【算法数据结构体系篇class06】:堆、大根堆、小根堆、优先队列
一、堆结构
1)堆结构就是用数组实现的完全二叉树结构
2)完全二叉树中如果每棵子树的最大值都在顶部就是大根堆
3)完全二叉树中如果每棵子树的最小值都在顶部就是小根堆
4)堆结构的heapInsert与heapify操作
5)堆结构的增大add和减少poll
6)优先级队列结构,就是堆结构
heapInsert:
入堆排序操作,从数组最后一个位置插入,然后再与其父节点(i-1)/2比较大小,大则交换上去,接着往其爷节点持续走..直到顶,或小于当前节点的父节点则停止,完成排序
heapify:
堆下沉排序操作 剔除元素后,需要将交换到根部的元素往下沉判断排序,如果大于左右节点就不用动,小于则与左右较大节点交换,并下沉继续判断,直到底部或者大于左右子节点
代码演示:
package class06;import java.util.Comparator;
import java.util.PriorityQueue;public class Heap {//大根堆 每个子树根节点比左右节点大public static class MyMaxHeap {private int[] heap;private int heapSize;private final int limit;public MyMaxHeap(int limit) {heap = new int[limit];heapSize = 0;this.limit = limit;}public boolean isEmpty() {return heapSize == 0;}public boolean isFull() {return limit == heapSize;}//入堆,同时保持堆的大根堆 有序public void push(int value) {if (isFull()) {throw new RuntimeException("堆已满,无法添加元素!");}//没满就赋值追加到数组后heap[heapSize] = value;//依次与该元素的父节点比较大小,大则交换两元素,然后接着往上走,直到顶或者不大于父节点,同时最后要把size+1heapInsert(heap, heapSize++);}//入堆操作,从数组最后一个位置插入,然后再与其父节点(i-1)/2比较大小,大则交换上去,接着往其爷节点持续走..直到顶,或小于当前节点的父节点则停止,完成排序private void heapInsert(int[] heap, int i) {//这个条件判断了两种情况,一个是大于父节点,一个是还没到顶节点(假如i来到顶部0 那么(i-1)/2也等0 为自己,是等于) 则继续循环。while (heap[i] > heap[(i - 1) / 2]) {swap(heap, i, (i - 1) / 2);i = (i - 1) / 2;}}//出堆,弹出最大值,顶部,然后保证当前堆仍有序 是大根堆public int pop() {if (isEmpty()) {throw new RuntimeException("堆已空,无法弹出元素!");}//弹出首元素,最大值int ans = heap[0];//然后把元素剔除两步 1.将首元素,与尾元素(heapSize是长度,尾元素是heapSize-1)交换,因为弹出操作,需要将heapSize 元素个数-1,两个操作只需要用--heapSize就能符合swap(heap, 0, --heapSize);//2.交换后表示将根节点元素剔除,然后需要确保现有堆的顺序heapify(heap, 0, heapSize);return ans;}//堆下沉排序操作 剔除元素后,需要将交换到根部的元素往下沉判断排序,如果大于左右节点就不用动,小于则与左右较大节点交换,并下沉继续判断,直到底部或者大于左右子节点private void heapify(int[] heap, int i, int heapSize) {//首先判断是否存在左子节点,左节点索引是i*2+1,不能超过heapSize-1尾索引,如果超过那肯定就到最后一个元素,右节点是比左节点大1 也更不会存在while (i * 2 + 1 < heapSize) {//此时确定有左节点,但需要判断是否有右节点i*2+2 如果有 并且大于左节点,那么左右节点较大值就是右节点,否则就是左节点int largest = i*2+2 < heapSize && heap[i*2+2]>heap[i*2+1]?i*2+2:i*2+1;//然后把较大的节点与父节点比较,谁大则重新赋值 largest最大值largest = heap[largest] > heap[i]?largest:i;if(largest == i) break; //如果判断后这个最大值位置就是父节点位置,相当于父节点都大于子节点,那么就不用交换,再下沉,此时已经完成排序,大的仍旧在前面,小的在下面,直接退出循环//子节点大于当前节点,那么与其较大的节点交换,交换完之后,当前节点i要来到较大节点largest位置 循环下沉swap(heap,i,largest);i = largest;}}private void swap(int[] heap, int i, int j) {int temp = heap[i];heap[i] = heap[j];heap[j] = temp;}}public static class RightMaxHeap {private int[] arr;private final int limit;private int size;public RightMaxHeap(int limit) {arr = new int[limit];this.limit = limit;size = 0;}public boolean isEmpty() {return size == 0;}public boolean isFull() {return size == limit;}public void push(int value) {if (size == limit) {throw new RuntimeException("heap is full");}arr[size++] = value;}public int pop() {int maxIndex = 0;for (int i = 1; i < size; i++) {if (arr[i] > arr[maxIndex]) {maxIndex = i;}}int ans = arr[maxIndex];arr[maxIndex] = arr[--size];return ans;}}//比较器用于排序public static class MyComparator implements Comparator<Integer>{@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1; //降序}}public static void main(String[] args) {// 大根堆 优先队列默认是小根堆,通过比较器降序排序实现大根堆PriorityQueue<Integer> heap = new PriorityQueue<>(new MyComparator());heap.add(5);heap.add(5);heap.add(5);heap.add(3);// 5 , 3System.out.println(heap.peek());heap.add(7);heap.add(0);heap.add(7);heap.add(0);heap.add(7);heap.add(0);System.out.println(heap.peek());while (!heap.isEmpty()) {System.out.println(heap.poll());}int value = 1000;int limit = 100;int testTimes = 1000000;for (int i = 0; i < testTimes; i++) {int curLimit = (int) (Math.random() * limit) + 1;MyMaxHeap my = new MyMaxHeap(curLimit);RightMaxHeap test = new RightMaxHeap(curLimit);int curOpTimes = (int) (Math.random() * limit);for (int j = 0; j < curOpTimes; j++) {if (my.isEmpty() != test.isEmpty()) {System.out.println("Oops!");}if (my.isFull() != test.isFull()) {System.out.println("Oops!");}if (my.isEmpty()) {int curValue = (int) (Math.random() * value);my.push(curValue);test.push(curValue);} else if (my.isFull()) {if (my.pop() != test.pop()) {System.out.println("Oops!");}} else {if (Math.random() < 0.5) {int curValue = (int) (Math.random() * value);my.push(curValue);test.push(curValue);} else {if (my.pop() != test.pop()) {System.out.println("Oops!");}}}}}System.out.println("finish!");}
}
二、堆排序,默认都是升序排序
1,先让整个数组都变成大根堆结构,建立堆的过程:
1)从上到下的方法,时间复杂度为O(N*logN)
2)从下到上的方法,时间复杂度为O(N)
2,把堆的最大值和堆末尾的值交换,然后减少堆的大小之后,再去调整堆,一直周而复始,时间复杂度为O(N*logN)
3,堆的大小减小成0之后,排序完成
手写堆结构来进行排序操作
代码演示:
package class06;import java.util.Arrays;
import java.util.PriorityQueue;public class HeapSort {/*** 堆排序 利用堆的heapInsert heapify操作实现* @param arr*/public static void heapSort(int[] arr){if(arr == null || arr.length < 2) return;//1.先使数组转换成一个大根堆,heapInsert heapify都可以 后者的时间复杂度更低,从下往上 时间复杂度O(N)int heapSize = arr.length;for(int i = arr.length-1;i>=0;i--){heapify(arr,i,heapSize);}//O(N*logN)
// for(int i = 0;i<arr.length;i++){
// heapInsert(arr,i);
// }//2、首位交换,把最大值放到尾部,因为排序我们按降序,最大值就是放到尾部swap(arr,0,--heapSize);//3.依次开始进行堆下沉操作 直到排完序// O(N*logN)while(heapSize > 0){ //O(N)heapify(arr,0,heapSize); //O(logN)swap(arr,0,--heapSize); //O(1)}}public static void heapInsert(int[] arr, int i){while ( arr[i] > arr[(i-1)/2]){swap(arr,i,(i-1)/2);i = (i-1)/2;}}public static void heapify(int[] arr, int i, int heapSize){int left = i*2+1;while(left < heapSize){int largest = left + 1 < heapSize && arr[left + 1] >arr[left]?left+1:left;largest = arr[largest] > arr[i] ? largest : i;if(largest == i) break;swap(arr,i,largest);i = largest;left = i*2+1;}}private static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}// for testpublic static void comparator(int[] arr) {Arrays.sort(arr);}// for testpublic static int[] generateRandomArray(int maxSize, int maxValue) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random()) - (int) (maxValue * Math.random());}return arr;}// for testpublic static int[] copyArray(int[] arr) {if (arr == null) {return null;}int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}// for testpublic static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null)) {return false;}if (arr1 == null && arr2 == null) {return true;}if (arr1.length != arr2.length) {return false;}for (int i = 0; i < arr1.length; i++) {if (arr1[i] != arr2[i]) {return false;}}return true;}// for testpublic static void printArray(int[] arr) {if (arr == null) {return;}for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}// for testpublic static void main(String[] args) {// 默认小根堆PriorityQueue<Integer> heap = new PriorityQueue<>();heap.add(6);heap.add(8);heap.add(0);heap.add(2);heap.add(9);heap.add(1);while (!heap.isEmpty()) {System.out.println(heap.poll());}int testTime = 500000;int maxSize = 100;int maxValue = 100;boolean succeed = true;for (int i = 0; i < testTime; i++) {int[] arr1 = generateRandomArray(maxSize, maxValue);int[] arr2 = copyArray(arr1);heapSort(arr1);comparator(arr2);if (!isEqual(arr1, arr2)) {succeed = false;break;}}System.out.println(succeed ? "Nice!" : "Fucking fucked!");int[] arr = generateRandomArray(maxSize, maxValue);printArray(arr);heapSort(arr);printArray(arr);}
}
三、限定条件下堆排序:假设每个元素移动的距离一定不超过k,并且k相对于数组长度来说是比较小的
题意:
已知一个几乎有序的数组。几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离一定不超过k,并且k相对于数组长度来说是比较小的。 请选择一个合适的排序策略,对这个数组进行排序。
思路:
小根堆排序、优先队列:题目中提到了一个,每个元素移动的距离一定不超过k,那么就说明,从第一个数开始,前k+1个数里面,存在一个数,是一定要排在0位置的,这样才能使得移动不超过k个, 比如一个数组最小是1,长度为8,k=5,最小1是需要排在索引0位置的,为了满足移动不超过5个位置,那么在arr[0-k]区间内必然有1,最远只能在rr[k],那么也是移动k为来到0 k-k=0 ,利用这个特性,用小根堆,先把前k个数[0,k-1]入堆,然后第二次开始,从[k,arr.length-1]入堆,入一次 就依次从头赋值给原数组,然后再出堆;比如前面例子,第一次肯定是把1赋值给arr[0],出堆,往后入堆,赋值arr[1],出堆..直到最后一个元素,最后可能堆还有元素,就依次赋值给后面的数组位置,依次出堆,完成堆排序
代码演示:(这里不手写堆结构,一般都是直接用PriorityQueue优先队列,默认小根堆排序,说是优先队列,其实也是堆结构实现的)
package class06;import java.util.Arrays;
import java.util.PriorityQueue;/**题意:* 已知一个几乎有序的数组。几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离一定不超过k,并且k相对于数组长度来说是比较小的。* 请选择一个合适的排序策略,对这个数组进行排序。** 思路:小根堆排序、优先队列:题目中提到了一个,每个元素移动的距离一定不超过k,那么就说明,从第一个数开始,前k+1个数里面,存在一个数,是一定要排在0位置的* 这样才能使得移动不超过k个, 比如一个数组最小是1,长度为8,k=5,最小1是需要排在索引0位置的,为了满足移动不超过5个位置,那么在arr[0-k]* 区间内必然有1,最远只能在rr[k],那么也是移动k为来到0 k-k=0 ,利用这个特性,用小根堆,先把前k个数[0,k-1]入堆,然后第二次开始,从[k,arr.length-1]* 入堆,入一次 就依次从头赋值给原数组,然后再出堆;比如前面例子,第一次肯定是把1赋值给arr[0],出堆,往后入堆,赋值arr[1],出堆..直到最后一个元素,* 最后可能堆还有元素,就依次赋值给后面的数组位置,依次出堆,完成堆排序*/
public class SortArrayDistanceLessK {public static void sortArrayDistanceLessK(int[] arr, int k){if(arr == null || arr.length <2) return;PriorityQueue<Integer> heap = new PriorityQueue<>();//技巧:把堆索引定义外面,定义for里面的话就没法给,后续的操作使用int index = 0;//1.首先我们把0,k-1的区间先入堆,下次开始入k时,就时要开始循环赋值、出堆,因为arr[k] 前面有k个数,//题目限定每个元素移动不超过k ,那么排在arr[0]的数,肯定就是再0,k区间内,所以再k入堆时,就可以出堆,其//最小值就是位于arr[0]//判断最小值是因为我们测试用例的k范围是随机的可能会大于数组长度for(;index < Math.min(arr.length-1,k);index++){heap.add(arr[index]);}//2.此时index = k ,开始往后遍历,index不超过数组长度 赋值,出堆//定义数组从0开始的下标 用于赋值int indexArr = 0;for(;index<arr.length;index++,indexArr++){heap.add(arr[index]);//出堆,赋值,出堆是因为该值已经赋值到数组了,就需要排除arr[indexArr] = heap.poll();}//3.此时遍历到最后,堆可能还有元素,需要依次再赋值到arr[indexArr]位置while(!heap.isEmpty()){arr[indexArr++] = heap.poll();}}// for testpublic static void comparator(int[] arr, int k) {Arrays.sort(arr);}// for testpublic static int[] randomArrayNoMoveMoreK(int maxSize, int maxValue, int K) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random()) - (int) (maxValue * Math.random());}// 先排个序Arrays.sort(arr);// 然后开始随意交换,但是保证每个数距离不超过K// swap[i] == true, 表示i位置已经参与过交换// swap[i] == false, 表示i位置没有参与过交换boolean[] isSwap = new boolean[arr.length];for (int i = 0; i < arr.length; i++) {int j = Math.min(i + (int) (Math.random() * (K + 1)), arr.length - 1);if (!isSwap[i] && !isSwap[j]) {isSwap[i] = true;isSwap[j] = true;int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}}return arr;}// for testpublic static int[] copyArray(int[] arr) {if (arr == null) {return null;}int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}// for testpublic static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null)) {return false;}if (arr1 == null && arr2 == null) {return true;}if (arr1.length != arr2.length) {return false;}for (int i = 0; i < arr1.length; i++) {if (arr1[i] != arr2[i]) {return false;}}return true;}// for testpublic static void printArray(int[] arr) {if (arr == null) {return;}for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}// for testpublic static void main(String[] args) {System.out.println("test begin");int testTime = 500000;int maxSize = 100;int maxValue = 100;boolean succeed = true;for (int i = 0; i < testTime; i++) {int k = (int) (Math.random() * maxSize) + 1;int[] arr = randomArrayNoMoveMoreK(maxSize, maxValue, k);int[] arr1 = copyArray(arr);int[] arr2 = copyArray(arr);sortArrayDistanceLessK(arr1, k);comparator(arr2, k);if (!isEqual(arr1, arr2)) {succeed = false;System.out.println("K : " + k);printArray(arr);printArray(arr1);printArray(arr2);break;}}System.out.println(succeed ? "Nice!" : "Fucking fucked!");}}
相关文章:

【算法数据结构体系篇class06】:堆、大根堆、小根堆、优先队列
一、堆结构1)堆结构就是用数组实现的完全二叉树结构2)完全二叉树中如果每棵子树的最大值都在顶部就是大根堆3)完全二叉树中如果每棵子树的最小值都在顶部就是小根堆4)堆结构的heapInsert与heapify操作5)堆结构的增大ad…...

试题 算法提高 最小字符串
资源限制内存限制:256.0MB C/C时间限制:2.0s Java时间限制:6.0s Python时间限制:10.0s问题描述给定一些字符串(只包含小写字母),要求将他们串起来构成一个字典序最小的字符串。输入格式第一行T,表示有T组数据。接下来T…...

已解决ImportError: cannot import name ‘featureextractor‘ from ‘radiomics‘
已解决from radiomics import featureextractor导包,抛出ImportError: cannot import name ‘featureextractor‘ from ‘radiomics‘异常的正确解决方法,亲测有效!!! 文章目录报错问题报错翻译报错原因解决方法联系博…...
乡村振兴研究:全网最全指标农村经济面板数据(2000-2021年)
数据来源:国家统计局 时间跨度:2000-2021年 区域范围:全国31省 指标说明: 部分样例数据: 行政区划代码地区年份经度纬度乡镇数(个)乡数(个)镇数(个)村民委员会数(个)乡村户数(万户)乡村人口(万人)乡村从业人员(万人…...
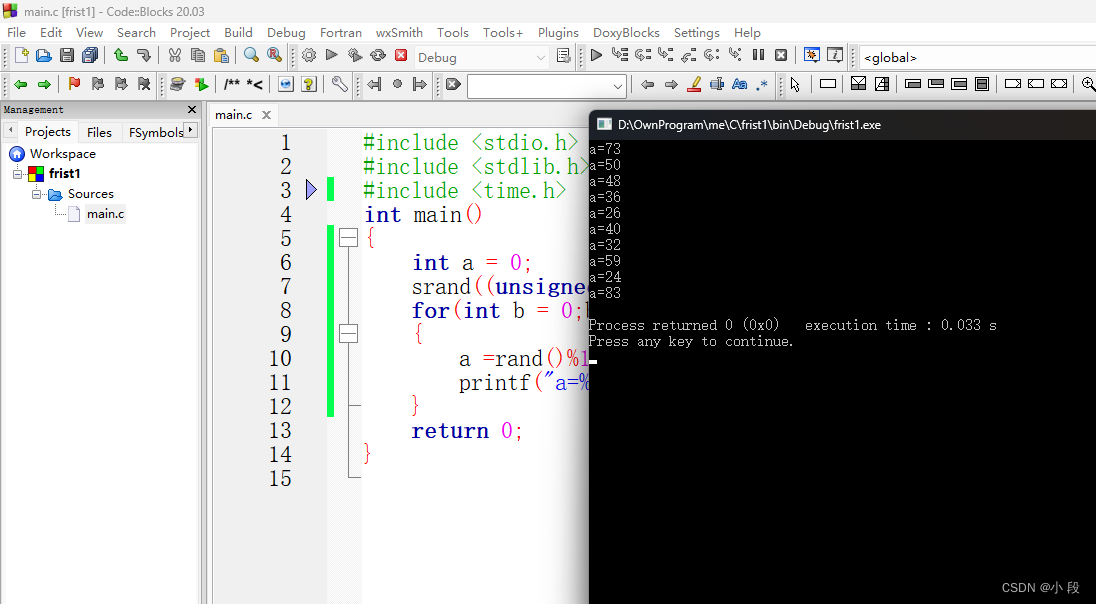
C语言中用rand()函数产生一随机数
在C语言中如何产生一个随机数呢?用rand()函数。 rand()函数在头文件:#include <stdio.h>中,函数原型:int rand(void);。rand()会返回一个范围在0到RAND_MAX(32767)之间的随机数(整数&…...

关于系统架构
1.系统架构分类: C/S架构 B/S架构 2.C/S架构 Client / Server(客户端 / 服务器) 特点:需要安装特定的客户端软件。 C/S架构的系统优点和缺点: 优点: 1)速度快(软件中数据大部分都是集成到客户端当中,很少量的数据从服…...

LeetCode 1237. 找出给定方程的正整数解
原题链接 难度:middle\color{orange}{middle}middle 2023/2/18 每日一题 题目描述 给你一个函数 f(x,y)f(x, y)f(x,y) 和一个目标结果 zzz,函数公式未知,请你计算方程 f(x,y)zf(x,y) zf(x,y)z 所有可能的正整数 数对 xxx 和 yyy。满足条件…...
【ArcGIS Pro二次开发】(5):UI管理_自定义控件的位置
新增的自定义控件一般放在默认的【加载项】选项卡下,但是根据需求,我们可能需要将控件放在新的自定义选项卡下,在自定义选项卡添加系统自带的控件,将自定义的按钮等控件放在右键菜单栏里以方便使用,等等。 下面就以一…...

学习OpenGL图形2D/3D编程
环境:WindowsVisual Studio 2019最流行的几个库:GLUT,SDL,SFML和GLFWGLFWGLAD库查看显卡OPENGL支持情况VS2019glfwgladopenGL3.3顶点着色器片段着色器VAO-VBO-(EBO)->渲染VAO-VBO-EBO->texture纹理矩阵matrix对图形transfor…...

2023美赛思路 | A题时间序列预测任务的模型选择总结
2023美赛思路 | A题时间序列预测任务的模型选择总结 目录 2023美赛思路 | A题时间序列预测任务的模型选择总结基本介绍数据描述任务介绍时序模型基本介绍 这道题分析植被就行,主要涉及不同植被间的相互作用,有竞争有相互促进,我查了下“植物科学数据中心”和“中国迁地保护植…...
PHP教材管理系统设计(源代码+毕业论文)
【P003】PHP教材管理系统设计(源代码论文) 设计方案 本系统采用B/S结构,所有的程序及数据都放在服务器上,终端在取得相应的权限后使用Web页面浏览,录入,修改等功能。在语言方面使用PHP语言,在…...
nps内网穿透工具
一、准备一台有公网ip的服务器 https://github.com/ehang-io/nps/releases 在这个地址下载服务端的安装包,centos的下载这个 上传到服务器上。 二、然后解压,安装,启动 [rootadministrator ~]# tar xzvf linux_amd64_server.tar.gz [roo…...

webpack打包时的热模块替代配置以及source-map
1.HMR 在devServer当中添加hot:true 热模块化功能 含义:当其中有一个文件发生变化的时候,那么就会被重新打包一次,极大的提高了构建速度 A.样式文件:可以使用HMR功能,因为在style-loader当中实现了 B.js文件:默认不能使用HMR功能…...
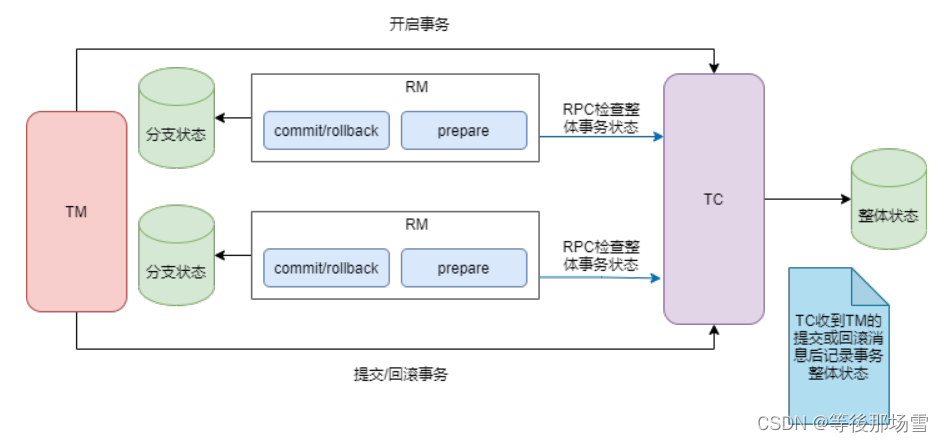
Seata架构篇 - TCC模式
TCC 模式 概述 TCC 是分布式事务中的两阶段提交协议,它的全称为 Try-Confirm-Cancel,即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel)。Try:对业务资源的检查并…...
前端最全面试题整理
前端基础 一、 HTTP/HTML/浏览器 1、说一下 http 和 https https 的 SSL 加密是在传输层实现的。 (1) http 和 https 的基本概念 http: 超文本传输协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(T…...
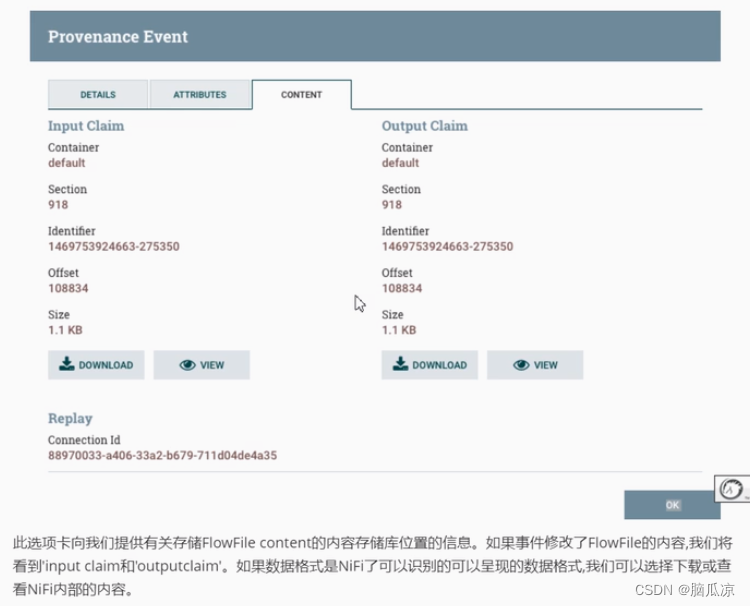
大数据之-Nifi-监控nifi数据流信息_监控数据来源_bub轻松复现---大数据之Nifi工作笔记0011
通过数据流功能可以轻松复现,数据的流向在某个时间点数据是怎么流动的,出现了什么问题,太强大了.. 真的是,可以看到通过右键,处理器,打开view data province就可以看到, 上面是处理器处理数据的详细信息 点击左侧的详情图标可以查看详情信息,details是这个事件处理的内容详情,…...

CUDA编程接口
编程接口 文章目录编程接口3.1利用NVCC编译3.1.1编译流程3.1.1.1 离线编译3.1.1.2 即时编译3.1.2 Binary 兼容性注意:仅桌面支持二进制兼容性。 Tegra 不支持它。 此外,不支持桌面和 Tegra 之间的二进制兼容性。3.1.3 PTX 兼容性3.1.4 应用程序兼容性3.1…...

惠普打印机使用
https://support.hp.com/cn-zh/product/hp-officejet-4500-all-in-one-printer-series-g510/3919445/document/c02076511HP 打印机 - 无法打印校准页本文适用于 HP 喷墨打印机。安装新墨盒后,打印机无法按预期打印校准页。步骤 1:确保打印机可以开始打印…...

Ubuntu升级cmake
目录 1、下载cmake安装包 2、开始安装 3、查看cmake版本 参考链接: https://blog.csdn.net/qq_27350133/article/details/121994229 1、下载cmake安装包 cmake安装包下载:download | cmake 我们根据自身需求下载所需版本的cmake安装包,这…...

CCNP350-401学习笔记(101-150题)
101、Refer to the exhibit SwitchC connects HR and Sales to the Core switch However, business needs require that no traffic from the Finance VLAN traverse this switch. Which command meets this requirement? A. SwitchC(config)#vtp pruning B. SwitchC(config)#…...

年薪50W+!AI产品经理爆火,0经验也能入行?3类人才需求+4大陪跑方案助你拿下高薪offer!
今年,无论是一些头部厂商,中小厂商,从海外到国内,大中小公司都在积极拥抱讨论AI和拥抱AI。AI 相关的人才缺口已达 500 万,其中AI产品经理需求旺盛,薪资中位数再创新高,36k/月。如果是在头部公司…...

GD32F407时钟树详解:168MHz系统时钟如何驱动你的ADC、SPI和CAN?
GD32F407时钟树深度解析:从PLL到外设的168MHz信号之旅 在嵌入式系统设计中,时钟如同芯片的"心跳",精确控制着每个外设的运作节奏。GD32F407这颗基于Cortex-M4内核的MCU,其168MHz的系统时钟如何精准分配到ADC、SPI、CAN等…...

ARM架构TLB失效指令VALE1IS/VALE1ISNXS详解
1. ARM TLB失效指令基础解析在ARMv8/v9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,缓存了虚拟地址到物理地址的转换结果。当操作系统修改页表后,必须通过TLB失效…...

收藏!AI时代程序员是消失还是逆袭?小白程序员必看大模型逆袭指南
收藏!AI时代程序员是消失还是逆袭?小白程序员必看大模型逆袭指南 文章探讨了AI对程序员行业的影响,指出AI抢走了程序员一半的饭碗,但也为另一半人打开了高阶职场的大门。初级岗位因AI工具普及而面临失业风险,但高级技术…...

systemverilog学习
1.数据类型 1.1logic类型和双状态数据类型 logic类型:在实际电路中,信号只有0和1两种状态,但是在电路设计中,能有四种状态,0、1、Z和X,X代表未知态,当给它两个驱动时(一边给0&#x…...

基于GPT-4与Neo4j构建智能推荐聊天机器人:从原理到实践
1. 项目概述:一个能“读懂”并“修改”数据库的智能聊天机器人 最近在捣鼓一个挺有意思的开源项目,叫 NeoGPT-Recommender 。简单来说,它不是一个普通的聊天机器人,而是一个能真正理解你、并基于你的喜好动态更新知识库的智能助…...

构建个人技能库:高效沉淀与复用代码片段的工程实践
1. 项目概述:一个技能库的诞生与价值最近在整理自己的技术工具箱时,我意识到一个问题:很多实用的代码片段、脚本和解决方案,都散落在不同的项目、笔记甚至聊天记录里。当需要快速解决一个特定问题时,要么得花时间回忆&…...

基于Electron的本地字幕翻译工具开发全解析
1. 项目概述:一个本地化的字幕翻译利器最近在折腾一些海外纪录片和课程视频,发现一个挺普遍的需求:手头有外文字幕文件(比如SRT、ASS),想把它翻译成中文,但又不希望把视频或字幕上传到任何在线服…...

DevOps 与 CI/CD 实战心得:静态网站的自动化部署
背景 自己做了一个独立站项目,访问地址是:https://www.wslwf.com 通过这次实践,对 DevOps 和 CI/CD 在静态网站场景中的应用有了更深的理解。 核心体会 1. 工具链选择至关重要 这次项目使用了 GitHub Actions GitHub Pages,这个组…...

LangChain集成MCP协议:构建模块化AI应用的新范式
1. 项目概述:当LangChain遇见MCP,构建下一代AI应用的新范式如果你最近在捣鼓LangChain,想给AI应用加点“料”,比如让它能实时查询数据库、调用外部API,甚至控制智能家居,那你大概率会遇到一个核心痛点&…...