生存期和动态生存期 1.1 静态生存期 对象的生存期与程序的运行期相同,则称它具有静态生存期在文件作用域中声明的对象都是具有静态生存期的若在函数内部的局部作用域中声明具有静态…...
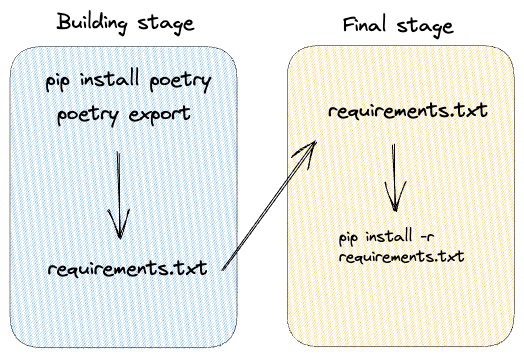
如何使Python Docker镜像安全、快速、小巧
一、说明 在微服务领域,拥有安全、高效和紧凑的 Docker 映像对于成功部署至关重要。本博客将探讨有助于构建此类映像的关键因素,包括不以 root 用户身份运行映像的重要性、在构建映像时更新和升级包、在编写 Dockerfile 指令时考虑 Docker 的层架构&…...
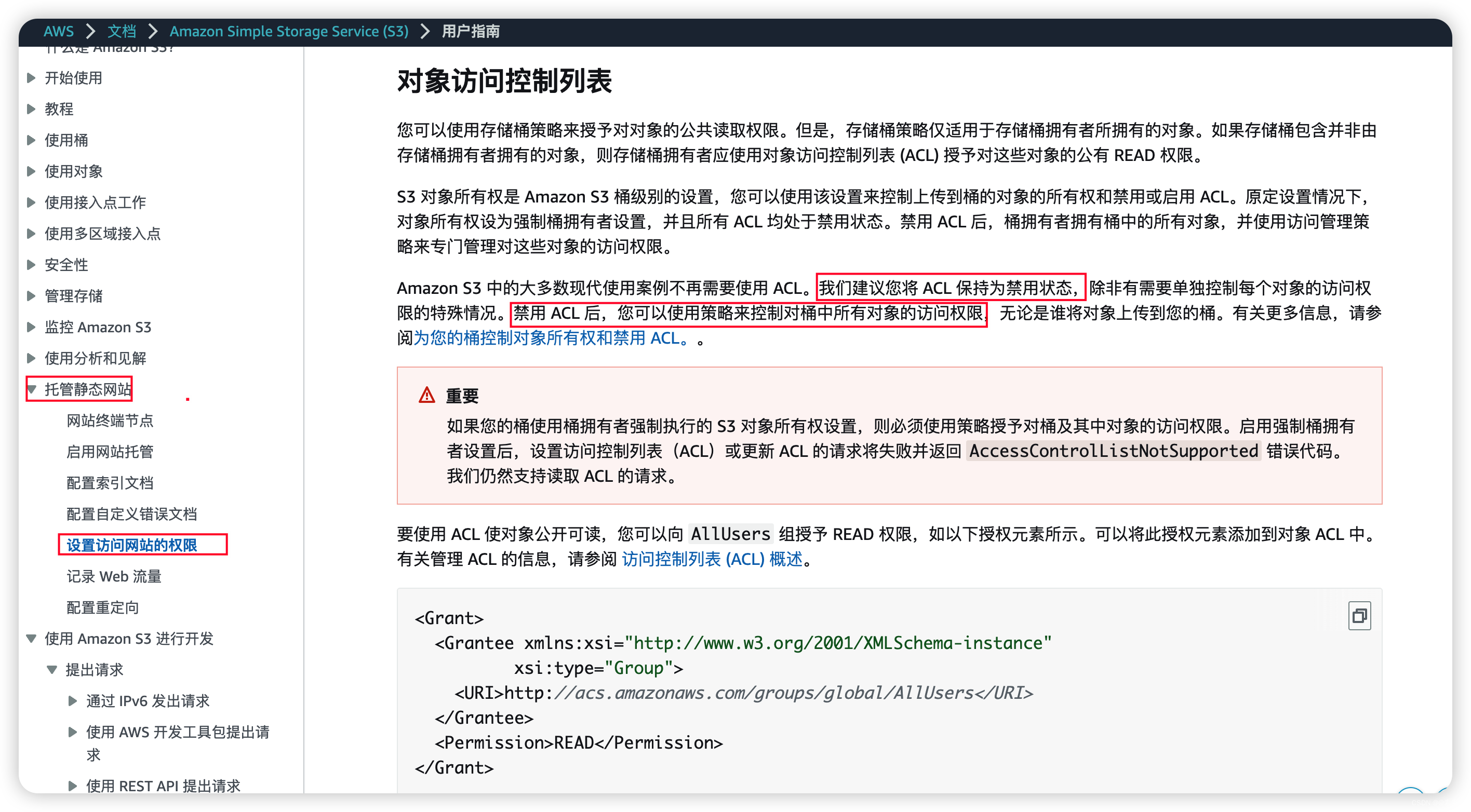
AWS——03篇(AWS之Amazon S3(云中可扩展存储)-01入门)
AWS——03篇(AWS之Amazon S3(云中可扩展存储)-01入门) 1. 前言2. 关于 Amazon S32.1 介绍2.1.1 简述2.1.2 详细介绍 2.2 Amazon S3 好处和功能2.3 3. 创建S3存储桶3.1 创建存储桶3.2 修改访问权限 4. 简单实用4.1 上传图片文件4.2…...

没有synchronized,rust怎么防并发?
学过Java的同学对synchronized肯定不陌生,那么rust里怎么办呢? 在Rust中,可以使用标准库提供的 std::sync::Mutex 来实现加锁功能。Mutex是互斥锁的一种实现,用于保护共享数据在并发访问时的安全性。 下面是一个简单的示例代码&a…...
)
1.Python简介及安装(3.11.4)
简介 Python 是一种解释型、面向对象、动态数据类型、高级、通用、解释型的高级程序设计语言。 Python 由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年。 像 Perl 语言一样, Python 源代码同样遵循 GPL(GNU General Public License) 协议。 官方宣布,…...

face_recognition人脸识别与人脸检测
1、安装face_recognition库 pip install face_recognition face_recognition库的人脸识别是基于业内领先的C开源库dlib中的深度学习模型,安装face_recognition库的同时会一并安装dlib深度学习框架。 2、face_recognition库的使用 1)load_image_file加…...
vue3获得url上的参数值
1、引入 import { useRoute } from vue-router2、获得const route useRoute() console.log(route.query.number)...

chapter15:springboot与监控管理
Spring Boot与监控管理视频 1. 简介 通过引入spring-boot-starter-actuator, 可以使用SpringBoot为我们提供的准生产环境下的应用监控和管理功能。我们可以通过http, jmx, ssh协议来进行操作,自动得到审计、健康及指标信息等。 步骤: 引入spring-boo…...

http历史版本
1,HTTP0.9 最早的http版本,后来才被定义为0.9版本。 这时候通信采用的是纯文本格式; 只支持get请求,且在服务器响应之后就关闭连接; 没有请求头的概念,功能比较简单。 2,HTTP1.0 这个版本增…...
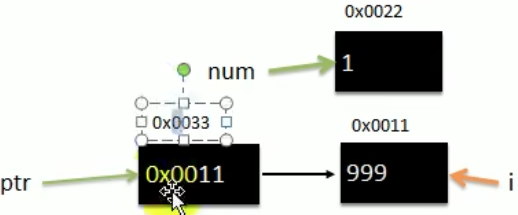
【Go语言】Golang保姆级入门教程 Go初学者chapter2
【Go语言】变量 VSCode插件 setting的首选项 一个程序就是一个世界 变量是程序的基本组成单位 变量的使用步骤 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zuxG8imp-1691479164956)(https://cdn.staticaly.com/gh/hudiework/imgmain/image-20…...
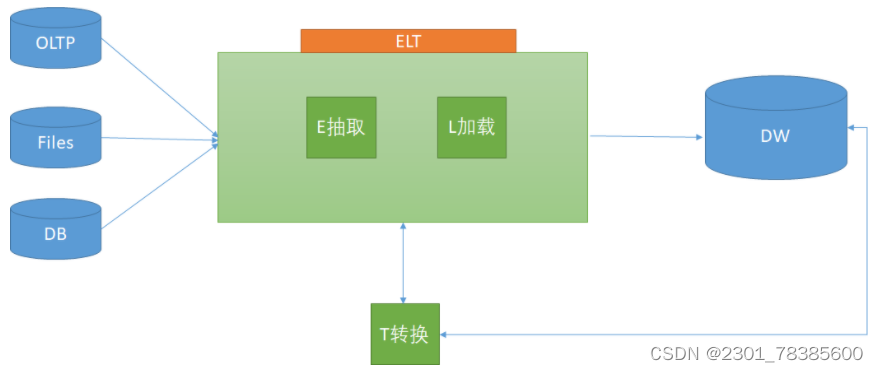
关于ETL的两种架构(ETL架构和ELT架构) qt
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库…...

【Linux】进程间通信——管道
目录 写在前面的话 什么是进程间通信 为什么要进行进程间通信 进程间通信的本质理解 进程间通信的方式 管道 System V IPC POSIX IPC 管道 什么是管道 匿名管道 什么是匿名管道 匿名管道通信的原理 pipe()的使用 匿名管道通信的特点 拓展代码 命名管道 什么是命…...

Element-plus中tooltip 提示框修改宽度——解决方案
tooltip 提示框修改宽度方法: 在element中,想要设置表格的内容,超出部分隐藏,鼠标悬浮提示 可以在el-table 上添加show-overflow-tooltip属性 同时可以通过tooltip-options配置提示信息 如下图代码 <el-tableshow-overflo…...
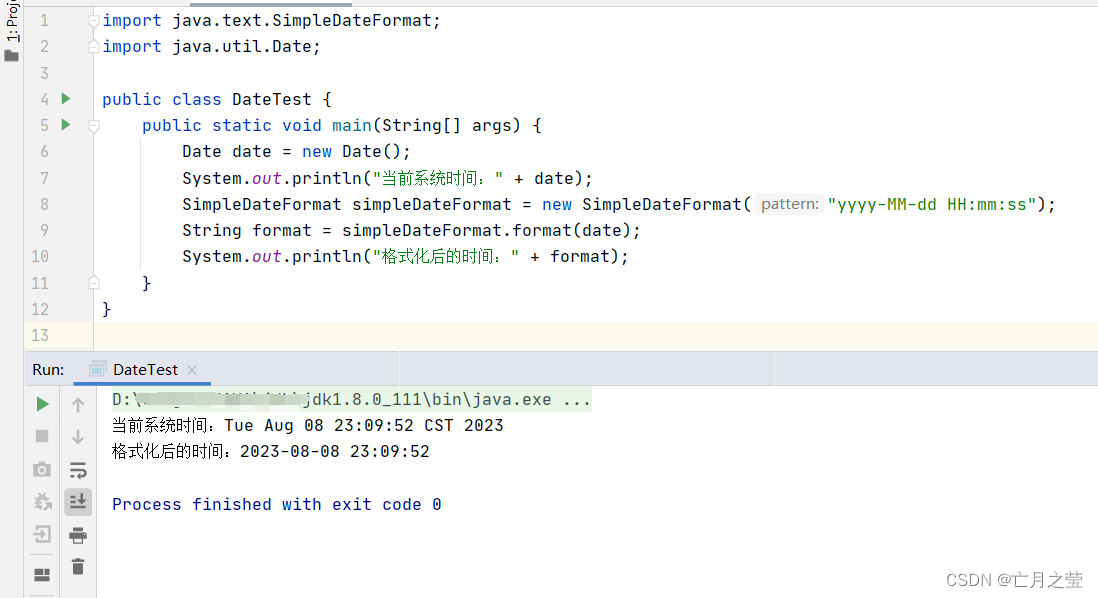
java实现当前系统时间格式化
import java.text.SimpleDateFormat; import java.util.Date;public class DateTest {public static void main(String[] args) {Date date new Date();System.out.println("当前系统时间:" date);SimpleDateFormat simpleDateFormat new SimpleDateFo…...

RK3568国产工业级车载方案:从核心板设计到量产落地的全流程解析
1. 项目概述:为什么选择RK3568作为国产车载方案的基石?在车载电子这个领域,尤其是面向工业级和商用车载应用,选型一款合适的核心处理器平台,往往决定了整个项目的成败周期、成本控制以及最终产品的市场竞争力。过去很长…...

创业团队如何利用Taotoken统一技术栈并降低AI接入门槛
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken统一技术栈并降低AI接入门槛 对于资源有限的创业团队而言,在产品中集成人工智能能力是提升竞…...

会计学论文降AI工具怎么选?财务审计方向高效降重指南
又到了毕业答辩的关键期,不少会计专业的同学都在发愁论文AI率不达标:财务分析部分的数据解读、审计研究的案例推导用AI辅助写完,一检测全是高风险,改了好几遍还是过不了学校的审核。我身边不少师弟师妹踩过工具的坑,要…...

软件许可优化,别被销售忽悠了,看看这几家到底谁管用
以前我们公司被Adobe审计过一次,赔了不少钱。之后老板让我专门研究软件许可优化这件事。市面上这几家都聊过、试过,我把真实感受跟你说说。先说你可能不太熟的:(gofarlic)这家是国内武汉的,一开始我也有点怀…...

Python核心基础
本文摘要:Python核心基础章节系统讲解了编程基础知识,主要包括:1.字面量的概念与写法,强调字符串必须使用引号包裹;2.变量与常量的定义与使用,介绍命名规则和三种命名风格;3.注释的两种形式&…...

告别踩坑!手把手教你用Cobalt Strike 4.7在Kali Linux上快速搭建团队服务器并上线第一台主机
Kali Linux环境下Cobalt Strike 4.7团队服务器部署与主机上线实战指南 在渗透测试和红队演练中,Cobalt Strike作为一款成熟的商业框架,其团队协作功能和丰富的攻击模拟能力备受安全从业者青睐。本文将基于Kali Linux系统,详细解析Cobalt Stri…...

破冰总结:写给 QA 的一份 30 天 AI 技术转型学习路线图
写在前面:一个不得不面对的现实 打开招聘网站,搜索“高级QA工程师”,你会发现薪资最高的一批岗位都有同一个关键词:AI。不是指“用AI写测试用例”那种浮于表面的用法,而是要求你真正理解AI系统的工作原理、能评估模型输出质量、能设计对抗性测试方案、能把RAG管线部署到生…...

PHP方案 swoole++io_uring写一个案例
下面是一个完整的 Swoole io_uring 案例,涵盖 HTTP 服务器、协程文件 I/O 和并发请求三个场景。--- ns)环境要求 …...

Co-IP/MS:蛋白免疫共沉淀质谱分析服务
免疫共沉淀质谱法(Co-IP/MS)是一种由免疫共沉淀技术联用质谱技术的蛋白互作研究技术,具备高分辨率鉴定和精确定量蛋白质复合物中每个组分的优势。Co-IP/MS使用靶向目标蛋白的特异性抗体,选择性地捕获目标蛋白质与其相互作用的分子…...

Python开发者三步完成Taotoken接入并运行第一个AI对话
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken接入并运行第一个AI对话 对于希望快速将大模型能力集成到Python项目中的开发者而言,找到…...