自然语言处理从入门到应用——LangChain:提示(Prompts)-[示例选择器(Example Selectors)]
分类目录:《自然语言处理从入门到应用》总目录
如果我们拥有大量的示例,我们可能需要选择在提示中包含哪些示例。ExampleSelector是负责执行此操作的类。 其基本接口定义如下所示:
class BaseExampleSelector(ABC):"""Interface for selecting examples to include in prompts."""def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:"""Select which examples to use based on the inputs."""
它只需要暴露一个select_examples方法,该方法接收输入变量并返回一个示例列表。具体如何选择这些示例取决于每个具体实现。
自定义示例选择器(Custom Example Selector)
自定义示例选择器从给定的示例的列表中选择固定个示例。一个ExampleSelector必须实现两个方法:
- 一个
add_example方法,它接受一个示例并将其添加到ExampleSelector中 - 一个
select_examples方法,它接受输入变量(用户输入),并返回要在few-shot提示中使用的示例列表
让我们实现一个简单的自定义ExampleSelector,它只随机选择两个示例。
实现自定义示例选择器
from langchain.prompts.example_selector.base import BaseExampleSelector
from typing import Dict, List
import numpy as npclass CustomExampleSelector(BaseExampleSelector):def __init__(self, examples: List[Dict[str, str]]):self.examples = examplesdef add_example(self, example: Dict[str, str]) -> None:"""Add new example to store for a key."""self.examples.append(example)def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:"""Select which examples to use based on the inputs."""return np.random.choice(self.examples, size=2, replace=False)
使用自定义示例选择器
examples = [{"foo": "1"},{"foo": "2"},{"foo": "3"}
]# 初始化示例选择器
example_selector = CustomExampleSelector(examples)# 选择示例
example_selector.select_examples({"foo": "foo"})
# -> [{'foo': '2'}, {'foo': '3'}]# 向示例集合添加新示例
example_selector.add_example({"foo": "4"})
example_selector.examples
# -> [{'foo': '1'}, {'foo': '2'}, {'foo': '3'}, {'foo': '4'}]# 选择示例
example_selector.select_examples({"foo": "foo"})
# -> [{'foo': '1'}, {'foo': '4'}]
基于长度的示例选择器(LengthBased ExampleSelector)
基于长度的示例选择器根据示例的长度来选择要使用的示例。当我们担心构建的提示内容超过上下文窗口的长度时这种示例选择器将非常有用。对于较长的输入,它会选择较少的示例进行包含,而对于较短的输入,它会选择更多的示例。
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector# These are a lot of examples of a pretend task of creating antonyms.
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},
]example_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)example_selector = LengthBasedExampleSelector(# These are the examples it has available to choose from.examples=examples, # This is the PromptTemplate being used to format the examples.example_prompt=example_prompt, # This is the maximum length that the formatted examples should be.# Length is measured by the get_text_length function below.max_length=25,# This is the function used to get the length of a string, which is used# to determine which examples to include. It is commented out because# it is provided as a default value if none is specified.# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)dynamic_prompt = FewShotPromptTemplate(# We provide an ExampleSelector instead of examples.example_selector=example_selector,example_prompt=example_prompt,prefix="Give the antonym of every input",suffix="Input: {adjective}\nOutput:", input_variables=["adjective"],
)
# An example with small input, so it selects all examples.
print(dynamic_prompt.format(adjective="big"))
输出:
Give the antonym of every inputInput: happy
Output: sadInput: tall
Output: shortInput: energetic
Output: lethargicInput: sunny
Output: gloomyInput: windy
Output: calmInput: big
Output:
当输入较长时:
# An example with long input, so it selects only one example.
long_string = "big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else"
print(dynamic_prompt.format(adjective=long_string))
Give the antonym of every input
输出:
Input: happy
Output: sadInput: big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else
Output:
我们还可以新增一个示例:
# You can add an example to an example selector as well.
new_example = {"input": "big", "output": "small"}
dynamic_prompt.example_selector.add_example(new_example)
print(dynamic_prompt.format(adjective="enthusiastic"))
输出:
Give the antonym of every inputInput: happy
Output: sadInput: tall
Output: shortInput: energetic
Output: lethargicInput: sunny
Output: gloomyInput: windy
Output: calmInput: big
Output: smallInput: enthusiastic
Output:
最大边际相关性示例选择器(Maximal Marginal Relevance ExampleSelector)
最大边际相关性示例选择器根据示例与输入的相似度以及多样性进行选择。它通过找到与输入具有最大余弦相似度的示例的嵌入,然后迭代地添加它们,同时对它们与已选择示例的接近程度进行惩罚,来实现这一目标。
from langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelector, SemanticSimilarityExampleSelector
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplateexample_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)# 这些是一个虚构任务创建反义词的许多示例。
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},
]
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(# 这是可供选择的示例列表。examples,# 这是用于生成嵌入向量以测量语义相似性的嵌入类。OpenAIEmbeddings(),# 这是用于存储嵌入向量并进行相似性搜索的 VectorStore 类。FAISS,# 这是要生成的示例数量。k=2
)
mmr_prompt = FewShotPromptTemplate(# 我们提供一个 ExampleSelector 而不是示例列表。example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入的反义词",suffix="输入:{adjective}\n输出:",input_variables=["adjective"],
)
# 输入是一个情感,因此应该选择 happy/sad 示例作为第一个示例
print(mmr_prompt.format(adjective="worried"))
输出:
Give the antonym of every inputInput: happy
Output: sadInput: windy
Output: calmInput: worried
Output:
我们还可以与仅基于相似性进行选择的情况进行比较:
# 使用 SemanticSimilarityExampleSelector 而不是 MaxMarginalRelevanceExampleSelector。
example_selector = SemanticSimilarityExampleSelector.from_examples(# 这是可供选择的示例列表。examples,# 这是用于生成嵌入向量以测量语义相似性的嵌入类。OpenAIEmbeddings(),# 这是用于存储嵌入向量并进行相似性搜索的 VectorStore 类。FAISS,# 这是要生成的示例数量。k=2
)
similar_prompt = FewShotPromptTemplate(# 我们提供一个 ExampleSelector 而不是示例列表。example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入的反义词",suffix="输入:{adjective}\n输出:",input_variables=["adjective"],
)
print(similar_prompt.format(adjective="worried"))
输出:
Give the antonym of every inputInput: happy
Output: sadInput: sunny
Output: gloomyInput: worried
Output:
N-Gram重叠示例选择器(N-Gram Overlap ExampleSelector)
NGramOverlapExampleSelector根据示例与输入之间的n-gram重叠得分选择和排序示例。n-gram重叠得分是一个介于0.0和1.0之间的浮点数。该选择器允许设置一个阈值分数。n-gram 重叠得分小于或等于阈值的示例将被排除。默认情况下,阈值设置为-1.0,因此不会排除任何示例,只会重新排序它们。将阈值设置为0.0将排除与输入没有n-gram重叠的示例。
from langchain.prompts import PromptTemplate
from langchain.prompts.example_selector.ngram_overlap import NGramOverlapExampleSelector
from langchain.prompts import FewShotPromptTemplate, PromptTemplateexample_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)# 这是一个假设任务(创建反义词)的许多示例。
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},
]
# 这些是虚构的翻译任务的示例。
examples = [{"input": "See Spot run.", "output": "Ver correr a Spot."},{"input": "My dog barks.", "output": "Mi perro ladra."},{"input": "Spot can run.", "output": "Spot puede correr."},
]example_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)example_selector = NGramOverlapExampleSelector(# 这些是可供选择的示例。examples=examples, # 用于格式化示例的 PromptTemplate。example_prompt=example_prompt, # 选择器停止的阈值分数。# 默认值为 -1.0。threshold=-1.0,# 对于负阈值:# 选择器按照 ngram 重叠得分对示例进行排序,不排除任何示例。# 对于大于 1.0 的阈值:# 选择器排除所有示例,并返回一个空列表。# 对于等于 0.0 的阈值:# 选择器根据 ngram 重叠得分对示例进行排序,# 并排除与输入没有 ngram 重叠的示例。
)
dynamic_prompt = FewShotPromptTemplate(# 我们提供 ExampleSelector 而不是示例。example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入的西班牙语翻译",suffix="输入:{sentence}\n输出:", input_variables=["sentence"],
)# 一个与“Spot can run.”有较大ngram重叠的示例输入
# 与“My dog barks.”没有重叠
print(dynamic_prompt.format(sentence="Spot can run fast."))
输出:
Give the Spanish translation of every inputInput: Spot can run.
Output: Spot puede correr.Input: See Spot run.
Output: Ver correr a Spot.Input: My dog barks.
Output: Mi perro ladra.Input: Spot can run fast.
Output:
我们还可以向NGramOverlapExampleSelector添加示例:
new_example = {"input": "Spot plays fetch.", "output": "Spot juega a buscar."}example_selector.add_example(new_example)
print(dynamic_prompt.format(sentence="Spot can run fast."))
输出:
Give the Spanish translation of every inputInput: Spot can run.
Output: Spot puede correr.Input: See Spot run.
Output: Ver correr a Spot.Input: Spot plays fetch.
Output: Spot juega a buscar.Input: My dog barks.
Output: Mi perro ladra.Input: Spot can run fast.
Output:
我们还以设置一个阈值,决定哪些示例会被排除:
# 例如,将阈值设为0.0
# 会排除与输入没有ngram重叠的示例。
# 因为"My dog barks."与"Spot can run fast."没有ngram重叠,
# 所以它被排除在外。
example_selector.threshold=0.0
print(dynamic_prompt.format(sentence="Spot can run fast."))
输出:
Give the Spanish translation of every inputInput: Spot can run.
Output: Spot puede correr.Input: See Spot run.
Output: Ver correr a Spot.Input: Spot plays fetch.
Output: Spot juega a buscar.Input: Spot can run fast.
Output:
我们也可以设置一个小的非零阈值:
example_selector.threshold=0.09
print(dynamic_prompt.format(sentence="Spot can play fetch."))
输出:
Give the Spanish translation of every inputInput: Spot can run.
Output: Spot puede correr.Input: Spot plays fetch.
Output: Spot juega a buscar.Input: Spot can play fetch.
Output:
我们再尝试设置大于1.0的阈值:
example_selector.threshold=1.0+1e-9
print(dynamic_prompt.format(sentence="Spot can play fetch."))
Give the Spanish translation of every input
输出:
Input: Spot can play fetch.
Output:
相似性示例选择器
语义相似性示例选择器根据输入与示例的相似性选择示例,它通过找到具有最大余弦相似度的嵌入的示例来实现这一点:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplateexample_prompt = PromptTemplate(input_variables=["input", "output"],template="Input: {input}\nOutput: {output}",
)
以下是一个虚构任务的许多示例,用于创建反义词:
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},
]
使用这些示例,可以创建一个语义相似性示例选择器:
example_selector = SemanticSimilarityExampleSelector.from_examples(# 这是可供选择的示例列表。examples,# 这是用于生成嵌入的嵌入类,用于衡量语义相似性。OpenAIEmbeddings(),# 这是用于存储嵌入并进行相似性搜索的VectorStore类。Chroma,# 这是要生成的示例数量。k=1
)similar_prompt = FewShotPromptTemplate(# 我们提供了一个ExampleSelector而不是示例列表。example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个词的反义词",suffix="输入:{adjective}\n输出:",input_variables=["adjective"],
)
通过使用这个示例选择器,我们可以根据输入的相似性来选择示例,并将其应用于生成反义词的问题:
Running Chroma using direct local API.
Using DuckDB in-memory for database. Data will be transient.
输入worried是一种情感,因此应选择happy/sad示例:
print(similar_prompt.format(adjective="worried"))
输出:
给出每个词的反义词输入:happy
输出:sad输入:worried
输出:
输入fat是一种度量,因此应选择tall/short示例:
print(similar_prompt.format(adjective="fat"))
输出:
给出每个词的反义词输入:happy
输出:sad输入:fat
输出:
我们还可以将新示例添加到SemanticSimilarityExampleSelector中:
similar_prompt.example_selector.add_example({"input": "enthusiastic", "output": "apathetic"})
print(similar_prompt.format(adjective="joyful"))
输出:
给出每个词的反义词输入:happy
输出:sad输入:joyful
输出:
参考文献:
[1] LangChain官方网站:https://www.langchain.com/
[2] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[3] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[示例选择器(Example Selectors)])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[示例选择器(Example Selectors)]
分类目录:《自然语言处理从入门到应用》总目录 如果我们拥有大量的示例,我们可能需要选择在提示中包含哪些示例。ExampleSelector是负责执行此操作的类。 其基本接口定义如下所示: class BaseExampleSelector(ABC):"""Interf…...

【实战项目】c++实现基于reactor的高并发服务器
基于Reactor的高并发服务器,分为反应堆模型,多线程,I/O模型,服务器,Http请求和响应五部分 全局 反应堆模型 Channel 描述了文件描述符以及读写事件,以及对应的读写销毁回调函数,对应存储ar…...

Docker部署ElasticSearch7
前言 帮助小伙伴快速部署研发或测试环境进行学习测试。springboot版本需要与ElasticSearch版本想对应,不同版本api不一致,会产生异常调用的情况。 一、拉取镜像 这里选择固定版本7.15.2 docker pull docker.elastic.co/elasticsearch/elasticsearch:…...
【算法|数组】滑动窗口
算法|数组——滑动窗口 引入 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度**。**如果不存在符合条件的子数组,返回 0 。 示例…...
)
笙默考试管理系统-MyExamTest----codemirror(2)
笙默考试管理系统-MyExamTest----codemirror(2) 目录 一、 笙默考试管理系统-MyExamTest----codemirror 二、 笙默考试管理系统-MyExamTest----codemirror 三、 笙默考试管理系统-MyExamTest----codemirror 四、 笙默考试管理系统-MyExamTest---…...
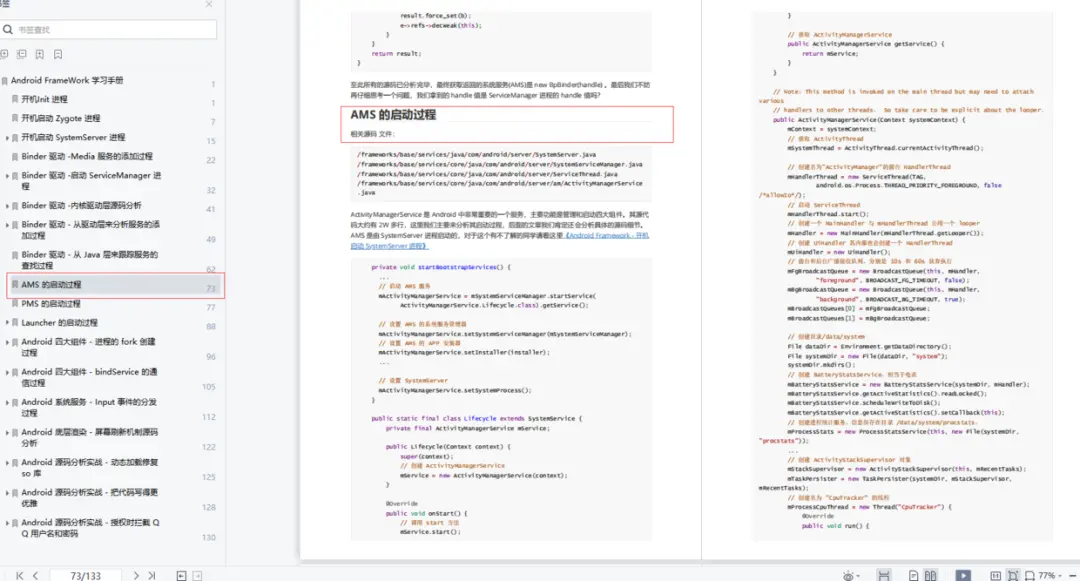
一次面试下来Android Framework 层的源码就问了4轮
说起字节跳动的这次面试经历,真的是现在都让我感觉背脊发凉,简直被面试官折磨的太难受了。虽然已经工作了七年,但是也只是纯粹的在写业务,对底层并没有一个很深的认识,这次面试经历直接的让我感受到我和那些一线大厂开…...
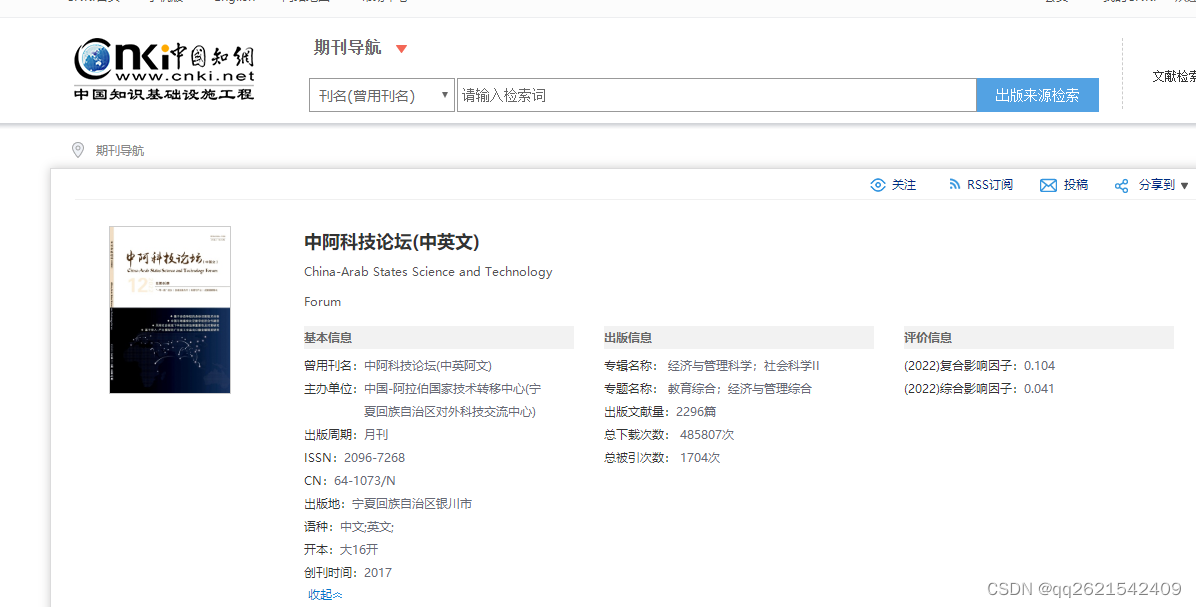
知网期刊《中阿科技论坛》简介及投稿须知
知网期刊《中阿科技论坛》简介及投稿须知 主管单位:宁夏回族自治区科学技术厅 主办单位:宁夏回族自治区对外科技交流中心(中国一阿拉伯国家技术转移中心) 刊 期:月刊 国际刊号:ISSN 2096-7268 国内刊号:CN 64-…...
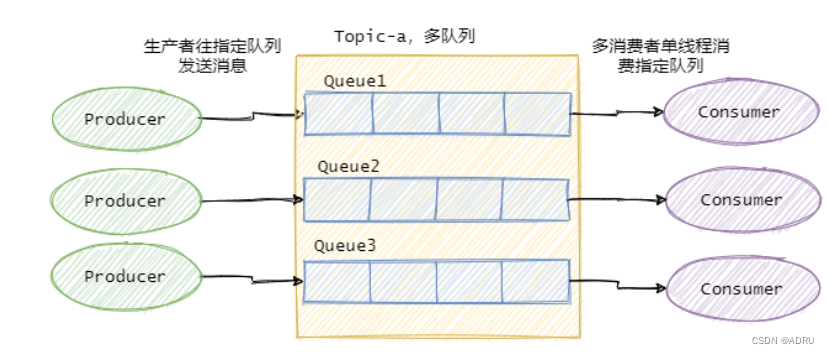
kafka是有序的吗?如何保证有序?
首先,Kafka无法保证消息的全局有序性,这是因为Kafka的设计中允许多个生产者并行地向同一个主题写入消息。而且,一个主题可能会被划分为多个分区,每个分区都可以在独立的生产者和消费者之间进行并行处理。因此,生产者将…...

centos 定时脚本检测tomcat是否启动,未启动情况下重新启动
编写脚本 tomcatMonitor.sh #!/bin/sh. /etc/profile . ~/.bash_profile#首先用ps -ef | grep tomcat 获得了tomcat进程信息,这样出来的结果中会包含grep本身, #因此通过 | grep -v grep 来排除grep本身,然后通过 awk {print $2}来打印出要…...
【Unity3D】消融特效
1 前言 选中物体消融特效中基于 Shader 实现了消融特效,本文将基于 Shader Graph 实现消融特效,两者原理一样,只是表达方式不同,另外,选中物体消融特效中通过 discard 丢弃片元,本文通过 alpha 测试丢弃片元…...
10.Eclipse配置Tomcat详细教程、如何使用Eclipse+tomcat创建并运行web项目
一、Tomcat的下载官网 -> 进入官网显示如图所示的界面,在下下载的是Tomcat9.0版本,你可以自己选一款 点击然后进入下面这个界面 最好是在你的D盘建立一个文件夹,把它解压在里面,文件夹名自己来吧,自己能知道里面装…...
MySQL索引1——索引基本概念与索引结构(B树、R树、Hash等)
目录 索引(INDEX)基本概念 索引结构分类 BTree树索引结构 Hash索引结构 Full-Text索引 R-Tree索引 索引(INDEX)基本概念 什么是索引 索引是帮助MySQL高效获取数据的有序数据结构 为数据库表中的某些列创建索引,就是对数据库表中某些列的值通过不同的数据结…...

2023-08-06力扣今日四题
链接: 剑指 Offer 59 - II. 队列的最大值 题意: 如题,要求O1给出数列的最大值 解: 类似滑动窗口 1 1 2 1 2用双端队列存储成2 2(每次从前面获取最大值,后面插入新数字)也就是第一个2覆盖了…...

Kubernetes入门 三、命令行工具 kubectl
目录 语法操作示例资源操作Pod 与集群资源类型与别名格式化输出 kubectl 是 Kubernetes 集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装和部署。 语法 使用以下语法从终端窗口运行 kubectl 命令: kub…...
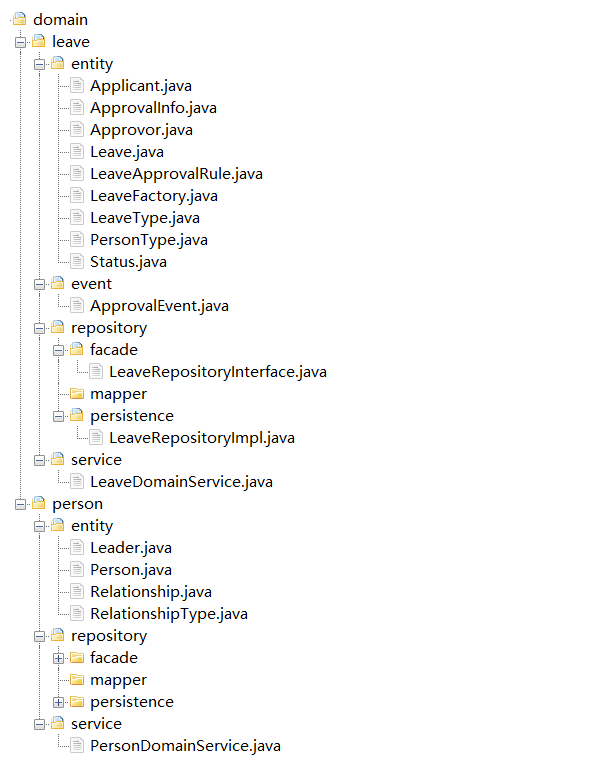
18 | 基于DDD的微服务设计实例
为了更好地理解 DDD 的设计流程,这篇文章会用一个项目来带你了解 DDD 的战略设计和战术设计,走一遍从领域建模到微服务设计的全过程,一起掌握 DDD 的主要设计流程和关键点。 项目基本信息 项目的目标是实现在线请假和考勤管理。功能描述如下…...
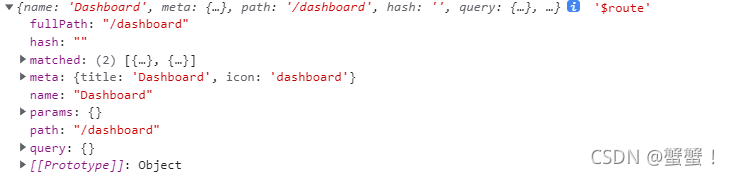
router和route的区别
简单理解为,route是用来获取路由信息的,router是用来操作路由的。 一、router router是VueRouter的实例,通过Vue.use(VueRouter)和VueRouter构造函数得到一个router的实例对象,这个对象中是一个全局的对象,他包含了所…...

每日后端面试5题 第五天
一、Redis的常用数据类型有哪些,简单说一下常用数据类型特点 1.字符串string 最基本的数据存储类型,普通字符串 SET key value 2.哈希hash 类似于Java中HashMap的结构 HSET key field value 3.列表list 按照插入顺序排序,操作左边或右…...

BGP基础实验
题目 IP地址配置 R1 R2 R3 R4 R5 AS2内全网通 R2: ospf 1 router-id 2.2.2.2 area 0.0.0.0 network 2.2.2.0 0.0.0.255 network 23.1.1.0 0.0.0.255 R3: ospf 1 router-id 3.3.3.3 area 0.0.0.0 network 3.3.3.0 0.0.0.255 network 23.…...
在excel中整理sql语句
数据准备 CREATE TABLE t_test (id varchar(32) NOT NULL,title varchar(255) DEFAULT NULL,date datetime DEFAULT NULL ) ENGINEInnoDB DEFAULT CHARSETutf8mb4; INSERT INTO t_test VALUES (87896cf20b5a4043b841351c2fd9271f,张三1,2023/6/8 14:06); INSERT INTO t_test …...

Vue中下载不同文件的几种方式
当在Vue中需要实现文件下载功能时,我们可以有多种方式来完成。下面将介绍五种常用的方法。 1. 使用window.open方法下载文件 <template><div><button click"downloadFile(file1.pdf)">下载文件1</button><button click"…...

MDCSwipeToChoose快速入门:5步创建你的第一个滑动卡片应用
MDCSwipeToChoose快速入门:5步创建你的第一个滑动卡片应用 【免费下载链接】MDCSwipeToChoose Swipe to "like" or "dislike" any view, just like Tinder.app. Build a flashcard app, a photo viewer, and more, in minutes, not hours! 项…...

bootstrap怎么设置表单为水平布局
Bootstrap 5 中需用 row align-items-center col-auto col-form-label 和 col 包裹 input 实现水平对齐;form-group 和 col-sm-2 等 v4 类已失效;复选框须用 form-check 结构;form-floating 不适用于水平布局。Bootstrap 5 中怎么让 label …...

跨越版本鸿沟:Vivado 2022.2与Petalinux 2022.1协同构建HDMI显示系统
1. 为什么需要跨越版本鸿沟? 最近在做一个基于Zynq-7000的开发项目,需要实现HDMI显示功能。按照传统做法,很多人会选择Vivado 2018.3Petalinux 2018.3这套"黄金组合",毕竟网上教程多,资料全。但实际使用中我…...

字符串拼接用“+”还是 StringBuilder?别再凭感觉写了辜
前言 Kubernetes 本身并不复杂,是我们把它搞复杂的。无论是刻意为之还是那种虽然出于好意却将优雅的原语堆砌成 鲁布戈德堡机械 的狂热。平台最初提供的 ReplicaSets、Services、ConfigMaps,这些基础组件简单直接,甚至显得有些枯燥。但后来我…...

终极指南:Ant Media Server性能基准测试 - 不同硬件配置下的低延迟流媒体表现对比
终极指南:Ant Media Server性能基准测试 - 不同硬件配置下的低延迟流媒体表现对比 【免费下载链接】Ant-Media-Server Ant Media Server — Ultra-low latency streaming engine with WebRTC (~0.5s), SRT, RTMP, HLS, CMAF, adaptive bitrate, transcoding & s…...

Gophish实战指南:从零构建邮件钓鱼实验环境
1. Gophish简介与核心功能 Gophish是一款专为企业和安全团队设计的开源钓鱼模拟工具,它让安全测试人员能够快速搭建逼真的钓鱼攻击环境。我第一次接触这个工具是在2018年的一次内部安全演练中,当时我们需要测试公司员工的网络安全意识,但市面…...

探索正点原子7寸RGB液晶屏:AD20工程实战
适用于正点原子7寸RGB液晶屏资料,包含AD20完整工程最近,我入手了一块正点原子的7寸RGB液晶屏,搭配AD20开发板,想着能折腾出点有意思的东西。折腾的过程虽然有点坎坷,但收获还是挺多的,现在就来分享一下我的…...

工业自动化场景下耐达讯自动化的 CC-Link IE 转 Modbus TCP 技术方案与应用实践
在工业自动化行业中,设备间协议异构性是系统集成面临的核心挑战之一。尤其在产线升级、老旧设备接入或跨品牌系统融合过程中,如何高效、稳定地实现不同通信协议之间的转换,直接关系到数据采集的完整性、控制系统的实时性以及整体项目的实施成…...

塑胶产品结构设计查询软件
塑胶产品结构设计核心要点速查指南(基于“紫垣商驿 v3.2”软件内容整理)本指南提炼了塑胶产品结构设计中关于胶厚、加强筋、孔的三个最关键模块的设计规范,旨在帮助工程师快速掌握核心原则,避免常见缺陷。第一章:胶厚&…...

OpenClaw人人养虾:语音唤醒
Voice Wake(语音唤醒)功能允许你通过说出唤醒词来激活 Agent,类似于 "Hey Siri" 或 "小爱同学"。唤醒前设备处于低功耗监听状态,唤醒后进入对话模式。 工作原理 低功耗监听 → 检测到唤醒词 → 激活 Agent …...