自然语言处理: 第六章Transformer- 现代大模型的基石
理论基础
Transformer(来自2017年google发表的Attention Is All You Need (arxiv.org) ),接上面一篇attention之后,transformer是基于自注意力基础上引申出来的结构,其主要解决了seq2seq的两个问题:
- 考虑了原序列和目标序列自身内部的自注意力
- 大大降低的计算成本以及复杂度,完全由全连接层替代了时序模型,使得模型可以并行处理
自从transformer 架构出现后,基于transformer的大模型就开始遍地开花,可以看到下图中超过百万级别的大模型凑够18年以后就层出不穷。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ffPqk5Dc-1691331654294)(image/transformer/1691331583320.png)]](https://img-blog.csdnimg.cn/0eaf65a4b1354a229bae10372ea963f8.png)
transformer的整体结构如下图,整体可以分成9各部分: 其中红线标记的就是transformer 独有的结构,主要是多头自注意力,位置编码。
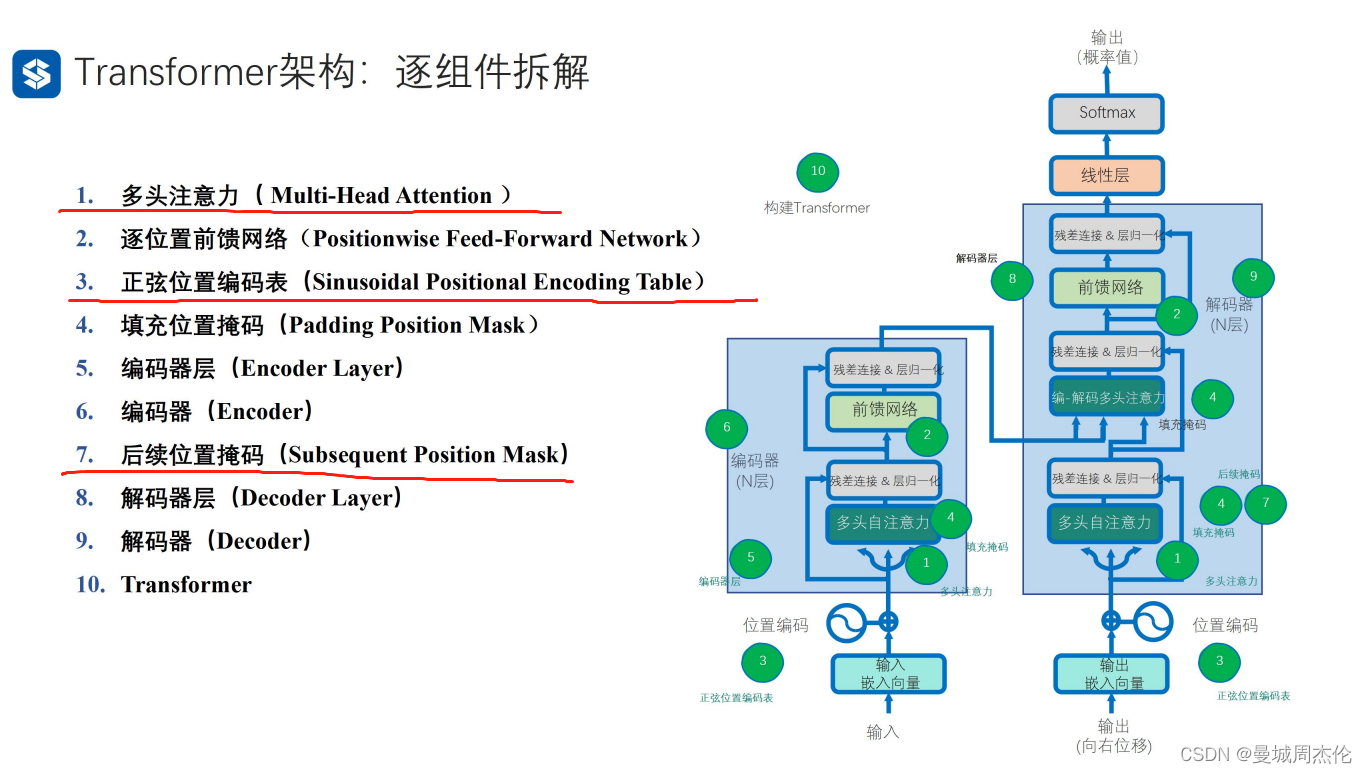
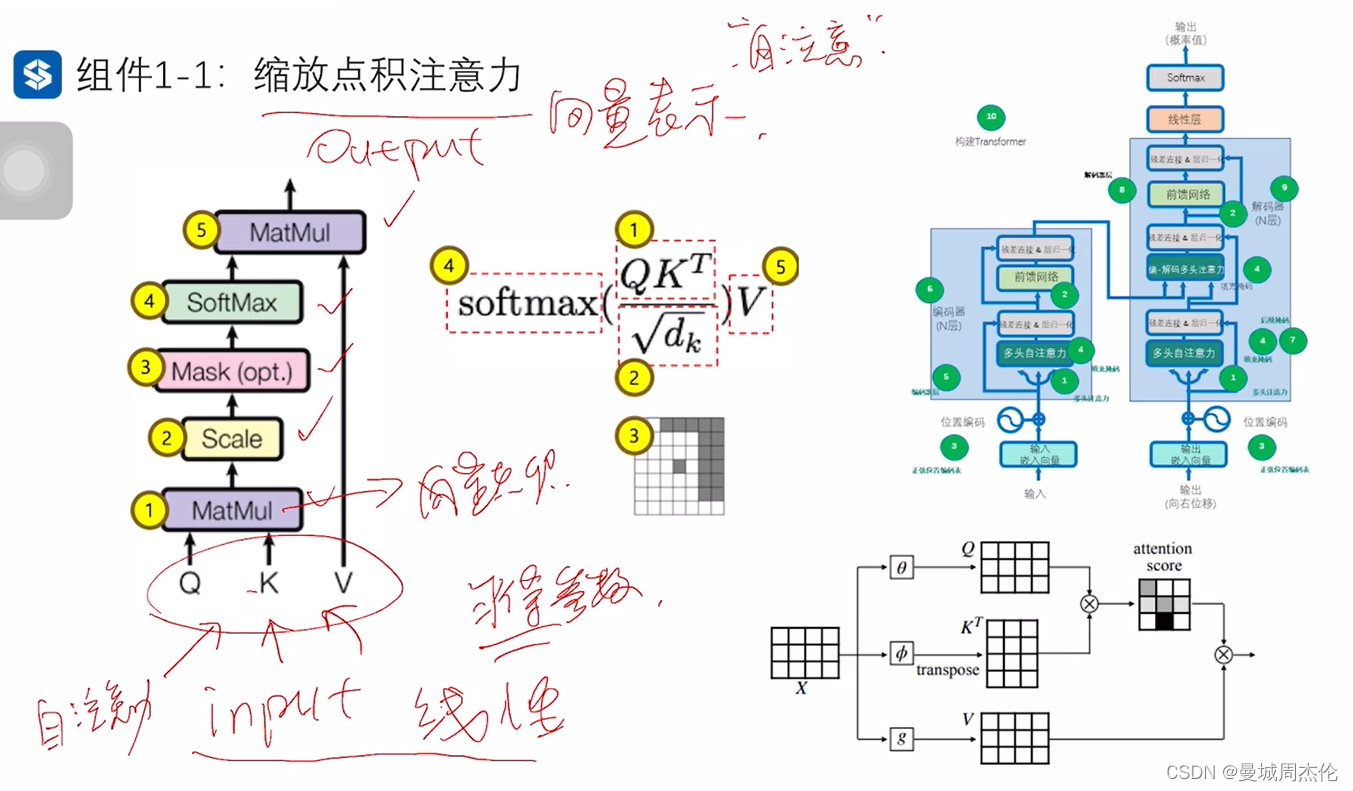
- 缩放点积注意力
自注意力简而言之就是输入向量X,通过一系列线性变换后,得到了一个同样维度的X’,但是这个X’ 不是简单的word2vec 而是一个动态的阅读过上下文的X’ ,它包含了丰富的信息。具体的变换操作可以参考上一篇博客Attention注意力机制。
- 逐位置前馈网络
对多头注意力的输出(batch , seq , embedding_size)继续多一层线性变换,并且是逐位置的进行线性变换后输出依然是(batch , seq , embedding_size)。这里的作用其实主要有两个:
- 对输入序列中的每个位置的表示进行变换,这里的逐位置意思是每个位置经过同样的权重和偏置,可以看作是1*1 卷积,后得到输出,这里是逐位置的变换,而不是整体将整个seq全部展开后进行变换是为了不引入顺序的依赖性,并且利用transformer架构中的并行处理
- 逐位置的前向传播网络还有助于增加模型的表达能力,可以让模型学到更复杂的特征表示,因为这里会涉及到一个seq , embedding_size 升维后再降维的操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xj4LfPUA-1691146825886)(image/transformer/1690945882920.png)]](https://img-blog.csdnimg.cn/14b43cc9c3d84946b077b47b4b29443c.png)
- 正弦位置编码表
因为在语言模型中,每个词的顺序是非常重要的,由于transformer 架构不像RNN这类时序模型一样,模型本身知道输入序列的顺序,,所以为了保留输入序列的顺序信息,所以引入了位置编码这个概念。
具体公式如下: 其中pos : ( 0 - seq_len ) , d :(embedding_size) , i : (0 - embedding_size ) , 其中不同的embedding上函数的相位不同
其中至于为什么用正弦函数进行编码,这个应该是一个实践出来的方程,因为他是一个周期性的函数,可以使得模型更好处理循环和重复出现的模式(比如语法结构)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zq7J4Rsv-1691146825887)(image/transformer/1690954897193.png)]](https://img-blog.csdnimg.cn/22ad2789b0dc49a7840a1d51376c7d53.png)
4. 填充位置掩码
由于深度学习里都是以batch为单位的作为训练的,所以需要把所有的句子都利用 <pad> 填充至等长,这样就可以做batch的训练。除此之外,为了将这里的 <pad >的注意力设置成0, 所以需要传入一个bool matrix 告诉网络哪些位置是填充了的,并将其注意力权重设置成无穷小。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YpLByv1S-1691146825887)(image/transformer/1690955558121.png)]](https://img-blog.csdnimg.cn/595036d7a1a94738a697d09d2596e84c.png)
5. 编码器
这里是由多个编码器层叠加形成最终的深层次的编码器,也就是前一层的输出是当前层的输入,最后一层的输出作为整个编码器的输出,具体结构如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1LTJO9fd-1691146825887)(image/transformer/1690960742565.png)]](https://img-blog.csdnimg.cn/ca06489554ce4987b72e035244717827.png)
而单层的编码器层是由自注意力 + (正弦)位置编码 + 填充掩码 + 前馈网络构成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tnVArlWH-1691146825888)(image/transformer/1690961277503.png)]](https://img-blog.csdnimg.cn/63785b05092c4ea6a02677cfa8ad3507.png)
6. 后续位置掩码
序列生成任务中,解码器的每个实践步都依赖于前面已经生成的部分序列,在解码器中,生成的自注意力由于每次生成的内容不能关注到后续位置的注意力,换句话说就是为了防止解码器在生成当前位置实过度依赖未来的信息。
举个例子比如说我的目标中英机器翻译 , 编码器的输入是I love you -> 解码器的输入应该是 <sos> 我 爱 你 <eos>所以对于编码器而言我由于我需要整个任务,所以我必须看完所有内容,所以我可以看完整个I love you 这一句话,但是对于解码器而言,我需要生成的目标是 <sos> 我 爱 你 <eos> 所以编码器只有看完了整个I love you 的输入解码器才能输出第一个字我, 而生成第二个字爱的时候,解码器只能看见 <sos> 我 这两个输入的自注意力,而不能看见爱和你,否则就类似作弊了。所以后续位置掩码就应运而生,类似一个三角矩阵。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TqvHpTDJ-1691146825888)(image/transformer/1690961679245.png)]](https://img-blog.csdnimg.cn/8d94198106f845ab8a095c55c52b3494.png)
- 解码器
解码器也是由N层解码器层深度叠加实现的,其中与编码器层结构类似,但是添加了几个特别的点是编解码多头注意力 , 这里比较好理解就是因为在解码器得到自己的自注意力后,需要与编码器的输出做注意力整合, 除此之外还有一个后续位置掩码。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SKLKBXI7-1691146825888)(image/transformer/1690962464158.png)]](https://img-blog.csdnimg.cn/c7b41d663b8d4b9c81964463876d799a.png)
代码实现
Transformer搭建
-
缩放点积注意力
# 定义缩放点积注意力类 class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): """Q 是当前要处理的上下文的信息, -> X1K 不同位置的输入与查询的相关性 -> X2V 是来自输入序列的一组表示 -> X2"""# 计算注意力分数(原始权重), score = (Q * K / 缩放因子)scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) #(batch , seq_q , seq_k)# 使用注意力掩码,将attn_mask中值为1的位置的权重替换为极小值scores.masked_fill_(attn_mask, -1e9) # 对注意力分数进行softmaxweights = nn.Softmax(dim=-1)(scores)# 计算上下文向量(也就是注意力的输出), 是上下文信息的紧凑表示context = torch.matmul(weights, V) # (batch , seq_q , embedding)return context, weights # 返回上下文向量和注意力分数 -
多头注意力类
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_embedding, d_k * n_heads) # Q的线性变换层self.W_K = nn.Linear(d_embedding, d_k * n_heads) # K的线性变换层self.W_V = nn.Linear(d_embedding, d_v * n_heads) # V的线性变换层self.linear = nn.Linear(n_heads * d_v, d_embedding)self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V, attn_mask): #-------------------------维度信息-------------------------------- # Q K V [batch_size, len_q/k/v, embedding_dim] #-------------------------维度信息-------------------------------- residual, batch_size = Q, Q.size(0) # 保留残差连接# 将输入进行线性变换和重塑,以便后续处理 , 下面的-1 代表的是qkv各自的seq_lenq_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)#-------------------------维度信息-------------------------------- # q_s k_s v_s: [batch_size, n_heads, len_q/k/v, d_q=k/v]#-------------------------维度信息-------------------------------- # 将注意力掩码复制到多头 attn_mask: [batch_size, n_heads, len_q, len_k]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)#-------------------------维度信息-------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k]#-------------------------维度信息-------------------------------- # 使用缩放点积注意力计算上下文和注意力权重# context: [batch_size, n_heads, len_q, dim_v]; weights: [batch_size, n_heads, len_q, len_k]context, weights = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)#-------------------------维度信息-------------------------------- # context [batch_size, n_heads, len_q, dim_v]# weights [batch_size, n_heads, len_q, len_k]#-------------------------维度信息-------------------------------- # 重塑上下文向量并进行线性变换,[batch_size, len_q, n_heads * dim_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) #-------------------------维度信息-------------------------------- # context [batch_size, len_q, n_heads * dim_v]#-------------------------维度信息-------------------------------- output = self.linear(context) # [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- # output [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- # 与输入(Q)进行残差链接,并进行层归一化后输出[batch_size, len_q, embedding_dim]output = self.layer_norm(output + residual)#-------------------------维度信息-------------------------------- # output [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- return output, weights # 返回层归一化的输出和注意力权重 -
逐位置前向传播网络
# 定义逐位置前向传播网络类 class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()# 定义一维卷积层1,用于将输入映射到更高维度self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=2048, kernel_size=1)# 定义一维卷积层2,用于将输入映射回原始维度self.conv2 = nn.Conv1d(in_channels=2048, out_channels=d_embedding, kernel_size=1)# 定义层归一化self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, inputs): # inputs: [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- # inputs [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- residual = inputs # 保留残差连接 [batch_size, len_q, embedding_dim]# 在卷积层1后使用ReLU激活函数 [batch_size, embedding_dim, len_q]->[batch_size, 2048, len_q]output = nn.ReLU()(self.conv1(inputs.transpose(1, 2))) #-------------------------维度信息-------------------------------- # output [batch_size, 2048, len_q]#-------------------------维度信息--------------------------------# 使用卷积层2进行降维 [batch_size, 2048, len_q]->[batch_size, embedding_dim, len_q]output = self.conv2(output).transpose(1, 2) # [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- # output [batch_size, len_q, embedding_dim]#-------------------------维度信息--------------------------------# 与输入进行残差链接,并进行层归一化,[batch_size, len_q, embedding_dim]output = self.layer_norm(output + residual) # [batch_size, len_q, embedding_dim]#-------------------------维度信息-------------------------------- # output [batch_size, len_q, embedding_dim]#-------------------------维度信息--------------------------------return output # 返回加入残差连接后层归一化的结果 -
正弦位置编码表
# 生成正弦位置编码表的函数,用于在Transformer中引入位置信息 def get_sin_enc_table(n_position, embedding_dim):#-------------------------维度信息--------------------------------# n_position: 输入序列的最大长度# embedding_dim: 词嵌入向量的维度#----------------------------------------------------------------- # 根据位置和维度信息,初始化正弦位置编码表sinusoid_table = np.zeros((n_position, embedding_dim)) # 遍历所有位置和维度,计算角度值for pos_i in range(n_position):for hid_j in range(embedding_dim):angle = pos_i / np.power(10000, 2 * (hid_j // 2) / embedding_dim)sinusoid_table[pos_i, hid_j] = angle # 计算正弦和余弦值sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i 偶数维sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 奇数维 #-------------------------维度信息--------------------------------# sinusoid_table 的维度是 [n_position, embedding_dim]#----------------------------------------------------------------- return torch.FloatTensor(sinusoid_table) # 返回正弦位置编码表 -
填充位置注意力掩码
# 生成填充注意力掩码的函数,用于在多头自注意力计算中忽略填充部分 def get_attn_pad_mask(seq_q, seq_k):#-------------------------维度信息--------------------------------# seq_q 的维度是 [batch_size, len_q]# seq_k 的维度是 [batch_size, len_k]#-----------------------------------------------------------------batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# 生成布尔类型张量[batch_size,1,len_k(=len_q)]pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) #<PAD> Token的编码值为0 # 变形为何注意力分数相同形状的张量 [batch_size,len_q,len_k]pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k)#-------------------------维度信息--------------------------------# pad_attn_mask 的维度是 [batch_size,len_q,len_k]#-----------------------------------------------------------------return pad_attn_mask # [batch_size,len_q,len_k] -
编码器(层)
# 定义编码器层类 class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() #多头自注意力层 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层def forward(self, enc_inputs, enc_self_attn_mask):#-------------------------维度信息--------------------------------# enc_inputs 的维度是 [batch_size, seq_len, embedding_dim]# enc_self_attn_mask 的维度是 [batch_size, seq_len, seq_len]#-----------------------------------------------------------------# 将相同的Q,K,V输入多头自注意力层enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs,enc_inputs, enc_self_attn_mask)# 将多头自注意力outputs输入位置前馈神经网络层enc_outputs = self.pos_ffn(enc_outputs)#-------------------------维度信息--------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同# attn_weights 的维度是 [batch_size, n_heads, seq_len, seq_len] 在注意力掩码维度上增加了头数#-----------------------------------------------------------------return enc_outputs, attn_weights # 返回编码器输出和每层编码器注意力权重# 定义编码器类 n_layers = 6 # 设置Encoder/Decoder的层数 class Encoder(nn.Module):def __init__(self, corpus):super(Encoder, self).__init__() self.src_emb = nn.Embedding(corpus.src_vocab, d_embedding) # 词嵌入层self.pos_emb = nn.Embedding.from_pretrained( \get_sin_enc_table(corpus.src_len+1, d_embedding), freeze=True) # 位置嵌入层self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))# 编码器层数def forward(self, enc_inputs): #-------------------------维度信息--------------------------------# enc_inputs 的维度是 [batch_size, source_len]#-----------------------------------------------------------------# 创建一个从1到source_len的位置索引序列pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs)#-------------------------维度信息--------------------------------# pos_indices 的维度是 [1, source_len]#----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加 [batch_size, source_len,embedding_dim]enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices)#-------------------------维度信息--------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim]#-----------------------------------------------------------------enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # 生成自注意力掩码#-------------------------维度信息--------------------------------# enc_self_attn_mask 的维度是 [batch_size, len_q, len_k] #----------------------------------------------------------------- enc_self_attn_weights = [] # 初始化 enc_self_attn_weights# 通过编码器层 [batch_size, seq_len, embedding_dim]for layer in self.layers: enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask)enc_self_attn_weights.append(enc_self_attn_weight)#-------------------------维度信息--------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同# enc_self_attn_weights 是一个列表,每个元素的维度是[batch_size, n_heads, seq_len, seq_len] #-----------------------------------------------------------------return enc_outputs, enc_self_attn_weights # 返回编码器输出和编码器注意力权重 -
后续注意力掩码
# 生成后续注意力掩码的函数,用于在多头自注意力计算中忽略未来信息 def get_attn_subsequent_mask(seq):#-------------------------维度信息--------------------------------# seq 的维度是 [batch_size, seq_len(Q)=seq_len(K)]#-----------------------------------------------------------------attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # 获取输入序列的形状 #-------------------------维度信息--------------------------------# attn_shape是一个一维张量 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------# 使用numpy创建一个上三角矩阵(triu = triangle upper)subsequent_mask = np.triu(np.ones(attn_shape), k=1)#-------------------------维度信息--------------------------------# subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------# 将numpy数组转换为PyTorch张量,并将数据类型设置为byte(布尔值)subsequent_mask = torch.from_numpy(subsequent_mask).byte()#-------------------------维度信息--------------------------------# 返回的subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------return subsequent_mask # 返回后续位置的注意力掩码 -
解码器(层)
# 定义解码器层类 class DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() # 多头自注意力层 self.dec_enc_attn = MultiHeadAttention() # 多头注意力层,连接编码器和解码器 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):#-------------------------维度信息--------------------------------# dec_inputs 的维度是 [batch_size, target_len, embedding_dim] ,右移一位# enc_outputs 的维度是 [batch_size, source_len, embedding_dim] , 编码器的输出# dec_self_attn_mask 的维度是 [batch_size, target_len, target_len] , 解码器位置掩码(正弦位置掩码 + 后续位置掩码)# dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len] , 编解码器掩码#----------------------------------------------------------------- # 将相同的Q,K,V输入多头自注意力层, 这里QKV都是dec_inputsdec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)#-------------------------维度信息--------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len]#----------------------------------------------------------------- # 将解码器输出和编码器输出输入多头注意力层 , Q:dec_inputs KV是enc_outputdec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) #-------------------------维度信息--------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len]#----------------------------------------------------------------- # 输入位置前馈神经网络层dec_outputs = self.pos_ffn(dec_outputs)#-------------------------维度信息--------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len]# dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len] #-----------------------------------------------------------------# 返回解码器层输出,每层的自注意力和解-编编码器注意力权重return dec_outputs, dec_self_attn, dec_enc_attn# 定义解码器类 n_layers = 6 # 设置Decoder的层数 class Decoder(nn.Module):def __init__(self, corpus):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(corpus.tgt_vocab, d_embedding) # 词嵌入层self.pos_emb = nn.Embedding.from_pretrained(get_sin_enc_table(corpus.tgt_len+1, d_embedding), freeze=True) # 位置嵌入层 self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 叠加多层def forward(self, dec_inputs, enc_inputs, enc_outputs): #-------------------------维度信息--------------------------------# dec_inputs 的维度是 [batch_size, target_len]# enc_inputs 的维度是 [batch_size, source_len]# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]#----------------------------------------------------------------- # 创建一个从1到source_len的位置索引序列pos_indices = torch.arange(1, dec_inputs.size(1) + 1).unsqueeze(0).to(dec_inputs)#-------------------------维度信息--------------------------------# pos_indices 的维度是 [1, target_len]#----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加 , 作为解码器层首个输入向量dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos_indices) #-------------------------维度信息--------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]#----------------------------------------------------------------- # 生成解码器自注意力掩码和解码器-编码器注意力掩码dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # 填充位掩码dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) # 后续位掩码dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask.to(device) \+ dec_self_attn_subsequent_mask.to(device)), 0) # 只要是填充位置或者后续位置是1的话就返回dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # 解码器-编码器掩码#-------------------------维度信息-------------------------------- # dec_self_attn_pad_mask 的维度是 [batch_size, target_len, target_len]# dec_self_attn_subsequent_mask 的维度是 [batch_size, target_len, target_len]# dec_self_attn_mask 的维度是 [batch_size, target_len, target_len]# dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len]#----------------------------------------------------------------- dec_self_attns, dec_enc_attns = [], [] # 初始化 dec_self_attns, dec_enc_attns# 通过解码器层 [batch_size, seq_len, embedding_dim]for layer in self.layers:dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)#-------------------------维度信息--------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, target_len]# dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, source_len]#----------------------------------------------------------------- # 返回解码器输出,解码器自注意力和解-编编码器注意力权重 return dec_outputs, dec_self_attns, dec_enc_attns -
Transformer类
# 定义Transformer模型
class Transformer(nn.Module):def __init__(self, corpus):super(Transformer, self).__init__() self.encoder = Encoder(corpus) # 初始化编码器实例 self.decoder = Decoder(corpus) # 初始化解码器实例# 定义线性投影层,将解码器输出转换为目标词汇表大小的概率分布self.projection = nn.Linear(d_embedding, corpus.tgt_vocab, bias=False)def forward(self, enc_inputs, dec_inputs):#-------------------------维度信息--------------------------------# enc_inputs 的维度是 [batch_size, source_seq_len]# dec_inputs 的维度是 [batch_size, target_seq_len]#----------------------------------------------------------------- # 将输入传递给编码器,并获取编码器输出和自注意力权重 enc_outputs, enc_self_attns = self.encoder(enc_inputs)#-------------------------维度信息--------------------------------# enc_outputs 的维度是 [batch_size, source_len, embedding_dim]# enc_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, src_seq_len, src_seq_len] #----------------------------------------------------------------- # 将编码器输出、解码器输入和编码器输入传递给解码器# 获取解码器输出、解码器自注意力权重和编码器-解码器注意力权重 dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)#-------------------------维度信息--------------------------------# dec_outputs 的维度是 [batch_size, target_len, embedding_dim]# dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len]# dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len] #----------------------------------------------------------------- # 将解码器输出传递给投影层,生成目标词汇表大小的概率分布dec_logits = self.projection(dec_outputs) #-------------------------维度信息--------------------------------# dec_logits 的维度是 [batch_size, tgt_seq_len, tgt_vocab_size]#-----------------------------------------------------------------# 返回逻辑值(原始预测结果),编码器自注意力权重,解码器自注意力权重,解-编码器注意力权重return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
数据集的读取
由于pytorch中的dataloader是按照batch读取数据,其中范式代码如下,其中√表示的是比较常需要设置的参数:
class torch.utils.data.DataLoader(dataset, # 继承torch.utils.data.Dataset,后面会细讲 √ batch_size = 1, # batch_size √ shuffle = False, # 是否每次迭代都需要打乱数据集 √ collate_fn = <function default_collate>, # 用于自定义样本处理的函数,后面会细讲 √ sampler = None, # 自定义采样规则batch_sampler = None, # num_workers = 0, # 使用多少个子进程来导入数据,默认是0意思是用主进程导入数据,这个数字必须要大于0 pin_memory = False, # 内存寄存,默认为False。在数据返回前,是否将数据复制到CUDA内存中。drop_last = False, # 丢弃最后数据,默认为False。设置了 batch_size 的数目后,最后一批数据未必是设置的数目,即batch_len / batch_size 不是整除的情况。这时你是否需要丢弃这批数据。timeout = 0, # 超时,默认为0。是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。 所以,数值必须大于等于0。worker_init_fn=None # 子进程导入模式,默认为Noun。在数据导入前和步长结束后,根据工作子进程的ID逐个按顺序导入数据)
上面可以看到dataset是自定义数据集的类,其继承于torch.utils.data.Dataset,主要用于读取单个数据,其必须要定义的三个函数__init__ , getitem__ , len__().例子如下:
class TranslationDataset(Dataset):def __init__(self, sentences, word2idx_cn, word2idx_en): # 设置参数self.sentences = sentencesself.word2idx_cn = word2idx_cnself.word2idx_en = word2idx_endef __len__(self): # 返回数据的长度return len(self.sentences)def __getitem__(self, index): # 输入id , 返回单个数据的 feature 以及 labelsentence_cn = [self.word2idx_cn[word] for word in self.sentences[index][0].split()]sentence_en = [self.word2idx_en[word] for word in self.sentences[index][1].split()]sentence_en_in = sentence_en[:-1] # remove <eos> , decorder inputsentence_en_out = sentence_en[1:] # remove <sos> , decorder outputreturn torch.tensor(sentence_cn), torch.tensor(sentence_en_in), torch.tensor(sentence_en_out)
可以看到如果初始化的dataset的每个单独的数据的长度并不一致
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-flpKVgHO-1691146825889)(image/transformer/1691131287251.png)]](https://img-blog.csdnimg.cn/4d97adcd0dc34470a5e7b2afdfd5de57.png)
其次是collate_fn, 我们都知道为了使得dataloader 按照batch读取数据时需要取出同等大小的batch 的数据,所以这里要求所有特征向量需要是等大小的,但是我们都知道nlp任务里大部分文本数据都不可能保证对齐,所以我们需要补pad,这里就需要利用这个colldate_fn函数/对象了。 下其中collate_fn 传入的参数是batch的数据 也就是batch of dataset[id] 针对于上面的TranslationDataset的形状就是[batch , 3] ,
def collate_fn(batch):batch.sort(key=lambda x: len(x[0]), reverse=True)sentence_cn, sentence_en_in, sentence_en_out = zip(*batch)sentence_cn = nn.utils.rnn.pad_sequence(sentence_cn, padding_value=corpus_loader.word2idx_cn['<pad>'],batch_first=True)sentence_en_in = nn.utils.rnn.pad_sequence(sentence_en_in, padding_value=corpus_loader.word2idx_en['<pad>'],batch_first=True)sentence_en_out = nn.utils.rnn.pad_sequence(sentence_en_out, padding_value=corpus_loader.word2idx_en['<pad>'],batch_first=True)return sentence_cn, sentence_en_in, sentence_en_out
其次是利用了nn.utils.rnn.pad_sequence 进行padding, 其中有三个参数, 整个函数最后返回[batch , M] , M是batch中最大的长度:
- target : list / 矩阵 , shape = [batch , N ] N 可以长度不一
- batch_first : 默认把batch放在第一维度
- padding_value : 填充的值,也就是padding的index
targets = pad_sequence(targets , batch_first=True , padding_value=self.pad_idx)
其次如果需要对collate_fn输入参数,一般有两种方法:
-
使用lambda函数
info = args.info # info是已经定义过的 loader = Dataloader(collate_fn=lambda x: collate_fn(x, info)) -
创建可以调用的类
class collater():def __init__(self, *params):self. params = paramsdef __call__(self, data):'''在这里重写collate_fn函数'''loader = Dataloader(collate_fn = collater(*params))
结果
最后利用nltk的API测试了下整个网络在整个训练集上的BLUE分数,这里其实是要分出一个验证集出来是比较好的,但是实践比较有限就不做了,可以看到整个BLUE的分数还不错有0.68左右。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zzkl7dkb-1691146825889)(image/transformer/1691146495846.png)]](https://img-blog.csdnimg.cn/cab614a1bbfb4225afd5129bb8fe314d.png)
相关文章:
自然语言处理: 第六章Transformer- 现代大模型的基石
理论基础 Transformer(来自2017年google发表的Attention Is All You Need (arxiv.org) ),接上面一篇attention之后,transformer是基于自注意力基础上引申出来的结构,其主要解决了seq2seq的两个问题: 考虑了原序列和目…...
)
01-Hadoop集群部署(普通用户)
Hadoop集群部署(普通用户) 环境准备 1)准备3台客户机(关闭防火墙、静态IP、主机名称) 如果这一步已经配置过了,可以忽略 # 1 关闭防火墙 systemctl stop firewalld.service # 关闭当前防火墙 systemctl…...

DC电源模块关于的电路布局设计
BOSHIDA DC电源模块关于的电路布局设计 DC电源模块是现代电子设备中常用的电源模块之一,其功能是将市电或其他输入电源转换成定电压、定电流的直流电源输出,以满足电子设备的供电需求。电路布局的设计是DC电源模块的重要组成部分,它直接影响…...
)
MATLAB实现免疫优化算法(附上多个完整仿真源码)
免疫优化算法是一种基于免疫学原理的优化算法。该算法的基本思想是通过模拟人类免疫系统的功能,来寻找最优解。 MATLAB是一种专门用于数学计算和数据处理的软件工具,它具有强大的数学计算和数据分析能力,可以方便地实现各种优化算法。 本文…...
登录界面中图片验证码的生成和校验
一、用pillpw生成图片验证码 1、安装pillow pip install pip install pillow2、下载字体 比如:Monaco.ttf 3、实现生成验证码的方法 该方法返回一个img ,可以把这个img图片保存到内存中,也可以以文件形式保存到磁盘,还返回了验证码的文字…...

go的make使用
在 Go 语言中,make 是一个用于创建切片、映射(map)和通道(channel)的内建函数。它提供了一种初始化和分配内存的方式,用于创建具有特定长度和容量的数据结构。下面将详细介绍 make 函数的使用方法和各种情况…...
竞赛项目 深度学习实现语义分割算法系统 - 机器视觉
文章目录 1 前言2 概念介绍2.1 什么是图像语义分割 3 条件随机场的深度学习模型3\. 1 多尺度特征融合 4 语义分割开发过程4.1 建立4.2 下载CamVid数据集4.3 加载CamVid图像4.4 加载CamVid像素标签图像 5 PyTorch 实现语义分割5.1 数据集准备5.2 训练基准模型5.3 损失函数5.4 归…...
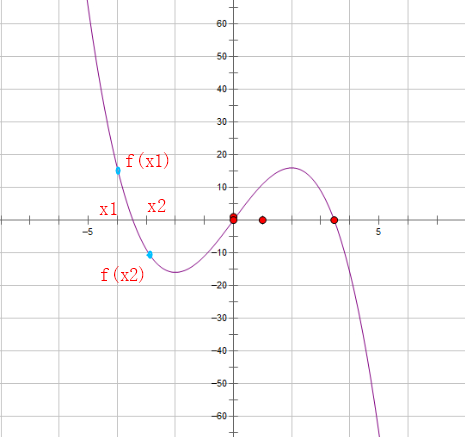
一元三次方程求解
一元三次方程求解 题目描述提示输入输出格式输入格式输出格式 输入输出样例输入样例输出样例 算法分析A C 代码 题目描述 有形如: a x 3 b x 2 c x d 0 ax^3bx^2c^xd0 ax3bx2cxd0一元三次方程。给出该方程中各项的系数 ( a a a, b b b,…...

基于java在线音乐网站设计与实现
在线音乐网站的设计与实现 摘 要 随着互联网趋势的到来,各行各业都在考虑利用互联网将自己推广出去,最好方式就是建立自己的互联网系统,并对其进行维护和管理。在现实运用中,应用软件的工作规则和开发步骤,采用SSM框架…...

Python爬虫如何更换ip防封
作为一名长期扎根在爬虫行业动态ip解决方案的技术员,我发现很多人常常在使用Python爬虫时遇到一个困扰,那就是如何更换IP地址。别担心,今天我就来教你如何在Python爬虫中更换IP,让你的爬虫不再受到IP封锁的困扰。废话不多说&#…...

涛思数据联合长虹佳华、阿里云 Marketplace 正式发布 TDengine Cloud
近日,涛思数据联合长虹佳华,正式在阿里云 Marketplace 发布全托管的时序数据云平台 TDengine Cloud,为用户提供更加丰富的订购渠道。目前用户可通过阿里云 Marketplace 轻松实现 TDengine Cloud 的订阅与部署,以最低的成本搭建最高…...
特殊符号的制作 台风 示例 使用第三方工具 Photoshop 地理信息系统空间分析实验教程 第三版
特殊符号的制作 首先这是一个含有字符的,使用arcgis自带的符号编辑器制作比较困难。所以我们准备采用Adobe Photoshop 来进行制作符号,然后直接导入符号的图片文件作为符号 我们打开ps,根据上面的图片的像素长宽比,设定合适的高度…...
IoTDB1.X windows运行失败问题的处理
在windows运行 IoTDB1.x时 会出现如图所示的问题 为什么会出现这样的问题?java没有安装还是未调用成功,我是JAVA8~11~17各种更换都未能解决问题,最后对其bat文件进行查看,发现在conf\datanode-env.bat、conf\confignode-env.bat这…...

pdf转图片【java版实现】
一、引入依赖 引入需要导入到项目中的依赖,如下所示: <!-- pdf转图片 --><dependency><groupId>net.sf.cssbox</groupId><artifactId>pdf2dom</artifactId><version>1.7</version></dependency>…...

python3.6 安装pillow失败
问题描述 python3 安装 pillow 失败 错误原因 python3.6 不支持 pillow9.0 以上的版本 解决方法: 指定版本安装 e.g., pillow8.0 pip3 install pillow8.0...

巨人互动|Meta海外户Meta的业务工具转化API
Meta的业务工具转化API是一项创新技术,它可以帮助企业实现更高效的业务工具转化和集成。通过这个API,企业可以将不同的业务工具整合到一个统一的平台上,提高工作效率和协作能力。本文小编将介绍Meta的业务工具转化API的功能和优势。 巨人互动…...

【JAVA】包、权限修饰符、final关键字、常量、枚举、抽象类、接口
1 包 包是用来分门别类的管理各种不同类的,类似于文件夹、建包利于程序的管理和维护。建包语句必须在第一行建包的语法格式:package 公司域名倒写.项目名称。包名建议全部小写相同包下的类可以直接访问,不同包下的类必须导包,才可…...
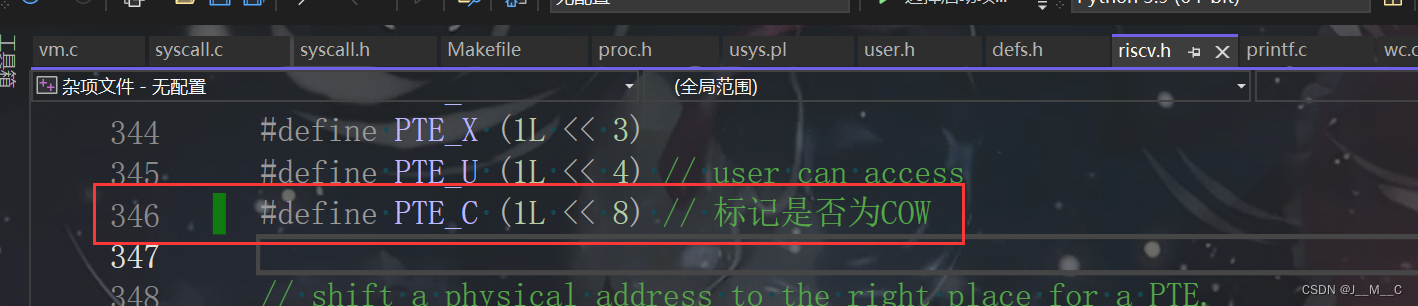
6.s081/6.1810(Fall 2022)Lab5: Copy-on-Write Fork for xv6
前言 本来往年这里还有个Lazy Allocation的,今年不知道为啥直接给跳过去了。. 其他篇章 环境搭建 Lab1: Utilities Lab2: System calls Lab3: Page tables Lab4: Traps Lab5: Copy-on-Write Fork for xv6 参考链接 官网链接 xv6手册链接,这个挺重要…...
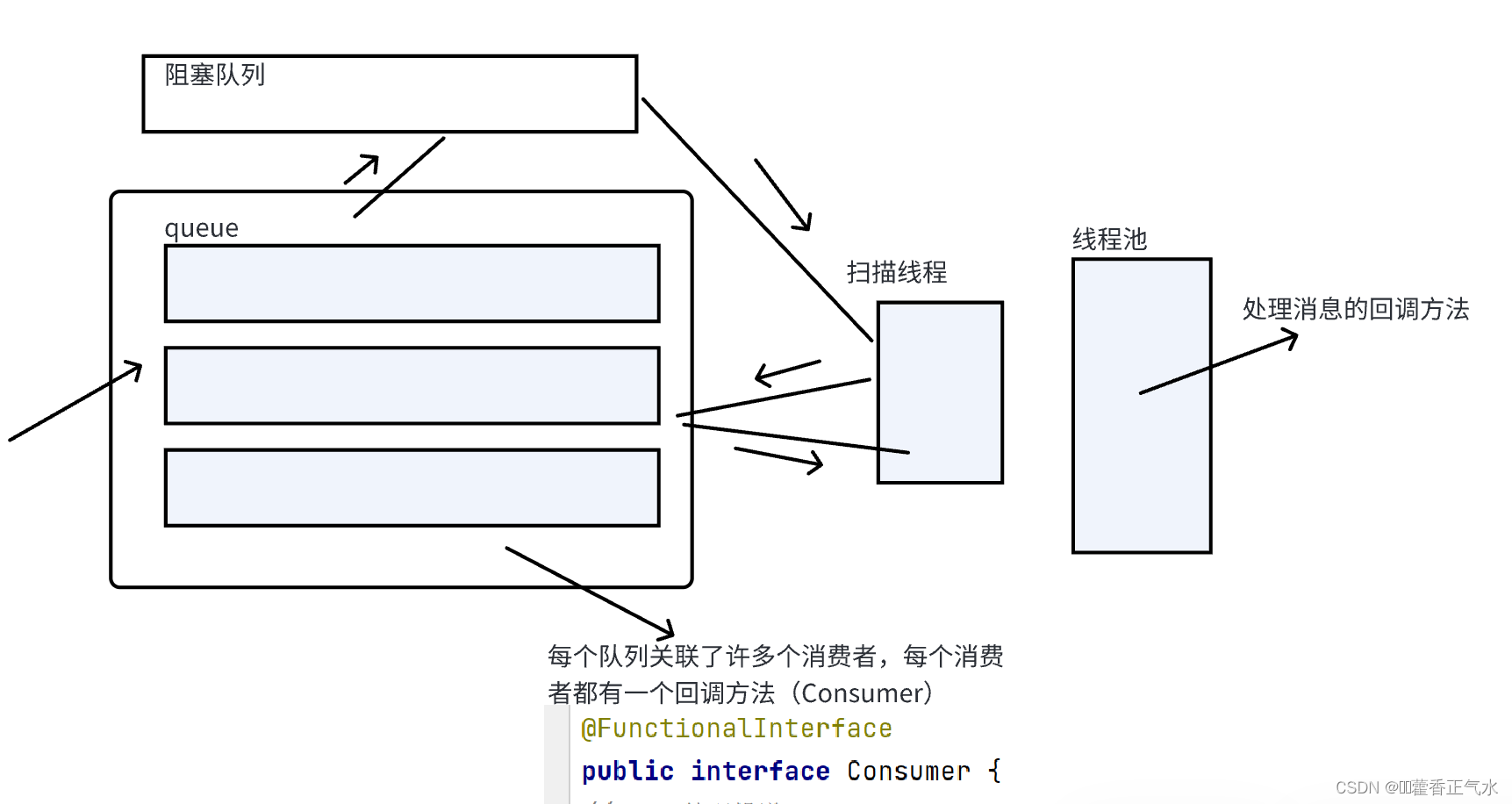
项目实战 — 消息队列(7){虚拟主机设计(2)}
目录 一、消费消息的规则 二、消费消息的具体实现方法 🍅 1、编写消费者类(ConsumerEnv) 🍅 2、编写Consumer函数式接口(回调函数) 🍅 3、编写ConsumeerManager类 🎄定义成员变…...
手把手教你快速实现内网穿透
快速内网穿透教程 文章目录 快速内网穿透教程前言*cpolar内网穿透使用教程*1. 安装cpolar内网穿透工具1.1 Windows系统1.2 Linux系统1.2.1 安装1.2.2 向系统添加服务1.2.3 启动服务1.2.4 查看服务状态 2. 创建隧道映射内网端口3. 获取公网地址 前言 要想实现在公网访问到本地的…...
)
从仿真到芯片:手把手将Simulink定点化FOC代码部署到STM32F4/F1(含数据溢出调试实录)
从仿真到芯片:手把手将Simulink定点化FOC代码部署到STM32F4/F1(含数据溢出调试实录) 在电机控制领域,Simulink模型仿真与真实硬件部署之间往往存在一道难以逾越的鸿沟。许多工程师能够熟练搭建浮点算法模型并获得理想的仿真结果&a…...

Wan2.1-umt5技术解析:深入理解其卷积神经网络优化策略
Wan2.1-umt5技术解析:深入理解其卷积神经网络优化策略 最近在社区里看到不少关于Wan2.1-umt5模型的讨论,大家普遍觉得它在处理文本和跨模态任务时,速度和效果都挺不错。作为一个长期关注模型底层优化的工程师,我很好奇它到底做了…...
)
告别官方地图限制:用Leaflet+Renderjs在uni-app里玩转天地图(安卓/H5实战)
突破uni-app地图限制:LeafletRenderjs集成天地图的跨端实践 在移动应用开发领域,地图功能已成为许多应用的核心组件。uni-app作为跨平台开发框架,虽然提供了官方地图组件,但其仅支持有限的几家主流地图服务商。当项目需要集成天地…...

AI原生应用框架lobu:快速构建与部署大语言模型应用
1. 项目概述:一个面向开发者的AI原生应用框架最近在开源社区里,一个名为lobu-ai/lobu的项目引起了我的注意。乍一看这个名字,你可能会觉得有点陌生,甚至有点“怪”。但如果你深入了解一下它的定位和设计理念,就会发现这…...

Cat-Catch终极使用手册:5步快速掌握网页资源嗅探
Cat-Catch终极使用手册:5步快速掌握网页资源嗅探 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常在网上遇到喜欢的视频、音频…...

D2RML完整指南:5分钟掌握暗黑2重制版多开技巧
D2RML完整指南:5分钟掌握暗黑2重制版多开技巧 【免费下载链接】D2RML Diablo 2 Resurrected Multilauncher 项目地址: https://gitcode.com/gh_mirrors/d2/D2RML 想要在《暗黑破坏神2:重制版》中同时操作多个角色却苦于繁琐的账户切换?…...

LibreHardwareMonitor:终极硬件监控解决方案,让你的电脑健康一目了然
LibreHardwareMonitor:终极硬件监控解决方案,让你的电脑健康一目了然 【免费下载链接】LibreHardwareMonitor Libre Hardware Monitor is free software that can monitor the temperature sensors, fan speeds, voltages, load and clock speeds of you…...

Voxtral-4B-TTS-2603效果集:9种语言同一旅游文案语音合成效果横向展示
Voxtral-4B-TTS-2603效果集:9种语言同一旅游文案语音合成效果横向展示 1. 多语言语音合成效果展示 Voxtral-4B-TTS-2603作为一款支持多语言的语音合成模型,其最吸引人的特点之一就是能够在不同语言间保持一致的音质和韵律表现。为了直观展示这一能力&a…...
与电平标准实战避坑指南)
别再乱配了!Spartan-6 FPGA的IOB供电(VCCAUX/VCCO)与电平标准实战避坑指南
Spartan-6 FPGA I/O供电设计实战:避开那些年我们踩过的坑 在FPGA设计领域,Spartan-6系列因其出色的性价比和灵活性,至今仍是许多工业控制、通信设备和嵌入式系统的首选。然而,当我们从实验室原型走向量产时,往往会发现…...

如何修复戴森V6/V7吸尘器电池锁死问题:开源固件终极解决方案
如何修复戴森V6/V7吸尘器电池锁死问题:开源固件终极解决方案 【免费下载链接】FU-Dyson-BMS (Unofficial) Firmware Upgrade for Dyson V6/V7 Vacuum Battery Management System 项目地址: https://gitcode.com/gh_mirrors/fu/FU-Dyson-BMS 您的戴森吸尘器突…...