使用Spark ALS模型 + Faiss向量检索实现用户扩量实例
1、通过ALS模型实现用户/商品Embedding的效果,获得其向量表示
准备训练数据, M = (U , I, R) 即 用户集U、商品集I、及评分数据R。
(1)商品集I的选择:可以根据业务目标确定商品候选集,比如TopK热度召回、或者流行度不高但在业务用户中区分度比较高的商品集等。个人建议量级控制在5W内,1W-2W左右比较合适,太大的话,用户产生行为的商品比较少,评分数据会非常的稀疏。
(2)用户集U的选择: 最好是粗召回策略确定的用户范围,因为ALS模型会生成所有U用户的特征向量表示,对于没有见过的用户u,没有其向量表示,其推荐也是冷启动策略。这里可以根据业务需要限制一个大范围,比如4000W-5000W的或大几百万的用户(从计算效率和内存使用上,个人建议500W内比较合适)。比如用户U定义为某些类目下购买人群、或者近期活跃人群等符合业务人群目标的潜在客户群。模型训练完之后,也是在这个用户集U中筛选出TopK相似的用户做推荐或扩量。
(3)评分数据R的选择:我们能采集到的大多是隐式反馈的数据,比如购买行为、浏览行为、收藏行为等。确定了U、I,确定了评分指标类型,就可以统计一段时间内,U对I的反馈数据R。数据量级大约在7亿条-10亿条,在模型参数设置合理的情况下,大约20-30分钟就可以训练完。
from pyspark.ml.recommendation import ALS
from pyspark.sql.functions import expr, isnull""" ALS模型参数解读,和大小设置建议:
:paramrank=10, maxIter=10, regParam=0.1, numUserBlocks=10,numItemBlocks=10, implicitPrefs=False, alpha=1.0, userCol="user", itemCol="item",seed=None, ratingCol="rating", nonnegative=False, checkpointInterval=10,intermediateStorageLevel="MEMORY_AND_DISK",finalStorageLevel="MEMORY_AND_DISK", coldStartStrategy="nan", blockSize=4096NumBlocks分块数:分块是为了并行计算,默认为10。可以根据数据量级适当放大,比如20。 可以对 numUserBlocks\numItemBlocks 单独进行配置并行度 ,也可以通过setNumBlocks(30)一起设置。正则化参数:默认为1。
秩rank:模型中隐藏因子的个数,默认是10。即特征向量的维度。
implicitPrefs:显式偏好信息-false,隐式偏好信息-true,默认false(显示) 。 电商场景中 购买、点击、分享,都是隐式反馈。
alpha:隐式反馈时的置信度参数,默认是1.0。只用于隐式的偏好数据。
setMaxIter(10):最大迭代次数,设置太大发生java.lang.StackOverflowError。建议范围 10 ~20。 超过20,比较容易失败。
coldStartStrategy: 预测时冷启动策略。默认是nan, 可以选择 drop。
"""ratings = spark.sql("""selectuser_acct, user_id, main_sku_id, item_id, ratingfrom dmb_dev.dmb_dev_als_model_rating_matrix""").repartition(3600)
train_data, test_data = ratings.randomSplit([0.9, 0.1], seed=4226)
train_data.cache()
als = ALS() \.setImplicitPrefs(True) \.setAlpha(0.7) \.setMaxIter(20) \.setRank(10) \.setRegParam(0.01) \.setNumBlocks(30) \.setUserCol("user_id") \.setItemCol("item_id") \.setRatingCol("rating") \.setColdStartStrategy("drop")
print(als.explainParams())als_model = als.fit(train_data)
als_model.write().overwrite().save(model_save_path)# 训练集合所有用户U的向量表示
candidate_user_factors = als_model.userFactors.withColumnRenamed("id", "user_id")\.join(train_data.select("user_acct", "user_id").dropDuplicates(), ["user_id"])\.withColumn("bin_group", expr("round(rand(),1)"))
candidate_user_factors.cache()
candidate_user_factors.write.format("orc").mode("overwrite")\.saveAsTable("dev.dev_als_model_all_trained_users_factor_result")
train_data.unpersist()# query用户的向量表示
target_user_factors = spark.sql("""selectuser_acct, user_idfrom dev.dev_wdy_als_seed_users_tablegroup by user_acct, user_id""").join(candidate_user_factors, ["user_acct", "user_id"])
target_user_factors.cache()
target_user_factors.write.format("orc").mode("overwrite")\.saveAsTable("dev.dev_als_model_seed_users_factor")# 候选用户向量表示
search_user_factors = candidate_user_factors.join(target_user_factors,candidate_user_factors["user_acct"] == target_user_factors["user_acct"],"left_outer")\.where(isnull(target_user_factors["user_acct"]))\.select(candidate_user_factors["user_acct"], candidate_user_factors["user_id"],candidate_user_factors["features"], candidate_user_factors["bin_group"])
search_user_factors.write.format("orc").mode("overwrite")\.saveAsTable("dev.dev_als_model_candidate_users_factor")
candidate_user_factors.unpersist()
target_user_factors.unpersist()
2、通过Faiss快速实现向量TopK相似检索
如果没有装faiss,可以选择安装CPU/GPU版本, pip install faiss-cpu
关于faiss的使用说明,可以参考向量数据库入坑指南:聊聊来自元宇宙大厂 Meta 的相似度检索技术 Faiss - 知乎
faiss来自facebook 开源 Meta Research · GitHub的github库为:GitHub - facebookresearch/faiss: A library for efficient similarity search and clustering of dense vectors.
根据业务需求的查询速度、精准度要求来选择合适的Faiss TopK向量查询方法。
# 判断 npy文件是否存在,不存在则执行以下操作;否则跳过此步骤,直接读取文件。
user_embedding = spark.sql("""select features[0],features[1],features[2],features[3],features[4],features[5],features[6],features[7],features[8],features[9] from dev.dev_als_model_candidate_users_factorwhere bin_group=0.1""").toPandas()# 量级500W内执行顺利,再大的量级容易内存溢出失败。
np.save("user_embedding_01.npy", np.array(user_embedding, order='C'))user_embedding = np.load("user_embedding_01.npy")
print("user_embedding data sample:", user_embedding[:3])
print("user embedding shape", user_embedding.shape)
dimension = user_embedding.shape[1]
nums_user = user_embedding.shape[0]faiss.normalize_L2(user_embedding)
index = faiss.IndexFlatIP(dimension)
index.add(user_embedding)
print("index is trained:", index.is_trained)
print("index n total:", index.ntotal)# 判断文件是否存在,如果存在则直接读取,否则先下载保存到本地。
## 这里k=30 或更大时,查询易失败。 k=20, 查询耗时久,但会成功,大约3小时。 k=10时,
k = 5
query1 = spark.sql("""select features[0],features[1],features[2],features[3],features[4],features[5],features[6],features[7],features[8],features[9] from dev.dev_als_model_seed_users_factor""").toPandas()
np.save("query.npy", np.array(query1, order='C'))
query = np.load("query.npy")
print("query shape:", query.shape)# 查询
t0 = time.time()
Deg, Ind = index.search(query, k)
t1 = time.time()
print("平均耗时 %7.3f min" % ((t1 - t0)/60))# 保存索引
faiss.write_index(index, "faiss_01.index")
np.save("Ind_01.npy", Ind)
np.save("Deg_01.npy", Deg)res = []
for i in range(query.shape[0]):q_vector = query[i]r_list = Ind[i]for j in range(len(r_list)):r_vector = user_embedding[r_list][j]sim = Deg[i][j]res.append(([float(v) for v in r_vector], float(sim)))res = spark.createDataFrame(res, ["recommend_vector", "similarity"]).repartition(10)
res.cache()res.write.format("orc").mode("overwrite")\.saveAsTable("dev.dev_als_model_recommend_vector_result")user_embedding = spark.sql("""select *from dev.dev_als_model_candidate_users_factorwhere bin_group=0.1""")
res.join(user_embedding, res["recommend_vector"] == user_embedding["features"])\.write.format("orc").mode("overwrite")\.saveAsTable("dev.dev_als_model_recommend_user_pin_result")
查询速度实验对比数据:
| IndexIVFFlat | IndexFlatIP | IndexFlatIP |
| user embedding shape (4474857, 10) | user embedding shape (4474857, 10) | user embedding shape (4474857, 10) |
| query shape: (78525, 10) | query shape: (78525, 10) | query shape: (34525, 10) |
| k=5 | k=5 | k=10 |
| 平均耗时 10.522 min | 平均耗时 > 6h | 平均耗时 3h-4h |
业务中查询的候选集可能有4000W-5000W,而且对于查询响应时间有要求,使用IndexIVFFlat更符合上线需求。
nlist = 50
quantizer = faiss.IndexFlatL2(dimension)
index = faiss.IndexIVFFlat(quantizer, dimension, nlist, faiss.METRIC_L2)
assert not index.is_trained
index.train(user_embedding)
assert index.is_trained
index.add(user_embedding) # 添加索引可能会有一点慢
index.nprobe = 10 # 默认 nprobe 是1 ,这里设置为103、通过I2I2U 或者 I2U2U来获得用户扩量结果
上述实现的是U2U的扩量方法,使用的是User-Factor向量表示。第一个U来自于业务营销目标I下的历史已购人群。即这是一个I2U2U的扩量方法。 I (目标商品)---> U(历史购买) ---> U(TopK相似) 。
当然也可以通过使用Item-Factor向量表示,实现 I2I2U,即 I (目标商品)---> I(TopK相似) ---> U(历史购买) ,这样来做商品相似召回,实现用户的扩量。
基于实验效果,或历史数据的验证来选择使用哪种方法投产。
4、算法设计框架总结
可以看到,这个算法设计框架其实是 Embedding + Faiss ,即用户/商品的向量表示 + Faiss快速向量相似检索 的设计模式。
那么第一部分的ALS模型当然可以替换成任何一种可以效果更好的Embedding算法模型,比如BERT 、Transformer等深度学习模型。而第二部分Faiss的查询可以保持不动,只要替换查询数据源就可以了。当然也可以将其优化成GPU的,或更快速的查询方式,以满足线上业务的需求。
但整体的算法设计框架是不变的,Embedding向量化 + Faiss相似检索。
Done.
相关文章:

使用Spark ALS模型 + Faiss向量检索实现用户扩量实例
1、通过ALS模型实现用户/商品Embedding的效果,获得其向量表示 准备训练数据, M (U , I, R) 即 用户集U、商品集I、及评分数据R。 (1)商品集I的选择:可以根据业务目标确定商品候选集,比如TopK热度召回、或…...

Jmeter入门之digest函数 jmeter字符串连接与登录串加密应用
登录请求中加密串是由多个子串连接,再加密之后传输。 参数连接:${var1}${var2}${var3} 加密函数:__digest (函数助手里如果没有该函数,请下载最新版本的jmeter5.0) 函数助手:Options > …...

uni-app实现图片上传功能
效果 代码 <uni-forms-item name"ViolationImg" label"三违照片 :"><uni-file-picker ref"image" limit"1" title"" fileMediatype"image" :listStyles"listStyles" :value"filePathsL…...
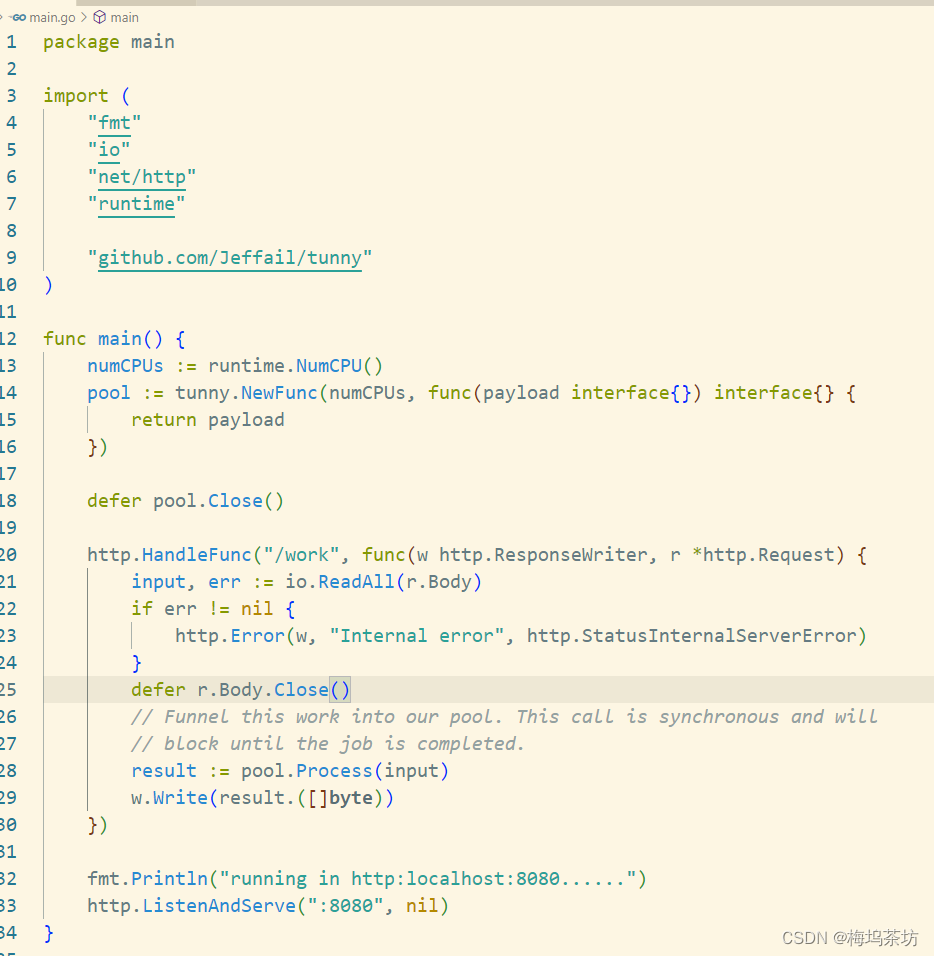
golang协程池库tunny实践
前言 线程池大家都听过,其主要解决的是线程频繁创建销毁带来的性能影响,控制线程数量。 go协程理论上支持百万协程并发,协程创建调度的消耗极低,但毕竟也是消耗对吧。 而且协程池可以做一些额外的功能,比如限制并发&…...
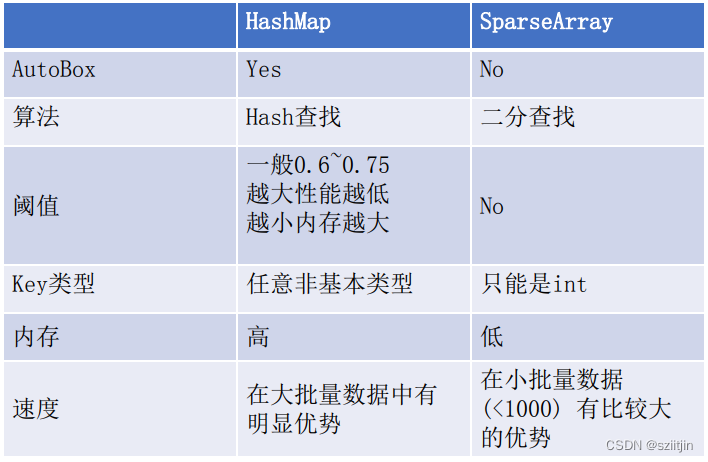
Android性能优化—数据结构优化
优化数据结构是提高Android应用性能的重要一环。在Android开发中,ArrayList、LinkedList和HashMap等常用的数据结构的正确使用对APP性能的提升有着重大的影响。 一、ArrayList ArrayList内部使用的是数组,默认大小10,当数组长度不足时&…...

STL模板——vector详解
一、vector对象的定义和初始化方式 vector 中的数据类型 T 可以代表任何数据类型,如 int、string、class、vector(构建多维数组) 等,就像一个可以放下任何东西的容器,因此 vector 也常被称作容器。字符串类型 string …...
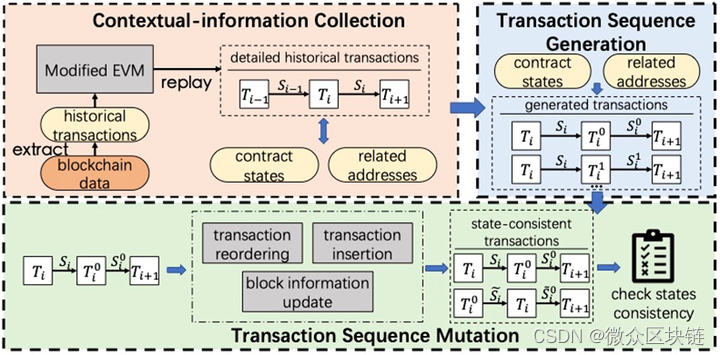
国际顶级学术会议ISSTA召开,中山大学与微众银行联合发表区块链最新研究成果
美国当地时间7月17日,软件工程领域顶级会议ISSTA 2023在西雅图正式召开。ISSTA (The 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis )是软件测试与分析方面最著名的国际会议之一,也是中国计算机学会…...
)
Android开发从0开始(图形与按钮)
Drawable: drawable是抽象类。包括图片,色块,画板,背景。 drawable-ldpi 存放低分辨率图片。drawable-hdpi 高分辨率。drawable-xxhdpi 超高分辨率。 Android:src”drawable/image” 即可使用 Shape: 形状图形。圆角,矩形等常见几…...

Git入门到精通——保姆级教程(涵盖GitHub、Gitee、GitLab)
文章目录 前言一、Git1.Git-概述1.1.Git-概述-版本控制介绍1.2.Git-概述-分布式版本控制VS集中式版本控制1.3.Git-概述-代码托管中心1.4.Git-概述-安装和客户端的使用 2.Git-命令(常用命令)2.1.Git-命令-设置用户签名2.2.Git-命令-初始化本地库2.3.Git-命令-查看本地库状态2.4.…...

题解 | #J.Permutation and Primes# 2023牛客暑期多校8
J.Permutation and Primes 构造 题目大意 给定一个正整数 n n n ,构造一个 n n n 的排列,使得每对相邻元素的和或差的绝对值为一奇素数 解题思路 两个数的和或差是奇数,那么它们的奇偶性一定是不同的,因此所求排列中&#…...
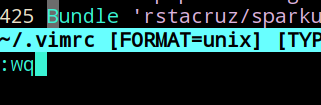
用vim打开后中文乱码怎么办
Vim中打开文件乱码主要是文件编码问题。用户可以参考如下解决方法。 1、用vim打开.vimrc配置文件 vim ~/.vimrc**注意:**如果用户根目录下没有.vimrc文件就把/etc/vim/vimrc文件复制过来直接用 cp /etc/vim/vimrc ~/.vimrc2、在.vimrc中加入如下内容 set termen…...

自然语言处理: 第六章Transformer- 现代大模型的基石
理论基础 Transformer(来自2017年google发表的Attention Is All You Need (arxiv.org) ),接上面一篇attention之后,transformer是基于自注意力基础上引申出来的结构,其主要解决了seq2seq的两个问题: 考虑了原序列和目…...
)
01-Hadoop集群部署(普通用户)
Hadoop集群部署(普通用户) 环境准备 1)准备3台客户机(关闭防火墙、静态IP、主机名称) 如果这一步已经配置过了,可以忽略 # 1 关闭防火墙 systemctl stop firewalld.service # 关闭当前防火墙 systemctl…...

DC电源模块关于的电路布局设计
BOSHIDA DC电源模块关于的电路布局设计 DC电源模块是现代电子设备中常用的电源模块之一,其功能是将市电或其他输入电源转换成定电压、定电流的直流电源输出,以满足电子设备的供电需求。电路布局的设计是DC电源模块的重要组成部分,它直接影响…...
)
MATLAB实现免疫优化算法(附上多个完整仿真源码)
免疫优化算法是一种基于免疫学原理的优化算法。该算法的基本思想是通过模拟人类免疫系统的功能,来寻找最优解。 MATLAB是一种专门用于数学计算和数据处理的软件工具,它具有强大的数学计算和数据分析能力,可以方便地实现各种优化算法。 本文…...
登录界面中图片验证码的生成和校验
一、用pillpw生成图片验证码 1、安装pillow pip install pip install pillow2、下载字体 比如:Monaco.ttf 3、实现生成验证码的方法 该方法返回一个img ,可以把这个img图片保存到内存中,也可以以文件形式保存到磁盘,还返回了验证码的文字…...

go的make使用
在 Go 语言中,make 是一个用于创建切片、映射(map)和通道(channel)的内建函数。它提供了一种初始化和分配内存的方式,用于创建具有特定长度和容量的数据结构。下面将详细介绍 make 函数的使用方法和各种情况…...
竞赛项目 深度学习实现语义分割算法系统 - 机器视觉
文章目录 1 前言2 概念介绍2.1 什么是图像语义分割 3 条件随机场的深度学习模型3\. 1 多尺度特征融合 4 语义分割开发过程4.1 建立4.2 下载CamVid数据集4.3 加载CamVid图像4.4 加载CamVid像素标签图像 5 PyTorch 实现语义分割5.1 数据集准备5.2 训练基准模型5.3 损失函数5.4 归…...
一元三次方程求解
一元三次方程求解 题目描述提示输入输出格式输入格式输出格式 输入输出样例输入样例输出样例 算法分析A C 代码 题目描述 有形如: a x 3 b x 2 c x d 0 ax^3bx^2c^xd0 ax3bx2cxd0一元三次方程。给出该方程中各项的系数 ( a a a, b b b,…...

基于java在线音乐网站设计与实现
在线音乐网站的设计与实现 摘 要 随着互联网趋势的到来,各行各业都在考虑利用互联网将自己推广出去,最好方式就是建立自己的互联网系统,并对其进行维护和管理。在现实运用中,应用软件的工作规则和开发步骤,采用SSM框架…...

终极OBS虚拟背景插件指南:3步实现专业级AI抠像直播
终极OBS虚拟背景插件指南:3步实现专业级AI抠像直播 【免费下载链接】obs-backgroundremoval An OBS plugin for removing background in portrait images (video), making it easy to replace the background when recording or streaming. 项目地址: https://git…...

MCP SQL Bridge:为AI助手安全连接本地数据库,实现智能数据查询
1. 项目概述:为你的AI助手装上数据库的“眼睛”如果你和我一样,日常开发中有一半的时间都在和数据库打交道,那你肯定也经历过这样的场景:想快速查一下某个表的结构,或者写个稍微复杂点的联表查询,都得在IDE…...

掌握JSTL核心标签:从入门到精通
JSTL核心标签库学习笔记在现代Java Web开发中,JSP标准标签库(JSTL)扮演着关键角色,它能有效替代JSP页面中的Java脚本代码,提升代码可读性和可维护性。本文将基于学习笔记,系统讲解JSTL核心标签库的核心功能…...

LFM2.5-VL-1.6B环保监测实践:水质检测图识别+指标分析+报告初稿生成
LFM2.5-VL-1.6B环保监测实践:水质检测图识别指标分析报告初稿生成 1. 项目概述 LFM2.5-VL-1.6B是Liquid AI推出的一款轻量级多模态大模型,专为边缘设备设计。这个1.6B参数的视觉语言模型(1.2B语言400M视觉)能够在低显存环境下高…...
)
保姆级教程:用川崎机器人AS语言实现多客户端TCP服务器(附完整代码)
川崎机器人AS语言构建工业级TCP服务器的实战指南 在工业自动化领域,机器人作为核心控制单元,经常需要与多个外部设备建立实时通信。川崎机器人的AS语言提供了强大的TCP通信功能,但官方示例往往只展示基础的单客户端连接场景。本文将彻底解决多…...
如何用Pixelle-Video快速制作专业短视频:AI全自动视频生成工具完全指南
如何用Pixelle-Video快速制作专业短视频:AI全自动视频生成工具完全指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video Pixe…...

森利威尔SL4011 是专门针对单节两节锂电3.7V 5V 7.4V升压恒压9V 12V 16V 内置MOS 峰值10A电流
输入兼容强,扩展超灵活 输入电压 2.7V - 12V,完美覆盖单节锂电池 3.0V - 4.2V 全周期,低至 3V 也能稳出 5V,告别电量低输出中断的尴尬。还支持单双节锂电池输入,智能穿戴、移动电源等便携设备电源架构都能适配。效率高…...

OpenAI官方终于说了:GPT-5.5提示词越简单越好,别再给冗长指令了
GPT-5.5来了,OpenAI说提示词该变写法了:越简单越好4月24日,OpenAI发布了新一代大模型GPT-5.5。比模型本身更值得注意的,是同步发布的官方提示词指南——这份指南传达了一个明确信号:GPT-5.5足够聪明,不需要…...
别再只数data_count了!巧用Xilinx FIFO的可编程标志(prog_full/empty)做精准流控
突破传统计数局限:Xilinx FIFO可编程标志的高效流控实践 在高速数据处理的FPGA设计中,FIFO(先进先出存储器)作为数据缓冲的核心组件,其性能直接影响系统吞吐量和稳定性。许多工程师习惯依赖rd_data_count和wr_data_cou…...

XXMI Launcher终极指南:一站式游戏模组管理器快速上手教程
XXMI Launcher终极指南:一站式游戏模组管理器快速上手教程 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否厌倦了为每个米哈游游戏单独安装不同的模组管理器&a…...