java高频面试题(2023最新)
目录
- 一.java基础
- 1.八大基础类型
- 2.java三大特性
- 3.重载和重写的区别
- 4.pubilc、protected、(dafault)不写、private修饰符的作用范围
- 5.==和equals的区别
- 6.hashcode()值相同,equals就一定为true
- 7.short s = 1;s = s + 1;(程序1)和 short s = 1; s += 1;(程序2)是否都能正常运行
- 8.说出下面程序的运行结果,及原因
- 9.&和&&的区别
- 10.String、StringBuffer、StringBuilder的区别
- 11.String rap = new String("ctrl");创建了几个对象?
- 12.什么是反射
- 13.浅拷贝和深拷贝的区别
- 14构造器能被重写吗
- 15.并发和并行
- 16.实例变量和类变量。
- 17.说出下面程序的运行结果,及原因
- 18.抽象类和接口的区别
- 19.Error和Exception有什么区别
- 20.NoClassDefFoundError和ClassNotFoundException区别
- 21.如果try{} 里有一个 return 语句,那么finalfly{} 里的代码会不会被执行,什么时候被执行,在 return 前还是后?
- 22.看一面代码执行结果是啥
- 22.final关键字有哪些用法?
- 23.jdk1.8的新特性
- 24.http中重定向和转发的区别
- 25.get和post请求的区别 delete、put
- 26.cookie和session的区别
- 27.java中的数据结构
- 28.什么是跨域?跨域的三要素
- 29.tomcat三个默认端口及其作用
- 30.throw 和 throws 的区别?
- 31.说一下你熟悉的设计模式
- 二.java集合
- 1.List、Set、Map的区别
- 2.List、Set、Map常用集合有哪些?
- 3.什么是哈希表
- 4.什么是哈希冲突
- 5.解决哈希冲突
- 6.HashMap的hash()算法,为什么不是h=key.hashcode(),而是key.hashcode()^ (h>>>16)
- 7.为什么HashMap的初始容量和扩容都是2的次幂
- 8.HashMap如果指定了不是2的次幂的容量会发生什么?
- 9.HashMap为什么线程不安全
- 10.解决Hashmap的线程安全问题
- 11.ConcurrentHashMap的原理
- 12.为什么用synchronized代替ReentrantLock
- 13.HashMap为什么使用链表
- 14.HashMap为什么使用红黑树
- 15.HashMap为什么不一上来就使用红黑树
- 16.说说你对红黑树的理解
- 17.为什么链表长度大于8,并且表的长度大于64的时候,链表会转换成红黑树?
- 18.为什么转成红黑树是8呢?而重新转为链表阈值是6呢?
- 19.为什么负载因子是0.75?
- 20.什么时候会扩容?
- 21.为什么不是满了扩容?
- 22.扩容过程
- 23.HashMap和Hashtable的区别
- 三.多线程
- 1.线程是什么?多线程是什么?
- 2.守护线程和用户线程
- 3.线程的各个状态
- 4.线程相关的基本方法有 wait,notify,notifyAll,sleep,join,yield 等
- 5.wait()和sleep()的区别?
- 6.为什么 wait()、notify()、notifyAll()方法定义在 Object 类里面,而不是 Thread 类?
- 7.实现多线程的方式
- 8.Runnable和Callable的区别
- 9.线程池的好处
- 10.线程池的七大参数
- 11.线程池的执行过程
- 12.四大方法
- 13.四大拒绝策略
- 14.什么是死锁?
- 15.造成死锁的四个必要条件
- 16.线程安全主要是三方面
- 17.volatile和synchronized的区别
- 18.synchronized和lock的区别
- 四.jvm
- 1.jvm是什么?
- 2.jvm的作用
- 3.java文件的加载过程
- 4.jdk、jre、jvm的区别
- 5.类加载器的作用
- 6.类加载器的类型
- 7.双亲委派机制的加载过程
- 8.双亲委派机制的优缺点
- 9.为什么要打破双亲委派机制
- 10.打破双亲委派机制的方式
- 11.jvm的每个部分储存的都是什么
- 12.内存溢出(oom)和栈溢出
- 13.垃圾回收的作用区域
- 14.怎么判断对象是否可回收
- 15.四种引用类型 强引用 软引用 弱引用 虚引用
- 16.垃圾回收算法
- 17.轻GC(Minor GC)和 重GC(Full GC)
- 18.什么时候会发生重GC
- 五.锁
- 1.悲观锁和乐观锁
- 2.悲观锁和乐观锁的场景
- 3.自旋锁和自适应自旋锁
- 4.无锁、偏向锁、轻量级锁、重量级锁
- 5.公平锁和非公平锁
- 6.可重入锁
- 7.独享锁和共享锁
- 8.互斥锁和读写锁
- 9.分段锁
- 10.锁优化技术
后续会持续更新,广告回来更精彩!如果想看原理可以看看我的另几篇文章
没有过多的讲解原理,你们只要背会了,就能快乐两年半。
一.java基础
1.八大基础类型
数字型: 字节类型(byte)、短整型short、整型int、长整型Long、单精度浮点数float、双精度浮点数double
字符型: 字符类型char、
布尔型: 布尔类型boolean、
2.java三大特性
封装: 使用private关键字,让对象私有,防止无关的程序去使用。
继承: 继承某个类,使子类可以使用父类的属性和方法。
多态: 同一个行为,不同的子类具有不同的表现形式。
3.重载和重写的区别
重载: 发生在同一类中,函数名必须一样,参数类型、参数个数、参数顺序、返回值、修饰符可以不一样。
重写: 发生在父子类中,函数名、参数、返回值必须一样,访问修饰符必须大于等于父类,异常要小于等于父类,父类方法是private不能重写。
4.pubilc、protected、(dafault)不写、private修饰符的作用范围
pubilc: 同类、同包、子类、不同包都可以使用。
protected: 同类、同包、子类可以使用,不同包不能。
(dafault)不写: 同类、同包可以使用,子类、不同包不能。
private: 只有同类可以。
5.==和equals的区别
==: 基础类型比较的值,引用类型比较的是地址值。
equals: 默认,比较的是值。重写之后比较的是两个对象是否相同,比如String类重写equals源码首先比较是否都是String对象,然后再向下比较。
6.hashcode()值相同,equals就一定为true
不一定,因为 "重地"和"通话"的hashcode值就相同,但是equals()就为false。
但是equals()为true,那么hashcode一定相同。
7.short s = 1;s = s + 1;(程序1)和 short s = 1; s += 1;(程序2)是否都能正常运行
程序1会编译报错,因为 s + 1的1是int类型,因为类型不兼容。强制转换失败。
程序2可以正常运行,因为java在复合赋值解释是 E1 += E2,等价于 E1 = (T)(E1 + E2),T是E1的类型,因此s += 1等价于 s = (short)(s + 1),所以进行了强制类型的转换,所以可以正常编译。
8.说出下面程序的运行结果,及原因
public static void main(String[] args) {Integer a = 128, b = 128, c = 127, d = 127;System.out.println(a == b);System.out.println(c == d);
}
结果:false,true
因为Integer = a,相当于自动装箱(基础类型转为包装类),因为Integer引入了IntegerCache来缓存一定的值,IntegerCache默认是 -128~127,所以128超过了范围,a和b不是相同对象,c和d是相同对象。
可以通过jvm启动时,修改缓存的上限。
9.&和&&的区别
&&: 如果一边为假,就不比较另一边。具有短路行
&: 两边都为假,结果才为假,多用于位运算。
10.String、StringBuffer、StringBuilder的区别
String: 适用于少量字符串。创建之后不可更改,对String的修改会生成新的String对象。
StringBuilder: 适用于大量字符串,线程不安全,性能更快。单线程使用
StringBuffer: 适用于大量字符串,线程安全。多线程使用,用synchronized关键字修饰。
11.String rap = new String(“ctrl”);创建了几个对象?
一个或两个,如果常量池存在,那就在堆创建一个实例对象,否则常量池也需要创建一个。
12.什么是反射
在运行过程中,对于任何一个类都能获取它的属性和方法,任何一个对象都能调用其方法,动态获取信息和动态调用,就是反射。
13.浅拷贝和深拷贝的区别
浅拷贝: 基础数据类型复制值,引用类型复制引用地址,修改一个对象的值,另一个对象也随之改变。
深拷贝: 基础数据类型复制值,引用类型在新的内存空间复制值,新老对象不共享内存,修改一个值,不影响另一个。
深拷贝相对浅拷贝速度慢,开销大。
14构造器能被重写吗
不能,可以被重载。
15.并发和并行
并发: 一个处理器同时处理多个任务。(一个人同时吃两个苹果)
并行: 多个处理器同时处理多个任务。(两个人同时吃两个苹果)
16.实例变量和类变量。
类变量是被static所修饰的,没有被static修饰的叫实例变量也叫成员变量。同理也存在类对象和实例对象,类方法和实例方法。
//类变量
public static String kunkun1 = "鸡你太美";//实例变量(成员变量)
public String kunkun2 = "鸡你不美";
17.说出下面程序的运行结果,及原因
public class InitialTest {public static void main(String[] args) {A ab = new B();ab = new B();}
}
class A {static { // 父类静态代码块System.out.print("A");}public A() { // 父类构造器System.out.print("a");}
}
class B extends A {static { // 子类静态代码块System.out.print("B");}public B() { // 子类构造器System.out.print("b");}
}结果:ABabab
原因:
①执行顺序是 父类静态代码块(父类静态变量) -> 子类静态代码块(子类静态变量) -> 父类非静态代码块 -> 父类构造方法 -> 子类非静态代码块 -> 子类构造方法
②静态代码块(静态变量)只执行一次。
18.抽象类和接口的区别
抽象类只能单继承,接口可以实现多个。
抽象类有构造方法,接口没有构造方法。
抽象类可以有实例变量,接口中没有实例变量,有常量。
抽象类可以包含非抽象方法,接口在java7之前所有方法都是抽象的,java之后可以包含非抽象方法。
抽象类中方法可以是任意修饰符,接口中java8之前都是public,java9支持private。
扩展:普通类是亲爹,会被怎么学都告诉你,抽象类(多个类具有相同的东西,拿出来放抽象类)是师傅,教你一部分秘籍,然后告诉你怎么学。接口(规范了某些行为)是干爹,只给你秘籍,怎么学全靠你。
19.Error和Exception有什么区别
Error: 程序无法处理,比较严重的问题,程序会立即崩溃,jvm停止运行。
Exception: 程序本身可以处理(向上抛出或者捕获)。编译时异常和运行时异常
20.NoClassDefFoundError和ClassNotFoundException区别
**NoClassDefFoundError:**在打包时漏掉了某些类或者打包时存在,然后你把target里的类删除,然后jvm运行时找不到报错。
**ClassNotFoundException:**在编译的时候某些类找不到,然后报错。
21.如果try{} 里有一个 return 语句,那么finalfly{} 里的代码会不会被执行,什么时候被执行,在 return 前还是后?
会执行,在return之前执行,如果finally有return那么try的return就会失效。
22.看一面代码执行结果是啥
public class TryDemo {public static void main(String[] args) {System.out.println(test1());}public static int test1() {int i = 0;try {i = 2;return i;} finally {i = 3;}}
}
结果 2
因为在return前,jvm会把2暂存起来,所以当i改变了,回到try时,还是会返回暂存的值。
22.final关键字有哪些用法?
修饰类: 不能被继承。
修饰方法: 不能被重写。
修饰变量: 声明时给定初始值,只能读取不能修改。如果是对象引用不能改,但是对象的属性可以修改。
23.jdk1.8的新特性
①lambda 表达式
②方法引用
③加入了base64的编码器和解码器
④函数式接口
⑤接口允许定义非抽象方法,使用default关键字即可
⑥时间日期类改进
24.http中重定向和转发的区别
重定向发送两次请求,转发发送一次请求
重定向地址栏会变化,转发地址栏不会变化
重定向是浏览器跳转,转发是服务器跳转
重定向可以跳转任意网址,转发只能跳转当前项目
重定向会有数据丢失,转发不会数据丢失
25.get和post请求的区别 delete、put
get是不安全的,数据放在url中,post相对来说安全
get传送的数据量小,post传送的数据量大
get效率比post高,是form的默认提交方法
26.cookie和session的区别
存储位置不同:cookie放在客户端电脑,session放在服务器端内存的一个对象
存储容量不同:cookie <=4KB,一个站点最多保存20个cookie,session是没有上限的,但是性能考虑不要放太多,而且要设置session删除机制
存储方式不同:cookie只能存储ASCLL字符串,session可以存储任何类型的数据
隐私策略不同:cookie放在本地,别人可以解析,进行cookie欺骗,session放在服务器,不存在敏感信息泄露
有效期不同:可以设置cookie的过期时间,session依赖于jsessionID的cookie,默认时间为-1,只需要关闭窗口就会失效
27.java中的数据结构
数组、链表、哈希表、栈、堆、队列、树、图
28.什么是跨域?跨域的三要素
跨域指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制
协议、域名、端口
注意:localhost和127.0.0.1虽然都指向本机,但也属于跨域
29.tomcat三个默认端口及其作用
8005:这个端口负责监听关闭tomcat的请求。
8009:接受其他服务器的请求
8080:用于监听浏览器发送的请求
30.throw 和 throws 的区别?
throw:抛出一个异常。
throws:声明一个异常。
31.说一下你熟悉的设计模式
单例模式: 保证被创建一次,节省系统开销。
工厂模式: 解耦代码。
观察者模式: 定义了对象之间的一对多的依赖,这样一来,当一个对象改变时,它的所有的依赖者都会收到通知并自动更新。
代理模式: 代理对象具备被代理对象的功能,并代替被代理对象完成相应操作,并能够在操作执行的前后,对操作进行增强处理。
模板模式: 较少代码冗余。例如:redis模板。
二.java集合
1.List、Set、Map的区别
List集合有序、可重复的单例集合。
Set集合无序、不可重复的单例集合。
Map集合有序、k不可重复,v可重复的双例集合。
2.List、Set、Map常用集合有哪些?
List
vector: 底层是数组,方法加了synchronized来保证线程安全,所以效率较慢,使用ArrayList替代。
ArrayList: 线程不安全,底层是数组,因为数组都是连续的地址,所以查询比较快。增删比较慢,增会生成一个新数组,把新增的元素和原有元素放到新数组中,删除会导致元素移动,所以增删速度较慢。
LinkedList: 线程不安全,底层是链表,因为地址不是连续的,都是一个节点和一个节点相连,每次查询都得重头开始查询,所以查询慢,增删只是断裂某个节点对整体影响不大,所以增删速度较快。
Set
HashSet: 底层是哈希表(数组+链表或数组+红黑树),在链表长度大于8时转为红黑树,在红黑树节点小于6时转为链表。其实就是实现了HashMap,值存入key,value是一个final修饰的对象。
TreeSet: 底层是红黑树结构,就是TreeMap实现,可以实现有序的集合。String和Integer可以根据值进行排序。如果是对象需要实现Comparator接口,重写compareTo()方法制定比较规则。
LinkedHashSet: 实现了HashSet,多一条链表来记录位置,所以是有序的。
Map<key,value>双例结构
TreeMap: 底层是红黑树,key可以按顺序排列。
HashMap: 底层是哈希表,可以很快的储存和检索,无序,大量迭代情况不佳。
LinkedHashMap: 底层是哈希表+链表,有序,大量迭代情况佳。
3.什么是哈希表
根据关键码值(Key value)而直接进行访问的数据结构,在一个表中,通过H(key)计算出key在表中的位置,H(key)就是哈希函数,表就是哈希表。
4.什么是哈希冲突
不用的key通过哈希函数计算出相同的储存地址,这就是哈希冲突。
5.解决哈希冲突
(1)开放地址法
如果发生哈希冲突,就会以当前地址为基准,再去寻找计算另一个位置,直到不发生哈希冲突,也叫再散列方法。
寻找的方法有:① 线性探测 1,2,3,m
② 二次探测 1的平方,-1的平方,2的平方,-2的平方,k的平方,-k的平方,k<=m/2
③ 随机探测 生成一个随机数,然后从随机地址+随机数++。
(2)链地址法
冲突的哈希值,连到到同一个链表上。
(3)再哈希法
多个哈希函数,发生冲突,就在用另一个算计,直到没有冲突。
(4)建立公共溢出区
哈希表分成基本表和溢出表,与基本表发生冲突的都填入溢出表。
6.HashMap的hash()算法,为什么不是h=key.hashcode(),而是key.hashcode()^ (h>>>16)
得到哈希值然后右移16位,然后进行异或运算,这样使哈希值的低16位也具有了一部分高16位的特性,增加更多的变化性,减少了哈希冲突。
7.为什么HashMap的初始容量和扩容都是2的次幂
因为计算元素存储的下标是(n-1)&哈希值,数组初始容量-1,得到的二进制都是1,这样可以减少哈希冲突,可以更好的均匀插入。
8.HashMap如果指定了不是2的次幂的容量会发生什么?
会获得一个大于指定的初始值的最接近2的次幂的值作为初始容量。
9.HashMap为什么线程不安全
jdk1.7中因为使用头插法,再扩容的时候,可能会造成闭环和数据丢失。
jdk1.8中使用尾插法,不会出现闭环和数据丢失,但是在多线程下,会发生数据覆盖。(put操作中,在putVal函数里) 值的覆盖还要长度的覆盖。
10.解决Hashmap的线程安全问题
(1)使用Hashtable解决,在方法加同步关键字,所以效率低下,已经被弃用。
(2)使用Collections.synchronizedMap(new HashMap<>()),不常用。
(3)ConcurrentHashMap(常用)
11.ConcurrentHashMap的原理
jdk1.7: 采用分段锁,是由Segment(继承ReentrantLock:可重入锁,默认是16,并发度是16)和HashEntry内部类组成,每一个Segment(锁)对应1个HashEntry(key,value)数组,数组之间互不影响,实现了并发访问。
jdk1.8: 抛弃分段锁,采用CAS(乐观锁)+synchronized实现更加细粒度的锁,Node数组+链表+红黑树结构。只要锁住链表的头节点(树的根节点),就不会影响其他数组的读写,提高了并发度。
12.为什么用synchronized代替ReentrantLock
①节省内存开销。ReentrantLock基于AQS来获得同步支持,但不是每个节点都需要同步支持,只有链表头节点或树的根节点需要同步,所以使用ReentrantLock会带来很大的内存开销。
②获得jvm支持,可重入锁只是api级别,而synchronized是jvm直接支持的,能够在jvm运行时做出相应的优化。
③在jdk1.6之后,对synchronized做了大量的优化,而且有多种锁状态,会从 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁一步步转换。
13.HashMap为什么使用链表
减少和解决哈希冲突,把冲突的值放在同一链表下。
14.HashMap为什么使用红黑树
当数据过多,链表遍历较慢,所以引入红黑树。
15.HashMap为什么不一上来就使用红黑树
维护成本较大,红黑树在插入新的数据后,可能会进行变色、左旋、右旋来保持平衡,所以当数据少时,就不需要红黑树。
16.说说你对红黑树的理解
①根节点是黑色。
②节点是黑色或红色。
③叶子节点是黑色。
④红色节点的子节点都是黑色。
⑤从任意节点到其子节点的所有路径都包含相同数目的黑色节点。
红黑树从根到叶子节点的最长路径不会超过最短路径的2倍。保证了红黑树的高效。
17.为什么链表长度大于8,并且表的长度大于64的时候,链表会转换成红黑树?
因为链表长度越长,哈希冲突概率就越小,当链表等于8时,哈希冲突就非常低了,是千万分之一,我们的map也不会存那么多数据,如果真要存那么多数据,那就转为红黑树,提高查询和插入的效率。
18.为什么转成红黑树是8呢?而重新转为链表阈值是6呢?
因为如果都是8的话,那么会频繁转换,会浪费资源。
19.为什么负载因子是0.75?
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;
加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容rehash操作的次数。
“冲突的机会”与“空间利用率”之间,寻找一种平衡与折中。
又因为根据泊松分布,当负载因子是0.75时,平均值时0.5,带入可得,当链表为8时,哈希冲突发生概率就很低了。
20.什么时候会扩容?
元素个数 > 数组长度 * 负载因子 例如 16 * 0.75 = 12,当元素超过12个时就会扩容。
链表长度大于8并且表长小于64,也会扩容
21.为什么不是满了扩容?
因为元素越多,空间利用率是高了,但是发生哈希冲突的几率也增加了。
22.扩容过程
jdk1.7: 会生成一个新table,然后会把旧table复制到新table,因为是头插法,在线程不安全的时候,可能会出现闭环和数据丢失。
jdk1.8: 记录旧table和新table,新table是旧table长度的两倍,然后循环旧table,把元素插入进新table。
23.HashMap和Hashtable的区别
①HashMap,运行key和value为null,Hashtable不允许为null。
②HashMap线程不安全,Hashtable线程安全。
三.多线程
1.线程是什么?多线程是什么?
线程: 是最小的调度单位,包含在进程中。
多线程: 多个线程并发执行的技术。
2.守护线程和用户线程
守护线程: jvm给的线程。比如:GC守护线程。
用户线程: 用户自己定义的线程。比如:main()线程。
拓展:
Thread.setDaemon(false)设置为用户线程
Thread.setDaemon(true)设置为守护线程
3.线程的各个状态
新建(New): 新建一个线程。
就绪(Runnable): 抢夺cpu的使用权。
运行(Running): 开始执行任务。
阻塞(Blocked): 让线程等待,等待结束进入就绪队列。
死亡(Dead): 线程正常结束或异常结束。
4.线程相关的基本方法有 wait,notify,notifyAll,sleep,join,yield 等
wait(): 线程等待,会释放锁,用于同步代码块或同步方法中,进入等待状态
sleep(): 线程睡眠,不会释放锁,进入超时等待状态
yield(): 线程让步,会使线程让出cpu使用权,进入就绪状态
join(): 指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。
notify(): 随机唤醒一个在等待中的线程,进入就绪状态。
notifyAll(): 唤醒全部在等待中的线程,进入就绪状态。
5.wait()和sleep()的区别?
① wait() 来自Object,sleep()来自Thread。
② wait()会释放锁,sleep()不会释放锁。
③ wait()只能用在同步方法或代码块中,sleep()可以用在任何地方。
④ wait()不需要捕获异常,sleep()需要捕获异常。
6.为什么 wait()、notify()、notifyAll()方法定义在 Object 类里面,而不是 Thread 类?
① 锁可以是任何对象,如果在Thread类中,那只能是Thread类的对象才能调用上面的方法了。
② java中进入临界区(同步代码块或同步方法),线程只需要拿到锁就行,而并不关心锁被那个线程持有。
③ 上面方法是java两个线程之间的通信机制,如果不能通过类似synchronized这样的Java关键字来实现这种机制,那么Object类中就是定义它们最好的地方,以此来使任何Java对象都可以拥有实现线程通信机制的能力。
7.实现多线程的方式
①继承Thread类。
②实现Runnable接口
③实现Callable接口
④线程池
8.Runnable和Callable的区别
①Runnable没有返回值,Callable有返回值。
②Runnable只能抛出异常,不能捕获,Callable 能抛出异常,也能捕获。
9.线程池的好处
① 线程是稀缺资源,使用线程池可以减少线程的创建和销毁,每个线程都可重复使用。
② 可以根据系统的需求,调整线程池里面线程的个数,防止了因为消耗内存过多导致服务器崩溃。
10.线程池的七大参数
corePoolSize: 核心线程数,创建不能被回收,可以设置被回收。
maximumPoolSize: 最大线程数。
keepAliveTime: 空闲线程存活时间。
unit: 单位。
workQueue: 等待队列。
handler: 拒绝策略。
11.线程池的执行过程
①接到任务,判断核心线程池是否满了,没满执行任务,满了放入等待队列。
②等待队列没满,存入队列,等待执行,满了去查看最大线程数。
③最大线程数没满,执行任务,满了执行拒绝策略。
12.四大方法
①ExecutorService executor = Executors.newCachedThreadPool(): 创建一个缓存线程池,灵活回收线程,任务过多,会oom。
②ExecutorService executor = Executors.newFixedThreadPool(): 创建一个指定线程数量的线程池。提高了线程池的效率和线程的创建的开销,等待队列可能堆积大量请求,导致oom。
③ExecutorService executor = Executors.newSingleThreadPool(): 创建一个单线程,保证线程的有序,出现异常再次创建,速度没那么快。
④ExecutorService executor = Executors.newScheduleThreadPool(): 创建一个定长的线程池,支持定时及周期性任务执行。
13.四大拒绝策略
①new ThreadPoolExecutor.AbortPolicy(): 添加线程池被拒绝,会抛出异常(默认策略)。
②new ThreadPoolExecutor.CallerRunsPolicy(): 添加线程池被拒绝,不会放弃任务,也不会抛出异常,会让调用者线程去执行这个任务(就是不会使用线程池里的线程去执行任务,会让调用线程池的线程去执行)。
③new ThreadPoolExecutor.DiscardPolicy(): 添加线程池被拒绝,丢掉任务,不抛异常。
④new ThreadPoolExecutor.DiscardOldestPolicy(): 添加线程池被拒绝,会把线程池队列中等待最久的任务放弃,把拒绝任务放进去。
14.什么是死锁?
各进程互相等待对方手里的资源,导致各进程都阻塞,无法向前推进的现象。
15.造成死锁的四个必要条件
互斥: 当资源被一个线程占用时,别的线程不能使用。
不可抢占: 进程阻塞时,对占用的资源不释放。
不剥夺: 进程获得资源未使用完,不能被强行剥夺。
循环等待: 若干进程之间形成头尾相连的循环等待资源关系。
16.线程安全主要是三方面
原子性: 操作不可分割,要么全部执行,并且不能被打断,否则全部不执行。
可见性: 可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性: 程序执行的顺序按照代码的先后顺序执行。
保证原子性
使用锁 synchronized和 lock。
使用CAS (compareAndSet:比较并交换),CAS是cpu的并发原语)。
保证可见性
使用锁 synchronized和 lock。
使用volatile关键字 。
保证有序性
使用 volatile 关键字
使用 synchronized 关键字。
17.volatile和synchronized的区别
① volatile仅能使用在变量级别的,synchronized可以使用在变量、方法、类级别的
② volatile不具备原子性,具备可见性,synchronized有原子性和可见性。
③ volatile不会造成线程阻塞,synchronized会造成线程阻塞。
④ volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized要好。
18.synchronized和lock的区别
① synchronized是关键字,lock是java类,默认是不公平锁(源码)。
② synchronized适合少量同步代码,lock适合大量同步代码。
③ synchronized会自动释放锁,lock必须放在finally中手工unlock释放锁,不然容易死锁。
四.jvm
1.jvm是什么?
java虚拟机,是实现java跨平台的核心组件。
2.jvm的作用
java中所有的类,必须被装载到jvm中才能使用,装载由类加载器完成,.class这个类型可以在虚拟机运行,但不是直接和操作系统交互,需要jvm解释给操作系统,解释的时候需要java类库,这样就能和操作系统交互。
3.java文件的加载过程
.java -> .class -> 类加载器 -> jvm
4.jdk、jre、jvm的区别
jdk: 包含java运行环境和开发环境、jvm、java类库。
jre: 包含java运行环境和jvm、java类库。
jvm: java虚拟机,是跨平台的核心组件。
5.类加载器的作用
将.class文件装载到jvm中,实质就是把文件从硬盘写到内存。
6.类加载器的类型
引导类加载器(Bootstrap ClassLoder): c++编写,jvm自带的加载器,负责加载java核心类库,该加载器无法直接获取。
拓展类加载器(Extension ClassLoder): 加载jre/lib/etc目录下的jar包。
系统类加载器(Application ClassLoder): 加载当前项目目录下的类或jar包,最常用的加载器。
自定义加载器(Custom ClassLoder): 开发人员自定义的。需要继承ClassLoader
7.双亲委派机制的加载过程
①接到类加载的请求。
②向上委托给父类加载器,直到引导类加载器。
③引导类加载器检查能否加载当前这个类,如果能,使用当前加载器,请求结束,如果不能,抛出异常,通知子加载器进行加载。
④重复③。
8.双亲委派机制的优缺点
优点:保证类加载的安全性,不管那个类被加载,都会被委托给引导类加载器,只有类加载器不能加载,才会让子加载器加载,这样保证最后得到的对象都是同样的一个。
缺点:子加载器可以使用父加载器加载的类,而父加载器不能使用子加载器加载的类。
9.为什么要打破双亲委派机制
子加载器可以使用父加载器加载的类,而父加载器不能使用子加载器加载的类。
例如:使用JDBC连接数据库,需要用到 com.mysql.jdbc.Driver和DriverManager类。然而DriverManager被引导类加载器所加载,而com.mysql.jdbc.Driver被当前调用者的加载器加载,使用引导类加载器加载不到,所以要打破双亲委派机制。
10.打破双亲委派机制的方式
① 自定义类加载器,重写loadclass方法。
② 使用线程上下文类(ServiceLoader:使父加载器可以加载子加载器的类)。
11.jvm的每个部分储存的都是什么
方法区(线程共享): 常量池、静态(static)变量以及方法信息(方法名、返回值、参数、修饰符等)等。
堆(线程共享): 是虚拟机内存中最大的一块,储存的是实例对象。
本地方法栈(线程不共享): 调用的本地方法,被native修饰的方法,java不能直接操作操作系统,所以需要native修饰的方法帮助。
虚拟机栈(线程不共享): 8大基本类型、对象引用、实例方法。
程序计数器(线程不共享): 每个线程启动是都会创建一个程序计数器,保存的是正在执行的jvm指令,程序计数器总是指向下一条将被执行指令的地址。
12.内存溢出(oom)和栈溢出
内存溢出的原因: (1)内存使用过多或者无法垃圾回收的内存过多,使运行需要的内存大于提供的内存。
(2)长期持有某些资源并且不释放,从而使资源不能及时释放,也称为内存泄漏。
解决: (1)进行jvm调优。-Xmx:jvm最大内存。-Xms:启动初始内存。-Xmn:新生代大小。 -Xss:每个虚拟机栈的大小。
(2)使用专业工具测试。
手动制造: 一直new对象就ok。
栈溢出原有: 线程请求的栈容量大于分配的栈容量。
解决: (1)修改代码 (2)调优 -Xss
手动制造: 一直调用实例方法。
13.垃圾回收的作用区域
作用在方法区和堆,主要实在堆中的伊甸园区。年轻代分为(伊甸园区和幸存区)
14.怎么判断对象是否可回收
可达性分析算法: 简单来说就是一个根对象通过引用链向下走,能走到的对象都是不可回收的。可作为根对象有: 虚拟机栈的引用的对象,本地栈的引用的对象,方法区引用的静态和常量对象。
引用计数算法: 每个对象都添加一个计数器,每多一个引用指向对象,计数器就加一,如果计数器为零,那么就是可回收的。
15.四种引用类型 强引用 软引用 弱引用 虚引用
强引用: 基于可达性分析算法,只有当对象不可达才能被回收,否则就算jvm满了,也不会被回收,会抛出oom。
软引用: 一些有用但是非必须的对象,当jvm即将满了,会将软引用关联对象回收,回收之后如果内存还是不够,会抛出oom。
弱引用: 不论内存是否够,只要开始垃圾回收,软引用的关联对象就会被回收。
虚引用: 最弱的引用和没有一样,随时可能被回收。
16.垃圾回收算法
标记-清除算法(适用老年代): 先把可回收的对象进行标记,然后再进行清除。
优点:算法简单。
缺点:产生大量的内存碎片,效率低。
复制算法(适用年轻代): 把内存分成两个相同的块,一个是from,一个是to,每次只使用一个块,当一个块满了,就把存活的对象放到另一个块中,然后清空当前块。主要用在年轻区中的幸存区。
优点:效率较高,没有内存碎片。
缺点:内存利用率低。
标记-整理算法(适用老年代): 标记-清除算法的升级版,也叫标记-压缩算法,先进行标记,然后让存活对象向一端移动,然后清除掉边界以外的内存。
有点:解决了内存利用率低和避免了内存碎片。
缺点:增加了一个移动成本。
17.轻GC(Minor GC)和 重GC(Full GC)
轻GC: 普通GC,当新对象在伊甸园区申请内存失败时,进行轻GC,会回收可回收对象,没有被回收的对象进入幸存区,新对象分配内存极大部分都是在伊甸园区,所以这个区GC比较频繁。一个对象经历15次GC,会进入老年区,可以设置。
重GC: 全局GC,对整个堆进行回收,所以要比轻GC慢,因此要减少重GC,我们所说的jvm调优,大部分都是针对重GC。
18.什么时候会发生重GC
①当老年区满了会重GC:年轻区对象进入或创建大对象会满。
②永久代满了会重GC。
③方法区满了会重GC。
④system.gc()会重GC 。
⑤轻GC后,进入老年代的大小大于老年代的可用内存会,第一次轻GC进入老年代要2MB,第二次的时候会判断是否大于2MB,不满足就会重GC。
五.锁
1.悲观锁和乐观锁
悲观锁: 在修改数据时,一定有别的线程来使用,所以在获取数据的时候会加锁。java中的synchronized和Lock都是悲观锁。
乐观锁: 在修改数据时,一定没有别的线程来使用,所以不会添加锁。但是在更新数据的时候,会查看有没有线程修改数据。比如:版本号和CAS原理(无锁算法)。
2.悲观锁和乐观锁的场景
悲观锁: 更适合写操作多的场景,因为先加锁可以保证数据的正确。
乐观锁: 更适合读操作多的场景,因为不加锁会让读操作的性能提升。
3.自旋锁和自适应自旋锁
前言:因为线程竞争,会导致线程阻塞或者挂起,但是如果同步资源的锁定时间很短,那么阻塞和挂起的花费的资源就得不偿失。
自旋锁: 当竞争的同步资源锁定时间短,就让线程自旋,如果自旋完成后,资源释放了锁,那线程就不用阻塞,直接获取资源,减少了切换线程的开销。实现原理是CAS。
缺点:占用了处理器的时间,如果锁被占用的时间短还好,如果长那就白白浪费了处理器的时间。所以要限定自旋次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
自适应自旋锁: 自旋次数不固定,是由上一个在同一个锁上的自旋时间和锁拥有者的状态决定。如果在同一个锁对象上,自旋刚刚获得锁,并且持有锁的线程在运行,那么虚拟机会认为这次自旋也可能成功,那么自旋的时间就会比较长,如果某个锁,自旋没成功获得过,那么可能就会直接省掉自旋,进入阻塞,避免浪费处理器时间。
4.无锁、偏向锁、轻量级锁、重量级锁
这四个锁是专门针对synchronized的,在 JDK1.6 中,对 synchronized 锁的实现引入了大量的优化,并且 synchronized 有多种锁状态。级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
无锁: 就是乐观锁。
偏向锁: 当只有一个线程访问加锁的资源,不存在多线程竞争的情况下,那么线程不需要重复获取锁,这时候就会给线程加一个偏向锁。(对比Mark Word解决加锁问题,避免CAS操作)
轻量级锁: 是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。(CAS+自旋)
重量级锁: 若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。(将除了拥有锁的线程以外的线程都阻塞)
5.公平锁和非公平锁
公平锁: 多个线程按照申请锁的顺序来获取锁。 Lock lock = new ReentrantLock(true); 默认是非公平锁,设置为true是公平锁。
优点:等待线程不会饿死。
缺点:CPU唤醒线程得开销比非公平锁要大。
非公平锁: 多个线程获取锁的顺序并不是按照申请锁的顺序。 sybchronized和lock都是非公平锁。
优点:减少唤醒线程得开销。
缺点:可能会出现线程饿死或者很久获得不了锁。
6.可重入锁
可重入锁: 也叫递归锁,同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。(提前锁对象是同一个对象或者类)。ReentrantLock和synchronized都是可重入锁。
7.独享锁和共享锁
独享锁: 独占锁是指锁一次只能被一个线程所持有。如果一个线程对数据加上排他锁后,那么其他线程不能再对该数据加任何类型的锁。获得独占锁的线程即能读数据又能修改数据。synchronized和Lock的显示类就是独占锁。
共享锁: 共享锁是指锁可被多个线程所持有。如果一个线程对数据加上共享锁后,那么其他线程只能对数据再加共享锁,不能加独占锁。获得共享锁的线程只能读数据,不能修改数据。
8.互斥锁和读写锁
互斥锁: 是独享锁的实现,某一资源同时只允许一个访问者对其访问。具有唯一和排它性。
读写锁: 是共享锁的实现,读写锁管理一组锁,一个是只读的锁,一个是写锁。读锁可以在没有写锁的时候被多个线程同时持有,而写锁是独占的。写锁的优先级要高于读锁。并发度要比互斥锁高,因为可以拥有多个读锁。
9.分段锁
是锁的设计,不是具体的某一种锁,分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
ConcurrentHashMap的锁机制jdk1.7用的就是分段锁。
10.锁优化技术
锁粗化: 将多个同步块的数量减少,并将单个同步块的作用范围扩大,本质上就是将多次上锁、解锁的请求合并为一次同步请求。
锁消失: 锁消除是指虚拟机编译器在运行时检测到了共享数据没有竞争的锁,从而将这些锁进行消除。
参考:
https://blog.csdn.net/guoguo527/article/details/118004077
https://www.cnblogs.com/jyroy/p/11365935.html
相关文章:
)
java高频面试题(2023最新)
目录一.java基础1.八大基础类型2.java三大特性3.重载和重写的区别4.pubilc、protected、(dafault)不写、private修饰符的作用范围5.和equals的区别6.hashcode()值相同,equals就一定为true7.short s 1;s s 1;(程序1)和 short s 1ÿ…...

视觉感知(二):车位线检测
1. 简介 本期为大家带来车位线检测相关知识点,以及算法工程落地的全流程演示。车位线检测是自动泊车领域必不可缺的一环,顾名思义就是采用环视鱼眼相机对路面上的车位线进行检测,从而识别出车位进行泊车。 较为常规的做法是使用四颗鱼眼相机环视拼接然后在鸟瞰图上做停车位…...

2023.2.10学习记录Docker容器
Docker 必须跑在Linux内核上 镜像是一个轻量级可执行的独立软件包 新建一个docker容器只需要几秒钟 Docker常用命令 启动类命令 镜像命令 容器命令 docker images docker search --limit 5 redis docker pull redis:6.0.8 docker system df 查看镜像/容器/…...

扩散模型diffusion model用于图像恢复任务详细原理 (去雨,去雾等皆可),附实现代码
文章目录1. 去噪扩散概率模型2. 前向扩散3. 反向采样3. 图像条件扩散模型4. 可以考虑改进的点5. 实现代码1. 去噪扩散概率模型 扩散模型是一类生成模型, 和生成对抗网络GAN 、变分自动编码器VAE和标准化流模型NFM等生成网络不同的是, 扩散模型在前向扩散过程中对图像逐步施加噪…...
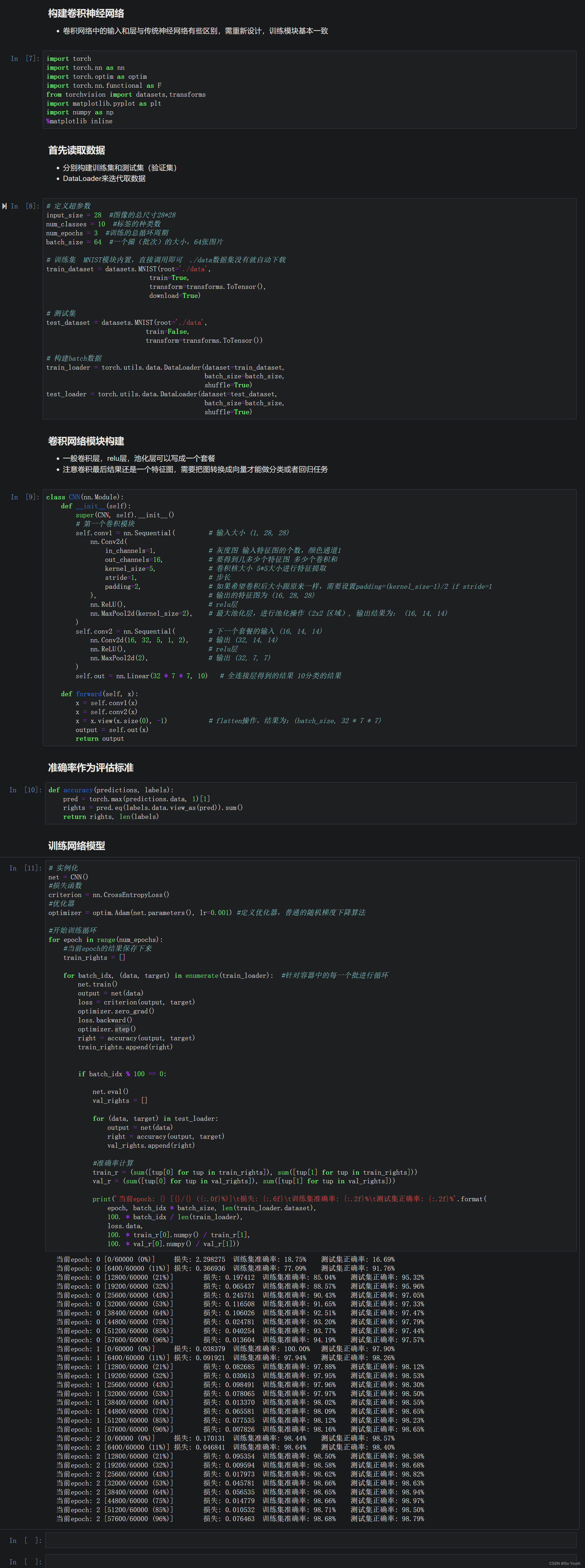
pytorch
PyTorch基础 import torch torch.__version__ #return 1.13.1cu116基本使用方法 矩阵 x torch.empty(5, 3)tensor([[1.4586e-19, 1.1578e27, 2.0780e-07],[6.0542e22, 7.8675e34, 4.6894e27],[1.6217e-19, 1.4333e-19, 2.7530e12],[7.5338e28, 8.1173e-10, 4.3861e-43],[2.…...

软件测试—对职业生涯发展的一些感想
目录:导读 职场生涯 1、短期规划 2、长期规划 自身定位 1、你在哪儿? 2、你想要什么? 3、你拥有什么? 4、你需要做什么?什么时候做? 5、淡定啊淡定 最近工作不是很忙,有空都是在看书&a…...
5年经验之谈:月薪3000到30000,测试工程师的变“行”记!
自我介绍下,我是一名转IT测试人,我的专业是化学,去化工厂实习才发现这专业的坑人之处,化学试剂害人不浅,有毒,易燃易爆,实验室经常用丙酮,甲醇,四氯化碳,接触…...
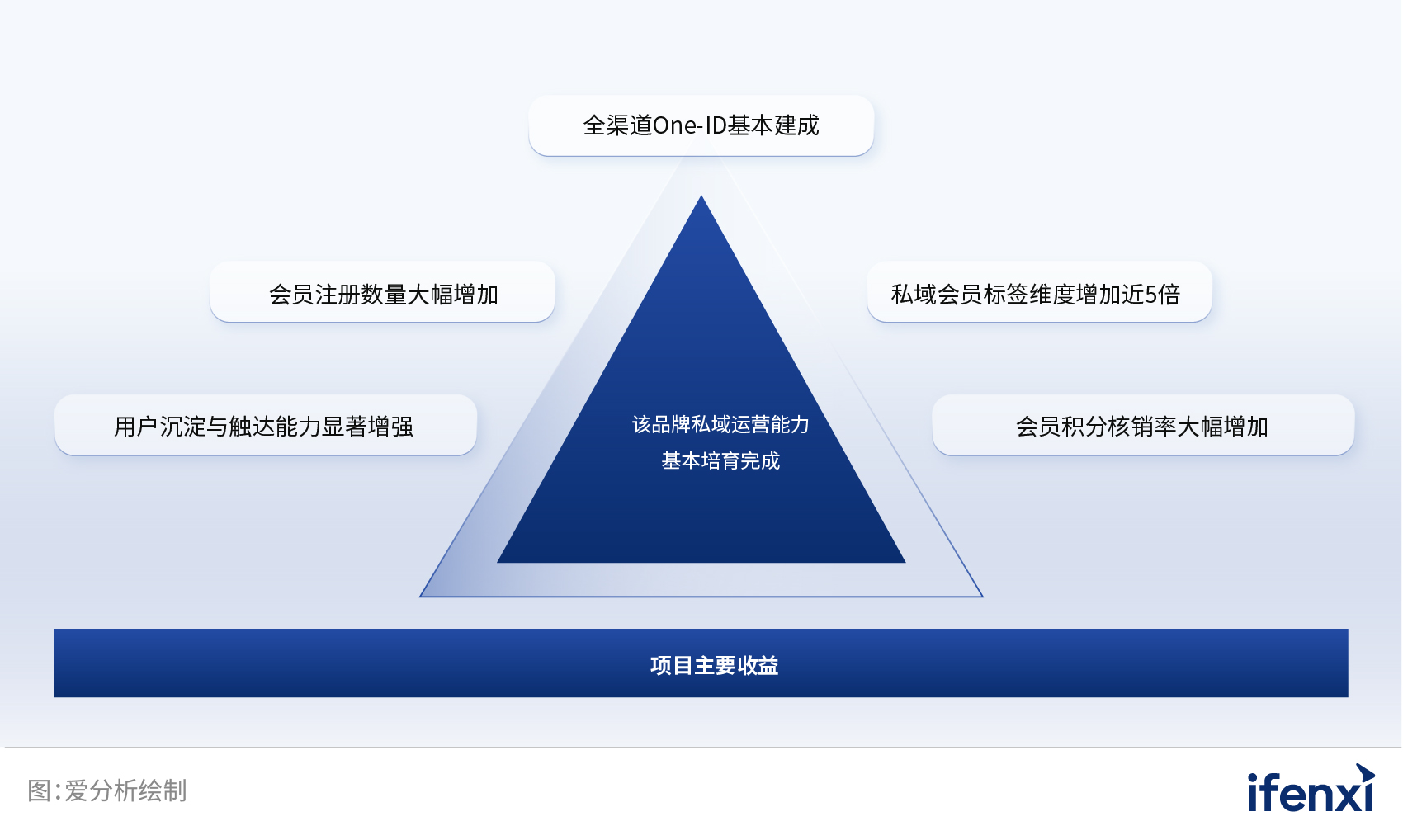
全价值链赋能,数字化助力营销价值全力释放 | 爱分析报告
报告编委 张扬 爱分析联合创始人&首席分析师 文鸿伟 爱分析高级分析师 王鹏 爱分析分析师 外部专家(按姓氏拼音排序) 黄洵 客易达 联合创始人 毛健 云徙科技 副总裁 & COO 特别鸣谢(按拼音排序) 报告摘要 在…...

【自学Docker 】Docker search命令
大纲 Docker search命令 docker search命令教程 docker search 命令用于从 Docker Hub 查找镜像。 docker search命令语法 haicoder(www.haicoder.net)# docker search [OPTIONS] TERMdocker search命令参数 参数描述docker search --filter设置过滤条件。docker search -…...
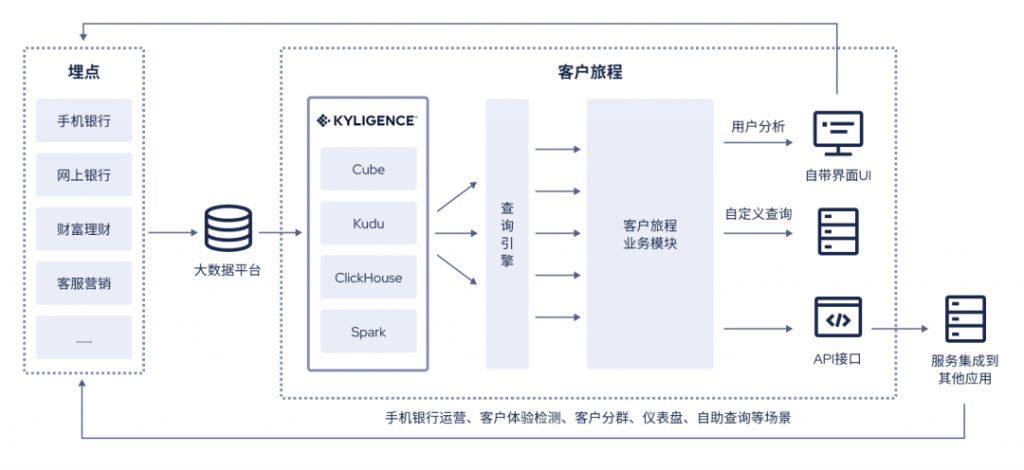
银行零售如何更贴近客户?是时候升级你的客户旅程平台了
随着数字化战略推进,各大银行持续加大对线上多渠道的建设投入,客户触达也愈发移动化、智能化。与此同时,手机银行飞速发展产生并累积了大量客户行为数据,呈多样化、海量化等特点,将在用户体验、客户经营、手机银行运营…...
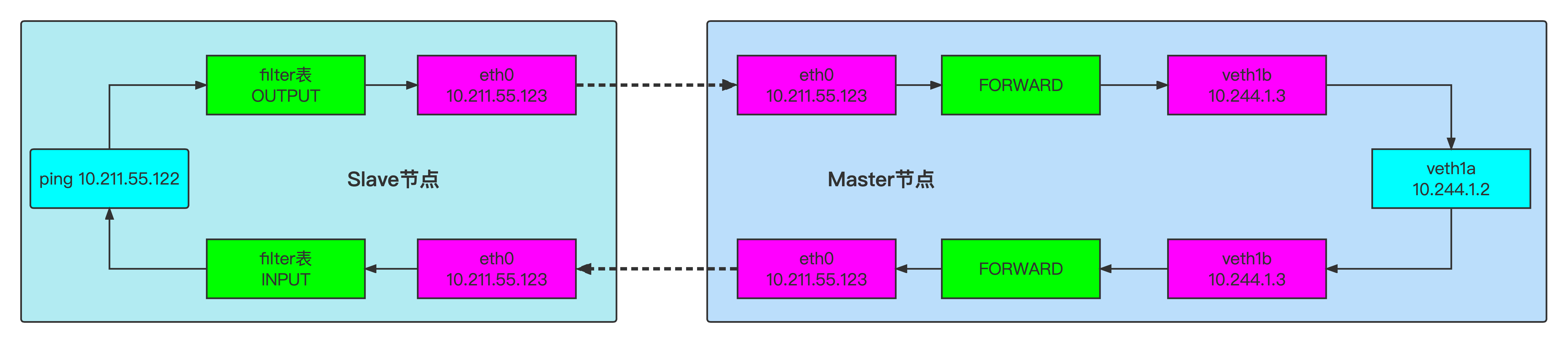
零入门kubernetes网络实战-12->基于DNAT技术使得外网可以访问本宿主机上veth-pair链接的内部网络
视频地址(稍后上传) 本篇文章测试如何让veth pair链接的内网网络可以被本局域网的其他宿主机访问到? 1、测试环境介绍 一台centos虚拟机 # 查看操作系统版本 cat /etc/centos-release # 内核版本 uname -a uname -r # 查看网卡信息 ip a s eth02、网络拓扑 3、操…...

conda环境管理命令
conda环境管理命令 1.环境检查 1)查看安装了哪些包 conda list 2)查看当前存在哪些虚拟环境 conda env list conda info -e [rootoracledb anaconda3]# conda info -e # conda environments: # base * /home/anaconda33)检查更新当前conda con…...
ubuntu clion从0开始搭建一个风格转换ONNX推理网络 opencv cuda::dnn::net
系统搭建 系统搭建 OpenCV的安装 cmake sudo apt-get install cmake其他环境以来 sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.dev libtiff5.dev libswscale-dev libjasper-dev 不安装会报这个错误 OpenCV(4.6.0) /hom…...

1.十大排序算法
1.什么是排序算法? 在梳理十大排序算法之前,虽然知道排序算法是将数字或字母按增序排列的算法,但该理解过于片面,那排序算法的权威定义是什么呢。 一个排序算法(英语:Sorting algorithm)是一种…...
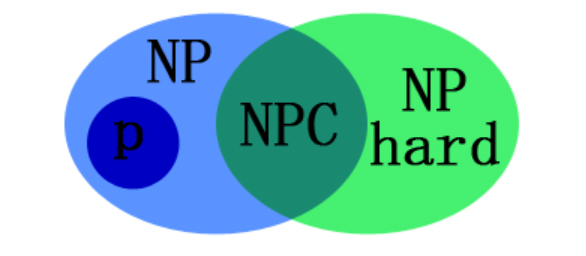
算法导论—SAT、NP、NPC、NP-Hard问题
算法导论—SAT、NP、NP-Hard、NPC问题SAT 问题基本定义问题复杂性P、NP、NP-Hard、NP-Complete(NPC)证明NP-Hard关系图NP问题的概念约化的定义NPC问题NP-Hard问题SAT 问题基本定义 SAT 问题 (Boolean satisfiability problem, 布尔可满足性问题,SAT): 给…...

linux入门---基础指令(上)
这里写目录标题前言ls指令pwd指令cd指令touch指令mkdirrmdirrmman指令cp指令mv指令前言 我们平时使用电脑主要是通过鼠标键盘以及操作系统中自带的图形来对电脑执行相应的命令,比如说我想打开D盘中的cctalk这个文件: 我就可以先用鼠标左键单击这个文件…...
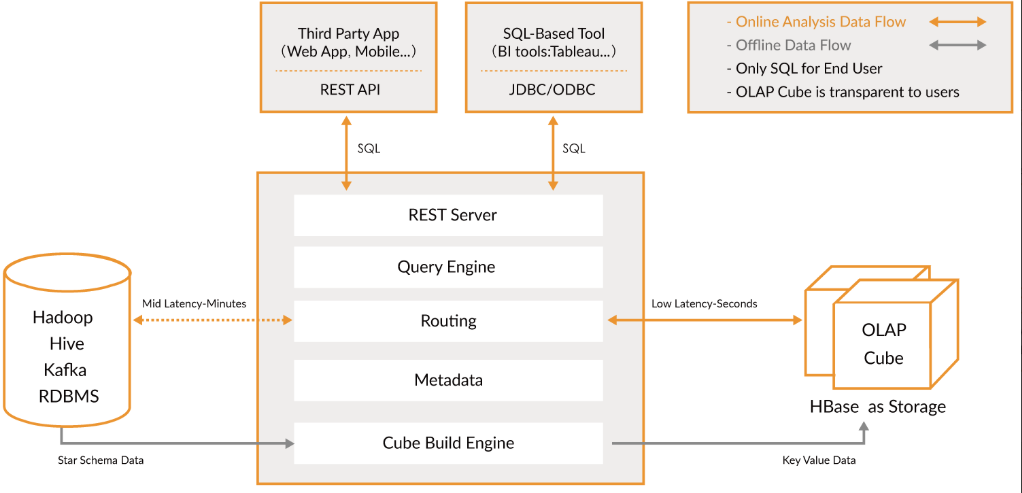
大数据Kylin(一):基础概念和Kylin简介
文章目录 基础概念和Kylin简介 一、OLTP与OLAP 1、OLTP 2、OLAP 3、OLTP与OLAP的关系 二、数据分析模型 1、星型模型 2、雪花模型 …...

推进行业生态发展完善,中国信通院第八批RPA评测工作正式启动
随着人工智能、云计算、大数据等新兴数字技术的高速发展,数字劳动力应用实践步伐加快,以数字生产力、数字创造力为基础的数字经济占比逐年上升。近年来,机器人流程自动化(Robotic Process Automation,RPA)成…...

DOM编程-获取下拉列表选中项的value
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>获取下拉列表选中项的value</title> </head> <body> <script type"text/javascript"> …...

认证服务-----技术点及亮点
大技术Nacos做注册中心把新建的微服务注册到Nacos上去两个步骤 在配置文件中配置应用名称、nacos的发现注册ip地址,端口号在启动类上用EnableDiscoveryClient注解开启注册功能使用Redis存验证码信息加入依赖配置地址和端口号即可直接注入StringRedisTemplate模板类用…...

GPU并行计算:SIMT架构与性能优化实践
1. SIMT架构的本质与硬件挑战 在GPU计算领域,单指令多线程(SIMT)执行模型是实现大规模并行的核心机制。与传统的SIMD(单指令多数据)不同,SIMT允许同一warp(通常包含32个线程)中的每个…...
)
SITS 2026闭门工作坊流出的7个LLM推理性能反模式(含3个被主流框架默认启用的致命配置)
更多请点击: https://intelliparadigm.com 第一章:AI原生性能优化:SITS 2026 LLM推理加速实战技巧 在 SITS 2026 基准测试中,LLM 推理延迟与显存带宽利用率成为关键瓶颈。AI 原生优化并非简单套用传统 CUDA kernel 调优ÿ…...

AIAgent系统崩溃前的7个征兆:基于SITS2026容错框架的实时预警与自愈方案
更多请点击: https://intelliparadigm.com 第一章:SITS2026容错框架的理论根基与演进脉络 SITS2026(Self-Integrating Tolerance System 2026)并非凭空而生,其设计深度植根于分布式系统可靠性理论、形式化验证方法论与…...
HCCS:整数优化的Transformer注意力Softmax替代方案
1. 整数优化的HCCS软最大替代方案概述在Transformer架构的多头注意力机制中,Softmax函数长期以来都是计算效率的瓶颈环节。传统Softmax需要进行指数运算和归一化操作,这在低精度整数推理场景下尤为昂贵。我们提出的HCCS(Head-Calibrated Clip…...

Rust异步运行时:从Tokio到生产环境实践
Rust异步运行时:从Tokio到生产环境实践 引言 异步编程是现代高性能后端服务的关键技术。Rust通过async/await语法和强大的运行时实现,提供了卓越的异步性能。 本文将深入探讨Rust的异步运行时,包括Tokio、async-std等运行时的原理、使用方法和…...

ImageGlass终极指南:5分钟掌握这款轻量级图片查看器的完整使用技巧
ImageGlass终极指南:5分钟掌握这款轻量级图片查看器的完整使用技巧 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass ImageGlass是一款专为Windows系统设计的轻量…...

OpenClaw用户迁移至Taotoken平台的具体配置步骤详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户迁移至Taotoken平台的具体配置步骤详解 如果你正在使用OpenClaw这类Agent框架,并希望将后端模型服务切换至…...

对比按次计费Token Plan套餐为长期项目节省可观成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按次计费Token Plan套餐为长期项目节省可观成本 在将大模型能力深度集成到产品功能或业务流程中时,持续的API调用会…...

企业内如何通过Taotoken实现API密钥的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过Taotoken实现API密钥的统一管理与审计 在将大模型能力引入企业内部的实践中,如何安全、有序地管理API密…...

网盘下载限速终结者:本地化直链解析工具的终极解决方案
网盘下载限速终结者:本地化直链解析工具的终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...