CNN成长路:从AlexNet到EfficientNet(02)
一、说明
在~10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。
二、第一阶段
见文:CNN成长路:从AlexNet到EfficientNet(01)
三、第二阶段:近代CNN
3.1 DenseNet: Densely Connected Convolutional Networks (2017)
跳过连接是一个非常酷的主意。我们为什么不跳过连接所有内容?
Densenet是将这种想法推向极端的一个例子。当然,与 ResNets 的主要区别在于我们将连接而不是添加特征图。
因此,其背后的核心思想是功能重用,这导致了非常紧凑的模型。因此,它比其他CNN需要更少的参数,因为没有重复的特征图。
好吧,为什么不呢?嗯......这里有两个问题:
-
特征映射的大小必须相同。
-
与所有先前特征映射的串联可能会导致内存爆炸。
为了解决第一个问题,我们有两个解决方案:
a) 使用具有适当填充的 conv 图层来保持空间暗淡或
b) 仅在称为密集块的块内使用密集跳过连接。
示例图像如下所示:
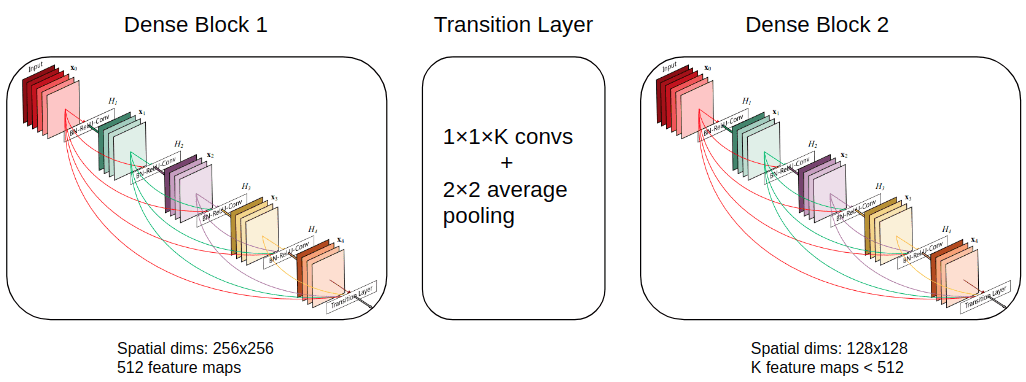
过渡层可以使用平均池化对图像尺寸进行下采样。
为了解决第二个问题,即内存爆炸,特征图通过 1x1 convs 减少(一种压缩)。请注意,我在图中使用了 K,但 densenet 使用�=��一个��一个��/2K=Fe a tmaps/2
此外,当不使用数据增强时,它们在每个卷积层后添加一个 p=0.2 的 dropout 层。
3.2 增长率
更重要的是,还有一个参数控制整个架构的特征图数量。这是增长率。它指定每个超密集卷积层的输出特征。鉴于k0初始特征图和k增长率,可以计算出每层输入特征图的数量l如
.在框架中,数字 k 是 4 的倍数,称为瓶颈大小 (bn_size)。
最后,我在这里引用DenseNet在火炬视觉中最重要的论点作为总结:
import torchvisionmodel = torchvision.models.DenseNet(growth_rate = 16, # how many filters to add each layer (`k` in paper)block_config = (6, 12, 24, 16), # how many layers in each pooling blocknum_init_features = 16, # the number of filters to learn in the first convolution layer (k0)bn_size= 4, # multiplicative factor for number of bottleneck (1x1 cons) layersdrop_rate = 0, # dropout rate after each dense conv layernum_classes = 30 # number of classification classes
)print(model) # see snapshot below在“密集”层(快照中的密集层5和6)内部,有一个瓶颈(1x1)层,将通道减少到bn_size∗growth_rate=64bn_size∗growth_rate=64在我们的例子中。否则,输入通道的数量将激增。如下图所示,每层加起来16=growth_rate16=growth_rate渠道。

在实践中,我发现基于 DenseNet 的模型训练速度很慢,但由于功能重用,与具有竞争力的模型相比,参数很少。
尽管DenseNet被提议用于图像分类,但它已被用于特征可重用性更为关键的领域的各种应用(即分割和医学成像应用)。从 Papers with Code 借来的饼图说明了这一点:
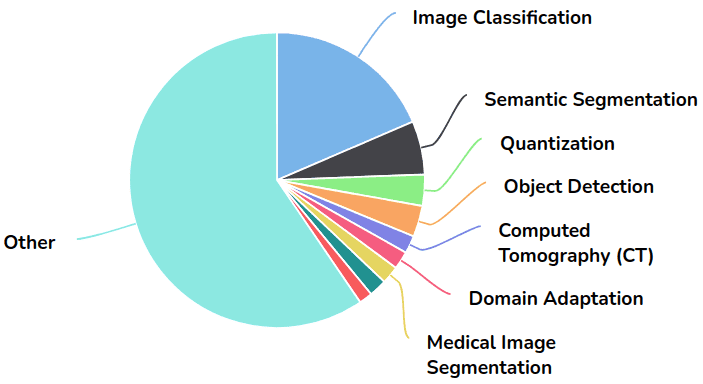
图片来自带有代码的论文
在 2017 年的 DenseNet 之后,我只发现 HRNet 架构很有趣,直到 2019 年 EfficientNet 问世!
3.3 大迁移(Big Transfer-BiT):一般视觉表示学习(2020)
尽管已经提出了许多ResNet的变体,但最新和最著名的是BiT。大转移(BiT)是一种可扩展的基于ResNet的模型,用于有效的图像预训练[5]。
他们基于 ResNet3 开发了 152 个 BiT 模型(小型、中型和大型)。对于BiT的大变化,他们使用ResNet152x4,这意味着每层都有4倍的通道。他们在比imagenet更大的数据集中对模型进行了一次预训练。最大的模型是在疯狂庞大的JFT数据集上训练的,该数据集由300M标记的图像组成。
该架构的主要贡献是规范化层的选择。为此,作者用组归一化(GN)和权重标准化(WS)取代了批次归一化(BN)。

图片来源:Lucas Beyer和Alexander Kolesnikov。源
为什么?因为第一个BN的参数(均值和方差)需要在预训练和转移之间进行调整。另一方面,GN 不依赖于任何参数状态。另一个原因是 BN 使用批处理级统计信息,这对于像 TPU 这样的小型设备的分布式训练变得不可靠。分布在 4 个 TPU 上的 500K 批次意味着每个工人有 8 个批次,这并不能很好地估计统计数据。通过将规范化技术更改为 GN+WS,它们避免了工作线程之间的同步。
显然,扩展到更大的数据集与模型大小密切相关。

资料来源:亚历山大·科列斯尼科夫等人,2020
在此图中,说明了与数据并行扩展体系结构的重要性。ILSVER是具有1M图像的Imagenet数据集,ImageNet-21K具有大约14M图像,JFT 300M!
最后,这种大型预训练模型可以微调到非常小的数据集,并获得非常好的性能。
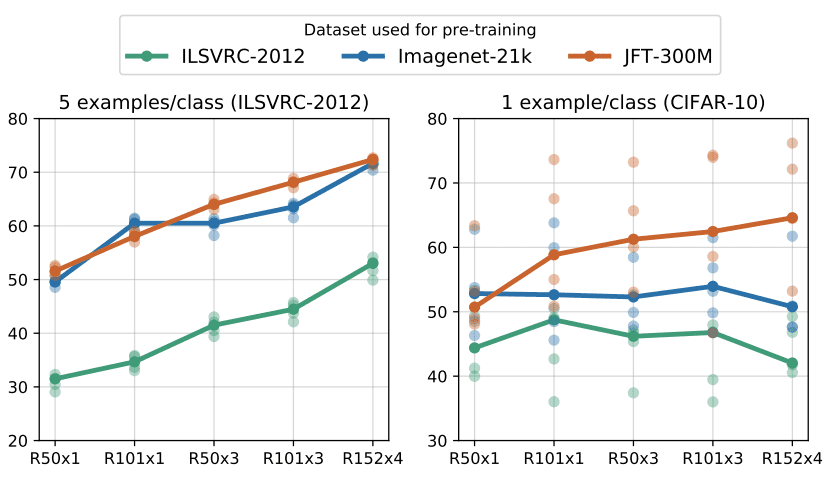
资料来源:亚历山大·科列斯尼科夫等人,2020
在 ImageNet 上每个类有 5 个示例,将 3 倍扩大,在 JFT 上预训练的 ResNet-50 (x3) 实现了与 AlexNet 相似的性能!
3.4 EfficientNet:重新思考卷积神经网络的模型缩放(2019)
EfficientNet是关于工程和规模的。它证明,如果您仔细设计架构,则可以使用合理的参数获得最佳结果。

来源:EfficientNet:重新思考卷积神经网络的模型缩放
该图演示了 ImageNet 精度与模型参数。
令人难以置信的是,EfficientNet-B1比ResNet-7小6.5倍,快7.152倍。
3.5 个性化升级
让我们了解这是如何实现的。
-
有了更多的层(深度),人们可以捕获更丰富和更复杂的特征,但这样的模型很难训练(由于梯度消失)
-
更广泛的网络更容易训练。它们往往能够捕获更细粒度的特征,但很快就会饱和。
-
通过训练更高分辨率的图像,卷积神经网络理论上能够捕获更细粒度的细节。同样,对于相当高的分辨率,精度增益会降低
作者没有找到最好的架构,而是建议从一个相对较小的基线模型开始。F并逐渐扩展它。
这缩小了设计空间。为了进一步限制设计空间,作者将所有层限制为具有恒定比率的均匀缩放。这样,我们就有了一个更易于处理的优化问题。最后,必须尊重我们基础设施的最大内存和 FLOP 数量。
下图很好地演示了这一点:

图片来源:Mingxing Tan和Quoc V. Le 2020。来源:EfficientNet:重新思考卷积神经网络的模型缩放
w是宽度,d深度,以及r分辨率缩放因子。通过缩放一个,它们中只有一个会在一个点上饱和。我们能做得更好吗?
3.5 复合缩放
因此,让我们同时放大网络深度(更多层)、宽度(每层更多通道)、分辨率(输入图像)。这称为复合缩放。
为此,我们必须在缩放过程中平衡上述所有维度。在这里,它变得令人兴奋。
这样:α⋅β2⋅γ2≈2,给定所有α,β,γ>1
现在φ控制所有所需的尺寸并将它们缩放在一起,但不能相等。α,β,γ告诉我们如何将额外的资源分配到网络。
注意到什么奇怪的东西了吗?β和γ在约束中平方。
原因很简单:网络深度加倍将使 FLOPS 翻倍,但宽度或输入分辨率加倍将使 FLOPS 增加四倍。通过这种方式,我们类似于卷积,这是基本的构建块。
基线架构是使用神经架构搜索找到的,因此它可以优化准确性和FLOPS,称为EfficientNet-B0。
还行,很酷。剩下的就是定义α,β,γ和φ.
-
修复φ=1,假设还有两次可用的资源,并执行网格搜索α,β,γ.EfficientNet-B0的最佳获取值是α=1.2,β=1.2,γ=1.15
-
修复α,β,γ并扩大规模φ关于硬件(FLOP + 内存)
在我看来,理解复合缩放有效性的最直观方法与 ImageNet 上相同基线模型 (EfficientNet-B0) 的单个缩放相当:
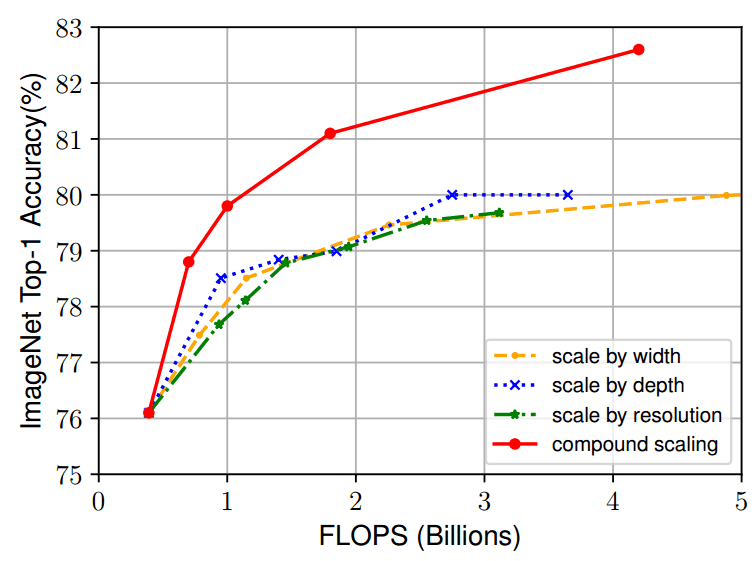
图片来源:Mingxing Tan和Quoc V. Le 2020。来源:EfficientNet:重新思考卷积神经网络的模型缩放
3.6 与吵闹的学生进行自我训练改进了图像网络分类(2020 年)
不久之后,使用了迭代半监督方法。它通过300亿张未标记的图像显着提高了Efficient-Net的性能。作者称培训计划为“嘈杂的学生培训” [8]。它由两个神经网络组成,称为教师和学生。迭代训练方案可以用 4 个步骤来描述:
-
在标记的图像上训练教师模型,
-
使用老师在300M未标记的图像上生成标签(伪标签))
-
在标记图像和伪标记图像的组合上训练学生模型。
-
从步骤 1 开始迭代,将学生视为教师。重新推断未标记的数据并从头开始培训新学生。
新学生模型通常大于教师模型,因此可以从更大的数据集中受益。此外,在训练学生模型时添加了明显的噪声,因此它被迫从伪标签中学习。
伪标签通常是软标签(连续分布)而不是硬标签(独热编码)。
此外,辍学和随机深度等不同的技术被用来训练新生[8]。
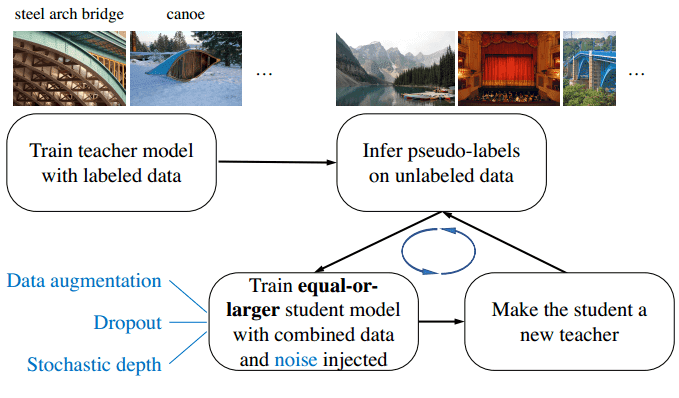
图片来源:Xizhe Xie et al. 来源:Noisy Student 的自我训练改进了 ImageNet 分类
在步骤 3 中,我们使用标记和未标记的数据联合训练模型。未标记的批大小在第一次迭代中设置为标记批大小的 14 倍,在第二次迭代中设置为 28 倍。
3.7 元伪标签 (2021)
动机:如果伪标签不准确,学生不会超过老师。这在伪标记方法中称为确认偏差。
高层次的思想:设计一个反馈机制来纠正教师的偏见。
观察结果来自伪标签如何影响学生在标记数据集上的表现。反馈信号是训练教师的奖励,类似于强化学习技术。
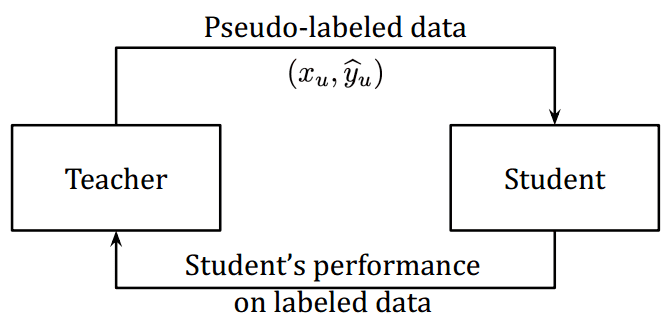
Hieu Pham等人,2020年。来源:元伪标签
这样,教师和学生就得到了共同的训练。教师从奖励信号中了解学生在来自标记数据集的一批图像上的表现。
3 总结和概括
那里有很多凸网!我们可以通过查看下表来总结它们:
| 型号名称 | 参数数量 [百万] | 图像网前 1 名精度 | 年 |
| 亚历克斯网 | 60 米 | 63.3 % | 2012 |
| 盗梦空间 V1 | 5 米 | 69.8 % | 2014 |
| VGG 16 | 138 米 | 74.4 % | 2014 |
| VGG 19 | 144 米 | 74.5 % | 2014 |
| 盗梦空间 V2 | 11,2 米 | 74.8 % | 2015 |
| 瑞思网-50 | 26 米 | 77.15 % | 2015 |
| 瑞思网-152 | 60 米 | 78.57 % | 2015 |
| 盗梦空间 V3 | 27 米 | 78.8 % | 2015 |
| 密集网-121 | 8 米 | 74.98 % | 2016 |
| 密集网-264 | 22. | 77.85 % | 2016 |
| BiT-L (ResNet) | 928 米 | 87.54 % | 2019 |
| 嘈杂学生高效网-L2 | 480 米 | 88.4 % | 2020 |
| 元伪标签 | 480 米 | 90.2 % | 2021 |
您可以注意到DenseNet模型的紧凑性。或者最先进的EfficientNet有多大。更多的参数并不总是能保证更高的精度,正如您在BiT和VGG中看到的那样。
在本文中,我们提供了最著名的深度学习架构背后的一些直觉。话虽如此,继续前进的唯一方法就是练习!从火炬视导入模型并根据您的数据对其进行微调。它是否比从头开始训练提供更好的准确性?
下一步是什么?使用深度学习为计算机视觉系统提供可靠而全面的方法。试一试!使用折扣代码 aisummer35 从您最喜欢的 AI 博客中获得独家 35% 的折扣。使用折扣代码 aisummer35 从您最喜欢的 AI 博客中获得独家 35% 的折扣。如果您更喜欢视觉课程,Andrew Ng的卷积神经网络是迄今为止最好的课程。
4 引用
[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017).使用深度卷积神经网络进行图像网络分类。ACM的通讯,60(6),84-90。
[2] Simonyan, K., & Zisserman, A. (2014).用于大规模图像识别的非常深的卷积网络。arXiv预印本arXiv:1409.1556。
[3] 塞格迪, C., 刘, W., 贾, Y., Sermanet, P., Reed, S., Anguelov, D., ...&Rabinovich, A. (2015).更深入地进行卷积。在IEEE计算机视觉和模式识别会议记录中(第1-9页)。
[4] He, K., Zhang, X., Ren, S., & Sun, J. (2016).用于图像识别的深度残差学习。IEEE计算机视觉和模式识别会议论文集(第770-778页)。
[5] Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., & Houlsby, N. (2019).大迁移(位):一般视觉表示学习。arXiv预印本arXiv:1912.11370,6(2)
[6] Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017).密集连接的卷积网络。IEEE计算机视觉和模式识别会议论文集(第4700-4708页)。
[7] Tan, M., & Le, Q. V. (2019).高效网络:重新思考卷积神经网络的模型缩放。arXiv预印本arXiv:1905.11946。
[8] Xie, Q., Luong, M. T., Hovy, E., & Le, Q. V. (2020).与嘈杂的学生进行自我训练可改进图像网分类。在IEEE/CVF计算机视觉和模式识别会议记录中(第10687-10698页)。
[9] Pham, H., Xie, Q., Dai, Z., & Le, Q. V. (2020).元伪标签。arXiv预印本arXiv:2003.10580。
[10] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016).重新思考计算机视觉的初始架构。IEEE计算机视觉和模式识别会议论文集(第2818-2826页)。
相关文章:
CNN成长路:从AlexNet到EfficientNet(02)
一、说明 在~10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。 二、第一阶段 …...

【Kubernetes】yaml文件格式
目录 YAML 语法格式: 查看 api 资源版本标签 写一个yaml文件demo 创建资源对象 查看创建的pod资源 创建service服务对外提供访问并测试 创建资源对象 查看创建的service 在浏览器输入 nodeIP:nodePort 即可访问 kubectl run --dry-runclient 打印相应的 A…...

Python web实战之Django的文件上传和处理详解
概要 关键词:Python Web开发、Django、文件上传、文件处理 今天分享一下Django的文件上传和处理。 1. 上传文件的基本原理 在开始深入讲解Django的文件上传和处理之前,先了解一下文件上传的基本原理。当用户选择要上传的文件后,该文件会被发…...

android res中values-swxxdp计算
一. res中values-swxxdp计算 以四寸中控面板为例 通过adb shell wm size获取屏幕大小为1264x1680 通过adb shell wm density获取屏幕显示密度dpi为300 最小宽度计算方法:s w 160 ∗ 手机宽度像素 / d p i sw160*手机宽度像素/dpisw160∗手机宽度像素/dpi 过公式…...

c动态内存申请
动态分配内存概述 先说数组的长度是预定义好的,固定不变的。但是呢,实际上所需的内存空间取决于实际输入的数据,而无法预先确定。所以根据实际情况,推出了内存管理函数。这些内存管理函数可以按需要动态分配内存空间,…...

C#8.0本质论第一章--C#概述
C#8.0本质论第一章–C#概述 朋友推荐的一本讲C#的书–C#本质论,英文叫Essential C#,官网可以免费看英文版的https://essentialcsharp.com/home。 C#可以为各种不同的系统平台开发应用软件和程序组件,支持移动设备,游戏主机&…...
geoserver编辑样式 【开发工具QGis的初次使用】
geoserver编辑样式 开发工具配置中文语言 geoserver样式的更改 开发工具 链接: geoserver样式style的更改 链接: QGis开发工具的安装及使用 配置中文语言 setting > options > general > 中文 geoserver样式的更改 链接: geoserver样式style的更改 利用QGIs Q…...
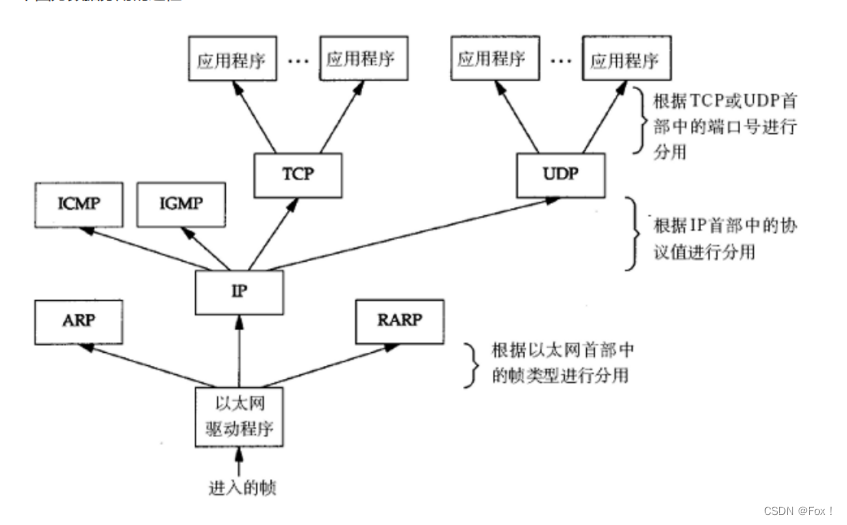
【网络基础知识铺垫】
文章目录 1 :peach:计算机网络背景:peach:1.1 :apple:网络发展:apple: 2 :peach:协议:peach:2.1 :apple:协议分层:apple:2.2 :apple:OSI七层模型:apple:2.3 :apple:TCP/IP模型:apple:2.4 :apple:TCP/IP模型与操作系统的关系:apple: 3 :peach:网络传输基本流程:peach:4 :peach:网…...

一个利用oracle异常处理的函数
函数主体如下: CREATE OR REPLACE FUNCTION fn_get_agmt_bal(p_agmt_no varchar2) RETURN NUMBER ISv_bal NUMBER : 0;--在SQL/PLUS中执行时,若合dbms_output生效,需先执行【SET SERVEROUTPUT ON】; BEGINselect agmt_balinto v_balfrom edw…...
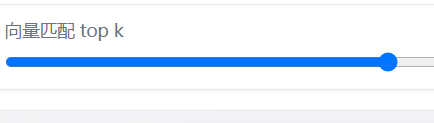
langchain-ChatGLM源码阅读:参数设置
文章目录 上下文关联对话轮数向量匹配 top k控制生成质量的参数参数设置心得 上下文关联 上下文关联相关参数: 知识相关度阈值score_threshold内容条数k是否启用上下文关联chunk_conent上下文最大长度chunk_size 其主要作用是在所在文档中扩展与当前query相似度较高…...

什么是Java中的工厂模式?
工厂模式(Factory Pattern)是一种常见的设计模式,它可以帮助我们简化对象创建的过程,将对象的创建与使用分离,提高代码的可维护性和可扩展性。在Java中,工厂模式通常分为简单工厂模式(Simple Fa…...
数据库--MySQL
一、什么是范式? 范式是数据库设计时遵循的一种规范,不同的规范要求遵循不同的范式。 最常用的三大范式 第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列) 第二范式(2NF):满足…...
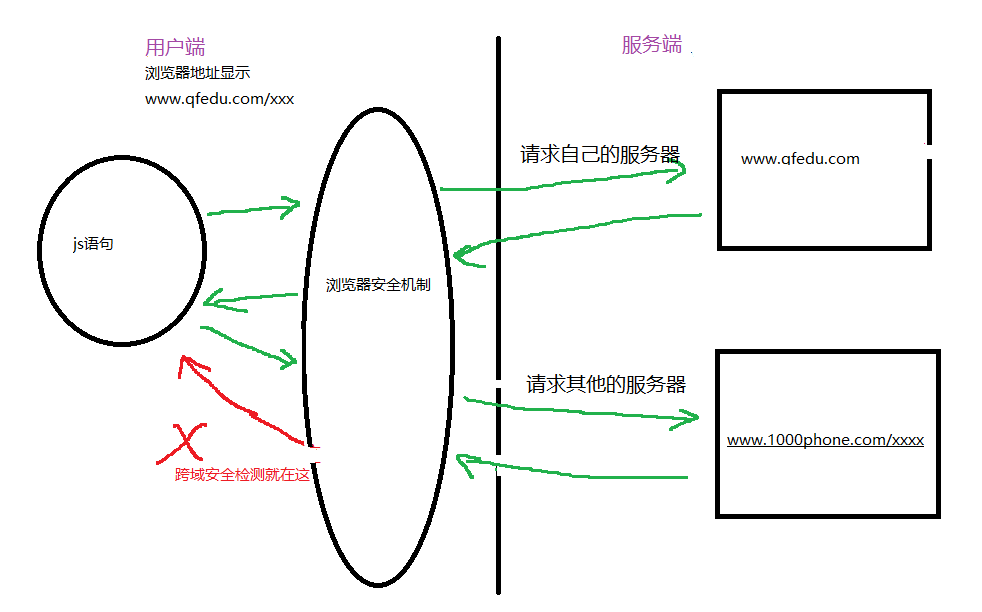
浏览器多管闲事之跨域
年少时的梦想就是买一台小霸王游戏机 当时的宣传语就是小霸王其乐无穷~。 大些了,攒够了零花钱,在家长的带领下终于买到了 那一刻我感觉就是最幸福的人 风都是甜的! 哪成想... 刚到家就被家长扣下了 “”禁止未成年人玩游戏机 (问过卖家了&a…...

那为什么 async 函数最终返回的是一个新的 Promise?
async 函数的设计就是这样的:无论你返回什么值,它都会自动被包装为一个 Promise 对象。这就是为什么说 async 函数最终返回的是一个新的 Promise 对象。 当你在 async 函数中使用 return 语句返回一个值时,这个值会成为最终返回的 Promise 对…...

Java的泛型
泛型 泛型又称参数化类型,是Jdk5.0出现的新特性,解决数据类型的安全性问题 在类声明或实例化时只要指定好需要的具体的类型即可 Java泛型可以保证如果程序在编译时没有发出警告,运行时就不会产生ClassCastException异常。同时,代码更加简洁…...
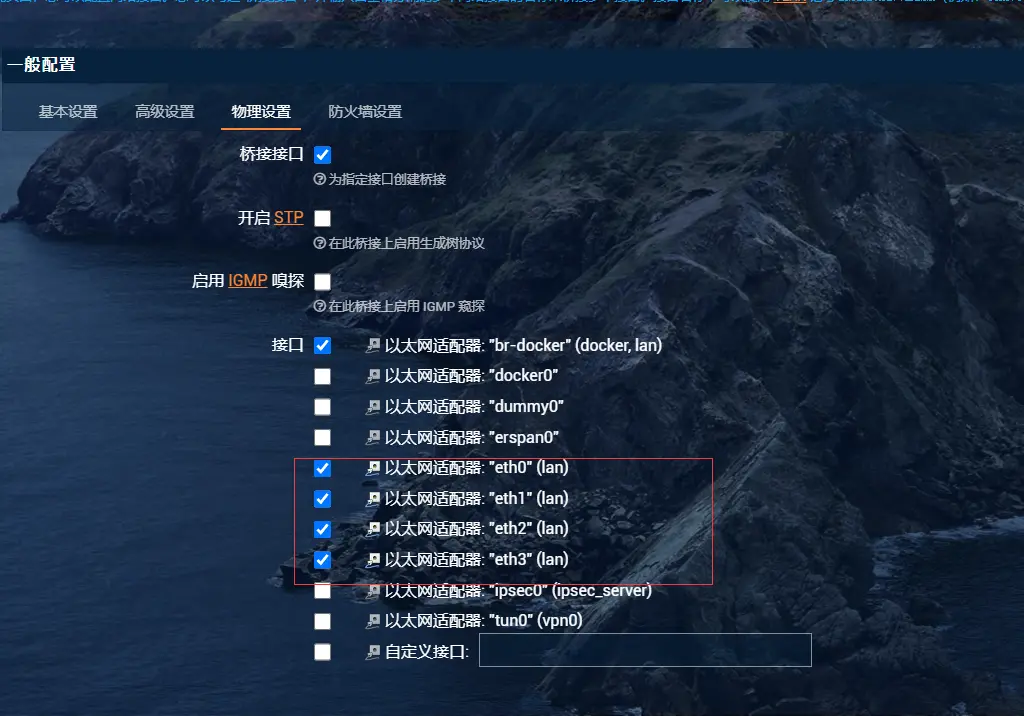
pve和openwrt以及我的电脑中网络的关系和互通组网
情况1 一台主机 有4个口,分别eth0,eth1,eth2,eth3 pve有管理口 这个情况下 ,没有openwrt 直接电脑和pve管理口连在一起就能进pve管理界面 情况2 假设pve 的管理口味eth0 openwrt中桥接的是eth0 eth1 eth2 那么电脑连接eth3或者pve管理口设置eth3…...

TypeScript学习笔记
1.ts和js的区别 2. ts的优势 3. ts下载后报错解决方法 报错: PS C:\Users\\Desktop> tsc -v tsc : 无法加载文件 C:\Users\32173\AppData\Roaming\npm\tsc.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/ go.microsoft.com/fwlink/?…...
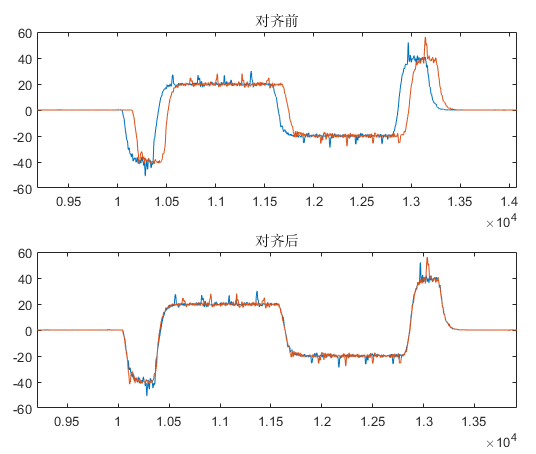
MATLAB实现两组数据的延时对齐效果
博主在某次实验中,相同的实验条件下分别采集了两组数据,发现两组数据存在一个延时,如下图所示: 本文记录消除这个延时,实现相同数据状态的对齐效果,采用MATLAB自带的xcorr函数实现,具体步骤如下…...
基于Spring Boot的网络在线学习网站的设计与实现(Java+spring boot+MySQL)
获取源码或者论文请私信博主 演示视频: 基于Spring Boot的网络在线学习网站的设计与实现(Javaspring bootMySQL) 使用技术: 前端:html css javascript jQuery ajax thymeleaf 微信小程序 后端:Java spri…...

Is a directory: ‘outs//.ipynb_checkpoints‘
提示out/文件夹的.ipynp_chechpoints是一个文件夹,但是打开文件夹却没有看到,可以得知他是一个隐藏文件夹,进入outs/文件夹,使用 ls -a可以看到所有文件 果然出现这个文件夹,但是我们这个outs/文件夹存放的是图片&am…...

XCOM 2模组管理终极指南:AML启动器完整教程
XCOM 2模组管理终极指南:AML启动器完整教程 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/xcom2-la…...

【CW32实战】从零到一:MDK环境配置与固件库点亮LED
1. 开发环境准备:MDK安装与固件库获取 第一次接触CW32系列单片机时,环境搭建往往是最让人头疼的环节。我刚开始用CW32F030的时候,光是安装软件就折腾了大半天。下面就把我踩过的坑和验证过的正确方法分享给大家。 首先需要下载MDK开发环境&am…...

系统流程图绘制技巧与Visio实战指南
1. 系统流程图基础与Visio入门 第一次接触系统流程图时,我也被那些奇怪的符号搞得一头雾水。直到接手一个库存管理系统项目,才真正理解这些图形背后的逻辑。系统流程图就像建筑师的蓝图,用标准化符号展示数据在系统中的流动路径。Visio作为流…...
工作原理系列(一))
AI智能体视觉检测系统(TVA)工作原理系列(一)
TVA初探——核心概念与应用场景解析作为企业初级技术人员,在接触AI智能体视觉检测系统(TVA)时,首先需要明确其核心定位、与传统机器视觉的区别,以及在工业场景中的实际应用价值。TVA全称为“Transformer-based Vision …...

Figma中文插件深度解析:如何实现设计工具的无缝本地化体验
Figma中文插件深度解析:如何实现设计工具的无缝本地化体验 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 在当今全球化设计协作环境中,Figma作为领先的云端设计…...

Akagi:雀魂AI助手终极指南 - 从菜鸟到高手的快速成长之路
Akagi:雀魂AI助手终极指南 - 从菜鸟到高手的快速成长之路 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Am…...

Nomic-Embed-Text-V2-MoE集成开发:在IntelliJ IDEA中配置Python模型调试环境
Nomic-Embed-Text-V2-MoE集成开发:在IntelliJ IDEA中配置Python模型调试环境 想试试那个挺火的Nomic-Embed-Text-V2-MoE模型,用它来搞点文本嵌入的应用,结果发现第一步就卡住了?代码在命令行里跑得磕磕绊绊,调试起来更…...

科哥封装Speech Seaco Paraformer:开箱即用,批量处理录音文件实战指南
科哥封装Speech Seaco Paraformer:开箱即用,批量处理录音文件实战指南 你是不是经常被一堆录音文件搞得焦头烂额?会议纪要、访谈记录、课程录音,一个个听下来再整理成文字,半天时间就没了。手动转写不仅效率低&#x…...

庖丁解牛:从Linux内核源码看NandFlash ECC校验的位运算艺术
1. 为什么需要ECC校验 NandFlash作为嵌入式系统中最常用的存储介质之一,其物理特性决定了它存在一定的位翻转概率。想象一下,你正在用笔记本记录重要会议内容,突然发现某个字的笔画出现了错误 - 这就是NandFlash面临的现实问题。位翻转可能由…...

EagleEye快速体验:DAMO-YOLO TinyNAS开箱即用的目标检测
EagleEye快速体验:DAMO-YOLO TinyNAS开箱即用的目标检测 1. 为什么选择EagleEye:工业级目标检测新选择 在工厂质检、安防监控等场景中,传统目标检测方案常常面临两难选择:要么牺牲速度换取精度,要么降低精度追求实时…...