fine-tuning(微调)的理解
fine-tuning
介绍
什么情况下使用微调
微调指导事项
不同数据集下使用微调
涉及到的其他知识
学习率(learning-rate)
卷积神经网络的核心
迁移学习与微调
什么是迁移学习
为什么要迁移学习
详细解释
自己的理解(不知道对不对)
介绍
fine-tuning的过程就是用训练好的参数(从已训练好的模型中获得)初始化自己的网络,然后用自己的数据接着训练,参数的调整方法与from scratch训练过程一样(梯度下降)。对于初始化过程,我们可以称自己的网络为目标网络,训练好的模型对应网络为源网络,要求目标网络待初始化的层要与源网络的层相同(层的名字、类型以及层的设置参数等等均相同)。
fine-tuning已经成为了使用DL网络的一个常用技巧(trick)。使用深度网络做图像处理任务时,使用一个在大的数据集上预训练好的模型在自己数据上微调往往可以得到比直接用自己数据训练更好的效果,这是因为在imagenet上预训练的模型参数从微调一开始就处于一个较好的位置,这样微调能够更快的使网络收敛。对于相同类别的任务我们可以默认这样去做比较好。然而当我们要做一个不同的任务,那么可能直接拿预训练的模型进行微调就不是最好的了。
一般我们在训练from scratch的时候往往要在一些超大型的数据集上训练,一个目的是为了让训练得到的特征(尤其是底层特征)更加多样。而从generative pre-training(生成式预训练)到discriminative fine-tuning(判别微调)的过程是一个对泛化特征进行面向任务的特化的过程。首先,如果你将底层特征可视化出来,会发现底层特征多是一些边、角之类的基础几何形状,高层特征可能会发生一些有趣的变化,直接反映出你的task。 在大数据集上进行预训练的目的之一是为了获得丰富、一般化的底层特征,换言之就是学到丰富的“基础几何形状”。有了这些丰富的基础几何形状,等过渡到小数据集上 finetune 的时候,就可以通过它们组合出上层具有强判别力的特征。此时,如果你再将组合出来的上层特征可视化,就会发现它们已经有模有样了。底层特征非常重要,如果底层特征不够好,特征类型不够充分,很可能训练不出来好的高层抽象。这就是为什么需要在大规模数据集上进行genertive training的原因之一。
网络越深,底层的参数越难得到有效训练,这也是为什么经常有人用 vggNet finetune 的原因之一。使用 backpropagation(反向传播)进行训练的时候残差逐层传递,有可能到底层的时候残差就很小了(gradient vanishing),导致底层的参数不动。
finetune 就是直接从别人已经训练好的网络上拷贝参数,然后针对自己的数据训练新的模型。这时候需要比较小的learning_rate, 因为要在不破坏原有模型的情况下 fit 自己的数据,finetune 的好处就是可以直接获得我们难以或者无法训练的底层参数。
什么情况下使用微调
(1)你要使用的数据集和预训练模型的数据集相似,如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。
(2)自己搭建或者使用的CNN模型正确率太低。
(3)数据集相似,但数据集数量太少。
(4)计算资源太少。
微调指导事项
1.通常的做法是截断预先训练好的网络的最后一层( softmax层),并用与我们自己的问题相关的新的softmax层替换它。例如,ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
⒉.使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch )的初始学习率小10倍。
3.如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
不同数据集下使用微调
1.数据量少,但数据相似度非常高。在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
2.数据量少,数据相似度低。在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的( n-k )层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
3.数据量大,数据相似度低。在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch )。
4.数据量大,数据相似度高。这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
涉及到的其他知识
学习率(learning-rate)
将输出误差反向传播给网络参数,以此来拟合样本的输出。本质上是最优化的一个过程,逐步趋向于最优解。但是每一次更新参数利用多少误差,就需要通过一个参数来控制,这个参数就是学习率(Learning rate),也称为步长。
学习率越大,输出误差对参数的影响就越大,参数更新的就越快,但同时受到异常数据的影响也就越大,梯度可能会在最小值附近来回震荡,甚至可能无法收敛。当学习率设置的过小时,收敛过程将变得十分缓慢。
最理想的学习率不是固定值,而是一个随着训练次数衰减的变化的值,也就是在训练初期,学习率比较大,随着训练的进行,学习率不断减小,直到模型收敛。
学习率大 学习率小
学习速度 快 慢
使用时间点 刚开始训练时 一定轮数过后
副作用 1.易损失值爆炸;2.易振荡 1.易过拟合;2.收敛速度慢
如果是迁移学习 ,由于模型已在原始数据上收敛,此时应设置较小学习率 (≤10^−4) 在新数据上进行微调 。
卷积神经网络的核心
(1)浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
(2)深层卷积层提取抽象特征,比如整个脸型。
(3)全连接层根据特征组合进行评分分类。
迁移学习与微调
什么是迁移学习
迁移学习(Transfer learning) 顾名思义就是把已训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。
为什么要迁移学习
1)站在巨人的肩膀上:前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要好。
2)训练成本可以很低:如果采用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用CPU都完全无压力,没有深度学习机器也可以做。
3)适用于小数据集:对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。
详细解释
1)Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
2)Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
3)Fine-tune:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
注:Transfer Learning关心的问题是:什么是“知识”以及如何更好地运用之前得到的“知识”,这可以有很多方法和手段,eg:SVM,贝叶斯,CNN等。而fine-tune只是其中的一种手段,更常用于形容迁移学习的后期微调中。
自己的理解(不知道对不对)
1.迁移学习,学习的是整个结构,包括函数权重参数等;
而fine-tuning,学习的是前n层的参数。
2.fine-tuning是迁移学习的方法之一。
————————————————
版权声明:本文为CSDN博主「好耶OvO」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_45652492/article/details/123379156
相关文章:
的理解)
fine-tuning(微调)的理解
fine-tuning 介绍 什么情况下使用微调 微调指导事项 不同数据集下使用微调 涉及到的其他知识 学习率(learning-rate) 卷积神经网络的核心 迁移学习与微调 什么是迁移学习 为什么要迁移学习 详细解释 自己的理解(不知道对不对) 介绍…...

深入理解设计模式面经
1 讲讲工厂方法模式, 1.1 给我一个java的demo 工厂方法模式是一种创建型设计模式,它提供了一个接口用于创建对象,但允许子类修改将要创建的对象类型。这种模式抽象了对象的创建过程,使得代码可以在不知道创建的对象具体类的情况…...

STM32单片机蓝牙APP宠物自动喂食器定时语音提醒喂食系统设计
实践制作DIY- GC00162---蓝牙APP宠物自动喂食器 一、功能说明: 基于STM32单片机设计---蓝牙APP宠物自动喂食器 二、功能说明: STM32F103C系列最小系统板LCD1602显示器DS1302时钟模块5个按键语音播报模块ULN2003步进电机模块LED灯板HC-05蓝牙模块&#x…...

武汉凯迪正大—串联谐振在电力系统中应用的优点:
变频串联谐振耐压试验装置在电力系统中应用的优点 1、所需电源容量大大减小。串联谐振电源是利用谐振电抗器和被试品电容谐振产生高电压和大电流的,在整个系统中,电源只需要提供系统中有功消耗的部分,因此,试验所需的电源功率只有…...

Git仓库、分支的区别
https://blog.csdn.net/weixin_30315905/article/details/94954617 git 仓库、分支的区别 首先,要明白仓库的概念 仓库可以理解为repository, 就是存放代码的地方,—— 其实是一个比较笼统的概念,不管里面的内容,总之…...

C#生成随机验证码
以下是一个简单的C#验证码示例: private void GenerateCaptcha() {// 生成随机字符串string chars "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";Random random new Random();string captchaString new string(Enumerable.Repe…...

如何使用C++来找出编码88表示的字符?指出至少两种方法。
在C中,可以使用整型值来表示字符编码,其中ASCII码是最常见的字符编码方案。要找出编码为88的字符,可以使用以下两种方法: 方法一:使用类型转换(显式类型转换或隐式类型转换)将整型值转换为字符…...

Kafka:springboot集成kafka收发消息
kafka环境搭建参考Kafka:安装和配置_moreCalm的博客-CSDN博客 1、springboot中引入kafka依赖 <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><…...
本质矩阵E、基本矩阵F、单应矩阵H
1. E (归一化坐标对进行计算) t ^ R 为3*3的矩阵, 因为R,t共有6个自由度,又因为单目尺度等价性,所以实际上E矩阵共有5个自由度。因此至少需要5个点对来求解。 2. 基本矩阵F:根据两帧间匹配的像素点对儿计算 3*3且自由度为7的矩阵kF也为基础矩阵&#x…...

Oracle database Linux自建环境备份至远端服务器自定义保留天数
环境准备 linux下安装oracle 请看 oracle12c单节点部署 系统版本: CentOS 7 软件版本: Oracle12c 备份策略与实现方法 此次备份依赖Oracle自带命令exp与linux下crontab命令(定时任务) exp Oracle中exp命令是一个用于导出数据库数据和对象的…...
|(线程池使用))
SpringBoot异步任务(2)|(线程池使用)
SpringBoot异步任务(2)|(线程池使用) 文章目录 SpringBoot异步任务(2)|(线程池使用)[TOC] 前言一、使用场景二、springboot添加异步任务1.配置线程池2.线程池的使用 总结 章节 第一章…...
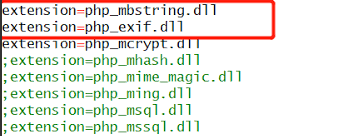
解决Windows:Call to undefined function exif_imagetype()
很明显,是php安装时没有打开某些扩展,以致不能执行exif_imagetype()这个方法,因此需要打开。 网上很多人说需要打开下面这两个扩展: extension=php_exif.dll extension=php_mbstring.dll 但只说对了一半,我一开始也按照网上文章说的打开这两个扩展,但是还是同样错误。…...
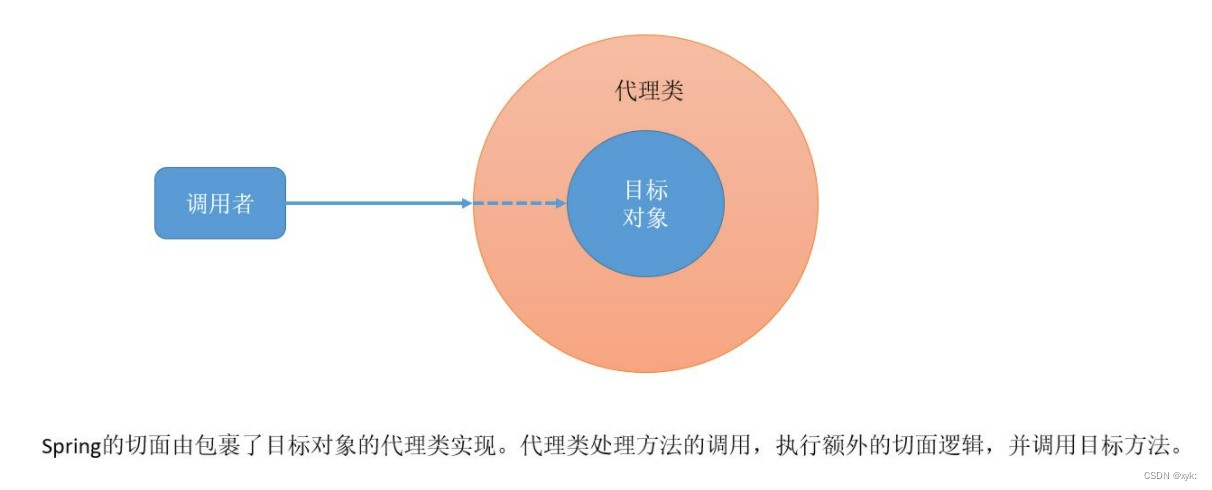
【Spring】Spring AOP 初识及实现原理解析
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: JavaEE进阶 目录 文章目录 一、初识AOP 1.1 什么是AOP? 1.2 AOP的组成 1.2.1 切面(Aspect) 1.2.2 切点(Pointcut) 1.2.3 连接点&…...

【Express.js】集成Redis
集成Redis 本节我们介绍在 express.js 中集成 redis. Redis是一个高性能的key-value内存数据库,支持事务、队列、持久化等特性,常用于高并发性能场景。 准备工作 创建一个 express.js 项目(本文基于evp-express-cli)在开发环境…...

StringBuilder创建的对象如何清空
要清空一个StringBuilder对象,可以使用其实例方法setLength(int newLength)来实现。将newLength参数设置为0,就可以将StringBuilder的内容清空。以下是一个示例代码: StringBuilder sb new StringBuilder(); // 添加一些内容到StringBuilde…...

mybatis-plus实现mysql自定义IKeyGenerator
1. IKeyGenerator主键生成 内置实现类,缺少mysql,因为mysql不支持序列,只能通过表模拟序列 H2KeyGenerator PostgreKeyGenerator KingbaseKeyGenerator 人大金仓的KES数据库 DB2KeyGenerator OracleKeyGenerator2. 新建表模拟序列 CREATE T…...

山西电力市场日前价格预测【2023-08-11】
日前价格预测 预测明日(2023-08-11)山西电力市场全天平均日前电价为367.15元/MWh。其中,最高日前电价为408.91元/MWh,预计出现在20: 00。最低日前电价为343.90元/MWh,预计出现在02: 30。 价差方向预测 1: 实…...

浏览器无法连接网络问题
问题描述 电脑其他程序都能正常联网,但是所有的浏览器都无法联网,同时外部网站都能ping通 问题诊断 查看电脑Internet连接的问题报告显示:该设备或资源(Web 代理)未设置为接受端口"7890"上的连接。 解决方案 经过检查发现不是IP地址…...
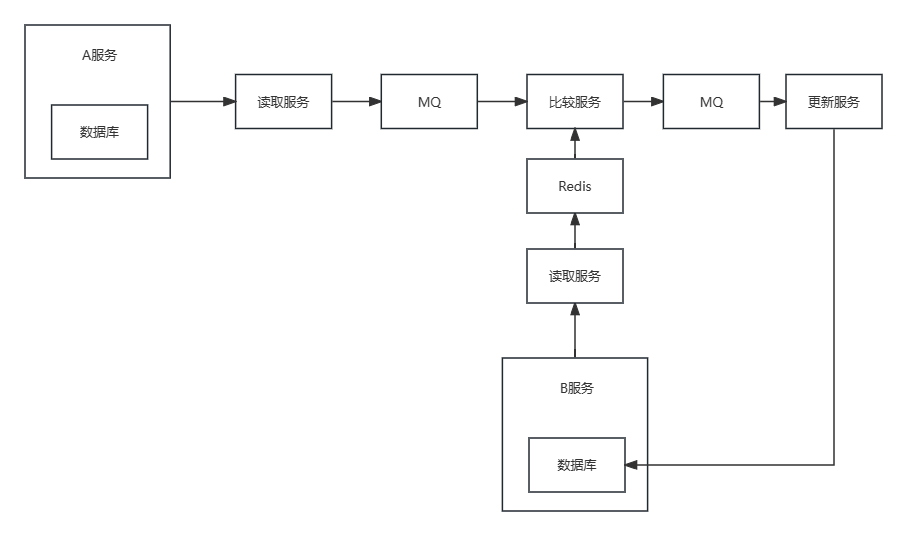
ZyjDataLink 全量MySQL同步程序 - 开发过程 01
开发过程由本人从 架构设计 到 代码实现 独立完成,通过该博客记录分享开发经验 ZyjDataLink 当前的目标是做到 MySQL大数据量的快速同步,后期希望扩展的功能 高度可操作性,融入增量数据库同步,跨数据库同步 ZyjDataLink 需求分析…...

为什么说Python股票接口是连接投资与编程的桥梁?
在现代金融领域,投资与技术的结合日益紧密,而Python作为一种强大的编程语言,为投资者提供了开发股票交易策略和分析市场数据的高效工具。 一、Python股票接口的重要性: Python作为一种易学易用的编程语言,逐渐成为金融…...

用STM32F407的FSMC总线给FPGA当外挂RAM?一个实战项目带你打通软硬件
STM32与FPGA的FSMC总线实战:打造高性能异构内存扩展方案 在嵌入式系统开发中,内存资源常常成为性能瓶颈。当STM32需要处理大规模数据时,内部SRAM可能捉襟见肘。本文将展示如何利用STM32F407的FSMC总线,将FPGA内部RAM无缝扩展为MCU…...

人工智能赋能软件开发:基于PyTorch 2.8的AI编程助手本地部署
人工智能赋能软件开发:基于PyTorch 2.8的AI编程助手本地部署 1. 为什么需要私有AI编程助手 想象一下这样的场景:凌晨两点,你正在赶一个紧急项目,遇到一个复杂的算法问题卡壳了。这时候如果有个懂行的搭档能随时提供建议该多好&a…...

辅助驾驶场景应用:如何用视觉定位模型理解道路目标
辅助驾驶场景应用:如何用视觉定位模型理解道路目标 1. 从“指哪打哪”到“看懂路况”:视觉定位在辅助驾驶中的价值 想象一下,你坐在副驾驶,用手指着前方说:“注意右边那辆白色轿车,它可能要变道。” 驾驶…...

5分钟极速部署DocsGPT:云原生Kubernetes实战指南
5分钟极速部署DocsGPT:云原生Kubernetes实战指南 【免费下载链接】DocsGPT Private AI platform for agents, assistants and enterprise search. Built-in Agent Builder, Deep research, Document analysis, Multi-model support, and API connectivity for agent…...

Laravel Cashier Stripe源码解析:理解设计原理与架构
Laravel Cashier Stripe源码解析:理解设计原理与架构 【免费下载链接】cashier-stripe Laravel Cashier provides an expressive, fluent interface to Stripes subscription billing services. 项目地址: https://gitcode.com/gh_mirrors/ca/cashier-stripe …...

Mediapipe手势识别实战——基于关节角度计算实现动态手势分类
1. 从Mediapipe基础到动态手势识别 第一次接触Mediapipe的手部关键点检测时,我被它的21个关节点输出惊艳到了。但很快发现一个问题:单纯画出关节点和连线,就像给手部画了张"骨架图",根本无法理解手势含义。直到尝试用关…...

Java的java.lang.ModuleLayer配置与模块解析在自定义类加载器中的集成
Java模块化系统自Java 9引入以来,为开发者提供了更强大的代码组织和隔离能力。其中,java.lang.ModuleLayer作为模块化的核心API之一,允许动态配置模块层次结构,而自定义类加载器则能进一步扩展模块化的灵活性。两者的结合为复杂应…...

数据团队该醒醒了:AI智能体不是你的下一个仪表盘众
7.1 初识三维模型 7.1.1 三维模型的数据载体 随着计算机图形技术的发展,我们或多或少都会见过或者听说过三维模型。笔者始终记得小时候第一次在电视上看到三维动画《变形金刚:超能勇士》的震撼感受;而现在我们已经可以在手机上玩三维游戏《王…...

手把手教你用HunyuanVideo-Foley:让无声视频秒变大片
手把手教你用HunyuanVideo-Foley:让无声视频秒变大片 1. 引言:为什么需要智能音效生成? 你有没有遇到过这样的尴尬场景?精心拍摄了一段视频,画面构图完美、运镜流畅,但播放时却一片寂静——没有环境音、没…...

OpenClaw Ontology技能学习笔记
一、技能核心基础1. 技能定位OpenClaw的长效知识图谱技能,打造AI本地结构化记忆,解决AI对话健忘、无关联推理、上下文断层问题,让AI持久记住人物、任务、项目等信息及关联关系。2. 核心解决问题- 普通AI:对话结束即遗忘࿰…...