langchain-ChatGLM源码阅读:参数设置
文章目录
- 上下文关联
- 对话轮数
- 向量匹配 top k
- 控制生成质量的参数
- 参数设置心得
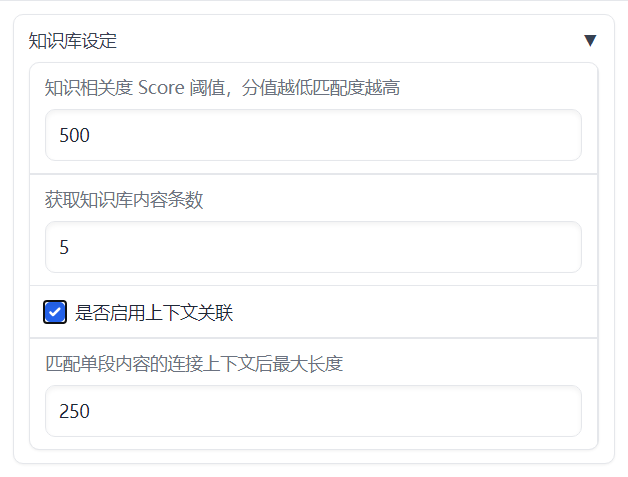
上下文关联
上下文关联相关参数:
- 知识相关度阈值score_threshold
- 内容条数k
- 是否启用上下文关联chunk_conent
- 上下文最大长度chunk_size
其主要作用是在所在文档中扩展与当前query相似度较高的知识库的内容,作为相关信息与query按照prompt规则组合后作为输入获得模型的回答。
- 获取查询句query嵌入:
faiss.py
def similarity_search_with_score(self, query: str, k: int = 4) -> List[Tuple[Document, float]]:"""Return docs most similar to query.Args:query: Text to look up documents similar to.k: Number of Documents to return. Defaults to 4.Returns:List of Documents most similar to the query and score for each"""embedding = self.embedding_function(query)docs = self.similarity_search_with_score_by_vector(embedding, k)return docs
- 上下文生成:
MyFAISS.py
def seperate_list(self, ls: List[int]) -> List[List[int]]:# TODO: 增加是否属于同一文档的判断lists = []ls1 = [ls[0]]for i in range(1, len(ls)):if ls[i - 1] + 1 == ls[i]:ls1.append(ls[i])else:lists.append(ls1)ls1 = [ls[i]]lists.append(ls1)return listsdef similarity_search_with_score_by_vector(self, embedding: List[float], k: int = 4) -> List[Document]:faiss = dependable_faiss_import()# (1,1024)vector = np.array([embedding], dtype=np.float32)# 默认FALSEif self._normalize_L2:faiss.normalize_L2(vector)# shape均为(1, k),这步获取与query有top-k相似度的知识库scores, indices = self.index.search(vector, k)docs = []id_set = set()store_len = len(self.index_to_docstore_id)rearrange_id_list = False# 遍历找到的k个最相似知识库的索引# k是第一次的筛选条件,score是第二次的筛选条件for j, i in enumerate(indices[0]):if i == -1 or 0 < self.score_threshold < scores[0][j]:# This happens when not enough docs are returned.continueif i in self.index_to_docstore_id:_id = self.index_to_docstore_id[i]# 执行接下来的操作else:continue# index→id→contentdoc = self.docstore.search(_id)if (not self.chunk_conent) or ("context_expand" in doc.metadata and not doc.metadata["context_expand"]):# 匹配出的文本如果不需要扩展上下文则执行如下代码if not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")doc.metadata["score"] = int(scores[0][j])docs.append(doc)continue# 其实存的都是indexid_set.add(i)docs_len = len(doc.page_content)# 跟外部变量定义的k重名了,烂# 一个知识库是分句后得到的一句话,i是当前知识库在总知识库中的位置,store_len是总知识库大小# 所以k说的是扩充上下文时最多能跨多少个知识库for k in range(1, max(i, store_len - i)):break_flag = Falseif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "forward":expand_range = [i + k]elif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "backward":expand_range = [i - k]else:# i=4922, k=1 → [4923, 4921]expand_range = [i + k, i - k]for l in expand_range:# 确保扩展上下文时不会造成重复if l not in id_set and 0 <= l < len(self.index_to_docstore_id):_id0 = self.index_to_docstore_id[l]doc0 = self.docstore.search(_id0)# 如果当前字数大于250或者是知识库跨了文件,扩充上下文过程终止# 这一句有些问题,有一端跨文件就终止,应该是两端同时跨才终止才对if docs_len + len(doc0.page_content) > self.chunk_size or doc0.metadata["source"] != \doc.metadata["source"]:break_flag = Truebreakelif doc0.metadata["source"] == doc.metadata["source"]:docs_len += len(doc0.page_content)id_set.add(l)rearrange_id_list = Trueif break_flag:break# 如果没有扩展上下文(不需要或是不能)if (not self.chunk_conent) or (not rearrange_id_list):return docsif len(id_set) == 0 and self.score_threshold > 0:return []id_list = sorted(list(id_set))# 连续必然属于同一文档,但不连续也可能在同一文档# 返回二级列表,第一级是连续的index列表,第二级是具体indexid_lists = self.seperate_list(id_list)for id_seq in id_lists:for id in id_seq:if id == id_seq[0]:_id = self.index_to_docstore_id[id]# doc = self.docstore.search(_id)doc = copy.deepcopy(self.docstore.search(_id))else:_id0 = self.index_to_docstore_id[id]doc0 = self.docstore.search(_id0)doc.page_content += " " + doc0.page_contentif not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")# indices为相关文件的索引# 因为可能会将多个连续的id合并,因此需要将同一seq内所有位于top-k的知识库的分数取最小值作为seq对应的分数doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]])doc.metadata["score"] = int(doc_score)docs.append(doc)# 注意这里docs没有按相似度排序,可以自行加个sortreturn docs
- prompt生成:
local_doc_qa.py
def get_knowledge_based_answer(self, query, vs_path, chat_history=[], streaming: bool = STREAMING):related_docs_with_score = vector_store.similarity_search_with_score(query, k=self.top_k)torch_gc()if len(related_docs_with_score) > 0:prompt = generate_prompt(related_docs_with_score, query)else:prompt = queryanswer_result_stream_result = self.llm_model_chain({"prompt": prompt, "history": chat_history, "streaming": streaming})def generate_prompt(related_docs: List[str],query: str,prompt_template: str = PROMPT_TEMPLATE, ) -> str:context = "\n".join([doc.page_content for doc in related_docs])prompt = prompt_template.replace("{question}", query).replace("{context}", context)return prompt
对话轮数
其实就是要存多少历史记录,如果为0的话就是在执行当前对话时不考虑历史问答
- 模型内部调用时使用,以chatglm为例:
chatglm_llm.py
def _generate_answer(self,inputs: Dict[str, Any],run_manager: Optional[CallbackManagerForChainRun] = None,generate_with_callback: AnswerResultStream = None) -> None:history = inputs[self.history_key]streaming = inputs[self.streaming_key]prompt = inputs[self.prompt_key]print(f"__call:{prompt}")# Create the StoppingCriteriaList with the stopping stringsstopping_criteria_list = transformers.StoppingCriteriaList()# 定义模型stopping_criteria 队列,在每次响应时将 torch.LongTensor, torch.FloatTensor同步到AnswerResultlistenerQueue = AnswerResultQueueSentinelTokenListenerQueue()stopping_criteria_list.append(listenerQueue)if streaming:history += [[]]for inum, (stream_resp, _) in enumerate(self.checkPoint.model.stream_chat(self.checkPoint.tokenizer,prompt,# 为0时history返回[]history=history[-self.history_len:-1] if self.history_len > 0 else [],max_length=self.max_token,temperature=self.temperature,top_p=self.top_p,top_k=self.top_k,stopping_criteria=stopping_criteria_list)):
向量匹配 top k
虽然放在了模型配置那一页,但实际上还是用来控制上下文关联里面的内容条数k的,不知道为什么写了两遍。。。
控制生成质量的参数
这些参数没有在前端显式地给出,而是写死在了模型定义里
- 模型定义,以chatglm为例:
chatglm_llm.py
class ChatGLMLLMChain(BaseAnswer, Chain, ABC):max_token: int = 10000temperature: float = 0.01# 相关度top_p = 0.4# 候选词数量top_k = 10checkPoint: LoaderCheckPoint = None# history = []history_len: int = 10
参数设置心得
- score_threshold和k设太小会找不到问题对应的原文件,太大找到一堆不相关的
- chunk_size设太小不能在原文件里找到问题对应的原文,太大无法有效归纳出答案
- temperature和top_p默认值下生成的答案基本固定,但也很死板;过大的temperature导致回答的事实不稳定;过大的top_p导致回答的语言风格不稳定;调整top_k没发现结果有什么变化
相关文章:
langchain-ChatGLM源码阅读:参数设置
文章目录 上下文关联对话轮数向量匹配 top k控制生成质量的参数参数设置心得 上下文关联 上下文关联相关参数: 知识相关度阈值score_threshold内容条数k是否启用上下文关联chunk_conent上下文最大长度chunk_size 其主要作用是在所在文档中扩展与当前query相似度较高…...

什么是Java中的工厂模式?
工厂模式(Factory Pattern)是一种常见的设计模式,它可以帮助我们简化对象创建的过程,将对象的创建与使用分离,提高代码的可维护性和可扩展性。在Java中,工厂模式通常分为简单工厂模式(Simple Fa…...
数据库--MySQL
一、什么是范式? 范式是数据库设计时遵循的一种规范,不同的规范要求遵循不同的范式。 最常用的三大范式 第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列) 第二范式(2NF):满足…...
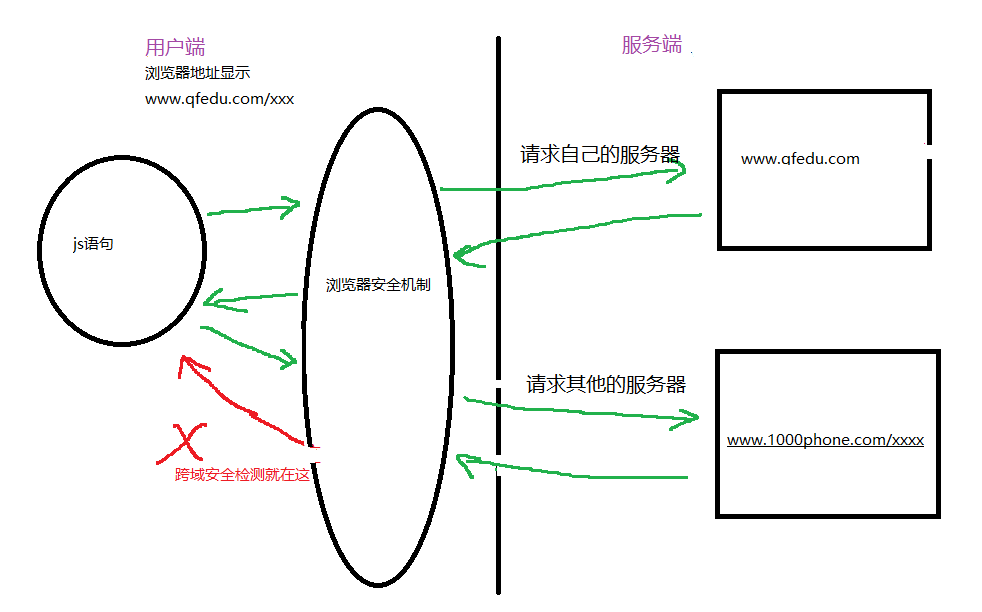
浏览器多管闲事之跨域
年少时的梦想就是买一台小霸王游戏机 当时的宣传语就是小霸王其乐无穷~。 大些了,攒够了零花钱,在家长的带领下终于买到了 那一刻我感觉就是最幸福的人 风都是甜的! 哪成想... 刚到家就被家长扣下了 “”禁止未成年人玩游戏机 (问过卖家了&a…...

那为什么 async 函数最终返回的是一个新的 Promise?
async 函数的设计就是这样的:无论你返回什么值,它都会自动被包装为一个 Promise 对象。这就是为什么说 async 函数最终返回的是一个新的 Promise 对象。 当你在 async 函数中使用 return 语句返回一个值时,这个值会成为最终返回的 Promise 对…...

Java的泛型
泛型 泛型又称参数化类型,是Jdk5.0出现的新特性,解决数据类型的安全性问题 在类声明或实例化时只要指定好需要的具体的类型即可 Java泛型可以保证如果程序在编译时没有发出警告,运行时就不会产生ClassCastException异常。同时,代码更加简洁…...
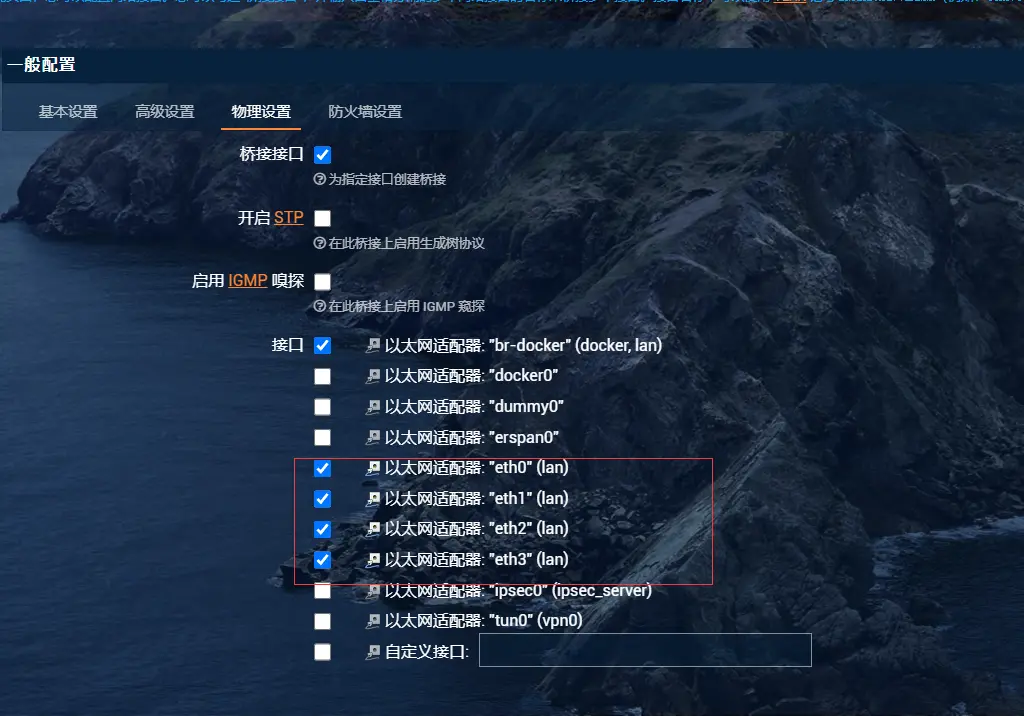
pve和openwrt以及我的电脑中网络的关系和互通组网
情况1 一台主机 有4个口,分别eth0,eth1,eth2,eth3 pve有管理口 这个情况下 ,没有openwrt 直接电脑和pve管理口连在一起就能进pve管理界面 情况2 假设pve 的管理口味eth0 openwrt中桥接的是eth0 eth1 eth2 那么电脑连接eth3或者pve管理口设置eth3…...

TypeScript学习笔记
1.ts和js的区别 2. ts的优势 3. ts下载后报错解决方法 报错: PS C:\Users\\Desktop> tsc -v tsc : 无法加载文件 C:\Users\32173\AppData\Roaming\npm\tsc.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/ go.microsoft.com/fwlink/?…...
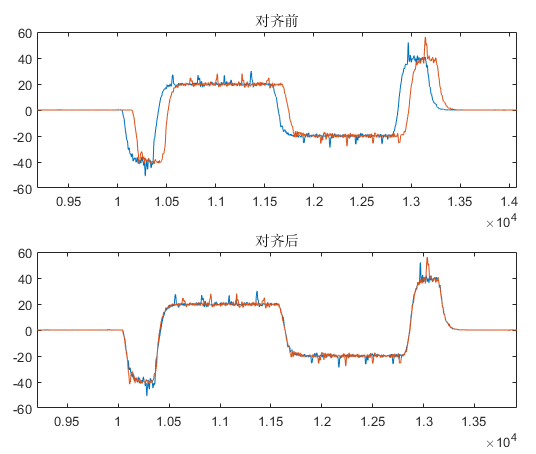
MATLAB实现两组数据的延时对齐效果
博主在某次实验中,相同的实验条件下分别采集了两组数据,发现两组数据存在一个延时,如下图所示: 本文记录消除这个延时,实现相同数据状态的对齐效果,采用MATLAB自带的xcorr函数实现,具体步骤如下…...
基于Spring Boot的网络在线学习网站的设计与实现(Java+spring boot+MySQL)
获取源码或者论文请私信博主 演示视频: 基于Spring Boot的网络在线学习网站的设计与实现(Javaspring bootMySQL) 使用技术: 前端:html css javascript jQuery ajax thymeleaf 微信小程序 后端:Java spri…...

Is a directory: ‘outs//.ipynb_checkpoints‘
提示out/文件夹的.ipynp_chechpoints是一个文件夹,但是打开文件夹却没有看到,可以得知他是一个隐藏文件夹,进入outs/文件夹,使用 ls -a可以看到所有文件 果然出现这个文件夹,但是我们这个outs/文件夹存放的是图片&am…...

PintOS lab2 User Programs 实验记录
Background 大体流程如下图所示,显然这时候start_process无法被调度到。 然后start_process 里面load .out文件 (.o文件就是对象文件,是可重定向文件的一种,通常以ELF格式保存,里面包含了对各个函数的入口标记,描述,…...

『CV学习笔记』docker和nvidia-docker离线安装
docker和nvidia-docker离线安装 文章目录 1. docker的deb包下载链接2. nvidia-docker 的deb包下载3. 重启 docker4. 检验安装5. Docker容器命令行不支持Tab键命令自动补全6. 参考文献这里是ubuntu操作系统, 如果是其他的操作系统,则需要安装对应的deb包1. docker的deb包下载链…...

使用JavaScript实现页面滑动切换效果
使用JavaScript实现页面滑动切换效果 在现代Web页面设计中,页面滑动切换效果已经成为了一种常见的设计要求,能够提升用户体验,增加页面的交互性。本文将通过JavaScript来实现这一效果。 首先,我们需要在HTML中添加一些基础结构和…...

react中的formik如何使用
介绍: Formik 是一个用于处理表单状态和验证的 React 库。它提供了一种简化和统一的方式来处理复杂的表单逻辑,包括表单值的管理、表单验证、表单提交和错误处理等。 使用 安装 Formik 和 Yup(用于表单验证): // ba…...

MYSQL储存过程
一、概念及形式 存储过程就是作为可执行对象存放在数据库中的一个或多个SQL命令,通俗来讲存储过程其实就是能完成一定操作的一组SQL语句。 1、自定义语句结束符 DELIMITER $$ 2、创建 使用CREATE动作及PROCEDURE关键字进行过程创建,一般格式为&…...
fastadmin、vue、react图标库适用于多种框架
在二开fastadmin中,在写vue以及react时,侧边导航栏以及按钮中常常需要很多图标,那么这些图标应该去哪里得到呢,在这里给大家一个链接,这里有丰富的图标库,可以找到自己想要的进行使用。 点击下方链接&…...

篇七:桥接模式:连接抽象和实现
篇七:“桥接模式:连接抽象和实现” 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料,…...

STL容器适配器 -- stack和queue(使用+实现)(C++)
stack和queue stackstack的介绍stack的使用stack的实现 queuequeue的介绍queue的使用queue的实现 deque简单介绍deque(双端队列)双开口连续打引号的原因 deque底层结构deque的迭代器封装结构(复杂)deque的优缺点 栈和队列数据结构…...

K8s operator从0到1实战
Operator基础知识 Kubernetes Operator是一种用于管理和扩展Kubernetes应用程序的模式和工具。它们是一种自定义的Kubernetes控制器,可以根据特定的应用程序需求和业务逻辑扩展Kubernetes功能。 Kubernetes Operator基于Kubernetes的控制器模式,通过自…...

避开滑模控制的5个大坑:从切换函数设计到抖振抑制的避坑指南
避开滑模控制的5个大坑:从切换函数设计到抖振抑制的避坑指南 滑模控制因其强鲁棒性和对参数变化的不敏感性,已成为非线性控制领域的重要工具。但在实际工程应用中,许多开发者常陷入一些典型陷阱,导致系统性能下降甚至失控。本文将…...
)
【限时解禁】某自动驾驶大模型在线学习模块源码片段(含动态LoRA路由+时间敏感缓存淘汰算法)
第一章:大模型工程化中的在线学习机制 2026奇点智能技术大会(https://ml-summit.org) 在线学习机制是大模型从静态部署走向动态演化的关键桥梁,它使模型能在生产环境中持续吸收新数据、响应分布偏移,并在不中断服务的前提下完成参数更新。与…...

Behaviac终极指南:掌握游戏AI行为树的7个实用技巧
Behaviac终极指南:掌握游戏AI行为树的7个实用技巧 【免费下载链接】behaviac behaviac is a framework of the game AI development, and it also can be used as a rapid game prototype design tool. behaviac supports the behavior tree, finite state machine …...

【AI应用】NotebookLM与Prompt工程:打造高效知识管理与创意生成工作流
1. 当知识管理遇上AI:NotebookLM的核心价值 每天打开电脑,你是不是也和我一样面对几十个浏览器标签页、十几个未整理的文档和无数碎片化笔记感到头疼?信息爆炸时代最痛苦的莫过于:明明资料都在手边,却像散落的拼图怎么…...

手把手教你用Cursor的.cursorrules文件,定制你的专属Python/React开发AI伙伴
用.cursorrules文件打造你的智能编程伙伴:Python/React开发者的终极配置指南 在当今快节奏的软件开发环境中,AI编程助手已经成为提升效率的必备工具。而Cursor作为其中的佼佼者,其真正的威力往往被大多数开发者所低估——通过精心设计的.curs…...

显示器“刷新率”的实战选择指南
1. 刷新率的基础认知:从翻书动画到电竞屏 第一次接触"刷新率"这个概念时,我正对着两台显示器纠结不已。左边是标注着60Hz的普通办公屏,右边是144Hz的电竞显示器,价格相差三倍。销售员反复强调"高刷屏更流畅"&…...

前端使用AI试水报告旁
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-temp…...

BetterNCM Installer终极指南:高效构建网易云插件生态的专业工具
BetterNCM Installer终极指南:高效构建网易云插件生态的专业工具 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 在数字音乐体验日益个性化的今天,网易云音乐用…...

2026年4月 AI编程技术热点:一场关于生产力的深度审视
一、事件聚焦:Claude Code 源码泄露始末📦 2026年4月科技圈最大"瓜" —— 不是AI突破,而是一次人为失误发生了什么Anthropic 在向 NPM 发布 Claude Code 安装包时,不小心把 51.2万行源代码 全部打包进去。任何人执行 np…...
)
Windows11下VSCode配置C/C++开发环境避坑指南(附完整配置文件)
Windows 11下VSCode配置C/C开发环境全流程解析 最近在帮几位刚接触编程的朋友配置Windows 11下的C/C开发环境时,发现即便是照着教程一步步操作,也总会遇到各种"坑"。作为一个从Visual Studio转战VSCode的老码农,我深知配置过程中的…...