6.6 实现卷积神经网络LeNet训练并预测手写体数字
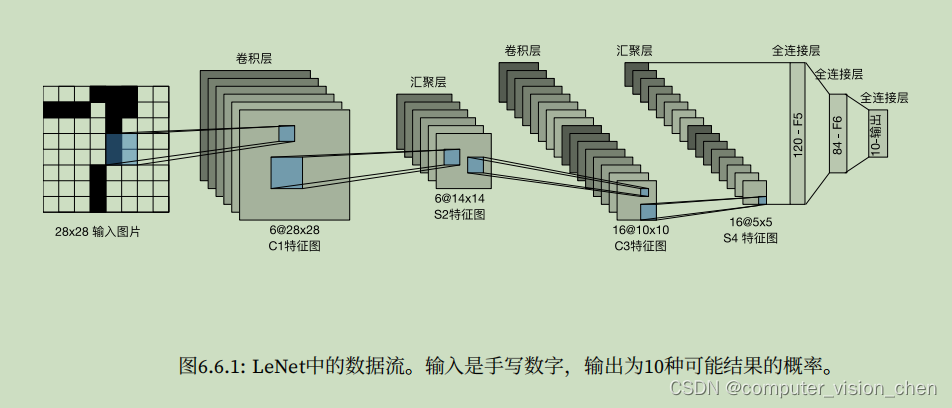
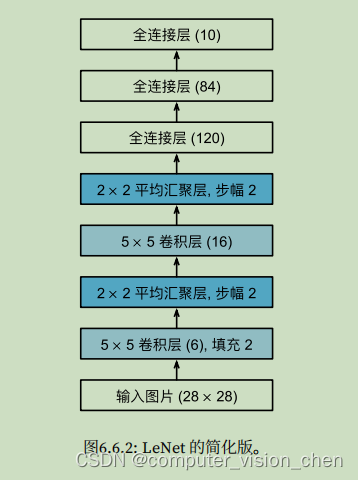
模型架构
代码实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),#padding=2补偿5x5卷积核导致的特征减少。nn.AvgPool2d(kernel_size=2,stride=2),nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2,stride=2),nn.Flatten(),nn.Linear(16*5*5,120),nn.Sigmoid(),nn.Linear(120,84),nn.Sigmoid(),nn.Linear(84,10)
)
'''定义X,并打印模型的形状'''
# 第一个参数是样本
X = torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)
# 输出如下:
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
'''定义训练批次并加载训练集和测试集'''
batch_size = 256
# 按照batch_size把数据集取出来。取出来之后是放到内存中的,后面要把它加载到GPU中
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
# 计算预测正确的个数
def accuracy(y_hat,y):'''计算预测正确的数量'''if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:# y_hat是下标表示类别,值是该类别的概率。模型结果是预测10个类的概率,谁的概率最大,就取谁的下标y_hat = y_hat.argmax(axis=1)# y_hat.type(y.dtype):因为==对数据类型很敏感,因此我们将y_hat的数据类型转换为与y的数据类型一致。# y_hat.type(y.dtype) == y,将预测值y_hat与真实值y比较,返回一个包含 0和1的张量,赋值给cam,最后求和会得到正确预测的数量。cam = y_hat.type(y.dtype) == yreturn float(cam.type(y.dtype).sum())
def evaluate_accuracy_gpu(net,data_iter,device=None):if isinstance(net,nn.Module):net.eval() # 将模型设置为评估模式if not device:'''iter(net.parameters())是将参数集合转换为迭代器,并获取其中的第一个元素next(iter(net.parameters())).device ,指取到net.parameters()的第一个元素,获取该元素的设备。'''device = next(iter(net.parameters())).device# Accumulator用于对多个变量进行累加,d2l.Accumulator(2) 是在Accumulator实例中创建了2个变量,分别用于存储正确预测的数量和预测的总数量。当我们遍历数据集时,两者都随着时间的推移而累加。metric = d2l.Accumulator(2) # 正确预测数,预测总数with torch.no_grad():for X,y in data_iter:if isinstance(X,list): # 详见文章最下面的补充内容X = [x.to(device) for x in X] # 令X使用设备deviceelse:X = X.to(device)y = y.to(device)# y.numel()是批次中样本的数量,accuracy(net(X),y)是用于计算模型在输入数据X上的输出结果与标签Y之间的准确率。# metric.add函数将正确预测的数量 和 样本数量作为参数传递进去,用于记录和累计这些指标的值。metric.add(accuracy(net(X),y),y.numel())return metric[0]/metric[1] # 返回准确率,其中metric[0]存放的是正确预测的个数,metric[1]存放的是样本数量,
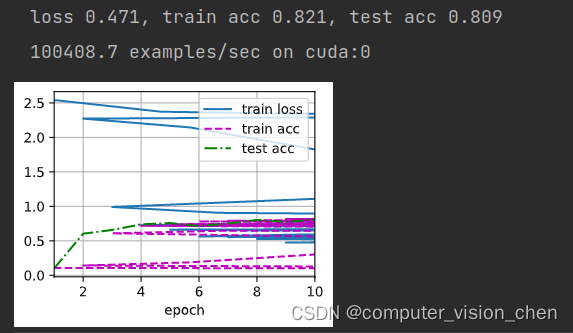
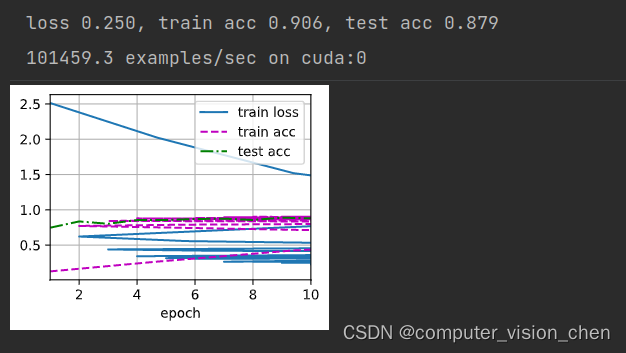
def train_ch6(net,train_iter,test_iter,num_epochs,lr,device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d: # 对神经网络中的线性层和卷积层的权重进行初始化nn.init.xavier_uniform_(m.weight) #用于初始化权重的函数,net.apply(init_weights)print('training on',device)net.to(device) # 设置模型使用deviceoptimizer = torch.optim.SGD(net.parameters(),lr=lr)loss = nn.CrossEntropyLoss()'''该代码创建了一个名为animator的动画器,用于在训练过程中可视化损失函数和准确率的变化情况'''animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],legend=['train loss','train acc','test acc'])timer,num_batches = d2l.Timer(),len(train_iter)for epoch in range(num_epochs):# 创建 Accumulator类,统计训练损失之和,正确预测个数之和,样本数metric = d2l.Accumulator(3)net.train()for i,(X,y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X,y = X.to(device),y.to(device)y_hat = net(X)l = loss(y_hat,y)l.backward()optimizer.step()with torch.no_grad():metric.add(l*X.shape[0], d2l.accuracy(y_hat,y), X.shape[0])timer.stop()train_l = metric[0] / metric[2] # 损失之和 / 样本数train_acc = metric[1] / metric[2] # 正确预测个数 / 样本数if (i+1) % (num_batches//5)==0 or i == num_epochs-1:animator.add(epoch + (i+1)/num_epochs,(train_l,train_acc,None))test_acc = evaluate_accuracy_gpu(net,test_iter)animator.add(epoch+1,(None,None,test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
# 定义学习率和批次 开始训练
lr,num_epochs = 0.9,10
train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
练习
把平均汇聚层改为最大汇聚层
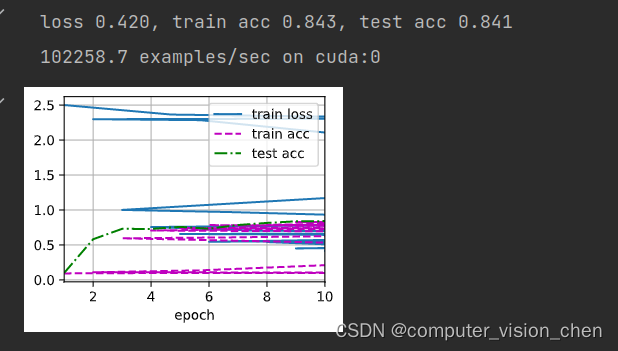
把平均池化改为最大池和把激活函数改为RelU之后的效果
net = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.ReLU(),#padding=2补偿5x5卷积核导致的特征减少。nn.MaxPool2d(kernel_size=2,stride=2),nn.Conv2d(6,16,kernel_size=5),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2),nn.Flatten(),nn.Linear(16*5*5,120),nn.ReLU(),nn.Linear(120,84),nn.Sigmoid(), #注意,此处不能改为RelU,此处的sigmoid是把预测结果映射成概率nn.Linear(84,10)
)
使用训练好的模型进行预测
y_hat = net(x)
补充:
isinstance(net,nn.Module)
isinstance(net,nn.Module)是Python的内置函数,用于判断一个对象是否属于制定类或其子类的实例。如果net是nn.Module类或子类的实例,那么表达式返回True,否则返回False. nn.Module是pytorch中用于构建神经网络模型的基类,其他神经网络都会继承它,因此使用 isinstance(net,nn.Module),可以确定Net对象是否为一个有效的神经网络模型。
`nn.init.xavier_uniform_(m.weight)
nn.init.xavier_uniform_(m.weight) 是一个用于初始化权重的函数,采用的是 Xavier 均匀分布初始化方法。
在神经网络中,权重的初始化非常重要,合适的初始化可以帮助网络更好地学习和收敛。Xavier 初始化方法是一种常用的权重初始化方法之一,旨在使权重在前向传播过程中保持方差不变。
具体而言,nn.init.xavier_uniform_() 函数会对输入的权重张量 m.weight 进行操作,将其初始化为一个均匀分布中的随机值。这个均匀分布的范围根据权重张量的形状进行调整,以保持前向传播过程中特征的方差稳定。
通过使用 Xavier 初始化方法,可以加速神经网络的训练过程,并且有助于避免梯度消失或梯度爆炸等问题。
相关文章:
6.6 实现卷积神经网络LeNet训练并预测手写体数字
模型架构 代码实现 import torch from torch import nn from d2l import torch as d2lnet nn.Sequential(nn.Conv2d(1,6,kernel_size5,padding2),nn.Sigmoid(),#padding2补偿5x5卷积核导致的特征减少。nn.AvgPool2d(kernel_size2,stride2),nn.Conv2d(6,16,kernel_size5),nn.S…...
Django路由Router
文章目录 一、路由router路由匹配命名空间反向解析 二、实践创建用户模型Model添加子路由 - 创建用户首页页面跳转 - 使用反向解析和命名空间1. 不使用命名空间的效果2. 使用命名空间的效果 用户详情页面跳转 - 路由传参路由传递多个参数re_path 以前写法,了解即可重定向Redire…...
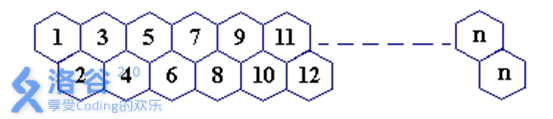
蜜蜂路线 P2437
蜜蜂路线 题目背景 无 题目描述 一只蜜蜂在下图所示的数字蜂房上爬动,已知它只能从标号小的蜂房爬到标号大的相邻蜂房,现在问你:蜜蜂从蜂房 m 开始爬到蜂房 n,m<n,有多少种爬行路线?(备注:题面有误&…...

无脑——010 复现yolov8 使用yolov8和rt detr 对比,并训练自己的数据集
1.配置环境 1. 首先去官网下载yolov8的zip https://github.com/ultralytics/ultralytics 存放在我的目录下G:\bsh\yolov8 然后使用conda创建新的环境 conda create -n yolov8 python3.8 #然后激活环境 conda activate yolov8然后安装pytorch,注意 ,py…...
如何给Google Chrome增加proxy
1. 先打开https://github.com/KaranGauswami/socks-to-http-proxy/releases 我的电脑是Liunx系统所以下载第一个 2. 下载完之后把这个文件变成可执行文件,可以是用这个命令 chmod x 文件名 3. 然后执行这个命令: ./sthp-linux -p 8080 -s 127.0.0.1:…...

设计模式——原型模式
原型模式就是有时我们需要多个类的实例,但是一个个创建,然后初始化,这样太麻烦了,此时可以使用克隆,来创建出克隆对象,就能大大的提高效率。具体就是要让此类实现Cloneable接口,然后重写Object类…...

Spring框架中的Bean生命周期
目录 Bean的实例化 BeanFactoryPostProcessor 属性赋值 循环依赖 初始化 处理各种Aware接口 执行BeanPostProcessor前置处理 执行InitializingBean初始化方法或执行init-method自定义初始化方法 执行BeanPostProcessor后置处理 销毁 Spring Bean 的生命周期总体分为…...

async和await修饰符
async和await是JavaScript中用来处理异步操作的关键字 。 async和await也是解决回调地域的终极方案,简单,而Promise链混杂难以看懂。 async关键字用于定义一个函数,使其返回一个Promise对象。这意味着该函数可以通过await关键字来暂停执行&…...
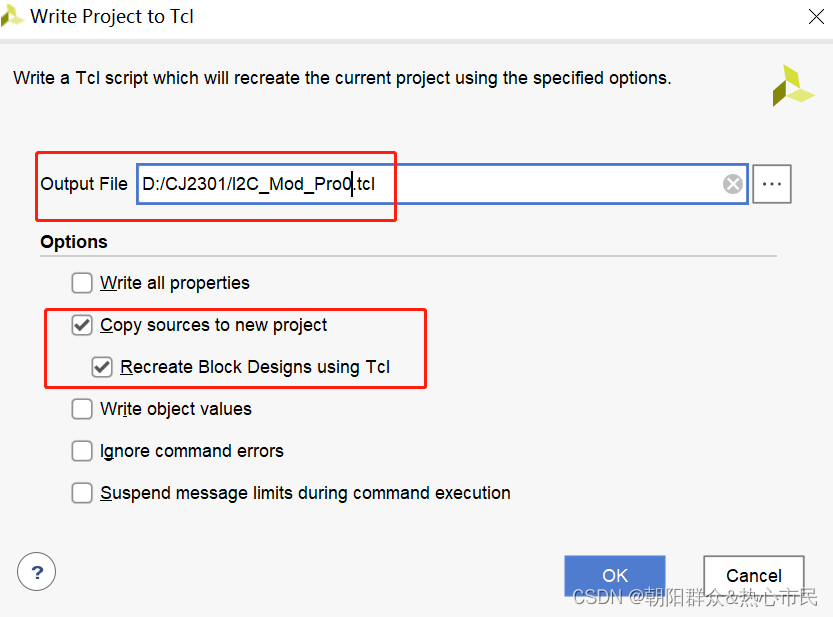
vivado tcl创建工程和Git管理
一、Tcl工程创建 二、Git版本管理 对于创建完成的工程需要Git备份时,不需要上传完整几百或上G的工程,使用tcl指令创建脚本,并只将Tcl脚本上传,克隆时,只需要克隆tcl脚本,使用vivado导入新建工程即可。 优…...

田间农业数字管理系统-高标准农田建设
政策背景 2019年11月,国务院办公厅印发的《国务院办公厅关于切实加强高标准农田建设提升粮食安全保障能力的意见》明确提出,到2022年,全国要建成10亿亩高标准农田。 2021年9月16日,由农业农村部印发的《全国高标准农田建设规划&a…...
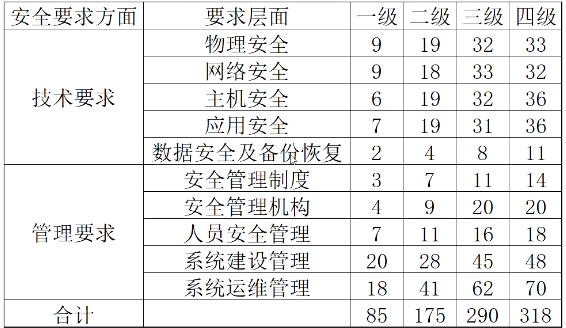
【网络安全】等保测评系列预热
【网络安全】等保测评系列预热 前言1. 什么是等级保护?2. 为什么要做等保?3. 路人甲疑问? 一、等保测试1. 渗透测试流程1.1 明确目标1.2 信息搜集1.3 漏洞探索1.4 漏洞验证1.5 信息分析1.6 获取所需1.7 信息整理1.8 形成报告 2. 等保概述2.1 …...
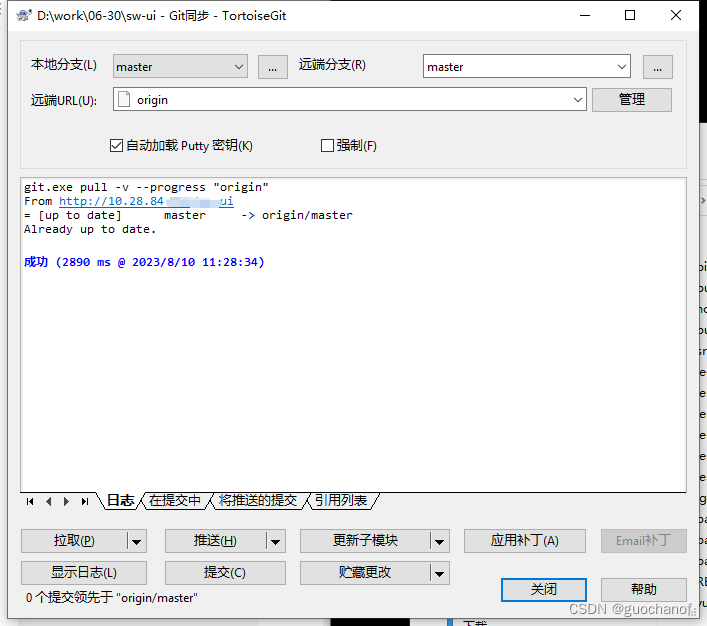
解决: git拉取报错 git 未能顺利结束 (退出码 1)
拉取代码失败信息 解决方法: 执行一下"git push -f origin master"命令即可 步骤: 1.项目文件夹右击选择"Git Bash Here",打开命令窗口 2. 输入"git push -f origin master"后,回画 执行结束 3.再拉取代码,成功...

【深度学习中的批量归一化BN和层归一化LN】BN层(Batch Normalization)和LN层(Layer Normalization)的区别
文章目录 1、概述2、BN层3、LN层4、Pytorch的实现5、BN层和LN层的对比 1、概述 归一化(Normalization) 方法:指的是把不同维度的特征(例如序列特征或者图像的特征图等)转换为相同或相似的尺度范围内的方法,比如把数据特征映射到[…...
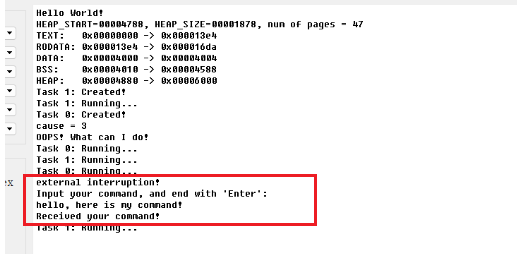
开发一个RISC-V上的操作系统(六)—— 中断(interrupt)和异常(exception)
目录 往期文章传送门 一、控制流 (Control Flow)和 Trap 二、Exceptions, Traps, and Interrupts Contained Trap Requested Trap Invisible Trap Fatal Trap 异常和中断的异同 三、RISC-V的异常处理 mtvec(Machine Trap-Vector Ba…...
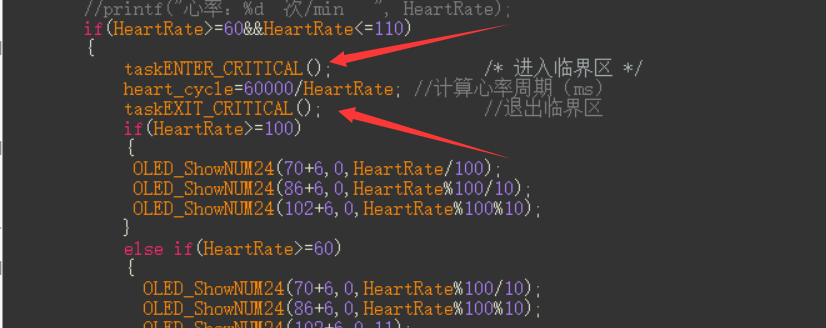
心跳跟随的心形灯(STM32(HAL)+WS2812+MAX30102)
文章目录 前言介绍系统框架原项目地址本项目开发开源地址硬件PCB软件功能 详细内容硬件外壳制作WS2812级联及控制MAX30102血氧传感器0.96OLEDFreeRTOS 效果视频总结 前言 在好几年前,我好像就看到了焊武帝 jiripraus在纪念结婚五周年时,制作的一个心跳跟…...
5. 服务发现
当主机较少时,在抓取配置中手动列出它们的IP地址和端口是常见的做法,但不适用于较大规模的集群。尤其不适用使用容器和基于云的实例的动态集群,这些实例经常会变化、创建或销毁的情况。 Prometheus通过使用服务发现解决了这个问题࿱…...

算法备案背后的原因:确保技术透明度与公正
随着现代技术的发展,算法逐渐渗透到我们日常生活的各个方面,从金融决策到个性化的商品推荐,再到医疗诊断和司法系统。然而,这种无所不在的应用也带来了一系列的社会和伦理问题,尤其是在算法的透明度和公正性上。这正是…...
Linux centos 常用命令 【持续更新】
一、查看文件信息 indoe和目录项 # df命令查看每个硬盘分区的inode总数和已经使用的数量 df -i# 查看inode的大学 xfs_growfs /dev/sda1|grep "isize"# 查看文件的indoe号码 ls -istat查看文件信息 # 文件的详细信息 stat anaconda-ks.cfg # -t参数是在一行内输出…...

《使用 VMware 在 Windows 上搭建 Linux 系统的完整指南》
《使用 VMware 在 Windows 上搭建 Linux 系统的完整指南》 1、准备工作1.1 安装 VMware 软件1.2 下载 Linux 发行版镜像文件1.3 安装SSH工具 2、创建新的虚拟机2.1 VMware页面2.2 打开VMware页面并点击创建新的虚拟机,选择自定义2.3 选择系统兼容性,默认…...

大数据Flink(六十):Flink 数据流和分层 API介绍
文章目录 Flink 数据流和分层 API介绍 一、Flink 数据流...

A.每日一题:2833. 距离原点最远的点
题目链接:2833. 距离原点最远的点(简单) 算法原理: 解法:遍历 1ms击败100.00% 时间复杂度O(N) 思路很简单,由于遇到“_”可左移也可右移,因此我们仅需统计出不加“_”时离原点最远的距离&#x…...

[特殊字符] EagleEye一文详解:DAMO-YOLO TinyNAS如何通过神经架构搜索压缩模型至3.2MB
EagleEye一文详解:DAMO-YOLO TinyNAS如何通过神经架构搜索压缩模型至3.2MB 基于 DAMO-YOLO TinyNAS 架构的毫秒级目标检测引擎 Powered by Dual RTX 4090 & Alibaba TinyNAS Technology 1. 项目简介 EagleEye是一款专为高并发、低延迟场景设计的智能视觉分析系…...

【优化求解】ADMM的电动车辆车队最优充电策略【含Matlab源码 15374期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

碧蓝航线Alas自动化脚本:告别繁琐操作,实现游戏全托管终极指南
碧蓝航线Alas自动化脚本:告别繁琐操作,实现游戏全托管终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoSc…...

2026年Hermes Agent/OpenClaw怎么部署?新手部署及token Plan配置详解
2026年Hermes Agent/OpenClaw怎么部署?新手部署及token Plan配置详解。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人办公…...
课程推荐与学习指南)
五大免费大语言模型(LLM)课程推荐与学习指南
1. 大语言模型(LLMs)学习资源概览过去两年,大语言模型(LLMs)的发展速度令人咋舌。从最初的文本补全到现在的多模态交互,这些模型正在重塑我们与数字世界的互动方式。作为一名长期跟踪AI技术发展的从业者&am…...

如何快速解锁加密音乐:3步搞定所有平台限制的实用指南
如何快速解锁加密音乐:3步搞定所有平台限制的实用指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https…...
)
西电C语言期末考,这36道XDOJ真题我帮你刷完了(附完整代码+难度分级)
西电C语言期末考通关指南:36道XDOJ真题深度解析与实战策略 作为经历过西电C语言期末考的"过来人",我深知这份XDOJ题库对备考的重要性。去年此时,我也曾像你们一样,面对浩如烟海的练习题感到无从下手。经过两周的集中攻关…...

终极指南:如何让老Mac重获新生,体验最新macOS系统
终极指南:如何让老Mac重获新生,体验最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果"抛弃"…...

构建企业级AI驱动测试自动化平台的完整架构实战
构建企业级AI驱动测试自动化平台的完整架构实战 【免费下载链接】testsigma Testsigma is an agentic test automation platform powered by AI-coworkers that work alongside QA teams to simplify testing, accelerate releases and improve quality across web, mobile, de…...