MySql之分库分表
数据库瓶颈
不管是IO瓶颈还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载的活跃连接数的阈值。在业务service来看, 就是可用数据库连接少甚至无连接可用,接下来就可以想象了(并发量、吞吐量、崩溃)。
IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询会产生大量的IO,降低查询速度->分库和垂直分表
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 ->分库
CPU瓶颈
第一种:SQl问题:如SQL中包含join,group by, order by,非索引字段条件查询等,增加CPU运算的操作->SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQl效率低,增加CPU运算的操作。->水平分表。
水平分库

1、概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2、结果:
每个库的结构都一样
每个库中的数据不一样,没有交集
所有库的数据并集是全量数据
3、场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库的情况下。
4、分析:库多了,io和cpu的压力自然可以成倍缓解
水平分表

垂直分库
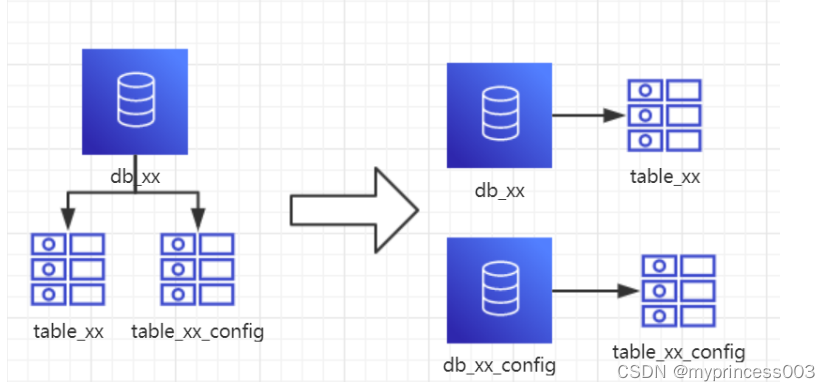
1、概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
2、结果:
每个库的结构都不一样
每个库的数据也不一样,没有交集
所有库的并集是全量数据
3、场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块的情况下。
4、分析:到这一步,基本上就可以服务化了。例如:随着业务的发展,一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再者,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
垂直分表
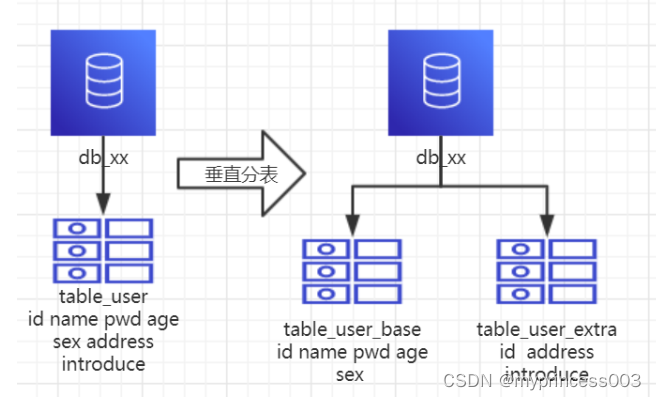
1、概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表中(主表和扩展表)。
2、结果:
每个表的结构不一样。
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据。
所有表的并集是全量数据。 3、场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大,以至于数据库缓存的数据行减少,查询时回去读磁盘数据产生大量随机读IO,产生IO瓶颈。
4、分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能经常会查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表,这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获取全部数据就需要关联两个表来取数据。
但记住千万别用join,因为Join不仅会增加CPU负担并且会将两个表耦合在一起(必须在一个数据库实例上)。关联数据应该在service层进行,分别获取主表和扩展表的数据,然后用关联字段关联得到全部数据。
分库分表工具
sharding-jdbc(当当)
TSharding(蘑菇街)
Atlas(奇虎360)
Cobar(阿里巴巴)
MyCAT(基于Cobar)
Oceanus(58同城)
Vitess(谷歌) 各种工具的利弊自查
分库分表带来的问题
分库分表能有效缓解单机和单表带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来一些问题,下面将描述这些问题和解决思路。
事务一致性问题
分布式事务
当更新内容同时存在于不同库找那个,不可避免会带来跨库事务问题。跨分片事务也是分布式事务,没有简单的方案,一般可使用“XA协议”和“两阶段提交”处理。
分布式事务能最大限度保证了数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间,导致事务在访问共享资源时发生冲突或死锁的概率增高。随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
最终一致性
对于那些性能要求很高,但对一致性要求不高的系统,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。与事务在执行中发生错误立刻回滚的方式不同,事务补偿是一种事后检查补救的措施,一些常见的实现方法有:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等。
跨节点关联查询join问题
切分之前,系统中很多列表和详情表的数据可以通过join来完成,但是切分之后,数据可能分布在不同的节点上,此时join带来的问题就比较麻烦了,考虑到性能,尽量避免使用Join查询。解决的一些方法:
全局表
全局表,也可看做“数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免库join查询,可以将这类表在每个数据库中都保存一份。这些数据通常很少修改,所以不必担心一致性的问题。
字段冗余
一种典型的反范式设计,利用空间换时间,为了性能而避免join查询。例如,订单表在保存userId的时候,也将userName也冗余的保存一份,这样查询订单详情顺表就可以查到用户名userName,就不用查询买家user表了。但这种方法适用场景也有限,比较适用依赖字段比较少的情况,而冗余字段的一致性也较难保证。
数据组装
在系统service业务层面,分两次查询,第一次查询的结果集找出关联的数据id,然后根据id发起器二次请求得到关联数据,最后将获得的结果进行字段组装。这是比较常用的方法。
ER分片
关系型数据库中,如果已经确定了表之间的关联关系(如订单表和订单详情表),并且将那些存在关联关系的表记录存放在同一个分片上,那么就能较好地避免跨分片join的问题,可以在一个分片内进行join。在1:1或1:n的情况下,通常按照主表的ID进行主键切分。
跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现limit分页、order by 排序等问题。分页需要按照指定字段进行排序,当排序字段就是分页字段时,通过分片规则就比较容易定位到指定的分片;当排序字段非分片字段时,就变得比较复杂.需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户如下图:
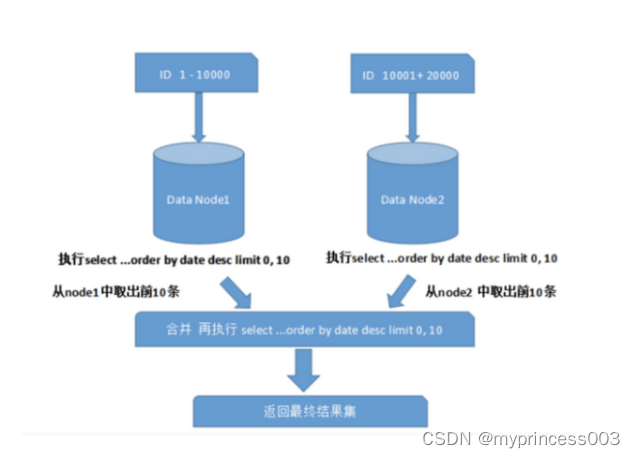
上图只是取第一页的数据,对性能影响还不是很大。但是如果取得页数很大,情况就变得复杂的多,因为各分片节点中的数据可能是随机的,为了排序的准确性,需要将所有节点的前N页数据都排序好做合并,最后再进行整体排序,这样的操作很耗费CPU和内存资源,所以页数越大,系统性能就会越差。
在使用Max、Min、Sum、Count之类的函数进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总再次计算。
方案很多,主流的如下:
数据库自增ID
使用
auto_increment_increment
auto_increment_offset
系统变量让MySQL以期望的值和偏移量来增加auto_increment列的值。
优点
最简单,不依赖于某节点,较普遍采用但需要非常仔细的配置服务器哦!
缺点
单点风险、单机性能瓶颈。不适用于一个节点包含多个分区表的场景。
数据库集群并设置相应步长(Flickr方案)
在一个全局数据库节点中创建一个包含auto_increment列的表,应用通过该表生成唯一数字。
优点
高可用、ID较简洁。
缺点
需要单独的数据库集群。
Redis等缓存NoSQL服务
避免了MySQL性能低的问题。
Snowflake(雪花算法)
优点
高性能高可用、易拓展。
缺点
需要独立的集群以及ZK。
各种GUID、Random算法
优点
简单。
缺点
生成ID较长,且有重复几率。
业务字段(美团的实践方案)
为减少运营成本并减少额外风险,美团排除了所有需要独立集群的方案,采用了带有业务属性的方案: 时间戳+用户标识码+随机数
优点:
方便、成本低
基本无重复的可能
自带分库规则,这里的用户标识码即为userID的后四位,在查询场景,只需订单号即可匹配到相应库表而无需用户ID,只取四位是希望订单号尽可能短,评估后四位已足。
可排序,因为时间戳在最前
缺点
长度稍长,性能要比int/bigint的稍差。
数据迁移、扩容问题
当业务高速发展、面临性能和存储瓶颈时,才会考虑分片设计,此时就不可避免的需要考虑历史数据的迁移问题。一般做法是先读出历史数据,然后按照指定的分片规则再将数据写入到各分片节点中。此外还需要根据当前的数据量个QPS,以及业务发展速度,进行容量规划,推算出大概需要多少分片(一般建议单个分片的单表数据量不超过1000W)
什么时候考虑分库分表
能不分就不分
并不是所有表都需要切分,主要还是看数据的增长速度。切分后在某种程度上提升了业务的复杂程度。不到万不得已不要轻易使用分库分表这个“大招”,避免“过度设计”和“过早优化”。分库分表之前,先尽力做力所能及的优化:升级硬件、升级网络、读写分离、索引优化等。当数据量达到单表瓶颈后,在考虑分库分表。
数据量过大,正常运维影响业务访问
这里的运维是指:
对数据库备份,如果单表太大,备份时需要大量的磁盘IO和网络IO
对一个很大的表做DDL,MYSQL会锁住整个表,这个时间会很长,这段时间业务不能访问此表,影响很大。
大表经常访问和更新,就更有可能出现锁等待。
随着业务发展,需要对某些字段垂直拆分
这里就不举例了。在实际业务中都可能会碰到,有些不经常访问或者更新频率低的字段应该从大表中分离出去。
数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。
相关文章:
MySql之分库分表
数据库瓶颈 不管是IO瓶颈还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载的活跃连接数的阈值。在业务service来看, 就是可用数据库连接少甚至无连接可用,接下来就可以想象了(并发量、吞…...
数据结构—图的遍历
6.3图的遍历 遍历定义: 从已给的连通图中某一顶点出发,沿着一些边访问遍历图中所有的顶点,且使每个顶点仅被访问一次,就叫作图的遍历,它是图的基本运算。 遍历实质:找每个顶点的邻接点的过程。 图的…...

MySQL主从复制基于二进制日志的高可用架构指南
前言 在现代数据库架构中,MySQL主从复制技术扮演着重要角色。它不仅可以提升数据库性能和可扩展性,还赋予系统卓越的高可用性和灾难恢复能力。本文将深入剖析MySQL主从复制的内部机制,同时通过一个实际案例,展示其在实际场景中的…...

RestTemplate HTTPS请求忽略SSL证书
问题描述 使用RestTemplate发送HTTPS请求的时候,出现了这样的一个问题: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification …...
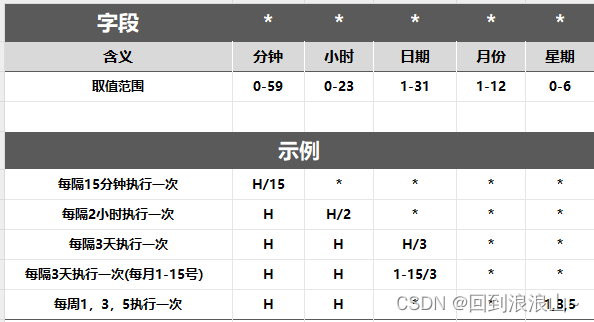
Jenkins触发器时间、次数设定
触发器触发条件介绍 触发器触发条件公式:由5颗星组成 * * * * * 分别代表:分钟(0-59) 小时(0-23) 日期(1-31) 月份(1-12) 星期(0-6) 企业项目中常用场景介绍 场景1:接口脚本部分测试通过,部分还在进行,回归测试脚本执行…...

kafka partition的数据文件(offffset,MessageSize,data)
partition中的每条Message包含了以下三个属性: offset,MessageSize,data,其中offset表示Message在这个partition中的偏移量,offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值&…...

htnl根据轮播图图片切换背景色
htnl根据轮播图图片切换背景色 <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>轮播图示例</title><link rel"stylesheet" href"https://cdn.jsdelivr.net/npm/swiper10/swiper-bundle.min.css&q…...
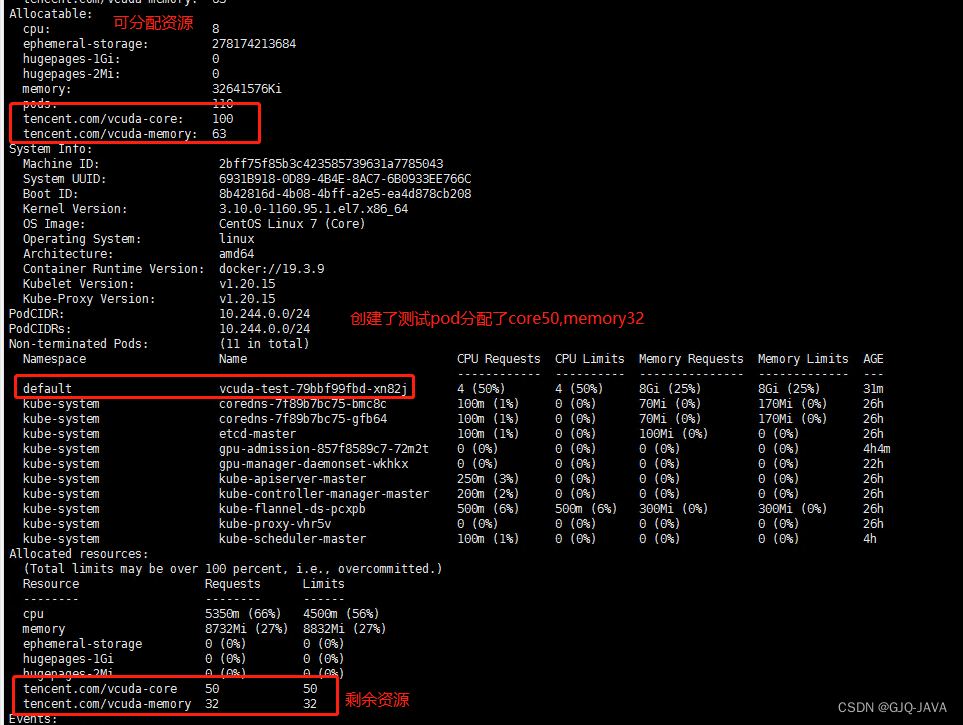
gpu-manager安装及测试
提示:GPU-manager安装为主部分内容做了升级开箱即用,有用请点收藏❤抱拳 文章目录 前言一、约束条件二、使用步骤1.下载镜像1.1 查看当前虚拟机的驱动类型: 2.部署gpu-manager3.部署gpu-admission4.修改kube-scheduler.yaml
Go和Java实现享元模式
Go和Java实现享元模式 下面通过一个实例来说明享元模式的使用。 1、享元模式 享元模式主要用于减少创建对象的数量,以减少内存占用和提高性能。这种类型的设计模式属于结构型模式,它提 供了减少对象数量从而改善应用所需的对象结构的方式。 享元模式…...
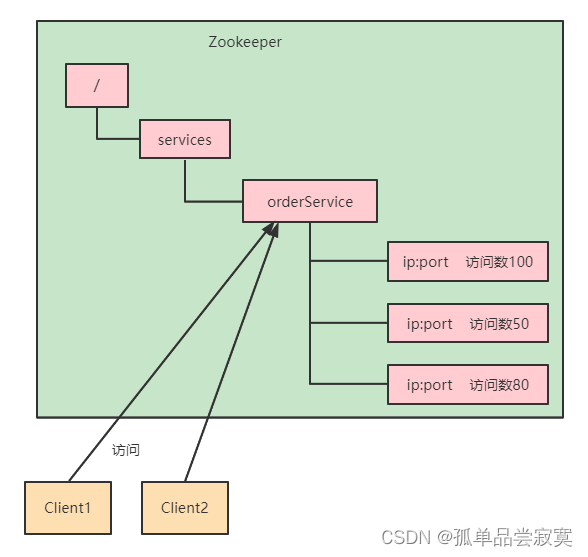
Zookeeper特性与节点数据类型详解
CAP&Base理论 CAP理论 cap理论是指对于一个分布式计算系统来说,不可能满足以下三点: 一致性 : 在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的 特性,等同于所有节点访问同一份最新的数据副本。在一致性的需…...
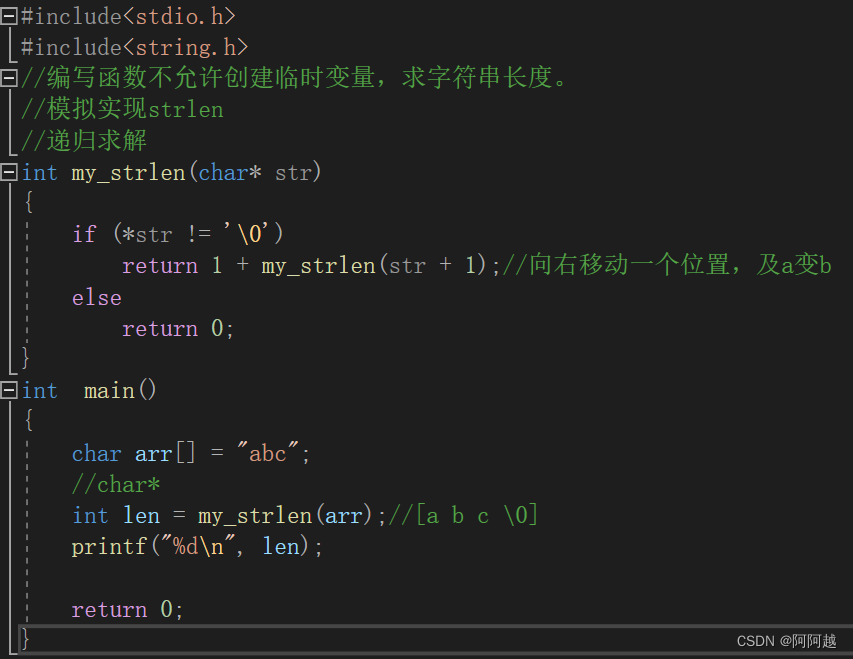
函数的递归
1、什么是递归? 程序调用自身的编程技巧称为递归。 递归作为一种算法在程序设计语言中广泛应用。一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解&#x…...

Android T 窗口层级其二 —— 层级结构树的构建(更新中)
如何通过dump中的内容找到对应的代码? 我们dump窗口层级发现会有很多信息,adb shell dumpsys activity containers 这里我们以其中的DefaultTaskDisplayArea为例 在源码的framework目录下查找该字符串,找到对应的代码就可以通过打印堆栈或者…...

ASIC芯片设计全流程项目实战课重磅上线 ,支持 65nm制程流片 !
全流程项目实战课学什么? 此次推出【 ASIC芯片设计全流程项目实战课】,基于IPA图像处理加速器,以企业级真实ASIC项目为案例,学员可参与全流程项目实践,以及65nm真实流片! 众所周知,放眼整个IC硕…...

背上沉重的书包准备run之react篇
沉重,太沉重了。。。没理好捏,等我脑子歇歇再好好补充一下 react特性? React 是一个用于构建用户界面的 JavaScript 库,它具有以下特性: 组件化开发:React 基于组件化思想,将 UI 拆分为独立、…...

LAMP及论坛搭建
一、概述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态Web站点服务及其应用开发环境。LAMP是一个缩写词,具体包括Linux操作系统、Apache网站服务器、MySQL数据库服务器、PHP(或…...
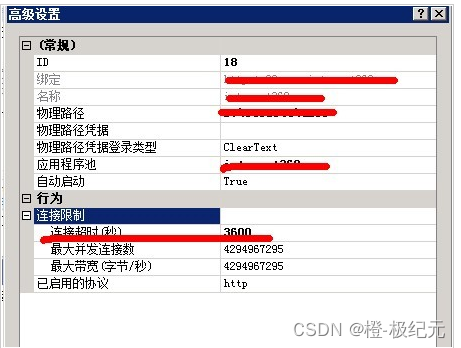
php-cgi.exe - FastCGI 进程超过了配置的请求超时时限
解决方案一: 处理(php-cgi.exe - FastCGI 进程超过了配置的请求超时时限)的问题 内容转载: 处理(php-cgi.exe - FastCGI 进程超过了配置的请求超时时限)的问题_php技巧_脚本之家 【详细错误】: HTTP 错误 500.0 - Internal Server Error C:…...
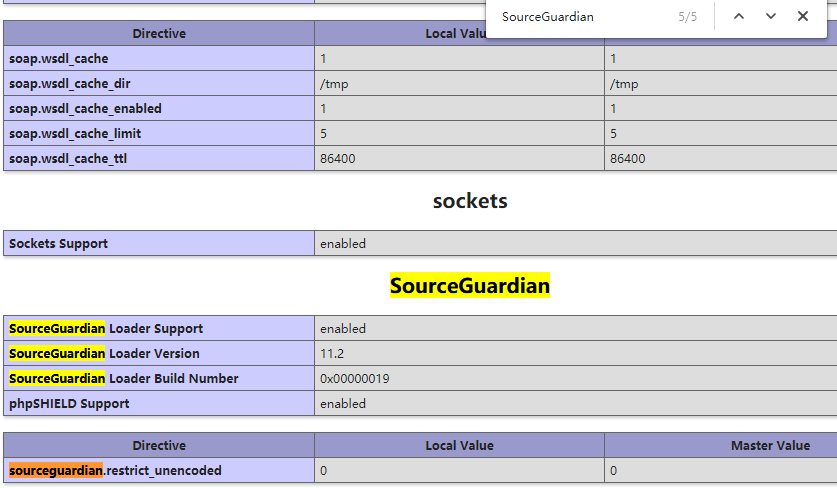
linux系统虚拟主机开启支持SourceGuardian(sg11)加密组件
注意:sg11我司只支持linux系统虚拟主机自主安装。支持php5.3及以上版本。 1、登陆主机控制面板,找到【远程文件下载】这个功能。 2、远程下载文件填写http://download.myhostadmin.net/vps/sg11_for_linux.zip 下载保存的路径填写/others/ 3、点击控制…...

让我们一起探讨汽车充电桩控制主板的应用
你是否想过,你的汽车充电桩可以更智能?可以支持更多类型的电池,更多操作系统,更多协议和更多电源?让我们一起探讨汽车充电桩控制主板的应用。 控制主板是充电桩的大脑,它可以应用于各种充电桩,包括智能充电桩、电动汽…...
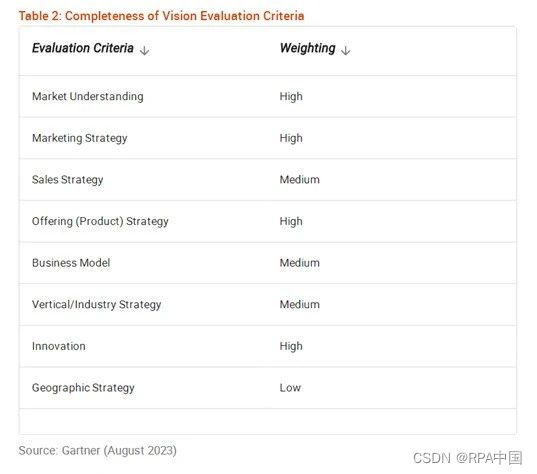
Gartner发布《2023年全球RPA魔力象限》:90%RPA厂商,将提供生成式AI自动化
8月3日,全球著名咨询调查机构Gartner发布了《2023年全球RPA魔力象限》,通过产品能力、技术创新、市场影响力等维度,对全球16家卓越RPA厂商进行了深度评估。 弘玑Cyclone(Cyclone Robotics)、来也(Laiye&am…...
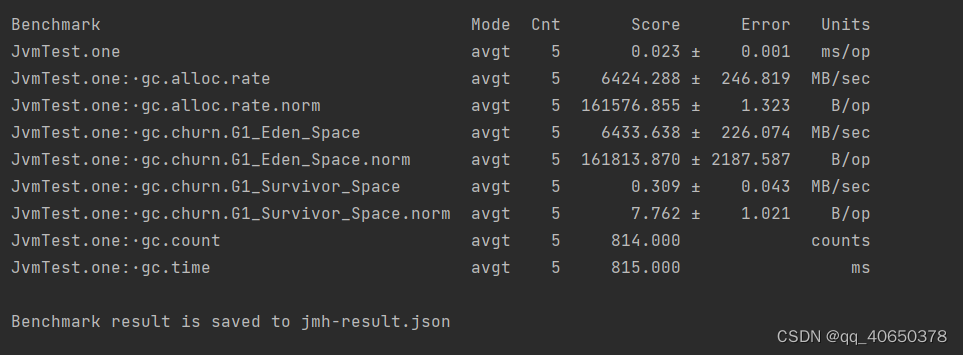
springboot整合JMH做优化实战
这段时间接手项目出现各种问题,令人不胜烦扰。吐槽下公司做项目完全靠人堆,大上快上风格注定留下一地鸡毛,修修补补不如想如何提升同事代码水准免得背锅。偶然看到关于JMH对于优化java代码的直观性,于是有了这篇文章,希…...

gitru:一个由 Rust 打造的零依赖 Git 提交信息校验工具芯
一、项目背景与核心价值 1. 解决的核心痛点 Navicat的数据库连接密码并非明文存储,而是通过AES算法加密后写入.ncx格式的XML配置文件中。一旦用户忘记密码,常规方式只能重新配置连接,效率极低。本项目只作为学习研究使用,不做其他…...

Ollama部署EmbeddingGemma-300m常见问题全解:从报错到实战
Ollama部署EmbeddingGemma-300m常见问题全解:从报错到实战 1. 为什么选择EmbeddingGemma-300m? EmbeddingGemma-300m是谷歌推出的轻量级文本嵌入模型,仅有3亿参数却继承了Gemini系列模型的强大能力。这个模型特别适合需要在本地环境部署语义…...

Formily企业级表单解决方案:分布式状态管理与高性能架构的终极实践
Formily企业级表单解决方案:分布式状态管理与高性能架构的终极实践 【免费下载链接】formily 📱🚀 🧩 Cross Device & High Performance Normal Form/Dynamic(JSON Schema) Form/Form Builder -- Support React/React Native/…...

利用Python嵌入式版打造便携式应用:从环境配置到一键分发
1. Python嵌入式版为何成为便携应用神器 第一次接触Python嵌入式版是在2018年给客户部署数据分析工具时。客户IT部门明确要求"不能安装任何软件",当时差点放弃,直到发现了这个藏在官网下载页角落的"embeddable package"。这个只有8M…...

微服务可观测性建设
微服务可观测性建设:打造高效运维的基石 在数字化转型的浪潮中,微服务架构凭借其灵活性和可扩展性成为企业技术演进的主流选择。随着服务数量的激增和分布式系统的复杂性提升,传统的监控手段已难以满足运维需求。微服务可观测性建设应运而生…...

-:RAG 入门-向量存储与企业级向量数据库 milvus匾
起因是我想在搞一些操作windows进程的事情时,老是需要右键以管理员身份运行,感觉很麻烦。就研究了一下怎么提权,顺手瞄了一眼Windows下用户态权限分配,然后也是感谢《深入解析Windows操作系统》这本书给我偷令牌的灵感吧ÿ…...

思博伦TCL并发测试避坑指南:HTTP/1.1配置与端口关联的最佳实践
思博伦TCL并发测试避坑指南:HTTP/1.1配置与端口关联的最佳实践 在性能测试领域,思博伦(Spirent)的TCL测试工具因其强大的功能和灵活性而备受推崇。然而,正是这种灵活性也带来了配置上的复杂性,特别是在HTTP…...

RK3588嵌入式Linux开发实战:uboot镜像合成与rkbin文件整合指南
1. RK3588开发必备:理解uboot镜像合成的核心意义 刚接触RK3588开发板时,很多工程师都会困惑:为什么编译好的uboot不能直接烧录?这个问题我最初也踩过坑。实际上,Rockchip平台的启动流程比传统嵌入式系统更复杂…...

从AES-CMAC到数字签名:揭秘消息认证与身份验证的技术演进
1. 从AES-CMAC到数字签名:技术演进全景图 记得我第一次接触消息认证码(MAC)是在开发智能门锁项目时。当时需要确保设备接收的指令不被篡改,但又不希望引入太复杂的加密机制。AES-CMAC就像个轻量级的"数据指纹生成器"&am…...

无需代码!AcousticSense AI音乐分类工具5分钟部署指南
无需代码!AcousticSense AI音乐分类工具5分钟部署指南 1. 让AI听懂音乐:视觉化流派分析新体验 你是否遇到过这样的情况:听到一首好歌却说不清它属于什么风格?或者需要整理上千首音乐却苦于手动分类?AcousticSense AI…...