揭示CTGAN的潜力:利用生成AI进行合成数据
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景
我们都知道,GAN在生成非结构化合成数据(如图像和文本)方面越来越受欢迎。然而,在使用GAN生成合成表格数据方面所做的工作很少。合成数据具有许多好处,包括其在机器学习应用程序、数据隐私、数据分析和数据增强中的使用。只有少数模型可用于生成合成表格数据,CTGAN(条件表格生成对抗网络)就是其中之一。与其他 GAN 一样,它使用生成器和鉴别器神经网络来创建与真实数据具有相似统计属性的合成数据。CTGAN可以保留真实数据的底层结构,包括列之间的相关性。CTGAN的额外好处包括通过特定于模式的规范化来增强训练过程,一些架构更改,以及通过使用条件生成器和采样训练来解决数据不平衡问题。
在这篇博文中,我使用CTGAN根据从Kaggle收集的信用分析数据集生成合成数据。
CTGAN的优点
- 生成与实际数据具有类似统计属性的合成表格数据,包括不同列之间的相关性。
- 保留真实数据的底层结构。
- CTGAN生成的合成数据可用于各种应用,例如数据增强,数据隐私和数据分析。
- 可以处理连续、离散和分类数据。
CTGAN的缺点
- CTGAN需要大量的真实表格数据来训练模型并生成与真实数据具有相似统计属性的合成数据。
- CTGAN是计算密集型的,可能需要大量的计算资源。
- CTGAN生成的合成数据的质量可能会有所不同,具体取决于用于训练模型的真实数据的质量。
调整CTGAN
与所有其他机器学习模型一样,CTGAN在调优时表现更好。在调整CTGAN时需要考虑多个参数。但是,对于此演示,我使用了“ctgan 库”附带的所有默认参数:
- 纪元:生成器和鉴别器网络在数据集上训练的次数。
- 学习率:模型在训练期间调整权重的速率。
- 批量大小:每次训练迭代中使用的样本数。
- 生成器和鉴别器网络大小。
- 优化算法的选择。
CTGAN还考虑了超参数,例如潜在空间的维数,生成器和判别器网络中的层数以及每层中使用的激活函数。参数和超参数的选择会影响生成的合成数据的性能和质量。
CTGAN的验证
CTGAN的验证是棘手的,因为它存在局限性,例如难以评估生成的合成数据的质量,特别是在涉及表格数据时。尽管有一些指标可用于评估真实数据和合成数据之间的相似性,但确定合成数据是否准确表示真实数据中的基本模式和关系仍然具有挑战性。此外,CTGAN容易受到过度拟合的影响,并且可以产生与训练数据过于相似的合成数据,这可能会限制它们泛化到新数据的能力。
一些常见的验证技术包括:
- 统计测试:比较生成数据和真实数据的统计属性。例如,使用相关性分析、柯尔莫哥罗夫-斯米尔诺夫检验、安德森-达林检验和卡方检验等检验来比较生成的数据和真实数据的分布。
- 可视化:通过绘制直方图、散点图或热图来可视化异同。
- 应用程序测试:通过在实际应用程序中使用合成数据,查看其性能是否与真实数据相似。
个案研究
关于信用分析数据
信用分析数据包含连续和离散/分类格式的客户数据。出于演示目的,我通过删除具有 null 值的行并删除本演示不需要的几列来预处理数据。由于计算资源的限制,运行所有数据和所有列将需要大量的计算能力,而我没有。以下是连续变量和分类变量的列列表(离散值,如子变量计数 (CNT_CHINDREN) 被视为分类变量):
分类变量:
TARGET
NAME_CONTRACT_TYPE
CODE_GENDER
FLAG_OWN_CAR
FLAG_OWN_REALTY
CNT_CHILDREN连续变量:
AMT_INCOME_TOTAL
AMT_CREDIT
AMT_ANNUITY
AMT_GOODS_PRICE生成模型需要大量干净的数据来训练以获得更好的结果。但是,由于计算能力的限制,我从超过 10,000 行的真实数据中只选择了 9,993 行(正好是 300,000 行)进行本演示。虽然这个数字可能被认为相对较小,但对于本演示的目的来说应该足够了。
真实数据的位置:
Credit Analysis | Kaggle
生成的合成数据的位置:
- CTGAN的综合信用分析数据(Kaggle)
- CTGAN生成的合成表格数据集(研究门)
- DOI: 10.13140/RG.2.2.23275.82728

信用分析数据 |图片来源:作者
结果
我生成了 10k(确切地说是 9997)合成数据点,并将它们与真实数据进行了比较。结果看起来不错,尽管仍有改进的潜力。在我的分析中,我使用了默认参数,其中“relu”作为激活函数和 3000 个 epoch。增加纪元的数量应该可以更好地生成类似真实的合成数据。生成器和鉴别器损失看起来也不错,损耗越低,表示合成数据和真实数据之间的相似性越近:

发生器和鉴别器损耗 |图片来源:作者
绝对对数平均值和标准差图中沿对角线的点表示生成的数据质量良好。

数值数据的绝对对数平均值和标准差 |图片来源:作者
下图中连续列的累积总和并不完全重叠,但它们很接近,这表明合成数据的生成良好且没有过度拟合。分类/离散数据的重叠表明生成的合成数据接近真实。进一步的统计分析见下图:
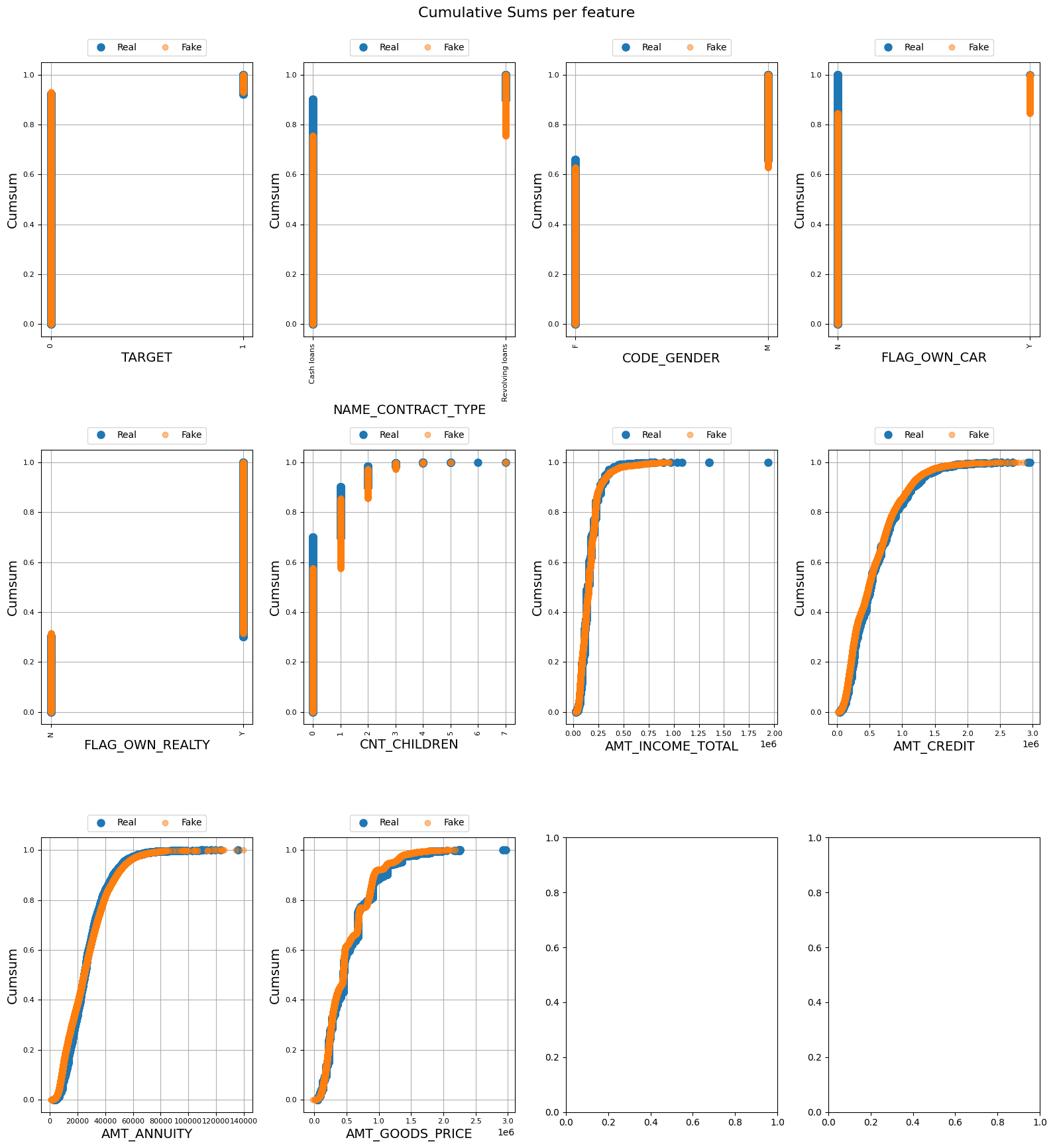
每个要素的累计总和 |图片来源:作者
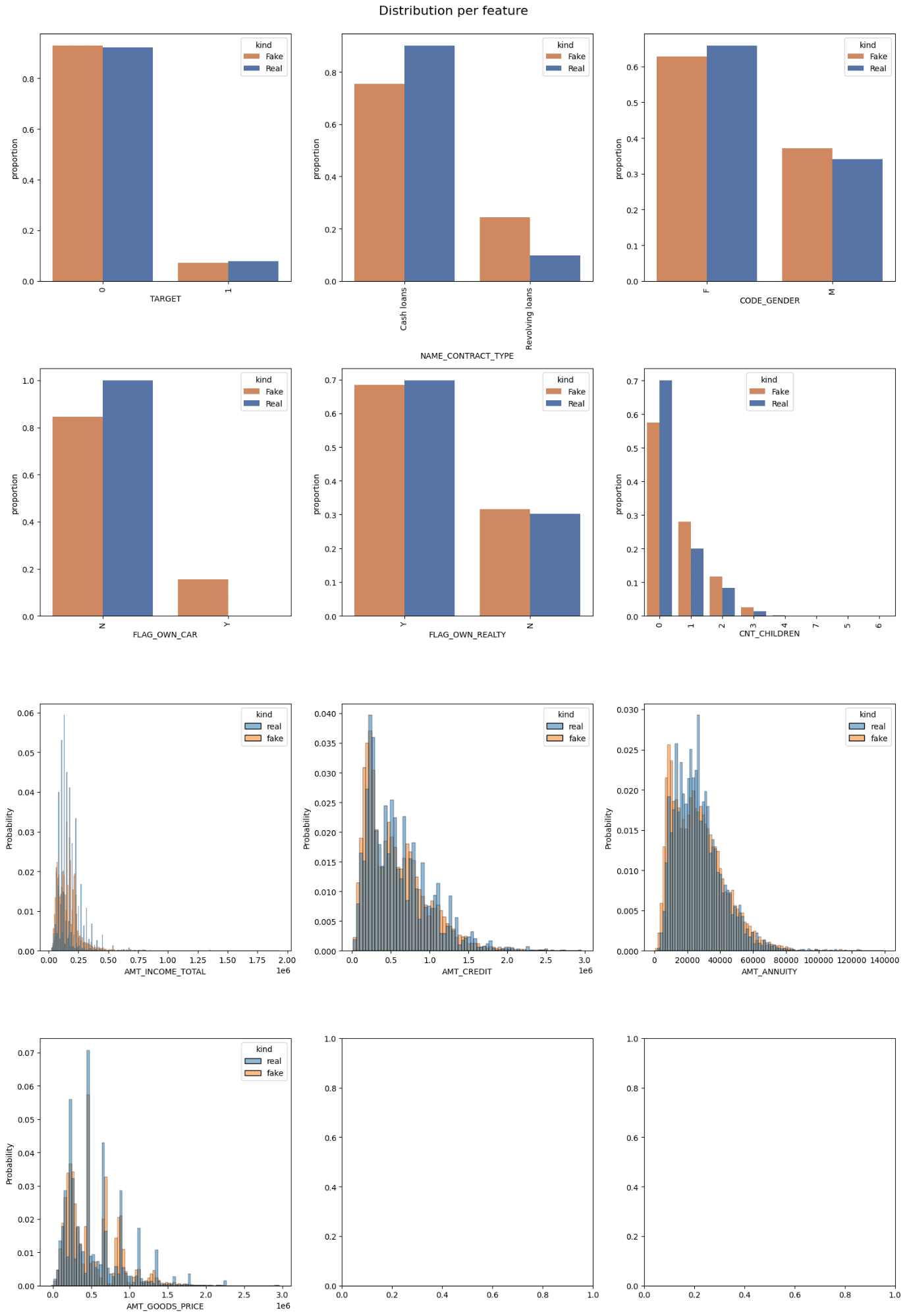
功能分布|图片来源:作者

特征分布 |图片来源:作者
主成分分析 |图片来源:作者
以下关联图显示了变量之间的明显相关性。重要的是要注意,即使经过彻底的微调,真实数据和合成数据之间的属性也可能存在差异。这些差异实际上是有益的,因为它们可能会揭示数据集中可用于创建新解决方案的隐藏属性。据观察,增加纪元数可以提高合成数据的质量。
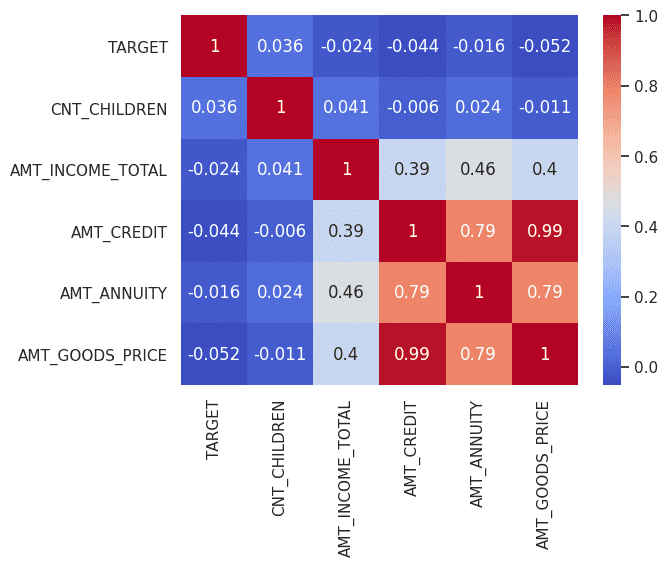
变量之间的相关性(真实数据) |图片来源:作者
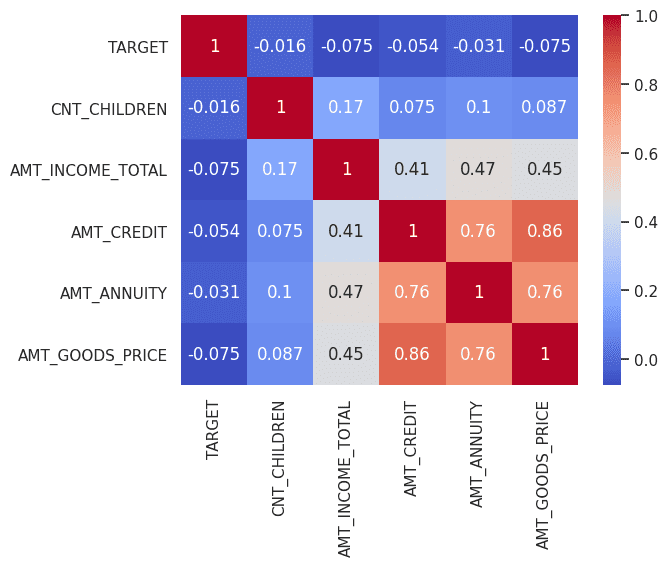
变量之间的相关性(合成数据) |图片来源:作者
样本数据和实际数据的汇总统计似乎也令人满意。
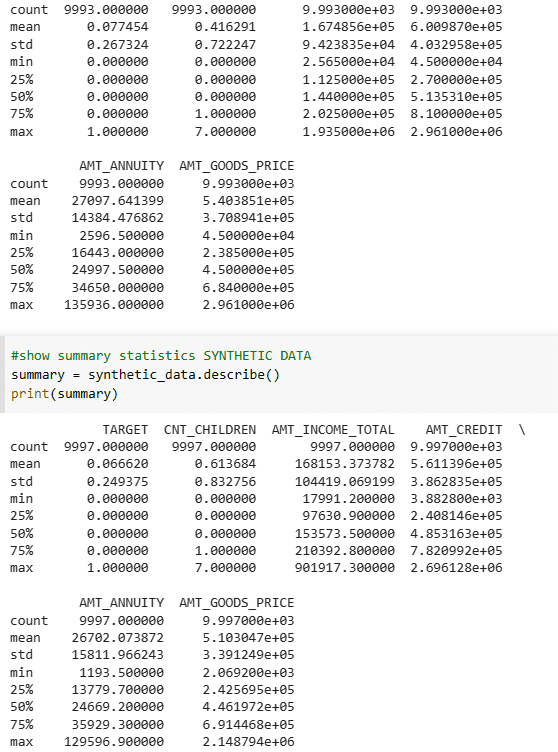
真实数据和合成数据的汇总统计 |图片来源:作者
Python代码
# Install CTGAN
!pip install ctgan# Install table evaluator to analyze generated synthetic data
!pip install table_evaluator
# Import libraries
import torch
import pandas as pd
import seaborn as sns
import torch.nn as nnfrom ctgan import CTGAN
from ctgan.synthesizers.ctgan import Generator# Import training Data
data = pd.read_csv("./application_data_edited_2.csv")# Declare Categorical Columns
categorical_features = ["TARGET","NAME_CONTRACT_TYPE","CODE_GENDER","FLAG_OWN_CAR","FLAG_OWN_REALTY","CNT_CHILDREN",
]# Declare Continuous Columns
continuous_cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]# Train Model
from ctgan import CTGANctgan = CTGAN(verbose=True)
ctgan.fit(data, categorical_features, epochs=100000)# Generate synthetic_data
synthetic_data = ctgan.sample(10000)# Analyze Synthetic Data
from table_evaluator import TableEvaluatorprint(data.shape, synthetic_data.shape)
table_evaluator = TableEvaluator(data, synthetic_data, cat_cols=categorical_features)
table_evaluator.visual_evaluation()
# compute the correlation matrix
corr = synthetic_data.corr()# plot the heatmap
sns.heatmap(corr, annot=True, cmap="coolwarm")# show summary statistics SYNTHETIC DATA
summary = synthetic_data.describe()
print(summary)
结论
CTGAN的训练过程有望收敛到生成的合成数据与真实数据无法区分的程度。然而,在现实中,不能保证趋同。有几个因素会影响CTGAN的收敛性,包括超参数的选择、数据的复杂性和模型的架构。此外,训练过程的不稳定性可能导致模式崩溃,其中生成器仅生成一组有限的相似样本,而不是探索数据分布的全部多样性。
原文链接:揭示CTGAN的潜力:利用生成AI进行合成数据 (mvrlink.com)
相关文章:
揭示CTGAN的潜力:利用生成AI进行合成数据
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景 我们都知道,GAN在生成非结构化合成数据(如图像和文本)方面越来越受欢迎。然而,在使用GAN生成合成表格数据方面所做的工作很少。合成数据具有许多好处&#x…...

GitHub中readme.md文件的编辑和使用
GitHub中readme.md文件的编辑和使用 | YuuiChungs BlogGitHub - guodongxiaren/README: README文件语法解读,即Github Flavored Markdown语法介绍...

Python 四舍五入到最接近的十位
本篇文章将讨论使用 Python 的 ceil() 函数将数字四舍五入到最接近的十。 Python 整数到最接近的十 Python 具有三个内置函数 round()、floor() 和 ceil(),可用于对数字进行舍入。 ceil() 函数属于数学模块,用于将浮点数舍入为大于或等于给定数字的最接…...
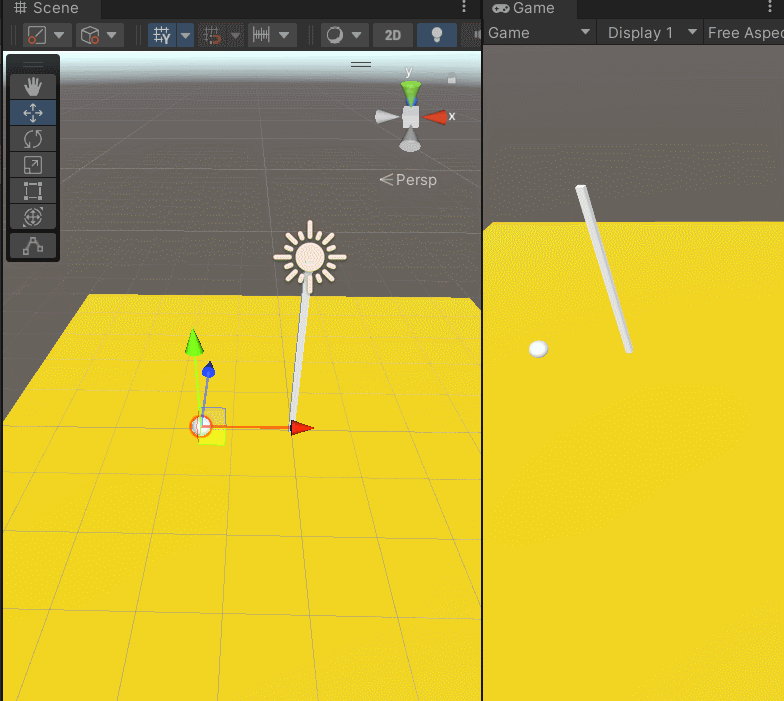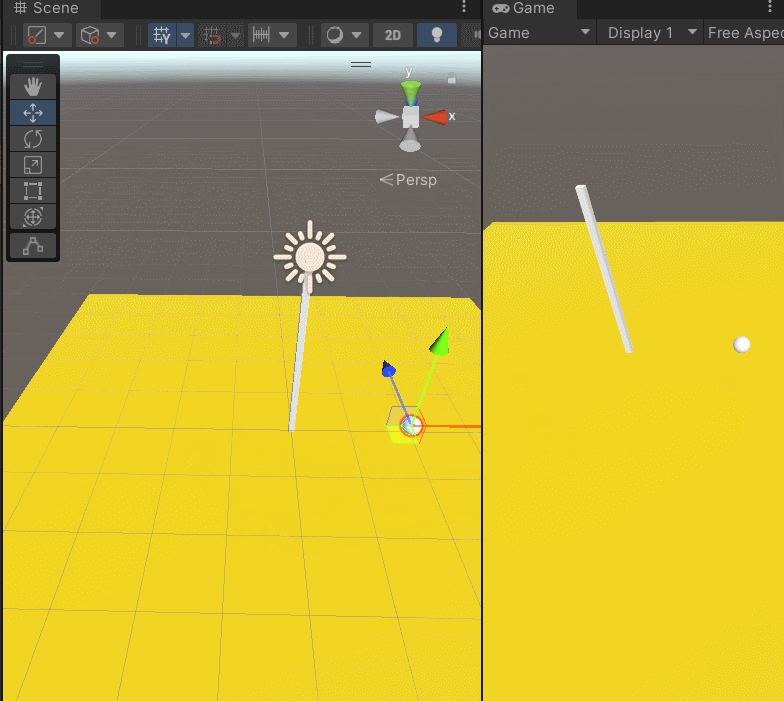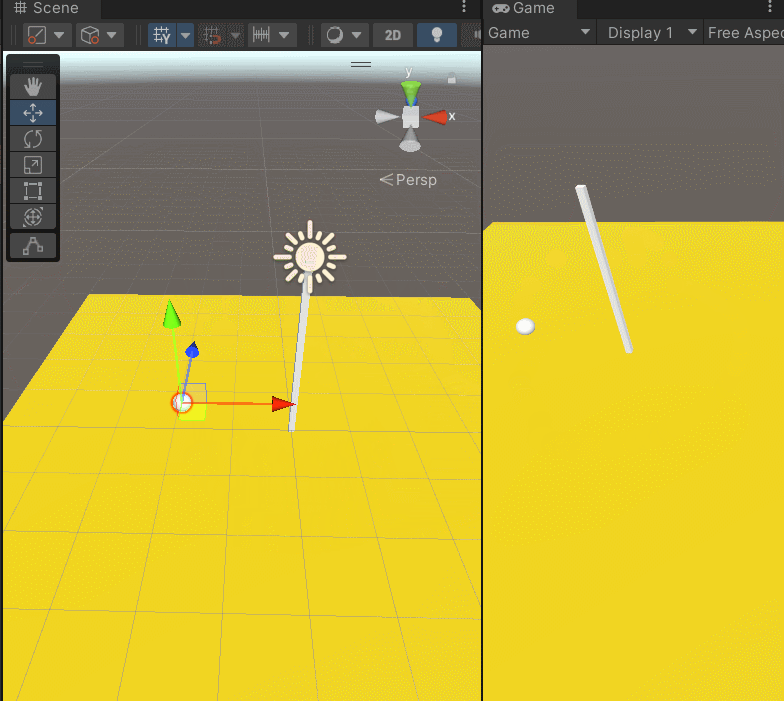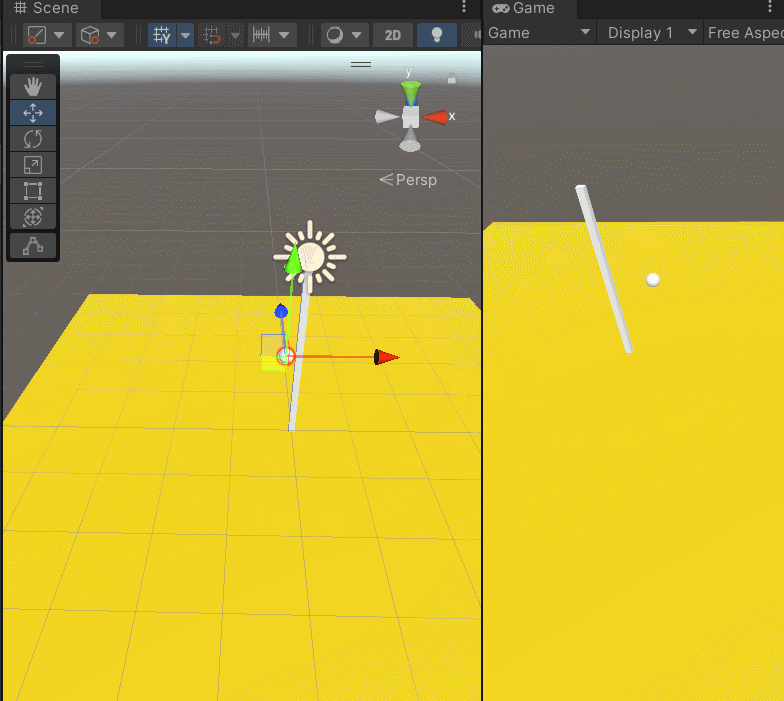
Unity限制在一个范围内移动
Unity限制在一个范围内移动 这个例子中,我们学习Vector3.ClampMagnitude的用法,限制小球在范围内移动。 在地图上放了一个小球,让他移动,但是不想让他掉下去,限制在一个球星范围内,就好像绳子拴住了一样&…...
建图)
dji uav建图导航系列(一)建图
文章目录 1、uav + rplidir雷达1.2、思岚激光雷达1.3、dji uav的launch文件2、cartographer激光建图2.1、启动文件2.2、config修改2.3、建图过程3、融合odom+laser建图1、uav + rplidir雷达 思岚激光雷达frame为base_laser_link, 无人机frame为base_footprint。 文件uav_lid…...

AAAI论文阅读
文章目录 Open-Vocabulary Multi-Label Classifcation via Multi-Modal Knowledge Transfer——知识蒸馏的范畴Med-EASi: Finely Annotated Dataset and Models for Controllable Simplifcation of Medical Texts——医学领域数据集构建“Nothing Abnormal”: Disambiguating M…...

填补5G物联一张网,美格智能快速推进RedCap商用落地
自5G R17版本标准冻结以来,RedCap一直引人注目。2023年更是5G RedCap突破性发展的一年,从首款5G RedCap调制解调器及射频系统——骁龙X35发布,到国内四大运营商发布RedCap技术白皮书,芯片厂商、模组厂商、运营商及终端企业都在积极…...
)
服务器杂七杂八的知识/常识归纳(不断更新)
一.pID与端口号不一样吗? pID(Process ID,进程标识符)和端口号是不同的概念。 pID是操作系统中用来唯一标识一个正在运行的进程的数字。每个正在运行的进程都会被分配一个唯一的pID,它可以用来追踪和管理进程。 而端口号是在网…...

掌握Java排序算法:实现主流排序方法与性能对比
一,C语言,主流的排序方法介绍 当谈论主流的排序方法时,通常指的是在实际应用中表现优秀且被广泛采用的排序算法。以下是常见的主流排序方法及其介绍、时间复杂度、空间复杂度和简单的C语言代码实现: 冒泡排序(Bubble S…...

jdk17 SpringBoot JPA集成多数据库
switchRegion(切换地区)功能, 客户端可手动切换地区 , 查询不同的数据库, 后台根据地区切换数据库, 请求头添加region的key 配置类 import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.boot.jdbc.DataSourceBuilder; im…...

vue 新学习 06 js的prototype ,export暴露,vue组件,一个重要的内置关系
01 在js中: 原型链 注意:构造函数.prototype实例化对象.__proto__,都是指向函数的原型。 export: -export用于对外输出本模块(一个文件可以理解为一个模块)变量的接口 -import用于在一个模块中加载另一个…...

冠达管理:“高温超导”不是“室温超导”,5天4板百利电气再次澄清
短短半个月,“室温超导”在惊喜、质疑间回转,但资本市场对“超导概念股”的炒作还在进行,8月7日室温超导概念持续疯涨。同花顺显现,到8月7日收盘,18只超导概念股中,有16只股票飘红。 广东研山私募证券投资&…...
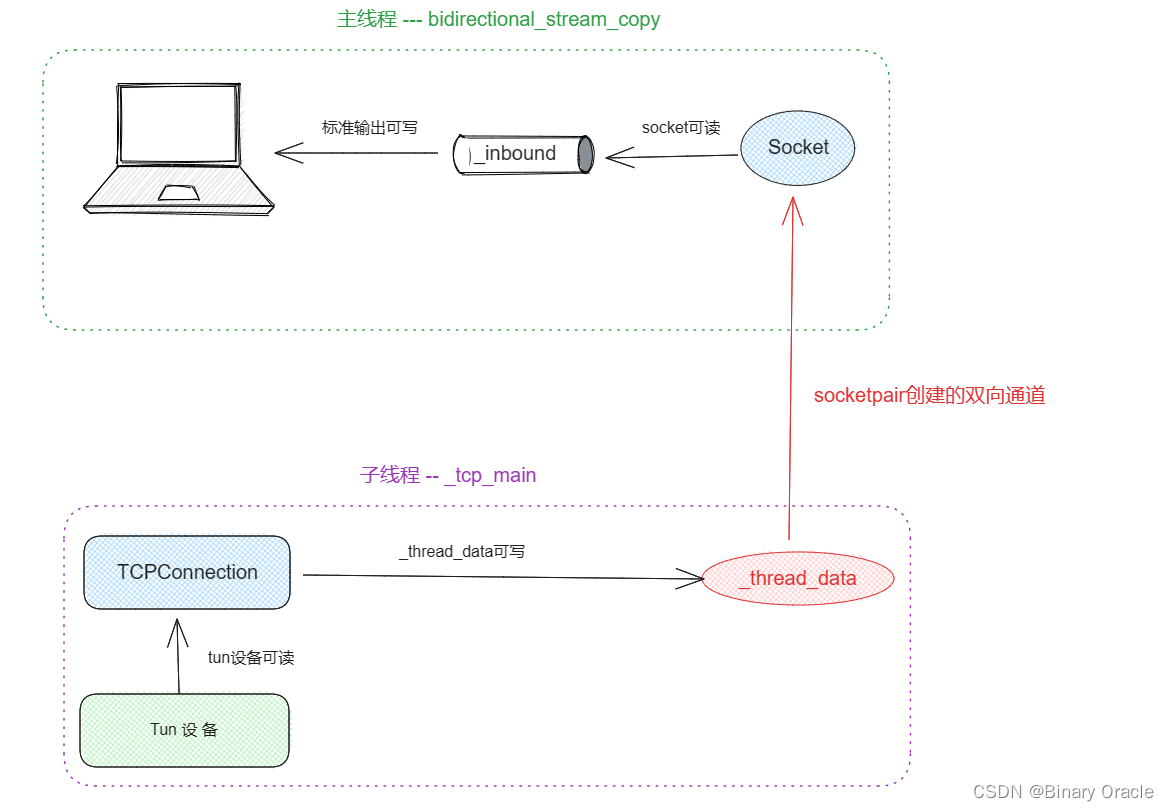
CS 144 Lab Four 收尾 -- 网络交互全流程解析
CS 144 Lab Four 收尾 -- 网络交互全流程解析 引言Tun/Tap简介tcp_ipv4.cc文件配置信息初始化cs144实现的fd家族体系基于自定义fd体系进行数据读写的adapter适配器体系自定义socket体系自定义事件循环EventLoop模板类TCPSpongeSocket详解listen_and_accept方法_tcp_main方法_in…...

Linux面试专题
Linux面试专题 1 Linux中主要有哪几种内核锁?2 Linux 中的用户模式和内核模式是什么含意?3 怎样申请大块内核内存?4用户进程间通信主要哪几种方式?5通过伙伴系统申请内核内存的函数有哪些?6) Linux 虚拟文件系统的关键数据结构有哪些?(至少写出四个)7) 对文件或设备的操作…...
详解)
MySQL错误日志(Error Log)详解
错误日志(Error Log)是 MySQL 中最常用的一种日志,主要记录 MySQL 服务器启动和停止过程中的信息、服务器在运行过程中发生的故障和异常情况等。 作为初学者,要学会利用错误日志来定位问题。下面介绍如何操作查看错误日志。 启动…...
Qt应用开发(基础篇)——LCD数值类 QLCDNumber
一、前言 QLCDNumber类继承于QFrame,QFrame继承于QWidget,是Qt的一个基础小部件。 QLCDNumber用来显示一个带有类似lcd数字的数字,适用于信号灯、跑步机、体温计、时钟、电表、水表、血压计等仪器类产品的数值显示。 QLCDNumber可以显示十进制…...
新版百度、百家号旋转验证码识别
昨天突然发现,百度旋转验证码发生了变化,导致使用老版本验证码训练出来的识别模型效果不佳。所有昨天花了一天时间完成了新版模型的训练。 老版本验证码 新版本验证码 新版的验证码感觉像是AI绘画随机生成的,还有随机阴影出现。 验证码识别…...
)
PMP考试每日一练(8月8日)
1、项目经理正在领导一个正在努力协作的多元文化团队。项目经理一开始将此视为团队建设的典型震荡阶段,但团队未能成功通过该阶段。结果,项目开始落后于进度。 项目经理在第一次发现这个问题时应该做哪两项工作?(选两个࿰…...
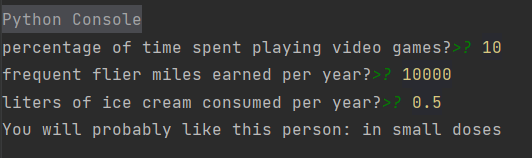
机器学习实战1-kNN最近邻算法
文章目录 机器学习基础机器学习的关键术语 k-近邻算法(KNN)准备:使用python导入数据实施kNN分类算法示例:使用kNN改进约会网站的配对效果准备数据:从文本文件中解析数据分析数据准备数据:归一化数值测试算法…...
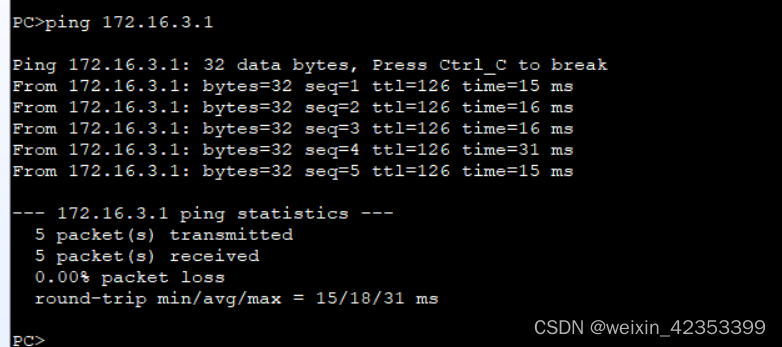
【eNSP】静态路由
【eNSP】静态路由 原理网关路由表 实验根据图片连接模块配置路由器设备R1R2R3R4 配置PC的IP地址、掩码、网关PC1PC2PC3 配置静态路由查看路由表R1R2R3R4测试能否通信 原理 网关 网关与路由器地址相同,一般路由地址为.1或.254。 网关是当电脑发送的数据的目标IP不在…...

专科英语A级和B级考试历年真题试卷及答案PDF电子版
高等学校英语应用能力考试(PRETCO)A 级、B 级历年真题试卷及答案 PDF 电子版,专为高职高专、大专在校生备考整理。内容涵盖2022年、2023年、2024年、2025年 6 月、12 月全套真题,含听力原文、答案解析、写作范文,题型覆…...

扁平化AI绘图黄金公式:sref 1280+--stylize 600+--v 6.2,为什么92%用户漏掉关键权重锚点?
更多请点击: https://codechina.net 第一章:扁平化AI绘图黄金公式的认知革命 传统AI绘图依赖复杂提示工程与多层参数调优,而“扁平化AI绘图黄金公式”颠覆了这一范式——它将生成逻辑压缩为三个可解释、可复用、可验证的核心要素:…...

为什么很多扩音设备总是啸叫?这块语音模组可能就是答案
做过扩音器、对讲机、会议设备的人,大概率都被这些问题折磨过:一开大音量就啸叫环境太吵听不清对讲时回音严重麦克风离远一点声音就没了最近看到一款 A-59F 语音处理模组,思路挺有意思。它把:AI降噪回音消除扩音防啸叫双麦定向拾音…...

3步搞定Photoshop图层批量导出:高效工具终极指南
3步搞定Photoshop图层批量导出:高效工具终极指南 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址: https://…...

Unity 2019格斗游戏开发:帧同步、输入缓冲与Hitbox/Hurtbox实现
1. 为什么2019版Unity仍是横板格斗开发的“黄金锚点”我带过三届游戏开发训练营,每次开课前都会问学员:“你最想用哪个版本做格斗游戏?”——超过七成的人脱口而出“最新版”。但当我把他们拉进一个用Unity 2019.4.40f1跑通的《街霸》风格连招…...

QCustomPlot交互秘籍:手把手实现数据点拾取、矩形框选与自定义高亮样式
QCustomPlot交互功能深度解析:从数据点拾取到视觉定制全攻略 1. 交互式数据可视化的核心价值 在现代数据可视化应用中,静态图表已经无法满足用户日益增长的交互需求。QCustomPlot作为Qt生态中功能强大的绘图库,其交互功能的设计既考虑了开发…...

长鑫存储逆袭:从近10年亏损超366亿到盈利超预期,能否成“中国海力士”?
长鑫存储逆袭:从巨亏到盈利超预期,能否成为“中国海力士”?“韩国巨头布局存储,中国巨头热衷于外卖。”这一波存储涨价潮,很多人用戏谑的方式来表达对中国几家互联网公司的“恨铁不成钢”。但长鑫存储却凭借一份极度亮…...

从‘Hello World’到工业通信:我的第一个C++ ADS客户端连接倍福PLC踩坑实录
从零搭建C ADS客户端:一位工程师的倍福PLC连接实战手记 第一次在Visual Studio里看到那个红色的编译错误时,我盯着屏幕足足愣了五分钟。"LNK2019: 无法解析的外部符号 __imp_AdsPortOpen",这行冰冷的报错彻底击碎了我以为照着官方…...

孤胆英雄的黄昏,社会化智能的黎明:一文看透 Multi-Agent 架构底层逻辑
在过去的一两年里,我们见证了单体大语言模型(LLM)的疯狂进化。我们给它穿上基建外骨骼(Harness),给它挂载无数的函数工具(Skills),试图把它打造成一个无所不能的“全栈超…...
)
Perplexity名言警句搜索深度解析(2024年Q2最新API行为逆向实测报告)
更多请点击: https://intelliparadigm.com 第一章:Perplexity名言警句搜索深度解析(2024年Q2最新API行为逆向实测报告) Perplexity 在 2024 年第二季度对 /search 端点实施了细粒度的请求签名验证与上下文指纹绑定机制࿰…...