HA3 SQL样本实验:一种混合计算查询的全新样本解决方案
作者:陆唯一(芜霜)
HA3(对外开源代号:Havenask )是阿里智能引擎团队自研的大规模分布式检索系统,广泛应用于阿里内部的搜索业务,是十多年来阿里在电商领域积累下来的核心竞争力产品。Ha3 SQL 是在原有Ha3引擎基础上,新增的SQL查询功能,引擎内置了SQL形式的的查询语法,允许用户通过写SQL语句来构造引擎查询。
一、概述
在搜推广这个业务场景内,样本构建是特征数据链路的一个重要环节,而且从工作流程上来看,做样本也通常是算法同学开始一个新实验的第一步。在这个环节的技术选型上,考虑到功能性、稳定性和上游数据的所在,大部分团队最终的选择都是MaxCompute。MaxCompute是一流的离线数据处理平台,但是在和算法同学的沟通交流中,我们频繁听到这些使用上的困扰:
-
样本存储占用了太多的MaxCompute空间;
-
样本构建任务会消耗非常多的计算资源,集群常年被样本任务耗尽资源;
-
新增特征、调整样本分布等实验的构建样本周期很长,时间成本高。
我们分析了这些困扰背后的本质原因,针对这里的关键点提供了一套新的样本解决方案:HA3 SQL样本实验功能。
通过在『构建样本-训练』这个流程中插入一个由HA3 SQL提供的查询层,非常精准地解决了上面列举的几个主要困扰点。目前已有多个算法团队接入这套样本解决方案并从中获得数据链路的全方面优化。
在本文中,我们会给出关于样本构建问题的分析与思考,介绍HA3 SQL样本实验的方案架构和里面值得和大家分享的一些技术细节,同时还会给出一些已经接入场景的性能报告和接入前后的成本对比。最后是我们在这个功能研发过程中的一些经验教训和未来工作展望。
二、样本场景问题介绍与分析
2.1 样本的现状
先简单介绍一下,在搜推广这个场景,样本通常长什么样,是怎么构建出来的。以最常见的CTR样本(曝光-点击样本)为例,参考谷歌WDL论文中的例子,一条典型的样本记录是这个样子的:
| pv_id | app_id | user_id | click | app_title | app_cate | app_download_count | user_age | user_sex |
| xxx_xx | 1234 | 4321 | 1 | | social | 3000 | 20 | 0 |
pv_id是某次请求对应的uuid,这条样本表达的含义就是:某次请求返回的app被用户在手机上点击了,在点击发生的当时,这个app的名字、下载量等属性是某某某,这个用户的年龄、性别等属性是某某某。一份样本就由上亿条这样的记录构成,这个数据会被训练时的机器学习模型消费,用于学习点击这个行为和各个特征之间的相关性。
这种样本常见的构建方式是这样的:pv_id app_id user_id click这些属性来源于用户行为埋点日志,记录了用户的行为发生时的一些关键id,算法同学会建立一系列上下游任务把这部分数据导入到MaxCompute上变成一张表示用户行为的分区表,同时还会准备若干以pv_id/app_id/user_id之类的字段为主键的属性表,通常称之为维表,最后以用户行为这张表作为起始,用上面的各个id把这些属性表join起来,最后再按训练平台的要求做一些格式上的处理,就生成了最终的样本表。
以SQL伪代码表示,关键步骤基本就是这样一段逻辑 :
select pv_id, app_id, user_id, timestamp, click, download
from clean_behaviour_table
left outer join app_profile_table
on clean_behaviour_table.app_id = app_profile_table.app_id
left outer join user_profile_table
on clean_behaviour_table.user_id = user_profile_table.user_id目前大部分的训练平台对于MaxCompute样本的支持基本都局限于单个MaxCompute表的遍历读取,所以算法同学需要把上面的这段sql在MaxCompute上执行一边,把结果写入到另外一张结果表里作为最终的样本。
与此同时,算法同学平时在样本方面的实验迭代主要是在行列两个维度进行的:
-
行级别的迭代实验是说在串起样本的行为流上做实验变更,比如变更负例的采样比例、筛选不同场景的样本;
-
列级别的迭代实验主要是新增各类不同维度的特征,比如多一张app的属性表或者在原有表上加一些字段。
并且因为上面讲到的训练平台的限制,算法基本需要为每一个这样的实验加一个类似上面伪代码的MaxCompute任务,另外产出一份样本表。
这套生产流程对应到公开业界概念的话,主要是feature store系统里面的离线批数据处理流程,MaxCompute对应的通常是Hive/Spark这样的系统,有兴趣了解的可以自行查阅。
2.2 主要矛盾分析
从上面描述的现状里面,可以提炼出样本这类任务的两个关键属性:
-
样本表从构建逻辑上看,是一个非常典型的星状模型,行为流表就是事实表,其它表是维表,同时因为训练平台的限制,样本被要求对这个星状模型做了完整的物化展开;
-
样本实验具体到构建逻辑其实就是在事实表和维表上的增减变化,和完整的构建SQL比,每次实验的变更通常局限在一两张表上。
依次来看,在阿里电商领域这个场景里,星状模型完全展开这个点带来了三个方面的影响:
-
单个样本任务的复杂、消耗资源大。因为在集团的很多场景,一天下来的样本条数是上亿甚至几十亿的,同时各个维表的维度也不小,商品表本来就是亿级维度的,用户-商品、用户-类目之类的交叉特征表更是能上千亿。样本任务通常至少会join七八张这样的表,这种级别的任务对于MaxCompute这样的离线计算平台来说,最基础的做法就是一轮轮的sort merge join,做完一个join,再根据下面一个join的key重新shuffle,这个是极其消耗资源的,而且对于规模到一定程度的场景,这个默认实现甚至根本跑不出来,需要用hash clutser、distributed mapjoin之类的方法来做优化。甚至是在MaxCompute之上另外再引入一层kv性质的外部服务,来加速这个join,过去几年里面内部的算法平台做过类似原理的工作。
-
存储冗余:对于部分维表来说,因为被行为表这个大表join了,维表中的一行可能在最终样本表中重复几十万次,你可以想象一下像iphone这种热门商品会在多少样本的目标商品和行为序列中存在,而又有多少iphone的商品侧特征完全被冗余存储了。我们曾经统计过,在主搜的样本中,各种行为序列的商品属性占了数据空间的2/3。完整的物化展开最终带来的结果就是头部场景随便一份ttl是30天的样本就能直接占掉几个PB的MaxCompute存储空间。
-
增改数据需要重刷整张表:因为MaxCompute本身没有修改已有分区表某些列的功能,如果需要订正数据或者加一些特征,唯一的选择是重新跑一遍,在这个过程中,其它无关字段也会被读取、再完整写入一遍。而算法的实验需求又意味着,上面描述的巨量计算和存储消耗,要直接再上一个数量级了,想要做多少个实验,就要把完整地再跑多少个样本任务,虽然这些任务里面可能两两之间只是多join少join了一个表的区别。理解了这两点,就能充分明白为什么样本任务堪称MaxCompute的资源杀手。
2.3 解决方案
从场景抽离出来,如果我们用数据库领域的概念来描述一下样本的问题,那MaxCompute样本的问题本质可以抽象成:多个复杂但相似度很高的星状模型视图被强制物化展开带来的计算、存储资源问题。
抽象成这个问题后我们的解决思路也就非常明确了,在数据处理层和训练层之间再加入一层查询层,把部分计算逻辑延迟到训练时在查询层进行,让实验样本间逻辑上重复的部分变成查询阶段的重复查询,计算层只对部分适合计算平台处理的逻辑和真正增量的数据进行处理,这样可以在资源和效率两个方面逼近最优。
可以思考两个行列实验的典型场景:调整负样本采样比例和新增特征表。
调整负样本是指对样本中的负例进行采样,因为有些场景的负例可能太多了对训练模型没有帮助。在之前的模式里面,这种实验只能通过产出多份事实表,再构建多份样本表来进行。
如果系统具备sql化查询的能力,我们可以只保留一张有完整负例的事实表,通过查询sql中的条件语句直接过滤掉一些负例,过滤后的记录再去join各种维表,这样做不同比例的实验只是调整一个sql参数的事情,不需要反复生成样本,直接起多个配置不同的训练任务即可。

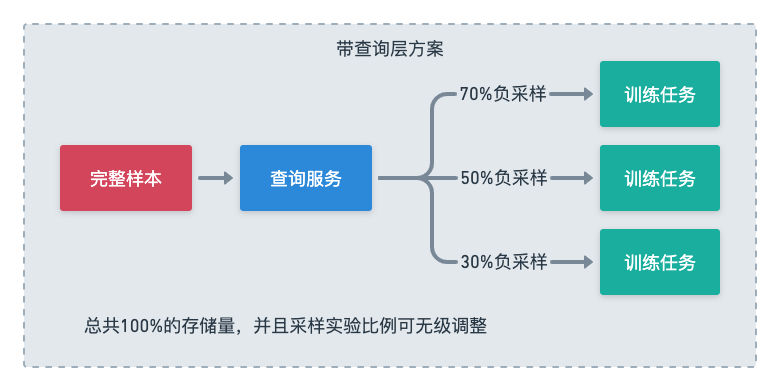
新增特征表在传统模式下也是必须新生成样本表,这意味着整个样本表数据的重写,而在有sql化查询能力的系统里面,如同在星状模型在传统数据库里的处理方式一样,我们只需要把这个新特征表的数据准备好,就能在查询时直接join上,完全不需要对之前的事实表和维表进行变更。
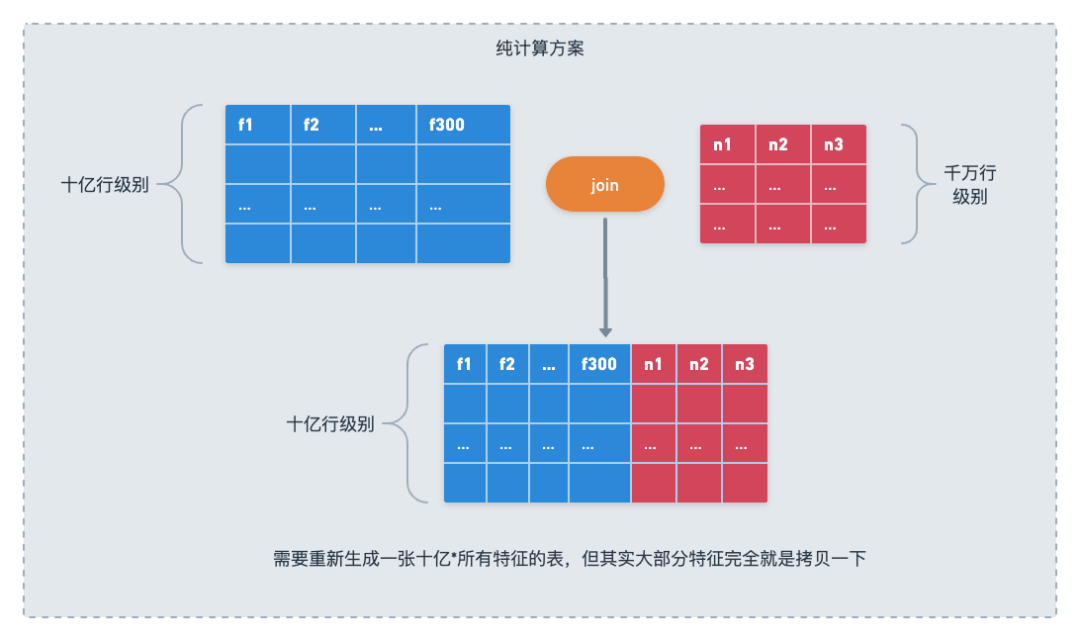

我们把这整个系统称为混合计算查询系统(Hybrid Computation Query System),区别于之前完全通过计算层生成样本的系统。
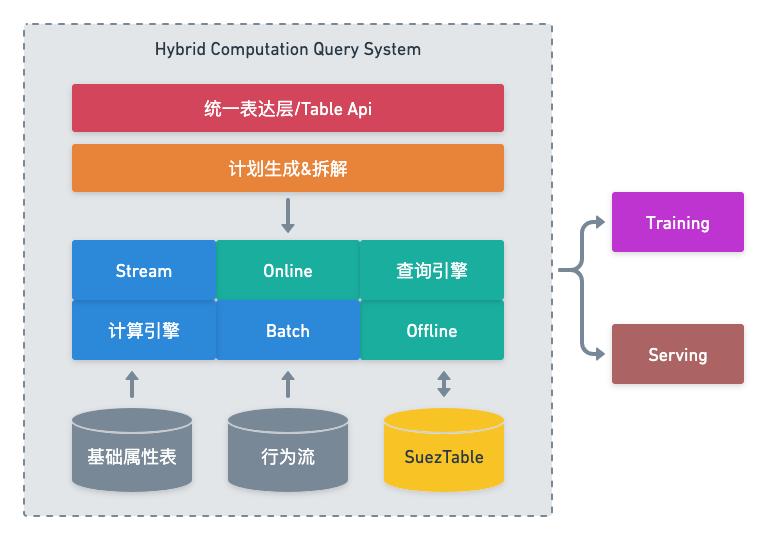
三、系统架构
3.1 查询层技术选型
确定了思路后,还需要进行技术选型,从样本这个场景来看,我们需要一个怎样的查询层呢?我们总结下来主要是以下几个关键点:
支持全功能的SQL:如上所说,样本本身完整的构建过程是适合用一段或多段SQL化的逻辑来描述的,传统的MaxCompute批样本构建本身就是用具体的MaxCompute SQL来描述了样本的构建逻辑,查询层同样支持全功能的SQL会有利于我们灵活地将适合的计算转移到查询层进行,同时也能让这个过程或者说内部逻辑更容易被用户(算法同学)所理解。
健壮的索引能力:想要把join转移到查询阶段来做的话,维表是一定需要预先建好索引的,查询层一定要有健壮、稳定的索引能力,并且有成熟、快速的构建流程。
对读写超高吞吐的支持,毫秒级别延迟:样本在训练读取过程中会实打实地scan完整的事实表,再join多个维表。而且不像olap性质的任务会后接聚合函数,训练是需要一整行的所有数据的,这里面的整体吞吐量在大规模的场景甚至会到几十GB/s这个量级。同时训练端本身的数据队列通常比较小,为了不阻塞训练,单次查询的latency也需要保持在毫秒级别。
原生的计算存储分离:无论样本的逻辑构建过程最终被拆成了哪些物理表和对应的组合逻辑,多份样本及每份样本多天的存储是不可能在查询集群的内存或者本地磁盘内放下的,客观上就要求查询系统能原生支持计算存储分离。与之同时产生的隐含需求是查询层需要有丰富灵活的cache机制来降低对存储层的压力并满足训练端的吞吐要求。
实时数据的支持:
-
一方面来说,odl(online deep learning)样本在样本实验上遇到的问题本质上和批样本是一致的,只不过一来odl样本不会保存很长时间,存储的问题不会很大,二来很长一段时间里面odl样本的搭建难度明显还是更高的,很多场景无力维护实验样本。而如果查询层本身支持实时数据源作为一种表的源,其实odl样本也是完全可以进行各种行列实验的。
-
另一方面,特征维表其实是有很强的实时性需求的,很多特征是和事件发生的时间相关的,之前只是因为MaxCompute上没法做这种维表,所以一直通过近似模拟或者埋点的方式来生成这部分特征,而如果查询层本身支持类似时序数据库的数据存储和读取,这部分特征其实是完全可以在离线生成的。
经过对查询层需求的分析和各种实测调研,最终我们决定用ha3 sql来做为我们样本实验方案的查询层。
ha3 sql的底层组件从支撑集团搜索的ha3引擎(havenask,已开源)发展而来,其核心组件indexlib上对上面列举的后四个关注点能很好地支持而且久经考验。而ha3 sql本身则是将传统的query表达式替换成了自定义的ha3 sql方言,样本场景的任务核心难点在于规模和多表连续join这个性质,构建逻辑本身所需的sql表达不复杂,目前的ha3 sql完全可以胜任。
同时ha3 sql也是AIOS体系内的项目,我们对其有完全的掌控能力,无论是问题的排查还是功能的扩展,都可以做到逻辑或者意愿的极限。
3.2 产品功能形态
查询层的runtime选型确定还没有完,关于如何把这个思路变成真正可用的产品功能,我们还需要回答一系列问题:
-
该如何描述样本的构建逻辑?用户在哪里描述这个逻辑?
-
在何时,如何将样本构建所依赖的MaxCompute表导入到ha3系统?
-
训练平台如何和这个新的查询层对接?
这块我们的整体思路是:用一套和上面的样本构建伪代码比较接近的DSL来让用户描述样本逻辑,通过这段DSL,我们既能获得依赖的MaxCompute表的信息,从而能创建周期性的ETL任务来导入ha3,同时我们也能根据DSL去生成最终训练查询样本时所需要的那段ha3 sql。
DSL部分我们最终的技术选型是RTP Table Api(一套之前用于构建在线特征的python sdk,接口设计主要参考了flink的Table Api,下文沿用Table Api的名字),具体例子和技术细节会在下一个章节详细阐述。从功能流程上看,整个系统的流程架构如下:

四、技术细节&优化工作
4.1 DSL模块
关于DSL本身的设计,我们选择了对Table Api做了一些扩展来作为样本构建得DSL,描述出来的样本构建逻辑大致如下:
from turing_script.sdk.itable import ITable as Table
from turing_script.biz_plugin.default_modules.base_sample_module import BaseSampleModuleclass SampleDemo(BaseSampleModule):def build(self, table_env) -> Table:##获取基础样本表base_sample = table_env.get_table('odps_project.base_sample')#需要join的维表,指明pk_name和需要的字段video_rtp_feature = table_env.get_table("odps_project.video_rtp_feature", pk_name = "video_id") \.select("video_id, gmv_score, video_pageview")#需要join的维表可支持多张author_feature = table_env.get_table("odps_project.mainse_vs_author_feature", pk_name = "author_id")#三张表按条件join,字段类型需一致,如字段名相同,可用_right_前缀来区分sample_exp = base_sample.left_outer_join(video_rtp_feature, 'int64(video_id)=_right_video_id') \.left_outer_join(author_feature, 'video_authorid=author_id') \.filter("reserverd_rand_key > 0.5")return sample_exp可以看到上面的样例代码本身也是一个和sql可以近似映射的过程,事实上Table Api和ha3 sql算是同根生的关系,底层复用了很多组件,比如iquan、calcite。而之所以选择基于Table Api改造来作为样本实验本身的DSL,主要是出于下面的考虑:
-
构建样本和在线RTP serving时构建输入其实是特征的一体两面,长期来看我们的目标是统一在线和离线的特征构建表达,所以我们倾向于用和RTP serving阶段构建相同的DSL。
-
因为涉及到调度、导入等逻辑,样本实验的DSL其实相当于融合了一部分DDL和DML的逻辑,如果通过ha3 sql来描述需要扩展部分sql语法,这个工作量会显著增大,而且有些逻辑和关系代数的映射并不直接,会影响我们在探索阶段的开发效率,也可能会给ha3 sql加上一些不必要的包袱。相对来说sdk式的接口拓展sql之外的功能和做接口兼容都会更容易一些,这一点在上面介绍的get_table接口性质里面体现地最为明显。
回到DSL本身,核心接口主要是两部分:
-
get_table是对原Table Api中scanregister_table两个接口的替换,和在线纯粹的查询不同,在样本场景我们需要让用户另外提供一些索引、配置之类的DDL性质信息,我们选择再这个接口中通过pk_name之类的参数来指定;
-
select filter join等常用的sql语义接口,这部分接口的含义和语法与原Table Api中完全一致,基本可以覆盖构建样本所需的sql动作。
在接口之下,我们实现了下列功能:
-
依赖表的分析推导,生成对应的ha3索引表配置;
-
自动去除冗余字段,缺失字段提示,得益于共享了iquan、calcite这样的基础组件,这部分能力基本是直接从底层享受到的;
-
查询用的ha3 sql自动生成。
4.2 索引表设计
另一个需要小心设计的地方是各个MaxCompute表对应的查询系统索引表配置,ha3底层的索引系统indexlib提供了非常多的索引类型和很多细致的参数配置——甚至可以说有点过于细致了,所以这层概念不宜直接暴露给用户,我们需要针对样本场景的需求,寻找合适的索引表配置,并将其与用户可以理解的DSL层面的一些概念挂钩。
✪ 4.2.1 事实表
样本场景的事实表一般有两种典型的例子,一种就是纯粹的行为流表,上面只有一些外键id和行为label,字段比较少;另外一种就是其它已经构建好的样本,用户期望基于这个基础样本另外join一些特征来做实验,这类表除了前一种的所有字段外,还包含大量已经生成好的特征,字段比较多,表的规模也比较大。
同时事实表在样本场景的使用方式就是全表遍历,不同实验里面可能会分别只需要一部分字段,本身并不会被其他表join。这个特性结合了上面样本作为事实表时数据规模较大的特点决定了事实表适合用列存表的形式来存储。一方面可以按列读取减少大量的seek,另一方面列存格式有利于压缩,可以降低样本类事实表的存储大小。所以最终我们选择把事实表配置成一张AliOrc格式的表,这也是通过indexlib支持的。
✪ 4.2.2 维表
维表的需求相对更加明确,样本场景的维表一定是索引即主键的,否则同样一条记录就join出多个结果了。维表是被join的角色,需要有索引提供快速检索能力,所以适合带索引的行存表来存储。又因为在样本场景里面,维表基本都是单字段或者双字段主键。所以我们选用了indexlib的kv和kkv索引表作为维表的存储格式。分别提供了按单主键和双主键去重和检索的功能。
4.3 调度系统
每天样本的导入流程涉及到多个阶段的动作,首先是当MaxCompute上对应的源表产出后,需要启动一个任务做ETL性质的工作,然后等待后续的ha3表构建、集群切换等流程的完成,而只有当一份样本依赖的所有表都已导入以后,我们才能将完整查询的ha3 sql写入meta系统。在表多的时候这个依赖流程还是比较复杂的,需要一个调度系统来辅助完成。
由于MaxCompute本身的任务调度是在DataWorks系统上的,同时算法同学对DataWorks的工作流程和补数据等操作都比较熟悉,所以我们决定把这部分调度依然基于DataWorks来实现。
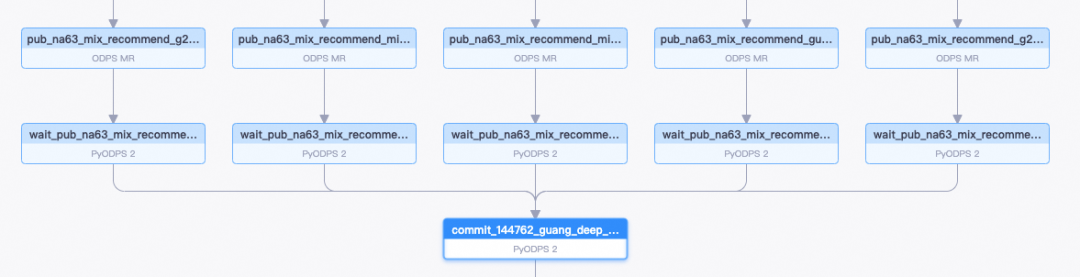
我们拆分了三种细粒度的调度任务:sink、wait、commit。
sink节点依赖MaxCompute的源表产出节点调度,启动数据导出任务;wait节点依赖sink节点调度,等待build和切换完成,sink和wait之所以拆分成两个节点,是让wait节点在超时、异常等情况下可以单独重跑,避免重复导入数据;commit依赖该样本任务所有表的wait节点,等所有表都切换完成后,重新执行一遍DSL逻辑,替换其中的表名为当天具体产出的分区表名,产出完整查询用sql写入meta系统。
我们接入了DataWorks的OpenApi系统,通过接口直接往各个团队的project里面注册了上面这些节点,用户只需要用上面的DSL描述好样本构建过程后这些节点都会自动创建出来。
一个复杂一点的样本调度实例如下:
4.4 集群部署和管理
对外我们给用户暴露的是类似数据库的DB概念,同一个DB内表都是可见的,如果多个样本依赖了相同的表,这部分表不会重复创建导入,而是会共用。这个也为后续潜在的跨团队共享特征、label等行为预留了空间。
目前我们搭建了全国不同地区机房的公共集群,根据算法团队project的所属机房来决定使用哪个公共集群。在导入链路中,MaxCompute集群、中转swift集群(类似kafka)、build集群、盘古集群是被保证在同一个地区的,避免出现跨地区长传带宽,而查询链路中,默认配置下训练集群会和DB集群、盘古集群完全在同一个机房,可以完全规避同城跨机房带宽,从而降低成本。
这部分整体上对用户都是完全透明的,用户只需要最开始根据自己MaxCompute机房的所在选择一下合适的DB即可。
但是在我们目前的集群管理运维工作中,这种模式目前也已发现了一些问题:
业务隔离性:因为共用了集群,一方面业务团队之间就有互相影响的风险,比如某天一个团队导入过多的表就可能会卡住其它团队的表切换,或者挤占资源。另一方面这个对我们的服务计费造成了很大的困扰,说不清一个集群的资源各个业务分别用了多少。
单集群规模过大:由于混用集群,而且各个团队MaxCompute的机房分布也是不均匀的,部分集群上面表的规模已经偏大,资源没法跟着业务需要线性扩展是一个问题,更大的问题在于因为我们基于的ha3、运维平台这套体系总体上之前还是围绕在线集群设计的,不会存在像样本这个场景单个集群成百上千张表的情况,所以我们在运维过程中触碰到了一系列木桶的短板,遇到过切换严重变慢甚至服务不可用的问题,虽然通过各种手段短期解决了,但是单集群规模的风险始终是达摩克利斯之剑。
所以这部分我们接下来的一个改造方向就是拆小集群,提供按团队、任务粒度的集群管理模式,从而规避上述问题。
4.5 训练平台对接
我们同时还在模型训练平台里做了HA3 SQL样本的适配工作,训练端最终拿到的每个分区的查询SQL大致是这样的:
SELECT *
FROM (SELECT *FROM (SELECT *FROM mainse_video_ha3_sample_ds_20221123/*+ SCAN_ATTR(batchSize='1', partitionIds='0', localLimit='100')*/) AS t0WHERE pv = 1 AND content_type = 'video') AS t1
INNER JOIN (SELECT pv_id, item_id, label, cartFROM mainse_video_click_to_pay_backbone_v2_ds_20221123) AS t2 ON t1.pv_id = t2.pv_id AND t1.item_id = t2.item_id对于一次训练来说,不同分区的样本。可能我们的sql语句会有所不同。比如从某天开始,一个字段从维表转移到事实表里面了,那么从这个分区开始的sql会有所变化,但是这个其实也是对训练端透明的,训练端只需要拿着sql去查询即可。
而对于一个分区的样本,一方面考虑到引擎服务内存压力,一方面为了对数据做shuffle,我们一般会分为256列,查询的时候通过SCAN_ATTR这个hint参数指定某一列,并且指点一个起始点和limit,相当于将所有数据划分成了许多个很小的分片。
具体到数据读取的实现,我们是通过以下几个op的串接实现的:
GenStreamSqlOp:根据样本名称与分区列表从特征中心api获取每天的meta信息,比如doc count、每天的sql语句模板,然后划分成许多小的字符串,每个字符串描述一个分片信息,譬如part_id, start_row等;
WorkQueueOp:一个全局的队列,所有的worker训练的时候都是从这个全局唯一的queue中取下一次要读取的样本分片,把GenStreamSqlOp的结果往queue里放,每次save checkpoint的时候,会把queue的一些消费信息记录进去,从而实现正常的训练failover;
SqlReadUpToOp:从queue中拿出来的分片,根据对应分区信息还原成一条完整sql,然后通过op中的流式客户端从远程ha3获取结果。由于离线训练环境与在线环境编译环境有所不同,我们这边对在线的结果做了一次封装,以tensor的形式返回防止出现兼容性的问题,也方便后续后端服务升级。
4.6 性能优化
✪ 4.6.1 ETL
数据导入的效率是我们关注的一个重点,因为样本实验功能的基本思路是把样本构建的部分逻辑替换到了查询,这部分MaxCompute任务就是可以省下来的,与之对应新增的是若干表的ETL任务,那么这两个任务之间速度的差异就是用户使用平台功能的第一个感受细节,我们认为需要在这个环节给用户一个印象深刻的对比。
传统的MaxCompute数据导出任务基本都是通过MaxCompute tunnel功能实现的,我们在使用过程中注意到两个比较主要的问题:
-
tunnel功能是要MaxCompute端起对应的转发服务的,还有对应的流控quota,在导比较大的表时经常被流控导致速度剧烈下降;
-
缺乏只导出部分列的功能,有些情况下我们只需要导出表中少量列的数据,用tunnel会造成浪费。
这样意味着在ETL流程里最开始从原数据系统把数据读出来都有瓶颈,就不用谈整个任务的速度了。为了解决这部分的问题我们换了种思路,借助我们自己的swift服务做了层中转,通过一个MR任务把源表数据写到swift,后续的build任务把swift topic作为数据源。这样一个MR任务基本就是最简单的遍历逻辑,消耗的cu极少,而且可以按需读取需要的字段。
解决了导出层面的问题后,我们还针对上文提到的基础样本作为事实表的情况做了专门的优化,这类表的特点是规模大,字段多,索引简单,同时因为我们借助了swift作为中转,可以借助swift实现数据shuffle,在这个前提下,传统索引构建任务的processor-builder-merger三段流程显得有些浪费了,而且离线任务资源不稳定、频繁启停的现状也会影响表构建的速度。
所以我们运用了具有读写一体能力的AIOS存储服务2.0,用一个使用在线资源的、服务化的写集群来承接表的build。在经过一系列参数调整测试后,可以稳定做到一个小时完成一份30T大小的样本表导入。
✪ 4.6.2 流式执行
如上面训练平台对接章节提到的,训练端最终执行的查询是一段切片后的sql,考虑到训练数据的凑批需要,这个切片大小一般是1w左右。初期实测下来这种query查询起来在cache已经命中的情况下依然会有较大的rt,导致训练端需要起多个查询并发才能让吞吐够得上后面模型的消费。排查后发现主要原因是当时ha3 sql的执行调度层比较接近批任务的调度模式,比如对于下面这样一个执行图:
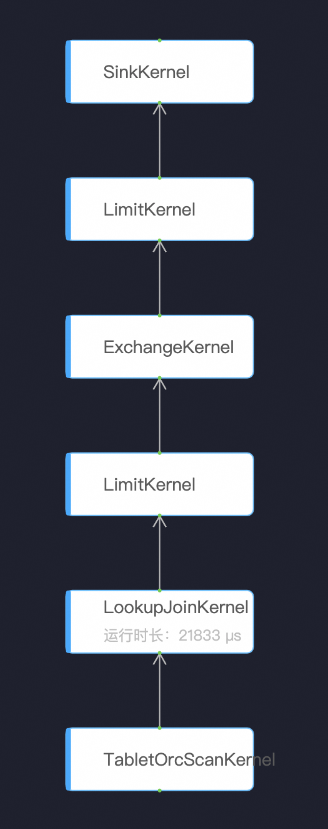
因为本身确实是一个串行的依赖图,服务端就只能这样没有任何并行的直接执行,rt就会非常可观。为了解决这个问题ha3的同学开发了新的流式执行引擎,在新的执行引擎里面,上下游kernel之前会用队列连接起来,每个kernel发现自己上游的队列里面有足够自己计算的一个mini batch的数据后就可以激发计算,这样就把一个逻辑上纯串行的过程并行了起来。
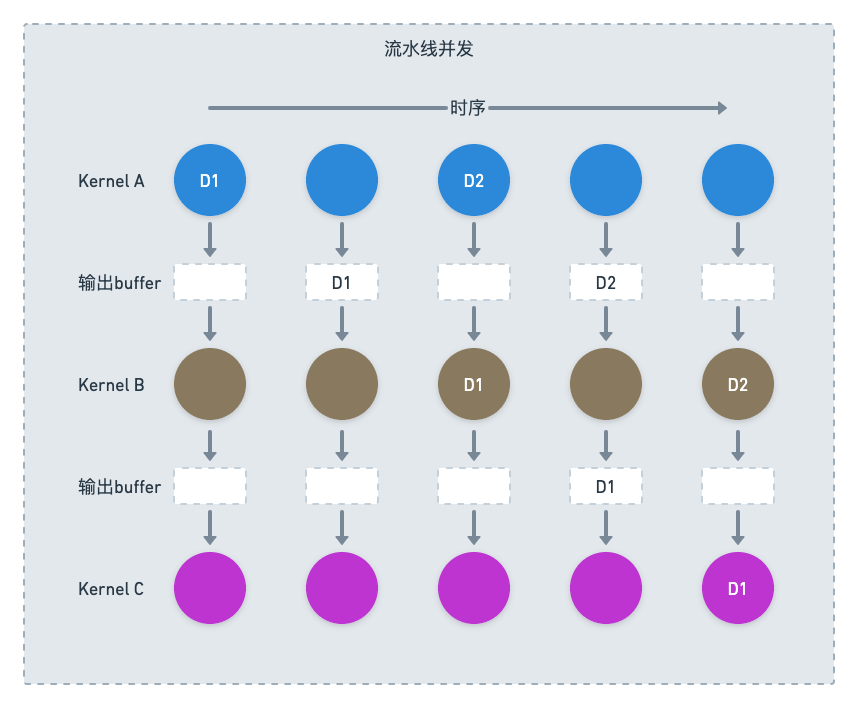
✪ 4.6.3 Caching
正如在查询层技术选型里面提到的,因为样本这个场景,表的总大小规模是一定会超过一个集群的内存上限的,所以完整数据只能放在盘古集群这样的DFS系统,而且是用HDD的离线盘古,那么像查询索引这样有多次seek动作的操作就必然要通过cache机制才能让查询速度符合期望。而indexlib内部有IO层统一的block cache机制,这项技术帮助我们能同时对事实表和维表进行caching。
另外在使用方面,考虑到样本场景的一些普遍业务特点,我们对数据的分布模式做了一些预设,从而获得更好的cache命中率。因为事实表通常是pv_id,item_id 双主键的,我们把事实表根据pv_id拆分了256列,这样事实表查询时的cache局部性就更好,同时有一类超大维度的维表通常也是带着pv_id作为其中一个主键的,这类表我们也会按pv_id拆分为256列,届时执行计划可以优化为一个单列上的local join。其它维度的维表最优的状态是根据主键性质和规模拆分成另外的列数单独部署,这也是我们现在的重点工作方向之一,目前这些维表先统一build成了一列平铺到了同一个部署上。
此外我们还注意到,线上集群的磁盘是ssd的,从磁盘读取的速度比从离线盘古读取要快2-3个数量级,把磁盘也作为cache的一层可以极大地扩大缓存空间。又是得益于indexlib的功能,我们通过简单的配置就用上了这层功能。目前集群的通用配置是128G的磁盘存储加上16G的内存,基于LRU淘汰。
五、场景成本案例
分享几个已经接入并替换掉MaxCompute样本的场景的具体使用方式和前后成本对比案例。
5.1 多场景通用样本
我们服务的其中一个算法团队管理了多个场景的推荐模型,各个场景用的特征是一样的,之前就接入了我们特征平台的全埋点功能,所有场景都通过一套特征配置统一埋点了下来,各个场景在离线训练时有单独用自己场景的样本训练的需求。从概念上讲这种使用方式是上文提到过的行级别实验,但是之前只能算法自己在MaxCompute上接着我们产出的全埋点样本,单独过滤出几张不同场景的样本表,训练分别读取。采用我们的样本实验功能后,结构变成了只需要导入那一份包含所有场景的全埋点样本,各个场景训练时根据场景id直接过滤出来。
该算法团队接入后经过精排在线严格AB,相比之前的链路,在离线效果均一致,并且模型每天还能提前两个小时切到线上。在所有场景推全,所用盘古存储从PB级别直接降到TB级别(均为物理存储大小)。
5.2 召回样本
某业务召回场景的样本则是一个非常典型的星状模型构建样本的例子,可以直接看样本代码:
from turing_script.sdk.itable import ITable as Table
from turing_script.biz_plugin.default_modules.base_sample_module import BaseSampleModuleclass SampleDemo(BaseSampleModule):def build(self, table_env) -> Table:base_sample = table_env.get_table('odps_project.base_sample', shard_key="pvid", with_extra_rand_key = True)#需要join的维表,指明pk_name和需要的字段,可支持多张user_feature = table_env.get_table("odps_project.user_feature", pk_name = "id")content_pos_feature = table_env.get_table("odps_project.content_pos_feature", pk_name = "id")content_neg_feature = table_env.get_table("odps_project.content_neg_feature", pk_name = "id")# sequence featuresequence_feature = table_env.get_table("odps_project.sequence_feature", pk_name = "pvid")#三张表按条件join,字段类型需一致,如字段名相同,可用_right_前缀来区分sample_exp = base_sample.left_outer_join(user_feature, 'user_id=_right_id') \.left_outer_join(content_pos_feature, 'content_id=_right_id') \.left_outer_join(content_neg_feature, 'neg_content_id=_right_id') \.left_outer_join(sequence_feature, 'pvid=_right_pvid') \.select("is_clk as label, *") return sample_exp这段代码基本就是MaxCompute上面最后生成样本表任务的等价替换,之前这个样本在MaxCompute上面存了8天,就能占据PB级别的存储,而迁移到HA3 SQL样本后,因为只需要分别存事实表和维表,存了14天的样本也仅用了几十TB的存储空间。
六、经验教训和展望
样本场景是我们关注和投入了很久的一个领域,部分技术尝试甚至可以追溯到两三年前,回顾这段历程,在技术和产品设计方面有不少感受值得和大家分享:
-
对全链路技术栈的把控力会直接影响这种复杂跨系统项目的成败,引入一个查询层解决样本构建和存储的问题这个想法我们其实很早就有,但是却始终无法找到一个符合场景要求的具体实现。而如今回过头去看,无论是本文提到ha3流式执行引擎改造、写集群直写索引,还是没有提到的各种查询计划生成的bug排查、细致的运行时内存管理逻辑修改等工作,如果我们没有办法去对各种底层系统做直接的改造,很难想象我们最终能完成这个项目。
-
统一代码库带来的集成迭代速度优势是显著而且不断积累的。本文提到了我们运用了很多底层系统团队开发的新功能,项目成员也去各个系统里面加过很多功能或者fix bug,而因为我们整个AIOS团队的代码基本都在一个统一的mono repo中,我们无论是想用上其它系统的最新功能还是自己去学习、更改系统,都是成本非常低的事情,这个对我们的效率提升是巨大的。
-
系统可以快速调试非常重要,我们一开始非常担心用户学习我们样本DSL的成本很高,而且会让我们花大量时间在这部分的答疑上。但是上线后发现,因为我们构建了了web ide开发环境,用户可以直接在页面里面编译DSL并直接看到具体报错,这个尝试过程很快,远比找我们答疑要快,用户普遍倾向于自己先试试,对于我们的答疑需求主要是具体方案和一些表的建议配置。
样本实验功能目前还是个很年轻的产品,我们还会持续在下面几个方面做改进:
-
集群部署形态往按团队、按任务粒度部署演进,提供更好的用户隔离性和灵活性,规避超大规模集群下的一些风险。但同时整个运维、runtime系统也需要适时针对离线的规模场景做重构优化,为规模问题做好两手准备。
-
查询性能优化方面,通过多zone拆表优化cache、自动扩缩容、自动调整调度参数等方式持续优化样本集群查询性能和成本,让样本读取方面不成为训练的瓶颈,同吞吐下降低样本集群资源消耗。
-
样本实验的具体功能还需要持续丰富,比如支持任意层多值MaxCompute表导入、补数据功能产品化、支持udf、建立业务报警机制等,满足业务在样本迭代方面的各类功能需求。
-
目前计算层的逻辑都是抛给用户前置处理掉的,后续会把计算层的任务生成也包含进来,承担诸如部分join的前置计算、样本数据分析之类的功能,让整个产品真正做到混合计算查询。
相关文章:
HA3 SQL样本实验:一种混合计算查询的全新样本解决方案
作者:陆唯一(芜霜) HA3(对外开源代号:Havenask )是阿里智能引擎团队自研的大规模分布式检索系统,广泛应用于阿里内部的搜索业务,是十多年来阿里在电商领域积累下来的核心竞争力产品。Ha3 SQL 是在原有Ha3引…...
)
Linux(Web与html)
域名 DNS与域名: 网络是基于tcp/ip协议进行通信和连接的 tcp/ip协议是五层协议:应用层–传输层—网络层----数据链路层----物理层每一台主机都有一个唯一的地址标识(固定的ip地址,用于区分用户和计算机。 ip地址:由…...
SpringBoot 底层机制分析[上]
文章目录 分析SpringBoot 底层机制【Tomcat 启动分析Spring 容器初始化Tomcat 如何关联Spring 容器】[上]搭建SpringBoot 底层机制开发环境Configuration Bean 会发生什么,并分析机制提出问题:SpringBoot 是怎么启动Tomcat ,并可以支持访问C…...
电源控制--对数与db分贝
在控制理论中,"db"通常表示分贝(decibel)的缩写。分贝是一种用于度量信号强度、增益或衰减的单位。 在控制系统中,分贝常用于描述信号的增益或衰减。通常,增益以正数的分贝值表示,而衰减以负数的…...
)
LeetCode 1749. 任意子数组和的绝对值的最大值(前缀和)
题目: 链接:LeetCode 1749. 任意子数组和的绝对值的最大值 难度:中等 给你一个整数数组 nums 。一个子数组 [numsl, numsl1, …, numsr-1, numsr] 的 和的绝对值 为 abs(numsl numsl1 … numsr-1 numsr) 。 请你找出 nums 中 和的绝对…...
python爬虫相关
目录 初识爬虫 爬虫分类 网络爬虫原理 爬虫基本工作流程 搜索引擎获取新网站的url robots.txt HTHP协议 Resquests模块 前言: 安装 普通请求 会话请求 response的常用方法 简单案例 aiohttp模块 使用前安装模块 具体案例 数据解析 re解析 bs4…...
PAT(Advanced Level) Practice(with python)——1023 Have Fun with Numbers
Code N int(input()) D_N 2*N # print(Yes)if len(str(D_N))>len(str(N)):print(No) else:for s in str(D_N):if s not in str(N) or str(D_N).count(s)!str(N).count(s):print("No")breakelse:print(Yes) print(D_N)...

springboot vue 初步集成onlyoffice
文章目录 前言一、vue ts1. 安装依赖2. onlyoffice组件实现(待优化)3. 使用组件4. 我的配置文件 二、springboot 回调代码1. 本地存储 三、效果展示踩坑总结问题1问题2 前言 对接onlyoffice,实现文档的预览和在线编辑功能。 一、vue ts …...
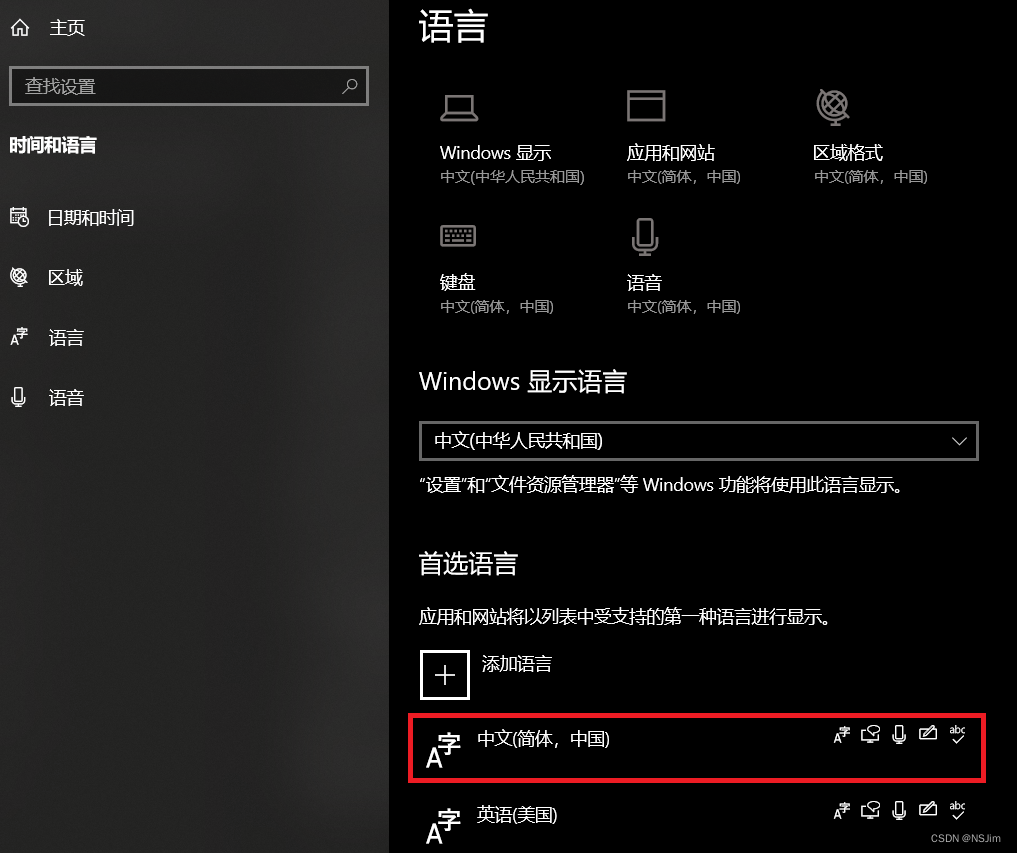
Win10语言设置 - 显示语言和应用语言
前言 Win10的语言设置可以设置显示语言和应用语言。其中,显示语言用于显示系统文字;应用语言用于应用程序显示文字。下文介绍如何设置。 显示语言 打开系统设置,选择时间和语言,如下图: 修改Windows显示语言即可更…...

RxJava的前世【RxJava系列之设计模式】
一. 前言 学习RxJava,少不了介绍它的设计模式。但我看大部分文章,都是先将其用法介绍一通,然后再结合其用法,讲解其设计模式。这样当然有很多好处,但我个人觉得,这种介绍方式,对于没有接触过Rx…...

sql 语句 字段字符串操作
substring_index() 函数 字符串截取 表达式:substring_index(column,str,count) 释义:截取字符串column,str出现从前往后数第count次,之前的所有字符 示例语句:SELECT substring_index(‘www.baidu.com’,‘.’,2) 结…...
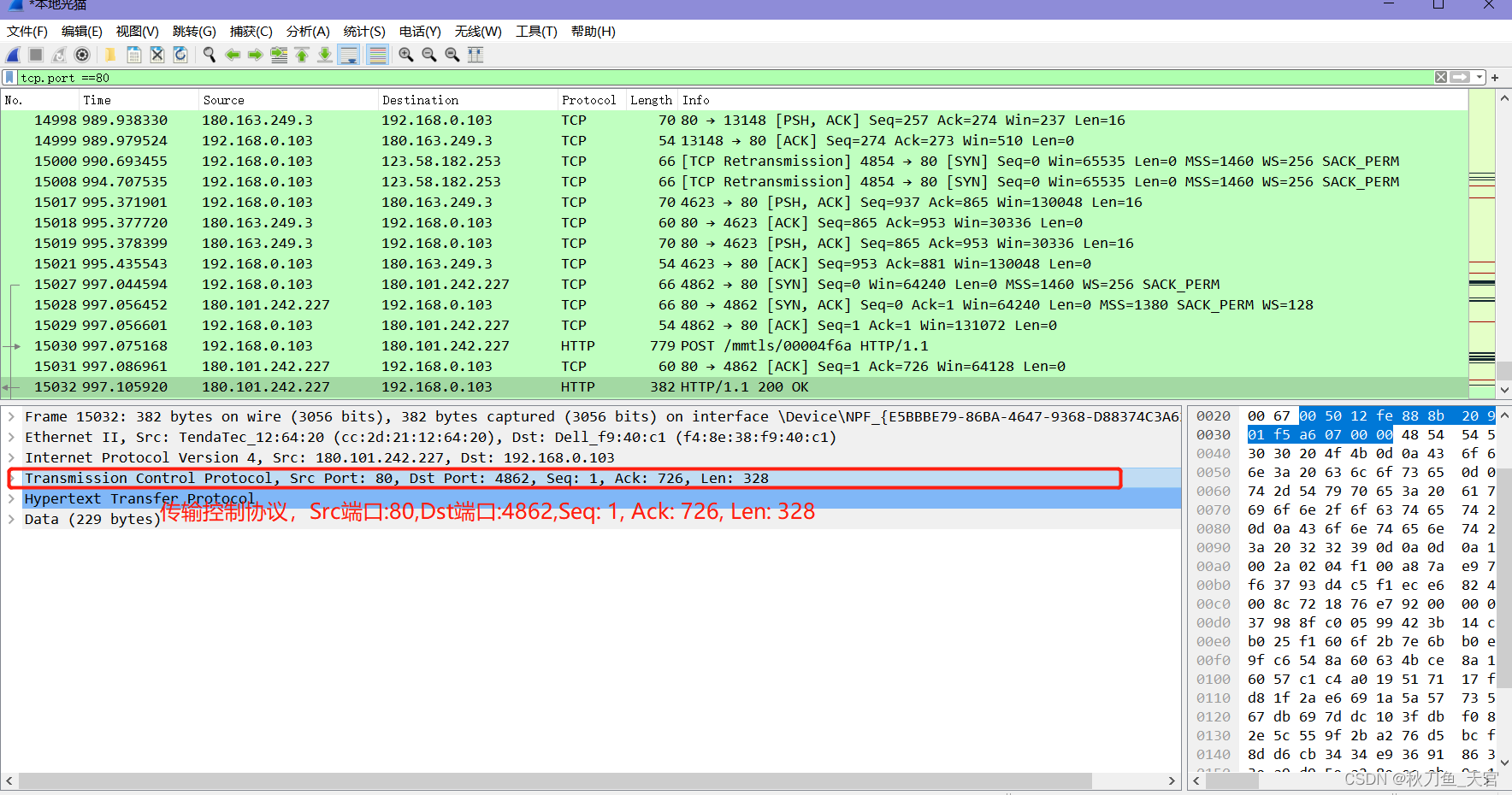
【网络工程】网络流量分析工具 Wireshark
文章目录 第一章:WireShark介绍第二章:WireShark应用第三章:Wireshark 实战 第一章:WireShark介绍 Wireshark (前身 Ethereal):它是一个强大的网络封包分析软件工具 ! 此工具使用WinPCAP作为接口,直接与网卡…...
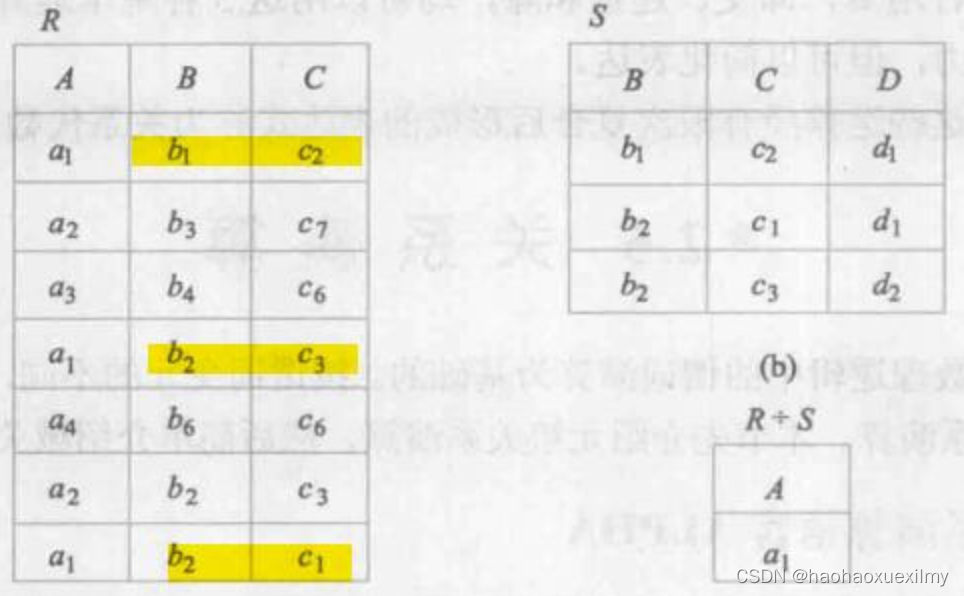
数据库总结
第一章绪论 一、数据库系统概述 1. 数据库的4个基本概念 1.数据:数据库中存储的基本对象,描述事物的符号记录。 2.数据库:长期储存在计算机内、有组织的、可共享的大量数据的集合。较小的冗余度、较高的数据独立性、易扩展性 3.数据库管…...

虹科方案 | 成都大运会进行时,保障大型活动无线电安全需要…
成都大运会 7月28日,备受关注的第31届世界大学生夏季运动会在成都正式开幕。据悉,这是全球首个5G加持的智慧大运会,也是众多成熟信息技术的综合“应用场”。使用基于5G三千兆、云网、8K超高清视频等技术,在比赛现场搭建多路8K摄像…...
【C语言】扫雷 小游戏
文章目录 一、游戏规则二、 代码逻辑三、游戏实现1. 游戏菜单设计2.设计雷区并随机布置雷(1) 设置雷区(2) 布置雷 3.排查雷 四、源码 一、游戏规则 1. 在9*9的小格子中,任意选取一个坐标(格子),选择后发现,如果没点中雷…...

Jmeter(六) - 从入门到精通 - 建立数据库测试计划(详解教程)
1.简介 在实际工作中,我们经常会听到数据库的性能和稳定性等等,这些有时候也需要测试工程师去评估和测试,因此这篇文章主要介绍了jmeter连接和创建数据库测试计划的过程,在文中通过示例和代码非常详细地介绍给大家,希望对各位小伙…...
swagger 3.0 学习笔记
引入pom <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter</artifactId><version>3.0.0</version></dependency>配置 import io.swagger.models.auth.In; import io.swagger.v3.oas.annotati…...

07 |「异步任务」
前言 实践是最好的学习方式,技术也如此。 文章目录 前言一、进程与线程1、进程2、线程 二、实现 一、进程与线程 1、进程 进程(Process)是操作系统分配资源的基本单位,它是一个执行中的程序实例;每个进程都有自己独立的内存空间,不同进程的内存是相互独…...

LoRaWan网关设计之入门指南
快速开始 以下是在目标平台本身上构建和运行 LoRaWan网关 的三步快速入门指南。 第 1 步:克隆 网关源码库 git clone https://github.com/lorabasics/basicstation.git...
互联网电影购票选座后台管理系统源码开发
搭建一个互联网电影购票选座后台管理系统需要进行以下步骤: 1. 需求分析:首先要明确系统的功能和需求,包括电影列表管理、场次管理、座位管理、订单管理等。 2. 技术选型:选择适合的技术栈进行开发,包括后端开发语言…...

StructBERT-中文-large部署案例:5个开源数据集训练的语义匹配服务
StructBERT-中文-large部署案例:5个开源数据集训练的语义匹配服务 1. 项目概述与核心价值 StructBERT中文文本相似度模型是一个专门针对中文语义匹配任务优化的深度学习模型。这个模型基于structbert-large-chinese预训练模型,使用五个高质量开源数据集…...
FDE会被AI完全替代吗?)
Palantir:两个不确定的问题(2)FDE会被AI完全替代吗?
从上一篇的分析可以得知,Palantir的整套系统,就是一个有机的企业级数字孪生体: 本体Ontology灵魂/主宰 它定义世界“是什么、有什么、彼此关系如何”,是客观现实与人类主观认识的统一,是整个系统的 “道”。 AIP心与…...

Qwen3-14B-Int4-AWQ效果深度评测:代码生成、推理与数学能力横向对比
Qwen3-14B-Int4-AWQ效果深度评测:代码生成、推理与数学能力横向对比 1. 评测背景与模型特点 Qwen3-14B-Int4-AWQ作为通义千问系列的最新量化版本,在保持原版14B参数规模的同时,通过AWQ(Activation-aware Weight Quantization&am…...

从BERT到GPT:预训练语言模型的技术演进史
一场改变软件测试范式的革命2018年,当谷歌发布BERT模型时,软件测试领域并未意识到这项技术将如何重塑自动化测试工具的设计逻辑。三年后,GPT-3的诞生让测试脚本自动生成从实验室走向工程实践。本文以软件测试工程师的视角,剖析预训…...
)
Debian 12 安装 Podman 5.7.1 最新版完整指南(含国内镜像加速配置)
Debian 12 容器化实践:Podman 5.7.1 高效部署与镜像加速全攻略 容器技术正在重塑现代应用交付的范式。作为Docker的替代方案,Podman以其无守护进程架构和原生rootless支持,正在成为开发者工具箱中的新宠。本文将带您深入探索在Debian 12上部…...

【JVM级性能跃迁】:Java 25虚拟线程在实时风控系统的SLA突破——P99延迟从820ms降至43ms
第一章:Java 25虚拟线程在高并发架构下的实践企业级应用场景 Java 25正式将虚拟线程(Virtual Threads)从预览特性转为标准特性,标志着JVM在轻量级并发模型上的重大演进。相比传统平台线程,虚拟线程由JVM调度、在用户态…...

AllWize库:面向Wize协议的LoRa射频嵌入式驱动开发指南
1. AllWize库概述:面向Wize协议的嵌入式无线通信底层实现 AllWize是一个专为Wize协议设计的Arduino兼容C库,核心目标是为RC1701HP系列射频模块提供轻量、可靠、跨平台的硬件抽象层。该库并非通用无线协议栈,而是深度绑定于RadioCrafts公司推…...

OPTIGA™ Trust M安全芯片Arduino开发全解析
1. OPTIGA™ Trust M 安全芯片 Arduino 库深度解析Infineon OPTIGA™ Trust M 是一款面向物联网边缘设备的高安全性硬件安全模块(HSM),其核心价值在于将密码学能力从软件层下沉至专用安全微控制器,从根本上规避密钥在主MCU内存中明…...

SolidEdge许可证分点典型成功案例深度解析
SolidEdge许可证分点典型成功案例深度解析记得上个月,项目组又是因为SolidEdge许可抢不到耽误了两天出图。工程师抓狂,IT部门也跟着着急。可巧的是,查账截图里显示,公司每年在软件授权上的投入早就超过千万,可也是&…...

nnUNet环境配置避坑指南:从PyTorch安装到数据集转换的完整流程
nnUNet环境配置与实战指南:从零搭建医学图像分割流水线 1. 环境部署:构建稳定高效的PyTorch基础 在开始nnUNet之旅前,确保拥有兼容的硬件环境:推荐使用NVIDIA显卡(RTX 3060及以上)、16GB以上内存和至少100G…...