Scikit-learn聚类方法代码批注及相关练习
一、代码批注
代码来自:https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler# make_blobs:为聚类产生数据集及其相应的标签;n_samples:样本点个数;centers:类别数;cluster_std:每个类别的方差;random_state:随机种子
# 这里centers里的三个二维坐标,其实代表了聚类的三个中心
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)# 标准化
X = StandardScaler().fit_transform(X)# 预估器,并得出模型(eps:数据点的邻域半径;min_samples:某个数据点的邻域内最少有的数据点个数)
db = DBSCAN(eps=0.2, min_samples=7).fit(X)# 生成n_samples个False
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
# 预测出的结果(有结果的为True,为噪音的是False)
core_samples_mask[db.core_sample_indices_] = True
# 获得预测结果
labels = db.labels_
# 获得预测的聚类数,忽略掉噪音
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
# 获得噪音数
n_noise_ = list(labels).count(-1)# 预测出的集群数,对应图中5中颜色
print('Estimated number of clusters: %d' % n_clusters_)
# 预测出噪音点的数量,对应图中的黑点
print('Estimated number of noise points: %d' % n_noise_)
# 同质性:簇的纯洁程度—对比分类问题的精度
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
# 完整性:簇的完整性—对比分类问题的召回率
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
# v测度:用来评估同一个数据集上两个独立赋值的一致性
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
# 调节的兰德系数(ARI):衡量两个数据分布的吻合程度
print("Adjusted Rand Index: %0.3f" % metrics.adjusted_rand_score(labels_true, labels))
# 调整互信息(AMI):衡量两个数据分布的吻合程度
print("Adjusted Mutual Information: %0.3f" % metrics.adjusted_mutual_info_score(labels_true, labels))
# 轮廓系数:将某个对象与自己的簇的相似程度和与其他簇的相似程度进行比较(肘方法)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels))import matplotlib.pyplot as pltunique_labels = set(labels)
# 给每个label赋个颜色
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):# 给噪音为黑色if k == -1:col = [0, 0, 0, 1]# 开始绘制,获得该种类的点class_member_mask = (labels == k)# core_samples_mask里false就是黑色噪音点# 取出同一类的点(这样&可以过滤掉黑点。如果没有core_samples_mask(黑点为false)会把黑点也画很大)xy = X[class_member_mask & core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=14)# 获得噪音点,注意:db.core_sample_indices_没出现的的不一定就是噪音点(小圆圈)xy = X[class_member_mask & ~core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col), markeredgecolor='k', markersize=6)plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
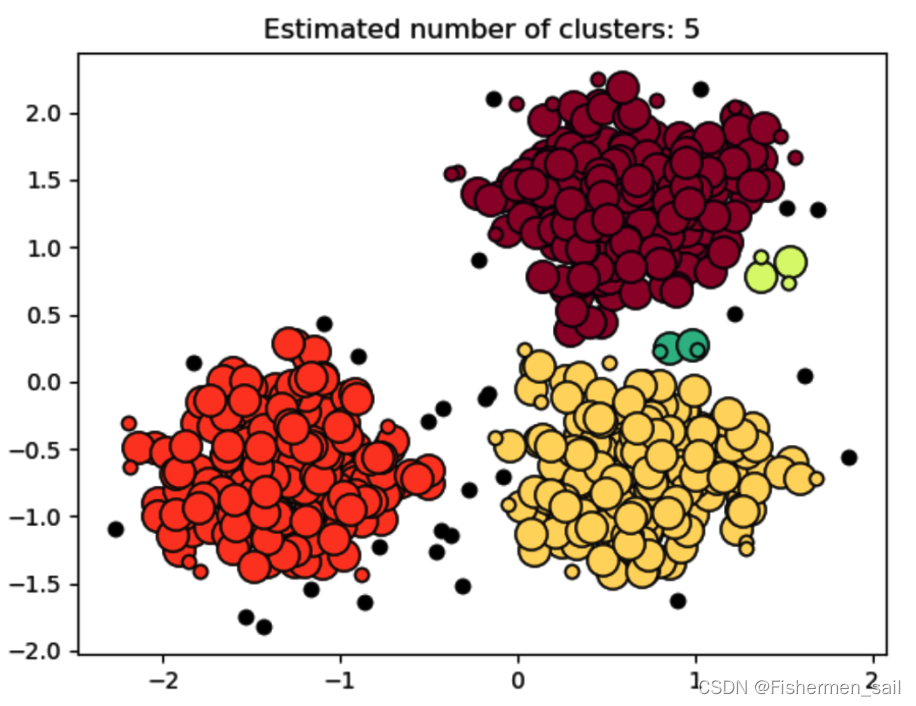
在实验中一直有个困惑,不知道这个小圆圈是怎么画上去的。它的原因是在“db.core_sample_indices_”和“db.labels”,起初我以为“db.core_sample_indices_”会生成除噪音点以外的其他index,也就是区分开了噪音点与聚类点。但其实并不是,有少部分不在“db.core_sample_indices_”中的点也是聚类点,在下方打印出来的值分别与它俩相对,可以看见前者并没有为32的index,理论上它应该为-1噪音点,但打印出“db.labels”发现index为32的值是1,是一个聚类点。这点也在scikit learn文档最后一段进行了说明,文档解释到图中大的圆为“core sample”,而小的圆为“non-core sample”,它也是聚类的一部分。





二、DBSCAN的使用
通过改变DBSCAN中min_samples参数观察图形的聚类效果。
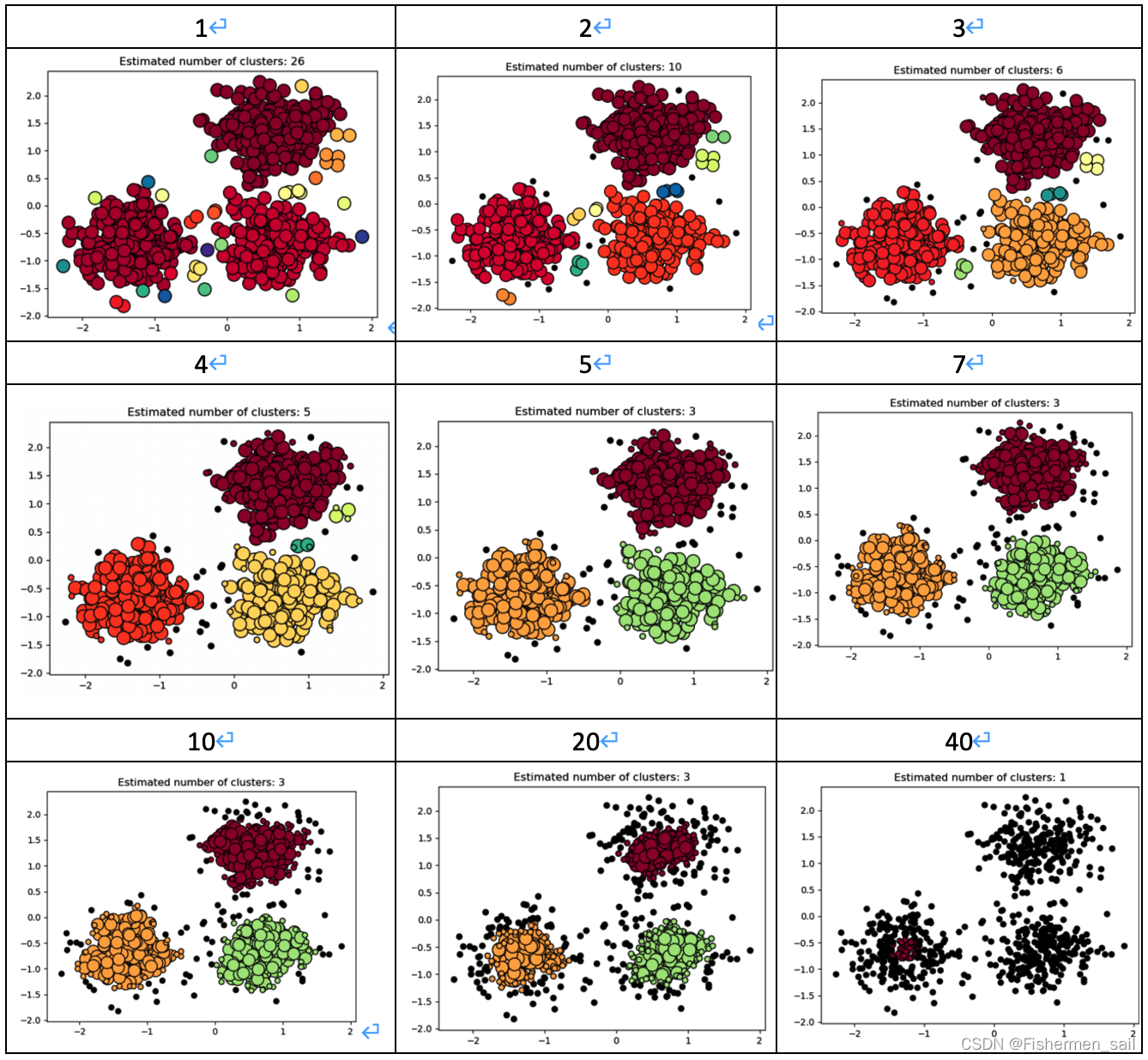
当min_samples为41时编译器报错。

观察上图可以发现随着min_samples的增大cluster越来越少,噪音点越来越多,直至报错。这是因为DBSCAN算法是基于密度的算法,所以它将密集区域内的点看作核心点(核心样本)。它主要有两个参数:min_samples和eps。
eps表示数据点的邻域半径,如果某个数据点的邻域内至少有min_sample个数据点,则将该数据点看作为核心点。如果某个核心点的邻域内有其他核心点,则将它们看作属于同一个簇。如果min_sampLes设置地太大,那么意味着更少的点会成为核心点,而更多的点将被标记为噪声。
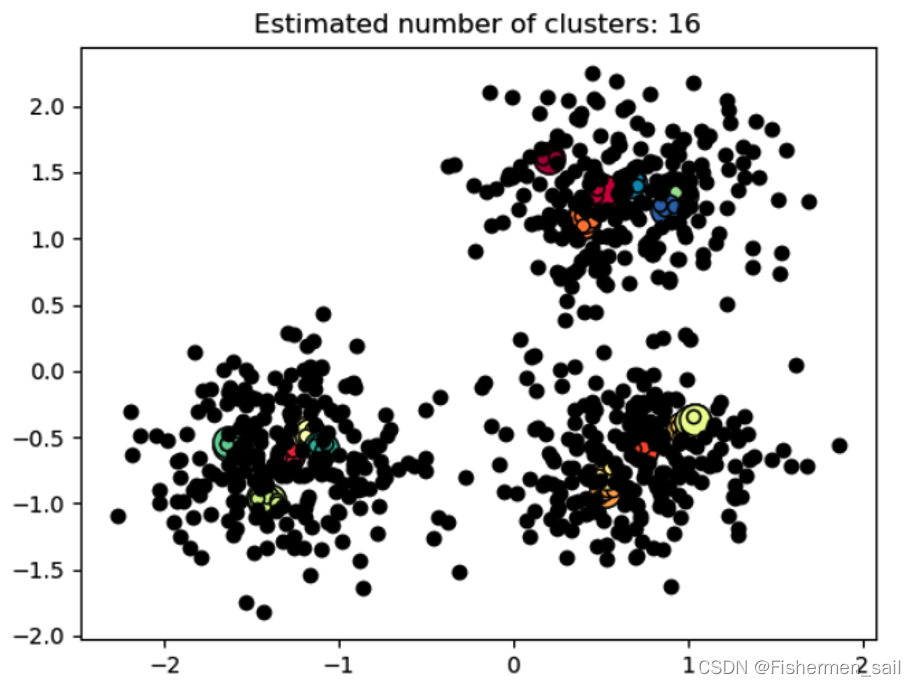
如果将eps设置得非常小,则有可能没有点成为核心点,并且可能导致所有点都被标记为噪声。如下图为eps=0.05,min_samples=5的图。
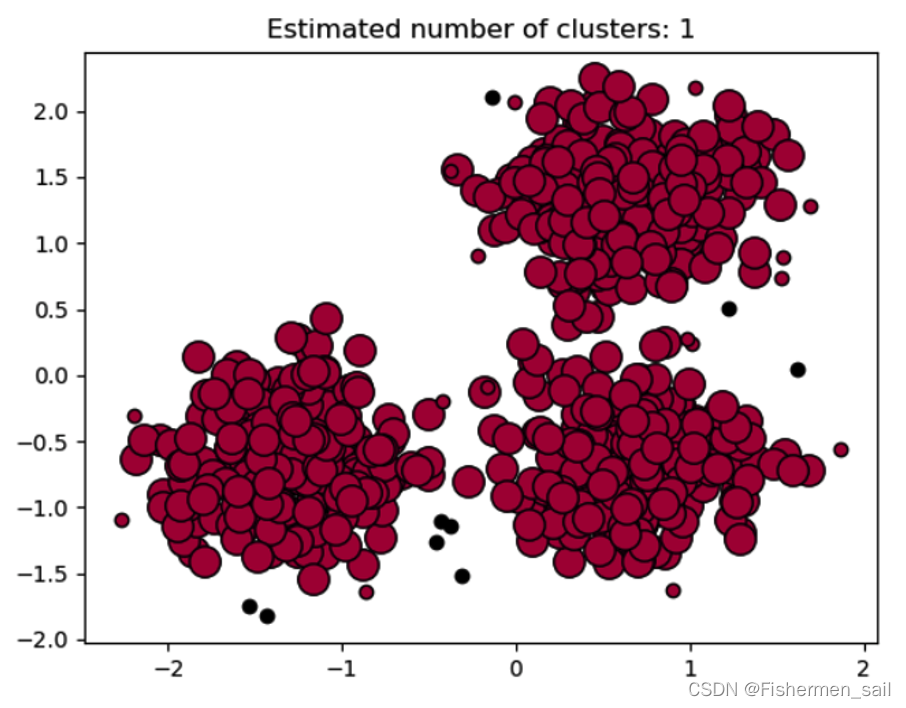
如果将eps设置为非常大,则将导致所有点都被划分到同一个簇。如下图为esp=0.3,min_samples=5的图。
三、KMeans的使用
由于KMeans并没有“core_sample_indices”这个属性,也就是不会分离出噪音点,需将该条语句注释掉。在画图时,由于并没有噪音点,也要进行相应改写。
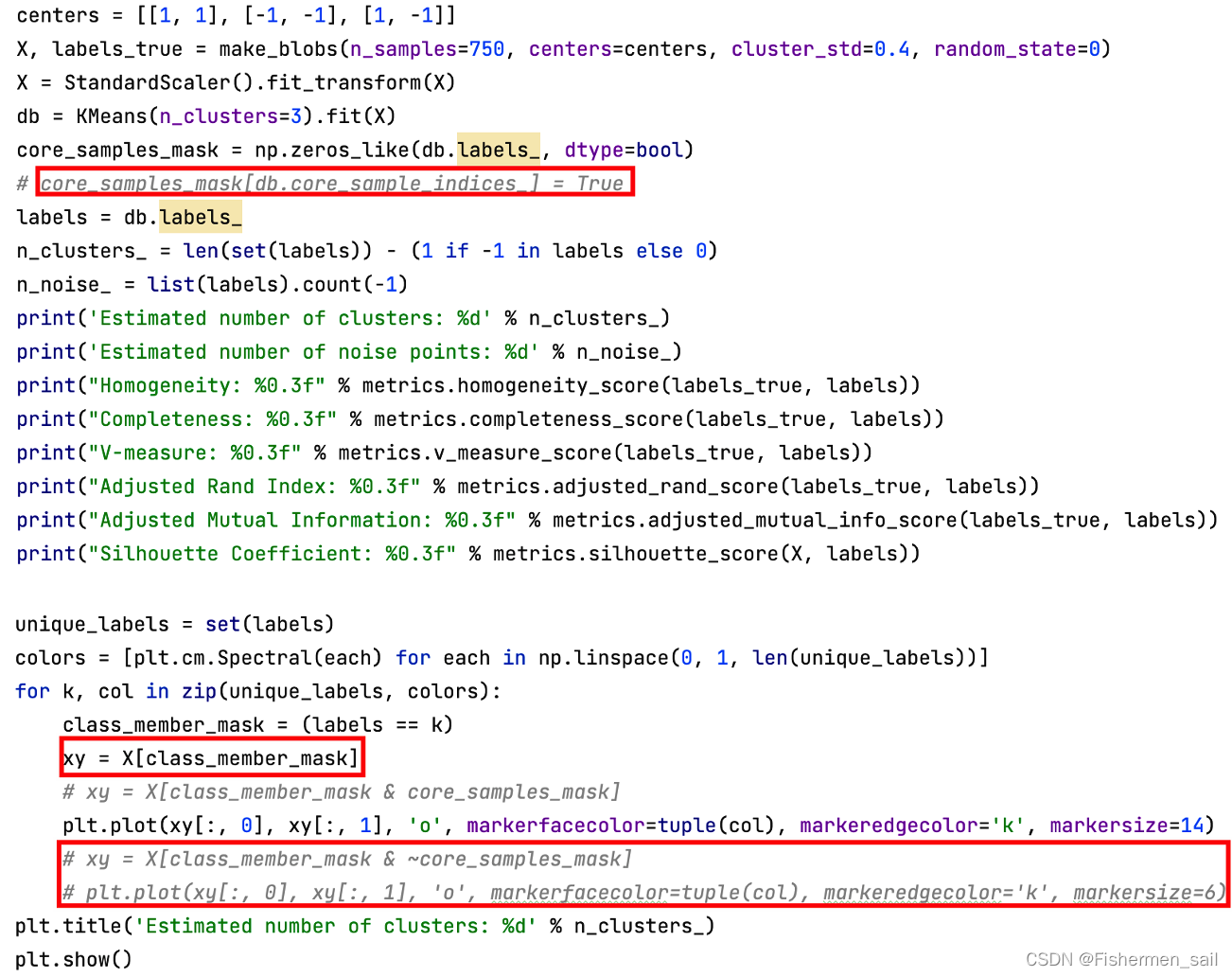
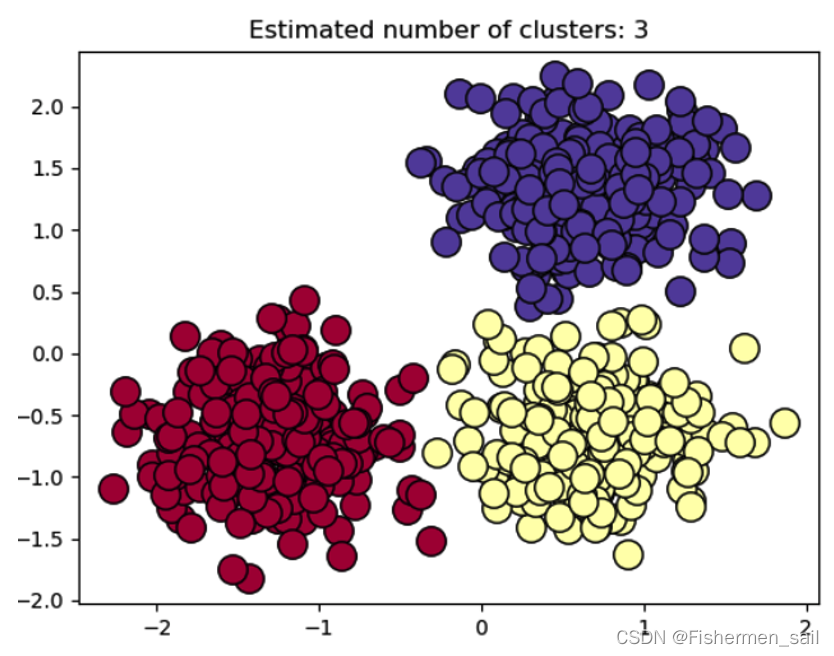
KMeans算法是根据给定的n个数据对象的数据集,构建n个划分聚类的方法,每个划分聚类即为一个簇。该方法将数据划分为n个簇,每个簇至少有一个数据对象,每个数据对象必须属于而且只能属于一个簇。同时要满足同一簇中的数据对象相似度高,不同簇中的数据对象相似度较小。聚类相似度是利用各簇中对象的均值来进行计算的。
KMeans 算法的处理流程如下,首先,随机地选择k个数据对象,每个数据对象代表一个簇中心,即选择k个初始中心;对剩余的每个对象,根据其与各簇中心的相似度(距离),将它赋给与其最相似的簇中心对应的簇;然后重新计算每个簇中所有对象的平均值,作为新的簇中心。不断重复以上这个过程,直到准则函数收敛,也就是簇中心不发生明显的变化。通常采用均方差作为准则函数,即最小化每个点到最近簇中心的距离的平方和。新的簇中心计算方法是计算该簇中所有对象的平均值,也就是分别对所有对象的各个维度的值求平均值,从而得到簇的中心点。
四、KMeans与DBSCAN对比
| KMeans | DBSCAN |
|---|---|
| 使用簇的基于原型的概念。 | 使用基于密度的概念。 |
| 只能用于具有明确定义的质心(如均值)的数据。 | 要求密度定义(基于传统的欧几里得密度概念)对于数据是有意义的。 |
| 需要指定簇的个数作为参数。 | 不需要事先知道要形成的簇类的数量,自动确定簇个数。 |
| 很难处理非球形的簇和不同形状的簇。 | 可以发现任意形状的簇类,可以处理不同大小和不同形状的簇。 |
| 可以用于稀疏的高纬数据,如文档数据。 | 不能很好反映高维数据。 |
| 可以发现不是明显分离的簇,即便簇有重叠也可以发现。 | 会合并有重叠的簇。 |
相关文章:
Scikit-learn聚类方法代码批注及相关练习
一、代码批注 代码来自:https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py import numpy as np from sklearn.cluster import DBSCAN from sklearn import metrics from sklearn.datasets …...

C#程序的启动显示方案(无窗口进程发送消息) - 开源研究系列文章
今天继续研究C#的WinForm的实例显示效果。 我们上次介绍了Winform窗体的唯一实例运行代码(见博文:基于C#的应用程序单例唯一运行的完美解决方案 - 开源研究系列文章 )。这就有一个问题,程序已经打开了,这时候再次运行该应用程序,…...

java泛型和通配符的使用
泛型机制 本质是参数化类型(与方法的形式参数比较,方法是参数化对象)。 优势:将类型检查由运行期提前到编译期。减少了很多错误。 泛型是jdk5.0的新特性。 集合中使用泛型 总结: ① 集合接口或集合类在jdk5.0时都修改为带泛型的结构② 在实例化集合类时…...
【网络】自定义协议 | 序列化和反序列化 | 以tcpServer为例
本文首发于 慕雪的寒舍 以tcpServer的计算器服务为例,实现一个自定义协议 阅读本文之前,请先阅读 tcpServer 本文完整代码详见 Gitee 1.重谈tcp 注意,当下所对tcp的描述都是以简单、方便理解起见,后续会对tcp协议进行深入解读 …...
06-3_Qt 5.9 C++开发指南_多窗体应用程序的设计(主要的窗体类及其用途;窗体类重要特性设置;多窗口应用程序设计)
文章目录 1. 主要的窗体类及其用途2. 窗体类重要特性的设置2.1 setAttribute()函数2.2 setWindowFlags()函数2.3 setWindowState()函数2.4 setWindowModality()函数2.5 setWindowOpacity()函数 3. 多窗口应用程序设计3.1 主窗口设计3.2 QFormDoc类的设计3.3 QFormDoc类的使用3.…...

(力扣)用两个栈实现队列
这里是栈的源代码:栈和队列的实现 当然,自己也可以写一个栈来用,对题目来说不影响,只要符合栈的特点就行。 题目: 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、pe…...

【自动化测试框架】关于unitttest你需要知道的事
一、UnitTest单元测试框架提供了那些功能 1.提供用例组织和执行 如何定义一条“测试用例”? 如何灵活地控制这些“测试用例”的执行? 2.提供丰定的断言方法 当测试用例的执行结果与预期结果不一致时,判定测试用例失败。在自动化测试中,通过“断言”…...
手机便签中可以打勾的圆圈或小方块怎么弄?
在日常的生活和工作中,很多网友除了使用手机便签来记录灵感想法、读书笔记、各种琐事、工作事项外,还会用它来记录一些清单,例如待办事项清单、读书清单、购物清单、旅行必备物品清单等。 在按照记录的清单内容来执行的时候,为了…...

【Linux】gdb 的使用
目录 1. 使用 gdb 的前置工作 2. 如何使用 gdb 进行调试 1、如何看到我的代码 2、如何打断点 3、怎么运行程序 4、如何进行逐过程调试 5、如何进行逐语句调试 6、如何监视变量值 7、如何跳到指定位置 8、运行完一个函数 9、怎么跳到下一个断点 10、如何禁用/开启…...
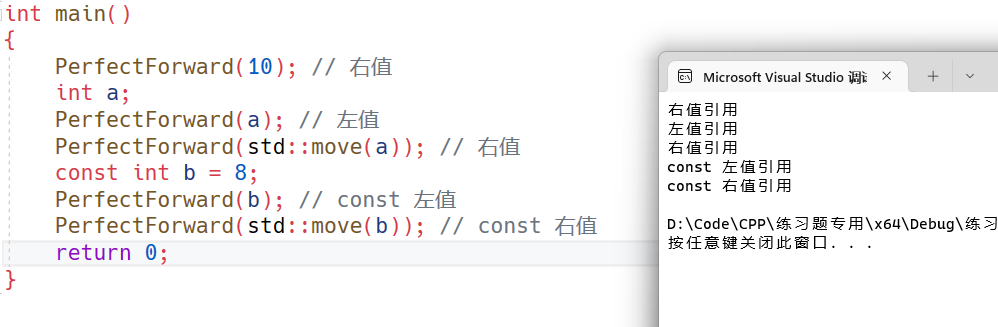
C++11之右值引用
C11之右值引用 传统的C语法中就有引用的语法,而C11中新增了的 右值引用(rvalue reference)语法特性,所以从现在开始我们之前学习的引用就叫做左值引用(lvalue reference)。无论左值引用还是右值引用&#…...

【PHP的设计模式】
PHP的设计模式 一、策略模式二、工厂模式三、单例模式四、注册模式五、适配器模式六、观察者模式 一、策略模式 策略模式是对象的行为模式,用意是对一组算法的封装。动态的选择需要的算法并使用。 策略模式指的是程序中涉及决策控制的一种模式。策略模式功能非常强…...
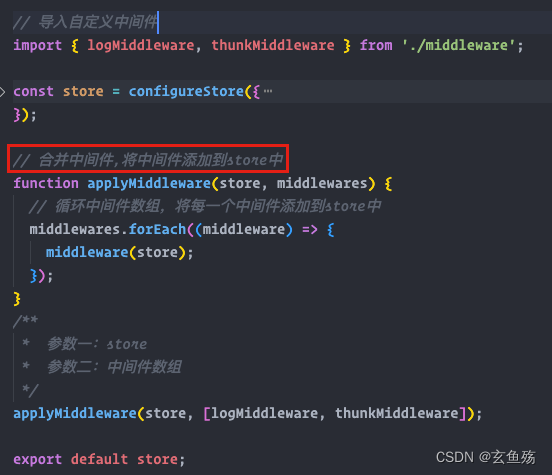
React 之 Redux - 状态管理
一、前言 1. 纯函数 函数式编程中有一个非常重要的概念叫纯函数,JavaScript符合函数式编程的范式,所以也有纯函数的概念 确定的输入,一定会产生确定的输出 函数在执行过程中,不能产生副作用 2. 副作用 表示在执行一个函数时&a…...

集合转数组
首先,我们在看到集合转数组的时候可能第一个想到的就是toArray(),但是我们在调用 toArray()的时候,可能会遇到异常 java.lang.ClassCastException;这是因为 toArray()方法返回的类型是 Obejct[],如果我们将其转换成其他类型&#…...

使用Python将Word文档转换为PDF的方法
摘要: 文介绍了如何使用Python编程语言将Word文档转换为PDF格式的方法。我们将使用python-docx和pywin32库来实现这个功能,这些库提供了与Microsoft Word应用程序的交互能力。 正文: 在现实生活和工作中,我们可能会遇到将Word文…...

Java 判断一个字符串在另一个字符串中出现的次数
1.split实现 package com.jiayou.peis.official.account.biz.utils;public class Test {public static void main(String[] args) {String k"0110110100100010101111100101011001101110111111000101101001100010101" "011101100101011010100011111010111001001…...
)
设计模式十三:代理(Proxy Pattern)
代理模式是一种结构型设计模式,它允许通过在对象和其真实服务之间添加一个代理对象来控制对该对象的访问。代理对象充当了客户端和真实服务对象之间的中介,并提供了额外的功能,如远程访问、延迟加载、访问控制等。 代理模式的使用场景包括&a…...

Redis基础 (三十八)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 1.1 NoSQL 1.2 Redis 二、安装 2.1 安装方式 : 三、目录结构 3.1 rpm -ql redis 3.2 /etc/redis.conf 主配置文件 3.3 /var/lib/redis …...

maven中的scope
1、compile:默认值,可省略不写。此值表示该依赖需要参与到项目的编译、测试以及运行周期中,打包时也要包含进去。 2、test:该依赖仅仅参与测试相关的工作,包括测试代码的编译和执行,不会被打包,…...
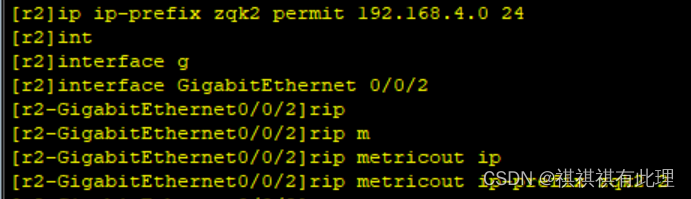
【网络基础实战之路】实现RIP协议与OSPF协议间路由交流的实战详解
系列文章传送门: 【网络基础实战之路】设计网络划分的实战详解 【网络基础实战之路】一文弄懂TCP的三次握手与四次断开 【网络基础实战之路】基于MGRE多点协议的实战详解 【网络基础实战之路】基于OSPF协议建立两个MGRE网络的实验详解 PS:本要求基于…...
CNN(四):ResNet与DenseNet结合--DPN
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊|接辅导、项目定制 前面实现了ResNet和DenseNet的算法,了解了它们有各自的特点: ResNet:通过建立前面层与后面层之间的“短路…...
)
CTF新手必看:用Python脚本搞定RSA常见攻击(附实战代码)
CTF密码学实战:Python脚本破解RSA五大攻击场景 在CTF竞赛中,RSA加密系统是最常见的密码学挑战之一。本文将带你深入实战,通过Python代码复现五种经典RSA攻击场景,从基础分解到高级数学技巧,每个案例都配有可直接运行的…...

TI SimpleLink平台实战:MSP432+CC3120构建统一嵌入式开发方案
1. 项目概述:为什么我们需要一个统一的嵌入式开发平台?如果你和我一样,在嵌入式行业摸爬滚打了几年,一定会对下面这个场景深有感触:老板今天说要做个带Wi-Fi的智能插座,你吭哧吭哧用ESP32调通了;…...

百考通:AI让每一份调研与设计都高效落地
在数字化时代,市场调研、产品设计、学术研究等场景中,问卷设计作为核心环节,直接影响着数据收集的质量与工作推进的效率。传统问卷设计往往面临流程繁琐、耗时耗力、问题设计不精准等痛点,而百考通(https://www.baikao…...
)
告别树莓派5?手把手教你用OrangePi 5搭建家庭媒体中心(基于RK3588)
告别树莓派5?手把手教你用OrangePi 5搭建家庭媒体中心(基于RK3588) 在智能家居日益普及的今天,家庭媒体中心已成为许多科技爱好者的必备设备。传统的解决方案往往依赖于昂贵的商业NAS或性能有限的树莓派,而基于RK3588芯…...

如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南
如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 你是否拥有一些老旧但质量优秀的游戏手柄、摇杆或方向盘,却发现在现代游戏…...

瑞萨RL78/F25电容触摸开发:从FSP配置到调试优化全解析
1. 项目概述与核心价值最近在做一个家电控制面板的项目,主控选型时看中了瑞萨的RL78/F25系列MCU。这个系列主打低功耗和高集成度,内置了电容式触摸感应单元(CTSU),对于需要触摸按键、滑条的应用来说,简直是…...

不用Remix在线版!在VSCode里用Hardhat写合约,搭配Ganache和MetaMask本地测试全流程
在VSCode中构建专业级以太坊开发环境:HardhatGanacheMetaMask全流程指南 对于追求高效开发的以太坊工程师而言,脱离浏览器限制、建立本地化开发工作流已成为专业化的标志。本文将带你用VSCodeHardhat打造企业级智能合约开发环境,结合Ganache私…...

强力解锁:5分钟掌握暗黑破坏神2存档编辑器的核心功能
强力解锁:5分钟掌握暗黑破坏神2存档编辑器的核心功能 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾为刷取一件心仪的暗黑2装备耗费数小时?是否想快速测试不同的角色build却苦于重复练级&#x…...

实测 DeepSeek-V4 接入 Hermes:一句话爬取几十个网页,真的丝滑!
你好,我是郭震OpenClaw龙虾使用有一段时间了,体感很好,即便使用本地模型,如Qwen3.5:9B这样的模型,养虾Token自由,回复也比较丝滑。如下所示,轻松生成HTML风格的文件结构树:也能轻松生…...
)
手把手教你给M301H-BYT盒子刷当贝纯净桌面(附Hi3798芯片短接点位图)
从零开始:M301H-BYT盒子刷机实战指南 家里的老旧电视盒子用久了总是卡顿、存储不足,还限制应用安装?今天我们就来彻底解决这个问题。本文将手把手教你如何为M301H-BYT盒子刷入当贝纯净桌面系统,让你的老设备重获新生。不同于简单的…...