AIGC:【LLM(五)】——Faiss:高效的大规模相似度检索库
文章目录
- 一.简介
- 1.1 什么是Faiss
- 1.2 Faiss的安装
- 二.Faiss检索流程
- 2.1 构建向量库
- 2.2 构建索引
- 2.3 top-k检索
- 三.Faiss构建索引的多种方式
- 3.1 Flat :暴力检索
- 3.2 IVFx Flat :倒排暴力检索
- 3.3 IVFxPQy 倒排乘积量化
- 3.4 LSH 局部敏感哈希
- 3.5 HNSWx
一.简介
1.1 什么是Faiss
Faiss的全称是Facebook AI Similarity Search,是Facebook的AI团队针对大规模相似度检索问题开发的一个工具,使用C++编写,有python接口,对10亿量级的索引可以做到毫秒级检索的性能。
简单来说,Faiss的工作就是把我们自己的候选向量集封装成一个index数据库,它可以加速我们检索相似向量top-K的过程,其中有些索引还支持GPU构建。
1.2 Faiss的安装
## cpu版
$ conda install -c pytorch faiss-cpu
## gpu版
$ conda install -c pytorch faiss-gpu
二.Faiss检索流程
2.1 构建向量库
这一部分就是将我们已有的数据转成向量库。
import numpy as np
d = 64 # 向量维度
nb = 100000 # index向量库的数据量
nq = 10000 # 待检索query的数目
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000. # index向量库的向量
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000. # 待检索的query向量
2.2 构建索引
用faiss 构建index,并将向量添加到index中。这里我们选用暴力检索的方法FlatL2,L2代表构建的index采用的相似度度量方法为L2范数,即欧氏距离。
import faiss
index = faiss.IndexFlatL2(d)
print(index.is_trained) # 输出为True,代表该类index不需要训练,只需要add向量进去即可
index.add(xb) # 将向量库中的向量加入到index中
print(index.ntotal) # 输出index中包含的向量总数,为100000
2.3 top-k检索
检索与query最相似的top-k。
k = 4 # topK的K值
D, I = index.search(xq, k)# xq为待检索向量,返回的I为每个待检索query最相似TopK的索引list,D为其对应的距离
print(I[:5])
print(D[-5:])
三.Faiss构建索引的多种方式
构建index方法和传参方法可以为:
dim, measure = 64, faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(dim, param, measure)
- dim为向量维数
- 最重要的是param参数,它是传入index的参数,代表需要构建什么类型的索引;
- measure为度量方法,目前支持两种,欧氏距离和inner product,即内积。因此,要计算余弦相似度,只需要将vecs归一化后,使用内积度量即可。
此外,Faiss官方支持八种度量方式,分别是:
1)METRIC_INNER_PRODUCT(内积)
2)METRIC_L1(曼哈顿距离)
3)METRIC_L2(欧氏距离)
4)METRIC_Linf(无穷范数)
5)METRIC_Lp(p范数)
6)METRIC_BrayCurtis(BC相异度)
7)METRIC_Canberra(兰氏距离/堪培拉距离)
8)METRIC_JensenShannon(JS散度)
3.1 Flat :暴力检索
- 优点:该方法是Faiss所有index中最准确的,召回率最高的方法,没有之一;
- 缺点:速度慢,占内存大。
- 使用情况:向量候选集很少,在50万以内,并且内存不紧张。
- Ps:虽然都是暴力检索,faiss的暴力检索速度比一般程序猿自己写的暴力检索要快上不少,所以并不代表其无用武之地,建议有暴力检索需求的同学还是用下faiss。
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'Flat'
index = faiss.index_factory(dim, param, measure)
index.is_trained # 输出为True
index.add(xb) # 向index中添加向量
3.2 IVFx Flat :倒排暴力检索
- 优点:IVF主要利用倒排的思想,在文档检索场景下的倒排技术是指,一个kw后面挂上很多个包含该词的doc,由于kw数量远远小于doc,因此会大大减少了检索的时间。在向量中如何使用倒排呢?可以拿出每个聚类中心下的向量ID,每个中心ID后面挂上一堆非中心向量,每次查询向量的时候找到最近的几个中心ID,分别搜索这几个中心下的非中心向量。通过减小搜索范围,提升搜索效率。
- 缺点:速度也还不是很快。
- 使用情况:相比Flat会大大增加检索的速度,建议百万级别向量可以使用。
- 参数:IVFx中的x是k-means聚类中心的个数
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'IVF100,Flat' # 代表k-means聚类中心为100,
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量
index.add(xb)
3.3 IVFxPQy 倒排乘积量化
- 优点:工业界大量使用此方法,各项指标都均可以接受,利用乘积量化的方法,改进了IVF的k-means,将一个向量的维度切成x段,每段分别进行k-means再检索。
- 缺点:集百家之长,自然也集百家之短
- 使用情况:一般来说,各方面没啥特殊的极端要求的话,最推荐使用该方法!
- 参数:IVFx,PQy,其中的x和y同上
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'IVF100,PQ16'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为False,因为倒排索引需要训练k-means,
index.train(xb) # 因此需要先训练index,再add向量 index.add(xb)
index.add(xb)
3.4 LSH 局部敏感哈希
- 原理:哈希对大家再熟悉不过,向量也可以采用哈希来加速查找,我们这里说的哈希指的是局部敏感哈希(Locality Sensitive Hashing,LSH),不同于传统哈希尽量不产生碰撞,局部敏感哈希依赖碰撞来查找近邻。高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希计算后分桶,使得他们哈希分桶值有很大的概率是一样的,若两点之间的距离较远,则他们哈希分桶值相同的概率会很小。
- 优点:训练非常快,支持分批导入,index占内存很小,检索也比较快
- 缺点:召回率非常拉垮。
- 使用情况:候选向量库非常大,离线检索,内存资源比较稀缺的情况
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'LSH'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.train(xb)
index.add(xb)
3.5 HNSWx
- 优点:该方法为基于图检索的改进方法,检索速度极快,10亿级别秒出检索结果,而且召回率几乎可以媲美Flat,最高能达到惊人的97%。检索的时间复杂度为loglogn,几乎可以无视候选向量的量级了。并且支持分批导入,极其适合线上任务,毫秒级别体验。
- 缺点:构建索引极慢,占用内存极大(是Faiss中最大的,大于原向量占用的内存大小)
- 参数:HNSWx中的x为构建图时每个点最多连接多少个节点,x越大,构图越复杂,查询越精确,当然构建index时间也就越慢,x取4~64中的任何一个整数。
- 使用情况:不在乎内存,并且有充裕的时间来构建index
- 构建方法:
dim, measure = 64, faiss.METRIC_L2
param = 'HNSW64'
index = faiss.index_factory(dim, param, measure)
print(index.is_trained) # 此时输出为True
index.add(xb)

相关文章:
AIGC:【LLM(五)】——Faiss:高效的大规模相似度检索库
文章目录 一.简介1.1 什么是Faiss1.2 Faiss的安装 二.Faiss检索流程2.1 构建向量库2.2 构建索引2.3 top-k检索 三.Faiss构建索引的多种方式3.1 Flat :暴力检索3.2 IVFx Flat :倒排暴力检索3.3 IVFxPQy 倒排乘积量化3.4 LSH 局部敏感哈希3.5 HNSWx 一.简介…...
-[记忆的类型Ⅱ])
自然语言处理从入门到应用——LangChain:记忆(Memory)-[记忆的类型Ⅱ]
分类目录:《自然语言处理从入门到应用》总目录 对话知识图谱记忆(Conversation Knowledge Graph Memory) 这种类型的记忆使用知识图谱来重建记忆: from langchain.memory import ConversationKGMemory from langchain.llms impo…...

桥接模式-java实现
桥接模式 桥接模式的本质,是解决一个基类,存在多个扩展维度的的问题。 比如一个图形基类,从颜色方面扩展和从形状上扩展,我们都需要这两个维度进行扩展,这就意味着,我们需要创建一个图形子类的同时&#x…...

Linux systemd管理常用的几个小案例
systemd是目前Linux系统上主要的系统守护进程管理工具,配置文件要以.service结尾且放到 /usr/lib/systemd/system/目录下面 1、systemd管理ElasticSearch [Unit] DescriptionElasticsearch Service[Service] Typeforking Userelastic Groupelastic ExecStart/home…...
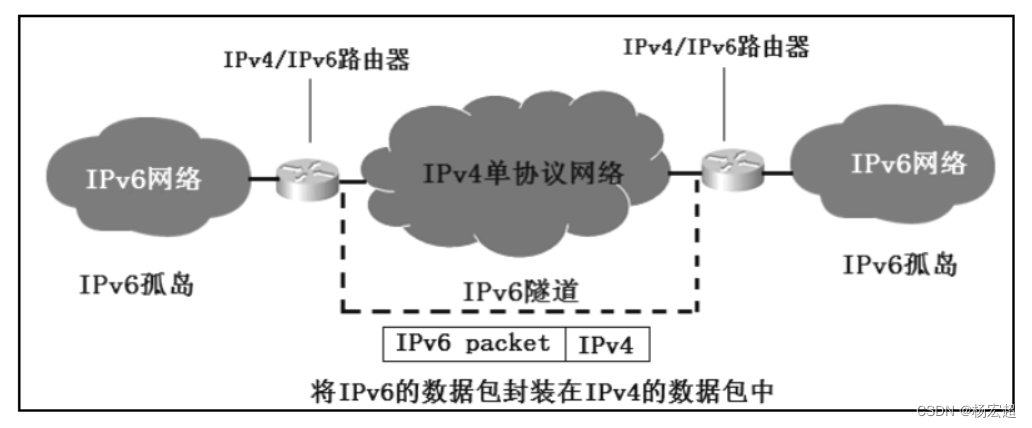
38、IPv6过渡技术
本节内容作为IPv6相关知识的最后一节内容,同时也作为我们本专栏网络层知识的最后一节内容,主要介绍从IPv4地址到IPv6地址过渡的相关技术。在这里我们只学习各类考试中常考的三种技术。 IPv4向IPv6的过渡 在前面的知识中,我们学习到了两种IP地…...

HMMER-序列分析软件介绍
HMMER是一个软件包,它提供了制作蛋白质和DNA序列域家族概率模型的工具,称为轮廓隐马尔可夫模型、轮廓HMM或仅轮廓,并使用这些轮廓来注释新序列、搜索序列数据库以寻找其他同源物,以及进行深度多重序列比对。HMMER是已知蛋白质和DN…...
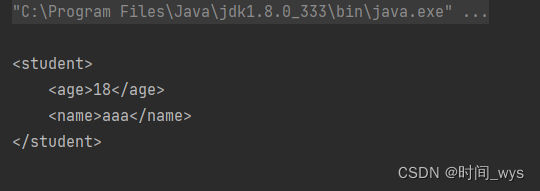
【项目学习1】如何将java对象转化为XML字符串
如何将java对象转化为XML字符串 将java对象转化为XML字符串,可以使用Java的XML操作库JAXB,具体操作步骤如下: 主要分为以下几步: 1、创建JAXBContext对象,用于映射Java类和XML。 JAXBContext jaxbContext JAXBConte…...

nginx负载均衡
负载均衡:反向代理来实现 正向代理的配置方法。 1、NGINX的七层代理和四层代理: 七层是最常用的反向代理方式,只能配置在nginx配置文件的http模块。而且配置方法名称:upstream 模块,不能写在server中,也…...
【毕业项目】自主设计HTTP
博客介绍:运用之前学过的各种知识 自己独立做出一个HTTP服务器 自主设计WEB服务器 背景目标描述技术特点项目定位开发环境WWW介绍 网络协议栈介绍网络协议栈整体网络协议栈细节与http相关的重要协议 HTTP背景知识补充特点uri & url & urn网址url HTTP请求和…...
关于安卓jar包修改并且重新发布
背景: 对于某些jar包,其内部是存在bug的,解决的方法无外乎就有以下几种方法: (1)通过反射,修改其赋值逻辑 (2)通过继承,重写其方法 (3࿰…...

Java课题笔记~ AspectJ 对 AOP 的实现(掌握)
AspectJ 对 AOP 的实现(掌握) 对于 AOP 这种编程思想,很多框架都进行了实现。Spring 就是其中之一,可以完成面向切面编程。然而,AspectJ 也实现了 AOP 的功能,且其实现方式更为简捷,使用更为方便,而且还支…...
npm 报错 cb() never called!
不知道有没有跟我一样的情况,在使用npm i的时候一直报错:cb() never called! 换了很多个node版本,还是不行,无法解决这个问题 百度也只是让降低node版本请缓存,gpt给出的解决方案也是同样的 但是缓存清过很多次了&a…...

finally有什么作用以及常用场景
在Java中,finally是一个关键字,用于定义一个代码块,该代码块中的代码无论是否发生异常都会被执行。finally块通常用于确保在程序执行过程中资源的释放和清理。 使用场景: 1. 资源释放:finally块经常用于释放打开的资…...

Python web实战之Django URL路由详解
概要 技术栈:Python、Django、Web开发、URL路由 Django是一种流行的Web应用程序框架,它采用了与其他主流框架类似的URL路由机制。URL路由是指将传入的URL请求映射到相应的视图函数或处理程序的过程。 什么是URL路由? URL路由是Web开发中非常…...
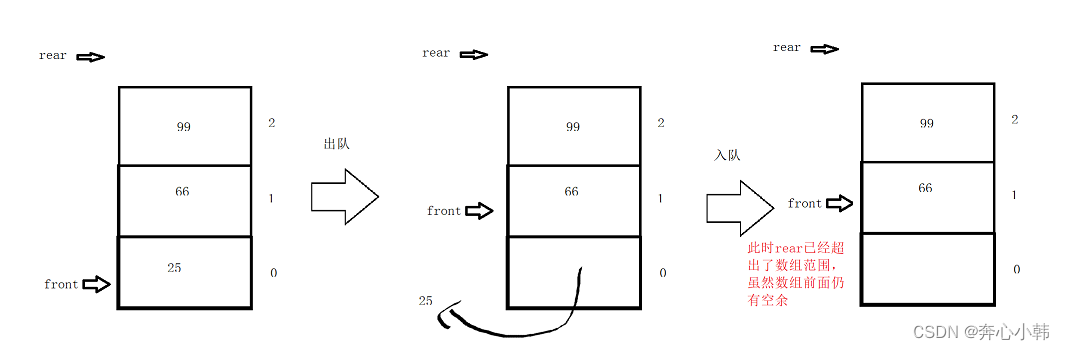
10-数据结构-队列(C语言)
队列 目录 目录 队列 一、队列基础知识 二、队列的基本操作 1.顺序存储 编辑 (1)顺序存储 (2)初始化及队空队满 (3)入队 (4)出队 (5)打印队列 &…...

面试之快速学习C++11 - 右值 移动构造 std::move
C11右值引用 字面意思,以引用传递的方式使用c右值左值和右值,左值是lvalue loactor value 存储在内存中,有明确存储地址的数据, 右值rvalue read value , 指的是那些可以提供数据值的数据(不一定可以寻址,…...
vue实现5*5宫格当鼠标滑过选中的正方形背景颜色统一变色
vue实现5*5宫格当鼠标滑过选中的正方形背景颜色统一变色 1、实现的效果 2、完整代码展示 <template><div id"app" mouseleave"handleMouseLeave({row: 0, col: 0 })"><div v-for"rowItem in squareNumber" :key"rowItem…...

2023-08-09 LeetCode每日一题(整数的各位积和之差)
2023-08-09每日一题 一、题目编号 1281. 整数的各位积和之差二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数 n,请你帮忙计算并返回该整数「各位数字之积」与「各位数字之和」的差。 示例1: 示例2: 提示: 1 …...
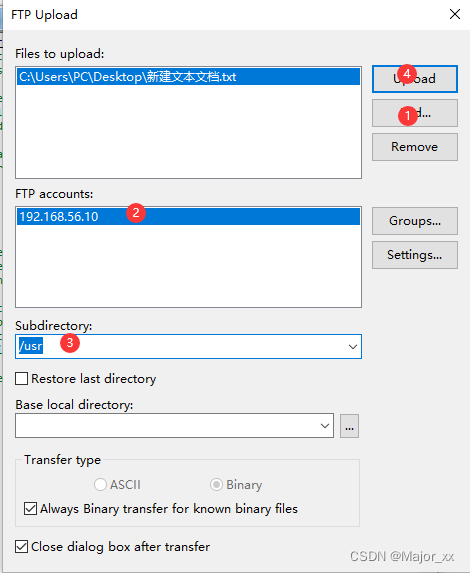
EditPlus连接Linux系统远程操作文件
EditPlus是一套功能强大的文本编辑器! 1.File ->FTP->FTP Settings; 2.Add->Description->FTP server->Username->Password->Subdirectory->Advanced Options 注意:这里的Subdirectory设置的是以后上传文件的默认…...

JVM 垃圾回收
垃圾回收算法 标记-清除算法(Mark and Sweep) 标记-清除算法分为两个阶段。在标记阶段,垃圾收集器会标记所有活动对象;在清除阶段,垃圾收集器会清除所有未标记的对象。标记-清除算法存在的问题是会产生内存碎片&#…...
)
IEC61850标准下的35kV变电站二次系统设计指南(附避雷器选型建议)
IEC61850标准下的35kV智能变电站二次系统设计与防雷保护全解析 在电力系统智能化转型的浪潮中,35kV变电站作为配电网的关键节点,其自动化水平直接影响着供电可靠性和运维效率。IEC61850标准作为电力自动化领域的"通用语言",为变电站…...

SpringAI 1.0.0 实战:用阿里百炼平台免费额度,5分钟搞定你的第一个AI对话接口
SpringAI 1.0.0实战:零成本搭建AI对话接口的完整指南 最近在技术社区里看到不少开发者对AI应用开发跃跃欲试,但往往被高昂的API调用成本劝退。作为一个经历过同样困扰的开发者,我发现阿里百炼平台提供的免费额度简直是成本敏感型开发者的福音…...

培训行业残酷真相,项目失败,90%都不是你的错
——致那些在深夜里,反复怀疑自己的你 今天我们助教又被学员点名夸奖了。顺便一顿拉扯,我们聊了很多。 这位学员告诉我,他很信命,曾找人看过他的命盘,总的来说就是一个非常普通的盘,这辈子注定赚不了什么大…...

C# 面试高频题:装箱和拆箱是如何影响性能的?非
OCP原则 ocp指开闭原则,对扩展开放,对修改关闭。是七大原则中最基本的一个原则。 依赖倒置原则(DIP) 什么是依赖倒置原则 核心是面向接口编程、面向抽象编程, 不是面向具体编程。 依赖倒置原则的目的 降低耦合度&#…...

从数据划分到超参调优:交叉验证与网格搜索的实战指南
1. 为什么简单的数据划分会翻车? 刚入行做机器学习项目时,我最常犯的错误就是把数据集简单粗暴地拆成训练集和测试集。比如用sklearn的train_test_split按7:3比例划分,训练完模型看到测试集准确率不错就沾沾自喜。直到某次把模型部署到生产环…...

linux驱动调试方法整理
一般我喜欢把linux驱动的调试按矛盾分为几大类:1.驱动工程师和内核/自己的 2.应用工程师和驱动工程师的。其中我们需要掌握linux众多的调试控件才能灵活运用。驱动工程师和内核/自己的1.驱动加载和驱动调试信息使用printk(per_log)打印需求使…...

在Windows 10/11上部署ArcGIS 10.2开发环境:ArcEngine SDK for .NET配置详解
在Windows 10/11上构建ArcGIS 10.2开发环境:从零开始打造GIS应用 当你第一次尝试在Visual Studio中调用ArcEngine的类库时,是否遇到过令人抓狂的"未找到引用"错误?或是明明按照教程一步步操作,却在运行时遭遇神秘的许可…...

双膜储气柜的选择指南建议
Q1: 如何从公开信息初步判断双膜气柜可靠性与工艺适应性?A1: 可交叉验证以下核心维度:工艺细节:查看是否采用多次焊接成型、全密封处理,是否有泄漏监测、主动泄压等安全设计;环境适配:耐温范围、防冻设计、…...

企业知识竞赛系统选型指南:核心功能、采购清单与实施建议
企业知识竞赛系统选型指南:赋能培训与文化建设引言:为何需要专业的竞赛系统?在数字化学习时代,知识竞赛已成为企业激发员工学习热情、检验培训成果、营造竞争性学习氛围的有效手段。然而,依靠传统线下或简单的在线工具…...

医疗器械软件生命周期管理注意事项
医疗器械软件生命周期管理注意事项 医疗器械软件生命周期管理需遵循严格的法规要求和质量控制标准,确保软件的安全性、有效性和合规性。以下是关键注意事项: 法规与标准合规 确保符合所在地区的法规要求,如FDA的21 CFR Part 820(美…...