【MySQL】增删查改基础
文章目录
- 一、创建操作
- 1.1 单行插入
- 1.2 多行插入
- 1.3 插入否则替换更新
- 1.4 替换replace
- 二、查询操作
- 2.1 select查询
- 2.2 where条件判断
- 2.3 order by排序
- 2.4 limit筛选分页结果
- 三、更新操作
- 四、删除操作
- 4.1 删除一列
- 4.2 删除整张表数据
- 五、插入查询结果
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
先创建一张表:
mysql> create table if not exists stu(-> id int unsigned primary key auto_increment,-> sn int unsigned unique key comment '学号',-> name varchar(20) not null,-> qq varchar(20) unique key-> );
一、创建操作
1.1 单行插入
- 指定列单行插入
mysql> insert into stu (sn, name, qq) values(123, '张三', '1161');
Query OK, 1 row affected (0.01 sec)
- 单行全列插入
mysql> insert into stu values(2, 128, '李四', '7077');
Query OK, 1 row affected (0.00 sec)
into 可以省略。
mysql> select * from stu;
+----+------+--------+------+
| id | sn | name | qq |
+----+------+--------+------+
| 1 | 123 | 张三 | 1161 |
| 2 | 128 | 李四 | 7077 |
+----+------+--------+------+
2 rows in set (0.00 sec)
1.2 多行插入
可以直接一行全列插入。
mysql> insert into stu values(10, 132, '王五', '2498'),(11, 147, '赵六', '8088');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from stu;
+----+------+--------+------+
| id | sn | name | qq |
+----+------+--------+------+
| 1 | 123 | 张三 | 1161 |
| 2 | 128 | 李四 | 7077 |
| 10 | 132 | 王五 | 2498 |
| 11 | 147 | 赵六 | 8088 |
+----+------+--------+------+
4 rows in set (0.00 sec)
也可以指定行插入一列:
mysql> insert into stu (sn, name, qq) values(155, '刘备', '5279'),(452, '关羽', '7892');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings:
mysql> select * from stu;
+----+------+--------+------+
| id | sn | name | qq |
+----+------+--------+------+
| 1 | 123 | 张三 | 1161 |
| 2 | 128 | 李四 | 7077 |
| 10 | 132 | 王五 | 2498 |
| 11 | 147 | 赵六 | 8088 |
| 14 | 155 | 刘备 | 5279 |
| 15 | 452 | 关羽 | 7892 |
+----+------+--------+------+
6 rows in set (0.00 sec)
1.3 插入否则替换更新
对数据进行插入,首先数据要合法(相关字段没有被唯一键、主键、外键等进行约束),其次如果插入数据的id已存在,将会更新sn、name和qq而不是插入失败。
mysql> insert into stu values (15, 452, '张飞', '7892') on duplicate key update sn=452, name='张飞', qq='7892';
Query OK, 2 rows affected (0.00 sec)
mysql> select * from stu;
+----+------+--------+------+
| id | sn | name | qq |
+----+------+--------+------+
| 1 | 123 | 张三 | 1161 |
| 2 | 128 | 李四 | 7077 |
| 10 | 132 | 王五 | 2498 |
| 11 | 147 | 赵六 | 8088 |
| 14 | 155 | 刘备 | 5279 |
| 15 | 452 | 张飞 | 7892 |
+----+------+--------+------+
6 rows in set (0.00 sec)
1.4 替换replace
主键 或者 唯一键 没有冲突,则直接插入;
主键 或者 唯一键 如果冲突,则删除后再插入。
mysql> select * from stu;
+----+------+--------+------+
| id | sn | name | qq |
+----+------+--------+------+
| 1 | 123 | 张三 | 1161 |
| 2 | 128 | 李四 | 7077 |
| 10 | 132 | 王五 | 2498 |
| 11 | 147 | 赵六 | 8088 |
| 14 | 155 | 刘备 | 5279 |
| 15 | 452 | 张飞 | 7892 |
+----+------+--------+------+
6 rows in set (0.00 sec)mysql> replace into stu (sn, name, qq) values (258, '曹操', 5687);
Query OK, 1 row affected (0.01 sec)mysql> select * from stu;
+----+------+--------+------+
| id | sn | name | qq |
+----+------+--------+------+
| 1 | 123 | 张三 | 1161 |
| 2 | 128 | 李四 | 7077 |
| 10 | 132 | 王五 | 2498 |
| 11 | 147 | 赵六 | 8088 |
| 14 | 155 | 刘备 | 5279 |
| 15 | 452 | 张飞 | 7892 |
| 16 | 258 | 曹操 | 5687 |
+----+------+--------+------+
7 rows in set (0.00 sec)
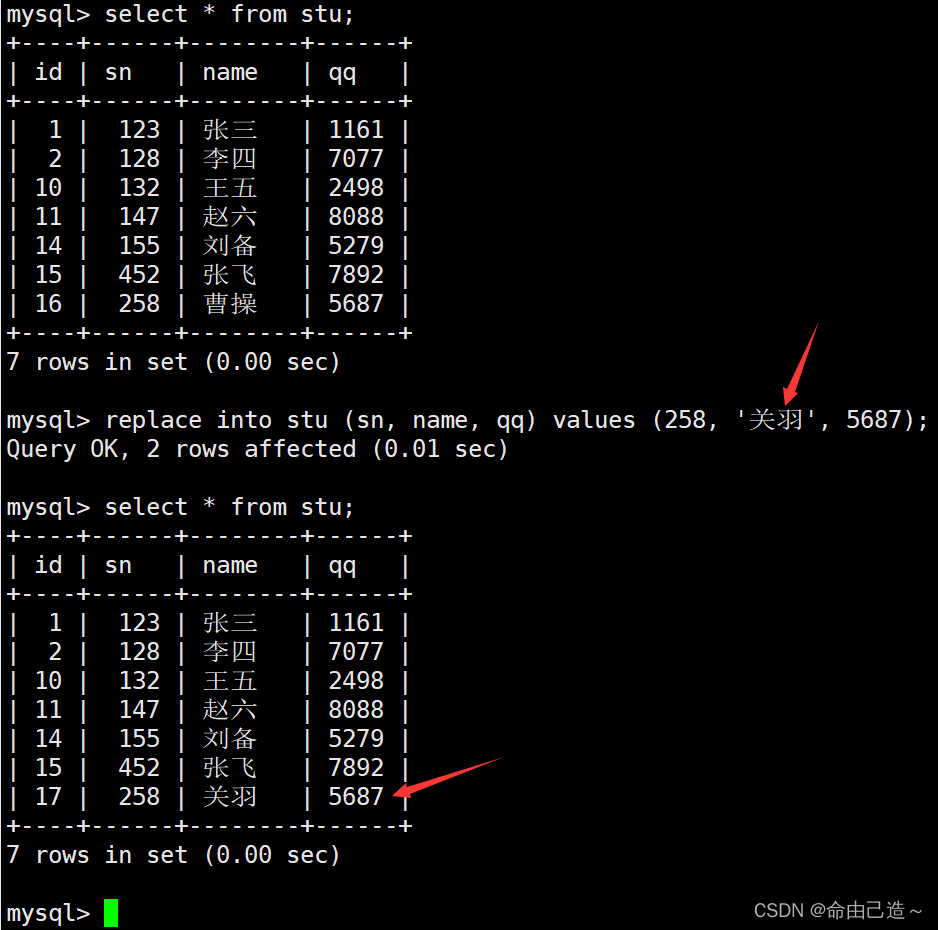
通过id也可以看出这行数据是先删除在插入的。
二、查询操作
先创建一个期末成绩表:
mysql> create table exam_result(-> id int unsigned primary key auto_increment,-> name varchar(20) not null comment '学生姓名',-> chinese float default 0.0 comment '语文成绩',-> math float default 0.0 comment '数学成绩',-> english float default 0.0 comment '英语成绩'-> );
Query OK, 0 rows affected (0.03 sec)
插入数据:
mysql> insert into exam_result (name, chinese, math, english) values-> ('张三' ,67, 98, 56),-> ('李四', 87, 78, 77),-> ('王五', 88, 98, 90),-> ('赵六', 82, 84, 67),-> ('田七', 55, 85, 45),-> ('孙八', 70, 73, 78),-> ('周九', 75, 65, 30);
Query OK, 7 rows affected (0.01 sec)
Records: 7 Duplicates: 0 Warnings: 0
2.1 select查询
- 全列查询
mysql> select * from exam_result;
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 1 | 张三 | 67 | 98 | 56 |
| 2 | 李四 | 87 | 78 | 77 |
| 3 | 王五 | 88 | 98 | 90 |
| 4 | 赵六 | 82 | 84 | 67 |
| 5 | 田七 | 55 | 85 | 45 |
| 6 | 孙八 | 70 | 73 | 78 |
| 7 | 周九 | 75 | 65 | 30 |
+----+--------+---------+------+---------+
7 rows in set (0.00 sec)
通常情况下不建议使用 * 进行全列查询
1、查询的列越多,意味着需要传输的数据量越大;
2、可能会影响到索引的使用。
- 指定列查询
mysql> select name from exam_result;
+--------+
| name |
+--------+
| 张三 |
| 李四 |
| 王五 |
| 赵六 |
| 田七 |
| 孙八 |
| 周九 |
+--------+
7 rows in set (0.00 sec)mysql> select name,english from exam_result;
+--------+---------+
| name | english |
+--------+---------+
| 张三 | 56 |
| 李四 | 77 |
| 王五 | 90 |
| 赵六 | 67 |
| 田七 | 45 |
| 孙八 | 78 |
| 周九 | 30 |
+--------+---------+
7 rows in set (0.00 sec)
- 查询字段为表达式
select可以计算表达式:
mysql> select 1+1;
+-----+
| 1+1 |
+-----+
| 2 |
+-----+
1 row in set (0.00 sec)
所以我们可以计算总分:
mysql> select name, (chinese + math + english) from exam_result;
+--------+----------------------------+
| name | (chinese + math + english) |
+--------+----------------------------+
| 张三 | 221 |
| 李四 | 242 |
| 王五 | 276 |
| 赵六 | 233 |
| 田七 | 185 |
| 孙八 | 221 |
| 周九 | 170 |
+--------+----------------------------+
7 rows in set (0.00 sec)#觉得计算式太长,可以用as给它重命名为total
mysql> select name, (chinese + math + english) as total from exam_result;
+--------+-------+
| name | total |
+--------+-------+
| 张三 | 221 |
| 李四 | 242 |
| 王五 | 276 |
| 赵六 | 233 |
| 田七 | 185 |
| 孙八 | 221 |
| 周九 | 170 |
+--------+-------+
7 rows in set (0.00 sec)# as也可以省略
mysql> select name 姓名, (chinese + math + english) 总分 from exam_result;
+--------+--------+
| 姓名 | 总分 |
+--------+--------+
| 张三 | 221 |
| 李四 | 242 |
| 王五 | 276 |
| 赵六 | 233 |
| 田七 | 185 |
| 孙八 | 221 |
| 周九 | 170 |
+--------+--------+
7 rows in set (0.00 sec)
- 筛选筛选结果去重distinct
mysql> select distinct math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
6 rows in set (0.00 sec)
2.2 where条件判断
- 比较运算符
运算符 说明
>, >=, <, <= 大于,大于等于,小于,小于等于
= 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL
<=> 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1)
!=, <> 不等于
BETWEEN a0 AND a1 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1)
IN (option, ...) 如果是 option 中的任意一个,返回 TRUE(1)
IS NULL 是 NULL
IS NOT NULL 不是 NULL
LIKE 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符
- 逻辑运算符
运算符 说明
AND 多个条件必须都为 TRUE(1),结果才是 TRUE(1)
OR 任意一个条件为 TRUE(1), 结果为 TRUE(1)
NOT 条件为 TRUE(1),结果为 FALSE(0)
演练:
- 找到英语小于60分的同学及其英语成绩
mysql> select name, english from exam_result where english<60;
+--------+---------+
| name | english |
+--------+---------+
| 张三 | 56 |
| 田七 | 45 |
| 周九 | 30 |
+--------+---------+
3 rows in set (0.00 sec)
- 找到语文成绩在 [80, 90] 分的同学及其语文成绩
# >=和<=
mysql> select name, chinese from exam_result where chinese>=80 and chinese<=90;
+--------+---------+
| name | chinese |
+--------+---------+
| 李四 | 87 |
| 王五 | 88 |
| 赵六 | 82 |
+--------+---------+
3 rows in set (0.00 sec)# between a0 and a1
mysql> select name, chinese from exam_result where chinese between 80 and 90;
+--------+---------+
| name | chinese |
+--------+---------+
| 李四 | 87 |
| 王五 | 88 |
| 赵六 | 82 |
+--------+---------+
3 rows in set (0.00 sec)
- 数学成绩是 98 或者 99 分的同学及数学成绩
# 多个or
mysql> select name, math from exam_result where math=98 or math=99;
+--------+------+
| name | math |
+--------+------+
| 张三 | 98 |
| 王五 | 98 |
+--------+------+
2 rows in set (0.00 sec)# in关键字
mysql> select name, math from exam_result where math in (98, 99);
+--------+------+
| name | math |
+--------+------+
| 张三 | 98 |
| 王五 | 98 |
+--------+------+
2 rows in set (0.00 sec)
- 筛选出姓张的以及张X同学(模糊匹配)
先插入一行数据:
mysql> insert into exam_result (name, chinese, math, english) values ('张翼德', 45, 98, 66);
Query OK, 1 row affected (0.01 sec)
先找出所有姓张的同学:
# '张%'找到所有张姓同学,%代表后面模糊匹配0-n个字符
mysql> select name from exam_result where name like '张%';
+-----------+
| name |
+-----------+
| 张三 |
| 张翼德 |
+-----------+
2 rows in set (0.00 sec)
接下来找到叫张某的同学:
# _代表模糊匹配1个字符
mysql> select name from exam_result where name like '张_';
+--------+
| name |
+--------+
| 张三 |
+--------+
1 row in set (0.00 sec)
- 找到语文成绩高于英语成绩的同学
mysql> select name, chinese, english from exam_result where english<chinese;
+--------+---------+---------+
| name | chinese | english |
+--------+---------+---------+
| 张三 | 67 | 56 |
| 李四 | 87 | 77 |
| 赵六 | 82 | 67 |
| 田七 | 55 | 45 |
| 周九 | 75 | 30 |
+--------+---------+---------+
5 rows in set (0.00 sec)
- 找到总分在200以下的同学
先看错误用法:
mysql> select name, chinese+math+english 'total' from exam_result where total < 200;
ERROR 1054 (42S22): Unknown column 'total' in 'where clause'
这主要是执行顺序的原因:
1️⃣ 执行from
2️⃣ 执行where字句
3️⃣ 筛选要打印的信息
这里执行where的时候发现没有total别名所以会出错。
所以后边不能用别名:
mysql> select name, chinese+math+english 'total' from exam_result where chinese+math+english < 200;
+--------+-------+
| name | total |
+--------+-------+
| 田七 | 185 |
| 周九 | 170 |
+--------+-------+
2 rows in set (0.00 sec)
- 找到英语成绩 > 80 并且不姓李的同学
mysql> select name, english from exam_result where english>80 and name!='李%';
+--------+---------+
| name | english |
+--------+---------+
| 王五 | 90 |
+--------+---------+
1 row in set (0.00 sec)
- NULL 的查询
mysql> select * from t10;
+--------+------+--------+
| name | age | gender |
+--------+------+--------+
| 李四 | 20 | 男 |
| 李四 | NULL | 男 |
+--------+------+--------+
2 rows in set (0.00 sec)
- 找到age是null的人
mysql> select name, age from t10 where age<=>null;
+--------+------+
| name | age |
+--------+------+
| 李四 | NULL |
+--------+------+
1 row in set (0.00 sec)
- 找到age不为null的人
mysql> select name, age from t10 where age is not null;
+--------+------+
| name | age |
+--------+------+
| 李四 | 20 |
+--------+------+
1 row in set (0.00 sec)
2.3 order by排序
对于没有 order by 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
ASC 为升序(从小到大)
DESC 为降序(从大到小)
默认为 ASC
NULL 视为比任何值都小
- 同学及数学成绩,按数学成绩升序/降序显示
# 升序 ASC
mysql> select name, math from exam_result order by math ASC;
+-----------+------+
| name | math |
+-----------+------+
| 周九 | 65 |
| 孙八 | 73 |
| 李四 | 78 |
| 赵六 | 84 |
| 田七 | 85 |
| 张三 | 98 |
| 王五 | 98 |
| 张翼德 | 98 |
+-----------+------+
8 rows in set (0.00 sec)# 降序 DESC
mysql> select name, math from exam_result order by math DESC;
+-----------+------+
| name | math |
+-----------+------+
| 张三 | 98 |
| 王五 | 98 |
| 张翼德 | 98 |
| 田七 | 85 |
| 赵六 | 84 |
| 李四 | 78 |
| 孙八 | 73 |
| 周九 | 65 |
+-----------+------+
8 rows in set (0.00 sec)
- 查询同学各门成绩,依次按 数学降序,英语降序,语文升序的方式显示
意思是如果数学成绩是相等的话就按照英语降序的顺序排,语文同理。
mysql> select name, math, english, chinese from exam_result order by math desc, english desc, chinese asc;
+-----------+------+---------+---------+
| name | math | english | chinese |
+-----------+------+---------+---------+
| 王五 | 98 | 90 | 88 |
| 张翼德 | 98 | 66 | 45 |
| 张三 | 98 | 56 | 67 |
| 田七 | 85 | 45 | 55 |
| 赵六 | 84 | 67 | 82 |
| 李四 | 78 | 77 | 87 |
| 孙八 | 73 | 78 | 70 |
| 周九 | 65 | 30 | 75 |
+-----------+------+---------+---------+
8 rows in set (0.00 sec)
- 查询同学的总分并且降序排序
mysql> select name, chinese+math+english as total from exam_result order by total desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 王五 | 276 |
| 李四 | 242 |
| 赵六 | 233 |
| 张三 | 221 |
| 孙八 | 221 |
| 张翼德 | 209 |
| 田七 | 185 |
| 周九 | 170 |
+-----------+-------+
8 rows in set (0.00 sec)
上面的where语句是不能用别名的。但在这里可以使用别名,还是因为顺序的问题。
第一优先级:明确找的是哪张表exam_result
第二优先级:where子句
第三优先级:chinese+math+english 总分
第四优先级:order by 总分 desc(要有合适的数据再进行排序)
第五优先级:limit(数据准备好了,才进行显示)
- 查询姓张的同学或者姓李的同学数学成绩,结果按数学成绩由高到低显示
mysql> select name, math from exam_result where name like '张%' or name like '李%' order by math desc;
+-----------+------+
| name | math |
+-----------+------+
| 张三 | 98 |
| 张翼德 | 98 |
| 李四 | 78 |
+-----------+------+
3 rows in set (0.00 sec)
2.4 limit筛选分页结果
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 张三 | 67 | 98 | 56 |
| 2 | 李四 | 87 | 78 | 77 |
| 3 | 王五 | 88 | 98 | 90 |
| 4 | 赵六 | 82 | 84 | 67 |
| 5 | 田七 | 55 | 85 | 45 |
| 6 | 孙八 | 70 | 73 | 78 |
| 7 | 周九 | 75 | 65 | 30 |
| 8 | 张翼德 | 45 | 98 | 66 |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)
这样显示数据太多了。
我们想要看表的前五行:
mysql> select * from exam_result limit 5;
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 1 | 张三 | 67 | 98 | 56 |
| 2 | 李四 | 87 | 78 | 77 |
| 3 | 王五 | 88 | 98 | 90 |
| 4 | 赵六 | 82 | 84 | 67 |
| 5 | 田七 | 55 | 85 | 45 |
+----+--------+---------+------+---------+
5 rows in set (0.00 sec)
当然也可以从中间开始截取:
mysql> select * from exam_result limit 1,3;
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 2 | 李四 | 87 | 78 | 77 |
| 3 | 王五 | 88 | 98 | 90 |
| 4 | 赵六 | 82 | 84 | 67 |
+----+--------+---------+------+---------+
3 rows in set (0.00 sec)# limit s offset n其中s代表步长,n代表下标
mysql> select * from exam_result limit 3 offset 1;
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 2 | 李四 | 87 | 78 | 77 |
| 3 | 王五 | 88 | 98 | 90 |
| 4 | 赵六 | 82 | 84 | 67 |
+----+--------+---------+------+---------+
3 rows in set (0.00 sec)
这里要注意limit的本质并不是条件筛选,而是显示。
三、更新操作
直接举例子:
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 张三 | 67 | 98 | 56 |
| 2 | 李四 | 87 | 78 | 77 |
| 3 | 王五 | 88 | 98 | 90 |
| 4 | 赵六 | 82 | 84 | 67 |
| 5 | 田七 | 55 | 85 | 45 |
| 6 | 孙八 | 70 | 73 | 78 |
| 7 | 周九 | 75 | 65 | 30 |
| 8 | 张翼德 | 45 | 98 | 66 |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)
- 把王五的数学成绩改成80
mysql> update exam_result set math=80 where name='王五';
Query OK, 1 row affected (0.01 sec)mysql> select name, math from exam_result where name='王五';
+--------+------+
| name | math |
+--------+------+
| 王五 | 80 |
+--------+------+
1 row in set (0.00 sec)
- 把李四的语文成绩改成60,数学成绩改成80
mysql> update exam_result set chinese=60, math=80 where name='李四';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from exam_result where name='李四';
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 2 | 李四 | 60 | 80 | 77 |
+----+--------+---------+------+---------+
1 row in set (0.00 sec)
- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
mysql> update exam_result set math=math+30 order by chinese+math+english asc limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
- 将所有人的语文成绩翻两倍
mysql> update exam_result set chinese=chinese*2;
Query OK, 8 rows affected (0.02 sec)
Rows matched: 8 Changed: 8 Warnings: 0mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 张三 | 134 | 98 | 56 |
| 2 | 李四 | 120 | 80 | 77 |
| 3 | 王五 | 176 | 80 | 90 |
| 4 | 赵六 | 164 | 84 | 67 |
| 5 | 田七 | 110 | 115 | 45 |
| 6 | 孙八 | 140 | 73 | 78 |
| 7 | 周九 | 150 | 95 | 30 |
| 8 | 张翼德 | 90 | 128 | 66 |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)
没有where子句直接更新全表,需谨慎!update的搞错了危害不亚于delete。
四、删除操作
4.1 删除一列
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
- 删除周九的成绩
mysql> select * from exam_result where name='周九';
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 7 | 周九 | 150 | 95 | 30 |
+----+--------+---------+------+---------+
1 row in set (0.01 sec)mysql> delete from exam_result where name='周九';
Query OK, 1 row affected (0.00 sec)mysql> select * from exam_result where name='周九';
Empty set (0.00 sec)
- 删除班级分数最高的成绩
mysql> delete from exam_result order by chinese+math+english desc limit 1;
Query OK, 1 row affected (0.01 sec)
4.2 删除整张表数据
语法:
delete from 表名
这样只是情况了表的数据,但是表还在。如果存在自增长约束,再插入数据就会按照上一个自增最大值+1。
- 截断表
语法:
truncate [table] 表名
只能对整表操作,不能像 DELETE 一样针对部分数据操作;
实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
会重置 AUTO_INCREMENT 项
五、插入查询结果
- 删除表中的的重复记录,重复的数据只能有一份
# 创建表
mysql> create table duplicate_table(-> id int,-> name varchar(20));
Query OK, 0 rows affected (0.04 sec)# 插入数据
mysql> insert into duplicate_table values-> (100, 'a'),-> (100, 'a'),-> (200, 'b'),-> (200, 'b'),-> (200, 'b'),-> (300, 'c');
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
查看表:
mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | a |
| 100 | a |
| 200 | b |
| 200 | b |
| 200 | b |
| 300 | c |
+------+------+
6 rows in set (0.00 sec)
去重思路:
- 1.创建一张属性和原表一样的空表
# 创建一张属性和duplicate_table一样的表no_duplicate_table(空表)
mysql> create table no_duplicate_table like duplicate_table;
Query OK, 0 rows affected (0.03 sec)
查看两张表得属性发现是一样的:
mysql> desc no_duplicate_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)mysql> desc duplicate_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
- 2.利用insert + distinct筛选出原表中去重后的数据
# 对原表select出来的结果insert进新表中
mysql> insert into no_duplicate_table select distinct * from duplicate_table;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | a |
| 200 | b |
| 300 | c |
+------+------+
3 rows in set (0.00 sec)
- 3.将原表名字修改为其他,将新表数据修改为原表名字
mysql> rename table duplicate_table to old_duplicate_table, no_duplicate_table to duplicate_table;
Query OK, 0 rows affected (0.02 sec)mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | a |
| 200 | b |
| 300 | c |
+------+------+
3 rows in set (0.00 sec)
这里的rename改名就是单纯的改名,其实就是文件名和inode的映射关系的改变。
相关文章:
【MySQL】增删查改基础
文章目录 一、创建操作1.1 单行插入1.2 多行插入1.3 插入否则替换更新1.4 替换replace 二、查询操作2.1 select查询2.2 where条件判断2.3 order by排序2.4 limit筛选分页结果 三、更新操作四、删除操作4.1 删除一列4.2 删除整张表数据 五、插入查询结果 CRUD : Create(创建), R…...
【vue+el-table+el-backtop】表格结合返回顶部使用,loading局部加载
效果图: 一. 表格结合返回顶部 二. 局部loading 解决方法: 一 返回顶部 target绑定滚动dom的父元素类名就可以了. 1.如果你的表格是 固定表头 的,那滚动dom的父元素类名就是 el-table__body-wrapper <el-backtop target".el-table__body-wrapper" :visibility…...
设计模式(4)装饰模式
一、介绍: 1、应用场景:把所需的功能按正确的顺序串联起来进行控制。动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更加灵活。 当需要给一个现有类添加附加职责,而又不能采用生成子类的方法…...
Redis——通用命令介绍
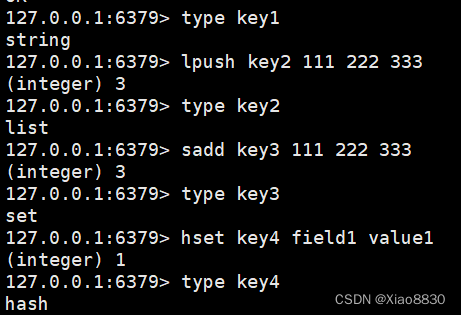
Redis官方文档 redis官方文档 核心命令 set 将key和value存储到Redis中,key和value都是字符串 set key valueRedis中不区分大小写,字符串类型也不需要添加单引号或者双引号 get 根据key读取value,如果当前key不存在,则返回…...

EmberJS教程_编程入门自学教程_菜鸟教程-免费教程分享
教程简介 Ember.js 是一个开源 JavaScript框架,用于开发基于模型-视图-控制器( MVC)架构的大型客户端 Web 应用程序。 Ember 旨在减少开发时间和提高生产力,它是全球采用的增长最快的前端应用程序框架之一。它目前在许多网站上使用,例如 Squ…...

Diffusion扩散模型学习4——Stable Diffusion原理解析-inpaint修复图片为例
Diffusion扩散模型学习4——Stable Diffusion原理解析-inpaint修复图片为例 学习前言源码下载地址原理解析一、先验知识二、什么是inpaint三、Stable Diffusion中的inpaint1、开源的inpaint模型2、基于base模型inpaint 四、inpaint流程1、输入图片到隐空间的编码2、文本编码3、…...

dns的负载分配是什么
DNS 负载分配是使用 DNS 系统对传入的网络流量进行分配的一种技术。这可以是基于多种策略来分配的,从简单的轮询到更复杂的基于地理位置或服务器健康状况的分配。下面是 DNS 负载分配的几种常见形式: 轮询(Round Robin)࿱…...
adb 通过wifi连接手机
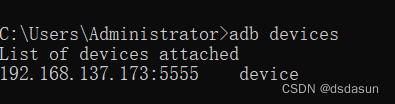
adb 通过wifi连接手机 1. 电脑通过USB线连接手机2. 手机开启USB调试模式,开启手机开发者模式3.手机开启USB调试模式 更多设置-》开发者选项-》USB调试4.点击Wi-Fi 高级设置,可以查看到手机Wi-Fi的IP地址,此IP地址adb命令后面的ip地址…...
将应用设置成系统App/获取Android设备SN号
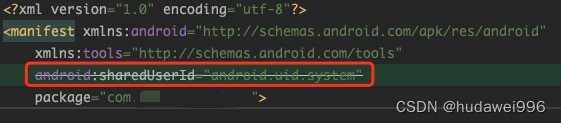
1,和系统签名一致;(签名设置签名文件) 2,配置Manifest 至此你的App就是一个系统App了,可以执行一些系统App才能有的操作,如获取机器SN号: public String getSerialNumber() {Strin…...

2.CUDA 编程手册中文版---编程模型
2.编程模型 更多精彩内容,请扫描下方二维码或者访问https://developer.nvidia.com/zh-cn/developer-program 来加入NVIDIA开发者计划 本章通过概述CUDA编程模型是如何在c中公开的,来介绍CUDA的主要概念。 编程接口中给出了对 CUDA C 的广泛描述。 本章…...
Claude 2、ChatGPT、Google Bard优劣势比较
Claude 2: 优势:Claude 2能够一次性处理多达10万个tokens(约7.5万个单词)。 tokens数量反映了模型可以处理的文本长度和上下文数量。tokens越多,模型理解语义的能力就越强)。它在法律、数学和编码等多个…...
Docker安装Hadoop分布式集群
一、准备环境 docker search hadoop docker pull sequenceiq/hadoop-docker docker images二、Hadoop集群搭建 1. 运行hadoop102容器 docker run --name hadoop102 -d -h hadoop102 -p 9870:9870 -p 19888:19888 -v /opt/data/hadoop:/opt/data/hadoop sequenceiq/hadoop-do…...
文盘 Rust -- tokio 绑定 cpu 实践
tokio 是 rust 生态中流行的异步运行时框架。在实际生产中我们如果希望 tokio 应用程序与特定的 cpu core 绑定该怎么处理呢?这次我们来聊聊这个话题。 首先我们先写一段简单的多任务程序。 use tokio::runtime; pub fn main() {let rt runtime::Builder::new_mu…...
微服务Ribbon-负载均衡策略和饥饿加载
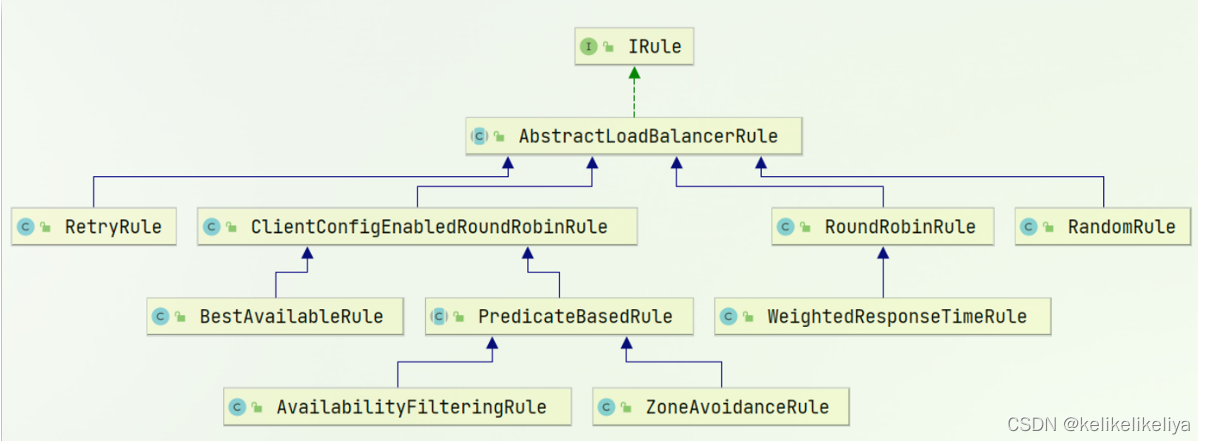
目录 一、负载均衡策略 1.1 负载均衡策略介绍 1.2 自定义负载均衡策略 二、饥饿加载 (笔记整理自bilibili黑马程序员课程) 一、负载均衡策略 1.1 负载均衡策略介绍 负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类&…...

uni-app 运行时报错“本应用使用HBuilderX x.x.x 或对应的cli版本编译,而手机端SDK版本是x.x.x。不匹配的版本可能造成应用异常”
uni-app 运行时报错“本应用使用HBuilderX x.x.x 或对应的cli版本编译,而手机端SDK版本是x.x.x。不匹配的版本可能造成应用异常” 出现原因 手机端SDK版本和HBuilderX版本不一致。 解决办法 方法一 项目根目录下找到 manifest.json 配置文件,选择源码…...
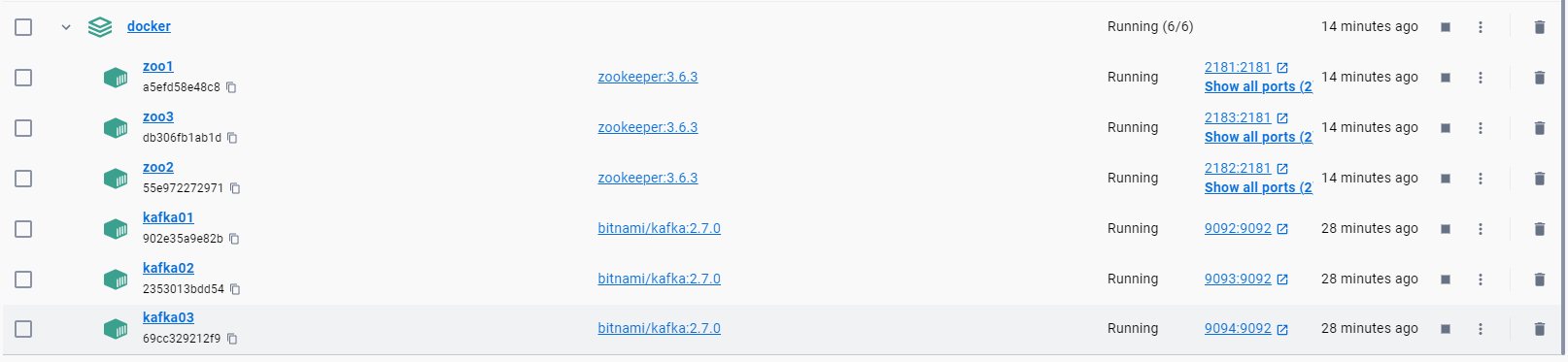
Windows使用docker desktop 安装kafka、zookeeper集群
docker-compose安装zookeeper集群 参考文章:http://t.csdn.cn/TtTYI https://blog.csdn.net/u010416101/article/details/122803105?spm1001.2014.3001.5501 准备工作: 在开始新建集群之前,新建好文件夹,用来挂载kafka、z…...

11 | 苹果十年财报分析
在本文中,我们将对苹果公司的财务报告进行深入分析,关注其销售收入、利润情况以及关键产品线的表现。我们将研究财报中的数据,挖掘背后的商业策略和市场动态,以便更好地了解苹果公司在不同市场环境下的业绩表现。通过对财报数据的解读和分析,我们将探讨苹果公司在竞争激烈…...

Zookeeper与Redis 对比
1. 为什么使用分布式锁? 使用分布式锁的目的,是为了保证同一时间只有一个 JVM 进程可以对共享资源进行操作。 根据锁的用途可以细分为以下两类: 1、 允许多个客户端操作共享资源,我们称为共享锁。 这种锁的一般是对共享资源具有幂…...
跨境商城服务平台搭建与开发(金融服务+税务管理)
随着全球电子商务的快速发展,跨境贸易已经成为一种新的商业趋势。在这个背景下,搭建一个跨境商城服务平台,提供金融服务、税务管理等一系列服务,可以极大地促进跨境贸易的发展。本文将详细阐述跨境商城服务平台搭建与开发的步骤。…...

docker配置文件
/etc/docker/daemon.json 文件作用 /etc/docker/daemon.json 文件是 Docker 配置文件,用于配置 Docker 守护进程的行为和参数。Docker 守护进程是负责管理和运行 Docker 容器的后台进程,通过修改 daemon.json 文件,可以对 Docker 守护进程进…...

[具身智能-320]:语料库就是“语言材料的仓库”。
简单来说,语料库就是“语言材料的仓库”。在人工智能和语言学领域,它指的是经过科学取样、加工和整理的大规模电子文本或数据集合。如果把大语言模型(LLM)比作一个正在上学的孩子,那么语料库就是它读的“书”、做的“题…...

【毫米波混合波束成形】第9章 多用户MIMO与干扰抑制的深度学习
目录 第一部分:原理详解 第9章 多用户干扰对齐与联合收发设计 9.1 多用户干扰对齐的网络求解 9.1.1 和速率最大化与最小用户速率公平性 9.1.1.1 加权最小均方误差(WMMSE)的展开 9.1.1.1.1 WMMSE迭代中接收波束与发射波束的交替更新层设计…...

Sabaki国际化与本地化:打造多语言围棋编辑环境
Sabaki国际化与本地化:打造多语言围棋编辑环境 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki Sabaki是一款优雅的围棋棋盘和SGF编辑器,为全球围棋…...
ClearerVoice-Studio精彩案例分享:16KHz电话录音经FRCRN处理后信噪比提升22dB
ClearerVoice-Studio精彩案例分享:16KHz电话录音经FRCRN处理后信噪比提升22dB 1. 案例背景与挑战 在日常工作和生活中,电话录音是我们经常遇到的需求。无论是重要的商务通话、客户服务记录,还是远程会议内容,清晰的录音质量都至…...
)
GraalVM Native Image内存优化实战手册(含JDK21+GraalVM24.1插件全链路安装避坑清单)
第一章:GraalVM Native Image内存优化实战手册导论GraalVM Native Image 将 Java 应用提前编译为独立的本地可执行文件,显著降低启动延迟与运行时内存开销。然而,默认构建的 native image 常因反射、动态代理、资源加载等隐式依赖而保留大量未…...

不用装软件!这款MicroPython浏览器 IDE :让你在手机上也能调试树莓派 Pico亚
1、普通的insert into 如果(主键/唯一建)存在,则会报错 新需求:就算冲突也不报错,用其他处理逻辑 回到顶部 2、基本语法(INSERT INTO ... ON CONFLICT (...) DO (UPDATE SET ...)/(NOTHING)) 语…...

AMA-SAM:用于高保真组织学细胞核分割的对抗性多域对齐万物分割模型/文献速递-多模态医学影像最新进展
2026.4.8本文提出了AMA-SAM框架,通过引入条件梯度反转层(CGRL)实现鲁棒的多域对齐,并设计高分辨率解码器(HR-Decoder)以保留精细细节,从而增强了万物分割模型(SAM)在高分…...

基于Python的情绪识别模型:从原理到实践
摘要情绪识别作为自然语言处理(NLP)领域的重要分支,在人机交互、社交媒体分析、客户服务等场景中具有广泛应用。本文系统介绍基于Python的情绪识别模型构建方法,涵盖数据预处理、特征提取、模型选择、训练评估及部署应用等关键环节…...

AWS首席执行官解释为何同时投资Anthropic与OpenAI并不存在冲突
AWS首席执行官马特加曼表示,亚马逊近期对OpenAI完成了500亿美元的投资,此前已与Anthropic建立长期合作关系并累计投入80亿美元。他认为,对于这家云计算巨头而言,处理此类利益冲突早已是家常便饭。加曼在本周于旧金山举办的HumanX大…...

如何在Windows、Linux和macOS上快速配置Ryujinx Switch模拟器:5个关键步骤提升游戏体验
如何在Windows、Linux和macOS上快速配置Ryujinx Switch模拟器:5个关键步骤提升游戏体验 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想要在电脑上畅玩Switch游戏吗&…...