TartanVO: A Generalizable Learning-based VO 论文阅读
论文信息
题目:TartanVO: A Generalizable Learning-based VO
作者:Wenshan Wang, Yaoyu Hu
来源:ICRL
时间:2021
代码地址:https://github.com/castacks/tartanvo
Abstract
我们提出了第一个基于学习的视觉里程计(VO)模型,该模型可推广到多个数据集和现实场景,并且在具有挑战性的场景中优于基于几何的方法。
我们通过利用 SLAM 数据集 TartanAir 来实现这一目标,该数据集在具有挑战性的环境中提供了大量多样化的合成数据。此外,为了使我们的 VO 模型能够跨数据集泛化,我们提出了一个大规模损失函数,并将相机内在参数合并到模型中。
实验表明,仅在合成数据上进行训练且无需任何微调的单一模型 TartanVO 可以推广到现实世界的数据集(例如 KITTI 和 EuRoC),在具有挑战性的轨迹上表现出相对于基于几何的方法的显着优势。
Introduction
基于几何的方法 [2,3,4,5] 和基于学习的方法 [6,7,8,9] 都取得了令人印象深刻的进展。然而,为实际应用开发稳健可靠的 VO 方法仍然是一个具有挑战性的问题
一方面,基于几何的方法在许多现实生活中不够稳健[10, 11]。
另一方面,虽然基于学习的方法在许多视觉任务上表现出了强大的性能,包括对象识别、语义分割、深度重建和光流,但我们还没有看到同样的情况发生在 VO 上。
现有的 VO 模型训练的多样性不足,这对于基于学习的方法能够泛化至关重要。
其次,当前大多数基于学习的 VO 模型都忽略了问题的一些基本性质,而这些性质在基于几何的 VO 理论中得到了很好的阐述。
为此,我们提出了一种基于学习的方法,可以解决上述两个问题,并且可以跨数据集泛化。我们的贡献有三个方面。
- 我们通过比较不同数量的训练数据的性能来证明数据多样性对 VO 模型泛化能力的关键影响。
- 我们设计了一个尺度损失函数来处理单目 VO 的尺度模糊性。
- 我们在 VO 模型中创建一个内在层 (IL),以实现跨不同相机的泛化。
Related Work
为了提高性能,端到端 VO 模型往往具有与相机运动相关的辅助输出,例如深度和光流。通过深度预测,模型通过在时间连续图像之间施加深度一致性来获取监督信号 [17, 21]。此过程可以解释为匹配 3D 空间中的时间观察结果。时间匹配的类似效果可以通过产生光流来实现,例如,[16,22,18]联合预测深度、光流和相机运动。
光流也可以被视为明确表达 2D 匹配的中间表示。然后,相机运动估计器可以处理光流数据,而不是直接处理原始图像[20, 23]。如果以这种方式设计,甚至可以根据可用的光流数据单独训练用于估计相机运动的组件[19]。我们遵循这些设计并使用光流作为中间表示。
众所周知,单目 VO 系统存在尺度模糊性。然而,大多数监督学习模型没有处理这个问题,而是直接使用模型预测和真实相机运动之间的差异作为监督[20,24,25]。在[19]中,通过将光流划分为子区域并在这些区域之间施加运动预测的一致性来处理尺度。在非学习方法中,如果 3D 地图可用,则可以解决尺度模糊性[26]。 Ummenhofer 等人[20]引入深度预测来校正尺度漂移。 Tateno 等人 [27] 和 Shen 等人 [28] 通过利用 SLAM 系统的关键帧选择技术改善了尺度问题。最近,Zhan 等人[29]使用 PnP 技术来显式求解比例因子。上述方法给 VO 系统带来了额外的复杂性,然而,对于单目设置,尤其是在评估阶段,尺度模糊性并没有完全被抑制。
相反,一些模型选择只产生符合规模的预测。 Wang等人[30]通过在计算损失函数之前对深度预测进行归一化来减少单目深度估计任务中的尺度模糊性。同样,我们将通过定义新的最大尺度损失函数,专注于预测平移方向,而不是从单目图像中恢复全尺寸。
当对来自新环境或新相机的图像进行测试时,基于学习的模型会遇到泛化问题。大多数 VO 模型都是在同一数据集上进行训练和测试的 [16,17,31,18]。一些多任务模型[6,20,32,22]仅测试其在深度预测上的泛化能力,而不是在相机姿态估计上的泛化能力。最近的努力,例如[33],使用模型适应来处理新环境,但是,需要在每个环境或每个摄像机的基础上进行额外的训练。在这项工作中,我们提出了一种通过将相机内在函数直接合并到模型中来实现跨相机/数据集泛化的新颖方法。
Approach
Background
我们关注单目 VO 问题,该问题采用两个连续的未失真图像 { I t , I t + 1 } \{I_t, I_{t+1}\} {It,It+1},并估计相对相机运动 δ t t + 1 = ( T , R ) δ^{t+1}_t = (T, R) δtt+1=(T,R),其中 T ∈ R 3 T ∈ \mathbb{R}^3 T∈R3 是 3D 平移, R ∈ s o ( 3 ) R ∈ so (3) R∈so(3) 表示 3D 旋转。根据对极几何理论[34],基于几何的 VO 有两个方面。
首先,从 I t I_t It和 I t + 1 I_{t+1} It+1中提取并匹配视觉特征。
然后使用匹配结果,计算导致恢复最大尺度相机运动 δ t t + 1 δ^{t+1}_t δtt+1的基本矩阵。
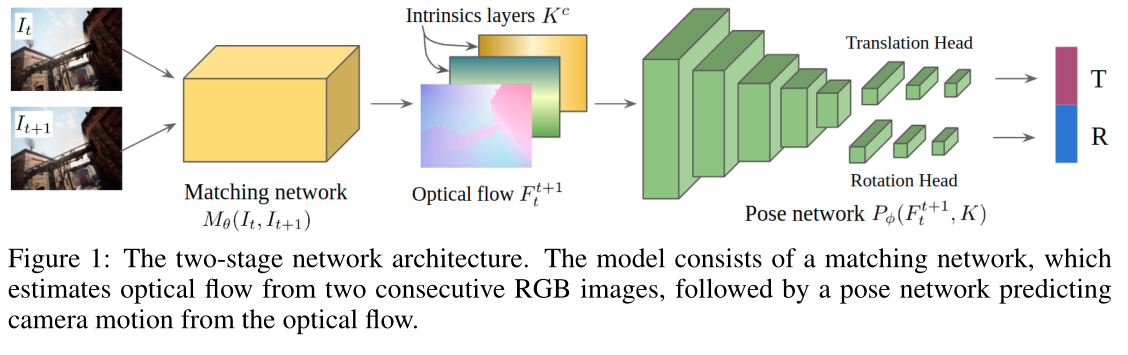
我们的模型由两个子模块组成。
一个是匹配模块 M θ ( I t , I t + 1 ) M_θ(I_t, I_{t+1}) Mθ(It,It+1),从两个连续的 RGB 图像(即光流)。
另一个是位姿模块 P ϕ ( F t t + 1 ) P\phi(F_t^{t+1}) Pϕ(Ftt+1),它从匹配结果中恢复相机运动 δ t t + 1 δ_t^{t+1} δtt+1(图 1)。
这种模块化设计也广泛应用于其他基于学习的方法,特别是无监督 VO
Training on large scale diverse data
泛化能力一直是基于学习的方法最关键的问题之一。之前的大多数监督模型都是在 KITTI 数据集或由微型飞行器(MA V)收集的 EuRoC 数据集 [36]。
大多数无监督方法也只在非常统一的场景中训练模型(例如 KITTI 和 Cityscape [37])。据我们所知,目前还没有基于学习的模型表现出在多种类型场景(汽车/MA V、室内/室外)上运行的能力。为了实现这一目标,我们认为训练数据必须涵盖不同的场景和运动模式。
TartanAir [11] 是一个大规模数据集,具有高度多样化的场景和运动模式,包含超过 400,000 个数据帧。它提供多模态地面真实标签,包括深度、分割、光流和相机姿势。场景包括室内、室外、城市、自然和科幻环境。数据通过模拟针孔相机收集,该相机在 3D 空间中以随机且丰富的 6DoF 运动模式移动。
我们在任务中利用单目图像序列 { I t } \{I_t\} {It}、光流标签 { F t t + 1 } \{F ^{t+1}_t \} {Ftt+1} 和地面实况相机运动 { δ t t + 1 } \{δ^{t+1}_t\} {δtt+1}。我们的目标是共同最小化光流损耗 L f L_f Lf 和相机运动损耗 L p L_p Lp。端到端损耗定义为:
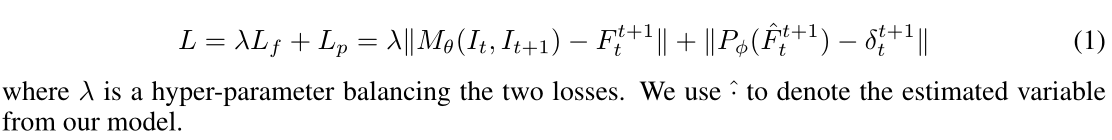
Up-to-scale loss function
在大多数现有的基于学习的VO研究中,模型通常忽略尺度问题并尝试用尺度来恢复运动。如果模型是使用相同的相机并在相同类型的场景中进行训练和测试的,这是可行的。但一旦相机发生变化就不可行。
按照基于几何的方法,我们仅从单目序列中恢复最大尺度的相机运动。知道尺度模糊度只影响平移 T T T ,我们为 T T T 设计了一个新的损失函数,并保持旋转 R R R 的损失不变。我们为 L P L_P LP 提出了两个大规模损失函数:余弦相似度损失 L p c o s L^{cos}_p Lpcos 和归一化距离损失 L p n o r m L^{norm}_p Lpnorm 。 L p c o s L^{cos}_p Lpcos 由估计的 T ^ \hat{T} T^ 和标签 T T T 之间的余弦角定义:

Cross generalization by encoding camera intrinsics
在对极几何理论中,从基本矩阵恢复相机位姿时需要相机本征(假设图像未失真)。事实上,基于学习的方法不太可能推广到具有不同相机内在特性的数据。想象一个简单的情况,相机更换了更大焦距的镜头。假设图像的分辨率保持不变,相同量的相机运动将引入更大的光流值,我们称之为内在模糊度。
对于内在模糊性的一个诱人的解决方案是扭曲输入图像以匹配训练数据的相机内在。然而,这不太实用,尤其是当相机差异太大时。如图2-a所示,如果模型在TartanAir上训练,扭曲的KITTI图像仅覆盖TartanAir视野(FoV)的一小部分。训练后,模型学会利用视场中所有可能位置的线索以及这些线索之间的相互关系。扭曲的 KITTI 图像中不再存在一些线索,导致性能急剧下降。
Instrinsics layer
我们建议训练一个以 RGB 图像和相机内部参数作为输入的模型,以便于该模型可以直接处理来自各种相机设置的图像。
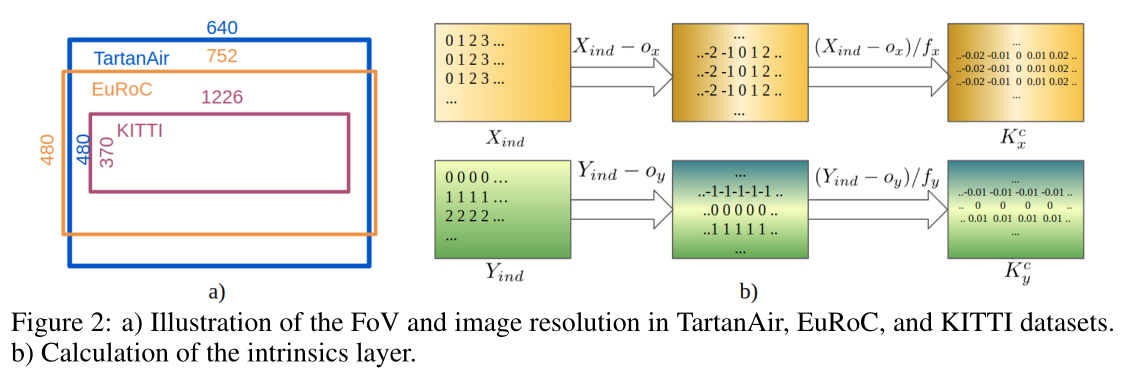
具体来说,我们设计了一个新的姿态网络 P ϕ ( F t t + 1 , K ) P_\phi(F^{t+1}_t , K) Pϕ(Ftt+1,K),而不是仅从特征匹配 F t t + 1 F^{t+1}_t Ftt+1 中恢复相机运动 T t t + 1 T^{t+1}_t Ttt+1 ,该网络也取决于相机内在参数 K = { f x , f y , o x , o y } K = \{f_x ,f_y,o_x,o_y\} K={fx,fy,ox,oy},其中 f x f_x fx和 f y f_y fy是焦距, o x o_x ox和 o y o_y oy表示主点的位置。

Data generation for various camera intrinsics
为了使模型可以跨不同相机推广,我们需要具有各种相机内在特性的训练数据。
TartanAir 只有一组相机内在函数,其中 f x = f y = 320 、 o x = 320 f_x = f_y = 320、o_x = 320 fx=fy=320、ox=320 和 o y = 240 o_y = 240 oy=240。我们通过随机裁剪和调整输入图像大小 (RCR) 来模拟各种内在函数。
如图3所示,我们首先在随机位置以随机大小裁剪图像。接下来,我们将裁剪后的图像调整为原始大小。
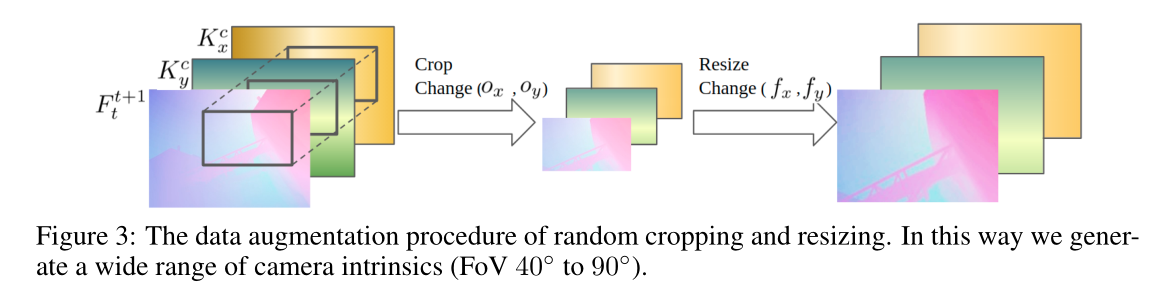
IL 的优点之一是,在 RCR 期间,我们可以使用图像裁剪 IL 并调整其大小,而无需重新计算 IL。为了覆盖 FoV 在 40° 到 90° 之间的典型相机,我们发现在 RCR 期间使用高达 2.5 的随机调整大小因子就足够了。
请注意,地面实况光流还应根据调整大小因子进行缩放。我们在训练中使用非常积极的裁剪和移动,这意味着光学中心可能远离图像中心。尽管所得的内在参数在现代相机中并不常见,但我们发现泛化能力得到了提高
Experimental


相关文章:
TartanVO: A Generalizable Learning-based VO 论文阅读
论文信息 题目:TartanVO: A Generalizable Learning-based VO 作者:Wenshan Wang, Yaoyu Hu 来源:ICRL 时间:2021 代码地址:https://github.com/castacks/tartanvo Abstract 我们提出了第一个基于学习的视觉里程计&…...
单例模式-java实现
介绍 单例模式的意图:保证某个类在系统中有且仅有一个实例。 我们可以看到下面的类图:一般的单例的实现,是属性中保持着一个自己的私有静态实例引用,还有一个私有的构造方法,然后再开放一个静态的获取实例的方法给外界…...

篇八:装饰器模式:动态增加功能
篇八:“装饰器模式:动态增加功能” 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料,…...

算法通关村第五关——n数之和问题解析
1. 两数之和问题 力扣第1题就是两数之和问题,给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那两个整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一…...

小白到运维工程师自学之路 第七十集 (Kubernetes集群部署)
一、概述 Kubernetes(简称K8S)是一个开源的容器编排和管理平台,是由Google发起并捐赠给Cloud Native Computing Foundation(CNCF)管理的项目。它的目标是简化容器化应用的部署、扩展、管理和自动化操作。 以下是Kube…...
docker 部署mysql 5.6集群
docker搭建mysql的集群(一主双从) 1.拉取镜像 docker pull mysql:5.6 2.启动master容器 docker run -it -d --name mysql_master -p 3306:3306 --ip 192.168.162.100 \ -v /data/mysql_master/mysql:/var/lib/mysql \ -v /data/mysql_master/conf.d…...

mysql基本信息查询
1.查看mysql表的数据量 select table_schema as 数据库, table_name as 表名, table_rows as 记录数, truncate(data_length/1024/1024, 2) as 数据容量(MB), truncate(index_length/1024/1024, 2) as 索引容量(MB) from information_schema.tables order by data_length des…...

C语言初学者必读:使用for循环将数字从大到小排序并输出
在学习C语言编程的过程中,了解数组的输入和排序是非常基础且重要的一部分。本文将以通俗易懂的方式,教你如何使用for循环实现将输入的n个数字按照从大到小的顺序输出,帮助你逐步掌握数组的使用和排序算法。 第一步:获取用户输入 …...

【Vue+Element-plus】记录后台首页多echart图静态页面
一、页面效果 二、完整代码 Index.vue <template><div><div><DateTime /><!-- {{username}} --></div><el-row :gutter"20"><el-col :span"8"><div class"grid-content bg-purple"><P…...

BM5 合并k个已排序的链表 javascript
描述 合并 k 个升序的链表并将结果作为一个升序的链表返回其头节点。 数据范围: 示例1 输入: [{1,2,3},{4,5,6,7}] 返回值: {1,2,3,4,5,6,7}示例2 输入: [{1,2},{1,4,5},{6}] 返回值: {1,1,2,4,5,6}解题思路 利用两个…...
1.利用matlab建立符号表达式(matlab程序)
1.简述 、 1. 使用sym命令创建符号变量和表达式 语法: sym(‘变量’,参数) %把变量定义为符号对象 说明:参数用来设置限定符号变量的数学特性,可以选择为’positive’、’real’和’unreal’, ’positive’ 表示为“正、实”符…...
LVS工作环境配置
一、LVS-DR工作模式配置 模拟环境如下: 1台客户机 1台LVS负载调度器 2台web服务器 1、环境部署 (1)LVS负载调度器 yum install -y ipvsadm # 在LVS负载调度器上进行环境安装 ifconfig ens33:200 192.168.134.200/24 # 配置LVS的VIP…...

金蝶,「起舞」在大模型时代
在过去的几年时间里,基于EBC的平台能力,金蝶已经走出了一个新的进化之路,这条路是对自身产品竞争力的重新构建,也更是对企业数字化转型需求的更大程度满足。 如今,苍穹GPT大模型更是让这种竞争力和服务力更向前一步。…...
解决Vs Code工具开发时 保存React文件时出现乱码情况
Vs Code工具开发时 保存React文件时出现乱码情况 插件库搜索:JS-CSS-HTML Formatter 把这个插件禁用或者卸载就解决保存时出现乱码的问题了; 如果没有解决,再看下面方案! 出现乱码问题通常是因为文件的编码格式不正确。您可以尝试以下解决方法: 确认文件编码格式&a…...

Fastjson 使用指南
文章目录 Fastjson 使用指南0 简要说明为什么要用JSON?用JSON的好处是什么?为什么要用JSON?JSON好处 1 常用数据类型的JSON格式值的范围 2 快速上手2.1 依赖2.2 实体类2.3 测试类 3 常见用法3.1 序列化操作核心操作对象转换为JSON串list转换J…...
阿里云内容审核服务使用(图片审核)
说明:在项目中,我们经常会对用户上传的内容(如文字、图片)等资源内容进行审核,审核包括两方面,一方面是内容与描述不符,一方面是违反法律法规。本文介绍使用阿里提供的内容审核服务,…...

git撤回最近一次push操作
git push -f origin HEAD^:branch_name其中,branch_name 是你想要撤回 push 操作的分支的名称。 这个命令将会强制推送到远程仓库,将远程分支回滚到上一个提交(HEAD^ 意味着上一个提交)。这样做会丢失最近一次 push 的更改&#…...

2000-2022年上市公司环境不确定性(原始数据+测算代码+测算结果)
2000-2022年上市公司环境不确定性指数(含原始数据 代码和计算结果) 1、时间:2000-2022年 2、指标:gupiao代码、名称、日期、年份、总资产净利润率ROA、营业收入、上市日期、成立日期、行业代码、年末是否ST或PT、行业、EU未调整…...

网络基本概念
目录 一、IP地址 1. 概念 2. 格式 3. 特殊IP 二、端口号 1.概念 2. 格式 3.注意事项 三、 协议 1. 概念 2. 作用 四、协议分层 1. 网络设备所在分层 五、封装与分用 六、客户端和服务器 1. 客户端与服务器通信的过程 一、IP地址 1. 概念 IP地址主要用于标识网络主机.其他网络…...
2.安装Docker-ce
一、删除之前安装的docker(若之前未安装过,此步骤省略…) 进入centos根目录执行以下命令(\ 是linux系统种命令换行符,如果命令过长,可以用\来换行) yum remove docker \ docker-client \ docker-client-latest \ doc…...

Tina Linux音频开发指南:从ALSA框架到实战调试
1. 项目概述:为什么我们需要一份音频开发指南?在嵌入式Linux的世界里,音频开发常常被开发者们戏称为“玄学”。我见过太多项目,硬件电路设计得漂漂亮亮,系统也跑得飞快,但一到音频部分就卡壳——要么是播放…...

Multi-Agent产品创新:从单一场景到跨域协同的演进
Multi-Agent产品创新:从单一场景到跨域协同的演进 关键词:多智能体系统、产品创新、跨域协同、单一场景智能、Agent协作框架、LLM驱动Agent、分布式智能 摘要:大语言模型的爆发式发展,让智能Agent从实验室走向了大众消费级产品。本文从生活场景的真实痛点切入,逐层拆解Mul…...
)
【JavaSE全面教学】Java集合框架下Day13(2026年)
写在前面:这是JavaSE系列的第13篇。上一篇讲了List家族,今天来讲Set和Map。HashMap是面试中问得最多的集合类,底层原理必须搞懂。建议收藏,反复看。 文章目录 一、Set集合:不可重复1.1 Set的特点1.2 HashSet1.3 Linked…...

告别日志脱敏烦恼:手把手教你用sensitive注解优雅保护用户隐私数据
优雅实现日志脱敏:基于注解的隐私数据保护实战指南 在金融、电商等强合规领域,用户隐私数据保护早已从"可选"变为"必选"。每次看到同事在代码中手动拼接"手机号:"user.getPhone().substring(0,3)"****&qu…...

【软考高级架构】案例题考前突击——分布式一致性在互联网金融平台的应用
案例分析题:分布式一致性在互联网金融平台的应用 案例背景 某互联网金融平台为了满足高并发、高可用的业务需求,采用了基于微服务和分布式架构的系统设计。平台核心业务包括账户余额管理、交易流水记录、资金划转等关键模块。 为提升系统性能,架构师引入了如下关键设计:…...

DWT-DCT-SVD水印实战:如何保护你的摄影作品版权?一个摄影师的数字水印方案
摄影师必备:用DWT-DCT-SVD技术为作品穿上隐形防弹衣 清晨的阳光透过窗帘缝隙洒进工作室,摄影师林默正在整理昨晚拍摄的一组城市夜景。这组照片耗费了他整整三周时间——等待完美天气、调试设备、后期修图。当他准备将作品上传到个人作品集网站时&#x…...

Ahk2Exe:3步实现AutoHotkey脚本到EXE的专业编译方案
Ahk2Exe:3步实现AutoHotkey脚本到EXE的专业编译方案 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe Ahk2Exe是AutoHotkey官方推出的脚本编译器&#x…...

探索未来Web交互:Unity与Vue的梦幻联动
探索未来Web交互:Unity与Vue的梦幻联动 【下载地址】Unity打包成WebGL与Vue交互Demo 本示例仓库演示了如何将Unity开发的游戏或应用打包成WebGL格式,并在基于Vue.js的前端应用中进行集成与交互。通过这个项目,开发者可以学习到Unity与现代Web…...

Hotkey Detective:重塑Windows键盘操作的透明化洞察
Hotkey Detective:重塑Windows键盘操作的透明化洞察 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾在…...

告别黑盒:手把手教你用VTK在QT中‘组装’并驱动SolidWorks导出的机械臂模型
从STL零件到可交互机械臂:VTKQT三维可视化开发实战 机械臂的数字化仿真一直是工业自动化与机器人教学中的核心课题。想象一下,当你从SolidWorks中导出一堆零散的STL文件,如何在代码中让它们"活"起来——每个关节都能独立旋转&#…...